Recientemente,
hablamos sobre cómo obtener una pasantía en Google. Además de Google, nuestros estudiantes prueban suerte en JetBrains, Yandex, Acronis y otras compañías.
En este artículo compartiré mi experiencia de pasantías en
JetBrains Research , hablaré sobre las tareas que resuelven allí y me detendré en cómo el aprendizaje automático puede buscar errores en el código del programa.

Sobre mi
Mi nombre es Egor Bogomolov, soy un estudiante de cuarto año de la licenciatura de San Petersburgo HSE en Matemática Aplicada y Ciencias de la Computación. Durante los primeros 3 años, yo, como mis compañeros de clase, estudié en la Universidad Académica, y desde septiembre nos hemos mudado a la Escuela Superior de Economía con todo el departamento.
Después del segundo año, realicé una pasantía de verano en Google Zurich. Allí pasé tres meses trabajando en el equipo de Android Calendar, la mayoría del tiempo haciendo frontend'om y un poco de investigación UX. La parte más interesante de mi trabajo fue investigar cómo se verían las interfaces de calendario en el futuro. Resultó ser agradable que casi todo el trabajo que hice al final de la pasantía terminó en la versión principal de la aplicación. Pero el tema de las pasantías en Google está muy bien cubierto en una publicación anterior, así que hablaré sobre lo que hice este verano.
¿Qué es JB Research?
JetBrains Research es un conjunto de laboratorios que trabajan en varios campos: lenguajes de programación, matemática aplicada, aprendizaje automático, robótica y otros. Dentro de cada área hay varios grupos científicos. Debido a mi dirección, conozco mejor las actividades de los grupos en el campo del aprendizaje automático. Cada uno de ellos organiza seminarios semanales en los que los miembros del grupo o invitados invitan a hablar sobre su trabajo o artículos interesantes en su campo. Muchos estudiantes del HSE vienen a estos seminarios, ya que cruzan la calle desde el edificio principal del Campus HSE en San Petersburgo.
En nuestro programa de licenciatura, estamos necesariamente involucrados en trabajos de investigación (I + D) y presentamos los resultados de la investigación dos veces al año. A menudo, este trabajo se convierte gradualmente en pasantías de verano. Esto también sucedió con mi trabajo de investigación: este verano hice una pasantía en el laboratorio "Métodos de aprendizaje automático en ingeniería de software" con mi supervisor de investigación Timofey Bryksin. Las tareas que se están trabajando en este laboratorio incluyen sugerencias de refactorización automática, análisis del estilo de código para programadores, finalización de código y búsqueda de errores en el código del programa.
Mi pasantía duró dos meses (julio y agosto), y en el otoño seguí participando en tareas asignadas en el marco de la investigación. Trabajé en varias áreas, la más interesante de ellas, en mi opinión, fue la búsqueda automática de errores en el código, y quiero hablar sobre ello. El punto de partida fue
un artículo de Michael Pradel .
Búsqueda automática de errores
¿Cómo se buscan los errores ahora?
Por qué buscar errores es más o menos claro. Veamos cómo les va ahora. Los detectores de errores modernos se basan principalmente en el análisis de código estático. Para cada tipo de error, busque patrones notados previamente por los cuales pueda determinarse. Luego, para reducir el número de falsos positivos, se inventan heurísticas, inventadas para cada caso individual. Se pueden buscar patrones tanto en un árbol de sintaxis abstracta (AST) construido por código como en gráficos de un flujo de control o datos.
