En este artículo, simulamos y examinamos un protocolo de confirmación de dos fases usando TLA +.
El protocolo de confirmación de dos fases es práctico y se usa hoy en muchos sistemas distribuidos. Sin embargo, es bastante corto. Por lo tanto, podemos modelarlo rápidamente y aprender mucho. De hecho, con este ejemplo ilustraremos qué resultado en sistemas distribuidos es
fundamentalmente imposible .
El problema de compromiso bifásico
La transacción pasa a través de
los administradores de recursos (RM) . Todos los RM deben acordar si la transacción se
completará o
cancelará .
Transaction Manager (TM) toma la decisión final:
comprometer o
cancelar . La condición para el compromiso es la voluntad de comprometer todos los RM. De lo contrario, la transacción debería cancelarse.
Algunas notas sobre modelado
Para simplificar, realizamos simulaciones en un modelo de memoria compartida, no en un sistema de mensajería. También proporciona una validación rápida del modelo. Pero agregaremos no atomicidad a las acciones "leer desde el nodo vecino y actualizar el estado" para capturar un comportamiento interesante al enviar mensajes.
RM solo puede leer el estado de TM y leer / actualizar su propio estado. No puede leer el estado de otro administrador de recursos. Un TM puede leer el estado de todos los nodos RM y leer / actualizar su propio estado.
Definiciones

Las líneas 9-10 establecen el
rmState inicial para que cada RM
working y TM para
init .
El predicado
canCommit es
true si todos los RM están "preparados" (listos para comprometerse). Si RM existe en el estado final, el predicado
canAbort vuelve
canAbort .

Modelado TM es simple. El administrador de transacciones verifica la posibilidad de una confirmación o cancelación, y en consecuencia actualiza
tmState .
Existe la posibilidad de que TM no pueda hacer que
tmState "inaccesible", pero solo si la constante
TMMAYFAIL establece en
true antes de validar el modelo. En las etiquetas TLA + se determina el grado de atomicidad, es decir, su granularidad. Mediante las etiquetas F1 y F2, indicamos que los operadores correspondientes se realizan de forma no atómica (después de un tiempo indefinido) con respecto a los operadores anteriores.
Modelo RM

El modelo RM también es simple. Dado que los estados "de trabajo" y "preparados" no son definitivos, RM elige de forma no determinista entre las acciones hasta que alcanza el estado final. Un RM "en funcionamiento" puede entrar en un estado "interrumpido" o "preparado". RM "preparado" espera un compromiso / cancelación de TM - y actúa en consecuencia. La siguiente figura muestra las posibles transiciones de estado para un RM. Pero tenga en cuenta que tenemos varios RM, cada uno de los cuales pasa por sus estados a su propio ritmo sin conocer el estado de los otros RM.
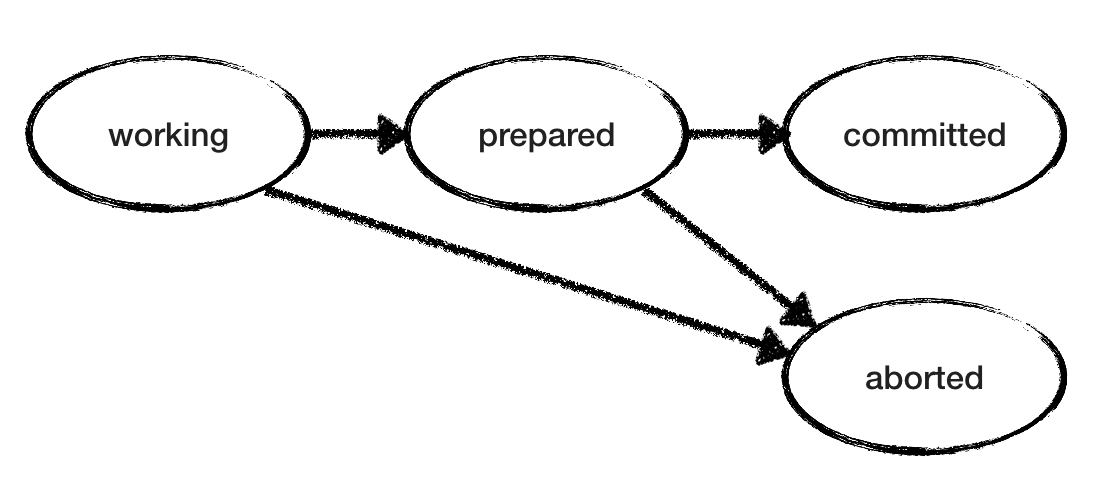
Modelo de confirmación en dos fases

Necesitamos verificar la consistencia de nuestro compromiso de dos fases: para que no haya RM diferentes, uno de los cuales dice "compromiso" y el otro "aborto".
El predicado
Completed verifica que el protocolo no se cuelga para siempre: al final, cada RM alcanza el estado final de
committed o
aborted .
Ahora estamos listos para probar el modelo de protocolo. Inicialmente, configuramos
TMMAYFAIL=FALSE, RM=1..3 para iniciar el protocolo con tres RM y un TM, es decir, en una configuración confiable. Probar el modelo lleva 15 segundos y dice que no hay errores. Tanto
Consistency como
Completed satisfechos con cualquier posible ejecución de protocolo con cualquier alternancia de acciones de RM y acciones de TM.

