
En artículos anteriores, traté de hablar sobre los conceptos básicos de fijación de precios y la creación de un árbol de decisión del cliente para el comercio minorista clásico. En este artículo, le contaré sobre un caso muy poco estándar e intentaré convencerlo de que usar el aprendizaje automático no es tan difícil como parece. El artículo es menos técnico y es más probable que demuestre que puede comenzar de a poco y esto ya traerá beneficios tangibles para el negocio.
Problema inicial
Hay una cadena de tiendas en nuestro continente que cambia su surtido una vez a la semana, por ejemplo, primero vende overlocks y luego ropa deportiva para hombres. Todos los productos no vendidos se envían a almacenes y seis meses después se devuelven a las tiendas nuevamente. Al mismo tiempo, la tienda tiene alrededor de 6 categorías diferentes de productos. Es decir El surtido de tiendas para cada semana es el siguiente:
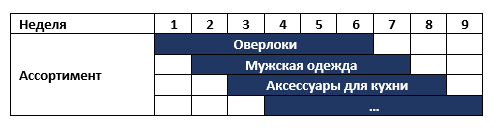
La red solicitó un sistema de planificación de rango con un requisito previo para el soporte de decisiones analíticas para los gerentes de categoría. Después de hablar con el negocio, propusimos dos soluciones potenciales muy rápidas que pueden brindar resultados mientras se implementa el sistema de planificación:
- ventas de bienes que no se venden durante las ventas principales
- Mejorar la precisión de la previsión de la demanda en las tiendas.
El primer punto del cliente no estaba satisfecho: la empresa se enorgullece de no organizar las ventas y mantener un nivel constante de margen. Al mismo tiempo, se gastan enormes cantidades de dinero en logística y almacenamiento de bienes. Como resultado, se decidió mejorar la precisión del pronóstico de la demanda para una distribución más precisa de las tiendas y almacenes.
Proceso actual
Debido a la naturaleza del negocio, cada producto individual no se vende durante mucho tiempo y es problemático obtener suficiente historial para el análisis clásico. El proceso de pronóstico actual es muy simple y está estructurado de la siguiente manera: unas pocas semanas antes del comienzo de las ventas principales en una pequeña parte de las ventas de prueba de las tiendas. En función de los resultados de las ventas de prueba, se toma la decisión de introducir productos en toda la red y se supone que cada tienda venderá en promedio tanto como se vendió en las tiendas de prueba.
Al aterrizar con el cliente, analizamos los datos actuales, nos dimos cuenta de lo que estaba sucediendo y propusimos una solución muy simple para mejorar la precisión del pronóstico.
Analizando datos
De los datos que se nos proporcionaron:
- Historial de transacciones por 1 año y 2 meses.
- Jerarquía de productos para la planificación. Desafortunadamente, carecía casi por completo de los atributos de los productos, pero más sobre eso más tarde
- Información sobre el rango y los precios para semanas específicas.
- Información sobre las ciudades donde se encuentran las tiendas.
No pudimos descargar información sobre saldos en poco tiempo, lo cual es crítico en este tipo de análisis (si no almacena esta información, comience), por lo tanto, en el futuro usamos el supuesto de que los productos están en los estantes y no hay escasez de productos.
Inmediatamente separamos 2 meses en una muestra de prueba para demostrar los resultados. Luego combinamos todos los datos disponibles en un gran escaparate, eliminándolos de devoluciones y ventas extrañas (por ejemplo, la cantidad en el cheque es de 0,51 por pieza de bienes). Tomó varios días. Después de preparar la vitrina, observamos la venta de bienes [unidades] al más alto nivel y vimos la siguiente imagen:
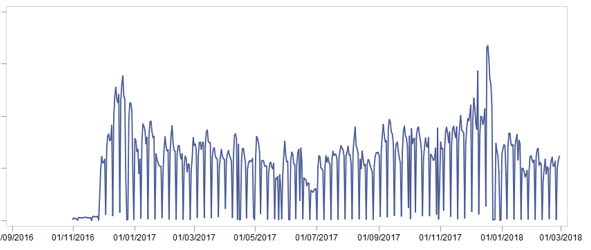
¿Cómo puede ayudarnos esta imagen? .. Pero con qué:
- Obviamente, hay estacionalidad: las ventas al final del año son más altas que en el medio
- Hay estacionalidad dentro del mes: a mediados de mes, las ventas son más altas que al principio y al final
- Hay estacionalidad dentro de la semana, no es tan interesante porque Como resultado, el pronóstico se hizo por semanas.
Los artículos descritos confirmaron el negocio. ¡Pero estas también son excelentes características para mejorar el pronóstico! Antes de agregarlos al modelo de pronóstico, pensemos qué otras características de las ventas deben tenerse en cuenta ... Me vienen a la mente ideas "obvias":
- Las ventas varían en promedio entre los diferentes grupos de productos.
- Las ventas varían entre diferentes tiendas.
- (Similar al párrafo anterior) Las ventas varían entre diferentes ciudades
- (Idea menos obvia) debido a las características específicas del negocio, la siguiente relación es visible: si el surtido futuro y anterior es similar, entonces las ventas del nuevo surtido serán más bajas.
En esto decidimos parar y construir un modelo.
Como parte de la construcción del modelo, todas las características encontradas se tradujeron en "características" del modelo. Aquí está la lista de características utilizadas como resultado:
- pronóstico actual, es decir ventas promedio de tiendas de prueba en [unidades] distribuidas a todas las tiendas
- número de mes y número de semana en mes
- todas las variables categóricas (ciudad, tienda, categorías de productos) se codificaron usando probabilidad suavizada (técnica útil: quien no la use todavía, úsela)
- calculó el retraso de 4 ventas promedio de las categorías de productos. Es decir si la compañía planea vender una camiseta azul, se calculó un retraso de las ventas promedio de la categoría de camisetas
ABT resultó ser simple, cada parámetro era comprensible para las empresas y no causó malentendidos ni rechazos. Entonces fue necesario comprender cómo compararemos la calidad del pronóstico.
Selección métrica
El cliente midió la precisión del pronóstico actual utilizando la métrica MAPE . La métrica es popular y simple, pero tiene ciertas desventajas cuando se trata de pronosticar la demanda. El hecho es que cuando se usa MAPE, los errores de tipo de pronóstico tienen el mayor impacto en el indicador final:

Un error de pronóstico relativo del 900%: parece grande, pero veamos las ventas de otro producto:

El error de pronóstico relativo es 33%, que es mucho menor que 900%, pero la desviación absoluta de la desviación de 100 [unidades] es mucho más importante para el negocio que la desviación de 18 [unidades]. Para tener en cuenta estas características, puede crear sus propias medidas interesantes, o puede utilizar otra medida popular para pronosticar la demanda: WAPE . Esta medida le da más peso a los productos con mayores ventas, lo cual es excelente para la tarea.
Le contamos a la compañía sobre varios enfoques para medir los errores de pronóstico, y el cliente acordó de buena gana que usar WAPE en esta tarea es más razonable. Después de eso, lanzamos Random Forest casi sin ajustar hiperparámetros y obtuvimos los siguientes resultados.
Resultados
Después de pronosticar el período de prueba, comparamos los valores pronosticados con los reales, así como con el pronóstico de la empresa. Como resultado, MAPE disminuyó en más del 15%, WAPE en más del 10% . Una vez calculado el impacto del pronóstico mejorado en los indicadores comerciales, se obtuvo una reducción en los costos por una cantidad bastante grande de millones de dólares.
¡Pasé 1 semana en todo el trabajo!
Pasos adicionales
Como beneficio adicional para el cliente, realizamos un pequeño experimento de DQ . Para un grupo de productos, a partir de los nombres de los productos, analizamos las características (color, tipo de producto, composición, etc.) y las agregamos al pronóstico. El resultado fue inspirador: en esta categoría, ambas medidas de error mejoraron más de un 8% adicional.
Como resultado, se le dio al cliente una descripción de cada característica, parámetros del modelo, parámetros de ensamblaje del escaparate ABT y se describieron pasos adicionales para mejorar el pronóstico (usar datos históricos durante más de un año; usar saldos; usar las características de los productos, etc.).
Conclusión
Durante una semana de colaboración con el cliente, fue posible aumentar significativamente la precisión de la previsión, sin prácticamente cambiar el proceso de negocio.
Seguramente, muchas personas ahora piensan que este caso es muy simple y no pueden lograr este enfoque en la empresa. La experiencia muestra que casi siempre hay lugares donde solo se utilizan supuestos básicos y opiniones de expertos. Desde estos lugares puede comenzar a utilizar el aprendizaje automático. Para hacer esto, debe preparar y estudiar cuidadosamente los datos, hablar con la empresa e intentar aplicar modelos populares que no requieren ajustes largos. Y apilar, incorporar características, modelos complejos, eso es todo para más adelante. Espero haberte convencido de que no es tan difícil como parece, solo tienes que pensar un poco y no tener miedo de comenzar.
No tenga miedo del aprendizaje automático, busque lugares donde se pueda utilizar en los procesos, no tenga miedo de investigar sus datos y deje que los consultores se acerquen a ellos y obtengan resultados geniales.
PD: Estamos reclutando jóvenes estudiantes estudiantes de Padawan para pasantías minoristas bajo la guía de Jedi con experiencia. Para empezar, el sentido común y el conocimiento de SQL son suficientes, le enseñaremos el resto. Puede convertirse en un experto en negocios o consultor técnico, lo que sea más interesante. Si hay interés o recomendaciones, escriba un mensaje personal