int foo() { if ((x < 0) || x > MAX) { return -1; } int ret = bar(x); if (ret != 0) { return -1; } else { return 1; } }
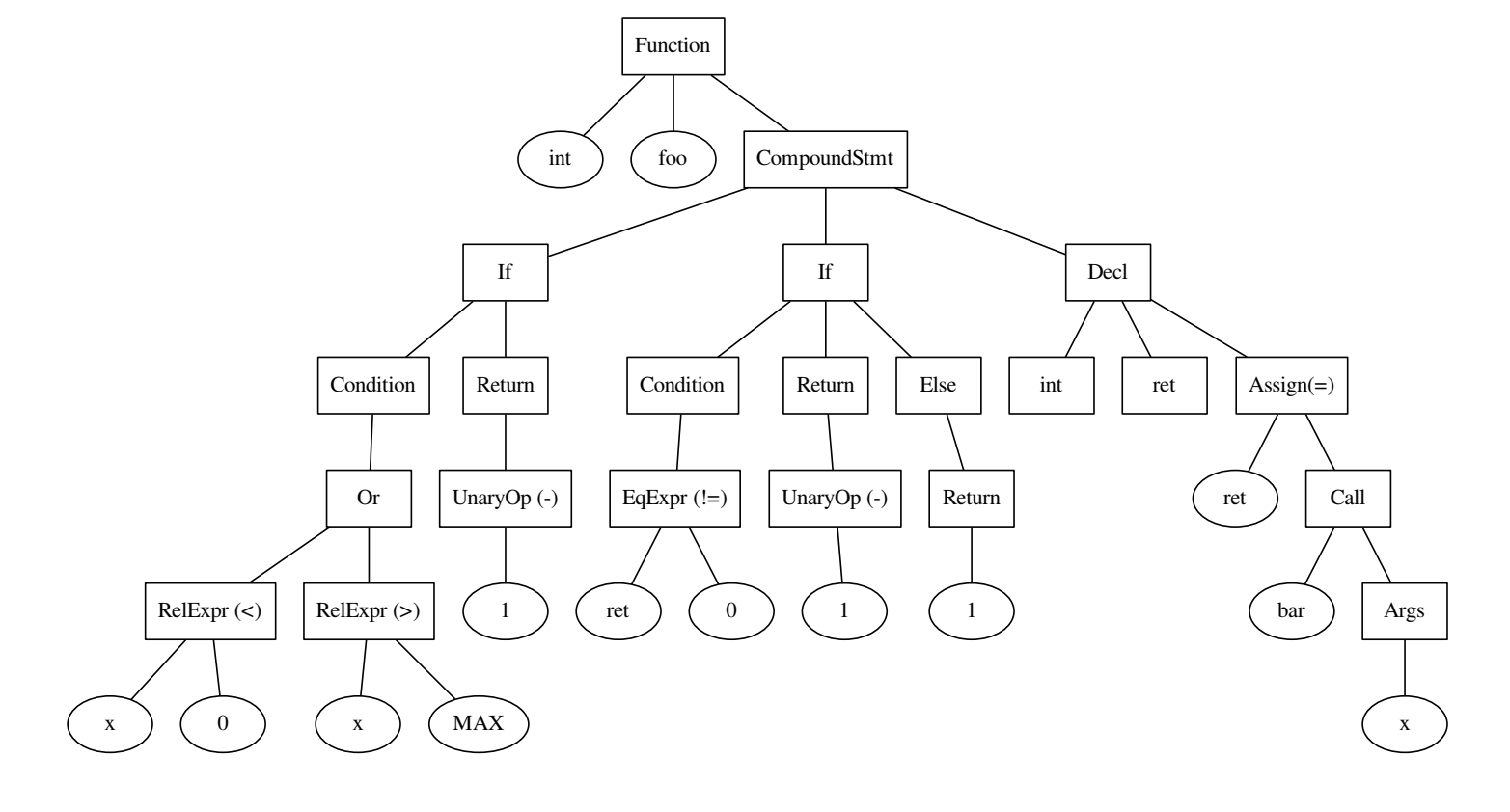
El código y el árbol que se construyó sobre él.
Para entender cómo funciona esto, considere un ejemplo. El tipo de errores puede ser el uso de = en lugar de == en C ++. Veamos el siguiente fragmento de código:
int value = 0; … if (value = 1) { ... } else { … }
Hubo un error en la expresión condicional, mientras que el primer = en la asignación del valor a la variable es correcto. El patrón viene de aquí: si la asignación se usa dentro de la condición en if, esto es un error potencial. Buscando dicho patrón en AST, podemos detectar el error y corregirlo.
int value = 0; … if (value == 1) { ... } else { … }
En un caso más general, no podremos encontrar tan fácilmente una manera de describir el error. Supongamos que queremos determinar el orden correcto de los operandos. De nuevo, mira los fragmentos de código:
for (int i = 2; i < n; i++) { a[i] = a[1 - i] + a[i - 2]; }
int bitReverse(int i) { return 1 - i; }
En el primer caso, el uso de 1-i fue erróneo, y en el segundo fue completamente correcto, lo cual es claro por el contexto. Pero, ¿cómo describirlo en forma de patrón? Con la complicación del tipo de errores, tenemos que considerar una sección más grande de código y analizar más y más casos individuales.
