"
Empresa " - operador de telecomunicaciones PJSC "Megafon"
"
Noda " es el servidor RabbitMQ.
Un "
clúster " es una combinación, en nuestro caso de tres, de nodos RabbitMQ que funcionan como un todo.
"
Contorno ": un conjunto de clústeres RabbitMQ, cuyas reglas para trabajar se determinan en el equilibrador frente a ellos.
"
Balanceador ", "
hap " - Haproxy - equilibrador que realiza la función de conmutar la carga en grupos dentro del bucle. Se utilizan un par de servidores Haproxy que se ejecutan en paralelo para cada bucle.
"
Subsistema ": el editor y / o consumidor de los mensajes transmitidos a través del conejo
"
SISTEMA ": un conjunto de subsistemas, que es una solución única de software y hardware utilizada por la empresa, caracterizada por la distribución en toda Rusia, pero con varios centros donde fluye toda la información y donde tienen lugar los principales cálculos y cálculos.
SYSTEM - un sistema distribuido geográficamente - desde Khabarovsk y Vladivostok hasta San Petersburgo y Krasnodar. Arquitectónicamente, estos son varios contornos centrales, divididos por las características de los subsistemas conectados a ellos.
¿Cuál es la tarea del transporte en las realidades de las telecomunicaciones?
En pocas palabras: sigue la respuesta de los subsistemas a la acción de cada suscriptor, que a su vez informa a los otros subsistemas sobre eventos y cambios posteriores. Los mensajes son generados por cualquier acción con el SISTEMA, no solo de los suscriptores, sino también del lado de los empleados de la Compañía y de los Subsistemas (una gran cantidad de tareas se realizan automáticamente).
Características del transporte en telecomunicaciones: flujo grande, no incorrecto, GRANDE de datos diversos transmitidos a través del transporte asíncrono.
Algunos subsistemas viven en clústeres separados debido a la gran cantidad de flujos de mensajes: simplemente no quedan recursos en el clúster, por ejemplo, con un flujo de mensajes de 5-6 mil mensajes / segundo, la cantidad de datos transferidos puede alcanzar 170-190 megabytes / segundo. Con tal perfil de carga, un intento de aterrizar a cualquier otra persona en este clúster tendrá consecuencias tristes: dado que no hay suficientes recursos para procesar todos los datos al mismo tiempo, el conejo comenzará a impulsar las conexiones entrantes en
flujo ; comenzará un proceso de publicación simple, con todas las consecuencias para todos los subsistemas y sistemas en todo
Requisitos básicos para el transporte:
- La accesibilidad de los vehículos debe ser del 99,99%. En la práctica, esto se traduce en un requisito operativo 24/7 y la capacidad de responder automáticamente a cualquier situación de emergencia.
- Seguridad de los datos: el porcentaje de mensajes perdidos en el transporte debe tender a 0.
Por ejemplo, al hacer una llamada, varios mensajes diferentes vuelan a través del transporte asíncrono. algunos mensajes están destinados a subsistemas que viven en el mismo circuito, y otros están destinados a la transmisión a nodos centrales. Varios subsistemas pueden reclamar el mismo mensaje, por lo tanto, en la etapa de publicación del mensaje en el conejo, se copia y se envía a diferentes consumidores. Y en algunos casos, la copia de mensajes se implementa obligatoriamente en un circuito intermedio, cuando la información debe entregarse desde el circuito de Khabarovsk al circuito de Krasnodar. La transmisión se realiza a través de uno de los Contornos centrales, donde se realizan copias de los mensajes, para los destinatarios centrales.
Además de los eventos causados por las acciones del suscriptor, los mensajes de servicio que intercambian los subsistemas pasan por el transporte. Por lo tanto, se obtienen varios miles de rutas de mensajería diferentes, algunas se cruzan, algunas existen de forma aislada. Es suficiente nombrar el número de colas involucradas en las rutas en diferentes contornos para comprender la escala aproximada del mapa de transporte: en los circuitos centrales 600, 200, 260, 15 ... y en los circuitos remotos 80-100 ...
Con tal implicación del transporte, los requisitos para el 100% de accesibilidad de todos los nodos de transporte ya no parecen excesivos. Estamos avanzando hacia la implementación de estos requisitos.
Cómo resolvemos tareas
Además del
propio RabbitMQ ,
Haproxy se usa para equilibrar la carga y proporcionar una respuesta automática a emergencias.
