La oficina de Intel de Nizhny Novgorod, entre otras cosas, está desarrollando algoritmos de visión por computadora basados en redes neuronales profundas. Muchos de nuestros algoritmos se publican en el repositorio de
Open Model Zoo . La capacitación modelo requiere una gran cantidad de datos etiquetados. Teóricamente, hay muchas formas de prepararlos, pero la disponibilidad de software especializado acelera este proceso muchas veces. Por lo tanto, para mejorar la eficiencia y la calidad del marcado, hemos desarrollado nuestra propia herramienta: la herramienta de
anotación de visión por computadora (CVAT) .
Por supuesto, en Internet puedes encontrar muchos datos anotados, pero hay algunos problemas. Por ejemplo, constantemente surgen nuevas tareas para las cuales simplemente no hay tales datos. Otro problema es que no todos los datos son adecuados para su uso en el desarrollo de productos comerciales, debido a sus acuerdos de licencia. Por lo tanto, además del desarrollo y la capacitación de algoritmos, nuestra actividad también incluye el marcado de datos. Este es un proceso bastante largo y lento, que no sería razonable imponer a los desarrolladores. Por ejemplo, para entrenar uno de nuestros algoritmos, se marcaron alrededor de 769,000 objetos durante más de 3,100 horas hombre.
Hay dos soluciones al problema:
- El primero es transferir los datos de marcado a empresas de terceros, con la especialización adecuada. Tuvimos una experiencia similar. Vale la pena señalar el complicado proceso de validación y re-partición de datos, así como la presencia de burocracia.
- El segundo, más conveniente para nosotros, es la creación y el apoyo de nuestro propio equipo de anotaciones. La conveniencia radica en la capacidad de establecer rápidamente nuevas tareas, administrar el progreso de su implementación y el equilibrio facilitado entre precio y calidad. Además, es posible implementar algoritmos de automatización personalizados y mejorar la calidad del marcado.
Inicialmente, la herramienta de anotación de visión por computadora se desarrolló específicamente para nuestro equipo de anotación.

Por supuesto, nuestro objetivo no era crear el "15º estándar". Al principio, utilizamos una solución lista para
usar :
Vatic , pero en el proceso, los equipos de anotación y algoritmos presentaron nuevos requisitos para ello, cuya implementación finalmente condujo a una reescritura completa del código del programa.
Más en el artículo:
- Información general (funcionalidad, aplicaciones, ventajas y desventajas de la herramienta)
- Historia y evolución (una breve historia sobre cómo CVAT vivió y se desarrolló)
- Dispositivo interno (descripción de arquitectura de alto nivel)
- Instrucciones de desarrollo (un poco sobre los objetivos que me gustaría alcanzar y las posibles formas de alcanzarlos)
Información general
Computer Vision Annotation Tool (CVAT) es una herramienta de código abierto para marcar imágenes y videos digitales. Su tarea principal es proporcionar al usuario medios convenientes y efectivos para marcar conjuntos de datos. Creamos CVAT como un servicio universal que admite diferentes tipos y formatos de marcado.
Para los usuarios finales, CVAT es una aplicación web basada en navegador. Es compatible con varios escenarios de trabajo y se puede utilizar tanto para el trabajo personal como en equipo. Las tareas principales del aprendizaje automático con un profesor en el campo del procesamiento de imágenes se pueden dividir en tres grupos:
- Detección de objetos
- Clasificación de la imagen
- Segmentación de imagen
CVAT es adecuado en todos estos escenarios.
Ventajas:- Falta de instalación por parte de los usuarios finales. Para crear una tarea o marcar datos, simplemente abra un enlace específico en el navegador.
- La capacidad de trabajar juntos. Existe la oportunidad de hacer que la tarea esté públicamente disponible para los usuarios y para paralelizar el trabajo en ella.
- Fácil de implementar. Instalar CVAT en la red local es un par de comandos a través del uso de Docker .
- Automatización del proceso de marcado. La interpolación, por ejemplo, le permite obtener marcas en muchos cuadros, con trabajo real solo en algunos clave.
- La experiencia de los profesionales. La herramienta fue desarrollada con la participación de anotaciones y varios equipos algorítmicos.
- La capacidad de integrarse. CVAT es adecuado para la integración en una plataforma más amplia. Por ejemplo, Onepanel .
- Soporte opcional para varias herramientas:
- Deep Learning Deployment Toolkit (componente como parte de OpenVINO)
- API de detección de objetos de Tensorflow (API TF OD)
- Sistema de análisis ELK (Elasticsearch + Logstash + Kibana)
- Kit de herramientas NVIDIA CUDA
- Soporte para varios escenarios de anotación.
