En Rostelecom, como en cualquier gran empresa, hay un almacén de datos corporativos (WCD). Nuestro WCD está en constante crecimiento y expansión, construimos útiles escaparates, informes y cubos de datos en él. En algún momento, nos enfrentamos con el hecho de que los datos de baja calidad interfieren con nosotros cuando construimos escaparates, las unidades resultantes no convergen con las unidades de los sistemas fuente y causan una falta de comprensión del negocio. Por ejemplo, los datos con valores nulos en claves foráneas (claves foráneas) no están conectados a datos de otras tablas.
Breve diagrama de WCD:
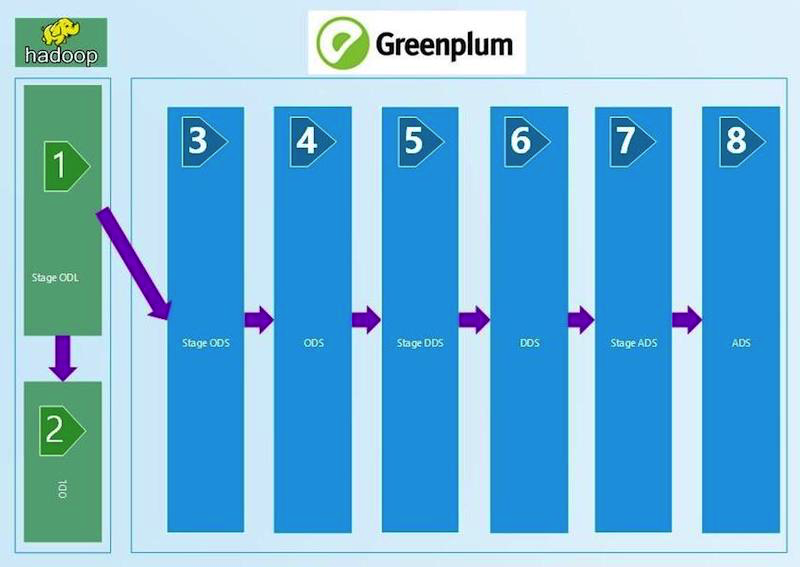
Entendimos que para garantizar la confianza en la calidad de los datos, necesitábamos un proceso de conciliación regular. Por supuesto, automatiza y permite que cada uno de los niveles tecnológicos esté seguro de la calidad de los datos y su convergencia, tanto vertical como horizontalmente. Como resultado, revisamos simultáneamente tres plataformas preparadas para gestionar las conciliaciones de varios proveedores y escribimos la nuestra. Compartimos nuestra experiencia en esta publicación.
Los inconvenientes de las plataformas terminadas son conocidos por todos: precio, flexibilidad limitada, falta de la capacidad de agregar y corregir funcionalidades. Pros: las piezas mdm (datos de oro, etc.), la capacitación y el soporte también están cerrados. Después de apreciar esto, rápidamente nos olvidamos de la compra y nos concentramos en desarrollar nuestra solución.
El núcleo de nuestro sistema está escrito en Python, y la base de datos de metadatos para almacenar, registrar y almacenar resultados está escrita en Oracle. Hay muchas bibliotecas para Python, utilizamos el mínimo necesario para las conexiones Hive (pyhive), GreenPlum (pgdb), Oracle (cx_Oracle). Conectar un tipo diferente de fuente tampoco debería ser un problema.
El conjunto de datos resultante (conjunto de resultados) lo colocamos en la tabla de Oracle resultante, donde evaluamos el estado de la reconciliación (ÉXITO / ERROR). APEX se configura en las tablas resultantes en las que se construye la visualización de los resultados, conveniente tanto para el mantenimiento como para la administración.
Para ejecutar verificaciones en el repositorio, se utiliza la orquesta de Informatica, que descarga datos. Al recibir el estado de descarga correcta, estos datos comenzarán a verificarse automáticamente. El uso de la parametrización de consultas y los metadatos de WCD permite el uso de plantillas de conciliación de consultas para conjuntos de tablas.
Ahora sobre las conciliaciones implementadas en esta plataforma.
Comenzamos con conciliaciones técnicas, que comparan la cantidad de datos en la entrada y las capas del WCD con la aplicación de ciertos filtros. Tomamos el archivo ctl que llegó a la entrada WCD, leemos el número de registros y lo comparamos con la tabla en Stage ODL y / o Stage ODS (1, 2, 3 en el diagrama). El criterio de verificación se define en la igualdad del número de registros (recuento). Si la cantidad converge, entonces el resultado es ÉXITO, no - ERROR y análisis manual del error.
Esta cadena de conciliaciones técnicas, en comparación con el número de registros, se extiende a la capa ADS (8 en el diagrama). Los filtros se cambian entre capas, que dependen del tipo de carga: DIM (libro de referencia), HDIM (libro de referencia histórico), FACT (tablas de acumulación reales), etc., así como de la versión del SCD y la capa. Cuanto más cerca de la capa de visualización, más sofisticados son los algoritmos de filtrado que utilizamos.
También se realizó una verificación técnica en la entrada en Python, que detecta duplicados en los campos clave. En nuestro GreenPlum, los campos clave (PK) no están protegidos contra duplicados por las herramientas del sistema de base de datos. Entonces, escribimos un script de Python que lee los campos de la tabla cargada de los metadatos PK y genera un script SQL que verifica la ausencia de tomas en ellos. La flexibilidad del enfoque nos permite usar PK que consta de uno o varios campos, lo cual es extremadamente conveniente. Dicha conciliación se extiende a la capa STG ADS.
unique_check import sys import os from datetime import datetime log_tmstmp = datetime.now().strftime("%Y-%m-%d %H:%M:%S") def do_check(args, context): tab = args[0] data = [] fld_str = "" try: sql = """SELECT 't_'||lower(table_id) as tn, lower(column_name) as cn FROM src_column@meta_data WHERE table_id = '%s' and is_primary_key = 'Y'""" % (tab,) for fld in context['ora_get_data'](context['ora_con'], sql): fld_str = fld_str + (fld_str and ",") + fld[1] if fld_str: config = context['script_config'] con_gp = context['pg_open_con'](config['user'], config['pwd'], config['host'], config['port'], config['dbname']) sql = """select %s as pkg_id, 't_%s' as table_name, 'PK fields' as column_name, coalesce(sum(cnt), 0) as NOT_UNIQUE_PK, to_char(current_timestamp, 'YYYY-MM-DD HH24:MI:SS') as sys_creation from (select 1 as cnt from edw_%s.t_%s where %s group by %s having count(*) > 1 ) sq; """ % (context["package"] or '0',tab.lower(), args[1], tab.lower(), (context["package"] and ("package_id = " + context["package"]) or "1=1"), fld_str ) data.extend(context['pg_get_data'](con_gp, sql)) con_gp.close() except Exception as e: raise return data or [[(context["package"] or 0),'t_'+tab.lower(), None, 0, log_tmstmp]] if __name__ == '__main__': sys.exit(do_check([sys.argv[1], sys.argv[2]], {}))
Ejemplo de código de python de reconciliación de unicidad. El módulo de control en Python realiza la llamada, la transferencia de los parámetros de conexión y la colocación de los resultados en la tabla resultante.La reconciliación por la ausencia de valores NULL se construye de manera similar a la anterior y también en Python. Leemos de los campos de metadatos de carga que no pueden tener valores vacíos (NULL) y verificamos su plenitud. La reconciliación se usa antes de la capa DDS (6 en el primer diagrama).
En la entrada al almacenamiento, también se implementa un análisis de tendencias de los paquetes de datos que llegan a la entrada. La cantidad de datos recibidos cuando llega un nuevo paquete se ingresa en la tabla de historial. Con un cambio significativo en la cantidad de datos, la persona responsable de la tabla y el SI (sistema fuente) recibe una notificación por correo electrónico (en los planes), ve un error en APEX antes de que el paquete de datos ingrese al Almacén y descubre la razón de esto con el SI.
Entre STG (STAGE) _ODS y ODS (capa de datos operativos) (3 y 4 en el diagrama), aparecen campos de eliminación técnica (indicador de eliminación = deleted_ind), cuya corrección también verificamos mediante consultas SQL. La entrada faltante debe marcarse como eliminada en ODS.
Se espera que el resultado del script de reconciliación vea cero errores. En el ejemplo de reconciliación presentado, los parámetros ~ # PKG_ID # ~ se pasan a través del bloque de control de Python, y los parámetros del tipo ~ P_JOIN_CONDITION ~ y ~ PERIOD_COL ~ se rellenan desde los metadatos de la tabla, el nombre de la tabla en sí ~ TABLE ~ desde los parámetros de inicio.
La siguiente es una reconciliación parametrizada. Ejemplo de código de reconciliación SQL entre STG_ODS y ODS para el tipo HDIM:
select package_id as pkg_id, 'T_~TABLE~' as table_name, to_char(current_timestamp, 'YYYY-MM-DD HH24:MI:SS'), coalesce(empty_in_ods, 0) as empty_in_ods, coalesce(not_equal_md5, 0) as not_equal_md5, coalesce(deleted_in_ods, 0) as deleted_in_ods, coalesce(not_deleted_in_ods, 0) as not_deleted_in_ods, max_load_dttm from (select max (src.package_id) as package_id, sum (case when tgt.md5 is null then 1 else 0 end) as empty_in_ods, sum (case when src.md5<>tgt.md5 and tgt.~PK~ is not null and tgt.deleted_ind = 0 then 1 else 0 end) as not_equal_md5, sum (case when tgt.deleted_ind = 1 and src.md5=tgt.md5 then 1 else 0 end) as deleted_in_ods from EDW_STG_ODS.T_~TABLE~ src left join EDW_ODS.T_~TABLE~ tgt on ~P_JOIN_CONDITION~ and tgt.active_ind ='Y' where ~
Un ejemplo de un código de reconciliación SQL entre STG_ODS y ODS para un tipo HDIM con parámetros sustituidos:
Comenzando con ODS, el historial se mantiene en los directorios, por lo tanto, debe verificarse la ausencia de intersecciones y huecos. Esto se hace contando el número de valores incorrectos en el historial y escribiendo el número resultante de errores en la tabla resultante. Si hay errores de historial en la tabla, deberán buscarse manualmente. La reconciliación depende del tipo de descarga: HDIM (guía de referencia del historial) en primer lugar. Realizamos conciliaciones de la corrección del historial de directorios hasta la capa ADS.
En la capa DDS (6 en el primer diagrama), se combinan diferentes SI (sistemas fuente) en una tabla; aparecen tablas HUB para generar claves sustitutas para vincular datos de diferentes sistemas fuente. Verificamos su unicidad con un control de pitón similar a la capa de escenario.
En la capa DDS, debe verificar que después de combinar con la tabla HUB, los valores de los tipos 0, -1, -2 no aparecieron en los campos clave, lo que significa unión incorrecta de la tabla, falta de datos. Podrían aparecer en ausencia de los datos necesarios en la tabla HUB. Y esto es un error para el análisis manual.
Las conciliaciones más complejas para los datos de la capa de ventana ADS (8 en el primer diagrama). Para una total confianza en la convergencia del resultado obtenido, aquí se implementa la verificación con un sistema fuente para la agregación de la cantidad de cargos. Por un lado, hay una clase de indicadores que incluyen acumulaciones acumuladas. Los recogemos durante un mes desde las ventanas del WCD. Por otro lado, tomamos agregados de los mismos cargos del sistema fuente. Se permite una discrepancia de no más del 1% o un valor absoluto determinado y acordado. Los conjuntos de resultados obtenidos por reconciliación se colocan en conjuntos de datos especialmente creados que reciben tablas de Oracle. Hacemos una comparación de datos en la vista de Oracle. Visualización de los resultados en APEX. La presencia de un conjunto completo de datos (conjunto de resultados) nos permite, si hay errores, profundizar y analizar los datos detallados del resultado, encontrar un artículo específico en el que se produjo la discrepancia y buscar sus razones.
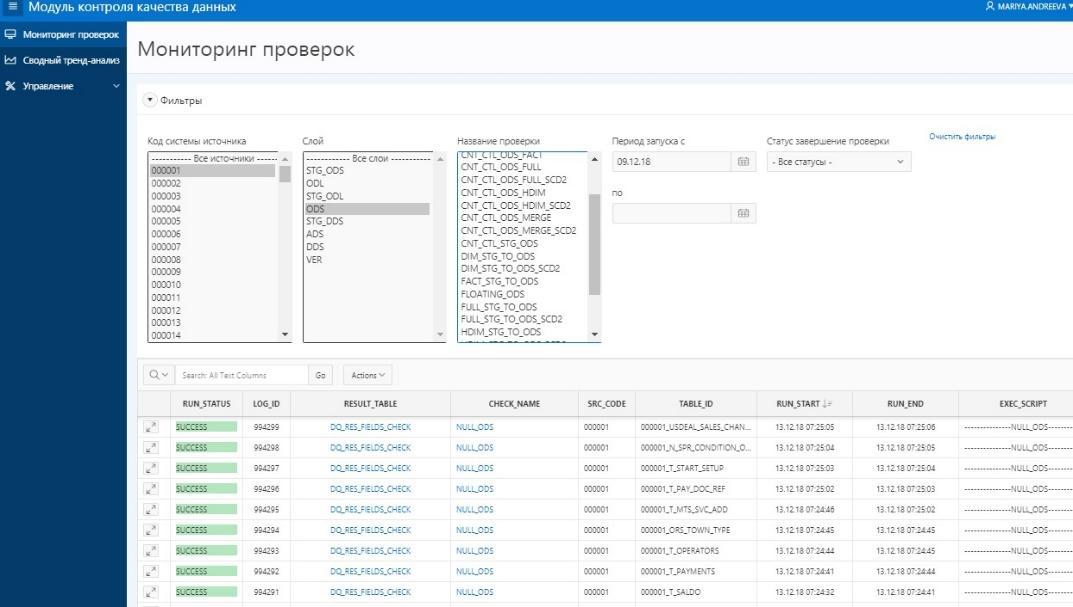 Presentación de resultados de conciliación a usuarios en APEX
Presentación de resultados de conciliación a usuarios en APEXPor el momento, hemos obtenido una aplicación viable y utilizada activamente para conciliar datos. Por supuesto, tenemos planes para desarrollar aún más la cantidad y calidad de las conciliaciones, y el desarrollo de la plataforma en sí. El desarrollo propio nos permite cambiar y modificar la funcionalidad lo suficientemente rápido.
Este artículo fue preparado por el equipo de gestión de datos de Rostelecom