Algunas palabras sobre el entorno de hardware y software en el que existen nuestros conejos:
- Todos los servidores de conejo son virtuales, con parámetros de 8-12 CPU, 16 Gb Mem, 200 Gb HDD. Como ha demostrado la experiencia, incluso el uso de servidores no virtuales espeluznantes con 90 núcleos y un montón de RAM proporciona un pequeño aumento de rendimiento a costos significativamente más altos. Versiones utilizadas: 3.6.6 (en la práctica, la más estable de 3.6) con un erlang de 18.3, 3.7.6 con un erlang de 20.1.
- Para Haproxy, los requisitos son mucho menores: 2 CPU, 4 Gb Mem, la versión haproxy es 1.8 estable. La carga de recursos en todos los servidores haproxy no supera el 15% de CPU / Mem.
- Todo el zoológico está ubicado en 14 centros de datos en 7 sitios en todo el país, unidos en una sola red. En cada uno de los centros de datos hay un grupo de tres nodos y un concentrador.
- Para los circuitos remotos, se utilizan 2 centros de datos, para cada uno de los circuitos centrales: 4.
- Los circuitos centrales interactúan entre sí, así como con los circuitos remotos; a su vez, los circuitos remotos funcionan solo con los circuitos centrales; no tienen comunicación directa entre ellos.
- Las configuraciones de Haps y Clusters dentro del mismo circuito son completamente idénticas. El punto de entrada para cada circuito es un alias para múltiples registros A-DNS. Por lo tanto, para evitar que esto suceda, al menos un hap y al menos uno de los Clusters (al menos un nodo en el Cluster) estarán disponibles en cada Circuito. Dado que el caso de falla de incluso 6 servidores en dos centros de datos al mismo tiempo es extremadamente improbable, se supone que la aceptabilidad es cercana al 100%.
Parece concebido (e implementado) todo esto así:

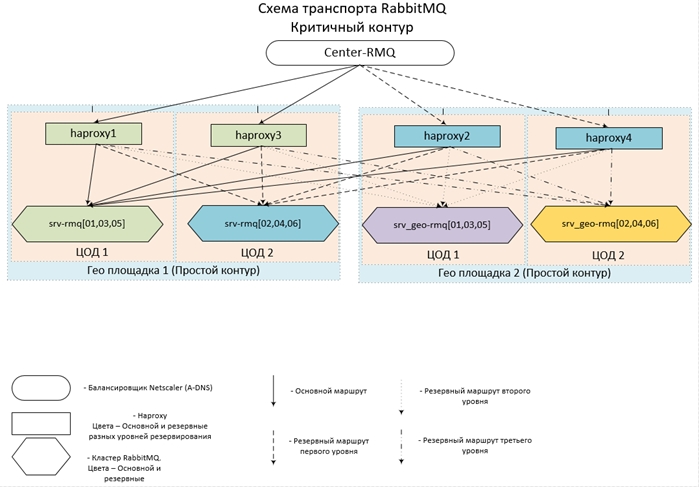
Ahora algunas configuraciones.
Configuración de Haproxy| frontend center-rmq_5672 | |
| atar | *: 5672 |
| modo | tcp |
| maxconn | 10,000 |
| cliente de tiempo de espera | 3h |
| opción | tcpka |
| opción | tcplog |
| default_backend | center-rmq_5672 |
| frontend center-rmq_5672_lvl_1 | |
| atar | localhost: 56721 |
| modo | tcp |
| maxconn | 10,000 |
| cliente de tiempo de espera | 3h |
| opción | tcpka |
| opción | tcplog |
| default_backend | center-rmq_5672_lvl_1 |
| backend center-rmq_5672 |
| balance | la menos común |
| modo | tcp |
| fullconn | 10,000 |
| tiempo de espera | servidor 3h |
| servidor | srv-rmq01 10/10/10/10/106767 verificar entre 5s subir 2 caer 3 sesiones de copia de seguridad de cierre marcadas |
| servidor | srv-rmq03 10/10/10/2011 11672 compruebe entre 5 aumentos 2 caídas 3 en sesiones de copia de seguridad de cierre marcadas |
| servidor | srv-rmq05 10/10/10/126767 verificar entre 5s subida 2 caída 3 en-marcado-apagado-apagado-copia de seguridad-sesiones |
| servidor | localhost 127.0.0.1 ∗ 6721 compruebe entre 5s subida 2 caída 3 copia de seguridad sesiones de apagado marcadas |
| backend center-rmq_5672_lvl_1 |
| balance | la menos común |
| modo | tcp |
| fullconn | 10,000 |
| tiempo de espera | servidor 3h |
| servidor | srv-rmq02 10/10/10/136767 verificar entre 5s subir 2 caer 3 en-marcado-apagado shutdown-backup-sessions |
| servidor | srv-rmq04 10/10/10/14/1067 verificar entre 5s subir 2 caer 3 en sesiones de copia de seguridad de cierre marcadas |
| servidor | srv-rmq06 10.10.10.5:0767 verificar entre 5s subida 2 caída 3 en-marcado-apagado shutdown-backup-sessions |
La primera sección del frente describe el punto de entrada, que conduce al grupo principal, la segunda sección está diseñada para equilibrar el nivel de reserva. Si simplemente describe todos los servidores secundarios de respaldo en la sección de back-end (instrucciones de respaldo), funcionará de la misma manera: si el clúster principal es completamente inaccesible, las conexiones irán al respaldo, sin embargo, todas las conexiones irán al PRIMER servidor de respaldo en la lista. Para garantizar el equilibrio de carga en todos los nodos de respaldo, solo presentamos un frente más, que ponemos a disposición solo con localhost, y le asignamos el servidor de respaldo.
