El segundo artículo de la serie "Desarrollo impulsado por pruebas de aplicaciones en Spring Boot" y esta vez hablaré sobre probar el acceso a la base de datos, un aspecto importante de las pruebas de integración. Le diré cómo determinar la interfaz de un servicio futuro para el acceso a datos a través de pruebas, cómo usar bases de datos integradas en memoria para realizar pruebas, trabajar con transacciones y cargar datos de prueba a la base de datos.
No hablaré mucho sobre TDD y las pruebas en general, invito a todos a leer el primer artículo: Cómo construir una pirámide en el tronco o Desarrollo de aplicaciones basadas en pruebas en la revista Spring Boot / geek
Comenzaré, como la última vez, con una pequeña parte teórica, y pasaré a la prueba de punta a punta.
Pirámide de prueba
Para comenzar, una descripción pequeña pero necesaria de una entidad tan importante en las pruebas como The Test Pyramid o the piramide de prueba .
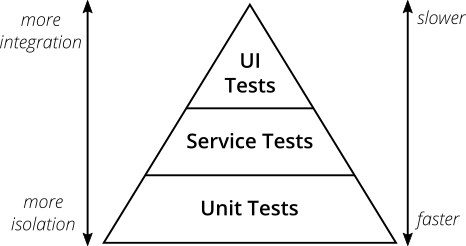
(tomado de The Practical Test Pyramid )
La pirámide de prueba es el enfoque cuando las pruebas se organizan en varios niveles.
- Las pruebas de UI (o de extremo a extremo, E2E ) son pocas y son lentas, pero prueban la aplicación real, sin simulacros y contrapartes de prueba. Las empresas a menudo piensan a este nivel y todos los marcos de BDD viven aquí (ver Cucumber en un artículo anterior).
- Les siguen las pruebas de integración (servicio, componente, cada una tiene su propia terminología), que ya se enfoca en un componente específico (servicio) del sistema, aislándolo de otros componentes a través de moki / dobles, pero aún verificando la integración con sistemas externos reales: estas pruebas están conectadas a la base de datos, enviar solicitudes REST, trabajo con una cola de mensajes. De hecho, estas son pruebas que verifican la integración de la lógica empresarial con el mundo exterior.
- En la parte inferior están las pruebas unitarias rápidas que prueban los bloques mínimos de código (clases, métodos) en completo aislamiento.
Spring ayuda a escribir pruebas para cada nivel, incluso para las pruebas unitarias , aunque esto puede sonar extraño, porque en el mundo de las pruebas unitarias no debería existir ningún conocimiento sobre el marco. Después de escribir la prueba E2E, solo mostraré cómo Spring permite incluso cosas tan puramente de "integración" como los controladores para probar de forma aislada.
Pero comenzaré desde la parte superior de la pirámide: la prueba de IU lenta, que comienza y prueba una aplicación completa.
Prueba de punta a punta
Entonces, una nueva característica:
Feature: A list of available cakes Background: catalogue is updated Given the following items are promoted | Title | Price | | Red Velvet | 3.95 | | Victoria Sponge | 5.50 | Scenario: a user visiting the web-site sees the list of items Given a new user, Alice When she visits Cake Factory web-site Then she sees that "Red Velvet" is available with price £3.95 And she sees that "Victoria Sponge" is available with price £5.50
Y aquí hay un aspecto inmediatamente interesante: ¿qué hacer con la prueba anterior, sobre el saludo en la página principal? Parece que ya no es relevante, después de iniciar el sitio en la página principal ya habrá un directorio, no un saludo. No hay una respuesta única, diría, depende de la situación. Pero el consejo principal: ¡no te apegues a las pruebas! Elimine cuando pierdan relevancia, vuelva a escribir para que sea más fácil de leer. Especialmente pruebas E2E: esta debería ser, de hecho, una especificación viva y actual . En mi caso, simplemente eliminé las pruebas anteriores y las reemplacé por otras nuevas, utilizando algunos de los pasos anteriores y agregando las que no existen.
