El compilador de optimización de AOT generalmente está estructurado de esta manera:
- interfaz que convierte el código fuente en representación intermedia
- Canalización de optimización independiente de la máquina (IR): una secuencia de pasadas que reescribe IR para eliminar secciones y estructuras ineficientes que no pueden convertirse directamente en código de máquina. A veces esta parte se llama de gama media.
- Motor dependiente de la máquina para generar código de ensamblaje o código de máquina.

En algunos compiladores, el formato IR permanece sin cambios durante todo el proceso de optimización, en otros, su formato o cambios semánticos. En LLVM, el formato y la semántica son fijos y, por lo tanto, es posible ejecutar pases en cualquier orden sin el riesgo de compilación incorrecta o bloqueos del compilador.
La secuencia de pases de optimización fue desarrollada por los desarrolladores del compilador, con el objetivo de completar el trabajo en un tiempo aceptable. Cambia de vez en cuando y, por supuesto, hay un conjunto diferente de pases para ejecutar en diferentes niveles de optimización. Uno de los temas a largo plazo en la investigación informática es el uso del aprendizaje automático u otros métodos para encontrar la mejor canalización de optimización para uso general y para aplicaciones específicas para las que la canalización predeterminada no es muy adecuada.
Los principios para diseñar los pasajes son el minimalismo y la ortogonalidad: cada pase debe hacer una cosa bien y su funcionalidad no debe solaparse. En la práctica, los compromisos son a veces posibles. En la práctica, cuando dos pases generan trabajo el uno para el otro, se pueden combinar en un pase más grande. Además, algunas funcionalidades de nivel IR, como plegar operadores constantes, son tan útiles que no tiene sentido colocarlas en un paso separado, LLVM minimiza por defecto las operaciones constantes cuando se crea una instrucción.
En esta publicación veremos cómo funcionan algunos pases de optimización de LLVM. Quiero decir que lees
esta parte sobre cómo Clang compila la función o que entiendes más o menos cómo funciona LLVM IR. Comprender el formulario SSA (asignación única estática) es especialmente útil:
Wikipedia le dará una introducción, y
este libro le dará más información de la que le gustaría saber. Lea también la
Referencia del lenguaje LLVM y una
lista de pases de optimización .
Veamos cómo Clang / LLVM 6.0.1 optimiza este código C ++:
bool is_sorted(int *a, int n) { for (int i = 0; i < n - 1; i++) if (a[i] > a[i + 1]) return false; return true; }
Al mismo tiempo, recordamos que la canalización de optimización es un lugar muy ocupado, y vamos a perder muchos momentos divertidos, como:
La alineación es una optimización simple pero muy importante que no ocurre en este ejemplo, porque consideramos solo una función. Casi todas las optimizaciones específicas para C ++, pero no para C. Auto-vectorización, lo que impide la salida anticipada del bucle
En el texto a continuación, omitiré todos los pases que no realicen cambios en el código. Además, no analizaremos el backend, que también hace mucho trabajo. ¡Pero incluso los pasajes restantes son muchos! (Perdón por las imágenes, pero esta parece ser la mejor manera de evitar dificultades de formato).
Aquí está el archivo IR creado por Clang (eliminé manualmente el atributo "optnone" que Clang insertó) y la línea de comando utilizada para ver el efecto de cada pase de optimización:
opt -O2 -print-before-all -print-after-all is_sorted2.ll
El primer paso es la
simplificación de CFG (gráfico de flujo de control). Como Clang no realiza la optimización, el IR que genera contiene opciones de optimización simples:

Aquí, la unidad base 26 simplemente se mueve al bloque 27. Dichos bloques se pueden eliminar redirigiendo las referencias a ellos por el bloque de destino. LLVM renumerará automáticamente los bloques. La lista completa de conversiones producidas por SimplifyCFG se encuentra en la parte superior del pasillo.
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
La mayoría de las oportunidades para la optimización de CFG aparecen como resultado del trabajo de otros pases LLVM. Por ejemplo, eliminar la eliminación del código muerto y mover invariantes de bucle puede conducir fácilmente a bloques de bases vacíos.
El siguiente pasaje,
SROA (reemplazo escalar de agregados), es uno de los más utilizados. Su nombre genera cierta confusión porque SROA es solo una de sus funciones. El pase verifica cada instrucción alloca (asignación de memoria en la pila de funciones) e intenta convertirla en registros SSA. Una instrucción alloca (
es decir, una variable en la pila de aprox. Transl.) Se convierte en muchos registros si se asigna estáticamente varias veces, y si alloca es una clase o estructura, se divide en componentes (esto se llama "escalar" reemplazo "mencionado en el nombre del pasaje). Una versión simple de SROA se rendiría a las variables de pila para las cuales se usa la operación de tomar una dirección, pero la versión LLVM interactúa con un algoritmo de análisis de alias y actúa de manera inteligente (aunque esto no es necesario en el siguiente ejemplo).

Después de SROA, las instrucciones de alloca (y las instrucciones correspondientes de carga y almacenamiento) desaparecen, y el código se vuelve más limpio y más adecuado para optimizaciones posteriores (por supuesto, SROA no puede eliminar toda alloca en el caso general, esto solo sucede si el análisis de puntero puede deshacerse por completo de los alias). En el proceso, SROA inserta instrucciones phi en el código. Las instrucciones phi forman el núcleo de la representación SSA, y la falta de phi en el código que genera Clang nos dice que Clang genera una versión trivial de SSA, en la que los bloques base están conectados a través de la memoria y no a través de registros SSA.
Lo que sigue es "
eliminación temprana de subexpresiones comunes ", CSE (eliminación temprana de subexpresiones comunes). CSE intenta eliminar los casos de subexpresiones excesivas que pueden ocurrir tanto en código escrito por humanos como en código parcialmente optimizado. "Early CSE" es una versión rápida y fácil de CSE que identifica cálculos triviales redundantes.

Aquí,% 10 y% 17 hacen lo mismo, es decir, el código puede reescribirse para que se use un valor y se elimine el segundo. Esto proporciona una idea de los beneficios de la SSA: cuando cada registro se asigna solo una vez, no existen versiones múltiples de un solo registro. Por lo tanto, los cálculos redundantes se pueden detectar usando equivalencia sintáctica, sin usar un análisis en profundidad del programa (este no es el caso de las ubicaciones de memoria que existen fuera del mundo SSA).
A continuación, se lanzan varios pases que no tienen ningún efecto en nuestro caso, y luego se lanza el "
optimizador de variable global ", que se describe a continuación:
, . , , , , ..Este pasaje realiza los siguientes cambios:
Agregó un atributo de función: metadatos utilizados por una parte del compilador para almacenar información sobre lo que podría ser útil para otra parte del compilador. Puede leer sobre el propósito de este atributo
aquí .
A diferencia de otras optimizaciones que consideramos, el optimizador de variables globales es interprocedural; se ve completamente en el módulo LLVM. Un módulo es (más o menos) el equivalente de una unidad de compilación en C y C ++. En contraste con la optimización interprocedural, intraprocedural ve solo una función a la vez.
