
Trabajo en el equipo de la plataforma Odnoklassniki y hoy hablaré sobre los detalles de arquitectura, diseño e implementación del servicio de distribución de música.
El artículo es una transcripción del informe en Joker 2018 .
Algunas estadísticas
Primero, algunas palabras sobre OK. Este es un servicio gigantesco que utilizan más de 70 millones de usuarios. Son atendidos por 7 mil automóviles en 4 centros de datos. Recientemente, hemos superado la marca de tráfico a 2 Tb / s sin tener en cuenta los numerosos sitios de CDN. Exprimimos al máximo nuestro hardware, los servicios más cargados atienden hasta 100,000 solicitudes por segundo desde un nodo de cuatro núcleos. Además, casi todos los servicios están escritos en Java.
Hay muchas secciones en OK, una de las más populares es "Música". En él, los usuarios pueden subir sus pistas, comprar y descargar música en diferentes calidades. La sección tiene un maravilloso catálogo, sistema de recomendación, radio y mucho más. Pero el objetivo principal del servicio, por supuesto, es reproducir música.
El distribuidor de música es responsable de transferir datos a reproductores de usuarios y aplicaciones móviles. Puede verlo en el inspector web si observa las solicitudes al dominio musicd.mycdn.me. La API del distribuidor es extremadamente simple. Responde a las solicitudes
GET HTTP y emite el rango de seguimiento solicitado.
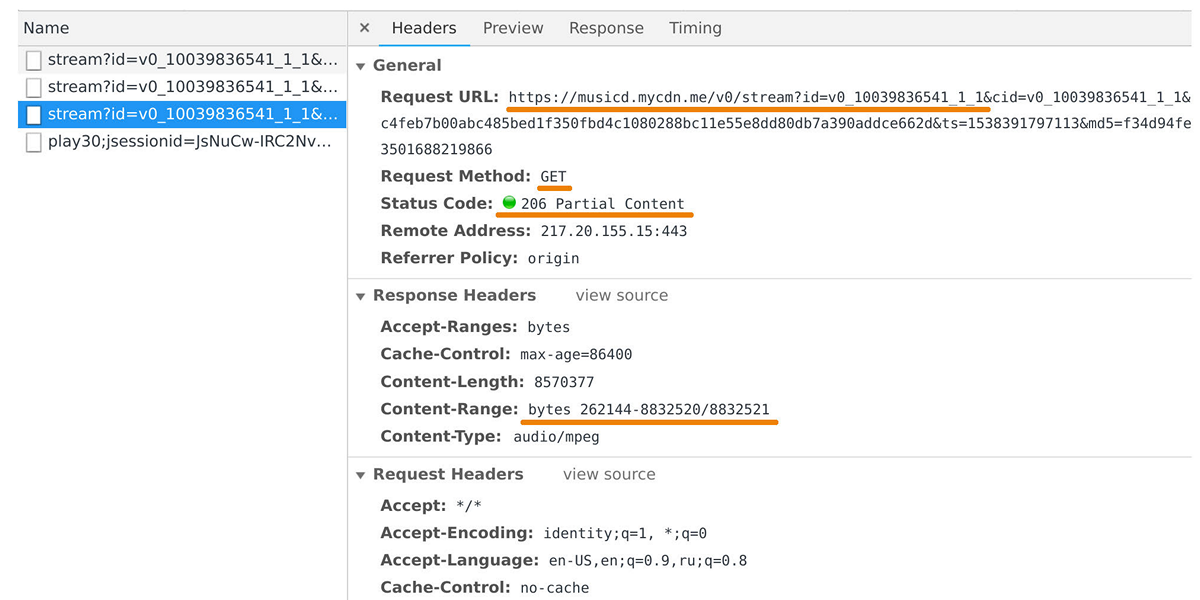
En el pico, la carga alcanza los 100 Gb / s a través de medio millón de conexiones. De hecho, el distribuidor de música es una interfaz de almacenamiento en caché frente a nuestro repositorio de pistas interno, que se basa en
One Blob Storage y
One Cold Storage y contiene petabytes de datos.
Como he hablado sobre el almacenamiento en caché, veamos las estadísticas de reproducción. Vemos un TOP pronunciado.
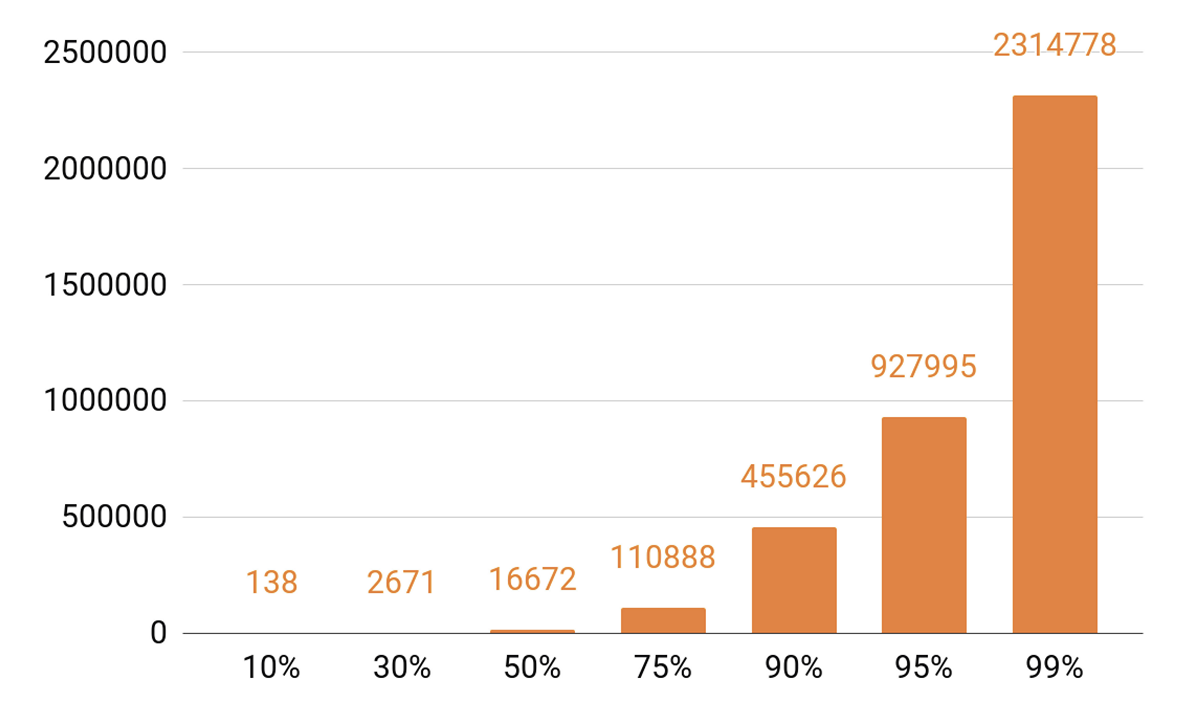
Aproximadamente 140 pistas cubren el 10% de todas las reproducciones por día. Si queremos que nuestro servidor de caché tenga un impacto de caché de al menos el 90%, entonces necesitamos medio millón de pistas para encajar en él. 95%: casi un millón de canciones.
Requisitos del distribuidor
¿Qué objetivos nos propusimos al desarrollar la próxima versión del distribuidor?
Queríamos que un nodo pudiera contener 100 mil conexiones. Y estas son conexiones de cliente lentas: un montón de navegadores y aplicaciones móviles a través de redes con velocidades variables. Al mismo tiempo, el servicio, como todos nuestros sistemas, debe ser escalable y tolerante a fallas.
En primer lugar, necesitamos escalar el ancho de banda del clúster para mantenernos al día con la creciente popularidad del servicio y poder dar más y más tráfico. También es necesario poder escalar la capacidad total de la memoria caché del clúster, porque el impacto de la memoria caché y el porcentaje de solicitudes que caerán en el almacenamiento de pistas dependen directamente de él.
