En condiciones de alta carga, la complejidad de optimizar las bases de datos relacionales aumenta en un orden de magnitud, ya que comprar hardware aún más potente es costoso y no hay forma de apagar la aplicación por la noche para un largo proceso de alteración de la base de datos y migración de datos.
Recientemente hablamos sobre cómo
optimizamos el código PHP para nuestra aplicación . Ahora ha llegado el turno del artículo sobre cómo cambiamos completamente la estructura interna de la base de datos más cargada e importante de Badoo, sin perder una sola solicitud.
Paciente
Users DataBase, o UDB, es un servicio que inicia casi cualquier solicitud a Badoo. Resuelve varios problemas: en primer lugar, es el repositorio central de los principales datos de usuario para los que se lleva a cabo la autorización (por ejemplo, correo electrónico, user_id o facebook_id). Además de almacenar estos datos, el servicio proporciona un control único (de modo que dos usuarios con el mismo correo electrónico, facebook_id, etc., no pueden registrarse en el sistema). Y el mismo servicio brinda información sobre cuál de los miles de fragmentos contiene todos los demás datos de usuario.
A finales de 2018, UDB almacena datos de más de 800 millones de usuarios, que ocupan aproximadamente 1 TB de espacio en disco. Todo esto es servido por pares de servidores MySQL maestro-esclavo en cada uno de nuestros centros de datos. En total, procesan más de 140,000 solicitudes por segundo.
La caída de UDB significa la inaccesibilidad de todo Badoo, ya que el código no podrá encontrar el fragmento en el que se encuentran los datos del usuario. Por lo tanto, se le imponen enormes exigencias de fiabilidad y disponibilidad.
Debido a esta especificidad, es muy costoso realizar cambios en la estructura de almacenamiento, por lo que tomamos muy en serio el diseño de UDB en 2013. Sin embargo, con el tiempo, los requisitos y los perfiles de carga cambian. En un esfuerzo por adaptar el sistema a los nuevos requisitos y niveles de carga, se realizaron muchos cambios pequeños y simples, pero, desafortunadamente, tales cambios están lejos de ser los más efectivos. Y llegó el día en que, en lugar del siguiente hack o la compra de hardware costoso, era más sabio hacer una optimización más global. Además consideraremos las etapas principales de este camino.
Optimizaciones no invasivas
Cualquier cambio en la estructura de una base de datos grande y cargada es bastante costoso debido a la complejidad del proceso de migración de datos. Por lo tanto, antes que nada, debe agotar todas las opciones de optimización que no afectan la estructura de datos, pero que se limitan a las consultas de código y SQL. Quizás esto sea suficiente para posponer el problema de la carga de trabajo excesiva durante un par de años, lo que le permitirá hacer algo más importante para el negocio en este momento.
Cuanto mejor comprenda su sistema, más fácil será encontrar enfoques para tales optimizaciones. Asegúrese de recopilar todas las métricas que pueden ayudarlo. No se trata solo de métricas del sistema como el uso de CPU y RAM o las métricas de una base de datos específica, sino también de métricas de nivel de aplicación de una aplicación que está vinculada a una base de datos optimizada. ¿Cuántas solicitudes por segundo tienen los diferentes tipos de operaciones? ¿Cuál es su tiempo de respuesta? ¿Cuál es el tamaño de la entrada y salida? Es sobre estas métricas que puede juzgar el éxito de la optimización. Es poco probable que necesite una optimización que reduzca ligeramente el uso de la CPU en el servidor de la base de datos, pero al mismo tiempo aumente el tiempo de respuesta de su aplicación en diez veces.

Después de haber comenzado a recopilar métricas de nivel de aplicación adicionales para UDB, pudimos comprender mejor cuáles de las operaciones realizadas crean el 80% de la carga y son los primeros candidatos para el estudio, y cuáles se usan poco o nada más.
Un análisis detallado de la operación más frecuente (extracción de usuarios que cumplen ciertos criterios) mostró que, a pesar del hecho de que todos los datos de usuario disponibles se solicitan de la base de datos, en realidad la aplicación en el 95% de los casos usa solo user_id. Simplemente separando este caso en un método API separado, que extrae solo una columna de la tabla, pudimos beneficiarnos del uso del índice de cobertura y usar esto para eliminar aproximadamente el 5% de la carga de la CPU del servidor de la base de datos.
