La publicación fue preparada por Yandex. Miembros del equipo de Cloud: Ivan Vetkasov - arquitecto, Leonid Klyuyev - editor
 Recientemente, hablamos sobre la arquitectura de Yandex.Cloud . Ahora pasemos de la teoría a la práctica. Existen varios servicios en la nube para el control automatizado de DBMS: Servicio administrado para ClickHouse, Servicio administrado para PostgreSQL y Servicio administrado para MongoDB. Todos ellos están basados en la plataforma y le permiten centrarse en la tarea de almacenamiento de datos y no en la administración de la infraestructura. Pero a veces también es importante controlar las máquinas virtuales del clúster. Por ejemplo, puede surgir una tarea de escalado en respuesta a un aumento o disminución de la carga. Por lo general, este escenario es uno de los que lleva más tiempo desde un punto de vista práctico. Hoy le diremos cómo Yandex.Cloud le permite automatizar tareas de escalado complejas y asegurarse de que la base de datos permanezca disponible en el proceso de redimensionamiento del clúster.
Recientemente, hablamos sobre la arquitectura de Yandex.Cloud . Ahora pasemos de la teoría a la práctica. Existen varios servicios en la nube para el control automatizado de DBMS: Servicio administrado para ClickHouse, Servicio administrado para PostgreSQL y Servicio administrado para MongoDB. Todos ellos están basados en la plataforma y le permiten centrarse en la tarea de almacenamiento de datos y no en la administración de la infraestructura. Pero a veces también es importante controlar las máquinas virtuales del clúster. Por ejemplo, puede surgir una tarea de escalado en respuesta a un aumento o disminución de la carga. Por lo general, este escenario es uno de los que lleva más tiempo desde un punto de vista práctico. Hoy le diremos cómo Yandex.Cloud le permite automatizar tareas de escalado complejas y asegurarse de que la base de datos permanezca disponible en el proceso de redimensionamiento del clúster.
Declaración del problema.
Al crear un clúster de cada servicio, el usuario puede determinar el número de hosts del clúster y la zona de disponibilidad (AZ), que corresponde al centro de datos físico. Ahora Yandex.Cloud utiliza tres centros de datos Yandex ubicados en la región central de Rusia. Por lo tanto, la configuración recomendada es el clúster DBMS con tres hosts, como el más coherente con los principios de construcción de una arquitectura de failover y resistente a desastres.
Entonces, imagine una situación en la que la carga en el clúster DBMS excedió las capacidades de la base de datos y es hora de agregar recursos informáticos. Esto se puede hacer tanto horizontalmente, agregando hosts al clúster como verticalmente, agregando recursos a cada máquina del clúster. Considere la segunda opción, como la que consume más tiempo y corre el riesgo de errores. ¿Por qué es esta opción laboriosa? Porque en el caso general, el procedimiento para agregar recursos se verá más o menos así: cambie la función del host; si es necesario, detenga el DBMS; apague la máquina virtual; cambiar su configuración; comenzamos cambiar los parámetros de DBMS; comenzamos un DBMS; Estamos esperando la sincronización de los cambios de datos acumulados. Y así, para los tres anfitriones a su vez. Muchos pasos: el riesgo de errores es alto. Puede automatizar este proceso; solo antes de iniciar la solución de automatización seleccionada debe probarse. Por lo general, no hay suficiente tiempo para las pruebas, pero en Yandex.Cloud se ejecuta rápidamente y sin acciones innecesarias de su parte. Empecemos
Pasos preliminares y proceso de prueba
Para la preparación necesitaremos:
- Acceso a la plataforma. Ahora cualquiera puede configurar un período de prueba en el sitio web en el sitio web Yandex.Cloud .
- Red en la nube (en mi ejemplo lo llamaré testvpc) y tres subredes ubicadas en diferentes AZ. Los rangos de direcciones de subred en este caso no son importantes.
- Bastión de acogida. A pesar de que Yandex.Cloud puede abrir el acceso externo al DBMS a través de una IP pública, publicar un DBMS en el dominio público no es la decisión correcta. Por lo tanto, agregamos un host de bastión al esquema, desde el cual abriremos conexiones a los hosts. Como tal host, puede usar una máquina con uso parcial (5 por ciento) del núcleo. Clickhouse-client debe estar instalado en la máquina virtual. Además, de acuerdo con las instrucciones para conectarse al servicio, debe descargar un certificado SSL.
- CLI Trabajaremos con Yandex.Cloud no a través de la consola, sino a través de la utilidad de línea de comandos, que también debe instalarse e iniciarse de acuerdo con la documentación .