Hoy es necesario poder escalar cualquier sistema distribuido horizontalmente, es decir, agregar máquinas y centros de datos. Pero también queríamos implementar el escalado vertical. Nuestro servidor moderno típico contiene 56 núcleos, 0.5-1 TB de RAM, una interfaz de red de 10 o 40 Gb y una docena de discos SSD.
Hablando de escalabilidad horizontal, surge un efecto interesante: cuando tienes miles de servidores y decenas de miles de discos, algo se rompe constantemente. La falla del disco es una rutina, los cambiamos a 20-30 piezas por semana. Y las fallas del servidor no sorprenden a nadie; se reemplazan 2-3 automóviles por día. También tuve que lidiar con fallas del centro de datos, por ejemplo, en 2018 hubo tres fallas de este tipo, y esta probablemente no sea la última vez.
¿Por qué soy todo esto? Cuando diseñamos cualquier sistema, sabemos que tarde o temprano se romperán. Por lo tanto, siempre
estudiamos cuidadosamente los escenarios de falla de todos los componentes del sistema. La principal forma de lidiar con las fallas es a través de la replicación de datos: varias copias de datos se almacenan en diferentes nodos.
También reservamos ancho de banda de red. Esto es importante porque si un componente del sistema falla, no se puede permitir que la carga de los componentes restantes se colapse.
Equilibrio
Primero, debe aprender a equilibrar las consultas de los usuarios entre los centros de datos y hacerlo automáticamente. Esto es en caso de que necesite realizar un trabajo de red, o si el centro de datos ha fallado. Pero el equilibrio también es necesario dentro de los centros de datos. Y queremos distribuir solicitudes entre nodos no al azar, sino con pesos. Por ejemplo, cuando cargamos una nueva versión de un servicio y queremos ingresar sin problemas un nuevo nodo en rotación. Los pesos también ayudan mucho durante las pruebas de estrés: aumentamos el peso y ponemos una carga mucho más pesada en el nodo para comprender los límites de sus capacidades. Y cuando un nodo falla bajo carga, rápidamente ponemos a cero el peso y lo retiramos de la rotación utilizando mecanismos de equilibrio.
¿Cómo se ve la ruta de solicitud del usuario al nodo, que devolverá los datos teniendo en cuenta el equilibrio?

El usuario inicia sesión a través del sitio web o la aplicación móvil y recibe la URL de la pista:
musicd.mycdn.me/v0/stream?id=...Para obtener la dirección IP del nombre de host en la URL, el cliente se pone en contacto con nuestro DNS GSLB, que conoce todos nuestros centros de datos y sitios CDN. GSLB DNS le da al cliente la dirección IP del equilibrador de uno de los centros de datos, y el cliente establece una conexión con él. El equilibrador conoce todos los nodos dentro de los centros de datos y su peso. En nombre del usuario, establece una conexión con uno de los nodos. Utilizamos
balanceadores L4 basados en N4Ware . Noda proporciona los datos del usuario directamente, sin pasar por el equilibrador. En servicios como un distribuidor, el tráfico saliente es significativamente mayor que el entrante.
Si un centro de datos falla, el GSLB DNS lo detecta y lo elimina rápidamente de la rotación: deja de proporcionar a los usuarios la dirección IP del equilibrador de este centro de datos. Si falla un nodo en el centro de datos, su peso se restablece y el equilibrador dentro del centro de datos deja de enviarle solicitudes.
Ahora considere equilibrar pistas por nodos dentro de un centro de datos. Consideraremos los centros de datos como unidades autónomas independientes, cada uno de ellos vivirá y trabajará, incluso si todos los demás murieron. Las pistas deben equilibrarse en todas las máquinas de manera uniforme para que no haya distorsiones de carga y replicarlas en diferentes nodos. Si un nodo falla, la carga debe distribuirse de manera uniforme entre los restantes.
Este problema se puede
resolver de diferentes maneras . Nos decidimos por
un hashing constante . Envolvemos todo el rango posible de hash de identificadores de pista en un anillo, y luego cada pista se muestra en un punto de este anillo. Luego distribuimos más o menos uniformemente los rangos de anillo entre los nodos en el clúster. Los nodos que almacenarán la pista se seleccionan arrastrando las pistas a un punto en el anillo y moviéndose en el sentido de las agujas del reloj.
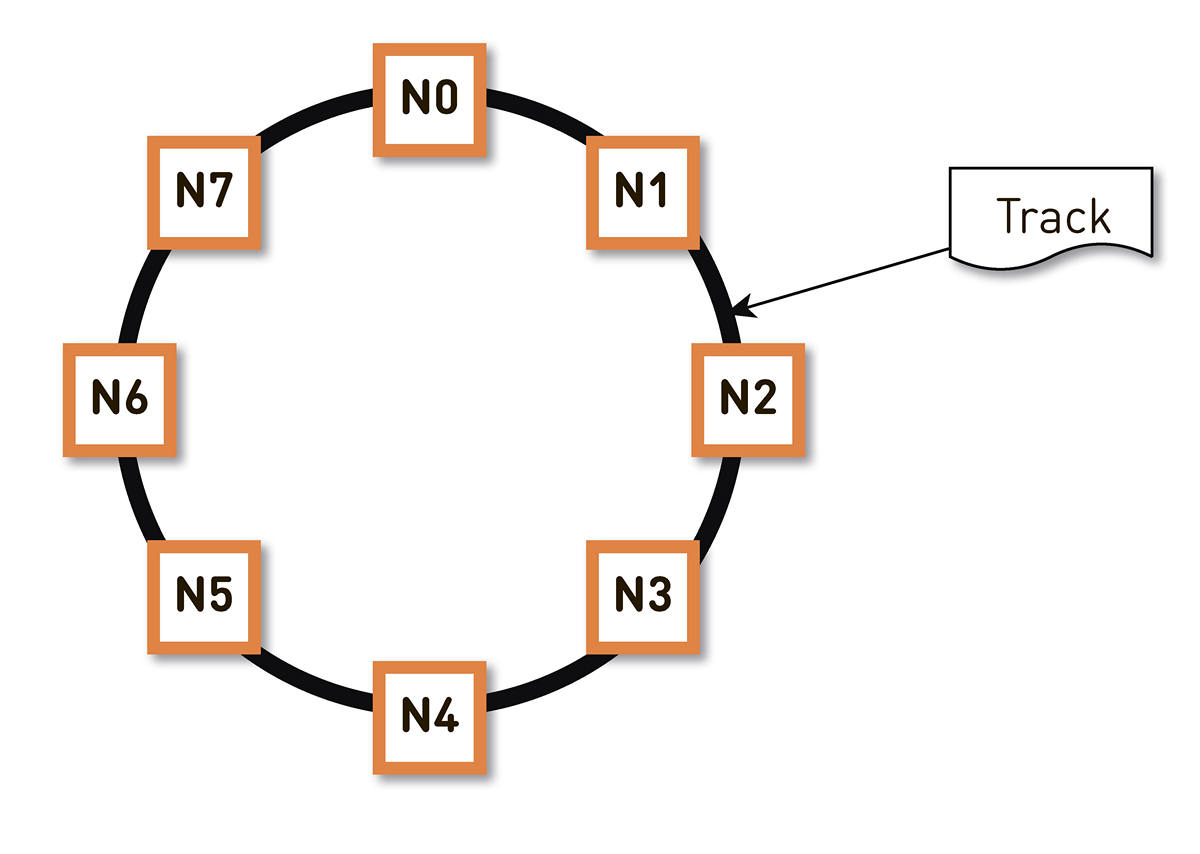
Pero tal esquema tiene un inconveniente: en caso de falla del nodo N2, por ejemplo, toda su carga recaerá en la próxima réplica en el anillo: N3. Y si no tiene un doble margen en el rendimiento, y esto no está justificado económicamente, lo más probable es que el segundo nodo también lo pase mal. Se desarrollará N3 con un alto grado de probabilidad, la carga irá a N4, y así sucesivamente: habrá una falla en cascada a lo largo de todo el anillo.
