¿Cómo normalizar adecuadamente el evento? ¿Cómo normalizar eventos similares de diferentes fuentes sin olvidar ni confundir nada? Pero, ¿qué pasa si dos expertos hacen esto independientemente? En este artículo, compartiremos una metodología de normalización común que puede ayudar a resolver este problema.
Imagen: Martinoflynn.comMuy a menudo, las reglas de correlación se basan en eventos normalizados. Por lo tanto, la normalización de los eventos y la forma correcta en que se realiza afecta directamente la precisión de las reglas de correlación.
Los problemas derivados de la normalización de eventos se formularon en el primer artículo (
aquí ), y las soluciones se propusieron en artículos posteriores (
aquí y
aquí ). Ahora resumimos lo descrito anteriormente y formamos un enfoque general para normalizar eventos.
Para empezar, recordamos qué herramientas del nivel de normalización hemos desarrollado:
- Se requiere un esquema de campo genérico para almacenar datos recuperados de eventos. Sus características:
- Tiene en cuenta la presencia de entidades en el evento: sujeto, objeto, fuente y transmisor de eventos, así como recursos.
- Proporciona una normalización correcta en los casos en que el evento contiene entidades de niveles de red y aplicaciones , y cuando tiene más de un Sujeto y / u Objeto.
- Le permite identificar y mantener explícitamente la estructura del proceso de interacción entre el Sujeto y el Objeto
- Sistema de categorización de eventos capaz de reflejar la semántica de un evento de TI o IB.
Metodología de normalización de eventos
Toda la metodología para normalizar eventos consta de tres pasos:
- Evaluación experta del evento.
- Definición del esquema de interacción.
- Definición de categoría de evento.
Para que sea más fácil entender cómo funciona la herramienta, seleccionaremos un evento y consideraremos en detalle todos los pasos de normalización de acuerdo con nuestra metodología.
Supongamos que tenemos una fuente: la base de datos Oracle DBMS con el siguiente direccionamiento de red:
- IP : 10.0.0.1;
- Nombre de host : myoracle;
- FQDN : myoracle.local.
De esta fuente, el agente SIEM descarga el siguiente evento:

Paso 1. Evaluación experta del evento.
Al comienzo del proceso de normalización de un evento, es importante comprender de qué se trata este evento. Es suficiente decir tu esencia a ti mismo. Si un experto, desde el evento inicial, aún no normalizado, no comprende qué procesos están ocurriendo en la fuente, estamos hablando, con alta probabilidad de que lo normalice incorrectamente. Entonces, ¿de qué tipo de operación correcta de las reglas de correlación podemos hablar?
El problema con qué tan bien el experto interpreta correctamente el evento es real. Por ejemplo, ¿puede un experto entender lo que significa el próximo evento?
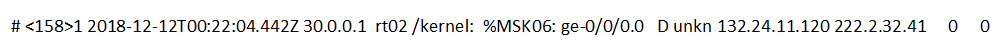
Si en el ejemplo original se puede captar la esencia del texto del evento en sí, entonces en este caso debe comprender bien con qué fuente está trabajando y en qué casos genera un evento similar. A veces, incluso tiene que desplegar un soporte separado con una fuente para reproducir completamente la situación en la que envía un evento complejo y difícil de interpretar a SIEM.
Volvamos al
ejemplo original con un evento de la base de datos Oracle. En esta etapa, el experto debería pensar así:
"
Como experto, creo que el evento inicial describe el proceso de revocar un rol de un usuario a otro en una base de datos Oracle ".
Paso 2. Determinar el esquema de interacción
El paso anterior nos permite asegurarnos de que podemos entender al menos el significado general del evento. Ahora analizaremos en detalle cómo distinguir entidades y determinar el esquema de su interacción.
De acuerdo con esta metodología, para cada
esquema de interacción, es necesario describir las reglas para la distribución de identificadores de entidad clave en los campos de un evento normalizado. Al mismo tiempo, se definen reglas para:
- Entidades de nivel de red
- Entidades del nivel de aplicación.
