 De un traductor:
De un traductor: hoy publicamos para usted un artículo conjunto de tres desarrolladores, Akaash Chikarmane, Erte Bablu y Nikhil Gaur, que describe el método para predecir la calificación de las aplicaciones en Google Play Store.
En este artículo, mostraremos cómo procesamos la información que usamos para predecir las calificaciones. También explicaremos por qué usamos estos o aquellos de ellos. Hablaremos sobre las transformaciones del paquete de datos con el que trabajamos y sobre lo que se puede lograr mediante la visualización.
Skillbox recomienda: Curso práctico de dos años "Soy un desarrollador web PRO" .
Le recordamos: para todos los lectores de "Habr": un descuento de 10.000 rublos al registrarse en cualquier curso de Skillbox con el código de promoción "Habr".
¿Por qué decidimos hacerlo?
Las aplicaciones móviles se han convertido en una parte integral de la vida, cada vez más desarrolladores se dedican solo a su creación. Además, muchos dependen directamente de los ingresos que traen las solicitudes. Por lo tanto, pronosticar el éxito es de gran importancia para ellos.
Nuestro objetivo es determinar la calificación general de la aplicación, para hacer esto de manera integral, porque demasiadas personas juzgan el programa, confiando solo en el número de "estrellas" establecidas por los usuarios. Las solicitudes con 4-5 puntos son más creíbles.
Preparación
La mayor parte de este proyecto está trabajando con datos, incluido el preprocesamiento. Como toda la información se tomó de Google Play Store, las matrices resultantes contenían muchos errores. Utilizamos varios modelos de regresión, incluido el Regresor de aumento de gradiente del paquete XGBoost, Regresión lineal y RidgeRegression.
Recopilación y análisis de datos.
El conjunto de datos con el que trabajamos se puede
encontrar aquí . Se compone de dos partes. El primero es la información objetiva, como el tamaño de la aplicación, el número de instalaciones, la categoría, el número de revisiones, el tipo de aplicación, su género, la fecha de la última actualización, etc., y las revisiones subjetivas, es decir, de los usuarios.
Las revisiones en sí fueron sometidas a análisis. Después de comparar los resultados, decidimos si incluir o no los datos de la encuesta en el modelo final.
Formamos un conjunto de datos objetivos por 12 funciones y una variable objetivo (calificación). El paquete incluía 10.8 mil unidades de información. En cuanto a las opiniones de los usuarios, seleccionamos las 100 funciones más relevantes y utilizamos cinco para 64.3 mil elementos. Todos los datos se recopilaron directamente de Google Play Store, la última vez que se actualizó hace tres meses.
Preprocesamiento de datos
El conjunto inicial de información se parecía a esto:
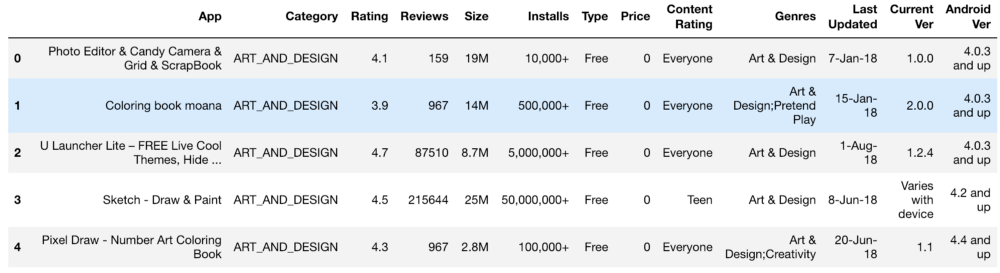
Configuración, clasificación, costo y tamaño: procesamos todo esto de tal manera que obtenemos números que son accesibles para la comprensión de la máquina. Al procesar varias funciones, surgieron problemas, como la necesidad de eliminar el "+". En el costo eliminamos $. El volumen de la aplicación resultó ser el más problemático en términos de procesamiento, ya que tanto KB como MB aparecieron, por lo que fue necesario hacer un trabajo para reducir todo a un solo formato. Los datos primarios se muestran a continuación y también se muestran después del procesamiento.