El último ejemplo motivador: la información útil también está contenida en los nombres de métodos y variables. Es aún más difícil de expresar por algunas condiciones especificadas manualmente.
int getSquare(int xDim, int yDim) { … } int x = 3, y = 4; int s = getSquare(y, x);
Una persona entiende que, muy probablemente, los argumentos en la llamada a la función están mezclados, porque tenemos un entendimiento de que x es más como xDim que yDim. Pero, ¿cómo informar esto al detector? Puede agregar algunas heurísticas de la forma "el nombre de la variable es el prefijo del nombre del argumento", pero suponga que x es más a menudo un ancho que una altura, por lo que ya no se expresa.
En pocas palabras: el problema del enfoque moderno para encontrar errores es que se debe hacer mucho trabajo con las manos: para determinar patrones, agregar heurísticas, por eso, agregar soporte para un nuevo tipo de error en el detector se vuelve lento. Además, es difícil usar una parte importante de la información que el desarrollador dejó en el código: los nombres de las variables y los métodos.
¿Cómo puede ayudar el aprendizaje automático?
Como habrás notado, en muchos ejemplos los errores son visibles para los humanos, pero son difíciles de describir formalmente. En tales situaciones, los métodos de aprendizaje automático a menudo pueden ayudar. Dejemos de buscar argumentos reorganizados en una llamada de función y comprendamos qué necesitamos buscarlos mediante el aprendizaje automático:
- Una gran cantidad de código de muestra sin errores
- Una gran cantidad de código con errores de un tipo dado
- Método para vectorizar fragmentos de código
- El modelo que enseñaremos para distinguir entre código con y sin errores
Podemos esperar que en la mayoría de los códigos establecidos en el dominio público, los argumentos en las llamadas a funciones estén en el orden correcto. Por lo tanto, para el código de muestra sin errores, puede tomar un gran conjunto de datos. En el caso del autor del artículo original, era JS 150K (150 mil archivos en Javascript), en nuestro caso, un conjunto de datos similar para Python.
Encontrar código con errores es mucho más difícil. Pero no podemos buscar los errores de otra persona, ¡pero hazlos tú mismo! Para el tipo de errores, debe especificar una función que, de acuerdo con el código correcto, la corromperá. En nuestro caso, reorganice los argumentos en la llamada a la función.
¿Cómo vectorizar el código?
Armados con muchos códigos buenos y malos, estamos casi listos para enseñar algo. Antes de eso, todavía tenemos que responder la pregunta: ¿cómo presentar fragmentos de código?
Una llamada de función se puede representar como una tupla del nombre de un método, el nombre de quién es el método, los nombres y los tipos de argumentos pasados a las variables. Si aprendemos cómo vectorizar tokens individuales (nombres de variables y métodos, todas las "palabras" encontradas en el código), podemos tomar la concatenación de vectores de tokens de interés para nosotros y obtener el vector deseado para el fragmento.
Para vectorizar tokens, echemos un vistazo a cómo se vectorizan las palabras en los textos ordinarios. Una de las formas más exitosas y populares es la word2vec propuesta en 2013.
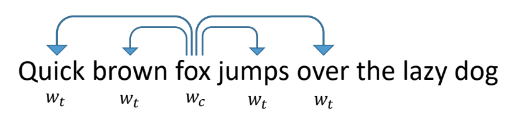
Funciona de la siguiente manera: enseñamos a la red a predecir por palabras otras palabras que aparecen junto a ella en los textos. Al mismo tiempo, la red parece una capa de entrada del tamaño de un diccionario, una capa oculta del tamaño de la vectorización que queremos obtener y una capa de salida, también del tamaño de un diccionario. Durante el entrenamiento, las redes se alimentan con un vector de unidad de entrada con una unidad en lugar de la palabra en cuestión (zorro), y en la salida queremos obtener las palabras que aparecen dentro de la ventana alrededor de esta palabra (rápido, marrón, saltos, sobre). En este caso, la red primero traduce todas las palabras en un vector en una capa oculta, y luego hace una predicción.
Los vectores resultantes para palabras individuales tienen buenas propiedades. Por ejemplo, los vectores de palabras con un significado similar están cerca uno del otro, y la suma y la diferencia de los vectores son la suma y la diferencia de los "significados" de las palabras.
Para hacer una vectorización similar de tokens en el código, debe configurar de alguna manera el entorno que se predecirá. Pueden ser información de AST: tipos de vértices alrededor, tokens encontrados, posición en un árbol.