Ahora establezca
TMMAYFAIL=TRUE y reinicie la verificación. El programa produce rápidamente el resultado opuesto, donde RM se atascó esperando una respuesta de un TM no disponible.

Vemos que en el
State=4 transiciones RM2 se interrumpen, en el
State=7 transiciones RM3 se interrumpen, en el
State=8 TM pasa al estado "colgar" y cae al
State=9 . En
State=10 sistema se congela porque RM1 permanece para siempre en un estado preparado, esperando la decisión de un TM caído.
Simulación BTM
Para evitar congelaciones de transacciones, agregamos una TM de respaldo (BTM), que rápidamente toma el control si la TM principal no está disponible. BTM usa la misma lógica que TM para tomar decisiones. Y por simplicidad, suponemos que el BTM nunca se bloquea.

Cuando probamos el modelo con el proceso BTM agregado, recibimos un nuevo mensaje de error.

BTM no puede aceptar un compromiso porque nuestra condición original,
canCommit establece que todos los
RMstates deben estar "preparados" y no tiene en cuenta la condición de que algunos RM ya hayan recibido una decisión de compromiso del TM original antes de que TMB tome el control. Es necesario reescribir las condiciones de
canCommit teniendo en cuenta dicha situación.

Éxito! Cuando probamos el modelo, logramos consistencia e integridad, ya que el BTM toma el control y completa la transacción si el TM cae.
Aquí está el modelo 2PCwithBTM en TLA + (BTM y la segunda línea de canCommit están inicialmente sin comentarios) y el
pdf correspondiente .
¿Qué pasa si RM también falla?
Asumimos que RM es confiable. Ahora cancele esta condición y vea cómo se comporta el protocolo cuando falla RM. Agregue el estado "inaccesible" al modelo de falla. Para investigar el comportamiento y simular la pérdida intermitente de disponibilidad, permita que el RM de emergencia se recupere y continúe trabajando leyendo su estado del registro. Aquí hay otro diagrama de transición de estado RM con el estado "inaccesible" agregado y las transiciones marcadas en rojo. Y a continuación se muestra el modelo revisado para RM.
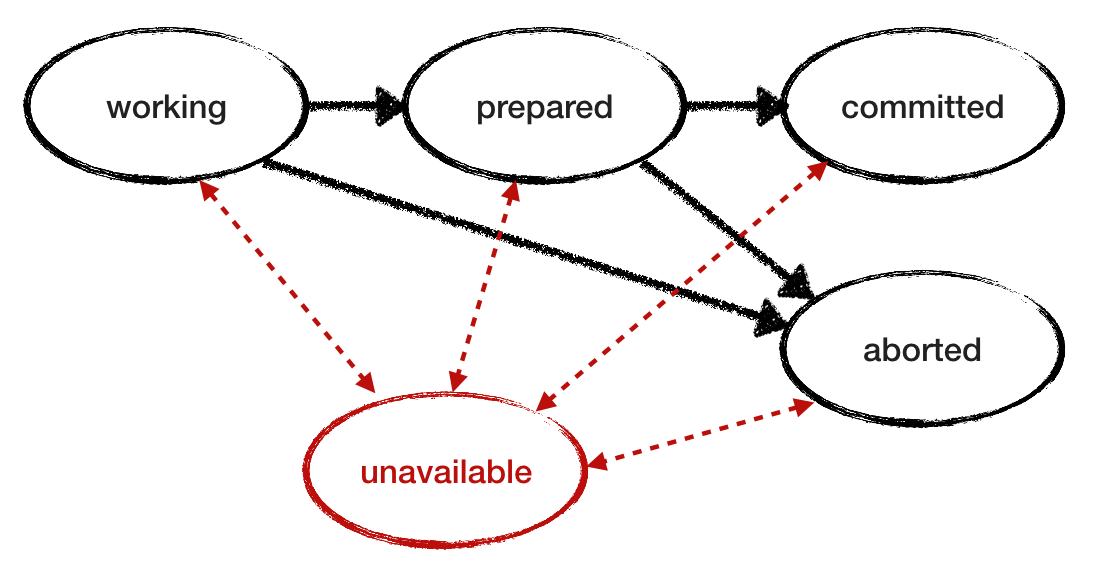