El escenario de prueba será simple: abra tres sesiones conectando el host del bastión a cada host del clúster de la base de datos, ejecute una consulta SQL en un ciclo con un período de, digamos, 1 segundo, después del cual enviaremos un comando para escalar el clúster y observar el comportamiento del sistema.
Momento de la verdad
Elija un DBMS para demostrar la escala. En PostgreSQL, a los hosts se les asignan roles, pero el servicio aún no tiene su conmutación transparente al escalar; esta funcionalidad está en nuestros planes. Dado que el resto de la mecánica de aumentar y disminuir el clúster es aproximadamente el mismo en el caso de los tres DBMS, por ejemplo, tome ClickHouse.
Creemos un objeto de experimento: un clúster que consta de tres hosts ubicados en diferentes subredes virtuales. Para hacer esto, ingrese el comando
yc managed-clickhouse cluster create con los argumentos necesarios. El orden de los argumentos coincide con su listado en la salida de "yc --help". La esencia del comando es simple: creamos un clúster ch-to-redimensionar en un entorno de producción con testvpc ubicado en la red virtual, establecemos un nombre y contraseña, 10 gigabytes de espacio en disco y la clase mínima s1.nano. Las siguientes características corresponden a esta clase: 1 CPU, 4 GB de RAM. En el futuro, para escalar, pasaremos a la clase s1.micro, de modo que se duplique el número de CPU y RAM. Para averiguar qué otras clases de host puede asignar, simplemente ingrese el comando
yc managed-clickhouse resource-preset list .
Por lo tanto, el comando para crear el clúster debe ser el siguiente:
yc managed-clickhouse cluster create --name ch-to-resize --environment production --network-name testvpc --host zone-id=ru-central1-a,subnet-id=e9bfnjacigdo9p6j7j2s,assign-public-ip=false,type=clickhouse --host zone-id=ru-central1-b,subnet-id=e2l8iamol3b9mrtskb8q,assign-public-ip=false,type=clickhouse --host zone-id=ru-central1-c,subnet-id=b0c6qit7u9e8r0egedvj,assign-public-ip=false,type=clickhouse --user name=test,password=test123123 --database name=testdb --clickhouse-disk-size 10 --clickhouse-resource-preset s1.nano --clickhouse-disk-type network-nvme –async
En respuesta, obtenemos el ID del clúster y una lista de nombres de host de sus hosts:
yc managed-clickhouse cluster list +----------------------+--------------+-----------------------------+--------+---------+ | ID | NAME | CREATED AT | HEALTH | STATUS | +----------------------+--------------+-----------------------------+--------+---------+ | c9q7cr4ji2fe462qej8p | ch-to-resize | 2018-12-10T08:59:09.100272Z | ALIVE | RUNNING | +----------------------+--------------+-----------------------------+--------+---------+ yc managed-clickhouse host list --cluster-id c9q7cr4ji2fe462qej8p +-------------------------------------------+----------------------+---------+---------------+ | NAME | CLUSTER ID | HEALTH | ZONE ID | +-------------------------------------------+----------------------+---------+---------------+ | rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net | c9q7cr4ji2fe462qej8p | ALIVE | ru-central1-a | | rc1a-sgxazra54xv6lhni.mdb.yandexcloud.net | c9q7cr4ji2fe462qej8p | UNKNOWN | ru-central1-a | | rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net | c9q7cr4ji2fe462qej8p | ALIVE | ru-central1-b | | rc1b-j1rtvsuz6t8x6ev2.mdb.yandexcloud.net | c9q7cr4ji2fe462qej8p | UNKNOWN | ru-central1-b | | rc1c-emo0f2990povj7ie.mdb.yandexcloud.net | c9q7cr4ji2fe462qej8p | UNKNOWN | ru-central1-c | | rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net | c9q7cr4ji2fe462qej8p | ALIVE | ru-central1-c | +-------------------------------------------+----------------------+---------+---------------+
Vamos a abrir una conexión a cada host y ejecutar una consulta a la base de datos:
clickhouse-client --host rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net --secure --user test --password test123123 --database testdb --port 9440 -q "select concat(host_name, ' is alive\!') from system.clusters where replica_num = 1" clickhouse-client --host rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net --secure --user test --password test123123 --database testdb --port 9440 -q "select concat(host_name, ' is alive!') from system.clusters where replica_num = 2" clickhouse-client --host rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net --secure --user test --password test123123 --database testdb --port 9440 -q "select concat(host_name, ' is alive\!') from system.clusters where replica_num = 3"
Finalmente, envíe una solicitud para aumentar el clúster:
yc managed-clickhouse cluster update --id c9q7cr4ji2fe462qej8p --clickhouse-resource-preset s1.micro -–async
Explicación de reducción de racimoSi queremos reducir, en lugar de aumentar la cantidad de recursos, necesitamos especificar una clase más pequeña, en referencia a la salida
yc managed-clickhouse resource-preset list , por ejemplo, s1.nano. Al mismo tiempo, la estructura del equipo en sí sigue siendo la misma.
Redirigí el resultado de la consulta a un archivo. Aquí hay una lista abreviada:
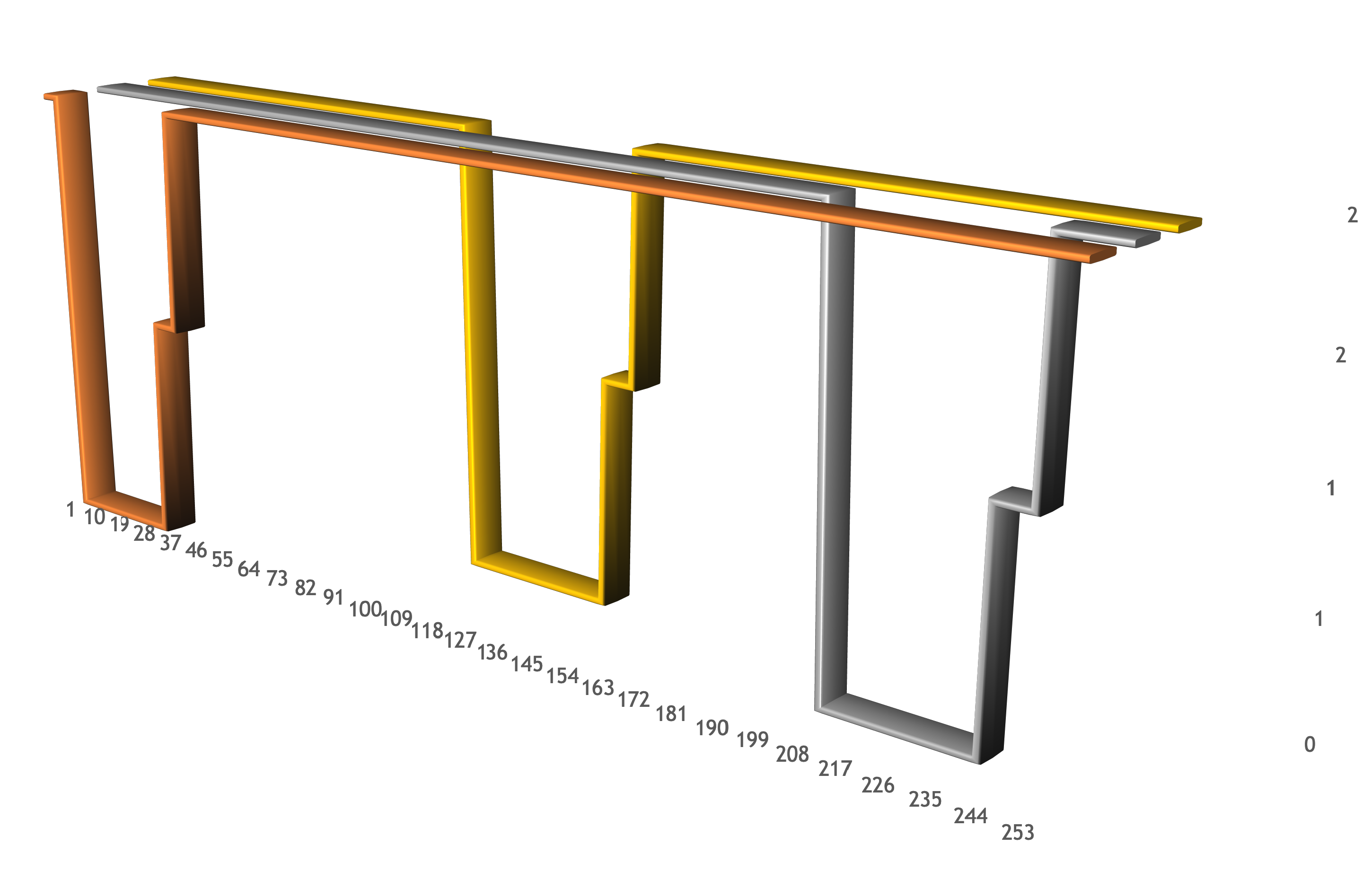
rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net Mon Dec 10 12:47:35 UTC 2018 rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net is alive! Mon Dec 10 12:47:36 UTC 2018 rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net is alive! Mon Dec 10 12:47:37 UTC 2018 rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net is alive! Mon Dec 10 12:47:38 UTC 2018 rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net is alive! Mon Dec 10 12:47:39 UTC 2018 rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net is alive! Mon Dec 10 12:47:40 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.7:9440: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7) Mon Dec 10 12:47:51 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.7:9440: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7) Mon Dec 10 12:48:02 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.7:9440: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7) Mon Dec 10 12:48:11 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7) Mon Dec 10 12:48:12 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7) Mon Dec 10 12:48:13 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7) Mon Dec 10 12:48:14 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7) Mon Dec 10 12:48:15 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7) Mon Dec 10 12:48:16 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7) Mon Dec 10 12:48:17 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7) Mon Dec 10 12:48:18 UTC 2018 rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net is alive! Mon Dec 10 12:48:19 UTC 2018 rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net is alive! Mon Dec 10 12:48:20 UTC 2018 rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net is alive! rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net: Mon Dec 10 12:50:58 UTC 2018 rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net is alive! Mon Dec 10 12:50:59 UTC 2018 rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net is alive! Mon Dec 10 12:51:00 UTC 2018 rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net is alive! Mon Dec 10 12:51:01 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.6:9440: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:12 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.6:9440: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:23 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.6:9440: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:34 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.6:9440: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:35 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:36 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:37 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:38 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:39 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:40 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:41 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:42 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:43 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:44 UTC 2018 rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net is alive! Mon Dec 10 12:51:45 UTC 2018 rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net is alive! Mon Dec 10 12:51:46 UTC 2018 rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net is alive! rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net: Mon Dec 10 12:49:15 UTC 2018 rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net is alive! Mon Dec 10 12:49:16 UTC 2018 rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net is alive! Mon Dec 10 12:49:17 UTC 2018 rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net is alive! Mon Dec 10 12:49:18 UTC 2018 rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net is alive! Mon Dec 10 12:49:19 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.8:9440: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8) Mon Dec 10 12:49:30 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.8:9440: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8) Mon Dec 10 12:49:41 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.8:9440: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8) Mon Dec 10 12:49:52 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.8:9440: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8) Mon Dec 10 12:49:56 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8) Mon Dec 10 12:49:57 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8) Mon Dec 10 12:49:58 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8) Mon Dec 10 12:49:59 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8) Mon Dec 10 12:50:00 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8) Mon Dec 10 12:50:01 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8) Mon Dec 10 12:50:03 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8) Mon Dec 10 12:50:04 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8) Mon Dec 10 12:50:05 UTC 2018 rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net is alive! Mon Dec 10 12:50:06 UTC 2018 rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net is alive! Mon Dec 10 12:50:07 UTC 2018 rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net is alive!
La lista muestra los momentos en que cada host del clúster se apaga (cuando comienza el tiempo de espera de conexión), los momentos en que se enciende el host y ClickHouse comienza a cargarse (cuando comienza la conexión rechazada), y también los momentos en que el host vuelve a funcionar. Lo más importante es la separación de los períodos de tiempo cuando los hosts no estaban disponibles. Mientras se escalaba, al menos dos hosts estaban disponibles para la ejecución de consultas. Esto se puede ver en el gráfico:
Conclusiones y mejores prácticas.
A primera vista, el desarrollo de proyectos con bases de datos incluye una gran cantidad de trabajo de rutina. Es necesario mantener la base de datos, es decir, crear copias de seguridad, establecer el proceso de actualización periódica del DBMS, etc. Los servicios de administración en la nube aparecieron principalmente para eliminar estas funciones que requieren mucho tiempo. Sin embargo, en un entorno de producción real, es útil que los sistemas no solo sean manejables desde el punto de vista del servicio, sino que también sean flexibles, en respuesta a las cargas en aumento y en descenso. Hablamos sobre cómo aumentar el rendimiento de la base de datos en Yandex.Cloud, manteniendo la capacidad de trabajo del proyecto para los usuarios. Si la base de datos está configurada correctamente, con el aumento del tráfico hay un aumento en la cantidad de recursos disponibles y con una recesión, una disminución múltiple, que también reduce sus costos.
¿Sobre qué enfoques, herramientas o tecnologías basadas en la nube le gustaría aprender? Sugiera temas en los comentarios para las siguientes publicaciones de Yandex.Cloud.