El ejemplo anterior describe el equilibrio del Loop remoto, que opera dentro de dos centros de datos: el servidor srv-rmq {01,03,05} - vivo en el centro de datos n. ° 1, srv-rmq {02,04,06} - en el centro de datos n. ° 2. Por lo tanto, para implementar la solución de cuatro codas, solo necesitamos agregar dos frentes locales más y dos secciones de back-end de los servidores de conejo correspondientes.
El comportamiento del equilibrador con esta configuración es el siguiente: mientras al menos un servidor principal está vivo, lo usamos. Si los servidores principales no están disponibles, trabajamos con una reserva. Si al menos un servidor primario está disponible, todas las conexiones a los servidores de respaldo se desconectan y, cuando se restablece la conexión, ya caen en el Clúster primario.
La experiencia operativa de dicha configuración muestra casi el 100% de disponibilidad de cada uno de los circuitos. Esta solución requiere que los Subsistemas sean completamente legales y simples: poder reconectarse con el conejo después de desconectarse.
Por lo tanto, hemos proporcionado equilibrio de carga a un número arbitrario de Clusters y cambiamos automáticamente entre ellos, es hora de ir directamente a los conejos.
Cada clúster se crea a partir de tres nodos, como muestra la práctica: el número más óptimo de nodos, lo que garantiza el equilibrio óptimo de disponibilidad / tolerancia a fallas / velocidad. Dado que el conejo no se escala horizontalmente (el rendimiento del clúster es igual al rendimiento del servidor más lento), creamos todos los nodos con los mismos parámetros óptimos para CPU / Mem / Hdd. Colocamos los servidores lo más cerca posible entre sí; en nuestro caso, estamos archivando máquinas virtuales dentro de la misma granja.
En cuanto a las condiciones previas, a continuación, los Subsistemas garantizarán el funcionamiento más estable y el cumplimiento del requisito de guardar los mensajes recibidos:
- El trabajo con el conejo es solo a través del protocolo amqp / amqps, a través del equilibrio. Autorización bajo cuentas locales - dentro de cada grupo (pozo y todo el circuito)
- Los subsistemas están conectados al conejo en modo pasivo: no se permiten y limitan las manipulaciones con las entidades de los conejos (creación de colas / eschendzhey / bind) a nivel de derechos de cuenta, simplemente no otorgamos derechos de configuración.
- Todas las entidades necesarias se crean de forma centralizada, no por medio de subsistemas, y en todos los clústeres de clúster se realizan de la misma manera: para garantizar el cambio automático al clúster de respaldo y viceversa. De lo contrario, podemos obtener una imagen: cambiamos a la reserva, pero la cola o el enlace no están allí, y podemos elegir un error de conexión o pérdida de mensajes.
Ahora directamente la configuración en conejos:
- Los hosts locales no tienen acceso a la interfaz web
- El acceso a la Web se organiza a través de LDAP: nos integramos con AD y obtenemos el registro de quién y dónde visitó la cámara web. En el nivel de configuración, restringimos los derechos de las cuentas de AD, no solo exigimos estar en un determinado grupo, sino que solo otorgamos derechos para "ver". Los grupos de monitoreo son más que suficientes. Y colgamos los derechos de administrador en otro grupo en AD, por lo tanto, el círculo de influencia en el transporte es muy limitado.