Ahora he llegado a un punto importante: la elección de la tecnología para almacenar datos. De acuerdo con el enfoque lean , me gustaría posponer la elección hasta el último momento, cuando sabré con certeza si el modelo relacional o no, cuáles son los requisitos de coherencia, transaccionalidad. En general, existen soluciones para esto, por ejemplo, la creación de gemelos de prueba y varios almacenamientos en memoria , pero hasta ahora no quiero complicar el artículo y elegir inmediatamente la tecnología: bases de datos relacionales. Pero para preservar al menos alguna posibilidad de elegir una base de datos, agregaré una abstracción: Spring Data JPA . JPA en sí es una especificación bastante abstracta para acceder a bases de datos relacionales, y Spring Data hace que su uso sea aún más fácil.
Spring Data JPA utiliza Hibernate como proveedor de forma predeterminada, pero también admite otras tecnologías, como EclipseLink y MyBatis. Para las personas que no están muy familiarizadas con la API de persistencia de Java, JPA es como una interfaz e Hibernate es una clase que la implementa.
Entonces, para agregar soporte JPA, agregué un par de dependencias:
implementation('org.springframework.boot:spring-boot-starter-data-jpa') runtime('com.h2database:h2')
Como base de datos, usaré H2 , una base de datos integrada escrita en Java, con la capacidad de trabajar en modo en memoria.
Usando Spring Data JPA, defino inmediatamente una interfaz para acceder a los datos:
interface CakeRepository extends CrudRepository<CakeEntity, String> { }
Y la esencia:
@Entity @Builder @AllArgsConstructor @Table(name = "cakes") class CakeEntity { public CakeEntity() { } @Id @GeneratedValue(strategy = GenerationType.IDENTITY) Long id; @NotBlank String title; @Positive BigDecimal price; @NotBlank @NaturalId String sku; boolean promoted; @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; CakeEntity cakeEntity = (CakeEntity) o; return Objects.equals(title, cakeEntity.title); } @Override public int hashCode() { return Objects.hash(title); } }
Hay un par de cosas menos obvias en la descripción de la entidad.
@NaturalId para el campo sku . Este campo se usa como un "identificador natural" para verificar la igualdad de las entidades; usar todos los campos o campos @Id en métodos equals / hashCode es más bien un antipatrón. Está bien escrito sobre cómo verificar correctamente la igualdad de las entidades, por ejemplo, aquí .- Para reducir un poco el código repetitivo, utilizo Project Lombok - procesador de anotación para Java. Le permite agregar varias cosas útiles, como
@Builder - para generar automáticamente un generador para una clase y @AllArgsConstructor para crear un constructor para todos los campos.
Spring Data proporcionará automáticamente una implementación de interfaz.
Por la pirámide
Ahora es el momento de bajar al siguiente nivel de la pirámide. Como regla general, recomendaría que siempre comience con la prueba e2e , ya que esto le permitirá determinar el "objetivo final" y los límites de la nueva función, pero no hay reglas estrictas adicionales. No es necesario escribir primero una prueba de integración, antes de pasar al nivel de la unidad. La mayoría de las veces es más conveniente y más simple, y es bastante natural bajar.
Pero específicamente ahora, me gustaría romper inmediatamente esta regla y escribir una prueba unitaria que ayudará a determinar la interfaz y el contrato de un nuevo componente que aún no existe. El controlador debe devolver un modelo que se completará a partir de un determinado componente X, y escribí esta prueba:
@ExtendWith(MockitoExtension.class) class IndexControllerTest { @Mock CakeFinder cakeFinder; @InjectMocks IndexController indexController; private Set<Cake> cakes = Set.of(new Cake("Test 1", "£10"), new Cake("Test 2", "£10")); @BeforeEach void setUp() { when(cakeFinder.findPromotedCakes()).thenReturn(cakes); } @Test void shouldReturnAListOfFoundPromotedCakes() { ModelAndView index = indexController.index(); assertThat(index.getModel()).extracting("cakes").contains(cakes); } }
Esta es una prueba de unidad pura: no hay contextos, no hay bases de datos aquí, solo Mockito para mok. Y esta prueba es solo una buena demostración de cómo Spring ayuda a las pruebas unitarias: el controlador en Spring MVC es solo una clase cuyos métodos aceptan parámetros de tipos ordinarios y devuelven objetos POJO - Ver modelos . No hay solicitudes HTTP, no hay respuestas, encabezados, JSON, XML: todo esto se aplicará automáticamente en la pila en forma de convertidores y serializadores. Sí, hay una pequeña "pista" para Spring en forma de ModelAndView , pero este es un POJO normal e incluso puede deshacerse de él si lo desea, es necesario específicamente para los controladores de UI.