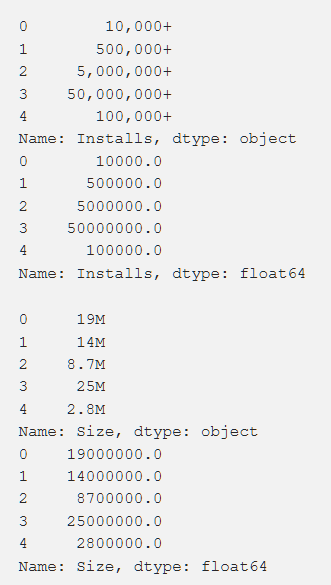
Además, transformamos algunos datos, haciéndolos más relevantes para nuestro trabajo. Por ejemplo, la información sobre la última actualización de la aplicación no fue muy útil. Para hacerlos más significativos, convertimos esto en información sobre el tiempo transcurrido desde la última actualización. El código para esta tarea se muestra a continuación.
from datetime import datetime from dateutil.relativedelta import relativedelta n = 3
También fue necesario llevar a un solo estándar variables con varios valores diferentes (por ejemplo, "Género"). Cómo se hizo esto se muestra a continuación.
from copy import deepcopy from sklearn.preprocessing import LabelEncoder def one_hot_encode_by_label(df, labels): df_new = deepcopy(df) for label in labels: dummies = df_new[label].str.get_dummies(sep = ";") df_new = df_new.drop(labels = label, axis = 1) df_new = df_new.join(dummies) return df_new def label_encode_by_label(df, labels): df_new = deepcopy(df) le = LabelEncoder() for label in labels: print(label + " is label encoded") le.fit(df_new[label]) dummies = le.transform(df_new[label]) df_new.drop(label, axis = 1) df_new[label] = pd.Series(dummies) return df_new
Para normalizar los datos, intentamos la conversión log1p. Ante él:
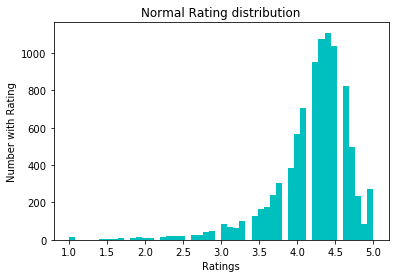
Después:
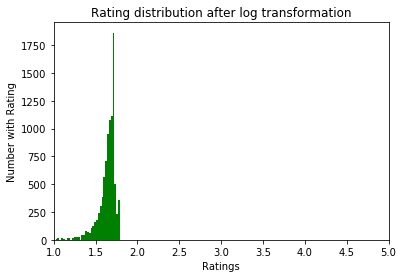
Exploración de datos.
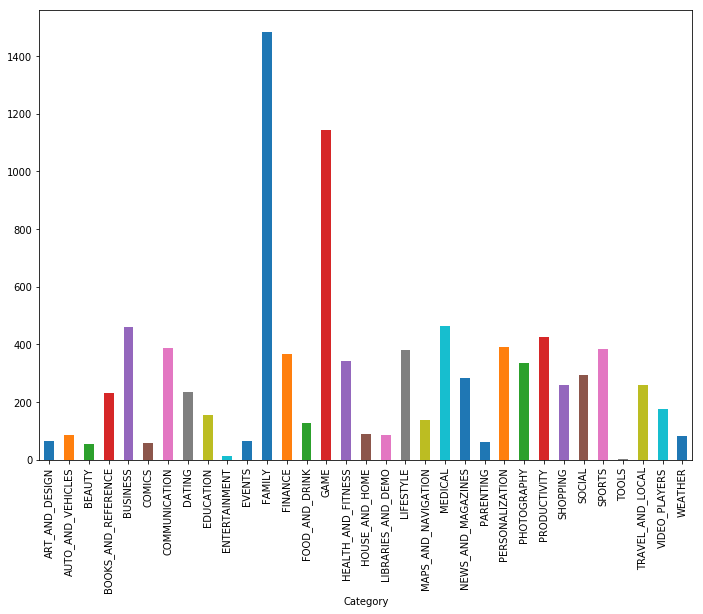
Como puede ver, los juegos y las aplicaciones para la familia son las dos categorías más populares. La mayoría de las aplicaciones también estaban en la categoría "Para todas las edades".
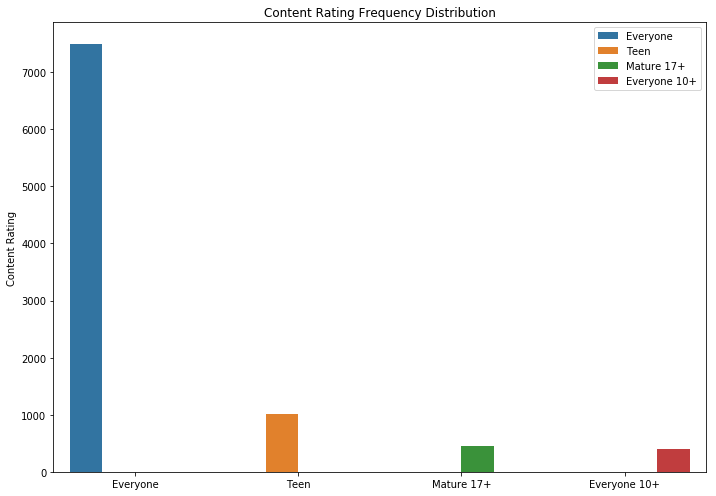

Es lógico que las aplicaciones con una calificación máxima tengan más revisiones que las de baja calificación. Algunos de ellos tienen muchas más críticas que todos los demás. Quizás la razón de esto sea un mensaje emergente, una llamada para calificar u otras técnicas similares.