Este problema se puede resolver aumentando el número de réplicas, pero luego disminuye la capacidad útil total del clúster en el anillo. Por lo tanto, hacemos lo contrario. Con el mismo número de nodos, el anillo se divide en un número significativamente mayor de rangos que se distribuyen aleatoriamente alrededor del anillo. Las réplicas de la pista se seleccionan de acuerdo con el algoritmo anterior.

En el ejemplo anterior, cada nodo es responsable de dos rangos. Si uno de los nodos falla, su carga completa no se ubicará en el siguiente nodo del anillo, sino que se distribuirá entre los otros dos nodos del clúster.
El anillo se calcula en base a un pequeño conjunto de parámetros algorítmicamente y se determina en cada nodo. Es decir, no lo almacenamos en algún tipo de configuración. Tenemos más de cien mil de estos rangos en producción, y en caso de falla de cualquiera de los nodos, la carga se distribuye de manera absolutamente uniforme entre todos los demás nodos vivos.
¿Cómo se ve la ruta de retorno para el usuario en un sistema con hashing consistente?
El usuario a través del equilibrador L4 llega a un nodo aleatorio. La selección del nodo es aleatoria, porque el equilibrador no sabe nada sobre la topología. Pero entonces cada réplica en el clúster lo sabe. El nodo que recibió la solicitud determina si es una réplica de la pista solicitada. Si no, cambia al modo proxy con una de las réplicas, establece una conexión con él y busca datos en su almacenamiento local. Si la pista no está allí, la réplica la extrae del almacén de pistas, la guarda en la tienda local y le da el proxy, que redirige los datos al usuario.
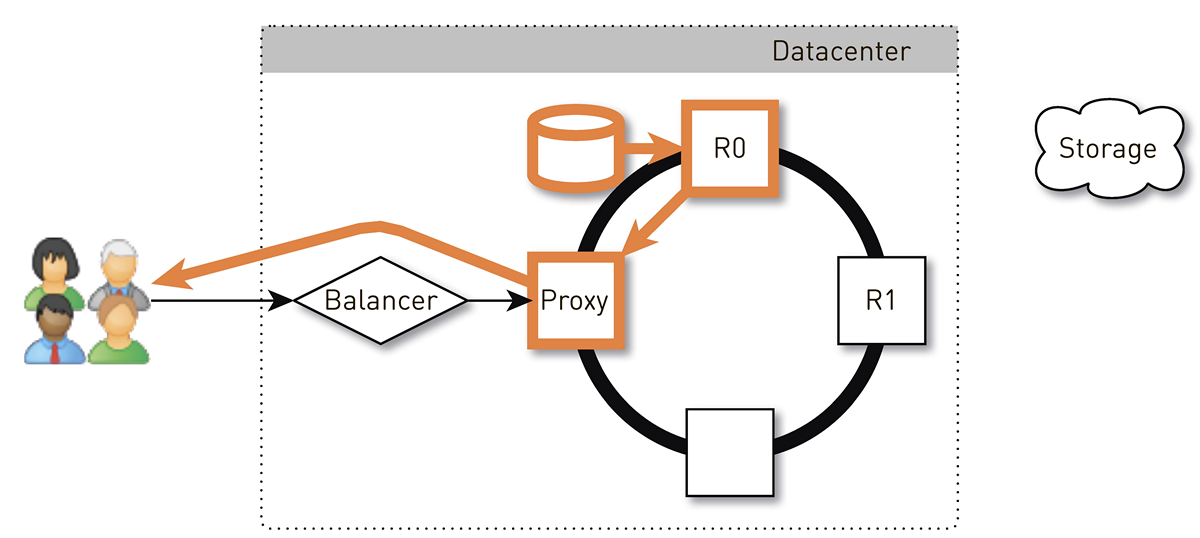
Si la unidad en la réplica falla, los datos del almacenamiento se transferirán directamente al usuario. Y si la réplica falla, entonces el proxy conoce todas las demás réplicas para esta pista, establecerá una conexión con otra réplica en vivo y recibirá datos de ella. Por lo tanto, garantizamos que si un usuario solicita una pista y al menos una réplica está viva, recibirá una respuesta.
¿Cómo funciona un nodo?
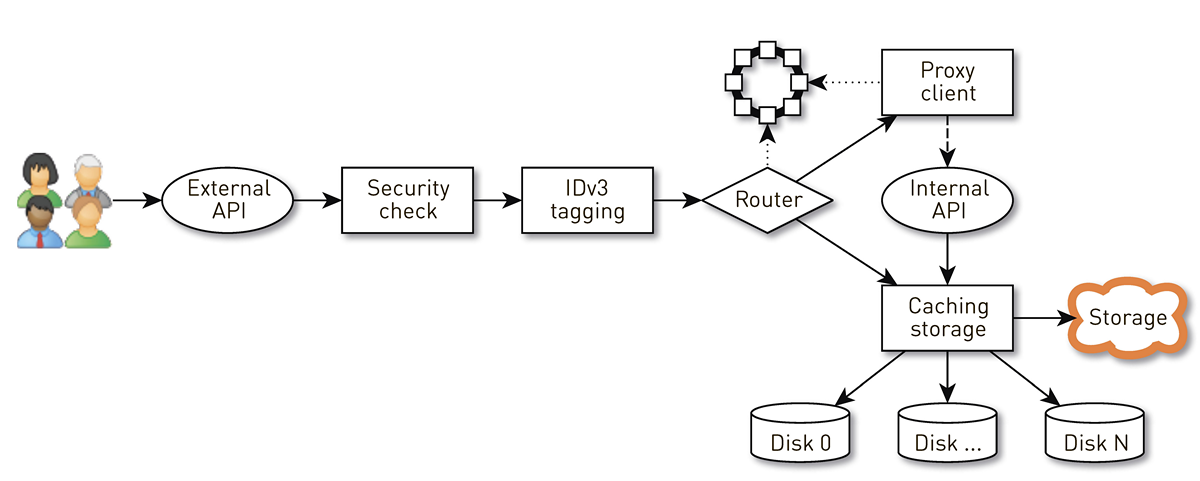
Un nodo es una tubería de un conjunto de etapas a través de las cuales pasa la solicitud de un usuario. Primero, la solicitud va a una API externa (enviamos todo a través de HTTPS). Luego se valida la solicitud: se verifican las firmas. Luego, las etiquetas IDv3 se construyen si es necesario, por ejemplo, al comprar una pista. La solicitud pasa a la etapa de enrutamiento, donde, en función de la topología del clúster, se determina cómo se devolverán los datos: o el nodo actual es una réplica de esta pista, o enviaremos un proxy desde otro nodo. En el segundo caso, el nodo a través del cliente proxy establece una conexión con la réplica a través de la API HTTP interna sin verificación de firmas. La réplica busca datos en el almacenamiento local; si encuentra una pista, la proporciona desde su disco; y si no lo hace, extrae pistas del almacenamiento, las almacena en caché y las dona.
Carga de nodo
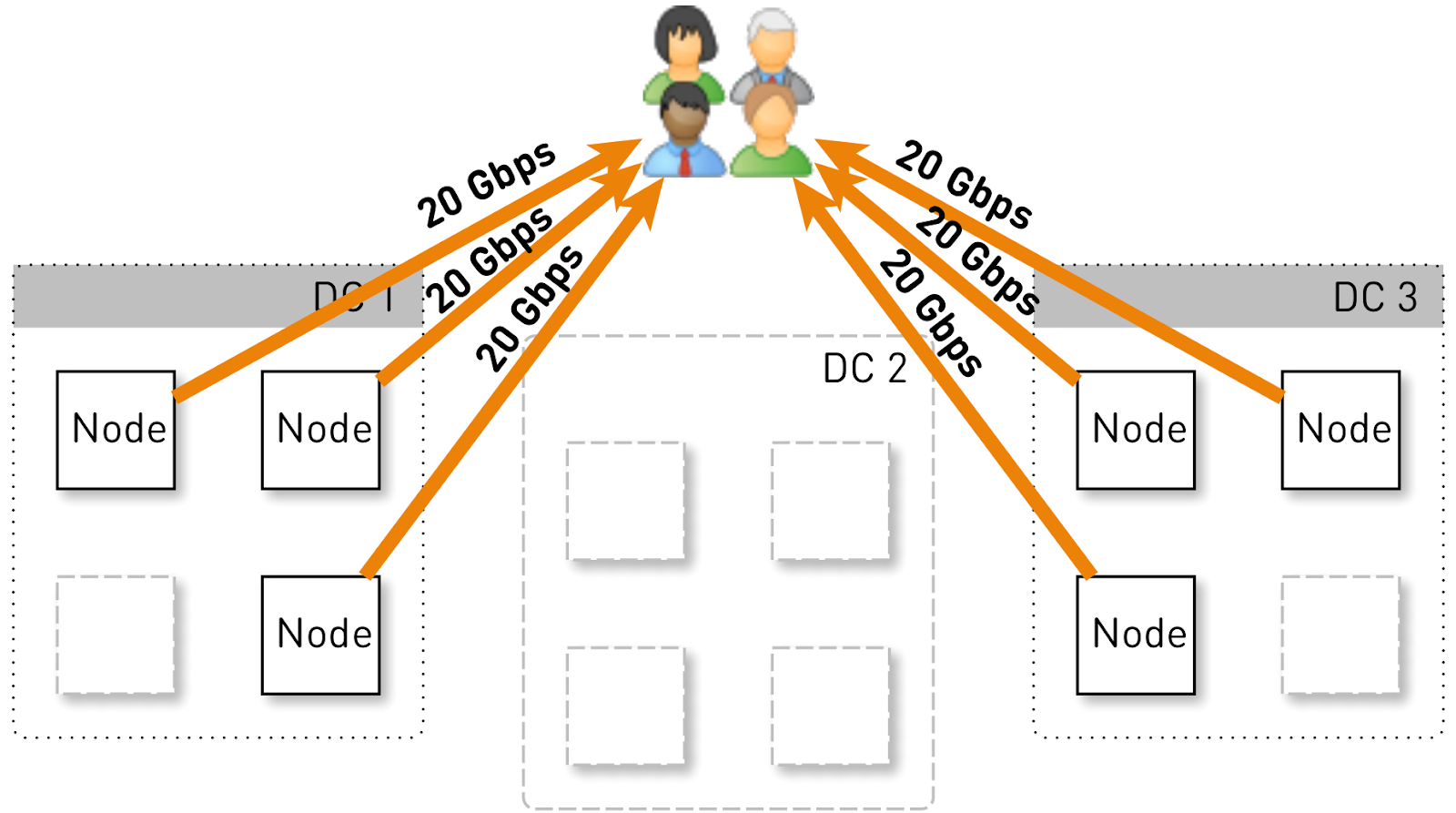
Vamos a estimar qué carga debe contener un nodo en esta configuración. Tengamos tres centros de datos con cuatro nodos cada uno.

El servicio completo debería servir a 120 Gbit / s, es decir, 40 Gbit / s por centro de datos. Supongamos que los networkers realizan maniobras o se produce un accidente, y quedan dos centros de datos DC1 y DC3. Ahora cada uno de ellos debería dar 60 Gbit / s. Pero aquí les correspondía a los desarrolladores implementar alguna actualización, en cada centro de datos quedaban 3 nodos activos y cada uno de ellos debería dar 20 Gbit / s.
Pero inicialmente en cada centro de datos había 4 nodos. Y si almacenamos dos réplicas en el centro de datos, con una probabilidad del 50%, el nodo que recibió la solicitud no será una réplica de la pista solicitada y representará los datos. Es decir, la mitad del tráfico dentro del centro de datos es proxy.
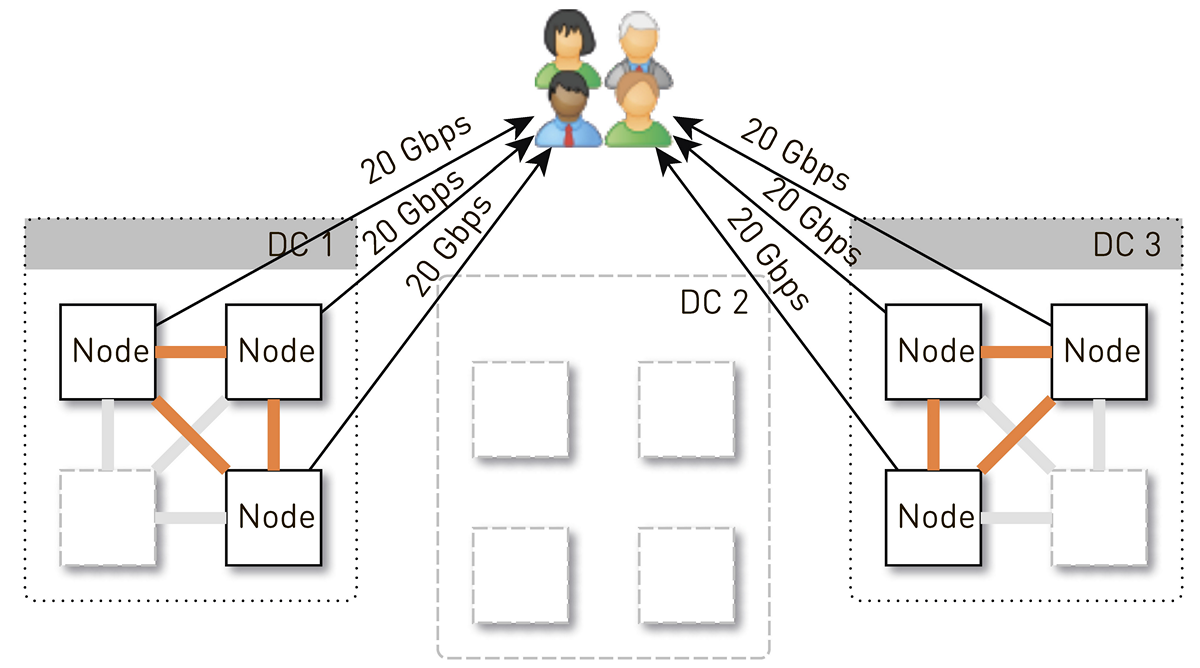
Entonces, un nodo debería dar a los usuarios 20 Gb / s. De estos, 10 Gb / s extrae de sus vecinos en el centro de datos. Pero el esquema es simétrico: el nodo da los mismos 10 Gb / s a los vecinos en el centro de datos. Resulta que 30 Gbit / s salen del nodo, de los cuales 20 Gbit / s deben ser atendidos por sí mismos, ya que es una réplica de los datos solicitados. Además, los datos irán de discos o de RAM, que contiene alrededor de 50 mil pistas "calientes". Según nuestras estadísticas de reproducción, esto le permite eliminar el 60-70% de la carga de los discos y permanecerá a unos 8 Gb / s. Este hilo es bastante capaz de entregar una docena de SSD.
Almacenamiento de datos en un nodo
Si coloca cada pista en un archivo separado, la sobrecarga de administrar estos archivos será enorme. Incluso reiniciar los nodos y escanear los datos en los discos tomará minutos, si no decenas de minutos.
Hay limitaciones menos obvias para este esquema. Por ejemplo, puede cargar pistas solo desde el principio. Y si el usuario solicitó la reproducción desde el medio y se perdió la memoria caché, entonces no podremos enviar un solo byte hasta que carguemos los datos en la ubicación deseada desde el repositorio de pistas. Además, podemos almacenar las pistas solo como un todo, incluso si es un audiolibro gigante que dejaron de escuchar en el tercer minuto. Continuará depositando peso muerto en el disco, desperdiciará espacio costoso y reducirá el impacto de caché de este nodo.
Por lo tanto, lo hacemos de una manera completamente diferente: dividimos las pistas en bloques de 256 KB, porque esto se correlaciona con el tamaño del bloque en el SSD, y ya estamos operando con estos bloques. Un disco de 1 TB contiene 4 millones de bloques. Cada disco en un nodo es un almacenamiento independiente, y todos los bloques de cada pista se distribuyen en todos los discos.
No llegamos inmediatamente a tal esquema, al principio todos los bloques de una pista se encontraban en un disco. Pero esto condujo a una fuerte distorsión de la carga entre los discos, ya que si una pista popular golpea uno de los discos, todas las solicitudes de sus datos irán a un disco. Para evitar esto, distribuimos los bloques de cada pista en todos los discos, equilibrando la carga.
Además, no olvidamos que tenemos un montón de RAM, pero decidimos no hacer el caché semántico, ya que tenemos un maravilloso caché de página en Linux.
¿Cómo almacenar bloques en discos?
Primero decidimos obtener un archivo XFS gigante del tamaño de un disco y poner todos los bloques en él. Entonces surgió la idea de trabajar directamente con un dispositivo de bloque. Implementamos ambas opciones, las comparamos y resultó que cuando se trabaja directamente con un dispositivo de bloque, la grabación es 1.5 veces más rápida, el tiempo de respuesta es 2-3 veces menor, la carga total del sistema es 2 veces menor.
Indice
Pero no es suficiente para poder almacenar bloques; debe mantener un índice de bloques de pistas de música a bloques en el disco.

Resultó ser bastante compacto, una entrada de índice solo toma 29 bytes. Para un almacenamiento de 10 TB, el índice es un poco más de 1 GB.
Hay un punto interesante aquí. En cada uno de estos registros, debe almacenar el tamaño total de toda la pista. Este es un ejemplo clásico de desnormalización. La razón es que, de acuerdo con la especificación en la respuesta de rango HTTP, debemos devolver el tamaño total del recurso, así como formar un encabezado de longitud de contenido. Si no fuera así, entonces todo sería aún más compacto.
Formulamos una serie de requisitos para el índice: trabajar rápidamente (preferiblemente, almacenado en la RAM), ser compacto y no ocupar espacio en la memoria caché de la página. Otro índice debe ser persistente. Si lo perdemos, perderemos información sobre en qué lugar del disco se almacena la pista, y esto equivale a limpiar los discos. Y en general, me gustaría que los viejos bloques, a los que no se haya accedido durante mucho tiempo, se suplanten de alguna manera, dejando espacio para pistas más populares. Hemos elegido la
política de exclusión de LRU : los bloques se eliminan una vez por minuto, el 1% de los bloques se mantienen libres. Por supuesto, la estructura del índice debe ser segura para subprocesos, porque tenemos 100 mil conexiones por nodo.
SharedMemoryFixedMap de nuestra biblioteca de código abierto
one-nio cumple todas estas condiciones de manera ideal.
Ponemos el índice en
tmpfs , funciona rápidamente, pero hay un matiz. Cuando la máquina se reinicia, todo lo que estaba en
tmpfs , incluido el índice, se pierde. Además, si debido al
sun.misc.Unsafe nuestro proceso se bloqueó, no está claro en qué estado se mantuvo el índice. Por lo tanto, hacemos una impresión de esto una vez por hora. Pero esto no es suficiente: dado que usamos extrusión de bloques, tenemos que admitir
WAL , en el que escribimos información sobre bloques extruidos. Las entradas sobre bloques en yesos y WAL deben clasificarse de alguna manera durante la recuperación. Para hacer esto, usamos el bloque de generación. Desempeña el papel de un contador de transacciones globales y se incrementa cada vez que cambia el índice. Veamos un ejemplo de cómo funciona esto.
Tome un índice con tres entradas: dos bloques de la pista No. 1 y un bloque de la pista No. 2.
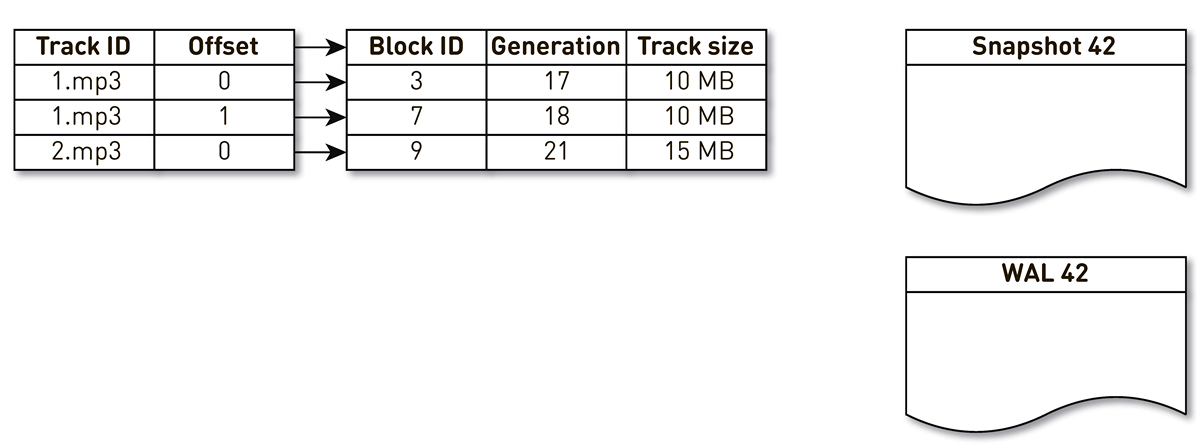
La corriente de creación de moldes se despierta e itera mediante este índice: la primera y segunda tuplas caen en el elenco. Luego, el flujo de aglomeración se vuelve hacia el índice, se da cuenta de que no se ha accedido al séptimo bloque durante mucho tiempo y decide usarlo para otra cosa. El proceso fuerza el bloqueo y escribe un registro en el WAL. Llega al bloque 9, ve que no ha sido contactado por mucho tiempo y también lo señala como desplazado. Aquí el usuario accede al sistema y se produce una pérdida de caché: se solicita una pista que no tenemos. Guardamos el bloque de esta pista en nuestro repositorio, sobrescribiendo el bloque 9. En este caso, la generación se incrementa y se vuelve igual a 22. Luego, se activa el proceso de creación de un molde, que no ha completado su trabajo, alcanza el último registro y lo escribe en el molde. Como resultado, tenemos dos registros en vivo en el índice, un elenco y WAL.
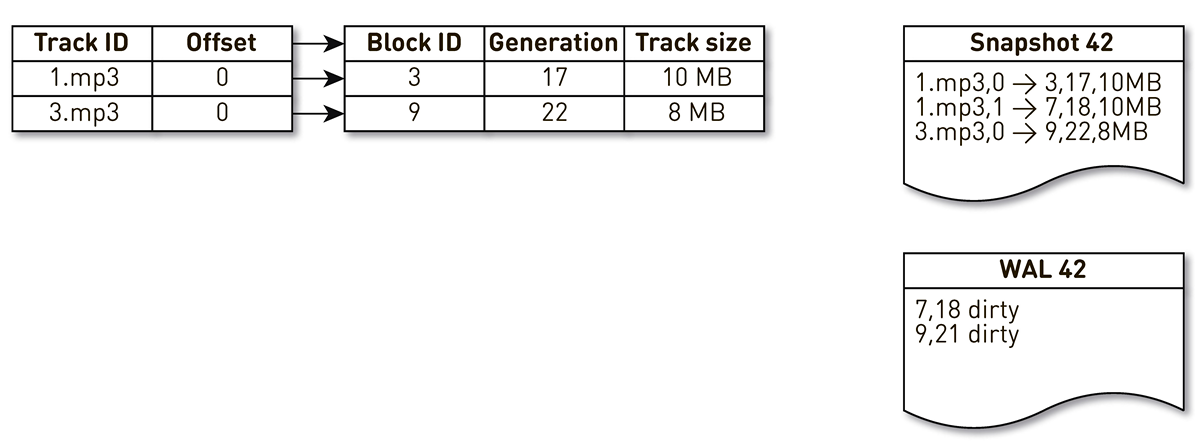
Cuando el nodo actual cae, restaurará el estado inicial del índice de la siguiente manera. Primero, escanee el WAL y construya un mapa de bloques sucio. La tarjeta almacena el mapeo desde el número de bloque hasta la generación cuando este bloque fue suplantado.