- Para facilitar la administración y el seguimiento:
En todos los VHOST, colgamos inmediatamente una política de nivel 0 con aplicación a todas las colas (patrón :. *):
- ha-mode: all : almacena todos los datos en todos los nodos del clúster, la velocidad de procesamiento de los mensajes disminuye, pero su seguridad y disponibilidad están garantizadas.
- ha-sync-mode: automatic : indica al rastreador que sincronice automáticamente los datos en todos los nodos del clúster: la seguridad y la disponibilidad de los datos también aumentan.
- modo de cola: perezoso : quizás una de las opciones más útiles que ha aparecido en conejos desde la versión 3.6: grabación inmediata de mensajes en el HDD. Esta opción reduce drásticamente el consumo de RAM y aumenta la seguridad de los datos durante las paradas / caídas de los nodos o del clúster en su conjunto.
- Configuraciones en el archivo de configuración ( rabbitmq-main / conf / rabbitmq.config ):
- Sección conejo : {vm_memory_high_watermark_paging_ratio, 0.5} - umbral para descargar mensajes al disco 50%. Con perezoso activado, sirve más como seguro cuando elaboramos una póliza, por ejemplo, nivel 1, en el que nos olvidamos de incluir perezoso .
- {vm_memory_high_watermark, 0.95} : limitamos el conejo al 95% de toda la RAM, ya que solo el conejo vive en los servidores, no tiene sentido introducir restricciones más estrictas. 5% "gesto amplio", que así sea: abandone el sistema operativo, el monitoreo y otras pequeñas cosas útiles. Como este valor es el límite superior, hay suficiente para todos.
- {cluster_partition_handling, pause_minority} : describe el comportamiento del clúster cuando se produce la partición de red; para tres o más clústeres de nodos, se recomienda esta marca: permite que el clúster se recupere.
- {disk_free_limit, "500MB"} - todo es simple, cuando hay 500 MB de espacio libre en disco - la publicación de mensajes se detendrá, solo estará disponible la resta.
- {auth_backends, [rabbit_auth_backend_internal, rabbit_auth_backend_ldap]} - orden de autorización para conejos: Primero, se verifica la presencia de un ultrasonido en la base de datos local, y si no, vaya al servidor LDAP.
- Sección rabbitmq_auth_backend_ldap - configuración de interacción con AD: {servidores, ["srv_dc1", "srv_dc2"]} - una lista de controladores de dominio en los que se realizará la autenticación.
- Los parámetros que describen directamente al usuario en AD, el puerto LDAP, etc. son puramente individuales y se describen en detalle en la documentación.
- Lo más importante para nosotros es una descripción de los derechos y restricciones sobre la administración y el acceso a la interfaz web de conejos: tag_queries:
[{administrador, {en_grupo, "cn = rabbitmq-admins, ou = GRP, ou = GRP_MAIN, dc = Mi_dominio, dc = ru"}},
{monitoreo,
{in_group, "cn = rabbitmq-web, ou = GRP, ou = GRP_MAIN, dc = Mi_dominio, dc = ru"}
}] - este diseño proporciona privilegios administrativos para todos los usuarios del grupo rabbitmq-admins y derechos de monitoreo (mínimamente suficiente para ver el acceso) para el grupo rabbitmq-web.
- resource_access_query :
{para,
[{permiso, configurar, {en_grupo, "cn = rabbitmq-admins, ou = GRP, ou = GRP_MAIN, dc = Mi_dominio, dc = ru"}},
{permiso, escribir, {en_grupo, "cn = rabbitmq-admins, ou = GRP, ou = GRP_MAIN, dc = Mi_dominio, dc = ru"}},
{permiso, lectura, {constante, verdadero}}
]
} : proporcionamos los derechos para configurar y escribir solo al grupo de administradores, a todos los demás que inicien sesión correctamente, los derechos son de solo lectura: puede leer mensajes a través de la interfaz web.
Obtenemos un clúster configurado (al nivel del archivo de configuración y la configuración en el conejo) que maximiza la disponibilidad y seguridad de los datos. Con esto implementamos el requisito: garantizar la disponibilidad y seguridad de los datos ... en la mayoría de los casos.
