En este tutorial, le mostraré cómo escribir su propia máquina virtual (VM) que puede ejecutar programas ensambladores como
2048 (mi amigo) o
Roguelike (el mío). Si sabe programar, pero quiere comprender mejor lo que sucede dentro de la computadora y cómo funcionan los lenguajes de programación, entonces este proyecto es para usted. Escribir su propia máquina virtual puede parecer un poco aterrador, pero prometo que el tema es sorprendentemente simple e instructivo.
El código final es de aproximadamente 250 líneas en C. Es suficiente conocer solo los conceptos básicos de C o C ++, como la
aritmética binaria . Cualquier sistema Unix (incluido macOS) es adecuado para compilar y ejecutar. Se utilizan varias API de Unix para configurar la entrada y la pantalla de la consola, pero no son esenciales para el código principal. (Se agradece la implementación del soporte de Windows).
Nota: esta VM es un programa competente . Es decir, ¡ya estás leyendo su código fuente ahora mismo! Cada parte del código se mostrará y explicará en detalle, para que pueda estar seguro de que no falta nada. El código final se crea mediante bloques de código de plexión . Repositorio del proyecto aquí .
1. Contenidos
- Tabla de contenidos
- Introduccion
- Arquitectura LC-3
- Ejemplos de ensamblador
- Ejecución del programa
- Implementación de instrucciones
- Instrucciones Cheat Sheet
- Procedimientos de procesamiento de interrupción
- Hoja de trucos para rutinas de interrupción
- Descargar software
- Registros mapeados de memoria
- Características de la plataforma
- Inicio de máquina virtual
- Método alternativo en C ++
2. Introducción
¿Qué es una máquina virtual?
Una máquina virtual es un programa que actúa como una computadora. Simula un procesador con varios otros componentes de hardware, lo que le permite realizar operaciones aritméticas, leer y escribir en la memoria e interactuar con dispositivos de entrada / salida como una computadora física real. Lo más importante es que VM entiende un lenguaje de máquina que puede usar para programar.
La cantidad de hardware que simula una VM en particular depende de su propósito. Algunas máquinas virtuales reproducen el comportamiento de una computadora en particular. La gente ya no tiene NES, pero aún podemos jugar juegos para NES simulando hardware a nivel de software. Estos emuladores deben
recrear con precisión cada
detalle y cada componente de hardware principal del dispositivo original.
¡Otras máquinas virtuales no corresponden a ninguna computadora en particular, sino que corresponden parcialmente a varias a la vez! Esto se hace principalmente para facilitar el desarrollo de software. Imagine que desea crear un programa que se ejecute en múltiples arquitecturas de computadora. La máquina virtual proporciona una plataforma estándar que proporciona portabilidad. No es necesario reescribir el programa en diferentes dialectos de ensamblador para cada arquitectura. Es suficiente hacer solo una pequeña VM en cada idioma. Después de eso, cualquier programa puede escribirse solo una vez en el lenguaje ensamblador de una máquina virtual.
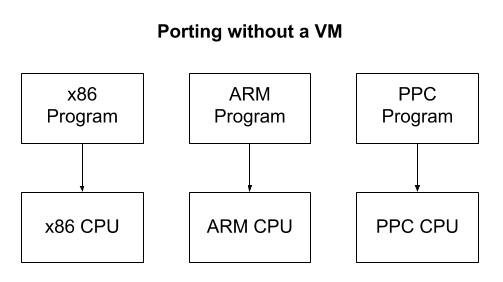

Nota: el compilador resuelve tales problemas compilando un lenguaje estándar de alto nivel para diferentes arquitecturas de procesador. VM crea una arquitectura de CPU estándar que se simula en varios dispositivos de hardware. Una de las ventajas del compilador es que no hay sobrecarga en tiempo de ejecución como lo hace VM. Aunque los compiladores funcionan bien, escribir un nuevo compilador para múltiples plataformas es muy difícil, por lo que las máquinas virtuales siguen siendo útiles. En realidad, a diferentes niveles, tanto VM como compiladores se usan juntos.
La máquina virtual Java (JVM) es un ejemplo muy exitoso. El JVM en sí es de tamaño relativamente mediano; es lo suficientemente pequeño como para que un programador lo entienda. Esto le permite escribir código para miles de dispositivos diferentes, incluidos los teléfonos. Después de implementar la JVM en el nuevo dispositivo, cualquier programa escrito de Java, Kotlin o Clojure puede trabajar en él sin cambios. Los únicos costos serán solo los gastos generales de la propia máquina virtual y una
mayor abstracción del nivel de la máquina. Esto suele ser un compromiso bastante bueno.
Una VM no tiene que ser grande ni ubicua para proporcionar beneficios similares. Los
videojuegos más antiguos a menudo usaban máquinas virtuales pequeñas para crear
sistemas de secuencias de comandos simples.
Las máquinas virtuales también son útiles para aislar programas de forma segura. Una aplicación es la recolección de basura.
No hay una forma trivial de implementar la recolección de basura automática sobre C o C ++, ya que el programa no puede ver su propia pila o variables. Sin embargo, la VM está "fuera" del programa en ejecución y puede observar todas las
referencias a las celdas de memoria en la pila.