El análisis de otra operación frecuente mostró que, a pesar del hecho de que se realiza para cada solicitud HTTP, en realidad, los datos que recupera son extremadamente raros. Tradujimos esta solicitud a un modelo perezoso.
El objetivo principal de las métricas en el caso de un proyecto de optimización es comprender mejor su base de datos y encontrar las piezas más gordas. No tiene sentido gastar mucho tiempo y esfuerzo optimizando consultas que representan menos del 1% de su perfil de carga. Si no tiene métricas que le permitan comprender el perfil de su carga, recójalas. Con tales optimizaciones en el lado del código, logramos eliminar aproximadamente el 15% del uso de la CPU del 80% de la base de datos consumida.
Ideas de prueba
Si va a optimizar una base de datos cargada cambiando su estructura, debe comenzar por verificar sus ideas en un banco de pruebas, ya que incluso las optimizaciones que parecen muy prometedoras en teoría pueden no tener un efecto positivo en la práctica (y a veces incluso pueden tener un efecto negativo). Y es poco probable que desee saber sobre esto solo después de una larga migración de datos en producción.
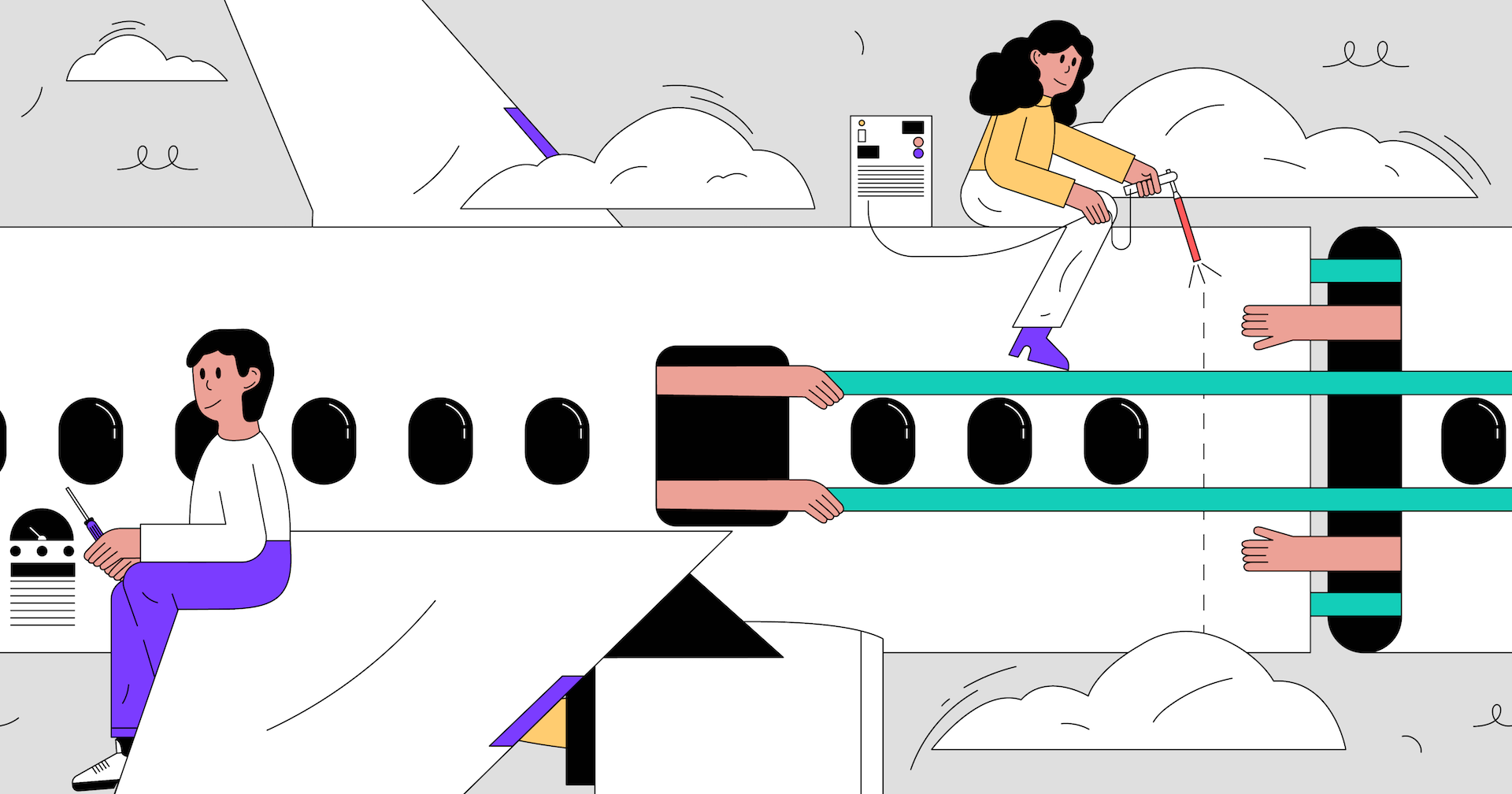
Cuanto más cerca esté la configuración de su stand de la configuración de producción, más confiable será el resultado. Un punto importante es asegurar la carga correcta del soporte. Ejecutar consultas aleatorias o las mismas puede conducir a resultados falsos. La mejor opción es utilizar solicitudes reales de producción. Para UDB, registramos desde la producción cada décima solicitud de lectura de API (incluidos los parámetros) en forma de solo un registro JSON en un archivo. Por un día, recopilamos un registro de 65 GB de tamaño de 700 millones de solicitudes.