- Código abierto bajo una licencia MIT simple y gratuita.
Desventajas- Soporte de navegador limitado. El rendimiento de la parte del cliente está garantizado solo en el navegador Google Chrome. No probamos CVAT en otros navegadores, pero en teoría, la herramienta puede funcionar en Opera, Yandex Browser y otros con el motor Chromium.
- El sistema de pruebas automáticas no ha sido desarrollado. Todos los controles de estado se llevan a cabo manualmente, lo que ralentiza significativamente el desarrollo. Sin embargo, ya estamos trabajando en una solución a este problema junto con los estudiantes de UNN. Lobachevsky como parte del proyecto IT Lab .
- No hay documentación del código fuente disponible. Involucrarse en el desarrollo puede ser bastante difícil.
- Limitaciones de rendimiento. Con las crecientes demandas en el volumen de marcado, enfrentamos varios problemas, como la limitación de Chrome Sandbox en el uso de RAM.
Por supuesto, estas listas no son exhaustivas, pero contienen disposiciones básicas.
Como se mencionó anteriormente, CVAT admite una serie de componentes adicionales. Entre ellos están:
Deep Learning Deployment Toolkit como parte del
OpenVINO Toolkit : se utiliza para acelerar el lanzamiento del modelo TF OD API en ausencia de una GPU. Estamos trabajando en un par de otros usos útiles para este componente.
API de detección de objetos de Tensorflow : se usa para marcar objetos automáticamente. De manera predeterminada, utilizamos el modelo F2 RCNN Inception Resnet V2, capacitado en
COCO (80 clases), pero no debería haber dificultades para conectar otros modelos.
Logstash, Elasticsearch, Kibana : le permiten visualizar y analizar los registros acumulados por los clientes. Esto se puede utilizar, por ejemplo, para supervisar el proceso de marcado o buscar errores y las causas de su aparición.
 NVIDIA CUDA Toolkit
NVIDIA CUDA Toolkit : un conjunto de herramientas para realizar cálculos en el procesador de gráficos (GPU). Se puede usar para acelerar el diseño automático con TF OD API o en otros complementos personalizados.
Marcado de datos
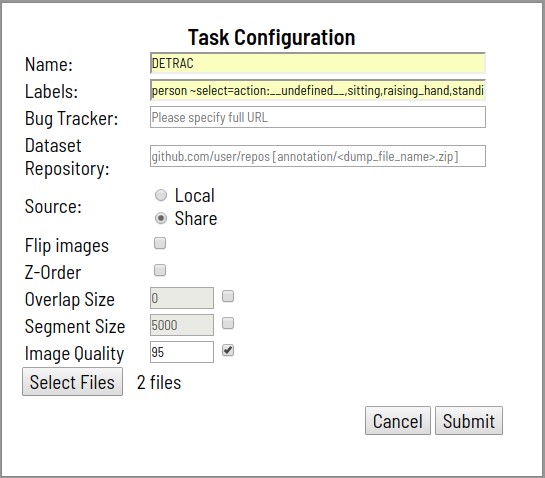
- El proceso comienza con la declaración del problema para el diseño. La puesta en escena incluye:
- Especificar un nombre de tarea
- Enumeración de las clases a marcar y sus atributos.
- Especificar archivos para descargar
- Los datos se descargan del sistema de archivos local o de un sistema de archivos distribuido montado en un contenedor
- Una tarea puede contener un archivo con imágenes, un video, un conjunto de imágenes e incluso una estructura de directorio con imágenes cuando se descarga mediante almacenamiento distribuido
- Opcionalmente configurado:
- Enlace a especificaciones de marcado detalladas, así como a cualquier otra información adicional (Bug Tracker)
- Enlace a un repositorio Git remoto para almacenar anotaciones (Repositorio de conjunto de datos)
- Rotar todas las imágenes 180 grados (Voltear imágenes)
- Capa de soporte para tareas de segmentación (Z-Order)
- Tamaño del segmento Una tarea descargable se puede dividir en varias subtareas para trabajo paralelo
- Área de intersección del segmento (superposición). Se usa en video para fusionar anotaciones en diferentes segmentos
- Nivel de calidad al convertir imágenes (Calidad de imagen)
- Después de procesar la solicitud, la tarea creada aparecerá en la lista de tareas.

- Cada uno de los enlaces en la sección Trabajos corresponde a un segmento. En este caso, la tarea no estaba segmentada previamente. Al hacer clic en cualquiera de los enlaces, se abre la página de marcado.