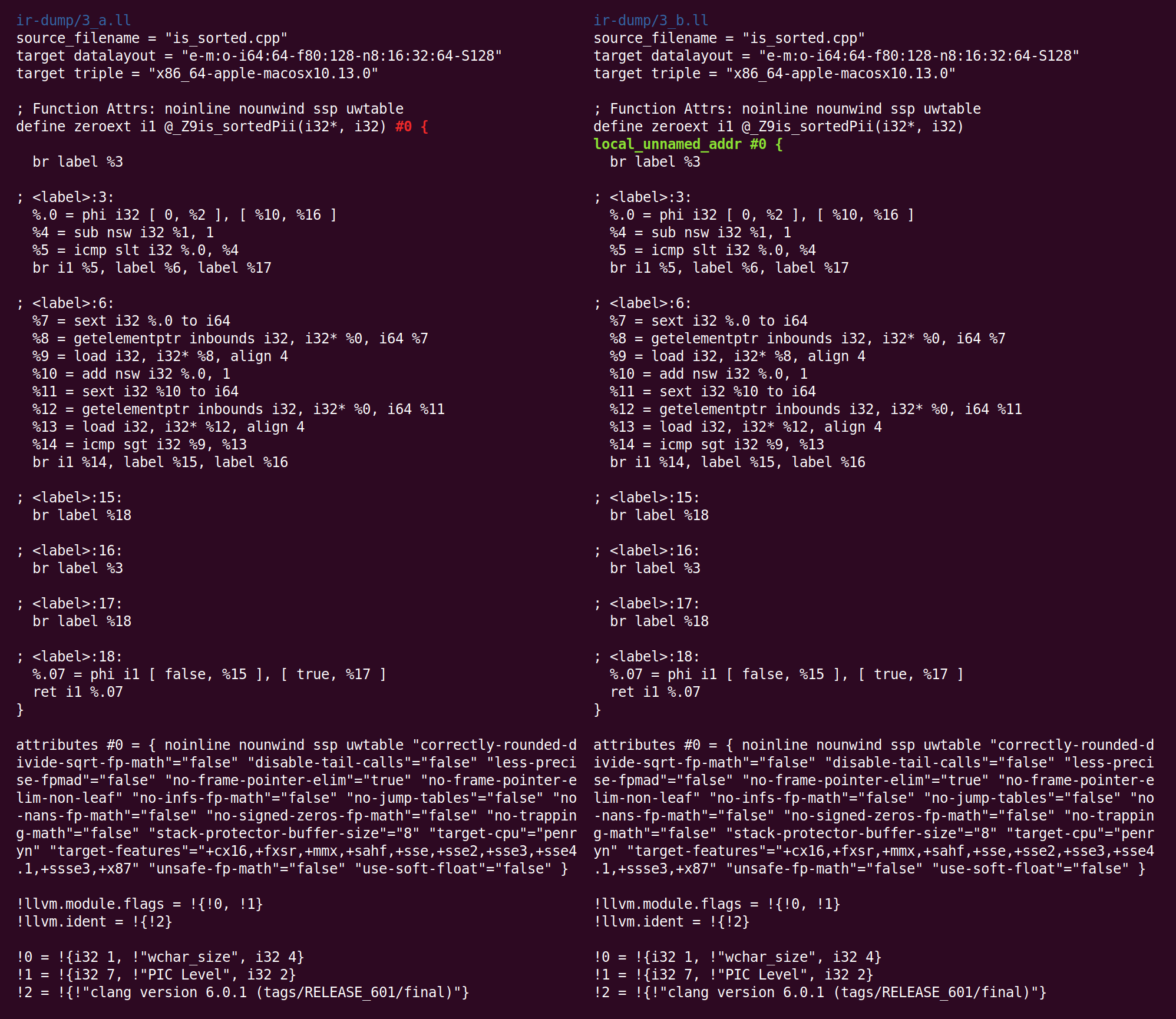
El siguiente pasaje combina instrucciones y se llama "
combinador de instrucciones ", InstCombine. Esta es una colección grande y diversa de
optimizaciones de
mirilla , que (generalmente) reescribe algunas instrucciones, combinadas con datos comunes, en una forma más eficiente. InstCombine no cambia el flujo de control de una función. En el ejemplo anterior, no cambió mucho:
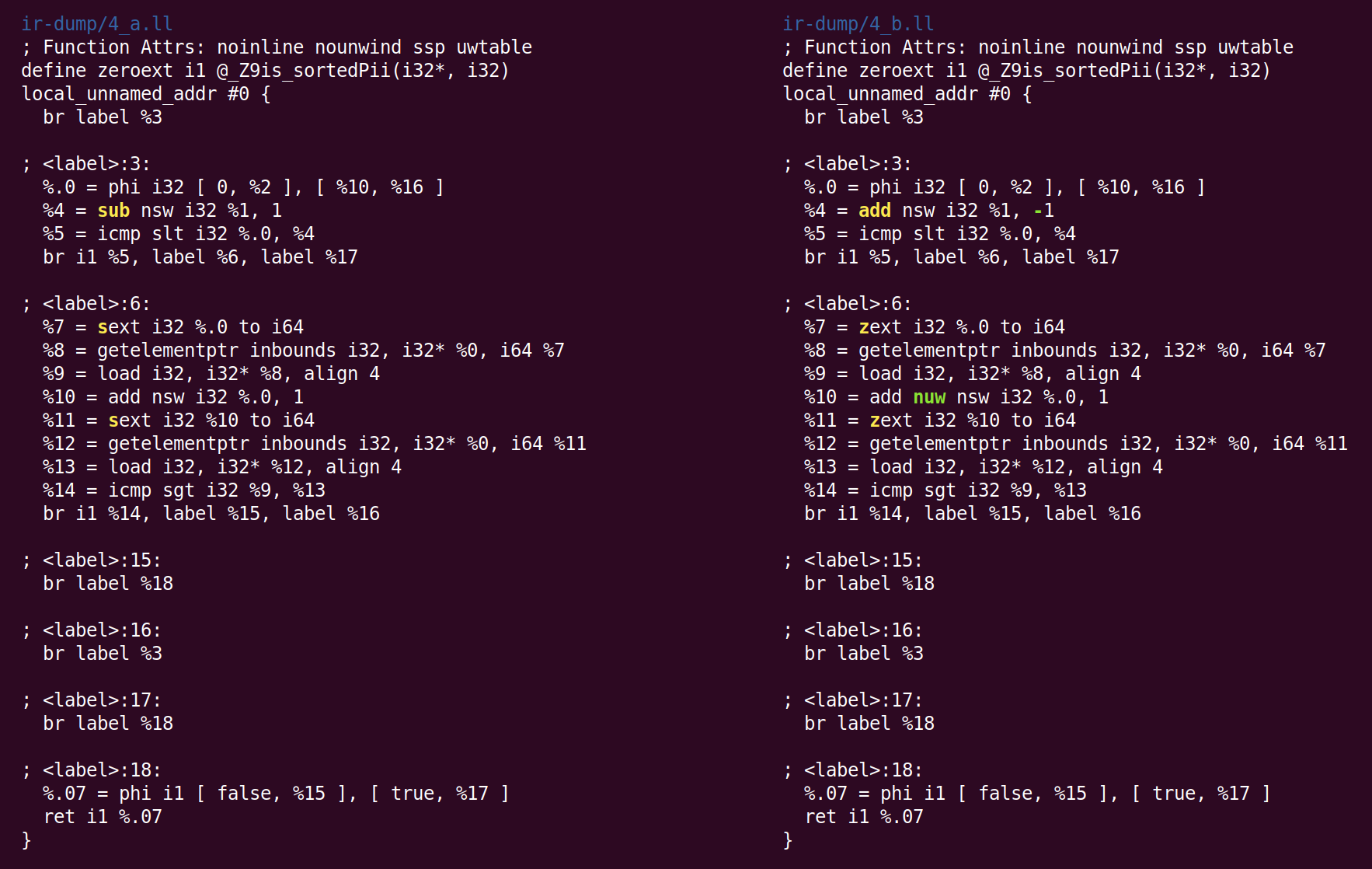
Aquí, en lugar de restar 1 de% 1, para calcular% 4, agregamos -1. Esto no es optimización, sino canonicalización. Cuando hay muchas maneras de hacer el cálculo, LLVM intenta llevarlo a la forma canónica (a menudo elegida al azar) que los pases y backends posteriores esperan ver. El segundo cambio realizado por InstCombine es la forma canónica de dos operaciones de expansión con signo (la instrucción de texto), que calculan% 7 y% 11 convertido a expansión cero (zext). Esta conversión es segura cuando el compilador puede probar que el sexto operando no es negativo. En este caso, esto se debe a que la variable del bucle cambia de 0 a n (si n es