No probamos el registro, en comparación con el número de solicitudes de lectura, es muy pequeño y no afecta nuestra carga. Sin embargo, este puede no ser el caso en su caso. Si desea cargar el banco de pruebas con solicitudes de escritura, deberá recopilar cada solicitud, ya que omitir las solicitudes de escritura puede generar errores de coherencia en el banco de pruebas.
El siguiente paso es perder correctamente el registro en el soporte. Utilizamos 400 trabajadores PHP, lanzados desde nuestra
nube de script , que leen el registro recopilado de la cola rápida y ejecutan solicitudes secuencialmente. En este caso, la cola se llena con otro script con una velocidad estrictamente definida. Para probar ideas, utilizamos la velocidad de x10, que, multiplicada por el hecho de que recolectamos de la producción solo cada décima solicitud, proporcionó la misma cantidad de RPS que en la producción.
Con estos coeficientes, resulta que el día de producción con todas las cargas caídas en el banco de pruebas vuela en solo dos horas y media.
Entonces, por ejemplo, la primera prueba que realizamos a una velocidad de x5 (50% de la carga de producción) en el registro de consultas durante medio día se veía así:
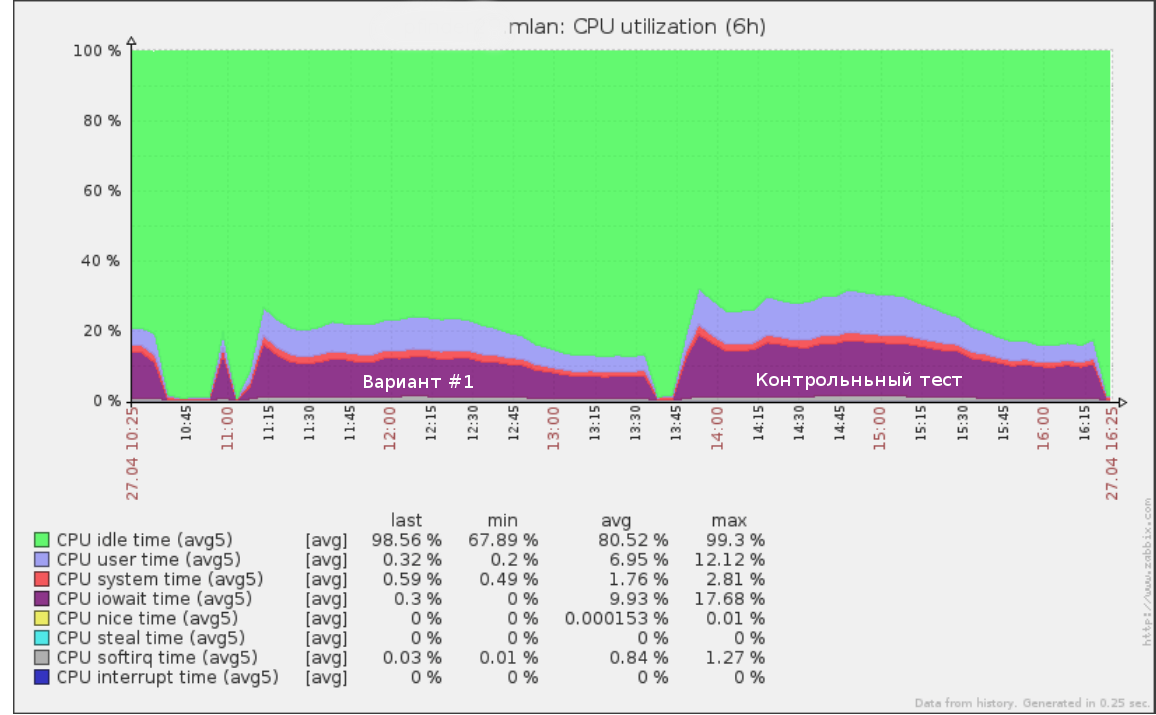
Se pueden usar las mismas herramientas para realizar una prueba de falla: aumentando la velocidad (y por lo tanto RPS) hasta que la base en el soporte comience a degradarse. Esto le dará una idea clara de cuánto más puede soportar su base de datos.