Es importante recordar que existen esquemas en los cuales el Sujeto es igual al Objeto e igual a la Fuente. Para tales esquemas, es necesario definir claramente las reglas para llenar los campos de las tres entidades. Si esto no se hace, entonces, al nivel de las reglas de correlación o la búsqueda de eventos, comenzarán los problemas y aparecerá una lógica adicional para la interpretación correcta de los campos vacíos. Sobre esto: en el artículo dedicado
a los esquemas de interacción .
Veamos cómo funciona este paso de la metodología en el
ejemplo inicial:
- Esquema de interacción a nivel de red : un esquema completo de recolección directa, sin un transmisor.
- Esquema de interacción a nivel de aplicación : interacción a través de un recurso.
Para estos esquemas, se pueden definir las siguientes reglas de normalización:
- Entidades de capa de red:
- Asunto :
- Campo: src.ip = <vacío>
- Campo: src.hostname = alex_host
- Campo: src.fqdn = <vacío>
- Objeto
- Campo: dst.ip = 10.0.0.1
- Campo: dst.hostname = myoracle
- Campo: dst.fqdn = myoracle.local
- Fuente (coincide con el objeto) :
- Campo: event_source.ip = 10.0.0.1
- Campo: event_source.hostname = myoracle
- Campo: event_source.fqdn = myoracle.local
- Transmisor :
- Campo: forwarder.ip = <vacío>
- Campo: forwarder.hostname = <vacío>
- Campo: forwarder.fqdn = <vacío>
- Canal de interacción :
- Campo: Interaction.id = 2342594
- Entidades del nivel de aplicación (colección de elementos):
- Asunto :
- Campo: subject [1] .name = "Alex"
- Campo: subject [1] .type = "cuenta"
- Objeto
- Campo: objeto [1] .name = "Bob"
- Campo: objeto [1] .type = "cuenta"
- Recurso
- Campo: recurso [1] .name = "MYROLE"
- Campo: recurso [1] .type = "rol"
Paso 3. Definir una categoría de evento
Una vez que se han identificado todas las entidades clave del evento, es necesario describir la esencia del proceso reflejado en el evento y transferirlo al lenguaje de normalización. Para estos fines, se utiliza un sistema para clasificar eventos. El sistema de categorización de eventos se discutió en detalle en un
artículo separado, ahora veamos cómo funciona en la práctica.
Para unificar la normalización, el sistema de categorización define las siguientes reglas:
- Para cada categoría de cada nivel de TI y eventos de seguridad de la información, un experto forma un directorio con una lista de la información que debe encontrarse en el evento inicial y normalizarse.
- Si a un evento se le asignó alguna categoría, el experto, de acuerdo con el directorio, está obligado a encontrar la información requerida y normalizarla.
- Cada categoría define un conjunto de campos de esquema de eventos normalizados que deben completarse.
Por lo tanto, la categoría seleccionada para el evento establece una correspondencia directa entre:
- semántica de eventos;
- información importante que se extraerá del evento, de acuerdo con la categoría fijada;
- Un conjunto de campos del esquema de un evento normalizado en el que esta información debe ser "puesta".
Este enfoque le permite comprender claramente de la categoría de cualquier evento qué datos se encuentran en qué campos del evento normalizado.
Si, con el apoyo de nuevas fuentes, resulta que alguna información importante necesita ser extraída adicionalmente de los eventos de una determinada categoría, entonces se ingresa en el directorio. En este caso, necesitas:
- definir reglas para completar los campos del esquema de eventos;
- llevar a cabo una auditoría de normalización para eventos en esta categoría de todas las fuentes admitidas anteriormente;
- Agregue nueva información a eventos previamente normalizados.
De esta manera, se mantiene la consistencia de los cambios realizados. Considere el ejemplo original.
De acuerdo con el sistema de categorización, este evento tiene las siguientes categorías:
- Sistema de categorización : eventos de TI
- Categoría de primer nivel (Nivel 1) : usuario y derechos
- Categoría del segundo nivel (Nivel 2) : Usuario
- Categoría del tercer nivel (nivel 3) : manipulación
El directorio para esta categoría se ve así:
- Al normalizar eventos en la categoría Usuario y Derechos , es importante comprender:
- Si se utilizó la escalada de privilegios, en nombre de quién se implementa el proceso.