negativo, el bucle no se ejecuta en absoluto). El último cambio fue la adición del indicador "nuw" (sin ajuste sin firmar) a la instrucción que calcula% 10. Podemos ver que esto es seguro, por el hecho de que (1) la variable del bucle siempre aumenta y (2) si la variable comienza desde cero y aumenta, quedaría indefinida cuando el signo cambia en la intersección INT_MAX antes de que alcance un desbordamiento sin signo, después de UINT_MAX. Este indicador se puede usar para optimizaciones posteriores.
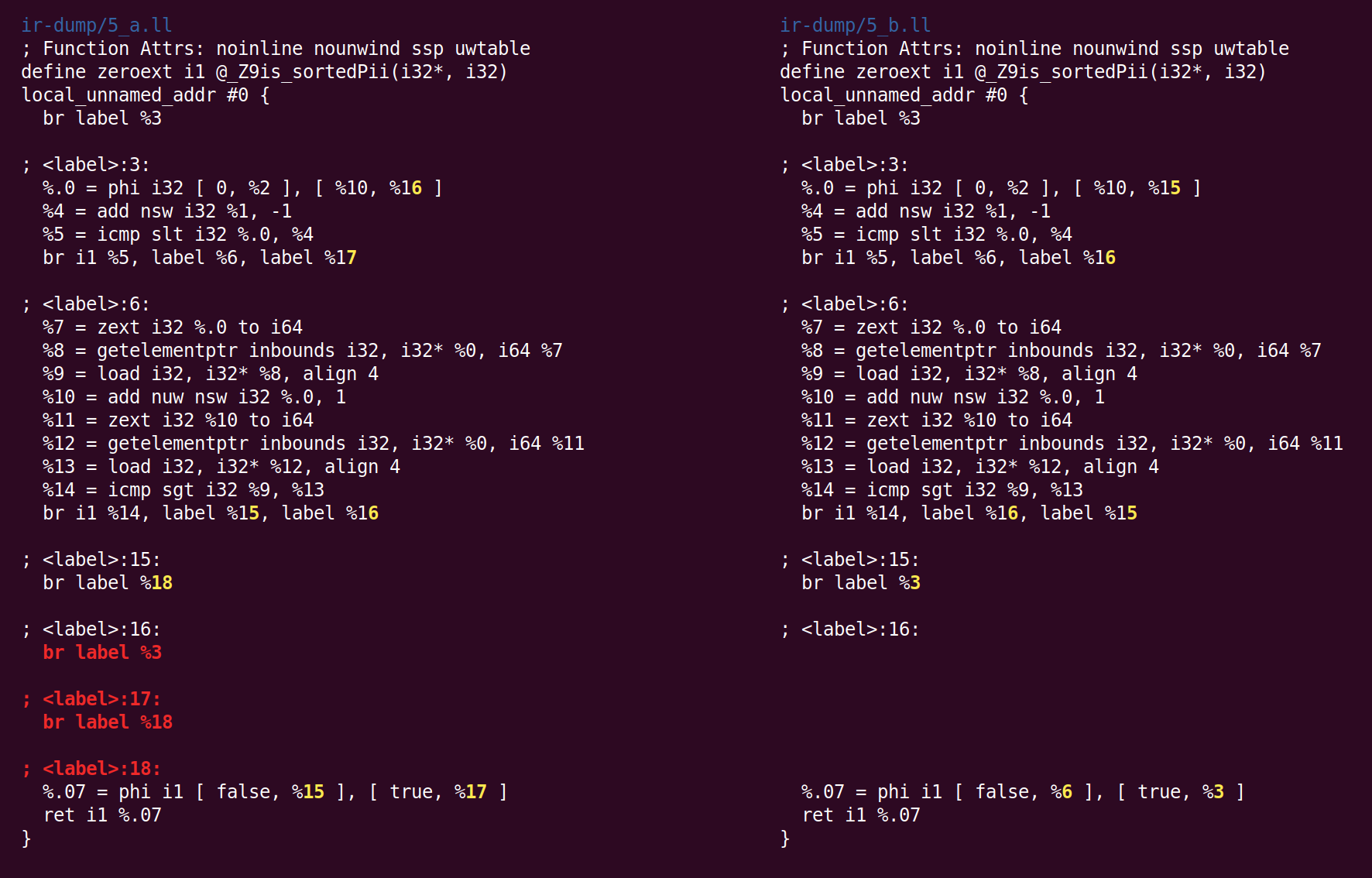
A continuación, SimplifyCFG comienza por segunda vez y elimina dos bloques base vacíos:
Luego, el pase "Deducir atributos de función" anota la función:

"Norecurse" significa que la función no está incluida en ninguna llamada recursiva, "solo lectura" significa que la función no cambia el estado global. El atributo de parámetro "nocapture" significa que el parámetro no se guarda en ningún lugar después de salir de la función, y "solo lectura" significa que la función no modifica la memoria. Puede ver una
lista de atributos de funciones y
atributos de parámetros .