Después de eso, comenzamos a iterar sobre el molde usando el mapa como filtro. Observamos el primer registro del elenco, se relaciona con el bloque número 3. No se lo menciona entre los sucios, lo que significa que está vivo y entra en el índice. Llegamos al bloque número 7 con la décimo octava generación, pero el mapa de bloques sucios nos dice que solo en la generación 18 el bloque se desplazó. Por lo tanto, no cae en el índice. Llegamos al último registro, que describe el contenido del bloque 9 con 22 generaciones. Este bloque se menciona en el mapa de bloques sucios, pero fue suplantado anteriormente. Por lo tanto, se reutiliza para nuevos datos y entra en el índice. El objetivo se logra.
Optimizaciones
Pero eso no es todo, vamos más abajo.
Comencemos con el caché de la página. Inicialmente contamos con él, pero cuando comenzamos a realizar pruebas de carga de la primera versión,
resultó que la tasa de aciertos de la caché de la página no alcanzó el 20%. Sugirieron que el problema se lea con anticipación: no almacenamos archivos, sino bloques, mientras servimos un montón de conexiones, y en esta configuración, trabajar con el disco es aleatoriamente eficiente. Casi nunca leemos nada secuencialmente. Afortunadamente, en Linux hay una llamada
posix_fadvise que le permite decirle al kernel cómo vamos a trabajar con el descriptor de archivo; en particular, podemos decir que no necesitamos leer con anticipación pasando el indicador
POSIX_FADV_RANDOM . Esta llamada al sistema está disponible a través de
one-nio . En funcionamiento, nuestro acierto de caché es 70-80%. El número de lecturas físicas de los discos disminuyó en más de 2 veces, el retraso en la respuesta HTTP disminuyó en un 20%.
Vamos más allá. El servicio tiene un tamaño de almacenamiento dinámico bastante grande. Para facilitar la vida de los cachés TLB del procesador, decidimos incluir páginas enormes para nuestro proceso Java. Como resultado, obtuvimos una ganancia notable por el tiempo de recolección de basura (GC Time / Safepoint Total Time es 20-30% menor), la carga del kernel se volvió más uniforme, pero no notó ningún efecto en los gráficos de latencia HTTP.Incidente
Poco después de que comenzara el servicio, ocurrió el único incidente (hasta ahora).Una tarde después del final de la jornada laboral, las quejas sobre la reproducción de música generaron apoyo. Los usuarios escribieron que incluyeron su pista favorita, pero cada pocos segundos escucharon música extraña de otros tiempos y personas, y el jugador les dijo que reproducía su pista favorita. Bastante rápidamente redujo el círculo de búsqueda a un auto, lo que dio algo extraño. Descubrimos por los registros que recientemente se reinició. Para simplificar, teníamos dos discos e índices que describían el contenido de los bloques. Un índice dice que el cuarto bloque de la pista Daft Punk se encuentra en el bloque número 2 del disco sdc, y el bloque cero de la pista Stas Mikhailov se encuentra en el bloque cero del disco sdd.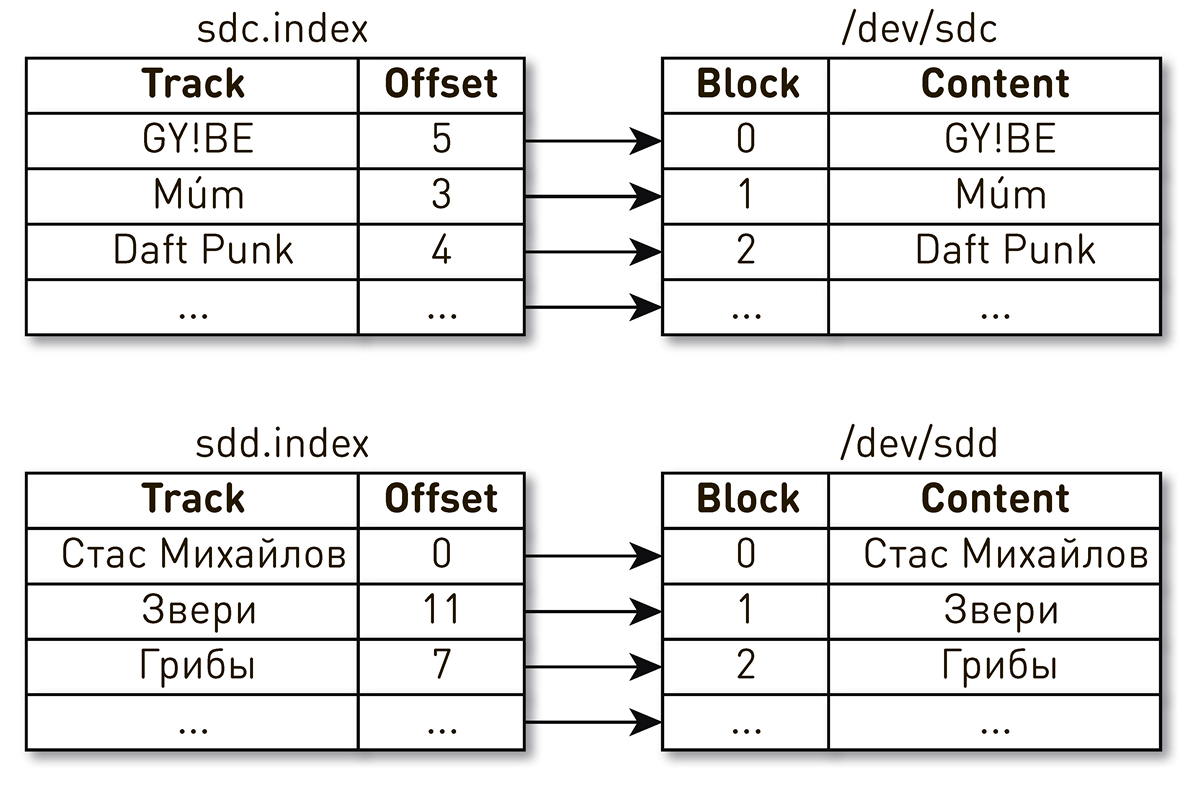
, . Linux
: , .

. ID.
WWN , WAL. , , .
El análisis de problemas en tales sistemas distribuidos es difícil porque la solicitud de un usuario pasa por muchas etapas y cruza los límites de los nodos. En el caso de CDN, todo se vuelve aún más complicado, porque para CDN, el upstream es el centro de datos del hogar. Puede haber muchas de esas esperanzas. Además, el sistema sirve a cientos de miles de conexiones de usuarios. Es bastante difícil entender en qué etapa hay un problema al procesar una solicitud de un usuario específico.Simplificamos nuestras vidas así. Al iniciar sesión, marcamos todas las solicitudes con una etiqueta similar a Open Tracing y Zipkin . , . , , HTTP- . , , , , , , .
. , : , , .
ByteBuffer buffer = ByteBuffer.allocate(size); int count = fileChannel.read(buffer, position); if (count <= 0) {
, :
FileChannel.read() kernel space user space;SocketChannel.write() , user space kernel space.
, Linux
sendfile() , , user space. ,
one-nio . ,
sendfile() — 10 /
sendfile() 0.
user-space SSL-
sendfile() , . .
SocketChannel FileChannel ,
Async Profiler ,
sun.nio.ch.IOUtil ,
read() write() . .
ByteBuffer bb = Util.getTemporaryDirectBuffer(dst.remaining()); try { int n = readIntoNativeBuffer(fd, bb, position, nd); bb.flip(); if (n > 0) dst.put(bb); return n; } finally { Util.offerFirstTemporaryDirectBuffer(bb); }
. heap
ByteBuffer , , , heap
ByteBuffer , . .
.
one-nio .
MallocMT — , . SSL , Java heap,
ByteBuffer ,
FileChannel . .
final Allocator allocator = new MallocMT(size, concurrency); int write(Socket socket) { if (socket.getSslContext() != null) { long address = allocator.malloc(size); ByteBuffer buf = DirectMemory.wrap(address, size); int available = channel.read(buf, offset); socket.writeRaw(address, available, flags);
100 000
Pero el éxito del sistema no está garantizado por una implementación razonable en los niveles inferiores. Hay otro problema aquí. El transportador en cada nodo sirve hasta 100 mil conexiones simultáneas. ¿Cómo organizar los cálculos en tal sistema?Lo primero que viene a la mente es crear un hilo de ejecución para cada cliente o conexión, y en él realizamos las etapas de canalización una tras otra. Si es necesario, bloquee, luego continúe. Pero con tal esquema, los costos de los cambios de contexto y las pilas de flujos serán excesivos, ya que estamos hablando de un distribuidor y muchos flujos. Por lo tanto, fuimos por el otro lado.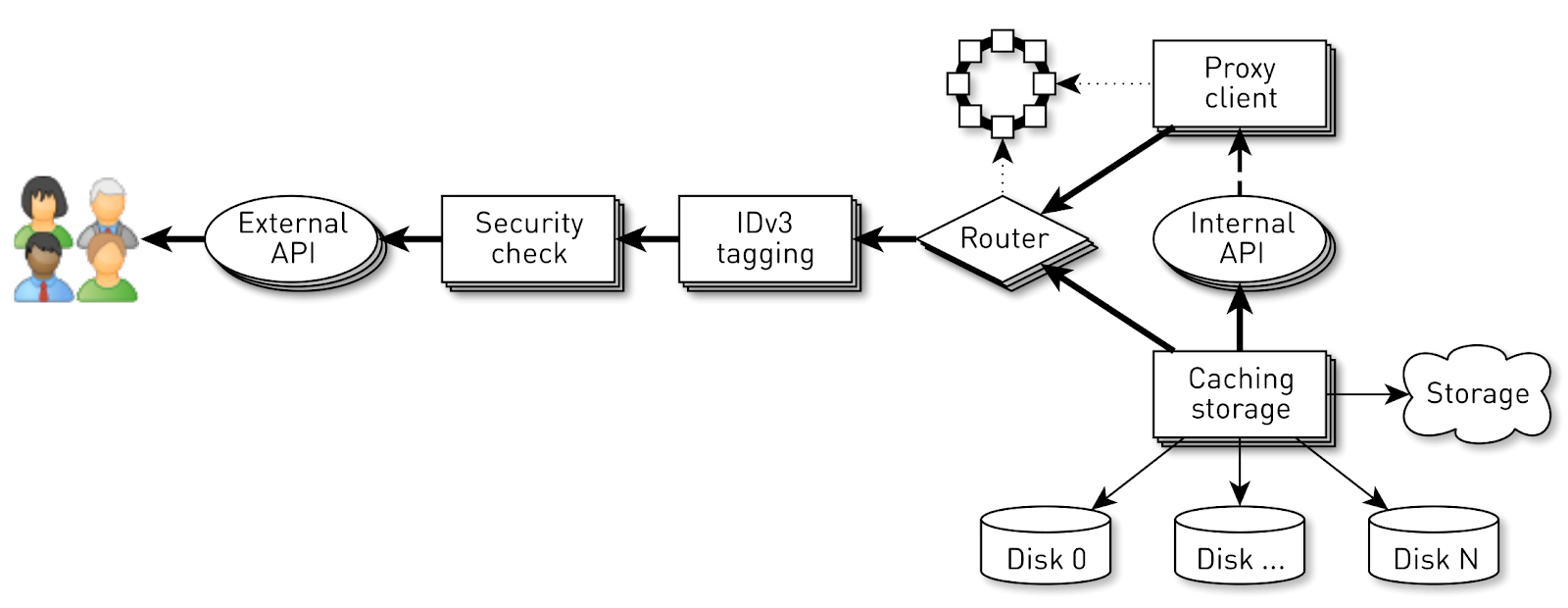 Se crea una tubería lógica para cada conexión, que consiste en etapas que interactúan entre sí de forma asincrónica. Cada etapa tiene un turno que almacena las solicitudes entrantes. Para la ejecución de etapas, se utilizan pequeños grupos de subprocesos comunes. Si necesita procesar un mensaje de la cola de solicitudes, tomamos una secuencia del grupo, procesamos el mensaje y devolvemos la secuencia al grupo. Con este esquema, los datos se envían desde el almacenamiento al cliente.Pero tal esquema no está exento de defectos. Los backends son mucho más rápidos que las conexiones de usuario. Cuando los datos pasan a través de la tubería, se acumulan en la etapa más lenta, es decir. en la etapa de escribir bloques en el socket de conexión del cliente. Tarde o temprano, esto conducirá al colapso del sistema. Si intenta limitar las colas en estas etapas, entonces todo se detendrá instantáneamente, porque las tuberías en la cadena al zócalo del usuario se bloquearán. Y dado que usan grupos de hilos compartidos, bloquearán todos los hilos en ellos. Necesita contrapresión.Para hacer esto, usamos corrientes en chorro. La esencia del enfoque es que el suscriptor controla la velocidad de los datos provenientes del editor utilizando la demanda. La demanda significa la cantidad de datos que el suscriptor está listo para procesar junto con la demanda anterior que ya ha señalado. El editor tiene derecho a enviar datos, pero sin exceder la demanda acumulada total en este momento, menos los datos ya enviados.Por lo tanto, el sistema cambia dinámicamente entre los modos push y pull. En modo push, el suscriptor es más rápido que el editor, lo que significa que el editor siempre tiene una demanda insatisfecha del suscriptor, pero no tiene datos. Tan pronto como aparecen los datos, los envía inmediatamente al suscriptor. El modo de extracción ocurre cuando el editor es más rápido que el suscriptor. Es decir, el editor estaría encantado de enviar datos, solo la demanda es cero. Tan pronto como el suscriptor dice que está listo para procesar un poco más, el editor inmediatamente le envía un dato como parte de la demanda.Nuestro transportador se convierte en una corriente en chorro. Cada etapa se convierte en editor de la etapa anterior y suscriptor de la siguiente.La interfaz de las corrientes en chorro se ve extremadamente simple.
Se crea una tubería lógica para cada conexión, que consiste en etapas que interactúan entre sí de forma asincrónica. Cada etapa tiene un turno que almacena las solicitudes entrantes. Para la ejecución de etapas, se utilizan pequeños grupos de subprocesos comunes. Si necesita procesar un mensaje de la cola de solicitudes, tomamos una secuencia del grupo, procesamos el mensaje y devolvemos la secuencia al grupo. Con este esquema, los datos se envían desde el almacenamiento al cliente.Pero tal esquema no está exento de defectos. Los backends son mucho más rápidos que las conexiones de usuario. Cuando los datos pasan a través de la tubería, se acumulan en la etapa más lenta, es decir. en la etapa de escribir bloques en el socket de conexión del cliente. Tarde o temprano, esto conducirá al colapso del sistema. Si intenta limitar las colas en estas etapas, entonces todo se detendrá instantáneamente, porque las tuberías en la cadena al zócalo del usuario se bloquearán. Y dado que usan grupos de hilos compartidos, bloquearán todos los hilos en ellos. Necesita contrapresión.Para hacer esto, usamos corrientes en chorro. La esencia del enfoque es que el suscriptor controla la velocidad de los datos provenientes del editor utilizando la demanda. La demanda significa la cantidad de datos que el suscriptor está listo para procesar junto con la demanda anterior que ya ha señalado. El editor tiene derecho a enviar datos, pero sin exceder la demanda acumulada total en este momento, menos los datos ya enviados.Por lo tanto, el sistema cambia dinámicamente entre los modos push y pull. En modo push, el suscriptor es más rápido que el editor, lo que significa que el editor siempre tiene una demanda insatisfecha del suscriptor, pero no tiene datos. Tan pronto como aparecen los datos, los envía inmediatamente al suscriptor. El modo de extracción ocurre cuando el editor es más rápido que el suscriptor. Es decir, el editor estaría encantado de enviar datos, solo la demanda es cero. Tan pronto como el suscriptor dice que está listo para procesar un poco más, el editor inmediatamente le envía un dato como parte de la demanda.Nuestro transportador se convierte en una corriente en chorro. Cada etapa se convierte en editor de la etapa anterior y suscriptor de la siguiente.La interfaz de las corrientes en chorro se ve extremadamente simple. Publishervamos a firmarSubscriber , y solo debe implementar cuatro controladores: interface Publisher<T> { void subscribe(Subscriber<? super T> s); } interface Subscriber<T> { void onSubscribe(Subscription s); void onNext(T t); void onError(Throwable t); void onComplete(); } interface Subscription { void request(long n); void cancel(); }
Subscription le permite señalar la demanda y darse de baja. En ninguna parte es más fácil.
Como elemento de datos, no pasamos matrices de bytes, sino una abstracción como un fragmento. Hacemos esto para no arrastrar los datos en el montón, si es posible. Chunk es un enlace de datos con una interfaz muy limitada que le permite solo leer datos ByteBuffer, escribir en un socket o en un archivo. interface Chunk { int read(ByteBuffer dst); int write(Socket socket); void write(FileChannel channel, long offset); }
Hay muchas implementaciones de fragmentos:- El más popular, que se utiliza en el caso de aciertos de caché y al enviar datos desde el disco, es la implementación en la parte superior
RandomAccessFile. El fragmento contiene solo un enlace al archivo, el desplazamiento en este archivo y el tamaño de los datos. Atraviesa toda la tubería, llega a la toma de conexión del usuario y allí se convierte en una llamada sendfile(). Es decir, la memoria no se consume en absoluto. - cache miss : . , — , , — .
- , - heap.
ByteBuffer .
A pesar de la simplicidad de esta API, debe ser segura para subprocesos por especificación, y la mayoría de los métodos deben ser sin bloqueo. Elegimos el camino en el espíritu del Modelo de actor mecanografiado, inspirado en ejemplos del repositorio oficial de jet stream . Para hacer que las llamadas a métodos no sean bloqueadas, cuando llamamos al método, tomamos todos los parámetros, lo envolvemos en un mensaje, lo ponemos en la cola para su ejecución y devolvemos el control. Los mensajes de la cola se procesan estrictamente secuencialmente.Sin sincronización, el código es simple y directo.. publisher subscriber , , executor, .
AtomicBoolean happens before .
:
@Override void request(final long n) { enqueue(new Request(n)); } void enqueue(final M message) { mailbox.offer(message); tryScheduleToExecute(); }
tryScheduleToExecute() :
if (on.compareAndSet(false, true)) { try { executor.execute(this); } catch (Exception e) { ... } }
run() :
if (on.get()) try { dequeueAndProcess(); } finally { on.set(false); if (!messages.isEmpty()) { tryScheduleToExecute(); } } }
dequeueAndProcess() :
M message; while ((message = mailbox.poll()) != null) {
Tenemos una implementación completamente sin bloqueo. código simple y consistente, sin volatile, Atomic*, contención, y otros. En todo nuestro sistema, hay un total de 200 hilos para servir 100,000 conexiones.Al final
En producción, tenemos 12 máquinas, mientras que hay más de un doble margen en el ancho de banda. Cada máquina en modo normal proporciona hasta 10 Gbit / s a través de cientos de miles de conexiones. Hemos proporcionado escalabilidad y resistencia. Todo está escrito en Java y one-nio .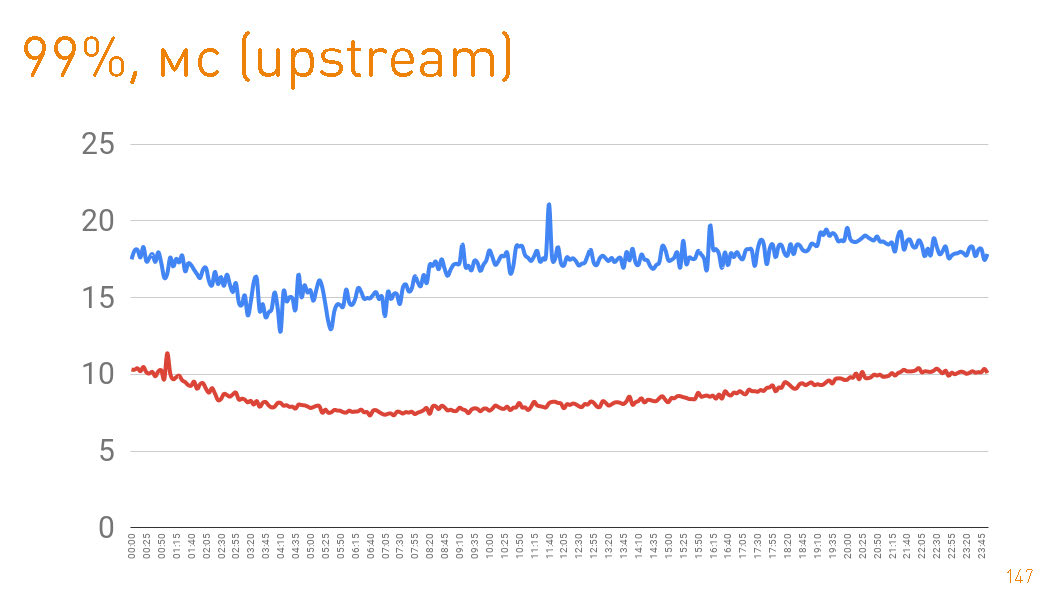 Este es un gráfico hasta el primer byte dado al usuario desde el lado del servidor. Percentil 99 menos de 20 ms. El gráfico azul es el retorno de los datos HTTPS al usuario. El gráfico rojo es el retorno de datos de la réplica al proxy a través de
Este es un gráfico hasta el primer byte dado al usuario desde el lado del servidor. Percentil 99 menos de 20 ms. El gráfico azul es el retorno de los datos HTTPS al usuario. El gráfico rojo es el retorno de datos de la réplica al proxy a través de sendfile()HTTP.En realidad, el impacto de caché en producción es del 97%, por lo que los gráficos describen la latencia de nuestro repositorio de pistas, del cual extraemos datos en caso de errores de caché, lo que tampoco es malo, considerando los petabytes de datos.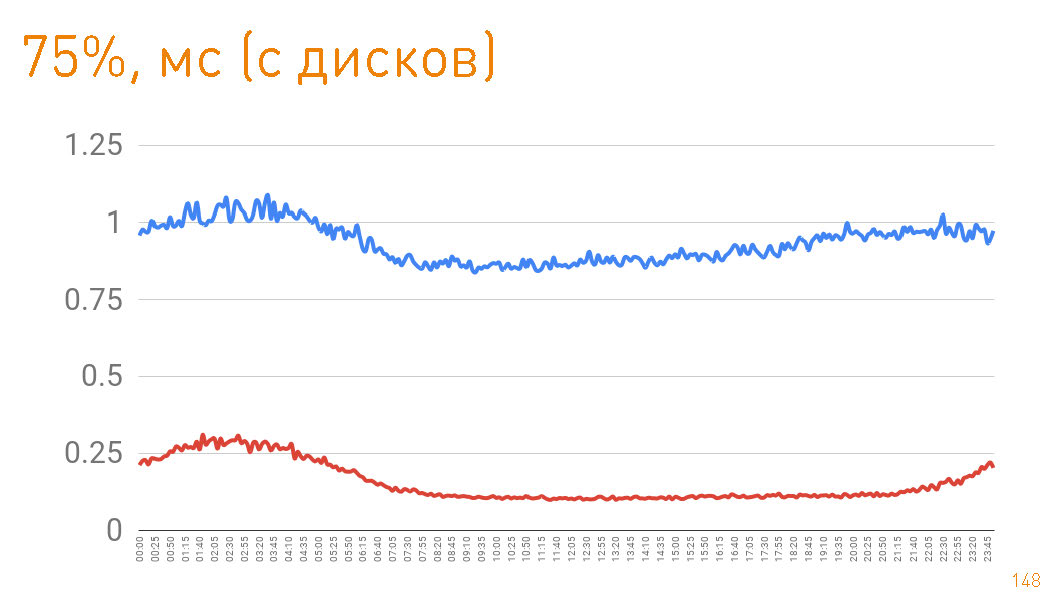
75- , 1 . — 300 . Es decir 0.7 — .
, , , . , .