Hay varios puntos que se deben considerar al operar sistemas tan cargados:
- Es mejor organizar todas las propiedades adicionales de las colas (TTL, caducar, longitud máxima, etc.) por parte de los políticos, en lugar de colgar parámetros al crear colas. Resulta una estructura flexiblemente personalizable que se puede personalizar sobre la marcha a las realidades cambiantes.
- Usando TTL. Cuanto más larga sea la cola, mayor será la carga en la CPU. Para evitar "romper el techo", también es mejor limitar la longitud de la cola a través de la longitud máxima.
- Además del conejo en sí, una serie de aplicaciones de utilidad están girando en el servidor, que, curiosamente, también requieren recursos de CPU. Un conejo glotón, por defecto, ocupa todos los granos disponibles ... Una situación desagradable puede resultar: una lucha por los recursos, que fácilmente puede conducir a frenos en el conejo. Para evitar la ocurrencia de tal situación, por ejemplo, de la siguiente manera: Cambie los parámetros del lanzamiento del erlang: introduzca un límite obligatorio en el número de núcleos utilizados. Hacemos esto de la siguiente manera: busque el archivo rabbitmq-env , busque el parámetro SERVER_ERL_ARGS = y agregue + sct L0-Xc0-X + SY: Y. Donde X es el número de núcleos-1 (el conteo comienza desde 0), Y - El número de núcleos -1 (el conteo es de 1). + sct L0-Xc0-X - cambia el enlace a los núcleos, + SY: Y - cambia el número de shedulers lanzados por el erlang. Entonces, para un sistema de 8 núcleos, los parámetros agregados tomarán la forma: + sct L0-6c0-6 + S 7: 7. De esta manera, le damos al conejo solo 7 núcleos y esperamos que el sistema operativo, al iniciar otros procesos, actúe de manera óptima y los cuelgue en un núcleo descargado.
Los matices de operar el zoológico resultante
De lo que ningún entorno puede protegerse es de la base colapsada de mnesia; desafortunadamente, ocurre con una probabilidad distinta de cero. Un resultado tan desastroso no es causado por fallas globales (por ejemplo, una falla completa de un centro de datos completo, la carga simplemente cambiará a otro clúster), sino más fallas locales, dentro del mismo segmento de red.
Además, son las fallas de la red local las que dan miedo, porque el apagado de emergencia de uno o dos nodos no tendrá consecuencias fatales, simplemente todas las solicitudes irán a un solo nodo y, como recordamos, el rendimiento depende del rendimiento del nodo solo. Las fallas en la red (no tenemos en cuenta las pequeñas interrupciones en la comunicación, se experimentan sin problemas) conducen a una situación en la que los nodos comienzan el proceso de sincronización entre ellos y luego la conexión se rompe una y otra vez durante unos segundos.
Por ejemplo, el parpadeo múltiple de la red y con una frecuencia de más de 5 segundos (solo se establece un tiempo de espera tal en la configuración de Hapov, ciertamente puede reproducirlos, pero para verificar la efectividad deberá repetir la falla, que nadie quiere).
El clúster aún puede soportar una o dos iteraciones de este tipo, pero más: las posibilidades ya son mínimas. En tal situación, una parada de un nodo caído puede guardar, pero es casi imposible hacerlo manualmente. Más a menudo, el resultado no es solo la pérdida de un nodo del clúster con el mensaje
"Partición de red" , sino también la imagen cuando los datos por parte de las colas vivieron solo en este nodo y no tuvieron tiempo de sincronizarse con los restantes. Visualmente: en la cola, los datos son
NaN .
Y ahora esta es una señal inequívoca: cambie al clúster de respaldo. El cambio proporcionará una suerte, solo necesita detener a los conejos en el grupo principal, una cuestión de varios minutos. Como resultado, obtenemos la restauración de la capacidad de trabajo del transporte y podemos proceder con seguridad al análisis del accidente y su eliminación.
Para eliminar un racimo dañado debajo de la carga, para evitar una mayor degradación, lo más simple es hacer que el conejo funcione en puertos que no sean 5672. Dado que estamos monitoreando a los conejos por el puerto regular, su desplazamiento, por ejemplo, por 5673 en la configuración del conejo, le permitirá iniciar completamente el clúster sin problemas e intentar restaurar su operatividad y los mensajes restantes en él.