Otro ejemplo de este comportamiento lo demuestran
los contratos inteligentes de Ethereum . Los contratos inteligentes son pequeños programas que son ejecutados por cada nodo de validación en la cadena de bloques. Es decir, los operadores permiten la ejecución en sus máquinas de cualquier programa escrito por desconocidos, sin ninguna oportunidad de estudiarlos con anticipación. Para evitar acciones maliciosas, se realizan en una
máquina virtual que no tiene acceso al sistema de archivos, red, disco, etc. Ethereum también es un buen ejemplo de portabilidad. Gracias a VM, puede escribir contratos inteligentes sin tener en cuenta las características de muchas plataformas.
3. Arquitectura LC-3
Nuestra VM simulará una computadora ficticia llamada
LC-3 . Es popular para enseñar a los estudiantes ensamblador. Aquí, un conjunto simplificado de comandos en
comparación con x86 , pero conserva todos los conceptos básicos que se utilizan en las CPU modernas.
Primero, debe simular los componentes de hardware necesarios. Intente comprender qué es cada componente, pero no se preocupe si no está seguro de cómo encaja en el panorama general. Comencemos creando un archivo en C. Cada fragmento de código de esta sección debe colocarse en el alcance global de este archivo.
El recuerdo
El LC-3 tiene 65.536 celdas de memoria (2
16 ), cada una de las cuales contiene un valor de 16 bits. Esto significa que solo puede almacenar 128 KB, ¡mucho menos de lo que está acostumbrado! En nuestro programa, esta memoria se almacena en una matriz simple:
uint16_t memory[UINT16_MAX];
Registros
Un registro es una ranura para almacenar un valor en la CPU. Los registros son como un "banco de trabajo" de la CPU. Para que pueda funcionar con algún dato, debe estar en uno de los registros. Pero dado que solo hay unos pocos registros, solo se puede descargar una cantidad mínima de datos en un momento dado. Los programas solucionan este problema cargando valores de la memoria en registros, calculando valores en otros registros y luego almacenando los resultados finales en la memoria.
Solo hay 10 registros en el LC-3, cada uno con 16 bits. La mayoría de ellos son de propósito general, pero algunos tienen roles asignados.
- 8 registros de uso general (
R0-R7 ) - 1 registro del mostrador de equipos (
PC ) - 1 registro de bandera de condición (
COND )
Los registros de propósito general se pueden usar para realizar cualquier cálculo de software. El contador de instrucciones es un entero sin signo que es la dirección de memoria de la siguiente instrucción a ejecutar. Las banderas de condición nos dicen información sobre el cálculo anterior.
enum { R_R0 = 0, R_R1, R_R2, R_R3, R_R4, R_R5, R_R6, R_R7, R_PC, R_COND, R_COUNT };
Al igual que la memoria, almacenaremos los registros en una matriz:
uint16_t reg[R_COUNT];
Conjunto de instrucciones
Una instrucción es un comando que le dice al procesador que realice algún tipo de tarea fundamental, por ejemplo, sumar dos números. La instrucción tiene un
código de operación (código de operación) que indica el tipo de tarea que se realiza, así como un conjunto de
parámetros que proporcionan información para la tarea que se realiza.
Cada
código de operación representa una tarea que el procesador "sabe" cómo realizar. Hay 16 códigos de operación en LC-3. Una computadora solo puede calcular la secuencia de estas sencillas instrucciones. La longitud de cada instrucción es de 16 bits, y los 4 bits de la izquierda almacenan el código de operación. El resto se usa para almacenar parámetros.
Más adelante discutiremos en detalle lo que hace cada instrucción. Defina los siguientes códigos de operación en este momento. Asegúrese de mantener este orden para obtener el valor de enumeración correcto:
enum { OP_BR = 0, OP_ADD, OP_LD, OP_ST, OP_JSR, OP_AND, OP_LDR, OP_STR, OP_RTI, OP_NOT, OP_LDI, OP_STI, OP_JMP, OP_RES, OP_LEA, OP_TRAP };
Nota: La arquitectura Intel x86 tiene cientos de instrucciones, mientras que otras arquitecturas como ARM y LC-3 son muy pocas. Los conjuntos de instrucciones pequeños se denominan RISC , mientras que los más grandes se denominan CISC . Los conjuntos de instrucciones grandes, por regla general, no proporcionan características fundamentalmente nuevas, pero a menudo simplifican la escritura del código de ensamblador . Una instrucción CISC puede reemplazar varias instrucciones RISC. Sin embargo, los procesadores CISC son más complejos y costosos de diseñar y fabricar. Esta y otras compensaciones no permiten llamar al diseño "óptimo" .
Banderas de condición
El registro
R_COND almacena indicadores de condición que proporcionan información sobre el último cálculo realizado. Esto permite que los programas verifiquen las condiciones lógicas, como
if (x > 0) { ... } .
Cada procesador tiene muchos indicadores de estado para indicar diversas situaciones. El LC-3 usa solo tres indicadores de condición que muestran el signo del cálculo anterior.
enum { FL_POS = 1 << 0, FL_ZRO = 1 << 1, FL_NEG = 1 << 2, };
Nota: (El carácter << se llama operador de desplazamiento a la izquierda . (n << k) desplaza los bits n izquierda por k lugares. Por lo tanto, 1 << 2 es igual a 4 Lea aquí si no está familiarizado con el concepto. Esto será muy importante).