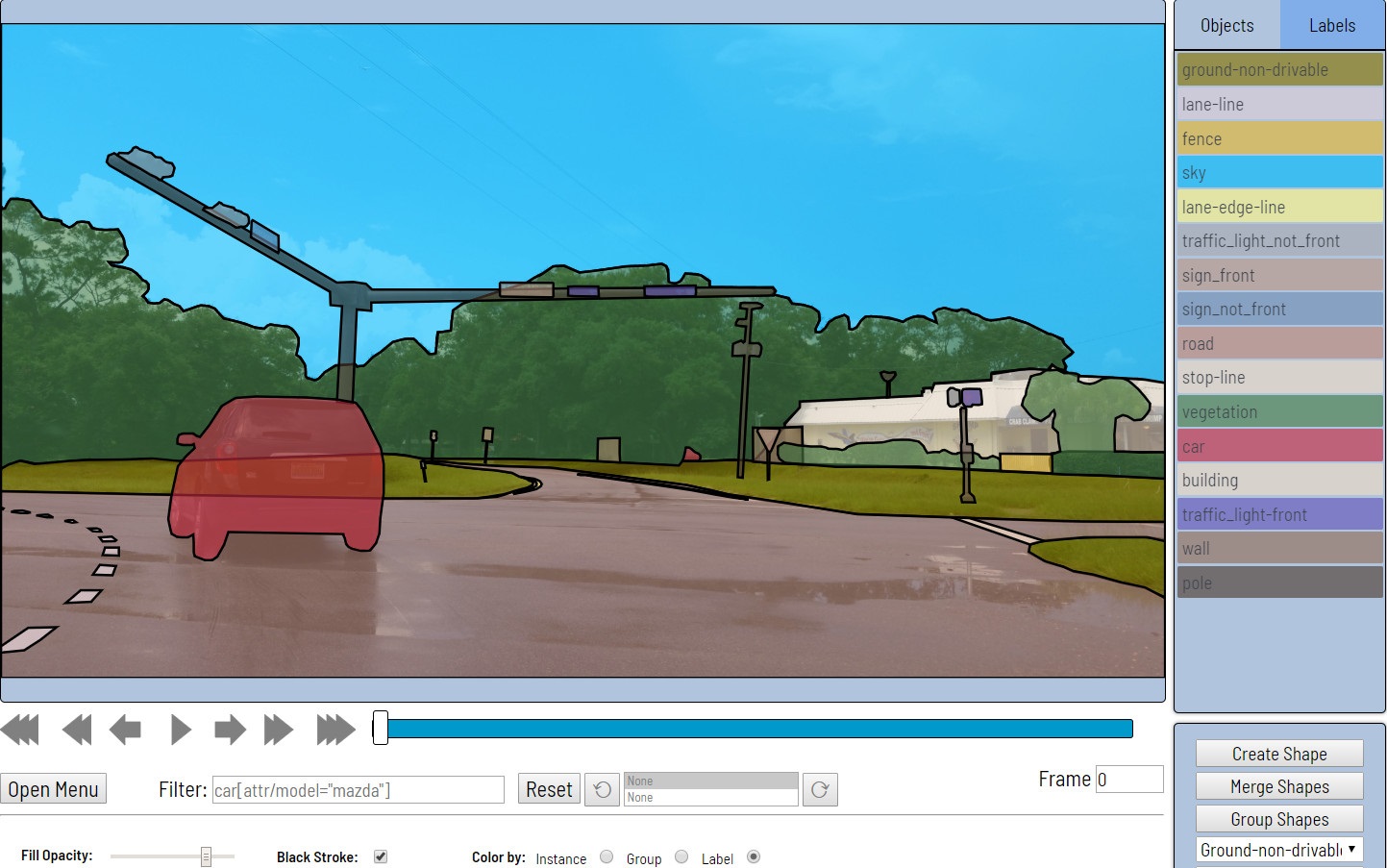
- A continuación, los datos se marcan directamente. Los rectángulos, los polígonos (principalmente para tareas de segmentación), las polilíneas (pueden ser útiles, por ejemplo, para la señalización de carreteras) y muchos puntos (por ejemplo, marcar puntos de referencia de la cara o estimar la postura) se proporcionan como primitivos.
