El enlace en el artículo de hoy es diferente al habitual. Este no es un proyecto para el que se analizó el código fuente, sino una serie de respuestas de la misma regla de diagnóstico en varios proyectos diferentes. ¿Cuál es el interés aquí? El hecho es que algunos de los fragmentos de código considerados contienen errores que son reproducibles cuando se trabaja con la aplicación, mientras que otros contienen vulnerabilidades (CVE). Además, al final del artículo discutiremos un poco sobre el tema de los defectos de seguridad.
Breve Prefacio
Todos los errores que se considerarán hoy en el artículo tienen un patrón similar:
- el programa recibe datos de la secuencia stdin ;
- se realiza una verificación para el éxito de la lectura de datos;
- Si los datos se leyeron con éxito, el carácter de acarreo se elimina de la línea.
Sin embargo, todos los fragmentos que se considerarán contienen errores y son vulnerables a la entrada manipulada. Dado que los datos se reciben de un usuario que puede violar la lógica de ejecución de la aplicación, hubo una gran tentación de intentar romper algo. Lo cual hice.
Todos los problemas a continuación fueron descubiertos por el
analizador estático PVS-Studio , que busca errores en el código no solo para C, C ++, sino también para C #, Java.
Por supuesto, encontrar un problema con un analizador estático es bueno, pero encontrar y reproducir es un nivel de placer completamente diferente. :)
Freeswitch
El primer fragmento de código sospechoso se encontró en el código del módulo
fs_cli.exe , que forma parte del kit de distribución FreeSWITCH:
static const char *basic_gets(int *cnt) { .... int c = getchar(); if (c < 0) { if (fgets(command_buf, sizeof(command_buf) - 1, stdin) != command_buf) { break; } command_buf[strlen(command_buf)-1] = '\0'; break; } .... }
Advertencia de PVS-Studio :
V1010 CWE-20 Los datos contaminados no
verificados se usan en el índice: 'strlen (command_buf)'.
El analizador advierte de una llamada sospechosa por índice a la matriz
command_buf . Se considera sospechoso porque los datos externos no verificados se utilizan como índice. Externo: porque se obtienen a través de la función
fgets del flujo
estándar . Sin verificar, ya que no se realizó ninguna verificación antes del uso. La expresión
fgets (command_buf, ....)! = Command_buf no cuenta, porque de esta manera solo verificamos el hecho de recibir los datos, pero no su contenido.
El problema con este código es que, bajo ciertas condiciones, '\ 0' se escribirá fuera de la matriz, lo que conducirá a un comportamiento indefinido. Para hacer esto, simplemente ingrese una cadena de longitud cero (una cadena de longitud cero desde el punto de vista del lenguaje C, es decir, uno en el que el primer carácter será '\ 0').
Calculemos qué sucede si pasa una cadena de longitud cero a la entrada:
- fgets (command_buf, ....) -> command_buf ;
- fgets (....)! = command_buf -> false ( entonces la rama de la instrucción if se ignora);
- strlen (comando_buf) -> 0 ;
- command_buf [strlen (command_buf) - 1] -> command_buf [-1] .
¡Uy!
Lo interesante aquí es que esta advertencia del analizador se puede "sentir con las manos". Para repetir el problema, necesita:
- llevar el programa a esta función;
- afine la entrada para que la llamada getchar () devuelva un valor negativo;
- El paso para los fgets funciona una línea con un terminal cero al principio, que debería leer con éxito.
Hurgando un poco en la fuente, inventé una secuencia específica para reproducir el problema:
- Ejecute fs_cli.exe en modo por lotes ( fs_cli.exe -b ). Observo que para realizar más pasos, la conexión fs_cli.exe al servidor debe ser exitosa. Para hacer esto, es suficiente, por ejemplo, ejecutar FreeSwitchConsole.exe localmente como administrador.
- Llevamos a cabo la entrada para que la llamada getchar () devuelva un valor negativo.
- Ingrese una línea con un terminal cero al principio (por ejemplo, '\ 0Oooops').
- ....
- BENEFICIOS!
La siguiente es una reproducción de video del problema:
Ncftp
Se descubrió un problema similar en el proyecto NcFTP, pero ya se encontró en dos lugares. Dado que el código es similar, considere solo un lugar problemático:
static int NcFTPConfirmResumeDownloadProc(....) { .... if (fgets(newname, sizeof(newname) - 1, stdin) == NULL) newname[0] = '\0'; newname[strlen(newname) - 1] = '\0'; .... }
Advertencia de PVS-Studio :
V1010 CWE-20 Los datos contaminados no
verificados se usan en el índice: 'strlen (newname)'.
Aquí, a diferencia del ejemplo de FreeSWITCH, el código está escrito peor y más propenso a problemas. Por ejemplo, escribir '\ 0' ocurre independientemente de si la lectura fue exitosa usando
fgets o no. Es decir, hay aún más posibilidades de cómo romper la lógica normal de ejecución. Vayamos de una manera comprobada: a través de líneas de longitud cero.