También es necesario refinar
canAbort teniendo en cuenta el estado de indisponibilidad. TM puede tomar la decisión de "colgar" si alguno de los servicios se encuentra en un estado interrumpido o inaccesible. Si se omite esta condición, un RM caído y no restaurado interrumpirá el progreso de la transacción. Por supuesto, nuevamente, debe considerar el RM, que aprendió la decisión de completar la transacción de la fuente TM.
Verificación del modelo
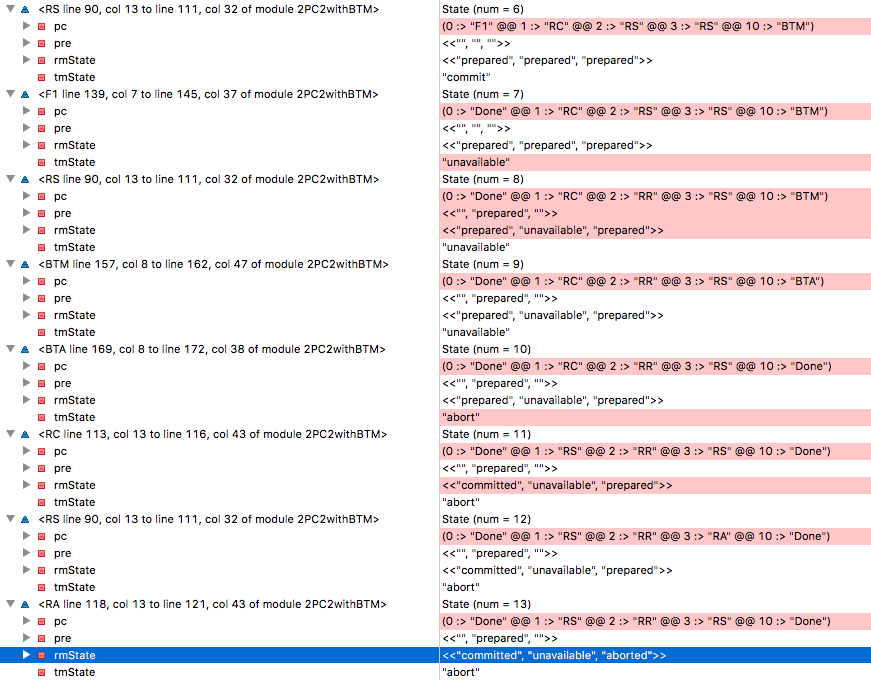
Cuando probamos el modelo, ¡hay un problema de inconsistencia! ¿Cómo pudo pasar esto? Trazamos el rastro.
Con
State=6 todos los RM están en un estado preparado, TM tomó la decisión de completar la transacción, RM1 vio esta decisión y cambió a la etiqueta RC, lo que significa que está listo para cambiar su estado a "completado". (Recuerde RM1, esta arma disparará en el último acto). Desafortunadamente, el TM cae en
State=7 , y RM2 deja de estar disponible en
State=8 . En el noveno paso, el BTM de respaldo toma el control y lee el estado de los tres RM como "preparado, inaccesible, preparado", y decide cancelar la transacción en el décimo paso. ¿Recuerdas RM1? Decide completar la transacción porque recibió tal decisión del TM original y entra en estado
committed en el paso 11. En
State=13 RM3 cumple la decisión de abortar la transacción de BTM y entra en el estado
aborted , y ahora hemos perdido la coherencia con RM1.
En este caso, el BTM tomó una decisión que violaba la
coherencia . Por otro lado, si hace que el BTM espere a que el RM deje el estado inaccesible, puede congelarse para siempre en caso de un accidente en el nodo, y esto violará la condición de
cumplimiento (progreso).
Un archivo de modelo TLA + actualizado está disponible aquí , así como el
correspondiente pdf .
Imposibilidad FLP
Entonces que paso? Nos topamos con el
teorema de Fisher, Lynch, Paterson (FLP) sobre la imposibilidad de consenso en un sistema asincrónico con fallas.