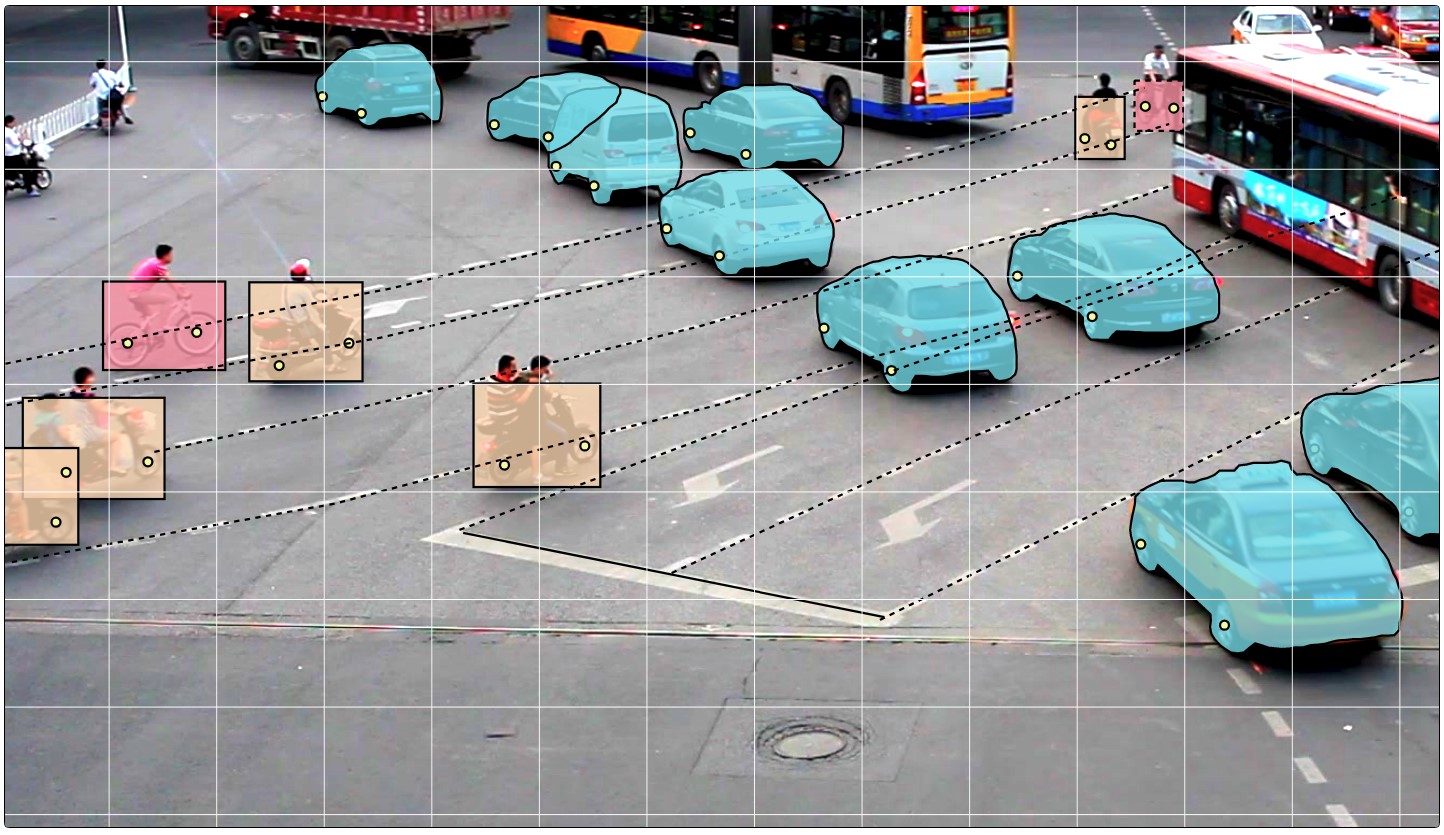
También están disponibles varias herramientas de automatización (copia, multiplicación a otros cuadros, interpolación, marcado preliminar con API TF OD), configuraciones visuales, muchas teclas de acceso rápido, búsqueda, filtrado y otras funcionalidades útiles. En la ventana de configuración, puede cambiar una serie de parámetros para un trabajo más cómodo.
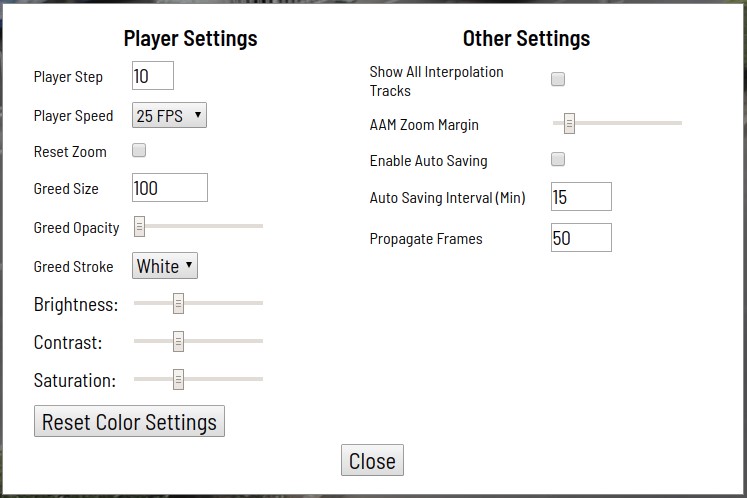
El cuadro de diálogo de ayuda contiene muchos métodos abreviados de teclado compatibles y algunos otros consejos.