No hablaré mucho sobre Mockito, puedes leer todo en la documentación oficial. Específicamente, solo hay puntos interesantes en esta prueba: uso MockitoExtension.class como el MockitoExtension.class prueba, y generará automáticamente mokas para los campos anotados por @Mock y luego inyectará estas mokas como dependencias en el constructor para el objeto en el campo marcado @InjectMocks . Puede hacer todo esto manualmente utilizando el método Mockito.mock() y luego crear una clase.
Y esta prueba ayuda a determinar el método del nuevo componente: findPromotedCakes , una lista de pasteles que queremos mostrar en la página principal. No determina qué es o cómo debería funcionar con la base de datos. La única responsabilidad del controlador es tomar lo que se le transfirió y devolver los modelos ("tortas") en un campo específico. Sin embargo, CakeFinder ya tiene el primer método en mi interfaz, lo que significa que puede escribir una prueba de integración para él.
Deliberadamente hice todas las clases dentro del paquete de cakes privadas para que nadie fuera del paquete pudiera usarlas. La única forma de obtener datos de la base de datos es con la interfaz CakeFinder, que es mi "componente X" para acceder a la base de datos. Se convierte en un "conector" natural, que puedo bloquear fácilmente si necesito probar algo de forma aislada y no tocar la base. Y su única implementación es JpaCakeFinder. Y si, por ejemplo, el tipo de base de datos o la fuente de datos cambian en el futuro, entonces deberá agregar una implementación de la interfaz CakeFinder sin cambiar el código que la usa.
Prueba de integración para JPA usando @DataJpaTest
Las pruebas de integración son pan y mantequilla de primavera. En él, de hecho, todo se hizo tan bien para las pruebas de integración que los desarrolladores a veces no quieren ir al nivel de la unidad o descuidar el nivel de la interfaz de usuario. Esto no es malo ni bueno. Repito que el objetivo principal de las pruebas es la confianza. Y un conjunto de pruebas de integración rápidas y efectivas puede ser suficiente para proporcionar esta confianza. Sin embargo, existe el peligro de que, con el tiempo, estas pruebas sean más lentas o más lentas, o simplemente comiencen a probar componentes de forma aislada, en lugar de integrarse.
Las pruebas de integración pueden ejecutar la aplicación tal como es ( @SpringBootTest ) o su componente separado (JPA, Web). En mi caso, quiero escribir una prueba enfocada para JPA, por lo que no necesito configurar controladores ni ningún otro componente. La anotación @DataJpaTest es responsable de esto en Spring Boot Test. Esta es una meta anotación, es decir Combina varias anotaciones diferentes que configuran diferentes aspectos de la prueba.
- @AutoConfigureDataJpa
- @AutoConfigureTestDatabase
- @AutoConfigureCache
- @AutoConfigureTestEntityManager
- @Transactional
Primero te contaré sobre cada uno individualmente, y luego te mostraré la prueba finalizada.
@AutoConfigureDataJpa
Carga un conjunto completo de configuraciones y repositorios de configuraciones (generación automática de implementaciones para CrudRepositories ), herramientas de migración para las bases de datos FlyWay y Liquibase, conectándose a la base de datos usando DataSource, el administrador de transacciones y finalmente Hibernate. De hecho, esto es solo un conjunto de configuraciones relevantes para acceder a los datos, ni DispatcherServlet de Web MVC, ni otros componentes están incluidos aquí.
@AutoConfigureTestDatabase
Este es uno de los aspectos más interesantes de la prueba JPA. Esta configuración busca en el classpath una de las bases de datos integradas admitidas y reconfigura el contexto para que DataSource apunte a una base de datos en memoria creada aleatoriamente . Como agregué la dependencia a la base H2, no necesito hacer nada más, solo tener esta anotación automáticamente para cada ejecución de prueba proporcionará una base vacía, y esto es simplemente increíblemente conveniente.