Lo hacemos en unos pocos pasos:
- Detenga todos los nodos del clúster fallido: el hap cambiará la carga al clúster de respaldo
- RABBITMQ_NODE_PORT=5673 rabbitmq-env – , Web - 15672.
- .
Al inicio, los índices se reconstruirán y, en la gran mayoría de los casos, todos los datos se restaurarán por completo. Desafortunadamente, se producen bloqueos como resultado de los cuales debe eliminar físicamente todos los mensajes del disco, dejando solo la configuración: los directorios msg_store_persistent , msg_store_transient , colas (para la versión 3.6) o msg_stores (para la versión 3.7) se eliminan en la carpeta con la base de datos .Después de una terapia tan radical, el grupo se inicia con la preservación de la estructura interna, pero sin mensajes.Y la opción más desagradable (observada solo una vez): el daño a la base fue tal que fue necesario eliminar por completo toda la base y reconstruir el grupo desde cero.Para la conveniencia de administrar y actualizar conejos, no se usa un ensamblaje listo para usar en rpm, sino un conejo desmontado usando cpio y reconfigurado (cambió las rutas en los scripts). La principal diferencia: no requiere privilegios de root para instalar / configurar, no está instalado en el sistema (el conejo reconstruido está perfectamente empaquetado en tgz) y se ejecuta desde cualquier usuario. Este enfoque le permite actualizar de manera flexible las versiones (si no requiere una parada completa del clúster; en este caso, simplemente cambie al clúster de respaldo y actualice, sin olvidar especificar el puerto desplazado para la operación). Incluso es posible ejecutar varias instancias de RabbitMQ en la misma máquina; para probar la opción es muy conveniente, puede implementar una copia arquitectónica reducida del zoológico de batalla.Como resultado del chamanismo con cpio y caminos en los scripts, tenemos una opción de compilación: dos carpetas de base de conejo (en el ensamblaje original - la carpeta mnesia) y rabbimq-main - aquí pongo todos los scripts necesarios del conejo y el propio erlang.En rabbimq-main / bin - enlaces simbólicos a scripts de conejo y erlang y un script de seguimiento de conejo (descripción a continuación).En rabbimq-main / init.d: la secuencia de comandos rabbitmq-server a través de la cual los registros comienzan / detienen / giran; en lib, el conejo mismo; en lib64 - erlang (usando una versión simplificada del erlang solo para conejo)Es extremadamente fácil actualizar el ensamblaje resultante cuando se lanzan nuevas versiones: agregue el contenido de rabbimq-main / lib y rabbimq-main / lib64 de las nuevas versiones y reemplace los enlaces simbólicos en bin. Si la actualización también afecta los scripts de control, simplemente cambie las rutas a la nuestra en ellos.Una ventaja significativa de este enfoque es la continuidad completa de las versiones: todas las rutas, scripts, comandos de control permanecen sin cambios, lo que le permite usar cualquier script de utilidad auto-escrito sin dopaje para cada versión.Desde la caída de los conejos, aunque rara, pero ocurriendo, fue necesario implementar un mecanismo para monitorear su salud en caso de una caída (manteniendo los registros de las razones de la caída). La falla de un nodo en el 99% de los casos va acompañada de una entrada de registro, incluso matar incluso deja rastros, esto permitió implementar el monitoreo del estado del conejo usando un script simple.Para las versiones 3.6 y 3.7, el script es ligeramente diferente debido a las diferencias en las entradas de registro.Para 3.7, solo se cambian dos líneas if (os.path.isfile('/data/logs/rabbitmq/startup_log')) and (os.path.isfile('/data/logs/rabbitmq/startup_err')): if ((b' OK ' in LastRow('/data/logs/rabbitmq/startup_log')) or (b'FAILED' in LastRow('/data/logs/rabbitmq/startup_log'))) and not (b'Gracefully halting Erlang VM' in LastRow('/data/logs/rabbitmq/startup_err')):
Configuramos una cuenta de crontab en la que el conejo funcionará (de forma predeterminada, rabbitmq) ejecutando este script (nombre del script: check_and_run) cada minuto (primero, le pedimos al administrador que otorgue a la cuenta el derecho de usar crontab, pero si tenemos derechos de root, lo hacemos nosotros mismos):
* / 1 * * * * ~ / rabbitmq-main / bin / check_and_runEl segundo punto de usar el conejo reensamblado es la rotación de los registros.