¡Hemos terminado de configurar los componentes de hardware de nuestra máquina virtual! Después de agregar inclusiones estándar (ver el enlace de arriba), su archivo debería verse así:
{Includes, 12} {Registers, 3} {Opcodes, 3} {Condition Flags, 3}
Aquí hay enlaces a secciones numeradas del artículo, de donde provienen los fragmentos de código correspondientes. Para una lista completa, vea el programa de trabajo - aprox. trans.4. Ejemplos de ensamblador
Ahora, echemos un vistazo al programa ensamblador LC-3 para tener una idea de lo que realmente hace la máquina virtual. No necesita saber cómo programar en ensamblador, ni entender todo aquí. Solo trata de tener una idea general de lo que está sucediendo. Aquí hay un simple "Hola Mundo":
.ORIG x3000 ; this is the address in memory where the program will be loaded LEA R0, HELLO_STR ; load the address of the HELLO_STR string into R0 PUTs ; output the string pointed to by R0 to the console HALT ; halt the program HELLO_STR .STRINGZ "Hello World!" ; store this string here in the program .END ; mark the end of the file
Como en C, el programa ejecuta una declaración de arriba a abajo. Pero a diferencia de C, no hay áreas anidadas
{} o estructuras de control como
if o
while ; solo una simple lista de operadores. Por lo tanto, es mucho más fácil de realizar.
Tenga en cuenta que los nombres de algunos operadores corresponden a los códigos de operación que definimos anteriormente. Sabemos que las instrucciones son de 16 bits, pero cada línea parece tener un número diferente de caracteres. ¿Cómo es posible tal desajuste?
Esto se debe a que el código que estamos leyendo está escrito en
lenguaje ensamblador , en texto plano, legible y de escritura. Una herramienta, llamada
ensamblador , convierte cada línea de texto en una instrucción binaria de 16 bits que comprende una máquina virtual. Esta forma binaria, que es esencialmente una matriz de instrucciones de 16 bits, se llama
código de máquina y en realidad es ejecutada por una máquina virtual.
Nota: aunque el compilador y el ensamblador juegan un papel similar en el desarrollo, no son lo mismo. El ensamblador simplemente codifica lo que el programador escribió en el texto, reemplazando los caracteres con su representación binaria y empaquetándolos en instrucciones.
Los
.STRINGZ .ORIG y
.STRINGZ parecen instrucciones, pero no. Estas son directivas de ensamblador que generan parte del código o datos. Por ejemplo,
.STRINGZ inserta una cadena de caracteres en una ubicación específica en un programa binario.
Los bucles y las condiciones se ejecutan utilizando una instrucción tipo goto. Aquí hay otro ejemplo que cuenta hasta 10.
AND R0, R0, 0 ; clear R0 LOOP ; label at the top of our loop ADD R0, R0, 1 ; add 1 to R0 and store back in R0 ADD R1, R0, -10 ; subtract 10 from R0 and store back in R1 BRn LOOP ; go back to LOOP if the result was negative ... ; R0 is now 10!
Nota: este tutorial no tiene que aprender el ensamblaje. Pero si está interesado, puede escribir y construir sus propios programas LC-3 utilizando las Herramientas LC-3 .
5. Ejecución del programa
Una vez más, los ejemplos anteriores solo dan una idea de lo que hace la VM. Para escribir una VM, no necesita una comprensión completa del ensamblador. Siempre que siga el procedimiento apropiado para leer y ejecutar instrucciones,
cualquier programa LC-3 funcionará correctamente, independientemente de su complejidad. En teoría, ¡una VM incluso puede ejecutar un navegador o un sistema operativo como Linux!
Si piensas profundamente, entonces esta es una idea filosóficamente maravillosa. Los programas mismos pueden producir acciones arbitrariamente complejas que nunca esperamos y que tal vez no podamos entender. Pero al mismo tiempo, toda su funcionalidad está limitada a un código simple, que escribiremos. Al mismo tiempo, sabemos todo y nada sobre cómo funciona cada programa. Turing mencionó esta maravillosa idea:
“La opinión de que las máquinas no pueden sorprender a una persona con nada se basa, creo, en un error, al que los matemáticos y filósofos son particularmente propensos. Me refiero a la suposición de que, dado que algún hecho se ha convertido en propiedad de la mente, inmediatamente todas las consecuencias de este hecho se convertirán en propiedad de la mente ". - Alan M. Turing
Procedimiento
Aquí está la descripción exacta del procedimiento para escribir:
- Descargue una instrucción de la memoria en la dirección del registro de la
PC . - Aumentar el registro de la
PC . - Vea el código de operación para determinar qué tipo de instrucción seguir.
- Siga las instrucciones usando sus parámetros.
- Regrese al paso 1.
Puede hacer la pregunta: "Pero si el ciclo continúa incrementando el contador en ausencia de
if o
while , ¿no terminarán las instrucciones?" La respuesta es no. Como ya mencionamos, algunas instrucciones tipo goto cambian el flujo de ejecución al saltar alrededor de la
PC .
Comenzamos el estudio de este proceso como un ejemplo del ciclo principal:
int main(int argc, const char* argv[]) { {Load Arguments, 12} {Setup, 12} enum { PC_START = 0x3000 }; reg[R_PC] = PC_START; int running = 1; while (running) { uint16_t instr = mem_read(reg[R_PC]++); uint16_t op = instr >> 12; switch (op) { case OP_ADD: {ADD, 6} break; case OP_AND: {AND, 7} break; case OP_NOT: {NOT, 7} break; case OP_BR: {BR, 7} break; case OP_JMP: {JMP, 7} break; case OP_JSR: {JSR, 7} break; case OP_LD: {LD, 7} break; case OP_LDI: {LDI, 6} break; case OP_LDR: {LDR, 7} break; case OP_LEA: {LEA, 7} break; case OP_ST: {ST, 7} break; case OP_STI: {STI, 7} break; case OP_STR: {STR, 7} break; case OP_TRAP: {TRAP, 8} break; case OP_RES: case OP_RTI: default: {BAD OPCODE, 7} break; } } {Shutdown, 12} }
6. Implementación de instrucciones
Ahora su tarea es hacer la implementación correcta para cada código de operación. Una especificación detallada de cada instrucción está contenida en la
documentación del proyecto . A partir de la especificación, debe averiguar cómo funciona cada instrucción y escribir una implementación. Esto es más fácil de lo que parece. Aquí demostraré cómo implementar dos de ellos. El código para el resto se puede encontrar en la siguiente sección.
AGREGAR
La instrucción
ADD toma dos números, los agrega y almacena el resultado en un registro. La especificación se encuentra en la documentación en la página 526. Cada instrucción
ADD es la siguiente:
Hay dos líneas en el diagrama, porque hay dos "modos" diferentes para esta instrucción. Antes de explicar los modos, intentemos encontrar las similitudes entre ellos. Ambos comienzan con cuatro bits idénticos
0001 . Este es el valor del código de operación para
OP_ADD . Los siguientes tres bits están marcados
DR para el registro de salida. El registro de salida es el lugar donde se almacena la cantidad. Los siguientes tres bits son:
SR1 . Este es un registro que contiene el primer número que se agregará.
Por lo tanto, sabemos dónde guardar el resultado, y sabemos el primer número para agregar. Solo queda averiguar el segundo número para sumar. Aquí las dos líneas comienzan a diferir. Tenga en cuenta que el quinto bit es 0 en la parte superior y 1. está en la parte inferior, este bit corresponde al
modo directo o al
modo de registro . En el modo de registro, el segundo número se almacena en el registro, como el primero. Está marcado como
SR2 y está contenido en los bits del dos al cero. Los bits 3 y 4 no se utilizan. En ensamblador, se escribirá así:
ADD R2 R0 R1 ; add the contents of R0 to R1 and store in R2.
En el modo inmediato, en lugar de agregar el contenido del registro, el valor inmediato se incrusta en la instrucción misma. Esto es conveniente porque el programa no necesita instrucciones adicionales para cargar este número en el registro de la memoria. En cambio, ya está dentro de las instrucciones cuando lo necesitamos. La compensación es que solo se pueden almacenar pequeños números allí. Para ser precisos, un máximo de 2
5 = 32. Esto es más útil para aumentar los contadores o valores. En ensamblador, puedes escribir así:
ADD R0 R0 1 ; add 1 to R0 and store back in R0
Aquí hay un extracto de la especificación:
Si el bit [5] es 0, entonces el segundo operando fuente se obtiene de SR2. Si el bit [5] es 1, entonces el segundo operando fuente se obtiene expandiendo imm5 a 16 bits. En ambos casos, el segundo operando fuente se agrega al contenido de SR1, y el resultado se almacena en DR. (pág. 526)
Esto es similar a lo que discutimos. Pero, ¿qué es una "extensión de significado"? Aunque en modo directo el valor tiene solo 5 bits, debe agregarse con un número de 16 bits. Estos 5 bits deben expandirse a 16 para corresponder a otro número. Para números positivos, podemos completar los bits faltantes con ceros y obtener el mismo valor. Sin embargo, para números negativos esto no funciona. Por ejemplo, -1 en cinco bits es
1 1111 . Si solo lo llena con ceros, obtenemos
0000 0000 0001 1111 , ¡que es 32! Expandir el valor evita este problema al llenar bits con ceros para números positivos y unos para números negativos.
uint16_t sign_extend(uint16_t x, int bit_count) { if ((x >> (bit_count - 1)) & 1) { x |= (0xFFFF << bit_count); } return x; }
Nota: si está interesado en números binarios negativos, puede leer acerca de códigos adicionales . Pero esto no es esencial. Simplemente copie el código anterior y úselo cuando la especificación indique expandir el valor.
La especificación tiene la última oración:
Los códigos de condición se establecen dependiendo de si el resultado es negativo, cero o positivo. (pág. 526)
Anteriormente definimos la condición de enumeración de las banderas, y ahora es el momento de usar estas banderas. Cada vez que se escribe un valor en el registro, necesitamos actualizar las banderas para indicar su signo. Escribimos una función para reutilizar:
void update_flags(uint16_t r) { if (reg[r] == 0) { reg[R_COND] = FL_ZRO; } else if (reg[r] >> 15) { reg[R_COND] = FL_NEG; } else { reg[R_COND] = FL_POS; } }
Ahora estamos listos para escribir el código para
ADD :
{ uint16_t r0 = (instr >> 9) & 0x7; uint16_t r1 = (instr >> 6) & 0x7; uint16_t imm_flag = (instr >> 5) & 0x1; if (imm_flag) { uint16_t imm5 = sign_extend(instr & 0x1F, 5); reg[r0] = reg[r1] + imm5; } else { uint16_t r2 = instr & 0x7; reg[r0] = reg[r1] + reg[r2]; } update_flags(r0); }
Esta sección tiene mucha información, así que resumamos.
ADD toma dos valores y los almacena en un registro.- En el modo de registro, el segundo valor a agregar está en el registro.