En nuestro ejemplo, BTM no puede decidir correctamente si RM2 está en un estado fallido o no, y decide incorrectamente cancelar la transacción. Si solo el TM original tomara la decisión, tal inexactitud en reconocer una falla no sería un problema. RM obedecerá cualquier decisión de TM, por lo que se mantendrá la coherencia y el progreso.
El problema es que tenemos dos objetos que toman decisiones: TM y BTM, observan el estado de RM en diferentes momentos y toman diferentes decisiones. Tal asimetría de información es la raíz de todo mal en los sistemas distribuidos.
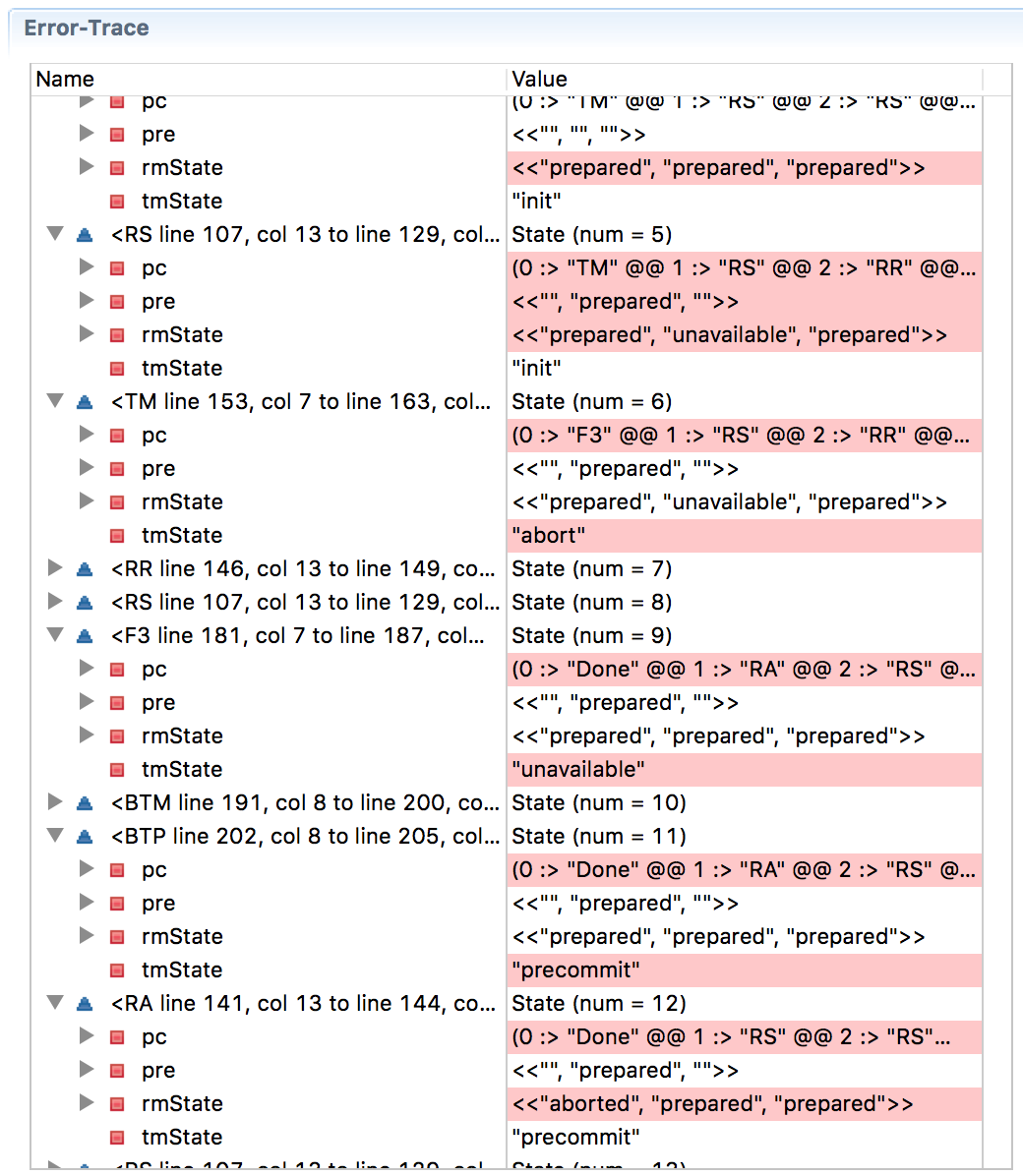
El problema no desaparece incluso con la expansión a una confirmación trifásica.
Aquí hay una confirmación trifásica modelada en TLA + (
versión pdf ), y a continuación se muestra un seguimiento de error que muestra que esta vez se ha violado el progreso (en
la página de Wikipedia sobre una confirmación trifásica , se describe una situación cuando RM1 se congela después de recibir una decisión antes de la confirmación, y la confirmación RM2 y RM3 cometer, lo que viola la consistencia).
Paxos está tratando de hacer del mundo un lugar mejor.

Pero no todo está perdido, la esperanza no ha muerto.
Tenemos paxos . Actúa perfectamente dentro del marco del teorema de FLP. La innovación de Paxos es que
siempre es
seguro (incluso con detectores inexactos, ejecución asincrónica y fallas), y
finalmente completa la transacción cuando el consenso se hace posible.
Puede emular TM en un clúster con tres nodos Paxos, y esto resolverá el problema de inconsistencia TM / BTM. O, como Gray y Lampport mostraron en un
artículo científico sobre el consenso en la confirmación de
transacciones , si RM usa el contenedor Paxos para almacenar sus decisiones simultáneamente con la respuesta TM, esto elimina un paso adicional en el algoritmo de protocolo estándar.