A principios de diciembre, Montreal organizó la 32ª conferencia anual de
sistemas de procesamiento de información neuronal sobre aprendizaje automático. Según una tabla de clasificación no oficial, esta conferencia es el primer evento de este formato en el mundo. Todas las entradas para la conferencia de este año se agotaron en un récord de 13 minutos. Tenemos un gran equipo de científicos de datos de MTS, pero solo uno de ellos, Marina Yaroslavtseva (
magoli ), tuvo la suerte de llegar a Montreal. Junto con Danila Savenkov (
danila_savenkov ), que se quedó sin visa y siguió la conferencia desde Moscú, hablaremos sobre los trabajos que nos parecieron más interesantes. Esta muestra es muy subjetiva, pero espero que te interese.
 Redes neuronales recurrentes relacionalesResumenCódigo
Redes neuronales recurrentes relacionalesResumenCódigoCuando se trabaja con secuencias, a menudo es muy importante cómo se relacionan entre sí los elementos de la secuencia. La arquitectura estándar de las redes de recurrencia (GRU, LSTM) difícilmente puede modelar la relación entre dos elementos que son bastante remotos entre sí. Hasta cierto punto, la atención ayuda a hacer frente a esto (
https://youtu.be/SysgYptB198 ,
https://youtu.be/quoGRI-1l0A ), pero aún así esto no es del todo correcto. La atención le permite determinar el peso con el que el estado oculto de cada uno de los pasos de la secuencia afectará el estado oculto final y, en consecuencia, la predicción. Estamos interesados en la relación de los elementos de la secuencia.
El año pasado, nuevamente en NIPS, Google sugirió abandonar por completo la recurrencia y usar la
auto atención . El enfoque demostró ser muy bueno, aunque principalmente en tareas seq2seq (el artículo proporciona resultados sobre traducción automática).
Los autores de este año utilizan la idea de auto-atención como parte de LSTM. No hay muchos cambios:
- Cambiamos el vector de estado de la celda a la matriz de "memoria" M. Hasta cierto punto, la matriz de memoria es muchos vectores de estado de la celda (muchas celdas de memoria). Al obtener un nuevo elemento de la secuencia, determinamos cuánto debe actualizar este elemento cada una de las celdas de memoria.
- Para cada elemento de la secuencia, actualizaremos esta matriz utilizando la atención del producto de puntos de múltiples cabezales (MHDPA, puede leer sobre este método en el artículo mencionado de google). El resultado de MHPDA para el elemento actual de la secuencia y la matriz M se ejecuta a través de una malla completamente conectada, el sigmoide y luego la matriz M se actualiza de la misma manera que el estado de la celda en LSTM
Se argumenta que es debido a MHDPA que la red puede tener en cuenta la interconexión de elementos de secuencia incluso cuando se eliminan entre sí.
Como problema de juguete, se le pide al modelo en la secuencia de vectores que encuentre el enésimo vector por distancia desde el Mth en términos de distancia euclidiana. Por ejemplo, hay una secuencia de 10 vectores y le pedimos que encuentre uno que esté en el tercer lugar cerca del quinto. Está claro que para responder a esta pregunta del modelo, es necesario evaluar de alguna manera las distancias desde todos los vectores hasta el quinto y clasificarlos. Aquí, el modelo propuesto por los autores derrota con confianza LSTM y
DNC . Además, los autores comparan su modelo con otras arquitecturas en Learning to Execute (obtenemos algunas líneas de código para ingresar, damos el resultado), Mini-Pacman, Language Modeling y en todas partes informan los mejores resultados.
Imputación de series temporales multivariantes con redes adversas generativasResumenCódigo (aunque no se vinculan aquí en el artículo)
En las series de tiempo multidimensionales, por regla general, hay una gran cantidad de omisiones, lo que impide el uso de métodos estadísticos avanzados. Las soluciones estándar: llenar con media / cero, eliminar casos incompletos, restaurar datos basados en expansiones de matriz en esta situación, a menudo no funcionan, porque no pueden reproducir dependencias de tiempo y la compleja distribución de series de tiempo multidimensionales.
La capacidad de las redes de confrontación generativas (GAN) para imitar cualquier distribución de datos, en particular, en las tareas de "dibujar" caras y generar oraciones, es ampliamente conocida. Pero, por regla general, tales modelos requieren capacitación inicial en un conjunto de datos completo sin lagunas, o no tienen en cuenta la naturaleza consistente de los datos.
Los autores proponen complementar el GAN con un nuevo elemento: la Unidad de recursión cerrada para la imputación (GRUI). La principal diferencia con el GRU habitual es que GRUI puede aprender de los datos a intervalos de diferentes longitudes entre observaciones y ajustar el efecto de las observaciones según su distancia en el tiempo desde el punto actual. Se calcula un parámetro de atenuación especial β, cuyo valor varía de 0 a 1 y cuanto más pequeño, mayor es el intervalo de tiempo entre la observación actual y la no vacía anterior.


Tanto el discriminador como el generador de GAN consisten en una capa GRUI y una capa totalmente conectada. Como es habitual en las GAN, el generador aprende a simular los datos de origen (en este caso, solo completa los espacios en blanco en las filas), y el discriminador aprende a distinguir las filas llenas con el generador de las reales.
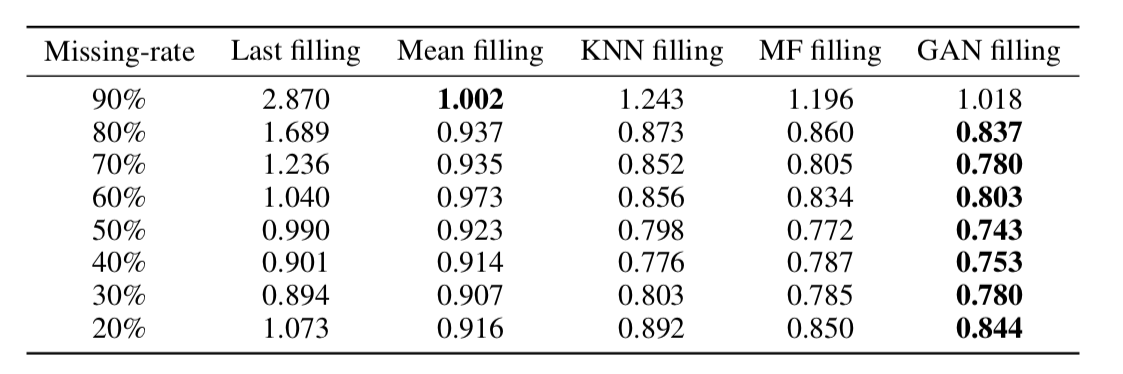
Al final resultó que, este enfoque restaura datos de manera muy adecuada incluso en series de tiempo con una gran cantidad de omisiones (en la tabla a continuación: recuperación de datos MSE en el conjunto de datos KDD dependiendo del porcentaje de omisiones y método de recuperación. En la mayoría de los casos, el método basado en GAN proporciona la mayor precisión recuperación).