- En modo directo, el segundo valor está incrustado en los 5 bits correctos de la instrucción.
- Los valores de menos de 16 bits deben expandirse.
- Cada vez que la instrucción cambia de mayúsculas y minúsculas, los indicadores de condición deben actualizarse.
Puede sentirse abrumado al escribir 15 instrucciones más. Sin embargo, la información obtenida aquí puede ser reutilizada. La mayoría de las instrucciones usan una combinación de expansión de valor, varios modos y actualizaciones de banderas.
LDI
LDI significa carga "indirecta" o "indirecta" (carga indirecta). Esta instrucción se utiliza para cargar un valor desde una ubicación de memoria en un registro. Especificaciones en la página 532.
Así es como se ve el diseño binario:
A diferencia de
ADD , no hay modos y menos parámetros. Esta vez, el código de operación es
1010 , que corresponde al valor de enumeración
OP_LDI . Nuevamente, vemos un
DR (registro de salida) de tres bits para almacenar el valor cargado. Los bits restantes se marcan como
PCoffset9 . Este es el valor inmediato incorporado en la instrucción (similar a
imm5 ). Como la instrucción se carga desde la memoria, podemos adivinar que este número es un tipo de dirección que dice desde dónde cargar el valor. La especificación explica con más detalle:
La dirección se calcula expandiendo los bits del valor [8:0] a 16 bits y agregando este valor a la PC ampliada. Lo que se almacena en la memoria en esta dirección es la dirección de los datos que se cargarán en el DR . (pág. 532)
Como antes, debe expandir este valor de 9 bits, pero esta vez agregarlo a la
PC actual. (Si observa el ciclo de ejecución, la
PC aumentó inmediatamente después de cargar esta instrucción). La suma resultante es la dirección de ubicación en la memoria, y esta dirección
contiene otro valor, que es la dirección del valor de carga.
Esto puede parecer una forma indirecta de leer de memoria, pero es necesario. La instrucción
LD está limitada a un desplazamiento de dirección de 9 bits, mientras que la memoria requiere una dirección de 16 bits.
LDI es útil para cargar valores que están almacenados en algún lugar fuera de la computadora actual, pero para usarlos, la dirección de la ubicación final debe almacenarse cerca. Puede pensarlo como una variable local en C, que es un puntero a algunos datos:
Como antes, después de escribir el valor en
DR , los indicadores deberían actualizarse:
Los códigos de condición se establecen dependiendo de si el resultado es negativo, cero o positivo. (pág. 532)
Aquí está el código para este caso: (
mem_read discutirá en la siguiente sección):
{ uint16_t r0 = (instr >> 9) & 0x7; uint16_t pc_offset = sign_extend(instr & 0x1ff, 9); reg[r0] = mem_read(mem_read(reg[R_PC] + pc_offset)); update_flags(r0); }
Como dije, para esta instrucción utilizamos una parte significativa del código y el conocimiento adquirido anteriormente al escribir
ADD . Lo mismo con el resto de las instrucciones.
Ahora necesita implementar el resto de las instrucciones. Siga las
especificaciones y use el código ya escrito. El código para todas las instrucciones se encuentra al final del artículo. No se necesitarán dos de los
OP_RTI OP_RES mencionados anteriormente:
OP_RTI y
OP_RES . Puede ignorarlos o dar un error si se los llama. Cuando haya terminado, ¡la mayor parte de su VM puede considerarse completa!
7. Cuna según las instrucciones.
Esta sección contiene implementaciones completas de las instrucciones restantes si está atascado.
RTI & RES
(no utilizado)
abort();
{ uint16_t r0 = (instr >> 9) & 0x7; uint16_t r1 = (instr >> 6) & 0x7; uint16_t imm_flag = (instr >> 5) & 0x1; if (imm_flag) { uint16_t imm5 = sign_extend(instr & 0x1F, 5); reg[r0] = reg[r1] & imm5; } else { uint16_t r2 = instr & 0x7; reg[r0] = reg[r1] & reg[r2]; } update_flags(r0); }
{ uint16_t r0 = (instr >> 9) & 0x7; uint16_t r1 = (instr >> 6) & 0x7; reg[r0] = ~reg[r1]; update_flags(r0); }
Rama
{ uint16_t pc_offset = sign_extend((instr) & 0x1ff, 9); uint16_t cond_flag = (instr >> 9) & 0x7; if (cond_flag & reg[R_COND]) { reg[R_PC] += pc_offset; } }
Saltar
RET se indica como una instrucción separada en la especificación, ya que este es otro comando en ensamblador. Este es en realidad un caso especial de
JMP .
RET ocurre siempre que
R1 sea 7.
{ uint16_t r1 = (instr >> 6) & 0x7; reg[R_PC] = reg[r1]; }
Saltar registro
{ uint16_t r1 = (instr >> 6) & 0x7; uint16_t long_pc_offset = sign_extend(instr & 0x7ff, 11); uint16_t long_flag = (instr >> 11) & 1; reg[R_R7] = reg[R_PC]; if (long_flag) { reg[R_PC] += long_pc_offset; } else { reg[R_PC] = reg[r1]; } break; }
Carga
{ uint16_t r0 = (instr >> 9) & 0x7; uint16_t pc_offset = sign_extend(instr & 0x1ff, 9); reg[r0] = mem_read(reg[R_PC] + pc_offset); update_flags(r0); }
Registro de carga
{ uint16_t r0 = (instr >> 9) & 0x7; uint16_t r1 = (instr >> 6) & 0x7; uint16_t offset = sign_extend(instr & 0x3F, 6); reg[r0] = mem_read(reg[r1] + offset); update_flags(r0); }
Dirección de carga efectiva
{ uint16_t r0 = (instr >> 9) & 0x7; uint16_t pc_offset = sign_extend(instr & 0x1ff, 9); reg[r0] = reg[R_PC] + pc_offset; update_flags(r0); }
Tienda
{ uint16_t r0 = (instr >> 9) & 0x7; uint16_t pc_offset = sign_extend(instr & 0x1ff, 9); mem_write(reg[R_PC] + pc_offset, reg[r0]); }
Tienda indirecta
{ uint16_t r0 = (instr >> 9) & 0x7; uint16_t pc_offset = sign_extend(instr & 0x1ff, 9); mem_write(mem_read(reg[R_PC] + pc_offset), reg[r0]); }
Registro de tienda
{ uint16_t r0 = (instr >> 9) & 0x7; uint16_t r1 = (instr >> 6) & 0x7; uint16_t offset = sign_extend(instr & 0x3F, 6); mem_write(reg[r1] + offset, reg[r0]); }
8. Procedimientos de manejo de interrupciones
LC-3 proporciona varias rutinas predefinidas para realizar tareas comunes e interactuar con dispositivos de E / S. Por ejemplo, hay procedimientos para recibir entradas de teclado y líneas de salida a la consola. Se llaman rutinas de trampa, que puede considerar como el sistema operativo o API para LC-3. A cada subprograma se le asigna un código de interrupción (código de captura) que lo identifica (similar a un código de operación).
Para ejecutarlo, se llama a una instrucción TRAPcon el código del subprograma deseado.Establezca la enumeración para cada código de interrupción: enum { TRAP_GETC = 0x20, TRAP_OUT = 0x21, TRAP_PUTS = 0x22, TRAP_IN = 0x23, TRAP_PUTSP = 0x24, TRAP_HALT = 0x25 };
Quizás se pregunte por qué los códigos de interrupción no están incluidos en las instrucciones. Esto se debe a que en realidad no agregan LC-3 ninguna funcionalidad nueva, sino que solo proporcionan una forma conveniente de completar la tarea (como las funciones del sistema en C). En el simulador oficial LC-3, los códigos de interrupción se escriben en ensamblador . Cuando se llama a un código de interrupción, la computadora se mueve a la dirección de este código. La CPU ejecuta las instrucciones del procedimiento y, una vez finalizado, se PCrestablece a la ubicación desde donde se activó la interrupción.: 0x3000 0x0 . , .
No hay una especificación sobre cómo implementar las rutinas de interrupción: solo lo que deberían hacer. En nuestra VM, actuaremos de manera un poco diferente escribiéndolos en C. Cuando se llama al código de interrupción, se llamará a la función C. Después de su operación, la instrucción continuará.Aunque los procedimientos pueden escribirse en ensamblador y la computadora física LC-3 lo será, esta no es la mejor opción para la VM. En lugar de escribir sus propios procedimientos primitivos de entrada-salida, puede usar los que están disponibles en nuestro sistema operativo. Esto mejorará el funcionamiento de la máquina virtual en nuestras computadoras, simplificará el código y proporcionará un mayor nivel de abstracción para la portabilidad.Nota: Un ejemplo específico es la entrada de teclado. La versión del ensamblador utiliza un bucle para verificar continuamente la entrada del teclado. ¡Pero se desperdicia mucho tiempo de procesador! Usando la función apropiada del sistema operativo, el programa puede dormir tranquilo antes de la señal de entrada.
En el operador de opción múltiple para el código de operación, TRAPagregue otro interruptor: switch (instr & 0xFF) { case TRAP_GETC: {TRAP GETC, 9} break; case TRAP_OUT: {TRAP OUT, 9} break; case TRAP_PUTS: {TRAP PUTS, 8} break; case TRAP_IN: {TRAP IN, 9} break; case TRAP_PUTSP: {TRAP PUTSP, 9} break; case TRAP_HALT: {TRAP HALT, 9} break; }
Al igual que con las instrucciones, le mostraré cómo implementar un procedimiento y hacer el resto usted mismo.Putts
El código de interrupción se PUTSutiliza para devolver una cadena con un cero final (de manera similar printfen C). Especificación en la página 543.Para mostrar una cadena, debemos darle a la rutina de interrupción una cadena para mostrar. Esto se hace almacenando la dirección del primer carácter R0antes de que comience el procesamiento.De la especificación:Mostrar la cadena de caracteres ASCII en la pantalla de la consola. Los caracteres están contenidos en celdas de memoria consecutivas, un caracter por celda, comenzando en la dirección especificada en R0. La salida finaliza cuando se encuentra un valor en la memoria x0000. (pág. 543)
Tenga en cuenta que, a diferencia de las cadenas C, aquí los caracteres no se almacenan en un byte, sino en una ubicación en la memoria . La ubicación de la memoria del LC-3 es de 16 bits, por lo que cada carácter de la cadena es de 16 bits. Para mostrar esto en la función C, debe convertir cada valor en un carácter e imprimirlos por separado. { uint16_t* c = memory + reg[R_R0]; while (*c) { putc((char)*c, stdout); ++c; } fflush(stdout); }