Vale la pena recordar que esta base estará completamente vacía, sin un esquema. Para generar el circuito, hay un par de opciones.
- Use la función Auto DDL de Hibernate. Spring Boot Test establecerá automáticamente este valor en
create-drop para que Hibernate genere un esquema a partir de la descripción de la entidad y lo elimine al final de la sesión. Esta es una característica increíblemente poderosa de Hibernate, que es muy útil para las pruebas. - Utilice las migraciones creadas por Flyway o Liquibase .
Puede leer más sobre los diferentes enfoques para inicializar la base de datos en la documentación .
@AutoConfigureCache
Simplemente configura el caché para usar NoOpCacheManager, es decir no guarde en caché nada. Esto es útil para evitar sorpresas en las pruebas.
@AutoConfigureTestEntityManager
Agrega un objeto TestEntityManager especial al TestEntityManager , que en sí mismo es una bestia interesante. EntityManager es la clase principal de JPA, que es responsable de agregar entidades a la sesión, eliminar y cosas similares. Solo cuando, por ejemplo, Hibernate entra en funcionamiento: agregar una entidad a una sesión no significa que se ejecutará una solicitud a la base de datos, y cargar desde una sesión no significa que se ejecutará una solicitud de selección. Debido a los mecanismos internos de Hibernate, las operaciones reales con la base de datos se realizarán en el momento adecuado, lo que determinará el marco en sí. Pero en las pruebas, puede ser necesario enviar algo a la base de datos a la fuerza, porque el propósito de las pruebas es probar la integración. Y TestEntityManager es solo un ayudante que ayudará a realizar algunas operaciones con la base de datos a la fuerza; por ejemplo, persistAndFlush() obligará a Hibernate a ejecutar todas las solicitudes.
@Transactional
Esta anotación hace que todas las pruebas de la clase sean transaccionales, con la reversión automática de la transacción al finalizar la prueba. Esto es solo un mecanismo para "limpiar" la base de datos antes de cada prueba, porque de lo contrario tendría que eliminar manualmente los datos de cada tabla.
Si una prueba debe administrar una transacción no es una pregunta tan simple y obvia como podría parecer. A pesar de la conveniencia del estado "limpio" de la base de datos, la presencia de @Transactional en las pruebas puede ser una sorpresa desagradable si el código de "batalla" no inicia la transacción en sí, sino que requiere uno existente. Esto puede llevar al hecho de que la prueba de integración pasa, pero cuando el código real se ejecuta desde el controlador, y no desde la prueba, el servicio no tendrá una transacción activa y el método arrojará una excepción. Aunque esto parece peligroso, con pruebas de alto nivel de pruebas de IU, las pruebas transaccionales no son tan malas. En mi experiencia, solo vi una vez, cuando una prueba de integración aprobada bloqueó el código de producción, lo que claramente requería la existencia de una transacción existente. Pero si aún necesita verificar que los servicios y componentes administran correctamente las transacciones, puede "bloquear" la anotación @Transactional en la prueba con el modo deseado (por ejemplo, no inicie la transacción).
Prueba de integración con @SpringBootTest
También quiero señalar que @DataJpaTest no es un ejemplo único de una prueba de integración focal, hay @WebMvcTest , @DataMongoTest y muchos otros. Pero una de las anotaciones de prueba más importantes sigue siendo @SpringBootTest , que lanza la aplicación "tal cual" para las pruebas, con todos los componentes e integraciones configurados. Surge una pregunta lógica: si puede ejecutar toda la aplicación, ¿por qué realizar pruebas focales de DataJpa, por ejemplo? Yo diría que no hay reglas estrictas aquí nuevamente.
Si es posible ejecutar aplicaciones cada vez, aislar los bloqueos en las pruebas, no sobrecargar y no volver a complicar la configuración de la prueba, entonces, por supuesto, puede y debe usar @SpringBootTest.