Dado que no estamos vinculados al sistema logrotate, utilizamos la funcionalidad proporcionada por el desarrollador: el
script rabbitmq-server de init.d (para la versión 3.6)
Al hacer pequeños cambios a
rotate_logs_rabbitmq ()Añadir:
find ${RABBITMQ_LOG_BASE}/http_api/*.log.* -maxdepth 0 -type f ! -name "*.gz" | xargs -i gzip --force {} find ${RABBITMQ_LOG_BASE}/*.log.*.back -maxdepth 0 -type f | xargs -i gzip {} find ${RABBITMQ_LOG_BASE}/*.gz -type f -mtime +30 -delete find ${RABBITMQ_LOG_BASE}/http_api/*.gz -type f -mtime +30 -delete
El resultado de ejecutar el script rabbitmq-server con la clave rotate-logs: los registros están comprimidos por gzip y se almacenan solo durante los últimos 30 días.
http_api : la ruta donde el conejo coloca los registros http: configurados en el archivo de configuración:
{rabbitmq_management, [{rates_mode, detallado}, {http_log_dir, path_to_logs / http_api "}]}Al mismo tiempo, estoy prestando atención a
{rates_mode, detallado } : la opción aumenta ligeramente la carga, pero le permite ver información sobre el usuario que publica mensajes en el INTERCAMBIO en la interfaz WEB (y, en consecuencia, atraviesa la API). La información es extremadamente necesaria, porque todas las conexiones pasan por el equilibrador; solo veremos la IP de los equilibradores mismos. Y si desconcierta todos los Subsistemas que trabajan con el conejo para que completen los parámetros de propiedades del Cliente en las propiedades de sus conexiones con los conejos, entonces será posible obtener información detallada en el nivel de conexión quién exactamente, dónde y con qué intensidad publica los mensajes.
Con el lanzamiento de las nuevas versiones 3.7, hubo un rechazo completo del script
rabbimq-server en init.d. Para facilitar la operación (la uniformidad de los comandos de control independientemente de la versión del conejo) y una transición más suave entre las versiones, en el conejo reensamblado continuamos usando este script. La verdad es otra vez:
cambiaremos un poco
rotate_logs_rabbitmq () , ya que el mecanismo para nombrar registros después de la rotación ha cambiado en 3.7:
mv ${RABBITMQ_LOG_BASE}/$NODENAME.log.0 ${RABBITMQ_LOG_BASE}/$NODENAME.log.$(date +%Y%m%d-%H%M%S).back mv ${RABBITMQ_LOG_BASE}/$(echo $NODENAME)_upgrade.log.0 ${RABBITMQ_LOG_BASE}/$(echo $NODENAME)_upgrade.log.$(date +%Y%m%d-%H%M%S).back find ${RABBITMQ_LOG_BASE}/http_api/*.log.* -maxdepth 0 -type f ! -name "*.gz" | xargs -i gzip --force {} find ${RABBITMQ_LOG_BASE}/*.log.* -maxdepth 0 -type f ! -name "*.gz" | xargs -i gzip --force {} find ${RABBITMQ_LOG_BASE}/*.gz -type f -mtime +30 -delete find ${RABBITMQ_LOG_BASE}/http_api/*.gz -type f -mtime +30 -delete
Ahora solo queda agregar la tarea de rotación de registros a crontab, por ejemplo, todos los días a las 23-00:
00 23 * * * ~ / rabbitmq-main / init.d / rabbitmq-server rotate-logsPasemos a las tareas que deben resolverse en el marco de la operación de la "granja de conejos":
- Manipulaciones con entidades de conejo: creación / eliminación de entidades de conejo: ekschendzhey, colas, enlaces, palas, usuarios, políticas. Y hacer esto es absolutamente idéntico en todos los Cluster Clusters.
- Después de cambiar a / desde el Clúster de respaldo, es necesario transferir los mensajes que permanecieron en él al Clúster actual.
- Crear copias de seguridad de las configuraciones de todos los Clusters de todos los Circuitos
- Sincronización completa de configuraciones de clúster dentro del contorno
- Detener / iniciar conejos
- Para analizar los flujos de datos actuales: todos los mensajes van y, si van, a dónde deberían ir o ...
- Encuentre y atrape los mensajes que pasan por cualquier criterio
La operación de nuestro zoológico y la solución de tareas sonoras a través del plug-in regular
rabbitmq_management suministrado es posible, pero extremadamente inconveniente, por lo que se desarrolló e implementó un caparazón para
controlar toda la variedad de conejos .