No se requiere nada más para este procedimiento. Las rutinas de interrupción son bastante sencillas si conoce C. Ahora regrese a las especificaciones e implemente el resto. Al igual que con las instrucciones, el código completo se puede encontrar al final de esta guía.9. Cheat sheet para rutinas de interrupción
Esta sección contiene implementaciones completas de las rutinas de interrupción restantes.Entrada de personaje
reg[R_R0] = (uint16_t)getchar();
Salida de caracteres
putc((char)reg[R_R0], stdout); fflush(stdout);
Solicitud de entrada de caracteres
printf("Enter a character: "); reg[R_R0] = (uint16_t)getchar();
Salida de línea
{ uint16_t* c = memory + reg[R_R0]; while (*c) { char char1 = (*c) & 0xFF; putc(char1, stdout); char char2 = (*c) >> 8; if (char2) putc(char2, stdout); ++c; } fflush(stdout); }
Terminación del programa
puts("HALT"); fflush(stdout); running = 0;
10. Descarga de programas
Hablamos mucho sobre cargar y ejecutar instrucciones desde la memoria, pero ¿cómo entran las instrucciones en la memoria en general? Al convertir un programa ensamblador a código de máquina, el resultado es un archivo que contiene una serie de instrucciones y datos. Se puede descargar simplemente copiando el contenido directamente a una dirección en la memoria.Los primeros 16 bits del archivo de programa indican la dirección en la memoria donde debe comenzar el programa. Esta dirección se llama origen . Debe leerse primero, después de lo cual el resto de los datos se leen en la memoria desde el archivo.Aquí está el código para cargar el programa en la memoria LC-3: void read_image_file(FILE* file) { uint16_t origin; fread(&origin, sizeof(origin), 1, file); origin = swap16(origin); uint16_t max_read = UINT16_MAX - origin; uint16_t* p = memory + origin; size_t read = fread(p, sizeof(uint16_t), max_read, file); while (read-- > 0) { *p = swap16(*p); ++p; } }
Tenga en cuenta que para cada valor cargado se llama swap16. Los programas LC-3 están escritos en orden de bytes directo, pero la mayoría de las computadoras modernas usan el orden inverso. Como resultado, necesitamos voltear cada uno cargado uint16. (Si accidentalmente usa una computadora extraña como PPC , entonces no necesita cambiar nada). uint16_t swap16(uint16_t x) { return (x << 8) | (x >> 8); }
Nota: El orden de bytes se refiere a cómo se interpretan los bytes de un entero. En orden inverso, el primer byte es el dígito menos significativo, y en orden inverso, viceversa. Hasta donde yo sé, la decisión es principalmente arbitraria. Diferentes compañías tomaron decisiones diferentes, por lo que ahora tenemos implementaciones diferentes. Para este proyecto, ya no necesita saber nada sobre el orden de los bytes.
Agregue también una función conveniente para read_image_file, que toma la ruta de la cadena: int read_image(const char* image_path) { FILE* file = fopen(image_path, "rb"); if (!file) { return 0; }; read_image_file(file); fclose(file); return 1; }
11. Registros mapeados
Algunos registros especiales no están disponibles en la tabla de registro regular. En cambio, una dirección especial está reservada para ellos en la memoria. Para leer y escribir en estos registros, simplemente lea y escriba en su memoria. Se llaman registros mapeados en memoria . Por lo general, se utilizan para interactuar con dispositivos de hardware especiales.Para nuestro LC-3, necesitamos implementar dos registros asignables. Este es el registro de estado del teclado ( KBSR) y el registro de datos del teclado ( KBDR). El primero indica si se ha presionado la tecla y el segundo determina qué tecla se ha presionado.Aunque la entrada del teclado se puede solicitar usando GETC, bloquea la ejecución hasta que se recibe la entrada. KBSRy KBDRpermitirinterrogar el estado del dispositivo mientras continúa ejecutando el programa, para que siga respondiendo mientras espera la entrada. enum { MR_KBSR = 0xFE00, MR_KBDR = 0xFE02 };
Los registros mapeados complican un poco el acceso a la memoria. No podemos leer y escribir directamente en la matriz de memoria, sino que debemos llamar a funciones especiales: setter y getter. Después de leer la memoria del registro KBSR, el captador comprueba el teclado y actualiza ambas ubicaciones en la memoria. void mem_write(uint16_t address, uint16_t val) { memory[address] = val; } uint16_t mem_read(uint16_t address) { if (address == MR_KBSR) { if (check_key()) { memory[MR_KBSR] = (1 << 15); memory[MR_KBDR] = getchar(); } else { memory[MR_KBSR] = 0; } } return memory[address]; }
¡Este es el último componente de una máquina virtual! Si ha implementado el resto de las rutinas e instrucciones de interrupción, ¡está casi listo para probarlo!Todo lo escrito debe agregarse al archivo C en el siguiente orden: {Memory Mapped Registers, 11} {TRAP Codes, 8} {Memory Storage, 3} {Register Storage, 3} {Functions, 12} {Main Loop, 5}
12. Características de la plataforma