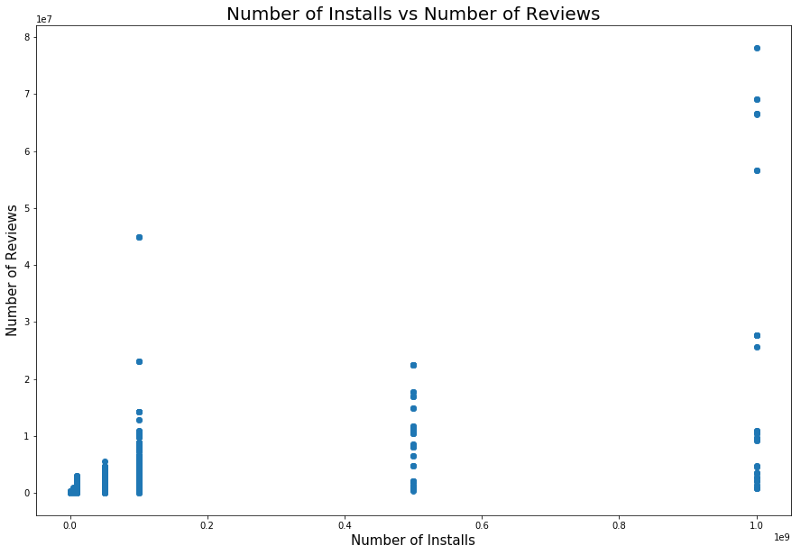
También existe una relación entre el número de instalaciones y el número de revisiones. La correlación se muestra en la captura de pantalla a continuación.
Un análisis detallado de esta dependencia puede dar una idea de por qué las categorías populares de aplicaciones tienen más instalaciones y más revisiones.
Modelos y resultados
Utilizamos la división de pruebas para dividir los datos en conjuntos de prueba y entrenamiento. La validación cruzada con GridSearchCV se utilizó para mejorar los resultados del entrenamiento del modelo con el fin de encontrar el mejor alfa con Lasso, Ridge Regression y XGBRegressor del paquete XGBoost. El último modelo generalmente es extremadamente efectivo, pero al usarlo, uno debe tener cuidado de ajustar los resultados; este es uno de los peligros que esperan los investigadores. El valor eficaz inicial sin ningún procesamiento especialmente cuidadoso de los objetos (solo codificación y limpieza) fue de aproximadamente 0.228.
Después de la conversión logarítmica de las calificaciones, el error estándar cayó a 0.219, lo cual fue una ligera mejora, pero nos dimos cuenta de que hicimos todo bien.
Utilizamos la regresión lineal después de evaluar la relación entre revisiones, actitudes y calificaciones. En particular, analizamos la información estadística de estas variables, incluyendo el r cuadrado y la p, tomando como resultado una decisión sobre la regresión lineal. El primer modelo de regresión lineal utilizado mostró una correlación entre las configuraciones y una calificación de 0.2233, el modelo de regresión lineal Nuestras Revisiones y Calificaciones nos dio un MSE de 0.2107, y el modelo de regresión lineal combinado, Revisiones, Configuraciones y Calificaciones ", Nos dio un MSE de 0.214.
Además, utilizamos el modelo KNeighboursRegressor. Los resultados de su uso se muestran a continuación.

Conclusiones
Después de que los datos primarios de Google Play Store se convirtieron a un formato utilizable, trazamos y derivamos funciones para comprender las correlaciones entre los valores individuales. Luego, estos resultados se utilizaron para construir un modelo óptimo.
Inicialmente, creíamos que no sería demasiado difícil encontrarlo, para poder construir un modelo preciso. Pero la tarea fue más difícil de lo que esperábamos.
Además de lo que se ha hecho, también puede:
- crear un modelo separado para cada género;
- Cree nuevas funciones a partir de las versiones del sistema operativo Android, como lo hicimos anteriormente con las fechas;
- para aprender el algoritmo más profundamente: teníamos un número suficiente de puntos de datos categóricos y numéricos;
- analizar y borrar datos de forma independiente desde Google App Store.
Todos los resultados están
disponibles aquí .
Skillbox recomienda: