Continuamos experimentando con los formatos de los mitaps. Recientemente, en un ring de boxeo,
chocamos con un bus de datos centralizado y Service Mesh. Esta vez decidimos probar algo más pacífico: StandUp, es decir, un micrófono abierto. El tema fue elegido en la base de datos en memoria.

¿En qué casos debo cambiar a memoria? ¿Cómo y por qué escalar? ¿Y a qué vale la pena prestarle atención? Las respuestas están en los discursos de los oradores, que cubriremos en esta publicación.
Pero primero, imagine los altavoces:
- Andrey Trushkin, Jefe del Centro de Innovación y Tecnologías Avanzadas de Promsvyazbank
- Vladislav Shpileva, desarrollador de Tarantool
- Artyom Shitov, arquitecto de soluciones de GridGain
Cambiar a memoria
Las tendencias actuales en el mercado financiero imponen requisitos mucho más estrictos sobre el tiempo de respuesta y la operación de la automatización de procesos en general. Además, casi todas las instituciones financieras más grandes de hoy buscan construir sus propios ecosistemas.
En este sentido, vemos por nosotros mismos dos aplicaciones principales de soluciones en memoria. El primero es el almacenamiento en caché de datos de integración. Según el escenario clásico, en las grandes empresas existen varios sistemas automatizados que proporcionan datos a solicitud del usuario. O un sistema externo, pero en este caso, el iniciador en la mayoría de los casos es el usuario. Tradicionalmente, estos sistemas almacenaban datos estructurados de cierta manera en la base de datos, accediendo a ellos a pedido.
Hoy, tales sistemas ya no cumplen con los requisitos en términos de carga. Aquí no debemos olvidar las llamadas remotas de estos sistemas por parte de los sistemas de consumo. Esto implica la necesidad de revisar los enfoques para el almacenamiento y la presentación de datos a usuarios, sistemas automatizados o servicios individuales. Salida lógica: almacenamiento de datos relevantes utilizados por los servicios en el nivel de capa en memoria; Hay muchos casos exitosos similares en el mercado.
Este fue el primer caso. El segundo es efectivo, desde un punto de vista técnico, la gestión de procesos de negocio. Los sistemas BPM tradicionales automatizan la ejecución de ciertas operaciones de acuerdo con un algoritmo predefinido. Y en muchos casos surgen preguntas: ¿por qué estos sistemas no son lo suficientemente eficientes y rápidos?
Típicamente, tales sistemas escriben cada paso (o un pequeño conjunto de pasos, diseñado como una transacción comercial) en la base de datos. Por lo tanto, están vinculados al tiempo de respuesta y la interacción con estos sistemas. Ahora, el número de instancias de procesos de negocio que se ejecutan simultáneamente en tiempo real es de órdenes de magnitud hace más de 10 años. Por lo tanto, los sistemas modernos de gestión de procesos comerciales deberían tener un rendimiento significativamente mayor y garantizar la ejecución de aplicaciones descentralizadas. Además, hoy todas las empresas están avanzando hacia la formación de un gran entorno de microservicios. El desafío es que diferentes instancias de procesos de negocios pueden compartir y usar eficientemente datos operativos. Dentro del marco de la orquestación, tiene sentido almacenarlos en una solución en memoria.
Problema de reconciliación
Supongamos que tenemos una gran cantidad de nodos y servicios, que se llevan a cabo una serie de procesos comerciales, cuyas acciones se implementan en forma de microservicios. Para mejorar el rendimiento, cada uno de ellos comienza a escribir su estado en una instancia de memoria local. Obtenemos una gran cantidad de instancias locales. ¿Cómo garantizar la relevancia y la coherencia para todos?
Utilizamos zonas de zonas en memoria. Por ejemplo, dependiendo del dominio comercial. Cuando cortamos un dominio comercial, determinamos que ciertos microservicios / procesos comerciales funcionan solo dentro del marco de la zona que es responsable del dominio correspondiente. De esta forma podemos acelerar la actualización de la memoria caché y la solución completa en memoria.
Al mismo tiempo, el caché responsable del dominio opera en modo de replicación completa: el número limitado de nodos debido a la distribución entre dominios garantiza la velocidad y la corrección de la solución en este modo. La zonificación y la fragmentación máxima ayudan a resolver los problemas de sincronización, operación del clúster, etc. en un gran número total de nodos.
Naturalmente, a menudo surgen preguntas sobre la fiabilidad de las soluciones en memoria. Sí, no todo se puede poner allí. Para garantizar la fiabilidad, siempre tenemos bases de datos al lado de la memoria. Por ejemplo, para problemas importantes con los informes que deben reunirse, lo que puede ser difícil en una gran cantidad de nodos. Entonces, ¿cuál es nuestra visión hoy: la
sinergia de los dos enfoques .
También vale la pena señalar que estos dos enfoques tampoco son del todo correctos solo para contrastar. Y al mismo tiempo, concéntrate en ellos. Los fabricantes y colaboradores de sistemas avanzados de virtualización en contenedores, como Kubernetes, ya nos brindan opciones para un almacenamiento confiable a largo plazo. Ya han aparecido buenos casos industriales para implementar soluciones, en los que el almacenamiento se lleva a cabo en un formato virtualizado.
Uno de los periódicos más grandes de EE. UU. Ofrece a sus lectores la oportunidad de recibir cualquier número en línea que se haya publicado desde el comienzo de la publicación de este periódico en el siglo XIX. Podemos imaginar el nivel de carga. El almacenamiento lo implementan a través de la plataforma Apache Kafka, implementada en Kubernetes. Aquí hay otra opción para almacenar información y proporcionar acceso a una gran cantidad de clientes bajo una gran carga. Al diseñar nuevas soluciones, también vale la pena prestar atención a esta opción.
Escalado de bases de datos en memoria con Tarantool
Supongamos que tenemos un servidor. Acepta solicitudes, almacena datos. De repente hay más solicitudes y datos, el servidor deja de hacer frente a la carga. Puede cargar más hardware en el servidor y aceptará más solicitudes. Pero este es un callejón sin salida por tres razones a la vez: alto costo, capacidades técnicas limitadas y problemas con la tolerancia a fallas. En cambio, hay una escala horizontal: los "amigos" acuden al servidor para ayudarlo a completar las tareas. Los dos tipos principales de escala horizontal son la replicación y el fragmentación.
La replicación se produce cuando hay muchos servidores, todos almacenan los mismos datos y las solicitudes de los clientes se encuentran dispersas en todos estos servidores. Así es como escala la informática, no los datos. Esto funciona cuando los datos se colocan en un nodo, pero hay tantas solicitudes de clientes que un servidor no puede manejarlos. Además, aquí se mejora mucho la tolerancia a fallos.
El fragmentación se utiliza para escalar datos: se crean muchos servidores y almacenan datos diferentes. Entonces escala tanto los cálculos como los datos. Pero la tolerancia a fallas en este caso es baja. Si falla un servidor, se perderá parte de los datos.
Hay un tercer enfoque: combinarlos. Dividimos el clúster en subgrupos, los llamamos conjuntos de réplica. Cada uno de ellos almacena los mismos datos, y los datos no se cruzan entre conjuntos de réplicas. El resultado es escalar datos, computación y tolerancia a fallas.