El proceso de marcado se puede ver en los ejemplos a continuación.
CVAT puede interpolar linealmente rectángulos y atributos entre fotogramas clave en un video. Debido a esto, la anotación en el conjunto de cuadros se muestra automáticamente.
El modo de anotación de atributos se desarrolló para el escenario de clasificación, que le permite acelerar la anotación de atributos al enfocar el marcado en una propiedad específica. Además, el marcado aquí ocurre mediante el uso de "teclas de acceso rápido".
Los polígonos admiten la segmentación semántica y las secuencias de comandos de segmentación de instancias. Diferentes configuraciones visuales facilitan el proceso de validación.
- Recibir anotación
Al presionar el botón "Anotar volcado" se inicia el proceso de preparación y carga de resultados de marcado como un solo archivo. Un archivo de anotación es un archivo .xml especificado que contiene algunos metadatos de tareas y toda la anotación. El marcado se puede descargar directamente al repositorio de Git, si este último se conectó en la etapa de creación de la tarea.
Historia y evolución
Al principio, no teníamos ninguna unificación, y cada tarea de marcado se realizaba con sus propias herramientas, principalmente escritas en C ++ usando la
biblioteca OpenCV . Estas herramientas se instalaron localmente en máquinas de usuarios finales, no había un mecanismo para compartir datos, una tubería común para configurar y marcar tareas, muchas cosas tenían que hacerse manualmente.
El punto de partida de la historia de CVAT se puede considerar a fines de 2016, cuando se introdujo
Vatic como herramienta de diseño, cuya interfaz se presenta a continuación. Vatic fue de código abierto e introdujo algunas ideas geniales y generales, como el marcado de interpolación entre fotogramas clave en una arquitectura de aplicación de video o cliente-servidor. Sin embargo, en general, proporcionó una funcionalidad de marcado bastante modesta, e hicimos mucho trabajo por nuestra cuenta.
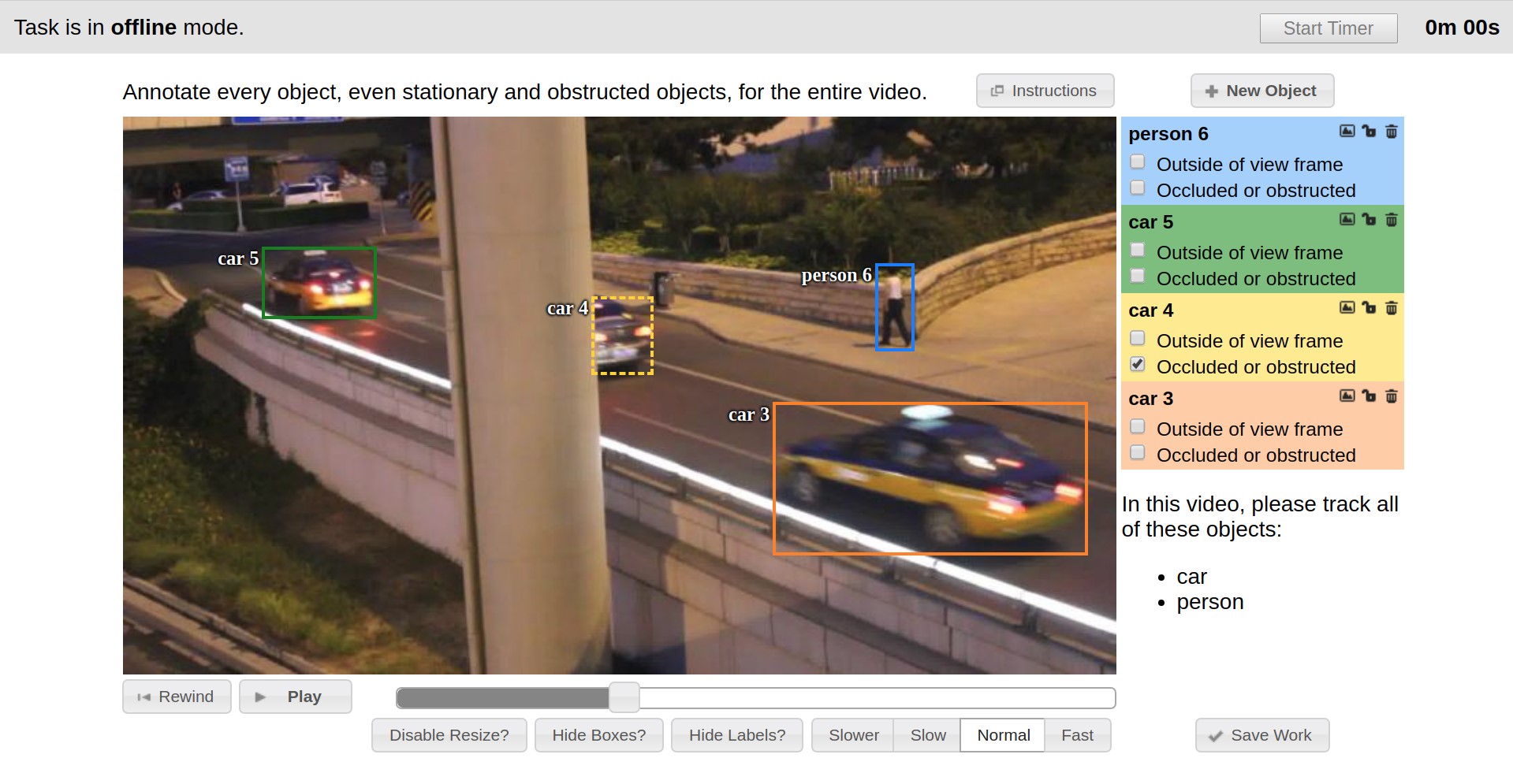
Entonces, por ejemplo, durante los primeros seis meses, se implementó la capacidad de anotar imágenes, se agregaron atributos de objetos de los usuarios, se desarrolló una página con una lista de tareas existentes y la capacidad de agregar otras nuevas a través de la interfaz web.
Durante la segunda mitad de 2017, presentamos la API de detección de objetos de Tensorflow como método para obtener un marcado preliminar. Hubo muchas mejoras menores en el cliente, pero al final nos enfrentamos con el hecho de que la parte del cliente comenzó a funcionar muy lentamente. El hecho fue que el tamaño de las tareas aumentó, el tiempo de su apertura aumentó en proporción al número de cuadros y datos etiquetados, la IU se desaceleró debido a la presentación ineficiente de los objetos etiquetados, el progreso a menudo se perdió con