 Sobre la dimensionalidad de las incrustaciones de palabrasResumenCódigo
Sobre la dimensionalidad de las incrustaciones de palabrasResumenCódigoLa inclusión de palabras / representación vectorial de palabras es un enfoque ampliamente utilizado para diversas aplicaciones de PNL: desde sistemas de recomendación hasta el análisis de la coloración emocional de textos y la traducción automática.
Además, la cuestión de cómo establecer de manera óptima un hiperparámetro tan importante como la dimensión de los vectores permanece abierta. En la práctica, la mayoría de las veces se selecciona mediante búsqueda empírica exhaustiva o se establece de forma predeterminada, por ejemplo, en el nivel de 300. Al mismo tiempo, una dimensión demasiado pequeña no permite reflejar todas las relaciones significativas entre palabras, y demasiado grande puede conducir a una nueva capacitación.
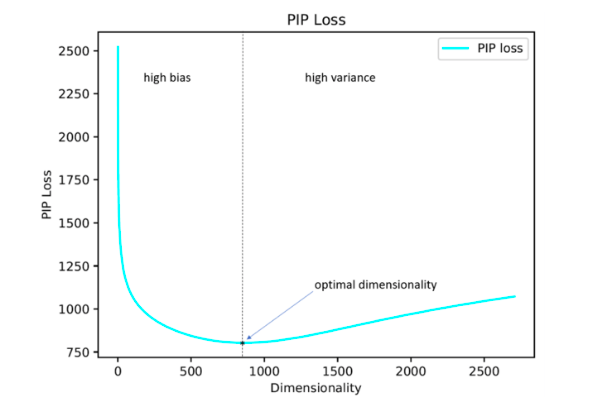
Los autores del estudio proponen su solución a este problema minimizando el parámetro de pérdida de PIP, una nueva medida de la diferencia entre las dos opciones de inclusión.
El cálculo se basa en matrices PIP que contienen los productos escalares de todos los pares de representaciones vectoriales de palabras en el corpus. La pérdida de PIP se calcula como la norma de Frobenius entre las matrices de PIP de dos incorporaciones: capacitado en datos (incrustación capacitada E_hat) e ideal, capacitado en datos ruidosos (incrustación Oracle E).
Parecería simple: debe elegir una dimensión que minimice la pérdida de PIP, el único momento incomprensible es dónde obtener la incrustación de Oracle. En 2015-2017, se publicaron varios trabajos en los que se demostró que varios métodos para construir incrustaciones (word2vec, GloVe, LSA) factorizan implícitamente (reducen la dimensión) la matriz de señales del caso. En el caso de word2vec (skip-gram), la matriz de señal es
PMI , en el caso de GloVe es la matriz de recuento de registros. Se propone tomar un diccionario de tamaño no muy grande, construir una matriz de señal y usar SVD para obtener la incrustación de oráculo. Por lo tanto, la dimensión de incrustación de oráculo es igual al rango de la matriz de señal (en la práctica, para un diccionario de 10k palabras, la dimensión será del orden de 2k). Sin embargo, nuestra matriz de señal empírica siempre es ruidosa y tenemos que recurrir a esquemas complicados para obtener la incrustación del oráculo y estimar la pérdida de PIP por una matriz ruidosa.
Los autores argumentan que para seleccionar la dimensión de incrustación óptima, es suficiente usar un diccionario de 10k palabras, lo que no es mucho y le permite ejecutar este procedimiento en un período de tiempo razonable.
Al final resultó que, la dimensión de inclusión calculada de esta manera en la mayoría de los casos con un error de hasta 5% coincide con la dimensión óptima determinada sobre la base de estimaciones de expertos. Resultó (esperado) que Word2Vec y GloVe prácticamente no se vuelven a entrenar (la pérdida de PIP no cae en dimensiones muy grandes), pero LSA se vuelve a entrenar con bastante fuerza.
Usando el código publicado en el github por los autores, uno puede buscar la dimensión óptima de Word2Vec (skip-gram), GloVe, LSA.
FRAGE: Representación de palabras agnósticas en frecuenciaResumenCódigoLos autores hablan sobre cómo las incrustaciones funcionan de manera diferente para palabras raras y populares. Por popular quiero decir no detener palabras (no las consideramos en absoluto), sino palabras informativas que no son muy raras.
Las observaciones son las siguientes:
Si hablamos de palabras populares, entonces su proximidad en la medida del coseno se refleja muy bien
- Su afinidad semántica. Para palabras raras, esto no es así (lo que se espera) y (lo que es menos esperado) el top-n de las palabras coseno más cercanas a una palabra rara también son raras y al mismo tiempo semánticamente no relacionadas. Es decir, las palabras raras y frecuentes en el espacio de las incrustaciones viven en diferentes lugares (en diferentes conos, si hablamos de coseno)
- Durante el entrenamiento, los vectores de palabras populares se actualizan mucho más a menudo y, en promedio, están dos veces más lejos de la inicialización que los vectores para palabras raras. Esto lleva al hecho de que la inclusión de palabras raras está en promedio más cerca del origen. Para ser honesto, siempre creí que, por el contrario, las incrustaciones de palabras raras son en promedio más largas y no sé cómo relacionarme con la declaración de los autores =)
Cualquiera que sea la relación entre las normas L2 de incrustaciones, la separabilidad de las palabras populares y raras no es un fenómeno muy bueno. Queremos que las incrustaciones reflejen la semántica de una palabra, no su frecuencia.
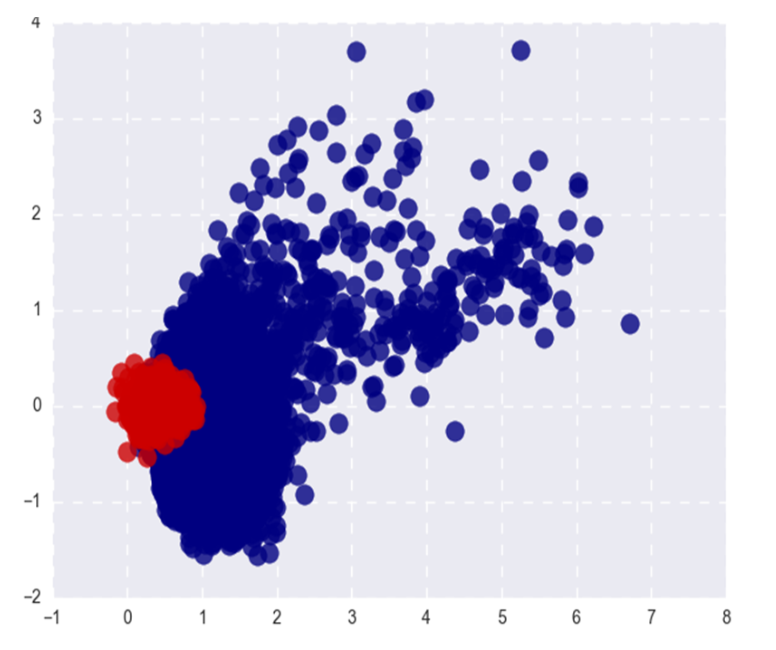
La imagen muestra palabras populares (rojas) y raras (azules) de Word2Vec después de SVD. Popular aquí se refiere al 20% superior de las palabras en frecuencia.
Si el problema estuviera solo en las normas L2 de incrustaciones, podríamos normalizarlas y vivir felices, pero, como dije en el primer párrafo, las palabras raras también están separadas de las populares por proximidad coseno (en coordenadas polares).
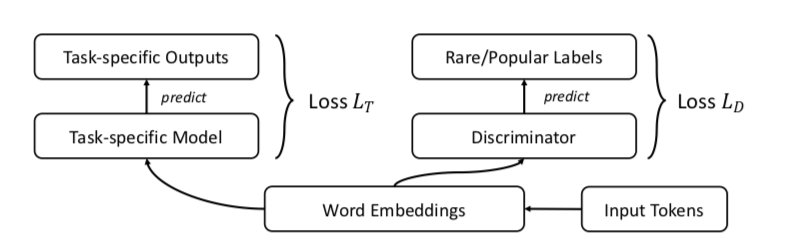
Los autores sugieren, por supuesto, GAN. Hagamos lo mismo que antes, pero agreguemos un discriminador que intente distinguir entre palabras populares y raras (nuevamente, consideramos que el n-% superior de las palabras en frecuencia es popular).
Se parece a esto:
Los autores prueban el enfoque en las tareas de similitud de palabras, traducción automática, clasificación de texto y modelado de idiomas, y en todos los lugares donde funcionan mejor que la línea base. En la similitud de palabras, se afirma que la calidad crece especialmente notablemente en palabras raras.
Un ejemplo: ciudadanía. Problemas de salto de gramo: felicidad, paquistaníes, despidos, refuerzos. Problemas de FRAGE: población, städtischen, dignidad, bürger. Las palabras ciudadano y ciudadanos en FRAGE están en 79º y 7º lugar, respectivamente (en proximidad a la ciudadanía), en skip-gram no están entre los 10000 principales.
Por alguna razón, los autores publicaron el código solo para tareas de traducción automática y modelado de idiomas, similitud de palabras y clasificación de texto en el repositorio, desafortunadamente, no están representados.
Alineación transversal sin supervisión de espacios de incrustación de voz y textoResumenCódigo: sin código, pero me gustaría
Estudios recientes han demostrado que dos espacios vectoriales entrenados utilizando algoritmos de incrustación (por ejemplo, word2vec) en cuerpos de texto en dos idiomas diferentes se pueden combinar entre sí sin marcas ni coincidencias de contenido entre los dos edificios. En particular, este enfoque se utiliza para la traducción automática en Facebook. Se utiliza una de las propiedades clave de los espacios de incrustación: dentro de ellos, las palabras similares deben estar geométricamente cercanas, y las diferentes, por el contrario, deben estar lejos una de la otra. Se supone que, en general, la estructura del espacio vectorial se conserva independientemente del idioma en el que el corpus era para la enseñanza.
Los autores del artículo fueron más allá y aplicaron un enfoque similar al campo del reconocimiento automático de voz y la traducción. Se propone entrenar el espacio vectorial por separado para el corpus de texto en el idioma de interés (por ejemplo, Wikipedia), por separado para el corpus del discurso grabado (en formato de audio), posiblemente en otro idioma, previamente dividido en palabras, y luego comparar estos dos espacios de la misma manera que con dos casos de texto
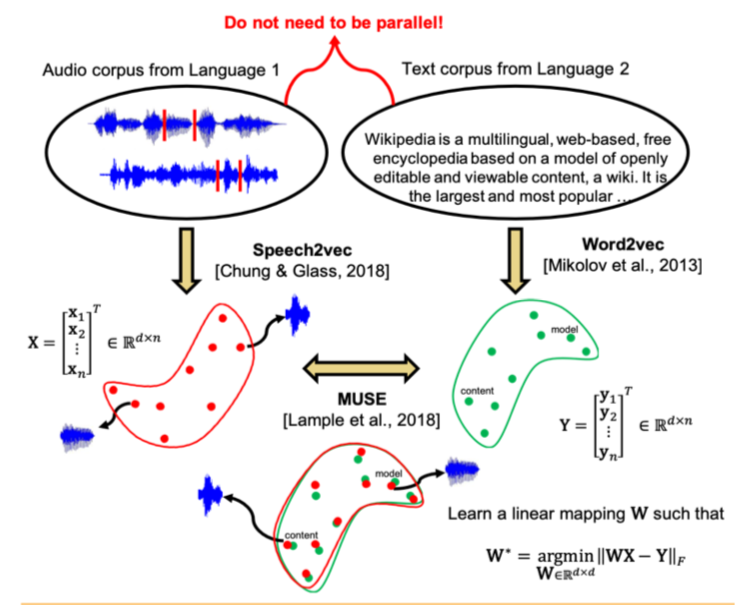
Para el corpus de texto, se usa word2vec, y para el habla, un enfoque similar, llamado por Speech2vec, se basa en LSTM y las metodologías utilizadas para word2vec (CBOW / skip-gram), por lo que se supone que combina palabras precisamente por características contextuales y semánticas, y No suena
Después de entrenar ambos espacios vectoriales y hay dos conjuntos de incrustaciones: S (en el cuerpo del habla), que consta de n incrustaciones de dimensión d1 y T (en el cuerpo del texto), que consta de m incrustaciones de dimensión d2, debe compararlas. Idealmente, tenemos un diccionario que determina qué vector de S corresponde a qué vector de T. Luego se forman dos matrices para la comparación: k incrustaciones se seleccionan de S, que forman una matriz X de tamaño d1 xk; de T, también se seleccionan las incrustaciones k correspondientes (según el diccionario) previamente seleccionadas de S, y se obtiene una matriz Y de tamaño d2 x k. A continuación, debe encontrar una asignación lineal W tal que:
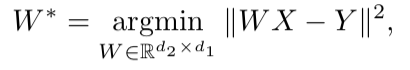
Pero dado que el artículo considera el enfoque no supervisado, inicialmente no existe un diccionario, por lo tanto, se propone un procedimiento para generar un diccionario sintético, que consta de dos partes. Primero, obtenemos la primera aproximación de W usando el entrenamiento de dominio-adversario (un modelo competitivo como GAN, pero en lugar del generador, un mapeo lineal de W, con el que tratamos de hacer que S y T sean indistinguibles entre sí, y el discriminador intenta determinar el origen real de la inclusión). Luego, en base a las palabras cuyas incorporaciones mostraron la mejor coincidencia entre sí y se encuentran con mayor frecuencia en ambos edificios, se forma un diccionario. Después de eso, se produce el refinamiento de W de acuerdo con la fórmula anterior.
Este enfoque proporciona resultados comparables al aprendizaje en datos etiquetados, lo que puede ser muy útil en la tarea de reconocer y traducir el habla de lenguajes raros para los que hay muy pocos cuerpos paralelos de habla-texto, o están ausentes.
Detección de anomalías profundas mediante transformaciones geométricasResumenCódigoUn enfoque bastante inusual en la detección de anomalías, que, según los autores, derrota en gran medida a otros enfoques.
La idea es esta: propongamos K diferentes transformaciones geométricas (una combinación de cambios, rotación de 90 grados y reflexión) y aplíquelas a cada imagen del conjunto de datos original. La imagen obtenida como resultado de la i-ésima transformación ahora pertenecerá a la clase i, es decir, habrá K clases en total, cada una de ellas estará representada por el número de imágenes que originalmente estaban en el conjunto de datos. Ahora vamos a enseñar una clasificación multiclase en dicho marcado (los autores eligieron el reinicio amplio).
Ahora podemos obtener K vectores y (Ti (x)) de dimensión K para una nueva imagen, donde Ti es la i-ésima transformación, x es la imagen, y es la salida del modelo. La definición básica de "normalidad" es la siguiente:
Aquí, para la imagen x, agregamos las probabilidades predichas de las clases correctas para todas las transformaciones. Cuanto mayor sea la "normalidad", más probable es que la imagen se tome de la misma distribución que la muestra de entrenamiento. Los autores afirman que esto ya funciona muy bien, pero sin embargo ofrecen una forma más compleja que funciona incluso un poco mejor. Asumiremos que el vector y (Ti (x)) para cada transformación de Ti está distribuido en
Dirichlet y tomaremos el logaritmo de probabilidad como una medida de "normalidad" de la imagen. Los parámetros de distribución de Dirichlet se estiman en un conjunto de entrenamiento.
Los autores informan sobre el increíble aumento del rendimiento en comparación con otros enfoques.
Un marco unificado simple para detectar muestras fuera de distribución y ataques adversosResumenCódigoLa identificación en la muestra para la aplicación del modelo de casos significativamente diferente de la distribución de la muestra de entrenamiento es uno de los requisitos principales para obtener resultados de clasificación confiables. Al mismo tiempo, las redes neuronales son conocidas por su característica con un alto grado de confianza (e incorrectamente) para clasificar objetos que no se encontraron en el entrenamiento o se corrompieron intencionalmente (ejemplos adversos).
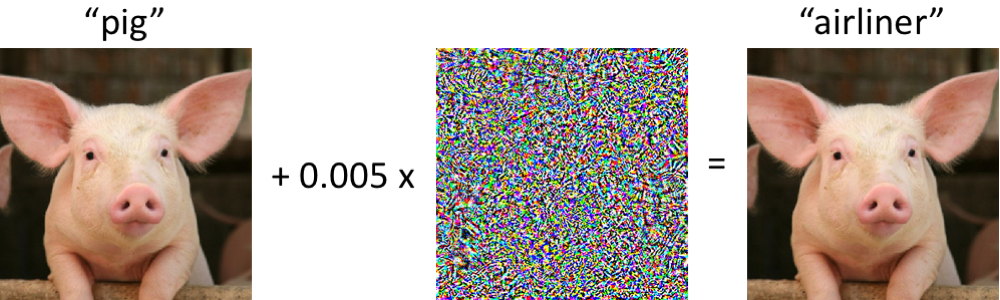
Los autores del artículo ofrecen un nuevo método para identificar esos y otros casos "malos". El enfoque se implementa de la siguiente manera: primero, se entrena una red neuronal con la salida softmax habitual, luego se toma la salida de su penúltima capa y se entrena el clasificador generativo sobre ella. Supongamos que x - que se alimenta a la entrada del modelo para un objeto de clasificación específico, y - la etiqueta de clase correspondiente, luego supongamos que tenemos un clasificador softmax preformado de la forma:
Donde wc y bc son los pesos y la constante de la capa softmax para la clase c, yf (.) Es la salida del penúltimo DNN de soja.
Además, sin ningún cambio en el clasificador pre-entrenado, se realiza una transición al clasificador generativo, a saber, análisis discriminante. Se supone que las características tomadas de la penúltima capa del clasificador softmax tienen una distribución normal multidimensional, cada componente del cual corresponde a una clase. Luego, la distribución condicional se puede especificar a través del vector de medias de la distribución multidimensional y su matriz de covarianza:
Para evaluar los parámetros del clasificador generativo, se calculan los promedios empíricos para cada clase, así como la covarianza para los casos de la muestra de entrenamiento {(x1, y1), ..., (xN, yN)}:
donde N es el número de casos de la clase correspondiente en el conjunto de entrenamiento. Luego, se calcula una medida de confiabilidad en la muestra de prueba: la distancia de Mahalanobis entre el caso de prueba y la distribución de clase normal más cercana a este caso.
Al final resultó que, una métrica de este tipo funciona de manera mucho más confiable en objetos atípicos o dañados, sin dar estimaciones altas, como la capa softmax. En la mayoría de las comparaciones con diferentes datos, el método propuesto mostró resultados que excedieron el estado actual de la técnica en la búsqueda de ambos casos que no estaban en la capacitación y que se estropearon intencionalmente.