El problema reproducido es un poco más complicado que con FreeSWITCH. La secuencia de pasos se describe a continuación:
- iniciando y conectándose al servidor desde el cual puede descargar el archivo. Por ejemplo, usé speedtest.tele2.net (al final, el comando de inicio de la aplicación se ve así: ncftp.exe speedtest.tele2.net );
- descargando un archivo del servidor. Localmente, un archivo con el mismo nombre pero con diferentes propiedades ya debería existir. Puede, por ejemplo, descargar un archivo del servidor, cambiarlo e intentar ejecutar el comando de descarga nuevamente (por ejemplo, obtener 512KB.zip );
- responda la pregunta sobre cómo elegir una acción con una línea que comience con el carácter 'N' (por ejemplo, ahora divirtámonos );
- ingrese '\ 0' (o algo más interesante);
- ....
- BENEFICIOS!
La reproducción del problema también se graba en video:
Openldap
En el proyecto OpenLDAP (más precisamente, en una de las utilidades que lo acompañan) pisaron el mismo rastrillo que en FreeSWITCH. Solo se intenta eliminar un carácter de salto de línea si la línea se leyó con éxito, pero tampoco hay protección contra las líneas de longitud cero.
Fragmento de código:
int main( int argc, char **argv ) { char buf[ 4096 ]; FILE *fp = NULL; .... if (....) { fp = stdin; } .... if ( fp == NULL ) { .... } else { while ((rc == 0 || contoper) && fgets(buf, sizeof(buf), fp) != NULL) { buf[ strlen( buf ) - 1 ] = '\0'; if ( *buf != '\0' ) { rc = dodelete( ld, buf ); if ( rc != 0 ) retval = rc; } } } .... }
Advertencia de PVS-Studio :
V1010 CWE-20 Los datos contaminados no
verificados se usan en el índice: 'strlen (buf)'.
Tiramos el exceso para que la esencia del problema se vuelva más obvia:
while (.... && fgets(buf, sizeof(buf), fp) != NULL) { buf[ strlen( buf ) - 1 ] = '\0'; .... }
Este código es mejor que NcFTP, pero sigue siendo vulnerable. Si en la solicitud se
olvida pasar una cadena de longitud cero a la entrada:
- fgets (buf, ....) -> buf ;
- fgets (....)! = NULL -> true (el cuerpo del ciclo while comienza a ejecutarse);
- strlen (buf) - 1 -> 0 - 1 -> -1 ;
- buf [-1] = '\ 0' .
libidn
A pesar del hecho de que los errores discutidos anteriormente son bastante interesantes (se reproducen de manera estable y pueden ser "tocados" (excepto que no pude alcanzar el problema de OpenLDAP)), no se los puede llamar vulnerabilidades, solo porque Los problemas no tienen asignados identificadores CVE.
Sin embargo, algunas vulnerabilidades reales tienen el mismo patrón de problemas. Los dos fragmentos de código a continuación se aplican al proyecto libidn.
Fragmento de código:
int main (int argc, char *argv[]) { .... else if (fgets (readbuf, BUFSIZ, stdin) == NULL) { if (feof (stdin)) break; error (EXIT_FAILURE, errno, _("input error")); } if (readbuf[strlen (readbuf) - 1] == '\n') readbuf[strlen (readbuf) - 1] = '\0'; .... }
Advertencia de PVS-Studio :
V1010 CWE-20 Los datos contaminados no
verificados se usan en el índice: 'strlen (readbuf)'.
La situación es similar, excepto que, a diferencia de los ejemplos anteriores, donde la grabación se realizó en el índice
-1 , aquí se realiza la lectura. Sin embargo, este sigue siendo un comportamiento indefinido. A este error se le ha
asignado su propio identificador
CVE (
CVE-2015-8948 ).
Después de detectar un problema, este código se cambió de la siguiente manera:
int main (int argc, char *argv[]) { .... else if (getline (&line, &linelen, stdin) == -1) { if (feof (stdin)) break; error (EXIT_FAILURE, errno, _("input error")); } if (line[strlen (line) - 1] == '\n') line[strlen (line) - 1] = '\0'; .... }
¿Un poco sorprendido? Sucede Nueva vulnerabilidad, identificador CVE correspondiente:
CVE-2016-6262 .
Advertencia de PVS-Studio :
V1010 CWE-20 Los datos contaminados no
verificados se usan en el índice: 'strlen (línea)'.
En otro intento, el problema se solucionó agregando una verificación para la longitud de la cadena de entrada:
if (strlen (line) > 0) if (line[strlen (line) - 1] == '\n') line[strlen (line) - 1] = '\0';
Echemos un vistazo a las fechas. El compromiso de 'cierre' CVE-2015-8948 - 10/08/2015. Comprometer el cierre CVE-2016-62-62 - 14/01/2016. Es decir, la diferencia entre las correcciones anteriores es de
5 meses . Aquí recuerda la ventaja del análisis estático como la detección de errores en las primeras etapas de la escritura de código ...
Análisis estático y seguridad
No habrá más ejemplos de código; en cambio, estadísticas y razonamiento. En esta sección, la opinión del autor puede no coincidir con la opinión del lector mucho más que antes en este artículo.
Nota Le recomiendo que lea otro artículo sobre un tema similar: "
¿Cómo puede ayudar PVS-Studio a encontrar vulnerabilidades? ". Hay ejemplos interesantes de vulnerabilidades que parecen simples errores. Además, en ese artículo hablé un poco sobre la terminología y por qué el análisis estático es imprescindible si le preocupa el tema de la seguridad.
Veamos las estadísticas sobre la cantidad de vulnerabilidades descubiertas en los últimos 10 años para evaluar la situación. Tomé los datos del sitio web
Detalles de CVE .
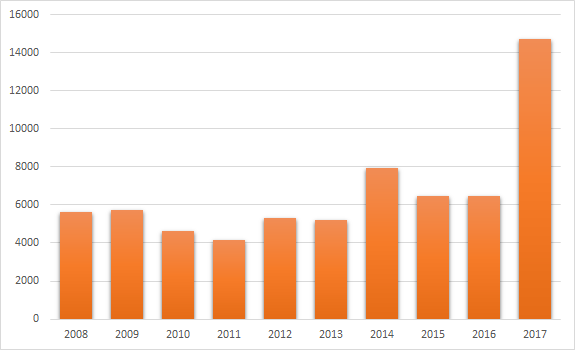
Se avecina una situación interesante. Hasta 2014, el número de CVE registradas no superó la marca de 6,000 unidades y, a partir de, no cayó por debajo. Pero lo más interesante aquí, por supuesto, son las estadísticas para 2017: el líder absoluto (14,714 unidades). En cuanto al año actual 2018, aún no ha terminado, pero ya está batiendo récords: 15.310 unidades.
¿Significa esto que todo el nuevo software está lleno de agujeros como un tamiz? No lo creo, y he aquí por qué:
- Mayor interés en el tema de las vulnerabilidades. Seguramente, incluso si no está muy cerca del tema de la seguridad, ha encontrado repetidamente artículos, notas, informes y videos sobre el tema de la seguridad. En otras palabras, se creó una especie de "bombo". ¿Es malo? Probablemente no. Al final, todo se reduce al hecho de que los desarrolladores están más preocupados por la seguridad de las aplicaciones, lo cual es bueno.
- Un aumento en el número de aplicaciones desarrolladas. Más código: es más probable que ocurra cualquier vulnerabilidad que reponga las estadísticas.
- Herramientas de búsqueda de vulnerabilidades mejoradas y garantía de calidad del código. Más demanda -> más oferta. Los analizadores, fuzzers y otras herramientas son cada vez más avanzados, lo que juega en manos de aquellos que desean buscar vulnerabilidades (independientemente de qué lado de las barricadas se encuentren).
Por lo tanto, la tendencia emergente no puede llamarse exclusivamente negativa: los editores están más preocupados por la seguridad de la información, se mejoran las herramientas para encontrar problemas y, sin duda, todo esto es positivo.
¿Esto significa que puedes relajarte y no "bañarte"? Creo que no Si le preocupa el tema de seguridad de sus aplicaciones, debe tomar tantas medidas de seguridad como sea posible. Esto es especialmente cierto si el código fuente está en el dominio público, ya que:
- más susceptible a incrustar vulnerabilidades externas;
- más propensos a "sondear" por aquellos "caballeros" que estén interesados en agujeros en su aplicación con el propósito de explotarlos. Aunque los simpatizantes en este caso podrán ayudarlo más.
No quiero decir que no necesita traducir sus proyectos en código abierto. Solo tenga en cuenta los controles de calidad / seguridad adecuados.
¿Es el análisis estático una medida tan adicional? Si El análisis estático hace un buen trabajo al detectar vulnerabilidades potenciales que podrían volverse reales en el futuro.
Me parece (admito que estoy equivocado) que muchos consideran las vulnerabilidades como un fenómeno de alto nivel. Si y no Los problemas de código que parecen simples errores de programación también pueden ser vulnerabilidades graves. Una vez más, se proporcionan algunos ejemplos de tales vulnerabilidades en el
artículo mencionado anteriormente . No subestimes los errores 'simples'.
Conclusión
No olvide que los datos de entrada pueden ser de longitud cero, y esto también debe tenerse en cuenta.
Conclusiones sobre si todo el bombo con vulnerabilidades es solo bombo, o si el problema existe, hágalo usted mismo.
Por mi parte, a menos que proponga probar su proyecto
PVS-Studio , si aún no lo ha hecho.
Todo lo mejor!

Si desea compartir este artículo con una audiencia de habla inglesa, utilice el enlace a la traducción: Sergey Vasiliev.
Disparate en el pie cuando manejes datos de entrada