- Campo: sujeto [i] .assign
- ¿Han sido exitosas las acciones?
- ¿Cuál es el código de retorno?
- Campo: result.status.code
- Al normalizar los eventos de la categoría Usuario , es importante comprender:
- ¿Hay alguna información sobre la dirección IP, nombre de host o fqdn de la máquina del usuario?
- Campos: src.ip, src.hostname, src.fqdn
- Campos: dst.ip, dst.hostname, dst.fqdn
- Bajo qué cuenta se conectó el usuario.
- Campos: sujeto [i] .name, objeto [i] .name
- ¿Hay alguna información sobre su cuenta en el sistema operativo?
- Campos: sujeto [i] .osname, objeto [i] .osname
- ¿Hay alguna información de cuenta de dominio?
- Campos: sujeto [i] .dominio, objeto [i] .dominio
- ¿Hay alguna información sobre la aplicación del usuario?
- Campos: sujeto [i] .application, objeto [i] .application
- Al normalizar eventos en la categoría Manipulación , es importante comprender:
- Tipo de operación.
- Campo: tipo de interacción.
- Lo que ha cambiado
- Campo: objeto [i] .name, objeto [i] .type - al cambiar cuentas
- Campo: recurso [i] .name, recurso [i] .type - al cambiar en recursos
- Lo que ha cambiado
- Campo: objeto [i] .modify
- Campo: recurso [i] .modify
- Si la operación fue en un recurso, quién es su propietario.
- Campo: recurso [i] .owner
Hemos dado esta guía para demostrar el principio de su formación, por lo tanto, no pretende ser precisa y completa.
Como resultado, el evento normalizado por esta metodología se ve así:
 Un ejemplo de un evento normalizado en el tercer paso de la metodología.
Un ejemplo de un evento normalizado en el tercer paso de la metodología.Conclusiones
La experiencia muestra que a menudo los errores de normalización y la ausencia de reglas de normalización uniformes a menudo conducen a falsos positivos de las reglas de correlación. Ahora tenemos un enfoque que permite, si no deshacerse, al menos minimizar el impacto del problema.
Entonces, para resumir, el enfoque incluye tres pasos:
- Paso 1 El experto intenta comprender la esencia general del fenómeno descrito en el evento inicial.
- Paso 2 El experto identifica las principales entidades de la red y el nivel de aplicación en el evento: Sujeto, Objeto, Fuente, Transmisor, Recurso, Canal de interacción. Los aísla en el evento y determina el patrón de interacción de estas entidades. Cada esquema genera reglas para colocar estas entidades en los campos de un evento normalizado: un esquema. Esto se describió en detalle en un artículo dedicado a los esquemas de interacción entre entidades.
- Paso 3 El experto determina la categoría del primer, segundo y tercer nivel. Para cada categoría, crea un directorio que incluye una descripción de los datos que es importante encontrar en el evento durante su normalización, información sobre qué campos del evento normalizado es necesario "colocar" los datos encontrados.
Ahora, a partir de la construcción de las reglas de correlación para "trabajar fuera de la caja", solo estamos separados por el problema de los cambios constantes en las propias entidades: los activos. Sus direcciones cambian, se introducen nuevos activos, los antiguos se retiran, los nodos del clúster cambian y las máquinas virtuales se mueven de un centro de datos a otro y, a veces, incluso con un cambio en el direccionamiento. Cómo superar estos problemas, hablaremos en el próximo artículo del ciclo.
Serie de artículos:Profundidades SIEM: correlaciones listas para usar. Parte 1: ¿marketing puro o un problema sin solución?Profundidades SIEM: correlaciones listas para usar. Parte 2. Esquema de datos como reflejo del modelo del "mundo"Profundidades SIEM: correlaciones listas para usar. Parte 3.1. Categorización de eventosProfundidades SIEM: correlaciones listas para usar. Parte 3.2. Metodología de normalización de eventos (
este artículo )
Profundidades SIEM: correlaciones listas para usar. Parte 4. Modelo del sistema como contexto de reglas de correlaciónProfundidades SIEM: correlaciones listas para usar. Parte 5. Metodología para desarrollar reglas de correlación