Además, los autores consideran otra aplicación interesante de su metodología: usar el clasificador generativo para resaltar nuevas clases que no estaban en capacitación en la prueba, y luego actualizar los parámetros del clasificador en sí para que pueda determinar esta nueva clase en el futuro.
Ejemplos adversarios que engañan tanto a la visión por computadora como a los humanos con tiempo limitadoResumen:
https://arxiv.org/abs/1802.08195adversarial examples . , . adversarial example . , , , , , , , adversarial attacks.

adversarial examples. adversarial examples , ( , ).
, adversarial example, . , , 63 . accuracy 10% , adversarial. , adversarial , . , perturbation perturbation , accuracy .
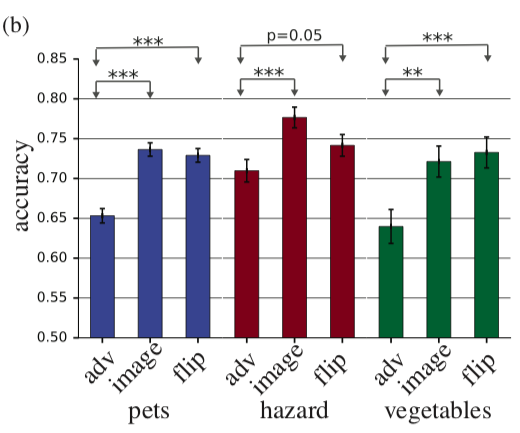
adv — adversarial example, image — , flip — + adversarial perturbation, .
Sanity Checks for Saliency MapsAbstract— . deep learning, saliency maps. Saliency maps . saliency map, , “”.

: “ saliency maps?” , :
- Saliency map
- Saliency map ,
, : cascading randomization ( , , saliency map) independent randomization ( ). : , saliency maps.
saliency map , , saliency maps. : “To our surprise, some widely deployed saliency methods are independent of both the data the model was trained on, and the model parameters”, — . , , saliency maps, , cascading randomization:
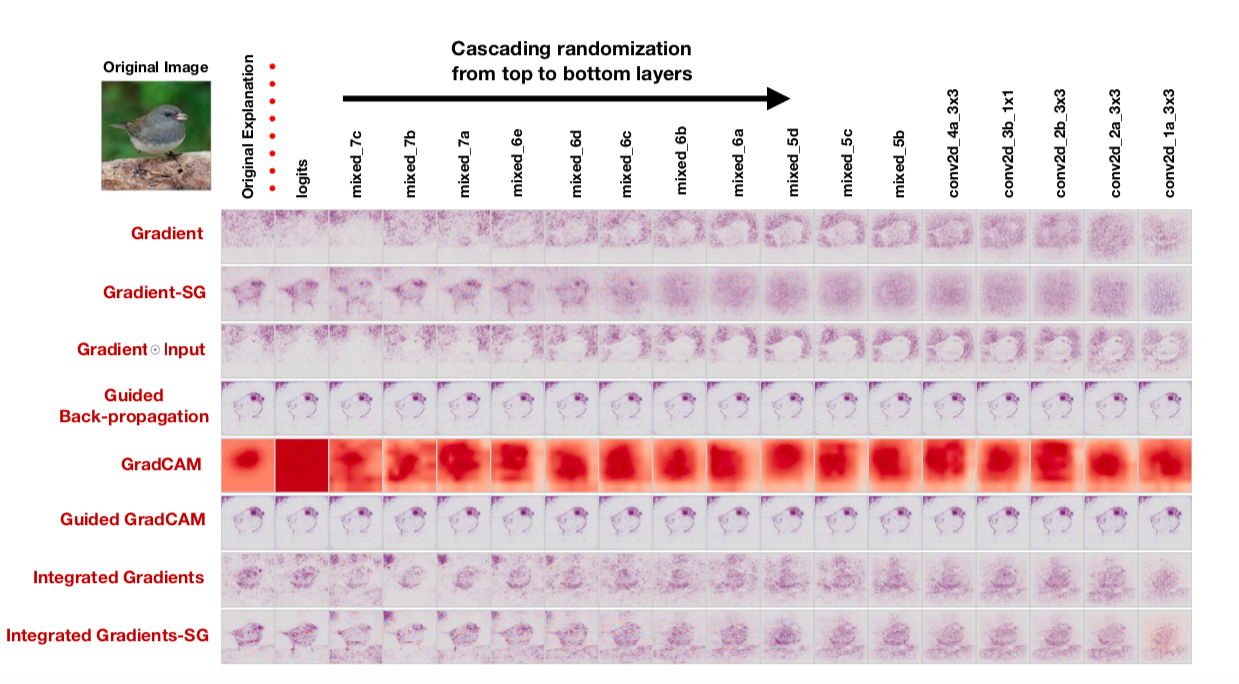
, . , saliency maps .
, — saliency maps , , confirmation bias. , .
An intriguing failing of convolutional neural networks and the CoordConv solutionAbstract:
https://arxiv.org/abs/1807.03247: , 10 .
Uber. , , , . , :
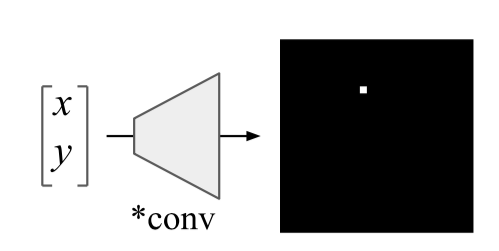
: ( CoodrConv ) i j, :
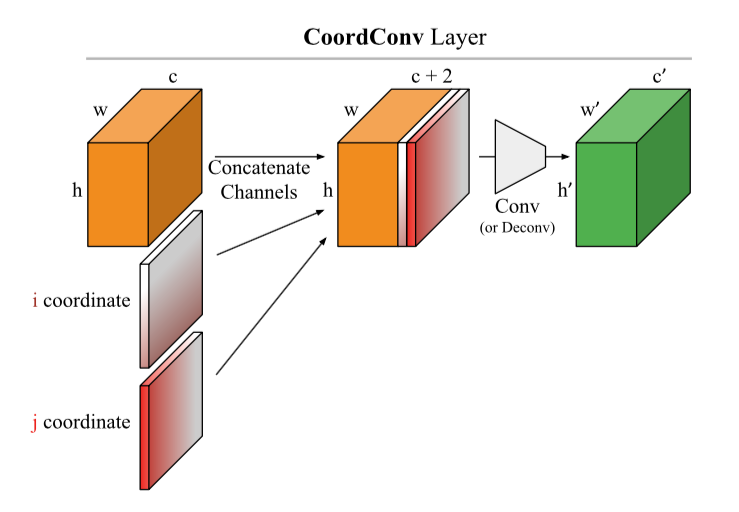
, :
- ImageNet'. , , , ,
- CoordConv object detection. MNIST, Faster R-CNN, IoU 21%
- CoordConv GAN .
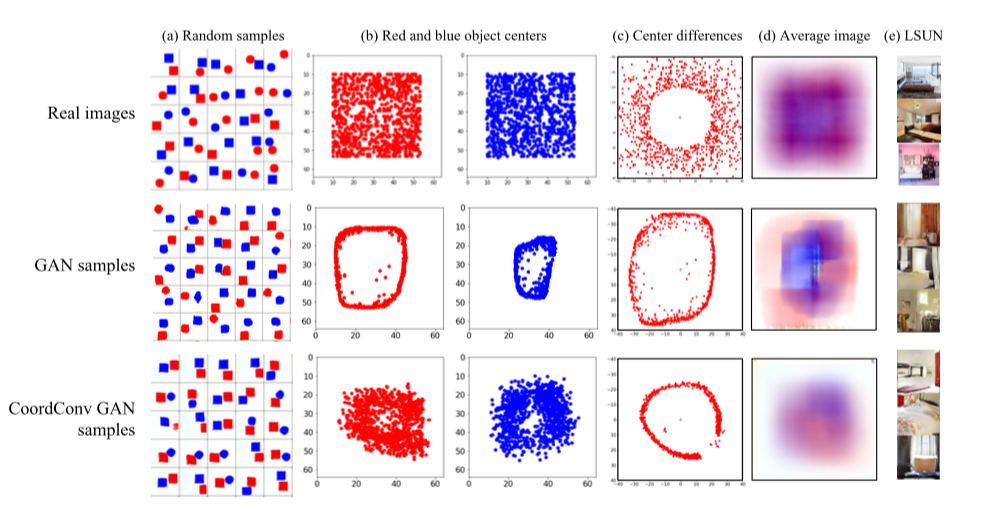
GAN' : LSUN. , — c. , GAN' , , . CoordConv , . LSUN d , , CoordConv GAN,
- 4. CoordConv A2C ( ) .
, , . CoordConv
U-net :
https://arxiv.org/abs/1812.01429, https://www.kaggle.com/c/tgs-salt-identification-challenge/discussion/69274 ,
https://github.com/mjDelta/Kaggle-RSNA-Pneumonia-Detection-Challenge .
.
Regularizing by the Variance of the Activations' Sample-VariancesAbstractbatch normalization. - . : S1 S2 :
donde σ2 son variaciones de muestra en S1 y S2, respectivamente, β es el coeficiente positivo entrenado. Los autores llaman a esta cosa pérdida de constancia de varianza (VCL) y la agregan a la pérdida total.
En la sección sobre experimentos, los autores se quejan de cómo no se reproducen los resultados de los artículos de otras personas y se comprometen a diseñar un código reproducible (presentado). Primero, experimentaron con una pequeña malla de 11 capas en el conjunto de datos de imágenes pequeñas (CIFAR-10 y CIFAR-100). Tenemos que VCL está demostrando, si usa Leaky ReLU o ELU como activaciones, pero la normalización por lotes funciona mejor con ReLU. Luego aumentan el número de capas 2 veces y cambian a Tiny Imagenet, una versión simplificada de Imagenet con 200 clases y una resolución de 64x64. En la validación, VCL supera la normalización de lotes en la red con ELU, así como ResNet-110 y DenseNet-40, pero supera a Wide-ResNet-32. Un punto interesante es que los mejores resultados se obtienen cuando los subconjuntos S1 y S2 consisten en dos muestras.
Además, los autores prueban el VCL en redes de retroalimentación y el VCL gana algo más a menudo que una red con normalización por lotes o sin regularización.
DropMax: Softmax variativo adaptativoResumenCódigoSe propone en el problema de clasificación multiclase en cada iteración del descenso del gradiente para que cada muestra elimine aleatoriamente cierto número de clases incorrectas. Además, también se está entrenando la probabilidad con la que dejamos caer una u otra clase para uno u otro objeto. Como resultado, resulta que la red "se concentra" en distinguir entre las clases más difíciles de separar.
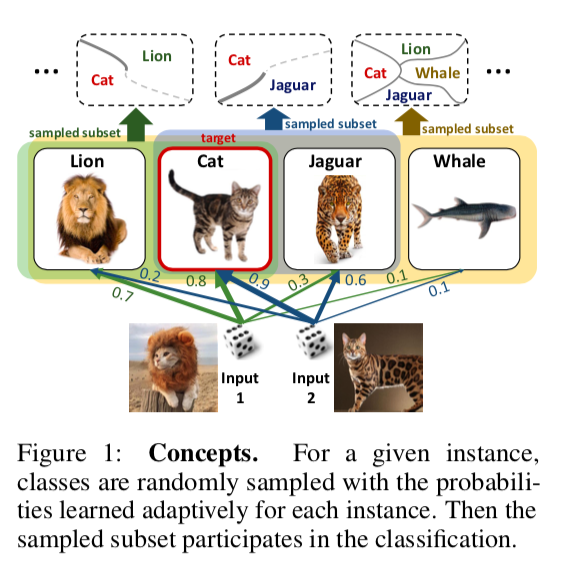
Los experimentos en los subconjuntos MNIST, CIFAR e Imagenet muestran que DropMax funciona mejor que SoftMax estándar y algunas de sus modificaciones.
Modelos inteligibles precisos con interacciones por pares(Los amigos no dejan que los amigos implementen modelos de caja negra: la importancia de la inteligibilidad en el aprendizaje automático)
Resumen:
http://www.cs.cornell.edu/~yinlou/papers/lou-kdd13.pdfCódigo: no está ahí. Estoy muy interesado en cómo los autores imbuyen un nombre tan ligeramente imperativo con una falta de código. Académicos, señor =)
Puede ver este paquete, por ejemplo:
https://github.com/dswah/pyGAM . No hace mucho tiempo se le agregaron interacciones de características (lo que realmente distingue a GAM de GA2M).
Este artículo fue presentado en el marco del taller "Interpretabilidad y robustez en audio, habla y lenguaje", aunque está dedicado a la interpretabilidad de los modelos en general, y no al campo del análisis de sonido y habla. Probablemente, todos se enfrentaron en cierta medida con el dilema de elegir entre la interpretabilidad del modelo y Su precisión. Si usamos la regresión lineal habitual, entonces podemos entender por los coeficientes cómo cada variable independiente afecta al dependiente. Si usamos modelos de caja negra, por ejemplo, el aumento de gradiente sin restricciones en la complejidad o las redes neuronales profundas, un modelo ajustado correctamente en los datos adecuados será muy preciso, pero el seguimiento y la explicación de todos los patrones que el modelo encontró en los datos será problemático. En consecuencia, será difícil explicar el modelo al cliente y rastrear si ha aprendido algo que no nos gustaría. La tabla a continuación proporciona estimaciones de la relativa interpretabilidad y precisión de varios tipos de modelos.

Un ejemplo de una situación en la que la mala interpretación del modelo se asocia con grandes riesgos: en uno de los conjuntos de datos médicos, se resolvió el problema de predecir la probabilidad del paciente de morir por neumonía. Se encontró el siguiente patrón interesante en los datos: si una persona tiene asma bronquial, entonces la probabilidad de morir de neumonía es menor que en personas sin esta enfermedad. Cuando los investigadores recurrieron a médicos en ejercicio, resultó que tal patrón realmente existe, ya que las personas con asma en el caso de la neumonía reciben la ayuda más rápida y los medicamentos más potentes. Si entrenamos a xgboost en este conjunto de datos, lo más probable es que él haya captado este patrón, y nuestro modelo clasificaría a los pacientes con asma como un grupo de bajo riesgo y, en consecuencia, recomendaría una menor prioridad e intensidad de tratamiento para ellos.
Los autores del artículo ofrecen una alternativa que es tanto interpretable como precisa al mismo tiempo: esta es GA2M, una subespecie de modelos aditivos generalizados.
El GAM clásico se puede considerar como una generalización adicional de GLM: un modelo es una suma, cada término del cual refleja la influencia de solo una variable independiente sobre el dependiente, pero la influencia se expresa no por un coeficiente de peso, como en GLM, sino por una función no paramétrica uniforme (como regla, definida por partes) funciones: estrías o árboles de poca profundidad, incluidos "tocones"). Debido a esta característica, los GAM pueden modelar relaciones más complejas que un modelo lineal simple. Por otro lado, las dependencias aprendidas (funciones) se pueden visualizar e interpretar.
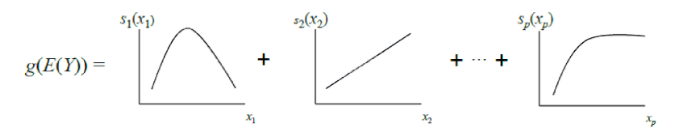
Sin embargo, los GAM estándar todavía a menudo no alcanzan la precisión de los algoritmos de caja negra. Para solucionar esto, los autores del artículo ofrecen un compromiso: agregar a la ecuación del modelo, además de las funciones de una variable, un pequeño número de funciones de dos variables: pares cuidadosamente seleccionados cuya interacción es significativa para predecir la variable dependiente. Por lo tanto, se obtiene GA2M.
Primero, se construye un GAM estándar (sin tener en cuenta la interacción de las variables), y luego se agregan pares de variables paso a paso (el GAM restante se usa como la variable objetivo). Para el caso en que hay muchas variables y actualizar el modelo después de cada paso es computacionalmente difícil, se propone un algoritmo de clasificación RÁPIDO, con el que puede preseleccionar pares potencialmente útiles y evitar la enumeración completa.
Este enfoque nos permite lograr una calidad cercana a los modelos de complejidad ilimitada. La tabla muestra la tasa de error de modelos aditivos generalizados en comparación con un bosque aleatorio para resolver el problema de clasificación en diferentes conjuntos de datos, y en la mayoría de los casos la calidad de predicción para GA2M con FAST y para bosques aleatorios no es significativamente diferente.
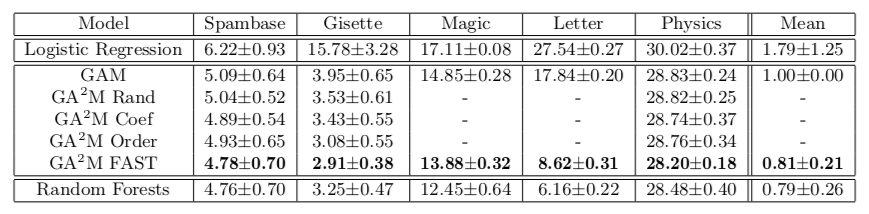
Me gustaría llamar la atención sobre las características del trabajo de los académicos que se ofrecen a enviar estos aumentos y lecciones profundas al horno. Tenga en cuenta que los conjuntos de datos en los que se presentan los resultados no contienen más de 20 mil objetos (todos los conjuntos de datos del repositorio UCI). Surge una pregunta natural: ¿realmente no hay un conjunto de datos abierto de tamaño normal para tales experimentos en 2018? Puede ir más allá y comparar en un conjunto de datos de 50 objetos: existe la posibilidad de que el modelo constante no difiera significativamente de un bosque aleatorio.
El siguiente punto es la regularización. En una gran cantidad de signos, es muy fácil volver a entrenar, incluso sin interacciones. Los autores pueden creer que este problema no existe, y el único problema es el modelo de caja negra. Al menos en el artículo, no se habla de regularización en ningún lado, aunque obviamente es necesario.
Y el último, sobre la interpretabilidad. Incluso los modelos lineales no son interpretables si tenemos muchas características. Cuando tiene 10 mil pesos distribuidos normalmente (en el caso de utilizar la regularización L2 será algo así), es imposible decir exactamente qué signos son responsables del hecho de que predic_proba da 0,86. Para la interpretación, queremos no solo un modelo lineal, sino un modelo lineal con pesos dispersos. Parece que esto se puede lograr mediante la regularización L1, pero aquí tampoco es tan simple. De un conjunto de características fuertemente correlacionadas, la regularización L1 elegirá una casi por accidente. El resto tendrá un peso de 0, aunque si una de estas características tiene capacidad predictiva, las otras claramente no son solo ruido. En términos de interpretación del modelo, esto puede estar bien, en términos de entender la relación de las características y la variable objetivo, esto es muy malo. Es decir, incluso con modelos lineales, no todo es tan simple,
aquí se pueden encontrar más detalles sobre modelos interpretables y creíbles.
Visualización para Machine Learning: UMAPAbsractCódigoEl día de los tutoriales, uno de los primeros en presentarse fue "Visualización para el aprendizaje automático" de Google Brain. Como parte del tutorial, nos contaron sobre la historia de las visualizaciones, comenzando por el creador de los primeros gráficos, así como sobre varias características del cerebro humano y la percepción y las técnicas que se pueden utilizar para llamar la atención sobre lo más importante de la imagen, incluso con muchos pequeños detalles, por ejemplo, resaltar forma, color, marco, etc., como en la imagen a continuación. Me saltearé esta parte, pero hay una
buena crítica .

Personalmente, estaba más interesado en el tema de la visualización de conjuntos de datos multidimensionales, en particular, el enfoque de Aproximación y Proyección de Colector Uniforme (UMAP), un nuevo método no lineal para reducir la dimensión. Se propuso en febrero de este año, por lo que pocas personas lo usan todavía, pero parece prometedor tanto en términos de tiempo de trabajo como en términos de la calidad de la separación de clases en visualizaciones bidimensionales. Entonces, en diferentes conjuntos de datos, UMAP está 2-10 veces por delante de t-SNE y otros métodos en términos de velocidad, y cuanto mayor sea la dimensión de datos, mayor será la brecha en el rendimiento:
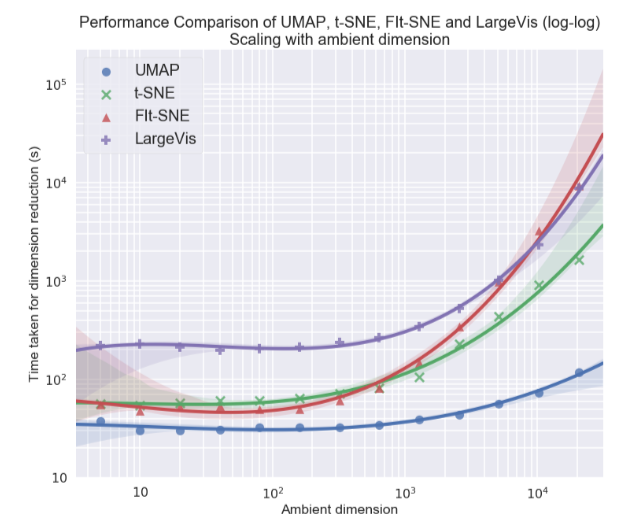
Además, a diferencia de t-SNE, el tiempo de funcionamiento de UMAP es casi independiente de la dimensión del nuevo espacio en el que integraremos nuestro conjunto de datos (consulte la figura a continuación), lo que lo convierte en una herramienta adecuada para otras tareas (además de la visualización), en particular, para reducir la dimensión antes de entrenar el modelo.
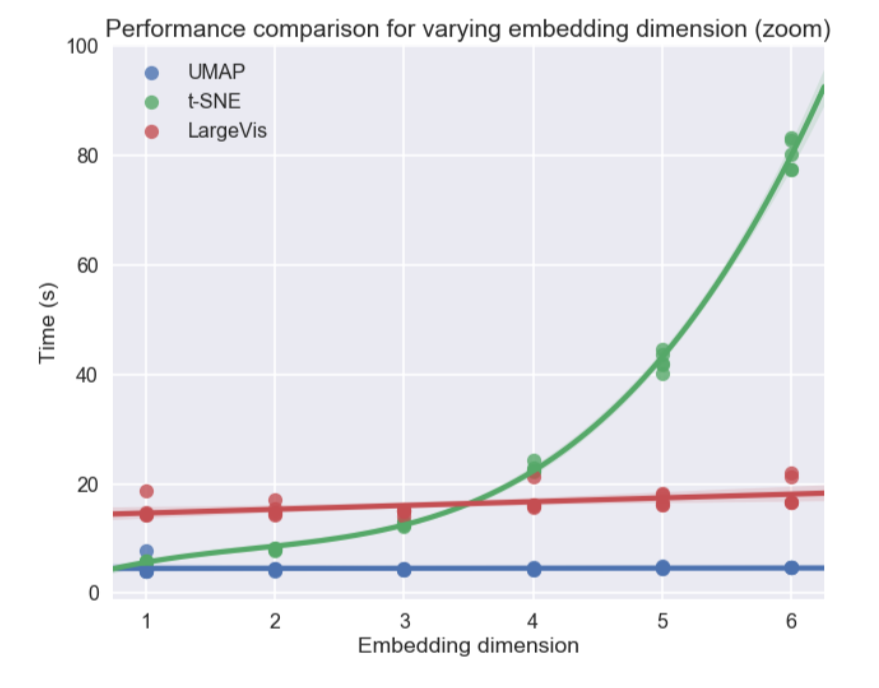
Al mismo tiempo, las pruebas en diferentes conjuntos de datos mostraron que UMAP no funciona peor para la visualización, y t-SNE es mejor en algunos lugares: por ejemplo, en conjuntos de datos MNIST y Fashion MNIST, las clases están mejor separadas en la versión con UMAP:
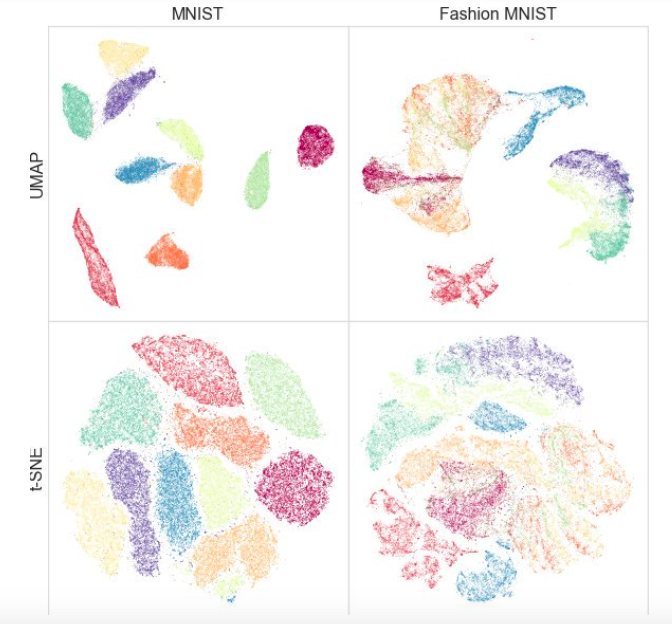
Una ventaja adicional es una implementación conveniente: la clase UMAP hereda de las clases sklearn, por lo que puede usarla como un transformador regular en la tubería sklearn. Además, se argumenta que UMAP es más interpretable que t-SNE, ya que mantiene mejor una estructura de datos global.
En el futuro, los autores planean agregar soporte para capacitación semi-supervisada, es decir, si tenemos etiquetas para al menos algunos de los objetos, podemos construir UMAP en base a esta información.
¿Qué artículos te gustaron? Escriba comentarios, haga preguntas, las responderemos.