Esta sección contiene algunos detalles tediosos necesarios para acceder al teclado y funcionar correctamente. No hay nada interesante o informativo sobre el funcionamiento de las máquinas virtuales. Siéntase libre de copiar y pegar!Si está intentando iniciar la VM en un sistema operativo que no sea Unix, como Windows, estas funciones deben reemplazarse con las funciones correspondientes de Windows. uint16_t check_key() { fd_set readfds; FD_ZERO(&readfds); FD_SET(STDIN_FILENO, &readfds); struct timeval timeout; timeout.tv_sec = 0; timeout.tv_usec = 0; return select(1, &readfds, NULL, NULL, &timeout) != 0; }
Código para extraer la ruta de los argumentos del programa y generar un ejemplo de uso si faltan. if (argc < 2) { printf("lc3 [image-file1] ...\n"); exit(2); } for (int j = 1; j < argc; ++j) { if (!read_image(argv[j])) { printf("failed to load image: %s\n", argv[j]); exit(1); } }
Código de configuración de entrada de terminal específico de Unix. struct termios original_tio; void disable_input_buffering() { tcgetattr(STDIN_FILENO, &original_tio); struct termios new_tio = original_tio; new_tio.c_lflag &= ~ICANON & ~ECHO; tcsetattr(STDIN_FILENO, TCSANOW, &new_tio); } void restore_input_buffering() { tcsetattr(STDIN_FILENO, TCSANOW, &original_tio); }
Cuando se interrumpe el programa, queremos devolver la consola a su configuración normal. void handle_interrupt(int signal) { restore_input_buffering(); printf("\n"); exit(-2); }
signal(SIGINT, handle_interrupt); disable_input_buffering();
restore_input_buffering();
{Sign Extend, 6} {Swap, 10} {Update Flags, 6} {Read Image File, 10} {Read Image, 10} {Check Key, 12} {Memory Access, 11} {Input Buffering, 12} {Handle Interrupt, 12}
#include <stdio.h> #include <stdlib.h> #include <stdint.h> #include <string.h> #include <signal.h> #include <unistd.h> #include <fcntl.h> #include <sys/time.h> #include <sys/types.h> #include <sys/termios.h> #include <sys/mman.h>
Inicio de máquina virtual
¡Ahora puede construir y ejecutar la máquina virtual LC-3!- Compila el programa con tu compilador favorito.
- Descargue la versión compilada de 2048 o Rogue .
- Ejecute el programa con el archivo obj como argumento:
lc3-vm path/to/2048.obj - ¡Juega en 2048!
Control the game using WASD keys. Are you on an ANSI terminal (y/n)? y +--------------------------+ | | | | | | | 2 | | | | 2 | | | | | | | +--------------------------+
Depuración
Si el programa no funciona correctamente, lo más probable es que haya codificado incorrectamente algún tipo de instrucción. Puede ser difícil de depurar. Le recomiendo que lea el código de ensamblador del programa al mismo tiempo, y use el depurador para recorrer las instrucciones de la máquina virtual de una en una. Al leer el código, asegúrese de que la VM vaya a las instrucciones previstas. Si se produce una falta de coincidencia, descubrirá qué instrucción causó el problema. Vuelva a leer la especificación y vuelva a verificar el código.14. Método alternativo en C ++
Aquí hay una forma avanzada de ejecutar instrucciones que reduce significativamente el tamaño del código. Esta es una sección completamente opcional.Dado que C ++ admite genéricos potentes durante el proceso de compilación, podemos crear partes de instrucciones utilizando el compilador. Este método reduce la duplicación de código y en realidad está más cerca del nivel de hardware de la computadora.La idea es reutilizar los pasos comunes a cada instrucción. Por ejemplo, algunas instrucciones usan direccionamiento indirecto o extensión de un valor y lo agregan al valor actual PC. De acuerdo, ¿sería bueno escribir este código una vez para todas las instrucciones?Considerando la instrucción como una secuencia de pasos, vemos que cada instrucción es solo una reorganización de varios pasos más pequeños. Usaremos banderas de bits para indicar qué pasos seguir para cada instrucción. El valor 1en el bit de número de instrucción indica que para esta instrucción el compilador debe incluir esta sección de código. template <unsigned op> void ins(uint16_t instr) { uint16_t r0, r1, r2, imm5, imm_flag; uint16_t pc_plus_off, base_plus_off; uint16_t opbit = (1 << op); if (0x4EEE & opbit) { r0 = (instr >> 9) & 0x7; } if (0x12E3 & opbit) { r1 = (instr >> 6) & 0x7; } if (0x0022 & opbit) { r2 = instr & 0x7; imm_flag = (instr >> 5) & 0x1; imm5 = sign_extend((instr) & 0x1F, 5); } if (0x00C0 & opbit) {
static void (*op_table[16])(uint16_t) = { ins<0>, ins<1>, ins<2>, ins<3>, ins<4>, ins<5>, ins<6>, ins<7>, NULL, ins<9>, ins<10>, ins<11>, ins<12>, NULL, ins<14>, ins<15> };
Nota: Aprendí sobre esta técnica del emulador NES desarrollado por Bisqwit . Si está interesado en la emulación o NES, le recomiendo sus videos.Otras versiones de C ++ usan el código ya escrito. Versión completa aquí . {Includes, 12} {Registers, 3} {Condition Flags, 3} {Opcodes, 3} {Memory Mapped Registers, 11} {TRAP Codes, 8} {Memory Storage, 3} {Register Storage, 3} {Functions, 12} int running = 1; {Instruction C++, 14} {Op Table, 14} int main(int argc, const char* argv[]) { {Load Arguments, 12} {Setup, 12} enum { PC_START = 0x3000 }; reg[R_PC] = PC_START; while (running) { uint16_t instr = mem_read(reg[R_PC]++); uint16_t op = instr >> 12; op_table[op](instr); } {Shutdown, 12} }