las horas de trabajo. La productividad se redujo principalmente en tareas con imágenes, ya que la base de la arquitectura de esa época se diseñó originalmente para trabajar con video. Existía la necesidad de un cambio completo en la arquitectura del cliente, con el cual nos las arreglamos exitosamente. La mayoría de los problemas de rendimiento en ese momento habían desaparecido. La interfaz web se ha vuelto mucho más rápida y estable. Marcar tareas más grandes se ha vuelto posible. En el mismo período, hubo un intento de introducir pruebas unitarias para proporcionar, hasta cierto punto, la automatización de las comprobaciones durante los cambios. Esta tarea no se ha resuelto con tanto éxito. Configuramos QUnit, Karma, Headless Chrome en el contenedor Docker, escribimos algunas pruebas, lanzamos todo esto en CI. Sin embargo, una gran parte del código permaneció, y aún permanece, descubierto por las pruebas. Otra innovación fue un sistema de registro de acciones del usuario con búsqueda y visualización posteriores basadas en ELK Stack. Le permite monitorear el proceso de los anotadores y buscar escenarios de acción que conduzcan a excepciones de software.
En la primera mitad de 2018, ampliamos la funcionalidad de nuestro cliente. Se agregó el modo de anotación de atributos, que implementa un script efectivo para marcar atributos, cuya idea tomamos prestada de colegas y generalizamos; Ahora puede filtrar objetos de acuerdo con una serie de signos, conectar un almacenamiento común para descargar datos al configurar tareas para verlas a través de un navegador y muchos otros. Las tareas se volvieron más voluminosas y los problemas de rendimiento comenzaron a surgir nuevamente, pero esta vez la parte del servidor fue el cuello de botella. El problema con Vatic era que contenía una gran cantidad de código auto-escrito para tareas que podrían resolverse de manera más fácil y eficiente utilizando soluciones preparadas. Entonces decidimos rehacer el lado del servidor. Elegimos Django como el marco del servidor, en gran parte debido a su popularidad y la disponibilidad de muchas cosas, como dicen, listas para usar. Después de la alteración de la parte del servidor, cuando no quedaba nada de Vatic, decidimos que ya habíamos hecho mucho trabajo, que se puede compartir con la comunidad. Entonces se decidió ir a código abierto. Obtener permiso para esto dentro de una gran empresa es un proceso bastante espinoso. Hay una gran lista de requisitos para esto. Incluyendo, era necesario encontrar un nombre. Esbozamos opciones y realizamos una serie de encuestas entre colegas. Como resultado, nuestra herramienta interna se llamó CVAT, y el 29 de junio de 2018, el código fuente se publicó en
GitHub en la organización OpenCV bajo la licencia MIT y con la versión inicial 0.1.0. El desarrollo posterior tuvo lugar en un repositorio público.