Sin embargo, en la vida real, las aplicaciones pueden requerir muchas configuraciones diferentes, conectarse a diferentes sistemas y no quisiera que mis pruebas de acceso a la base de datos caigan, porque la conexión a la cola de mensajes no está configurada. Por lo tanto, es importante usar el sentido común, y si para que la prueba con la anotación @SpringBootTest funcione, debe bloquear la mitad del sistema. ¿Tiene sentido entonces en @SpringBootTest?
Preparación de datos para la prueba.
Uno de los puntos clave para las pruebas es la preparación de datos. Cada prueba debe realizarse de forma aislada y preparar el entorno antes de comenzar, llevando el sistema a su estado original deseado. La opción más fácil para hacer esto es usar las anotaciones @BeforeEach / @BeforeAll y agregar entradas a la base de datos allí usando el repositorio, EntityManager o TestEntityManager . Pero hay otra opción que le permite ejecutar un script preparado o ejecutar la consulta SQL deseada, esta es la anotación @Sql . Antes de ejecutar la prueba, Spring Boot Test ejecutará automáticamente el script especificado, eliminando la necesidad de agregar el bloque @BeforeAll , y @Transactional se encargará de la @Transactional de los datos.
@DataJpaTest class JpaCakeFinderTest { private static final String PROMOTED_CAKE = "Red Velvet"; private static final String NON_PROMOTED_CAKE = "Victoria Sponge"; private CakeFinder finder; @Autowired CakeRepository cakeRepository; @Autowired TestEntityManager testEntityManager; @BeforeEach void setUp() { this.testEntityManager.persistAndFlush(CakeEntity.builder().title(PROMOTED_CAKE) .sku("SKU1").price(BigDecimal.TEN).promoted(true).build()); this.testEntityManager.persistAndFlush(CakeEntity.builder().sku("SKU2") .title(NON_PROMOTED_CAKE).price(BigDecimal.ONE).promoted(false).build()); finder = new JpaCakeFinder(cakeRepository); } ... }
Ciclo refactor rojo-verde
A pesar de esta cantidad de texto, para el desarrollador, la prueba todavía parece una clase simple con la anotación @DataJpaTest, pero espero poder mostrar cuántas cosas útiles están sucediendo bajo el capó, que el desarrollador no puede pensar. Ahora podemos pasar al ciclo TDD y esta vez mostraré un par de iteraciones TDD, con ejemplos de refactorización y código mínimo. Para que quede más claro, le recomiendo que mire el historial en Git, donde cada confirmación es un paso separado y significativo con una descripción de qué y cómo lo hace.
Preparación de datos
Utilizo el enfoque con @BeforeAll / @BeforeEach y @BeforeEach manualmente todos los registros en la base de datos. El ejemplo con la anotación @Sql se mueve a una clase separada JpaCakeFinderTestWithScriptSetup , duplica las pruebas, que, por supuesto, no deberían existir, y existe con el único propósito de demostrar el enfoque.
El estado inicial del sistema: hay dos entradas en el sistema, una torta participa en la promoción y debe incluirse en el resultado devuelto por el método, la segunda, no.
Primera prueba de prueba de integración
La primera prueba es la más simple: findPromotedCakes debe incluir una descripción y el precio del pastel que participa en la promoción.
Rojo
@Test void shouldReturnPromotedCakes() { Iterable<Cake> promotedCakes = finder.findPromotedCakes(); assertThat(promotedCakes).extracting(Cake::getTitle).contains(PROMOTED_CAKE); assertThat(promotedCakes).extracting(Cake::getPrice).contains("£10.00"); }
La prueba, por supuesto, se bloquea: la implementación predeterminada devuelve un conjunto vacío.
Verde
Naturalmente, nos gustaría escribir inmediatamente el filtrado, hacer una solicitud a la base de datos con where y así sucesivamente. Pero siguiendo la práctica de TDD, tengo que escribir el código mínimo para que la prueba pase . Y este código mínimo es devolver todos los registros en la base de datos. Sí, tan simple y cursi.
public Set<Cake> findPromotedCakes() { Spliterator<CakeEntity> cakes = this.cakeRepository.findAll() .spliterator(); return StreamSupport.stream(cakes, false).map( cakeEntity -> new Cake(cakeEntity.title, formatPrice(cakeEntity.price))) .collect(Collectors.toSet()); } private String formatPrice(BigDecimal price) { return "£" + price.setScale(2, RoundingMode.DOWN).toPlainString(); }
Probablemente algunos argumentarán que aquí puede hacer que la prueba sea verde incluso sin una base, simplemente codifique el resultado esperado por la prueba. Ocasionalmente escucho tal argumento, pero creo que todos entienden que TDD no es un dogma o una religión, no tiene sentido llevar esto al punto del absurdo. Pero si realmente lo desea, puede, por ejemplo, aleatorizar los datos de la instalación para que no estén codificados.