Luego, el pase "
rotar bucles " mueve el código en un intento de mejorar las condiciones para optimizaciones posteriores:

Aunque la diferencia parece intimidante, los cambios son en realidad pequeños. Podemos ver lo que sucedió, de una manera más legible, si le pedimos a LLVM que dibuje un gráfico de transferencia de control antes y después de pasar por los ciclos de rotación. Aquí está su vista antes (izquierda) y después (derecha):
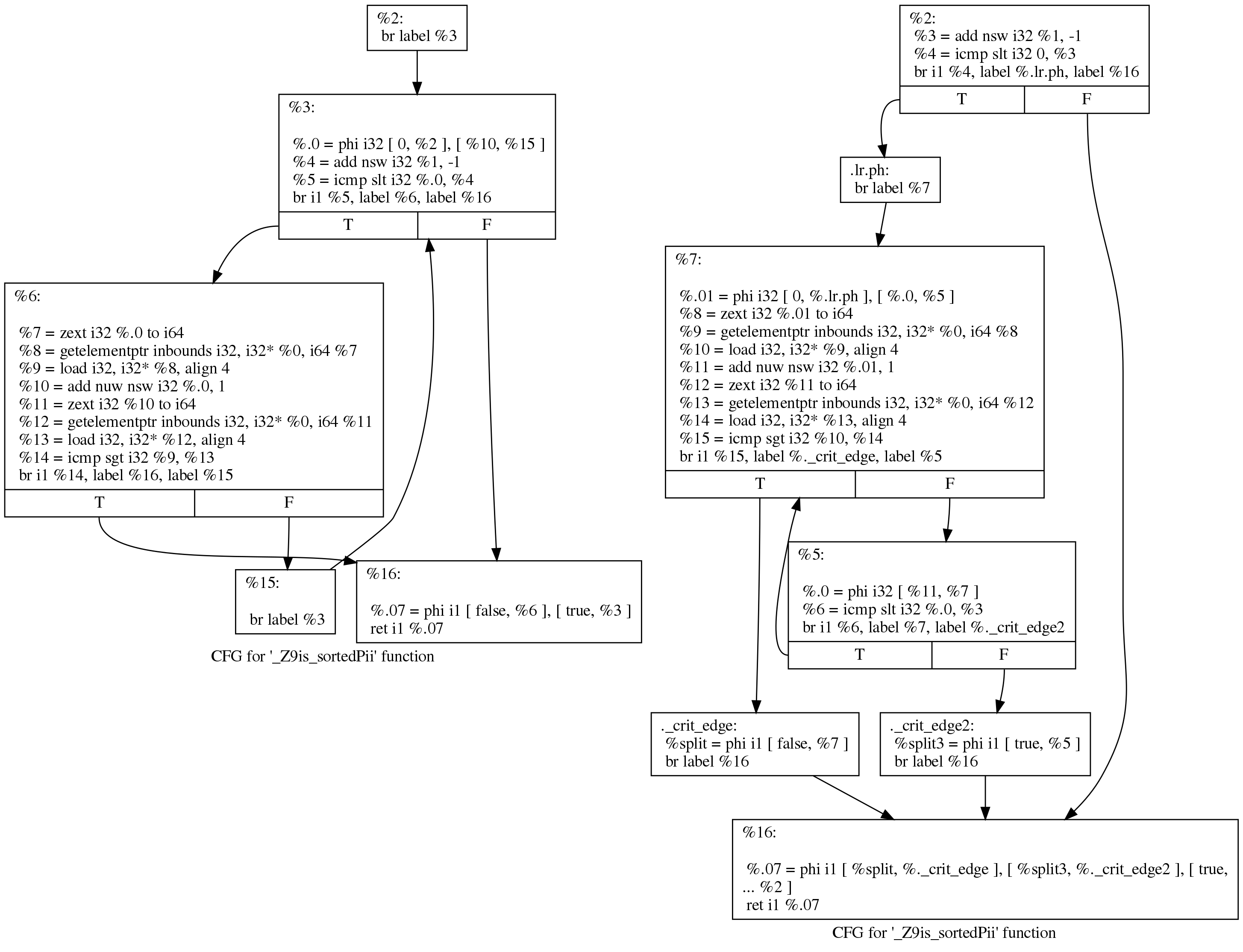
El código original sigue la estructura de bucle que generó Clang:
initializer goto COND COND: if (condition) goto BODY else goto EXIT BODY: body modifier goto COND EXIT:
Después de la ejecución, el bucle se ve así:
initializer if (condition) goto BODY else goto EXIT BODY: body modifier if (condition) goto BODY else goto EXIT EXIT:
(Las correcciones propuestas por Johannes Durfert se enumeran a continuación, ¡gracias!)
El propósito de la pasada de rotación del bucle es eliminar una rama, lo que permite más optimizaciones. No encontré una mejor descripción de esta conversión en Internet.
El pase de simplificación de CFG minimiza dos bloques base que contienen solo instrucciones phi degeneradas (de entrada única):

El paso del combinador de instrucciones convierte “% 4 = 0 s <(% 1 - 1)” en “% 4 =% 1 s> 1 ″ (donde s <y s> son operaciones para comparar operandos firmados), esto transformación útil, reduce la longitud de las cadenas de dependencia y también puede crear instrucciones "muertas" (inalcanzables) (vea el
parche que hace esto). Esta pasada también elimina las instrucciones triviales de phi que fueron agregadas por la pasada de rotación del bucle.

El siguiente es el pasaje "
canonicalizar bucles naturales ", que se describe en su propio código fuente de la siguiente manera:
, .
(Loop pre-header) , , . ,, LICM.
, , ( ) ( ). , , "store-sinking", LICM.
, (backedge).
Indirectbr . , . , , .
, simplifycfg , , , .
, , CFG, .