A finales de septiembre de 2018, se lanzó la versión principal 0.2.0. Hubo muchos pequeños cambios y correcciones, pero el foco principal estaba en soportar nuevos tipos de anotaciones. Entonces aparecieron varias herramientas para marcar y validar la segmentación, así como la capacidad de anotar con polilíneas o puntos.
El próximo lanzamiento, como un regalo de Navidad, está programado para el 31 de diciembre de 2018. Los puntos más significativos aquí son la integración opcional del kit de herramientas de implementación de Deep Learning como parte de OpenVINO, que se utiliza para acelerar el lanzamiento de la API TF OD en ausencia de una tarjeta gráfica NVIDIA; sistema de análisis de registro de usuario que no estaba disponible previamente en la versión pública; Muchas mejoras en el lado del cliente.
Hemos resumido el historial de CVAT hasta la fecha (diciembre de 2018) y revisado los eventos más significativos. Siempre puede leer más sobre el historial de
cambios en el
registro de
cambios .
Dispositivo interno
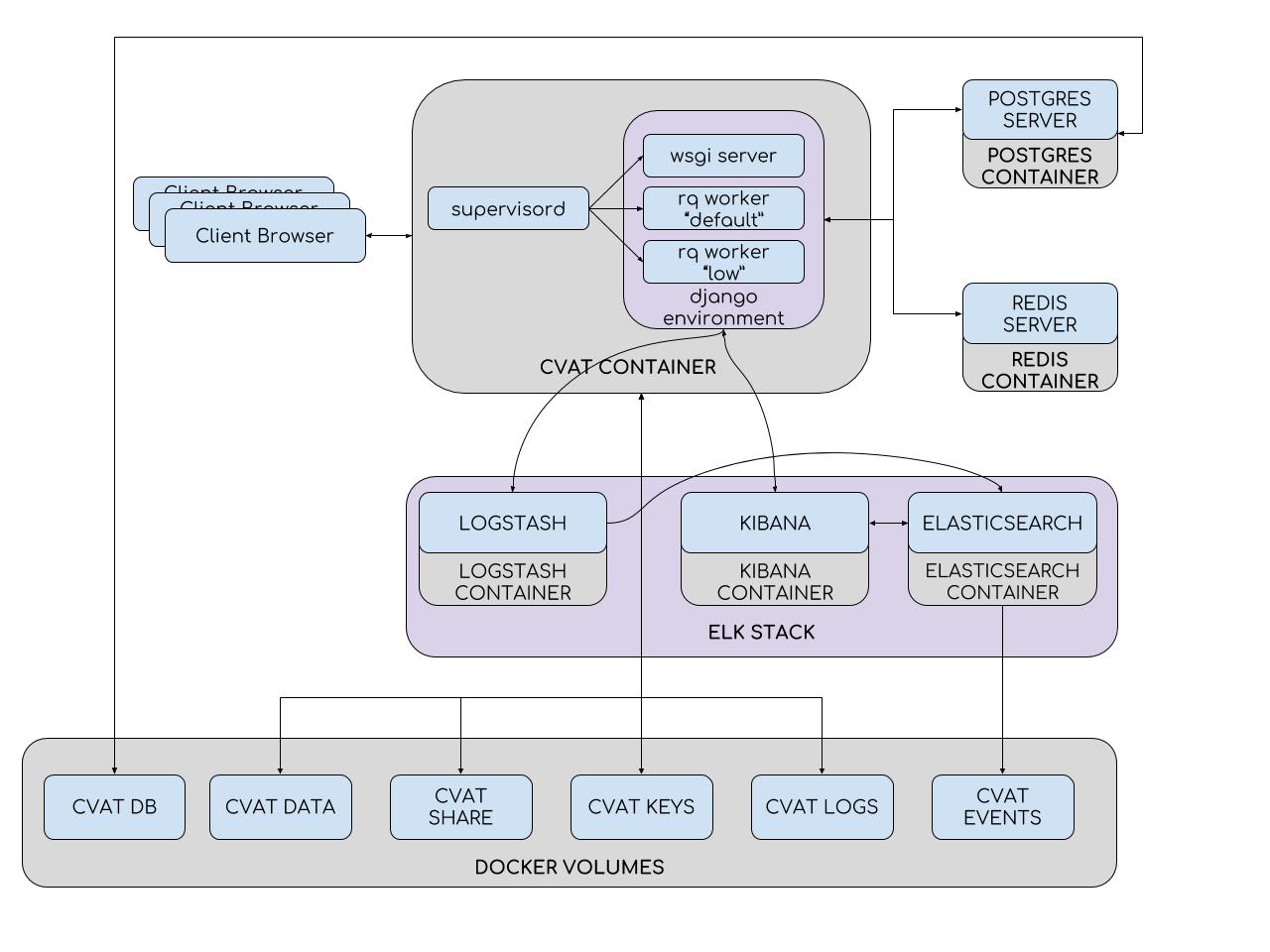
Para simplificar la instalación y la implementación, CVAT utiliza contenedores Docker. El sistema consta de varios contenedores. Se ejecuta un proceso de supervisión en el contenedor CVAT, que genera varios procesos de Python en el entorno Django. Uno de ellos es el servidor wsgi, que maneja las solicitudes de los clientes. Otros procesos, los trabajadores rq, se utilizan para procesar tareas "largas" de las colas de Redis: predeterminada y baja. Dichas tareas incluyen aquellas que no pueden procesarse dentro de una solicitud de un solo usuario (configurar una tarea, preparar un archivo de anotaciones, marcado con TF OD API y otros). El número de trabajadores se puede configurar en el archivo de configuración del supervisor.
El entorno Django interactúa con dos servidores de bases de datos. El servidor Redis almacena el estado de las colas de tareas y la base de datos CVAT contiene toda la información sobre tareas, usuarios, anotaciones, etc. PostgreSQL (y SQLite 3 en desarrollo) se utiliza como DBMS para CVAT. Todos los datos se almacenan en una partición conectable (volumen cvat db). Las secciones se usan donde es necesario evitar la pérdida de datos al actualizar el contenedor. Por lo tanto, los siguientes están montados en el contenedor CVAT:
- Sección con video e imágenes (volumen de datos cvat)
- Sección con teclas (volumen de teclas cvat)