Después de probar el nuevo esquema de datos, también es importante realizar una prueba de control en la estructura de la base de datos original. Si sus resultados y el rendimiento actual en la producción son muy diferentes, primero debe comprender los motivos. Quizás el servidor de prueba está configurado incorrectamente y no puede confiar en los datos de prueba de carga.
También vale la pena asegurarse de que el nuevo código funcione correctamente. Tiene poco sentido probar el rendimiento de las consultas que no hacen el trabajo. Le ayudarán las pruebas de integración que verifican si las API antiguas y nuevas devuelven los mismos valores en las mismas llamadas API.
Después de recibir resultados sobre todas las ideas, solo queda elegir opciones con el mejor equilibrio entre precio y calidad e introducir un nuevo esquema de producción.
Cambio de esquema
En primer lugar, observo que cambiar el esquema de datos sin detener el funcionamiento del servicio siempre es bastante difícil, costoso y arriesgado. Por lo tanto, si tiene la oportunidad de detener su aplicación mientras cambia la estructura, simplemente hágalo. En el caso de UDB, desafortunadamente, no podíamos permitirnos esto.
El segundo factor que afecta la complejidad de cambiar un circuito es la escala planificada del cambio. Si todos los cambios propuestos a las tablas no van más allá de un simple cambio (por ejemplo, agregando un par de nuevos índices o columnas), puede ponerlos en marcha con procesos típicos como
pt-online-schema-change y
gh-ost para MySQL o un esclavo alternativo seguido de cambiar sus lugares .
En nuestro caso, se mostró un excelente resultado mediante el fragmentación vertical de una tabla gigante de una docena más pequeña con otras columnas e índices y datos en un formato diferente. Tal conversión con herramientas típicas ya no es posible. Entonces que hacer?
Aplicamos el siguiente algoritmo:
- Alcanzamos un estado en el que tanto el esquema antiguo como el nuevo con datos actuales existen simultáneamente. La grabación va en ambos, y al mismo tiempo hay una garantía de consistencia de datos en ambas versiones. Consideraremos este artículo en detalle a continuación.
- Cambie gradualmente toda la lectura a un nuevo circuito, controlando la carga.
- Apague la grabación en el esquema anterior y elimínelo.
Las principales ventajas de este enfoque:
- seguridad: existe la posibilidad de retroceso instantáneo hasta la última etapa (simplemente cambie la lectura al esquema anterior, si algo salió mal);
- control de carga completa durante la migración de datos;
- no se requiere alterar mucho la gran mesa del antiguo circuito.
Sin embargo, también hay desventajas:
- la necesidad de mantener ambas versiones de los esquemas en el disco durante el proceso de migración (esto puede ser un problema si tiene poco espacio y la tabla que se está migrando es muy grande);
- una gran cantidad de código temporal para admitir el proceso de migración, que se cortará al finalizar;
- es posible lavar el caché leyendo dos esquemas en paralelo; existía el temor de que las versiones antiguas y nuevas competirían por la RAM, lo que podría conducir a la degradación del servicio (en realidad, esto realmente creó una carga adicional, sin embargo, dado que la migración se realizó fuera de las horas pico, esto no nos creó problemas).
La principal dificultad en este algoritmo es el primer punto. Lo consideraremos en detalle.
Cambiar sincronización
La migración de datos estáticos no es particularmente difícil. Sin embargo, ¿qué sucede si no puede detener la grabación completa mientras se migra la base de datos?
Hay varias opciones para lograr la sincronización del nuevo esquema: migración con rodar el registro y la grabación idempotente de migración.