Aquí vemos que se insertó el bloque de salida:
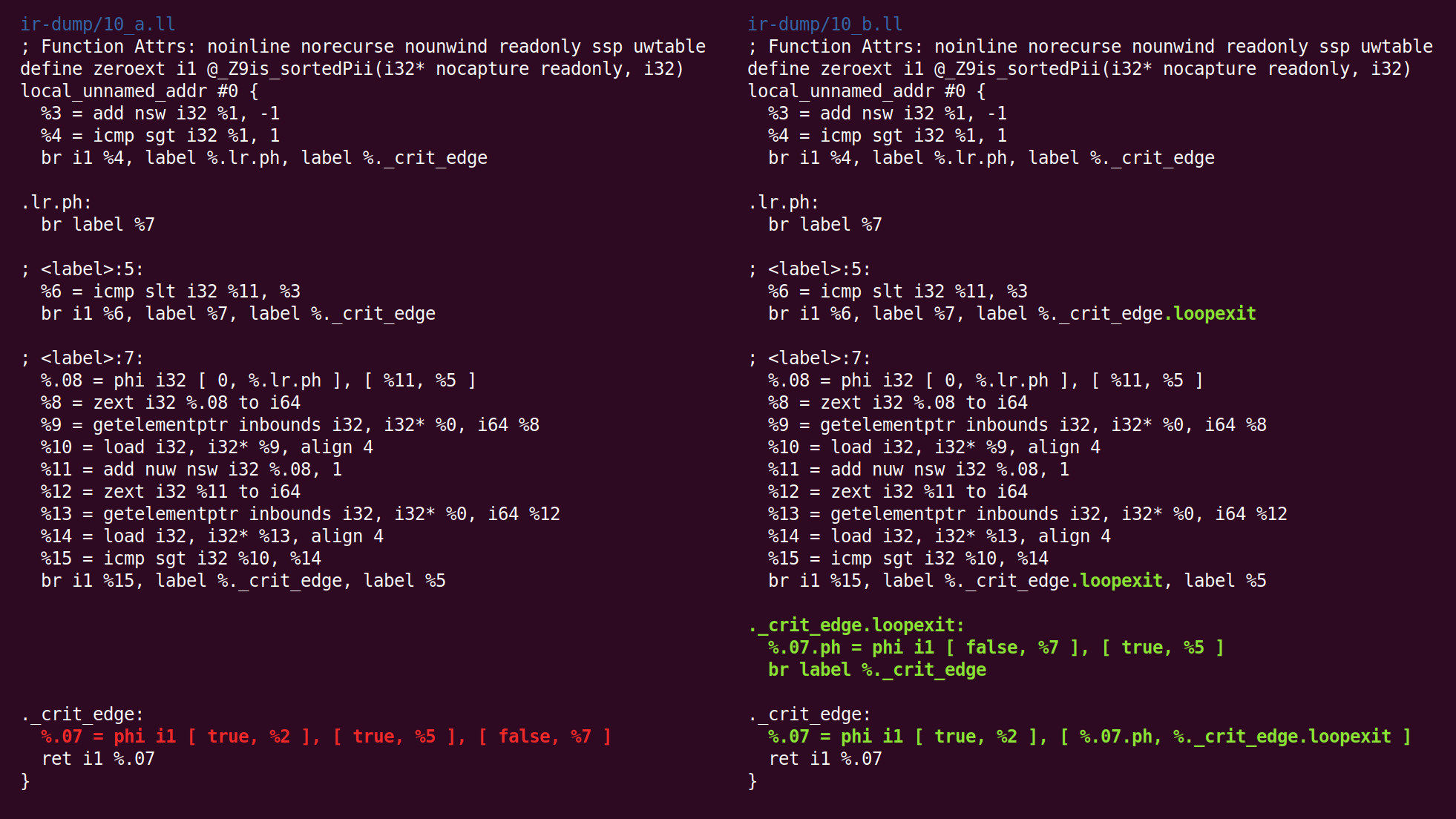
Luego sigue la "
simplificación de la variable de bucle ":
( , ), , .
, :
, . , 'for (i = 7; i*i < 1000; ++i)' 'for (i = 0; i != 25; ++i)'.
indvar , . , "".
El efecto de este pase será cambiar la variable del bucle de 32 bits a 64 bits:
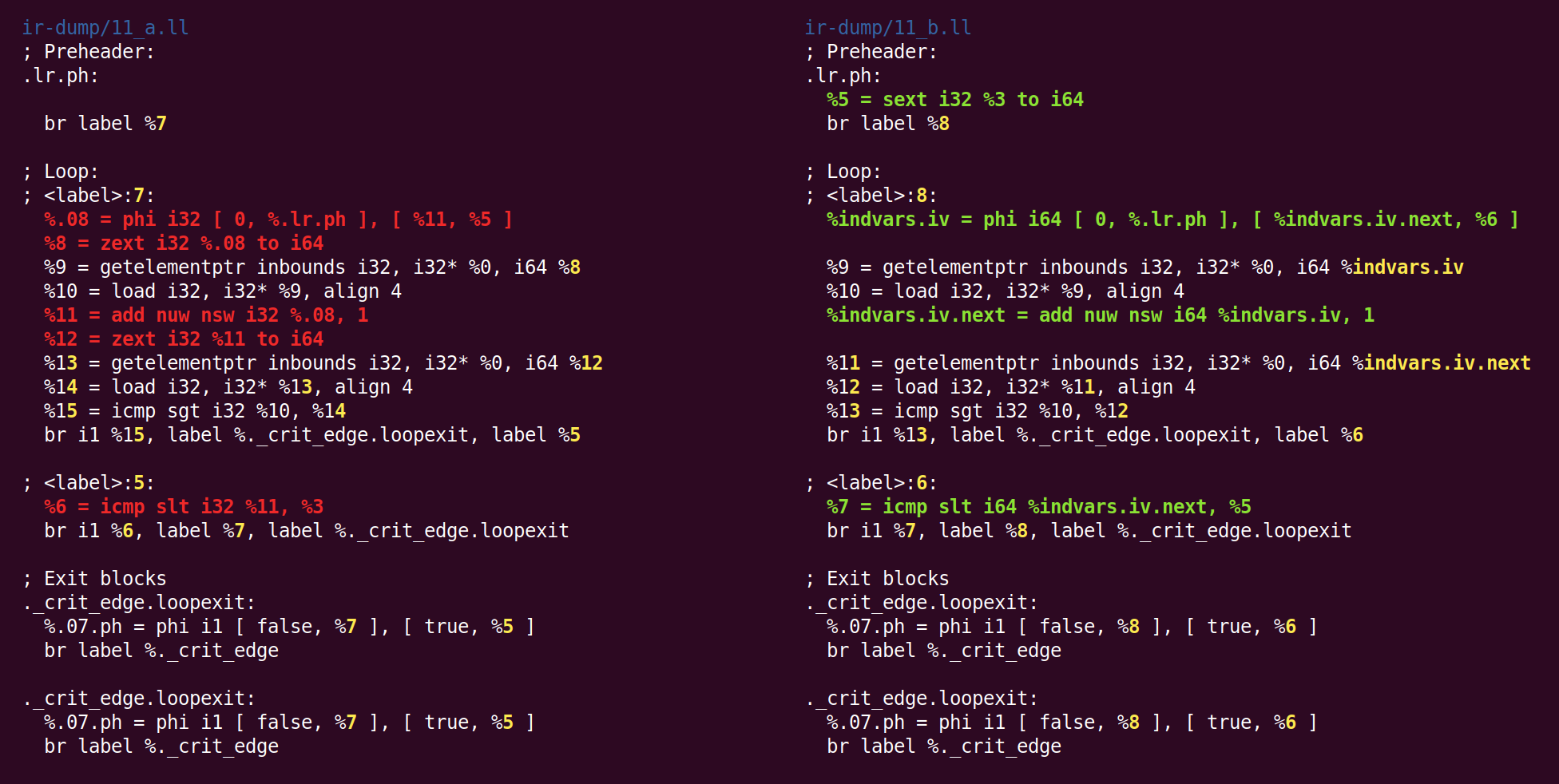
No sé por qué zext - previamente lanzado a la forma canónica desde sext, regresó nuevamente a sext.
Ahora el pase de "
numeración de valor global " está realizando una optimización muy inteligente. Una de las razones para escribir esta publicación es el deseo de mostrarla. ¿Puedes verla aquí?

Viste Sí, dos instrucciones de carga en el bucle de la izquierda, correspondientes a [i] y a [i + 1]. Aquí, el GVN descubrió que cargar un [i] no es necesario, porque un [i + 1] de una iteración del bucle se puede transferir a la siguiente, como un [i]. Este simple truco reduce a la mitad el número de lecturas de memoria realizadas por la función. Tanto LLVM como
GCC han aprendido a realizar esta transformación solo recientemente.
Puede preguntarse si este truco funcionará si comparamos un [i] con un [i + 2]. Resulta que no, pero GCC puede asignar
hasta cuatro registros para tales casos.
Entonces comienza el pase de "
eliminación de código muerto de seguimiento de bits ":
"Bit-Tracking Dead Code Elimination". (, "" "" ..) "" . , "" .Pero aquí resulta que tales trucos no son necesarios, porque el único código muerto es la instrucción GEP (obtener el puntero del elemento), y está trivialmente muerto (el pase GVN eliminó la instrucción de carga que utilizó la dirección calculada por esta instrucción):
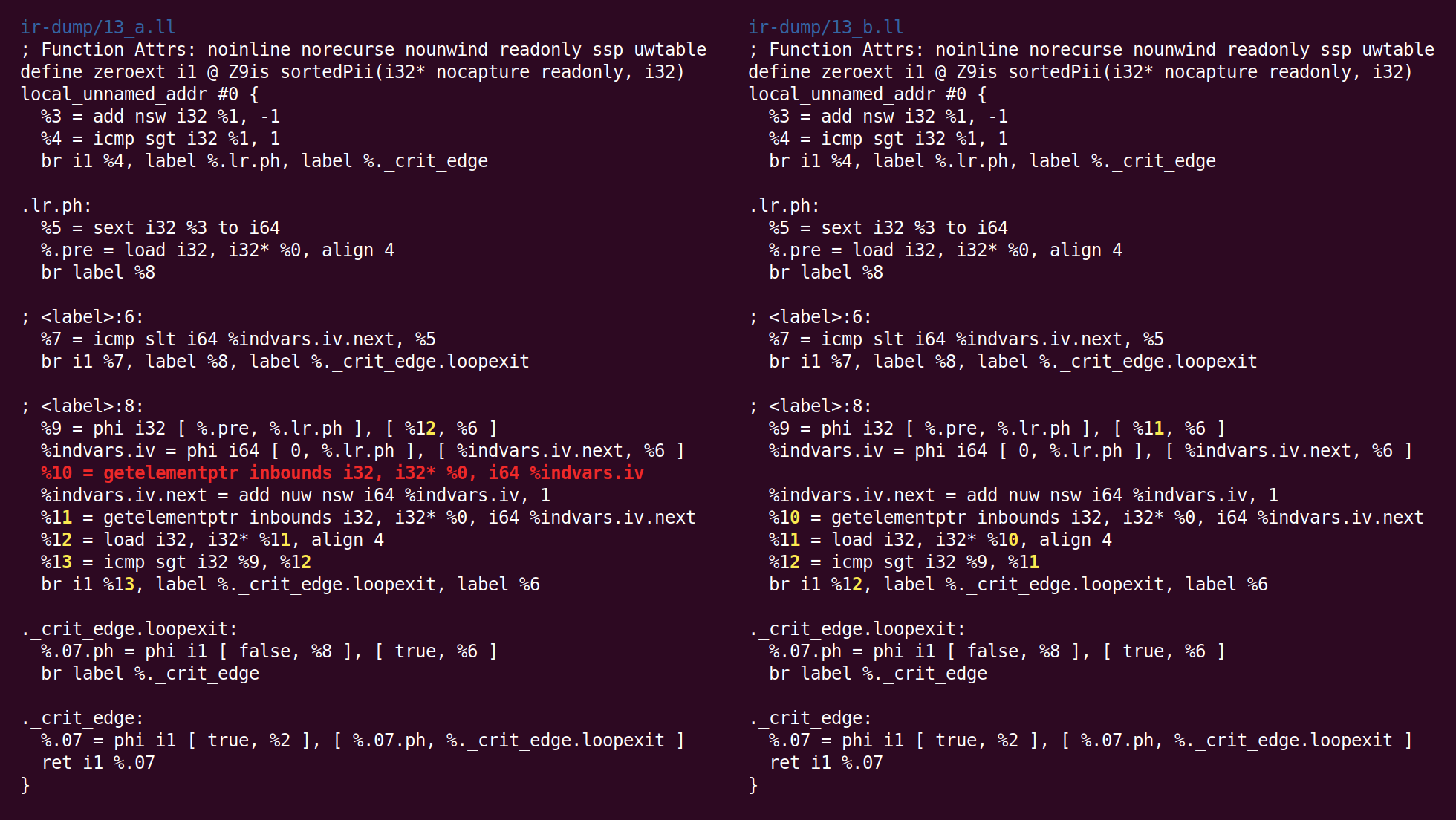
Ahora el algoritmo para combinar instrucciones ha colocado agregar en otra unidad base. La lógica por la cual esta transformación se colocó en InstCombine no está clara para mí, tal vez no haya un lugar obvio donde se pueda colocar:

Algo más extraño está sucediendo ahora: el pase de "
subprocesos de salto " ha eliminado lo que el pase "canonicalizar bucles naturales" había hecho antes:

Luego volvemos a la forma canónica:
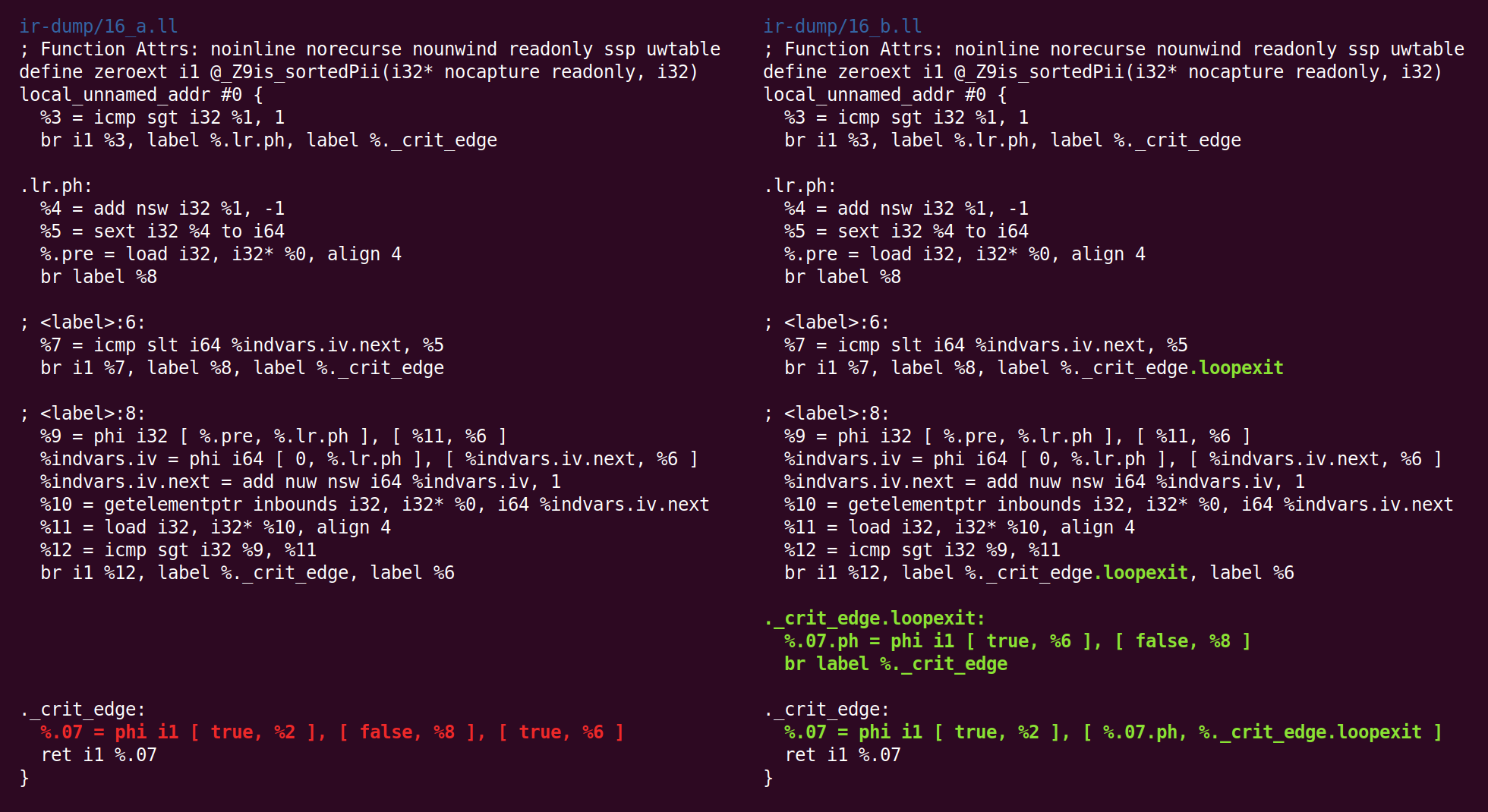
Y la simplificación de CFG lo transforma de manera diferente:
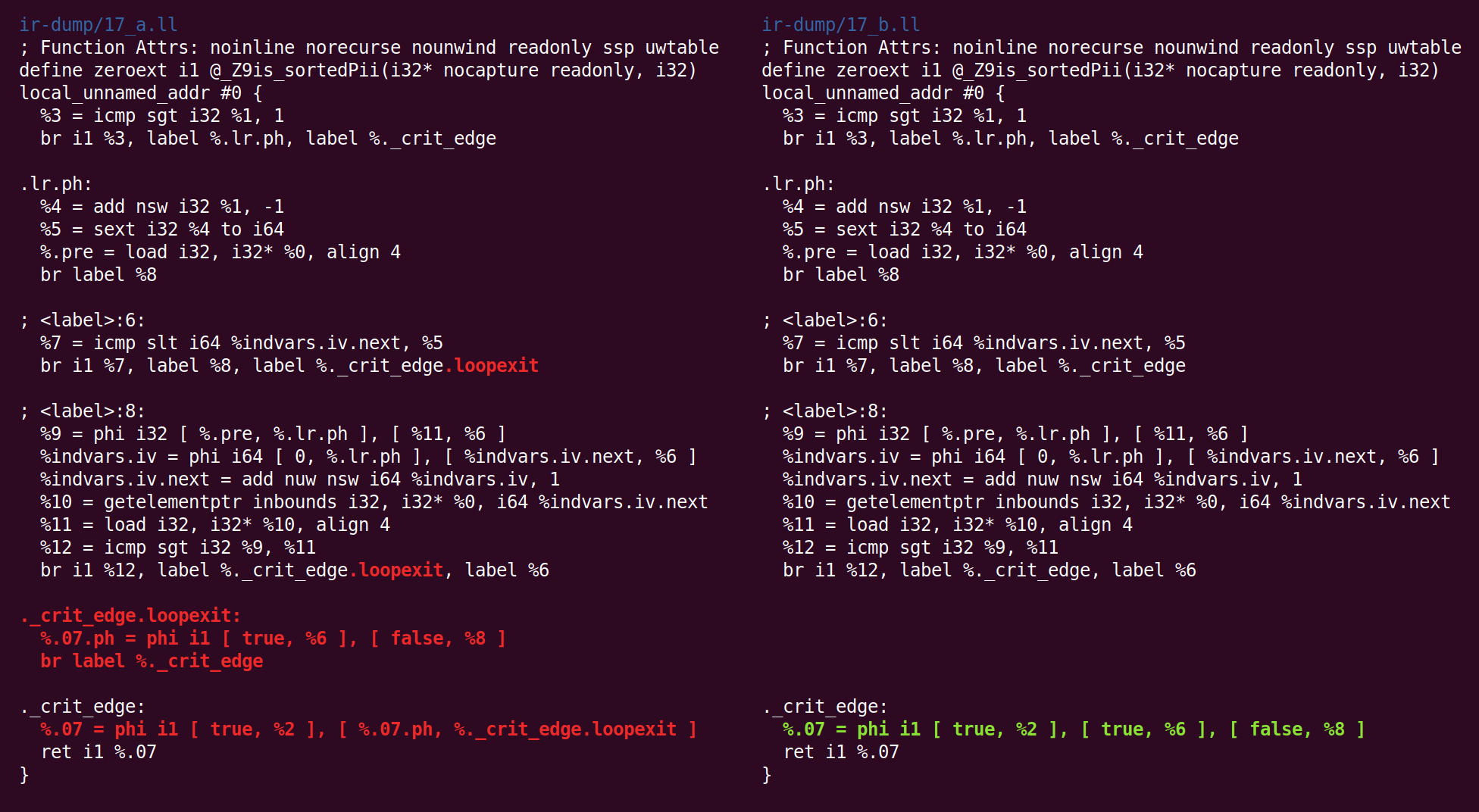
Y de regreso:
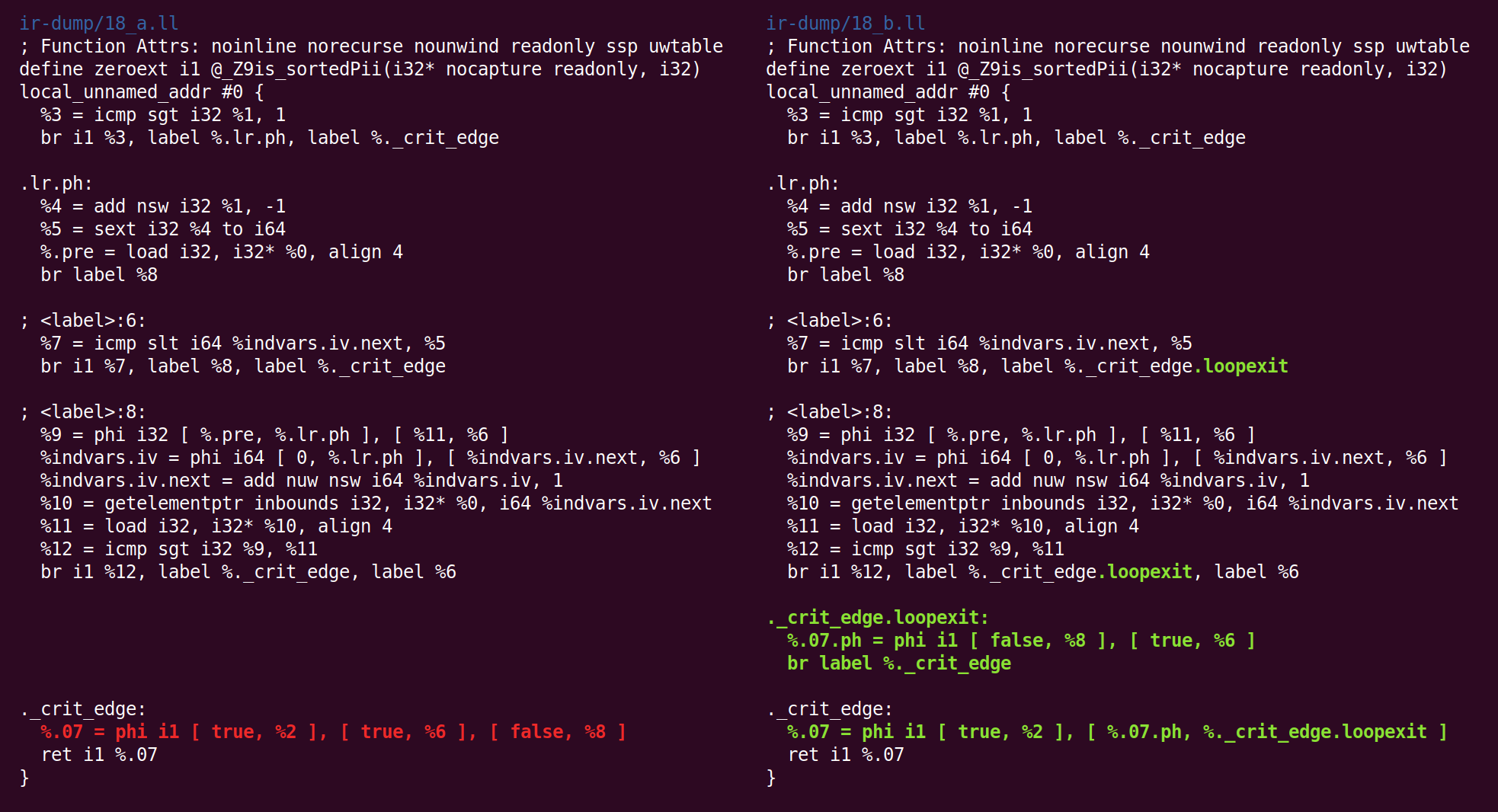
Y allí de nuevo:

Y de regreso:
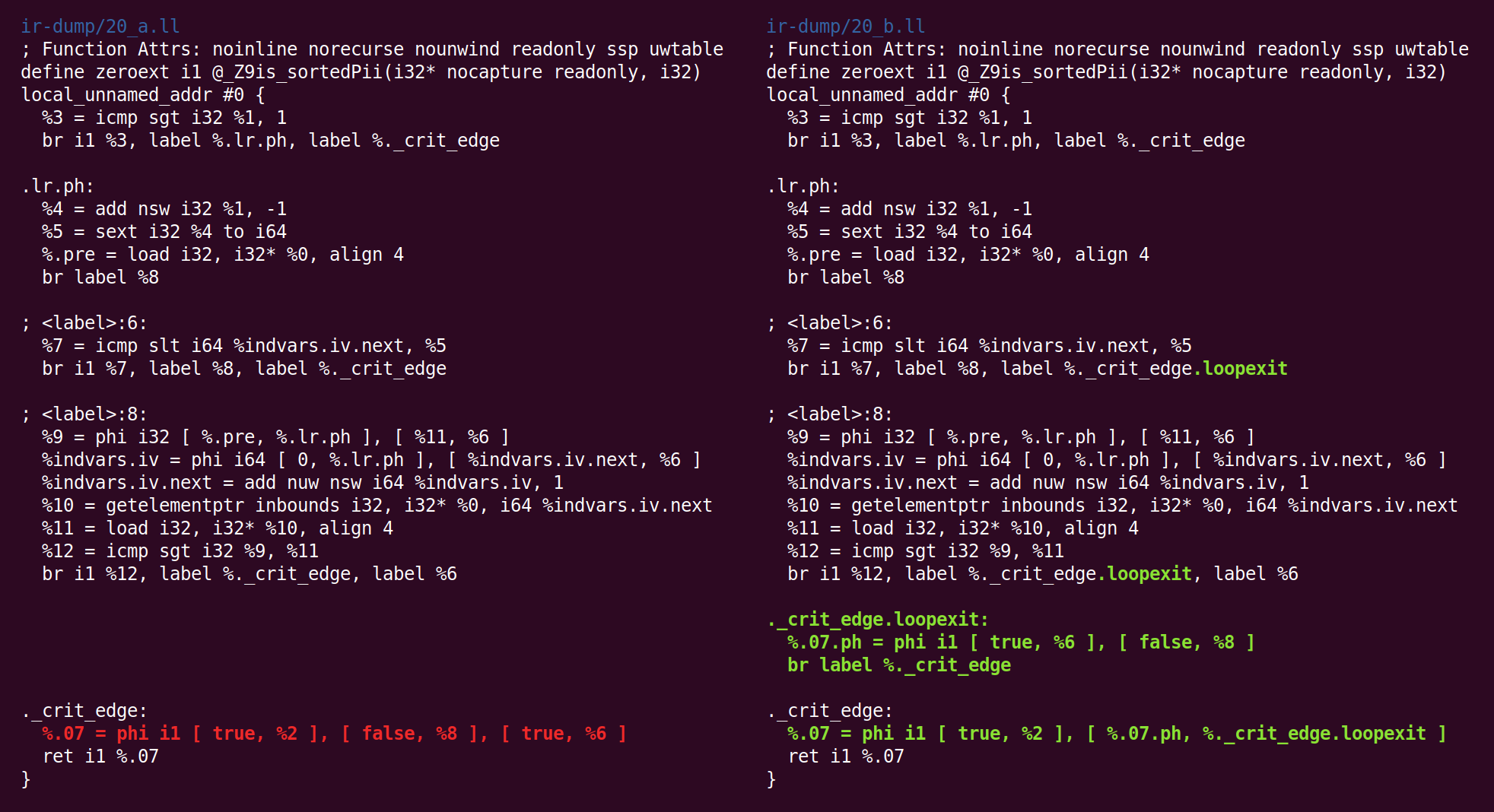
Y ahi:

Y finalmente, ¡hemos terminado con el midland! El código de la derecha es el código que pasaremos (en nuestro caso) al backend x86-64.
Puede que tenga curiosidad si las fluctuaciones en el comportamiento al final de la tubería son el resultado de un error del compilador, pero tengamos en cuenta que esta función es muy, muy simple y hay muchos pases involucrados en su procesamiento, pero ni siquiera los mencioné porque no realizó ningún cambio en el código. A lo largo de la segunda mitad de la canalización de optimización, observamos principalmente casos degenerados para esta función.
Agradecimientos: algunos estudiantes en mi curso de compilación en profundidad este otoño dejaron comentarios sobre un borrador de esta publicación (y también utilicé este material para la tarea). Revisé las funciones discutidas aquí en
este buen conjunto de conferencias sobre optimización de bucles.