- Sección con registros (volumen de registros de cvat)
- Almacenamiento de archivos compartidos (volumen compartido cvat)
El sistema de análisis consta de Elasticsearch, Logstash y Kibana envueltos en contenedores Docker. Al guardar el trabajo en el cliente, todos los datos, incluidos los registros, se transfieren al servidor. El servidor, a su vez, los envía a Logstash para su filtrado. Además, existe la posibilidad de enviar notificaciones automáticamente a correos electrónicos cuando se produce algún error. A continuación, los registros caen en Elasticsearch. Este último los guarda en una partición conectable (volumen de eventos cvat). Luego, el usuario puede usar la interfaz de Kibana para ver estadísticas y registros. Al mismo tiempo, Kibana interactuará activamente con Elasticsearch.
En el nivel fuente, CVAT consta de muchas aplicaciones de Django:
- Autenticación: autenticación de usuarios en el sistema (básico y LDAP)
- motor: una aplicación clave (modelos de base de datos básicos; carga y guardado de tareas; carga y descarga de anotaciones; marcado de la interfaz del cliente; interfaz del servidor para crear, cambiar y eliminar tareas)
- tablero de instrumentos: interfaz de cliente para crear, editar, buscar y eliminar tareas
- documentación: visualización de la documentación del usuario en la interfaz del cliente
- tf_annotation: anotación automática con la API de detección de objetos de Tensorflow
- log_viewer: envío de registros desde el cliente a Logstash al guardar una tarea
- log_proxy - Conexión proxy CVAT → Kibana
- git: integración del repositorio de Git para almacenar anotaciones
Nos esforzamos por crear un proyecto con una estructura flexible. Por esta razón, las aplicaciones opcionales no tienen incrustación de código duro. Desafortunadamente, aunque no tenemos un prototipo ideal del sistema de complemento, pero gradualmente, con el desarrollo de nuevas aplicaciones, la situación aquí está mejorando.
La parte del cliente se implementa en plantillas JavaScript y Django. JavaScript , , - ( ) model-view-controller. , (, , ) , . ( - UI), (, , : , , models, views controllers).
open source, . , . . , CVAT. , , . :
- CVAT , , , , . UI .
- . , .
- , . , .
- . deep learning , . , Deep Learning Deployment Toolkit OpenVINO - . , . , .
- demo- CVAT, , , . demo- Onepanel, CVAT .
- Amazon Mechanical Turk CVAT . SDK .
, . , , . open source . – , .
, PR . , ,
Gitter . , ! !
Referencias