Migrar una instantánea de datos seguido de reproducir el registro de los siguientes cambios
Cada transacción de actualización de datos se registra en una tabla especial a través de disparadores, ya sea a nivel de aplicación, o el binlog de replicación se usa como un registro. Después de tener dicho registro, puede abrir una transacción y migrar una instantánea de datos, recordando la posición en el registro. Entonces queda por comenzar a aplicar el registro recopilado en el nuevo esquema. Del mismo modo, por ejemplo, funciona la popular
herramienta de copia de seguridad MyStra Percona XtraBackup .
Una vez que el nuevo esquema ha alcanzado el registro en el registro actual, comienza la etapa más crucial: aún debe pausar la grabación en el esquema anterior por un corto período de tiempo y, asegurándose de que todo el registro disponible se aplique al nuevo esquema, lo que significa que los datos entre los esquemas son consistentes, A nivel de aplicación, habilite la grabación a la vez en ambas fuentes.
Las principales desventajas de este enfoque son que necesitará almacenar de alguna manera el registro de operaciones, que en sí mismo puede crear una carga en el complejo proceso de conmutación, así como en la probabilidad de romper el registro si, por alguna razón, los circuitos resultan ser inconsistentes.
Registro idempotente
La idea principal de este enfoque es comenzar a escribir en el nuevo esquema en paralelo con la escritura en el anterior antes de que los cambios estén completamente sincronizados, y luego completar la migración de los datos restantes. Del mismo modo, generalmente las columnas nuevas se llenan en tablas grandes.
La grabación síncrona se puede implementar tanto en los activadores de la base de datos como en el código fuente. Le aconsejo que haga esto precisamente en el código, ya que, en cualquier caso, eventualmente tendrá que escribir código que escriba datos en el nuevo esquema, y la implementación de la migración en el lado del código le proporcionará más control.
Un punto importante a considerar es que hasta que se complete la migración, el nuevo esquema estará en un estado inconsistente. Debido a esto, es posible un escenario cuando la actualización de una nueva tabla conduce a una violación de la constante de la base de datos (claves externas o un índice único), mientras que desde el punto de vista del esquema actual, la transacción es completamente correcta y debe llevarse a cabo.
Esta situación puede llevar a una reversión de buenas transacciones debido al proceso de migración. La forma más fácil de solucionar este problema es agregar el modificador IGNORE a todas las solicitudes para escribir datos en un nuevo esquema o interceptar la reversión de dicha transacción y ejecutar la versión sin escribir en el nuevo esquema.
El algoritmo de sincronización a través de la grabación idempotente en nuestro caso es el siguiente:
- Permitimos la grabación en un nuevo esquema en paralelo con la grabación en el antiguo en modo de compatibilidad (IGNORE).
- Ejecutamos un script que gradualmente pasa por alto el nuevo esquema y captura datos inconsistentes. Después de eso, los datos en ambas tablas deben sincronizarse, pero esto es inexacto debido a posibles conflictos en la cláusula 1.
- Iniciamos el verificador de consistencia de datos: abre la transacción y lee secuencialmente las líneas de los esquemas nuevos y antiguos comparando su correspondencia.
- Si hay conflictos, terminamos y volvemos al párrafo 3.
- Después de que el verificador mostró que los datos en ambos esquemas están sincronizados, entonces no debería haber más discrepancias entre los esquemas, a menos, por supuesto, que hayamos perdido algunos matices. Por lo tanto, esperamos un tiempo (por ejemplo, una semana) y ejecutamos una verificación de control. Si muestra que todo está bien, la tarea se completa con éxito y puede traducir la lectura.
Resultados
Como resultado de cambiar el formato de datos, pudimos reducir el tamaño de la tabla principal de 544 GB a 226 GB, reduciendo así la carga en el disco y aumentando la cantidad de datos útiles que caben en la RAM.
En total, desde el comienzo del proyecto, utilizando todos los enfoques descritos, pudimos reducir el uso de la CPU del servidor de bases de datos del 80% al 35% en el pico de tráfico. Los resultados de la prueba de esfuerzo posterior mostraron que a la tasa de crecimiento actual de la carga, podemos permanecer en el hardware existente durante al menos otros tres años.
Dividir una tabla enorme en varias simplificó el proceso de realizar modificaciones futuras en la base de datos, y también aceleró significativamente algunos scripts que recopilaron datos para BI.