Refactor
No veo mucha refactorización aquí, por lo que esta fase se puede omitir para esta prueba en particular. Pero todavía no recomendaría ignorar esta fase, es mejor detenerse y pensar cada vez en el estado "verde" del sistema: ¿es posible refactorizar algo para hacerlo mejor y más fácil?
Segunda prueba
Pero la segunda prueba ya verificará que ningún pastel promocionado caerá en el resultado devuelto por findPromotedCakes .
@Test void shouldNotReturnNonPromotedCakes() { Iterable<Cake> promotedCakes = finder.findPromotedCakes(); assertThat(promotedCakes).extracting(Cake::getTitle) .doesNotContain(NON_PROMOTED_CAKE); }
Rojo
La prueba, como se esperaba, falla: hay dos registros en la base de datos y el código simplemente los devuelve a todos.
Verde
Y de nuevo puedes pensar, ¿y cuál es el código mínimo que puedes escribir para pasar la prueba? Como ya hay una secuencia y su ensamblaje, simplemente puede agregar un bloque de filter allí.
public Set<Cake> findPromotedCakes() { Spliterator<CakeEntity> cakes = this.cakeRepository.findAll() .spliterator(); return StreamSupport.stream(cakes, false) .filter(cakeEntity -> cakeEntity.promoted) .map(cakeEntity -> new Cake(cakeEntity.title, formatPrice(cakeEntity.price))) .collect(Collectors.toSet()); }
Reiniciamos las pruebas: las pruebas de integración ahora son ecológicas. Ha llegado un momento importante: debido a la combinación de la prueba de unidad del controlador y la prueba de integración para trabajar con la base de datos, mi función está lista, ¡y la prueba de IU ahora pasa!
Refactor
Y como todas las pruebas son verdes, es hora de refactorizar. Creo que no es necesario aclarar que filtrar en la memoria no es una buena idea, es mejor hacerlo en la base de datos. Para hacer esto, agregué un nuevo método en el CakesRepository : findByPromotedIsTrue :
interface CakeRepository extends CrudRepository<CakeEntity, String> { Iterable<CakeEntity> findByPromotedIsTrue(); }
Para este método, Spring Data generó automáticamente un método que ejecutará una consulta del formulario select from cakes where promoted = true . Lea más sobre la generación de consultas en la documentación de Spring Data.
public Set<Cake> findPromotedCakes() { Spliterator<CakeEntity> cakes = this.cakeRepository.findByPromotedIsTrue() .spliterator(); return StreamSupport.stream(cakes, false).map( cakeEntity -> new Cake(cakeEntity.title, formatPrice(cakeEntity.price))) .collect(Collectors.toSet()); }
Este es un buen ejemplo de la flexibilidad que proporcionan las pruebas de integración y el enfoque de caja negra. Si el repositorio estaba bloqueado, no era imposible agregar un nuevo método sin cambiar las pruebas.
Conexión a la base de producción.
Para agregar un poco de "realismo" y mostrar cómo puede separar la configuración de las pruebas y la aplicación principal, agregaré una configuración de acceso a datos para la aplicación de "producción".
Todo se agrega tradicionalmente por la sección en application.yml :
datasource: url: jdbc:h2:./data/cake-factory
Esto guardará automáticamente los datos en el sistema de archivos en la carpeta ./data . Observo que esta carpeta no se creará en las pruebas: @DataJpaTest reemplazará automáticamente la conexión a la base de datos de archivos con una base de datos aleatoria en la memoria debido a la presencia de la anotación @AutoConfigureTestDatabase .
, — data.sql schema.sql . , Spring Boot . , , , .
Conclusión
, , , TDD .
Spring Security — Spring, .