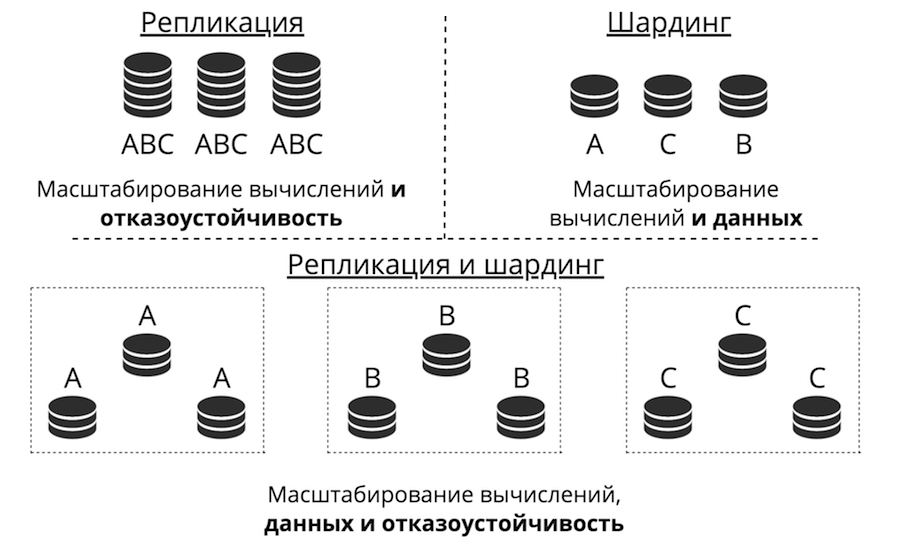
Replicación
La replicación puede ser de dos tipos: asíncrona y sincrónica. Asíncrono es cuando las solicitudes del cliente no esperan hasta que los datos se dispersen por las réplicas: escribir en una réplica es suficiente. Tan pronto como los datos llegan al disco, al registro, la transacción tiene éxito y algún día en el fondo estos datos se replican. Sincrónico: cuando una transacción se divide en 2 fases: preparar y confirmar. Commit no devolverá el éxito hasta que los datos se repliquen en algún quórum de réplicas.
La replicación asincrónica es obviamente más rápida porque nada descansa en la red. Los datos se enviarán a la red en segundo plano y la transacción en sí, tal como está registrada en el registro, se ha completado. Pero hay un problema: las réplicas pueden retrasarse entre sí, aparecen sincronizadas.
La replicación sincrónica es más confiable, pero mucho más lenta y más difícil de implementar. Hay protocolos complejos. En Tarantool, puede elegir cualquiera de estos tipos de replicaciones, según la tarea.

El retraso de las réplicas da lugar no solo a la desincronización, sino también al problema de ignorancia del maestro: no sabe cómo pasar sus cambios a la réplica. Los cambios generalmente se dan de forma incremental: se aplican y, de la misma forma, se alejan volando hacia la réplica. Pero, ¿qué hacer con ellos si la réplica no está disponible? Por ejemplo, todo se puede configurar en Tarantool, y el asistente se vuelve muy flexible.
Otro desafío: ¿cómo hacer que la topología sea compleja? Mail.ru, por ejemplo, tiene una topología con cientos de Tarantool. Tiene un núcleo de tarantool al que las tarántulas de réplica para copias de seguridad están vinculadas en un círculo. En Tarantool, puede hacer topologías completamente arbitrarias, la replicación con esta vive perfectamente.
Sharding
Ahora pasemos a la escala de datos: fragmentación. Puede ser de dos tipos: rangos y hashes. La división de rango es cuando todos los datos se ordenan por alguna clave de división, y esta secuencia grande se divide en rangos para que cada rango tenga aproximadamente la misma cantidad de datos. Y cada rango se almacena por completo en cualquier nodo físico. Pero por lo general, no se necesita tal fragmentación. Además, siempre es muy complicado.
También hay fragmentación con hashes. Se acaba de presentar en Tarantool. Es mucho más fácil de implementar, usar y casi siempre es adecuado en lugar de rangos de fragmentación. Funciona así: consideramos la función hash del registro y devuelve el número del nodo físico en el que almacenar. Hay problemas: en primer lugar, es difícil completar rápidamente una consulta compleja.
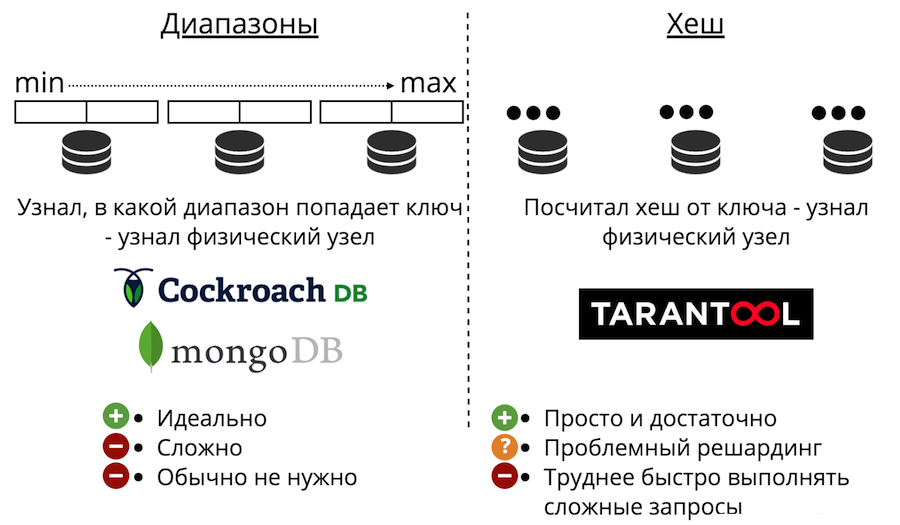
En segundo lugar, está el problema de la reorganización. Hay algún tipo de función de fragmento que devuelve el número del fragmento físico en el que se debe guardar la clave. Y cuando cambia el número de nodos, la función de fragmento también cambia. Esto significa que para todos los datos que están en el clúster, deberá volver a calcularse y verificarse nuevamente. Además, en la división clásica, algunos datos no se transferirán a un nuevo nodo, sino que simplemente se barajarán entre los nodos antiguos. Las transferencias inútiles no se pueden reducir a cero en el fragmentación clásica.
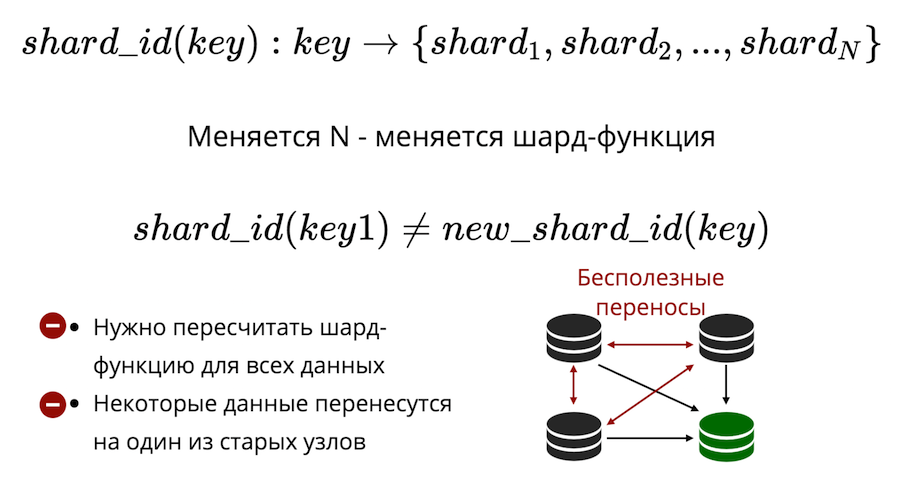
Tarantool utiliza fragmentación virtual: los datos se distribuyen no en nodos físicos, sino virtuales. Cubo virtual en un clúster virtual. Y las historias virtuales se presentan en las físicas. Y ya está garantizado que cada piso virtual se encuentra completamente en un piso físico.
¿Cómo resuelve esto el problema de la reventa? El hecho es que el número de depósitos es fijo y excede seriamente el número de nodos físicos. Por lo tanto, no importa cuánto escale físicamente su clúster, el depósito siempre será suficiente para almacenar datos y distribuirlos de manera uniforme. Y debido a que la función de fragmento no ha cambiado, no tendrá que volver a calcularla cuando cambie la composición del clúster.
Como resultado, obtenemos
tres tipos de fragmentación: rangos, hashes y cubos virtuales . En el caso de rangos y depósitos, existe un problema de búsqueda física.
¿Cómo solucionarlo? La primera forma: simplemente prohibir el re-compartir. Luego, para volver a compartir, tendrá que crear un nuevo clúster y transferir todo allí. La segunda forma: ir siempre a todos los nodos. Pero esto no tiene sentido, porque necesita escalar, y los cálculos no escalan así. Tercera opción: un módulo proxy, que sirve como un tipo de enrutador para cubos. Lo inicia, envía una solicitud allí, indicando el número del depósito, y enviará su solicitud como proxy al nodo físico deseado.
Avanzado en memoria con el ejemplo de plataforma GridGain
El negocio tiene requisitos de base de datos adicionales. Él quiere que todo esto sea tolerante a fallas y catastrófico. Quiere alta disponibilidad: para que nunca se pierda nada, para que pueda recuperarse rápidamente. También se necesita una escalabilidad fácil y económica, soporte sin complicaciones, confianza en la plataforma y mecanismos de acceso eficientes.
Todas estas ideas no son nuevas. Muchas de estas cosas se implementan, en un grado u otro, en los DBMS clásicos, en particular, la replicación entre centros de datos.
In-Memory ya no es una tecnología de inicio, son productos maduros que se utilizan en las empresas más grandes del mundo (Barclays, Citi Group, Microsoft, etc.). Se supone que allí se cumplen todos estos requisitos.
Entonces, si una catástrofe sucedió de repente, debería haber una oportunidad para recuperarse de la copia de seguridad. Y si estamos hablando de una organización financiera, es importante que esta copia de seguridad sea coherente y no solo una copia de todas las unidades. Para que no haya una situación en la que en algunas partes de los nodos los datos se restauraron en el momento X, y en la otra parte en el tiempo Y. Es muy importante tener la recuperación en un punto en el tiempo, de modo que incluso en una situación de corrupción de datos o un accidente particularmente grave, minimice la cantidad de pérdida.
Es importante poder enviar datos al disco. Para que el clúster no se sobrecargue y continúe funcionando aún más lentamente. Y para levantarse rápidamente del disco, y luego ya bombeó los datos a la memoria.
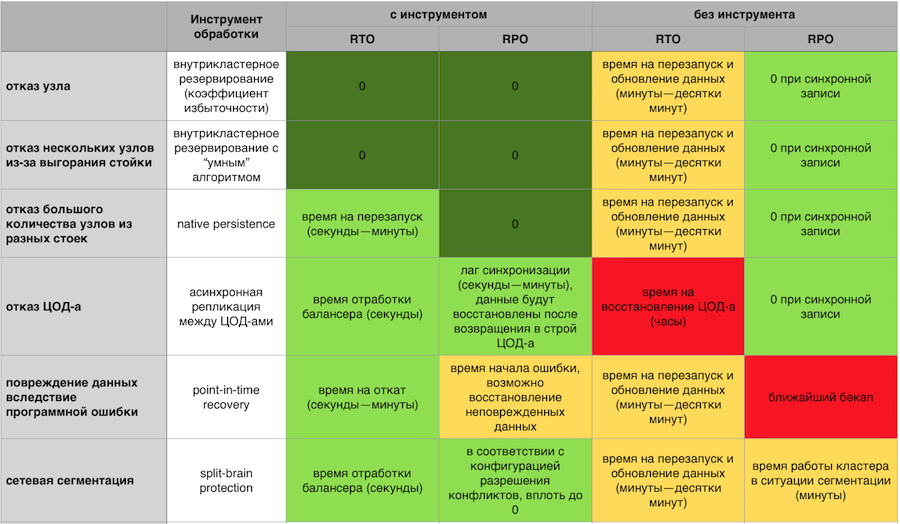 Respuesta en memoria a fallas con y sin componentes de tolerancia a fallas GridGain
Respuesta en memoria a fallas con y sin componentes de tolerancia a fallas GridGainUn clúster de conmutación por error debe escalar fácilmente horizontal y verticalmente. No tengo ganas de pagar mi servidor y ver cómo la mitad de los recursos están inactivos. No quiero tener el infierno de cientos de procesos que necesitan ser gestionados. Quiero un sistema simple desde el punto de vista del soporte, con entrada y salida fácil de nodos del clúster y un sistema de monitoreo desarrollado y maduro.
Considere MongoDB en esta perspectiva. Todos los que han trabajado con MongoDB conocen una gran cantidad de procesos. Si tenemos un MongoDB sombreado de 5 fragmentos, cada fragmento tendrá un conjunto de réplica de tres procesos (con una relación de redundancia de 3). Y esto son 15 procesos solo en los datos en sí. El almacenamiento de configuración de clúster es otro más 3 procesos, en total obtiene 18, y esto no incluye enrutadores. Si quieres 20 fragmentos, bienvenido a más de 63 procesos (por ejemplo, otros 8, un total de 71) procesos.
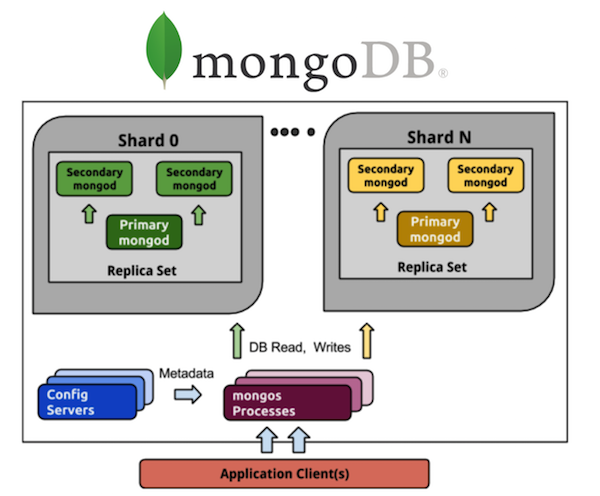
Compáralo con Cassandra. Tomamos los mismos 5 fragmentos: estos son 5 procesos y 5 nodos con la misma relación de redundancia de 3, que es mucho más simple en términos de control. Quiero 20 fragmentos: estos son 20 procesos. Puedo escalar mi clúster a cualquier número de nodos, no necesariamente un múltiplo de 3 (u otro valor del coeficiente de redundancia). Mucho más fácil y económico de implementar y mantener que los conjuntos de réplica.

Además, debe confiar en el sistema, para comprender qué respaldan las personas cada producto individual. Idealmente, la licencia debe ser de código abierto o núcleo abierto. Para que, en caso de fallecimiento del vendedor, se pueda hacer algo. También es bueno si el código fuente es administrado por una comunidad independiente: todos recordamos cómo MongoDB y Redis cambiaron las licencias a pedido de la compañía administradora. Cómo Aerospike introdujo restricciones en la edición comunitaria de "código abierto" a principios de año.
Necesita acceso efectivo a los datos. Casi todos tienen un lenguaje de consulta estructurado de una forma u otra. La mayoría de las veces usan SQL, es necesario que la adaptación con este lenguaje sea lo más fácil posible. Esto ayudará a la ejecución de consultas distribuidas, cuando no necesite enviar una solicitud por separado a cada nodo, pero puede comunicarse con el clúster como con una "ventana única". Sin pensar desde el punto de vista de la API, este es un conjunto de nodos (recuerde lo difícil que es trabajar con Memcache en grandes volúmenes incluso en el nivel más simple de poner / obtener, sin consultas SQL potencialmente complejas), garantías distribuidas de DDL y ACID.
Y finalmente, apoyo. Si algo de repente no funciona, entonces la compañía simplemente pierde dinero. Para algunas áreas esto no es crítico, pero a menudo es importante que alguien asuma la responsabilidad del producto y su trabajo. Que era posible en cualquier momento hacer un reclamo, y se resolvió rápidamente.
Con esta publicación estamos completando el año de Promsvyazbank en Habré. Recolectamos los deseos de Año Nuevo para los residentes de Khabrovsk en un video corto: