Hola colegas

En la última publicación del año saliente, queríamos mencionar Reinforcement Learning, un tema en el que ya estamos traduciendo un
libro .
Juzgue usted mismo: había un artículo elemental con Medium, que describía el contexto del problema, describía el algoritmo más simple con implementación en Python. El artículo tiene varios gifs. Y la motivación, la recompensa y la elección de la estrategia correcta en el camino hacia el éxito son cosas que serán extremadamente útiles para cada uno de nosotros en el próximo año.
Que tengas una buena lectura!
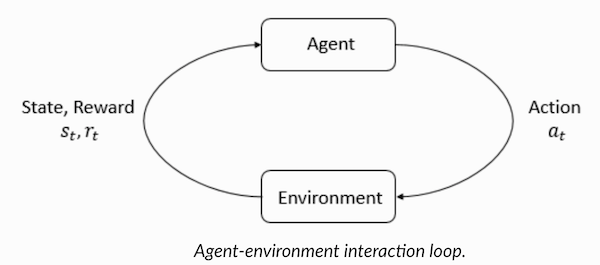
El aprendizaje reforzado es una forma de aprendizaje automático en el que el agente aprende a actuar en el entorno, realizando acciones y desarrollando así la intuición, después de lo cual observa los resultados de sus acciones. En este artículo te diré cómo entender y formular el problema de aprender con refuerzo, y luego resolverlo en Python.
Recientemente, nos hemos acostumbrado al hecho de que las computadoras juegan juegos contra humanos, ya sea como bots en juegos multijugador o como rivales en juegos uno a uno: digamos, en Dota2, PUB-G, Mario. La compañía de investigación
Deepmind hizo un
escándalo por las noticias cuando su programa AlphaGo 2016 venció al campeón surcoreano en 2016. Si eres un ávido jugador, podrías escuchar acerca de los cinco partidos de Dota 2 OpenAI Five, donde los autos lucharon contra las personas y derrotaron a los mejores jugadores en Dota2 en varios partidos. (Si está interesado en los detalles, el algoritmo se analiza en detalle
aquí y se examina cómo funcionaban las máquinas).

La última versión de OpenAI Five
lleva a Roshan .
Entonces, comencemos con la pregunta central. ¿Por qué necesitamos entrenamiento reforzado? ¿Se usa solo en juegos o es aplicable en escenarios realistas para resolver problemas aplicados? Si es la primera vez que lees el entrenamiento de refuerzo, simplemente no puedes imaginar la respuesta a estas preguntas. De hecho, el aprendizaje reforzado es una de las tecnologías más utilizadas y de rápido desarrollo en el campo de la inteligencia artificial.
Aquí hay una serie de áreas temáticas en las que los sistemas de aprendizaje por refuerzo son especialmente demandados:
- Vehículos no tripulados
- Industria del juego
- Robótica
- Sistemas de recomendación
- Publicidad y mercadeo
Resumen y antecedentes del aprendizaje por refuerzoEntonces, ¿cómo se formó el fenómeno de aprendizaje con refuerzo cuando tenemos tantos métodos de aprendizaje profundo y máquinas a nuestra disposición? "Fue inventado por Rich Sutton y Andrew Barto, el supervisor de investigación de Rich, quienes lo ayudaron a preparar su doctorado". El paradigma se formó por primera vez en la década de 1980 y luego fue arcaico. Posteriormente, Rich creía que ella tenía un gran futuro, y que eventualmente recibiría reconocimiento.
El aprendizaje reforzado admite la automatización en el entorno donde se implementa. Tanto la máquina como el aprendizaje profundo operan aproximadamente de la misma manera: están organizados estratégicamente de manera diferente, pero ambos paradigmas admiten la automatización. Entonces, ¿por qué surgió el entrenamiento de refuerzo?
Es una reminiscencia del proceso de aprendizaje natural en el que el proceso / modelo actúa y recibe comentarios sobre cómo se las arregla para hacer frente a la tarea: buena y no.
La máquina y el aprendizaje profundo también son opciones de capacitación, sin embargo, están más diseñados para identificar patrones en los datos disponibles. En el aprendizaje por refuerzo, por otro lado, dicha experiencia se obtiene mediante prueba y error; el sistema encuentra gradualmente las opciones correctas u óptimo global. Una gran ventaja adicional del aprendizaje reforzado es que, en este caso, no es necesario proporcionar un amplio conjunto de datos de capacitación, como ocurre con la enseñanza con un maestro. Unos pequeños fragmentos serán suficientes.
El concepto de aprendizaje por refuerzo.Imagina enseñar a tus gatos nuevos trucos; pero, desafortunadamente, los gatos no entienden el lenguaje humano, por lo que no puedes tomar y decirles lo que vas a jugar con ellos. Por lo tanto, actuará de manera diferente: imite la situación y el gato tratará de responder de una forma u otra en respuesta. Si el gato reaccionó de la manera que quería, entonces le vierte leche. ¿Entiendes lo que sucederá después? Una vez más, en una situación similar, el gato volverá a realizar la acción deseada, y con un entusiasmo aún mayor, con la esperanza de que se alimente aún mejor. Así es como se lleva a cabo el aprendizaje en un ejemplo positivo; pero, si intentas "educar" a un gato con incentivos negativos, por ejemplo, míralo estrictamente y frunce el ceño, por lo general no aprende en tales situaciones.
El aprendizaje reforzado funciona de manera similar. Le decimos a la máquina algunas entradas y acciones, y luego recompensamos la máquina dependiendo de la salida. Nuestro objetivo final es maximizar las recompensas. Ahora veamos cómo reformular el problema anterior en términos de aprendizaje por refuerzo.
- El gato actúa como un "agente" expuesto al "medio ambiente".
- El entorno es un hogar o área de juego, dependiendo de lo que le estés enseñando al gato.
- Las situaciones que surgen de la capacitación se denominan "estados". En el caso de un gato, ejemplos de condiciones son cuando el gato "corre" o "se arrastra debajo de la cama".
- Los agentes reaccionan realizando acciones y moviéndose de un "estado" a otro.
- Después de que el estado cambia, el agente recibe una "recompensa" o una "multa" dependiendo de la acción que haya tomado.
- La "estrategia" es una metodología para elegir una acción para obtener los mejores resultados.
Ahora que hemos descubierto qué es el aprendizaje por refuerzo, hablemos en detalle sobre los orígenes y la evolución del aprendizaje por refuerzo y el aprendizaje profundo con refuerzo, discutamos cómo este paradigma nos permite resolver problemas que son imposibles de aprender con o sin un maestro, y también tenga en cuenta lo siguiente Dato curioso: en la actualidad, el motor de búsqueda de Google está optimizado mediante algoritmos de aprendizaje por refuerzo.
Comprender la terminología del aprendizaje por refuerzoEl agente y el entorno desempeñan papeles clave en el algoritmo de aprendizaje de refuerzo. El entorno es el mundo en el que el Agente tiene que sobrevivir. Además, el Agente recibe señales de refuerzo del Medio Ambiente (recompensa): este es un número que describe cuán bueno o malo puede considerarse el estado actual del mundo. El propósito del Agente es maximizar la recompensa total, la llamada "ganancia". Antes de escribir nuestros primeros algoritmos de aprendizaje de refuerzo, debe comprender la siguiente terminología.

- Estados : un estado es una descripción completa de un mundo en el que no falta un solo fragmento de la información que lo caracteriza. Puede ser una posición, fija o dinámica. Como regla general, dichos estados se escriben en forma de matrices, matrices o tensores de orden superior.
- Acción : la acción generalmente depende de las condiciones ambientales, y en diferentes entornos el agente tomará diferentes acciones. Muchas acciones válidas del agente se registran en un espacio llamado "espacio de acción". Típicamente, el número de acciones en el espacio es finito.
- Entorno : este es el lugar en el que existe el agente y con el que interactúa. Se utilizan diferentes tipos de recompensas, estrategias, etc. para diferentes entornos.
- Recompensas y ganancias : debes controlar constantemente la función de recompensa R cuando entrenas con refuerzos. Es fundamental cuando configura un algoritmo, lo optimiza y también cuando deja de aprender. Depende del estado actual del mundo, la acción que se acaba de tomar y el próximo estado del mundo.
- Estrategias : una estrategia es una regla según la cual un agente elige la siguiente acción. El conjunto de estrategias también se conoce como el "cerebro" del agente.
Ahora que nos hemos familiarizado con la terminología de aprendizaje por refuerzo, solucionemos el problema utilizando los algoritmos apropiados. Antes de esto, debe comprender cómo formular un problema de este tipo y, al resolverlo, confiar en la terminología del entrenamiento con refuerzo.
Solución de taxiEntonces, pasamos a resolver el problema con el uso de algoritmos de refuerzo.
Supongamos que tenemos una zona de entrenamiento para un taxi no tripulado, que entrenamos para entregar pasajeros al estacionamiento en cuatro puntos diferentes (
R,G,Y,B ). Antes de eso, debe comprender y establecer el entorno en el que comenzamos a programar en Python. Si recién comienza a aprender Python, le recomiendo
este artículo .
El entorno para resolver un problema de taxi se puede configurar con OpenAI's
Gym : esta es una de las bibliotecas más populares para resolver problemas con el entrenamiento de refuerzo. Bueno, antes de usar el gimnasio, debe instalarlo en su máquina, y un administrador de paquetes de Python llamado pip es conveniente para esto. El siguiente es el comando de instalación.
pip install gymA continuación, veamos cómo se mostrará nuestro entorno. Todos los modelos y la interfaz para esta tarea ya están configurados en el gimnasio y nombrados bajo
Taxi-V2 . El fragmento de código a continuación se utiliza para mostrar este entorno.
“Tenemos 4 ubicaciones (indicadas por letras diferentes); nuestra tarea es recoger a un pasajero en un punto y dejarlo en otro. Obtenemos +20 puntos por un aterrizaje exitoso de pasajeros y perdemos 1 punto por cada paso gastado en él. También hay una penalización de 10 puntos por cada embarque y desembarque involuntario de un pasajero ". (Fuente:
gym.openai.com/envs/Taxi-v2 )
Aquí está la salida que veremos en nuestra consola:

Taxi V2 ENV
Genial,
env es el corazón de OpenAi Gym, es una interfaz de entorno unificada. Los siguientes son métodos env que nos parecen útiles:
env.reset : restablece el entorno y devuelve un estado inicial aleatorio.
env.step(action) :
env.step(action) desarrollo del entorno un paso en el tiempo.
env.step(action) : devuelve las siguientes variables
observation : Observación del medio ambiente.reward : reward si tu acción fue beneficiosa.done : indica si logramos recoger y dejar al pasajero correctamente, también denominado "un episodio".info : información adicional como el rendimiento y la latencia necesarios para la depuración.env.render : muestra un cuadro del entorno (útil para renderizar)
Entonces, después de examinar el entorno, intentemos comprender mejor el problema. Los taxis son el único automóvil en este estacionamiento. El estacionamiento se puede dividir en una cuadrícula de
5x5 , donde obtenemos 25 posibles ubicaciones de taxis. Estos 25 valores son uno de los elementos de nuestro espacio de estado. Tenga en cuenta: en este momento, nuestro taxi se encuentra en el punto con coordenadas (3, 1).
Hay 4 puntos en el entorno donde los pasajeros pueden abordar: estos son:
R, G, Y, B o
[(0,0), (0,4), (4,0), (4,3)] en coordenadas ( horizontalmente; verticalmente), si fuera posible interpretar el entorno anterior en coordenadas cartesianas. Si también tiene en cuenta un (1) estado más del pasajero: dentro del taxi, puede tomar todas las combinaciones de ubicaciones de pasajeros y sus destinos para calcular el número total de estados en nuestro entorno para la formación de taxis: tenemos cuatro (4) destinos y cinco (4+ 1) ubicaciones de pasajeros.
Entonces, en nuestro entorno para un taxi, hay 5 × 5 × 5 × 4 = 500 estados posibles. Un agente maneja una de las 500 condiciones y toma medidas. En nuestro caso, las opciones son las siguientes: moverse en una dirección u otra, o la decisión de recoger / dejar al pasajero. En otras palabras, tenemos a nuestra disposición seis acciones posibles:
recogida, caída, norte, este, sur, oeste (los últimos cuatro valores son direcciones en las que puede moverse un taxi).
Este es el
action space : el conjunto de todas las acciones que nuestro agente puede realizar en un estado determinado.
Como queda claro en la ilustración anterior, un taxi no puede realizar ciertas acciones en algunas situaciones (las paredes interfieren). En el código que describe el entorno, simplemente asignamos una penalización de -1 por cada golpe en la pared y un taxi que colisiona con la pared. Por lo tanto, tales multas se acumularán, por lo que el taxi intentará no golpear las paredes.
Tabla de recompensas: al crear un entorno de taxi, también se puede crear una tabla de recompensas primaria llamada P. Puede considerarla una matriz, donde el número de estados corresponde al número de filas y el número de acciones al número de columnas. Es decir, estamos hablando de la matriz de
states × actions .
Como absolutamente todas las condiciones se registran en esta matriz, puede ver los valores de recompensa predeterminados asignados al estado que hemos elegido para ilustrar:
>>> import gym >>> env = gym.make("Taxi-v2").env >>> env.P[328] {0: [(1.0, 433, -1, False)], 1: [(1.0, 233, -1, False)], 2: [(1.0, 353, -1, False)], 3: [(1.0, 333, -1, False)], 4: [(1.0, 333, -10, False)], 5: [(1.0, 333, -10, False)] }
La estructura de este diccionario es la siguiente:
{action: [(probability, nextstate, reward, done)]} .
- Los valores 0–5 corresponden a las acciones (sur, norte, este, oeste, recogida, devolución) que un taxi puede realizar en el estado actual que se muestra en la ilustración.
- done le permite juzgar cuándo dejamos con éxito al pasajero en el punto deseado.
Para resolver este problema sin ningún entrenamiento con refuerzo, puede establecer el estado objetivo, hacer una selección de espacios y luego, si puede alcanzar el estado objetivo durante un cierto número de iteraciones, suponga que este momento corresponde a la recompensa máxima. En otros estados, el valor de la recompensa se aproxima al máximo si el programa actúa correctamente (se acerca a la meta) o acumula multas si comete errores. Además, el valor de la multa no puede llegar a menos de -10.
Escribamos código para resolver este problema sin entrenamiento de refuerzo.
Dado que tenemos una tabla P con valores de recompensa predeterminados para cada estado, podemos intentar organizar la navegación de nuestro taxi solo en base a esta tabla.
Creamos un bucle sin fin, desplazándonos hasta que el pasajero llegue al destino (un episodio) o, en otras palabras, hasta que la tasa de recompensa alcance 20. El método
env.action_space.sample() selecciona automáticamente una acción aleatoria del conjunto de todas las acciones disponibles. . Considera lo que sucede:
import gym from time import sleep
Conclusión
créditos: OpenAI
El problema está resuelto, pero no está optimizado, o este algoritmo no funcionará en todos los casos. Necesitamos un agente de interacción adecuado para que el número de iteraciones gastadas por la máquina / algoritmo para resolver el problema siga siendo mínimo. Aquí el algoritmo de Q-learning nos ayudará, cuya implementación consideraremos en la siguiente sección.
Introduciendo Q-LearningA continuación se muestran los algoritmos de aprendizaje por refuerzo más populares y uno de los más simples. El entorno recompensa al agente por su entrenamiento gradual y por el hecho de que, en un estado particular, da el paso más óptimo. En la implementación discutida anteriormente, teníamos una tabla de recompensas "P", según la cual nuestro agente aprenderá. Según la tabla de recompensas, elige la siguiente acción según lo útil que sea, y luego actualiza otro valor, llamado valor Q. Como resultado, se crea una nueva tabla, llamada Q-table, que se muestra en la combinación (Estado, Acción). Si los valores Q son mejores, obtenemos recompensas más optimizadas.
Por ejemplo, si un taxi se encuentra en un estado en el que el pasajero se encuentra en el mismo punto que el taxi, es extremadamente probable que el valor Q para la acción "recoger" sea mayor que para otras acciones, por ejemplo, "dejar al pasajero" o "ir al norte". ".
Los valores Q se inicializan con valores aleatorios y, a medida que el agente interactúa con el entorno y recibe varias recompensas al realizar ciertas acciones, los valores Q se actualizan de acuerdo con la siguiente ecuación:

Esto plantea la pregunta: cómo inicializar los valores Q y cómo calcularlos. A medida que se realizan acciones, los valores Q se ejecutan en esta ecuación.
Aquí, Alpha y Gamma son los parámetros del algoritmo Q-learning. Alfa es el ritmo de aprendizaje, y gamma es el factor de descuento. Ambos valores pueden variar de 0 a 1 y a veces son iguales a uno. Gamma puede ser igual a cero, pero alfa no, porque el valor de las pérdidas durante la actualización debe compensarse (la tasa de aprendizaje es positiva). El valor alfa aquí es el mismo que cuando se enseña con un maestro. Gamma determina cuán importante queremos dar las recompensas que nos esperan en el futuro.
Este algoritmo se resume a continuación:
- Paso 1: inicialice la tabla Q, rellenándola con ceros, y para los valores Q establecemos constantes arbitrarias.
- Paso 2: Ahora deje que el agente responda al entorno y pruebe diferentes acciones. Para cada cambio de estado, seleccionamos una de todas las acciones posibles en este estado (S).
- Paso 3: vaya al siguiente estado (S ') en función de los resultados de la acción anterior (a).
- Paso 4: Para todas las acciones posibles desde el estado (S '), seleccione una con el valor Q más alto.
- Paso 5: Actualice los valores de la tabla Q de acuerdo con la ecuación anterior.
- Paso 6: Convierte el siguiente estado en el actual.
- Paso 7: Si se alcanza el estado objetivo, completamos el proceso y luego repetimos.
Q-learning en Python import gym import numpy as np import random from IPython.display import clear_output
Genial, ahora todos sus valores se almacenarán en la variable
q_table .
Por lo tanto, su modelo está entrenado en condiciones ambientales y ahora sabe cómo seleccionar pasajeros con mayor precisión. Y se familiarizó con el fenómeno del aprendizaje por refuerzo, y puede programar el algoritmo para resolver un nuevo problema.
Otras técnicas de aprendizaje de refuerzo:
- Procesos de toma de decisiones de Markov (MDP) y ecuaciones de Bellman
- Programación dinámica: RL basado en modelos, iteración de estrategia e iteración de valor
- Q-Training profundo
- Métodos de descenso de gradiente de estrategia
- Sarsa
El código para este ejercicio se encuentra en:
vihar / python-refuerzo-aprendizaje