Después de recibir una vectorización, puede ver qué fichas son similares entre sí. Para hacer esto, calcule la distancia del coseno entre ellos. Como resultado, se obtienen los siguientes vectores vecinos para Javascript (el número es la distancia del coseno):
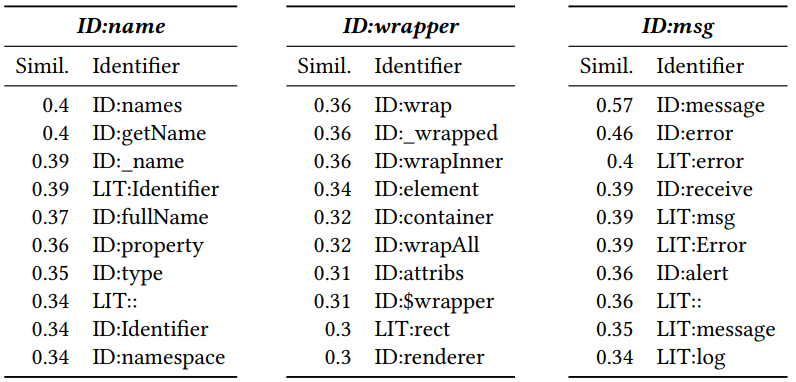
El ID y LIT agregados al principio indican si el token es un identificador (nombre de una variable, método) o un literal (constante). Se puede ver que la proximidad es significativa.
Clasificador de entrenamiento
Habiendo recibido una vectorización para tokens individuales, obtener una vista de un fragmento de código con un posible error es bastante simple: es una concatenación de vectores importantes para la clasificación de tokens. Un perceptrón de dos capas está entrenado en piezas de código con ReLU como función de activación y caída para reducir el sobreajuste. El aprendizaje converge rápidamente, el modelo resultante es pequeño y puede hacer predicciones para cientos de ejemplos por segundo. Esto le permite usarlo en tiempo real, lo cual se discutirá más adelante.
Resultados
La evaluación de calidad del clasificador resultante se dividió en dos partes: una evaluación en un gran número de ejemplos generados artificialmente y verificación manual en un pequeño número (50 para cada detector) de ejemplos con la mayor probabilidad pronosticada. Los resultados para los tres detectores (argumentos reorganizados, la corrección del operador binario y el operando binario) fueron los siguientes:
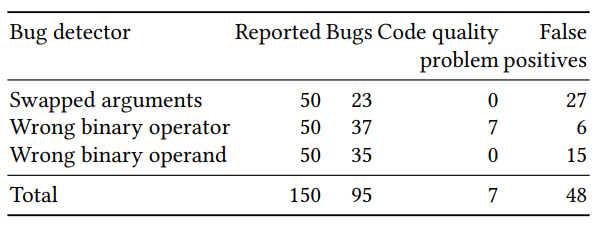
Algunos de los errores predichos serían difíciles de encontrar con los métodos de búsqueda clásicos. Un ejemplo con res reorganizado y err en una llamada a p.done:
var p = new Promise (); if ( promises === null || promises . length === 0) { p. done (error , result ) } else { promises [0](error, result).then( function(res, err) { p.done(res, err); }); }
También hubo ejemplos en los que no hubo error, pero las variables se deben cambiar de nombre para no confundir a la persona que intenta descifrar el código. Por ejemplo, agregar ancho y cada uno no parece ser una buena idea, aunque resultó no ser un error:
var cw = cs[i].width + each;
Python porting
Participé en la transferencia del trabajo de Michael Pradel de js a python, y luego creé un complemento para PyCharm que implementa inspecciones basadas en el método anterior. Utilizamos el conjunto de datos
Python 150K (150 mil archivos Python disponibles en GitHub).
Primero, resultó que en Python hay más tokens diferentes que en javascript. Para js, los 10,000 tokens más populares representaron más del 90% de todos los encontrados, mientras que para Python fue necesario usar alrededor de 40,000, lo que condujo a un aumento en el tamaño de los tokens en los vectores, lo que dificultó la transferencia al complemento.
En segundo lugar, habiendo implementado para Python una búsqueda de argumentos incorrectos en las llamadas de función y mirando los resultados manualmente, obtuve una tasa de error de más del 90%, que estaba en desacuerdo con los resultados para js. Habiendo entendido las razones, resultó que en javascript se declararon más funciones en el mismo archivo que sus llamadas. Yo, siguiendo el ejemplo del autor del artículo, al principio no permití la declaración de funciones de otros archivos, lo que condujo a malos resultados.
Hacia finales de agosto, completé la implementación de Python y escribí la base del complemento. El complemento continúa desarrollándose, ahora la estudiante Anastasia Tuchina de nuestro laboratorio se dedica a esto.
Puede encontrar los pasos para probar cómo funciona el complemento en el wiki del repositorio.
Enlaces en github:
Repositorio con implementación de pythonRepositorio con plugin