 La última vez,
La última vez, consideramos la opción de generar pulsos para motores paso a paso, parcialmente eliminados del software al nivel de firmware. En caso de éxito completo, esto promete la ausencia de la necesidad de procesar interrupciones que llegan con una frecuencia de hasta 40 kHz. Pero esa opción tiene una serie de defectos obvios. En primer lugar, las aceleraciones no son compatibles allí. En segundo lugar, la granularidad de las frecuencias de paso permitidas en esa solución es de cientos de hercios (por ejemplo, es posible generar frecuencias de 40,000 Hz y 39966 Hz, pero es imposible generar frecuencias con una magnitud entre estos dos valores).
Implementación de aceleración
¿Es posible eliminar las desventajas indicadas usando las mismas herramientas UDB sin complicar el sistema? Vamos a hacerlo bien. Comencemos con lo más difícil: con las aceleraciones. Las aceleraciones se agregan al principio y al final del camino. En primer lugar, si los pulsos de alta frecuencia se aplican inmediatamente al motor paso a paso, requerirá una corriente mayor para comenzar la operación. La corriente alta permitida es el calentamiento y el ruido, por lo que es mejor limitarlo. Pero luego el motor puede omitir los pasos al inicio. Por lo tanto, es mejor acelerar el motor suavemente. En segundo lugar, si una cabeza pesada se detiene abruptamente, entonces experimenta transitorios asociados con la inercia. Las olas son visibles en plástico. Por lo tanto, es suavemente necesario no solo dispersarse, sino también detener la cabeza. Clásicamente, se presenta un gráfico de la velocidad del motor en forma de trapecio. Aquí hay un fragmento del código fuente del firmware Marlin:

Ni siquiera intentaré averiguar si es posible implementar esto usando UDB. Esto se debe al hecho de que otro tipo de aceleración ahora está de moda: no trapezoidal, sino S-Curve. Su horario se ve así:
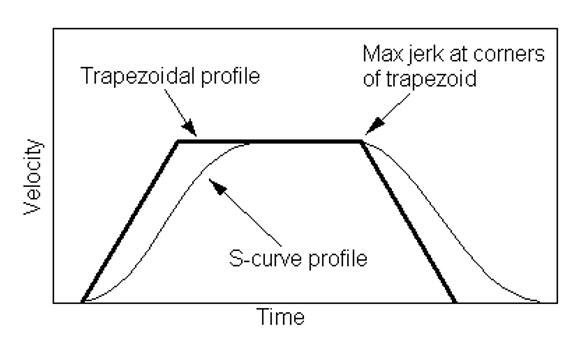
Esto definitivamente no es para UDB. ¿Rendirse? ¡Para nada! Ya noté que UDB no implementa una interfaz de hardware, sino que simplemente le permite transferir parte del código del software al nivel de firmware. Deje que el perfil calcule el procesador central, y la formación de pulsos escalonados todavía realiza UDB. El procesador central tiene mucho tiempo para los cálculos. La tarea de eliminar las interrupciones frecuentes continuará resolviéndose con bastante elegancia, y nadie planeó llevar el proceso por completo al nivel de firmware.
Por supuesto, el perfil deberá estar preparado en la memoria, y UDB recogerá los datos de allí utilizando DMA. ¿Pero cuánta memoria se requiere? Un milímetro necesita 200 pasos. ¡Ahora con codificación de 24 bits, esto es 600 bytes por 1 mm de movimiento de cabeza! Una vez más, ¿recuerdas las interrupciones no tan frecuentes pero constantes para transmitir todo en fragmentos? En realidad no! El hecho es que el mecanismo DMA de PSoC se basa en descriptores. Habiendo ejecutado la tarea desde un descriptor, el controlador DMA pasa al siguiente. Y así, a lo largo de la cadena, puedes usar muchos descriptores. Ilustramos esto con algunos dibujos de la documentación oficial:

En realidad, este mecanismo también se puede utilizar construyendo una cadena de tres descriptores:
| No | Explicación |
|---|
| 1 | De memoria a FIFO con incremento de dirección. Indica una sección con un perfil de aceleración. |
| 2 | De memoria a FIFO sin incremento de dirección. Envía todo el tiempo a la misma palabra en la memoria para una velocidad constante. |
| 3 | De memoria a FIFO con incremento de dirección. Indica una sección con un perfil de frenado.
|
Resulta que la ruta principal se describe en el paso 2, y allí se usa físicamente la misma palabra, que establece la velocidad constante. El consumo de memoria no es grande. En realidad, el segundo descriptor puede estar físicamente representado por dos o tres descriptores. Esto se debe al hecho de que la longitud máxima de bombeo, según TRM, puede ser de 64 kilobytes (la enmienda será menor). Es decir, 32.767 palabras. Que a 200 pasos por milímetro corresponderá a una trayectoria de 163 milímetros. Puede que tenga que hacer un segmento de dos o tres partes, dependiendo de la distancia máxima que el motor puede recorrer a la vez.
Sin embargo, para ahorrar memoria (y el gasto de los bloques UDB), propongo abandonar los bloques DatapPath de 24 bits, cambiando a los más económicos de 16 bits.
Entonces La primera propuesta de revisión.
Las matrices se preparan en la memoria que codifica la duración de los pasos. Además, esta información va a UDB usando DMA. La sección rectilínea está codificada por una matriz de un elemento, el bloque DMA no aumenta la dirección, eligiendo el mismo elemento todo el tiempo. Las secciones de aceleración, rectilíneas y de frenado están conectadas por los medios disponibles en el controlador DMA.Ajuste fino de rango medio
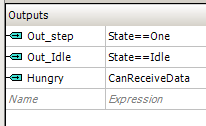
Ahora consideraremos cómo superar el problema de la granularidad de frecuencia. Por supuesto, no será posible configurarlo exactamente. Pero, de hecho, el "firmware" original tampoco puede hacer esto. En cambio, usan el algoritmo de Bresenham. Se agrega un retraso de una medida a algunos pasos. Como resultado, la frecuencia promedio se vuelve intermedia, entre un valor más pequeño y uno más grande. Al ajustar la proporción de períodos regulares y extendidos, puede cambiar suavemente la frecuencia promedio. Si nuestra velocidad ahora se establece no a través del registro de datos, sino que se transmite a través de FIFO, y la cantidad de pulsos generalmente se establece a través de la cantidad de palabras transmitidas a través de DMA, ambos registros de datos en UDB se liberan. Además, también se libera una de las baterías, que cuenta el número de pulsos. Aquí construiremos un cierto PWM sobre ellos.
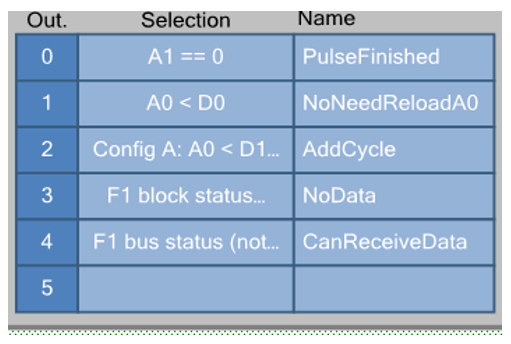
Por lo general, las ALU comparan y asignan registros con el mismo índice. Cuando un registro tiene un índice de 0 y el otro tiene un 1, no se pueden implementar todas las versiones de la operación. Pero logré armar el solitario de los registros bajo los cuales se puede hacer PWM. Resultó como se muestra en la figura.

Cuando se cumple la condición A0 <D1, agregaremos un latido adicional a la longitud de pulso dada. Cuando la condición no se cumple, no lo haremos.
Caballo esférico en condiciones normales.
Entonces, comenzamos a modificar el bloque desarrollado para UDB, teniendo en cuenta la nueva arquitectura. Reemplace la profundidad de bits de Datapath:
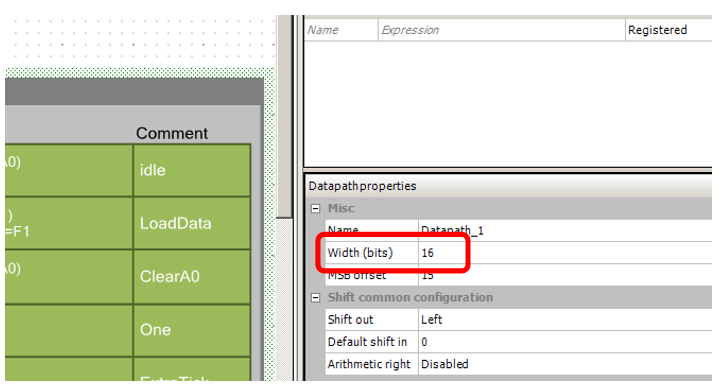
Necesitaremos muchas más salidas de Datapath que la última vez.
Al hacer doble clic en ellos, vemos los detalles:

Hay más dígitos para la variable
Estado , ¡no olvides conectar la más antigua! En la versión anterior, había un constante 0.
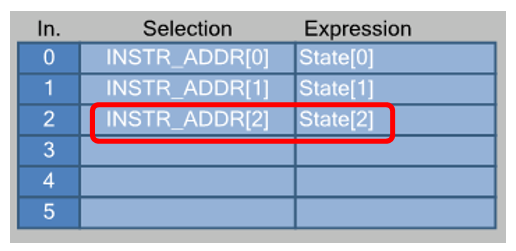
El gráfico de transición del autómata me sale así:

Estamos en estado
inactivo mientras FIFO1 está vacío. Por cierto, trabajar con FIFO1 y no FIFO0 es el resultado de la formación misma del solitario. El registro A0 se usa para implementar PWM, por lo que el ancho de pulso se determina mediante el registro A1. Y puedo descargarlo solo de FIFO1 (tal vez hay otros métodos secretos, pero no los conozco). Por lo tanto, DMA carga datos exactamente a FIFO1, y es precisamente el estado
"No vacío" para FIFO1 el que sale del estado
Inactivo .
ALU en estado
IDLE anula el registro A0:

Esto es necesario para que al comienzo de la operación PWM, siempre comience a funcionar desde el principio.
Pero los datos llegaron al FIFO. La máquina pasa al estado
LoadData :
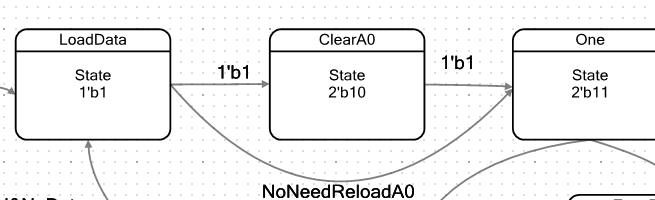
En este estado, la ALU carga la siguiente palabra del FIFO en el registro A1. En el camino, para no crear estados innecesarios, se incrementa el valor del contador A0, que se utiliza para trabajar con PWM:

Si el contador A0 aún no ha alcanzado el valor D0 (es decir, se activa la condición A0 <D0,
activando el indicador
NoNeedReloadA0 ), pasamos al estado
Uno . De lo contrario, el estado es
ClearA0 .
En el estado
ClearA0, la ALU simplemente pone a cero el valor de A0, comenzando un nuevo ciclo PWM:

después de lo cual la máquina también entra en
un estado, solo un latido más tarde.
Uno nos es familiar de la versión anterior de la máquina. ALU en él no realiza ninguna función.
Y así, en este estado, se genera una unidad a la salida de
Out_Step (aquí el optimizador funcionó mejor cuando la unidad es producida por la condición, esto se detectó empíricamente).
Estamos en este estado hasta que el contador de siete bits que ya conocemos se restablezca a cero. Pero si antes salíamos de este estado por un camino, ahora puede haber dos caminos: directo y retrasado al ritmo.
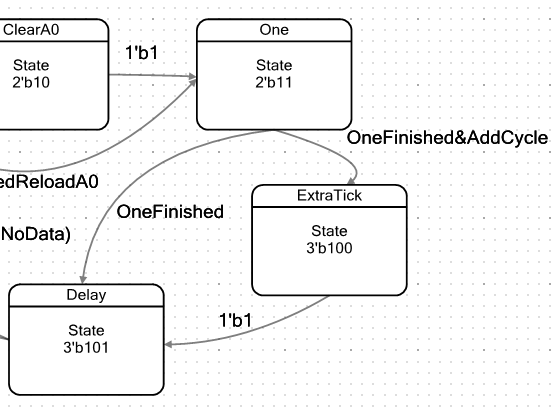
Entraremos en el estado ExtraTick si se establece el indicador
AddCycle , que se asigna para cumplir la condición A0 <D1. En este estado, la ALU no realiza ninguna acción beneficiosa. Es solo que el ciclo dura 1 latido más. Además, todas las rutas convergen en estado de
retraso .
Esta condición mide la duración del pulso. El registro A1 (cargado mientras aún está en el estado de
carga ) se reduce hasta llegar a cero.

Además, dependiendo de si hay datos adicionales en FIFO o no, la máquina cambiará a buscar la siguiente porción en el estado de
carga o en el estado
inactivo . Veamos esto no en la figura (hay flechas largas, todo será pequeño), sino en forma de tabla, haciendo doble clic en el estado
Retraso :
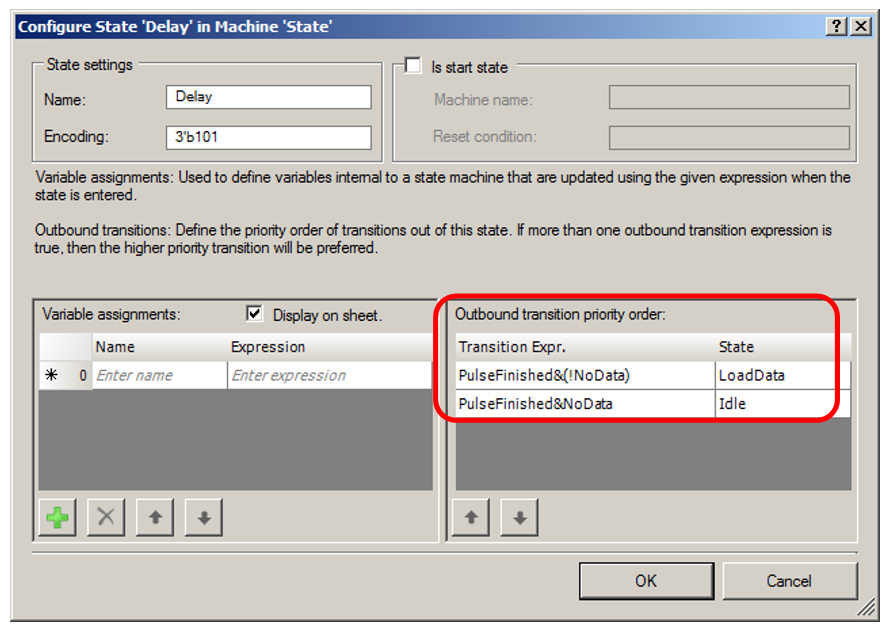
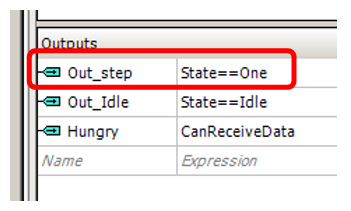
Ahora sale de UDB. Convertí el indicador de estar en estado
inactivo en una comparación asincrónica (en la versión anterior había un disparador que se activó y restableció en varios estados), ya que para ello el optimizador mostró el mejor resultado. Además, se agregó la bandera
Hungry , indicando a la unidad DMA que estaba lista para recibir datos. Está enrollado en la bandera
"FIFO1 no está lleno" . Como no está lleno, DMA puede cargar otra palabra de datos allí.
En la parte automática, eso es todo.
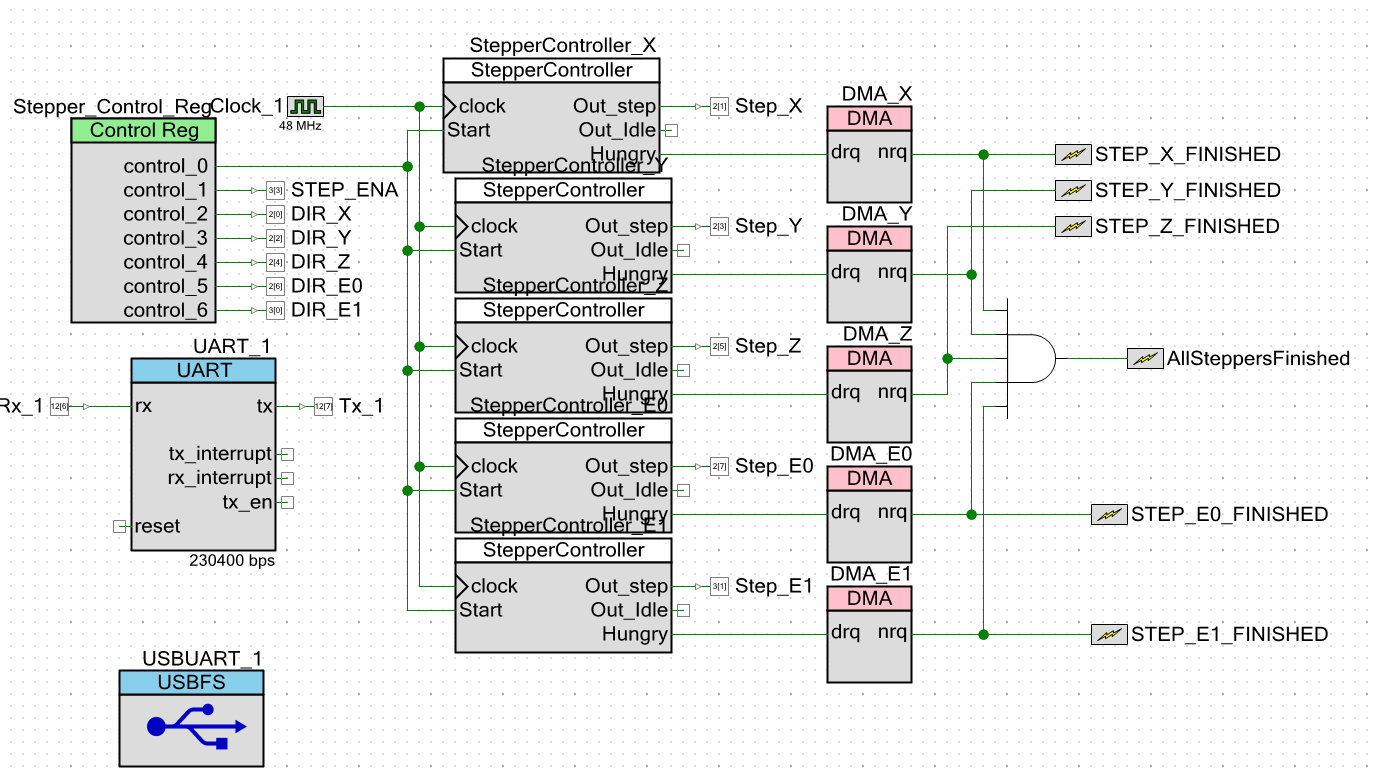
Agregue bloques DMA al diagrama principal del proyecto. Por el momento, comencé a interrumpir los indicadores de terminación de DMA, pero no el hecho de que esto sea correcto. Cuando se completa el proceso de acceso directo a la memoria, puede comenzar un nuevo proceso relacionado con el mismo segmento, pero no puede comenzar a completar la información sobre el nuevo segmento. FIFO todavía tiene tres o cuatro elementos. En este momento, todavía es imposible reprogramar los registros D0 y D1 del bloque basados en UDB, todavía son necesarios para la operación. Por lo tanto, es posible que las interrupciones basadas en las salidas
Out_Idle se agreguen
más tarde . Pero esa cocina ya no se relacionará con la programación de bloques UDB, por lo que solo la mencionaremos de pasada.
Experimentos de software
Como ahora no se sabe todo, no escribiremos ninguna función especial. Todos los controles se realizarán "En la frente". Luego, basándose en experimentos exitosos, se pueden escribir funciones API. Entonces Hacemos que la función
main () sea mínima. Simplemente configura el sistema e invoca la prueba seleccionada.
int main(void) { CyGlobalIntEnable;
Intentemos enviar un paquete de pulsos llamando a una función, verificando el hecho de insertar un pulso adicional. La llamada a la función es simple:
TestShortSteps();
Pero el cuerpo requiere explicación.
Daré toda la función primero void TestShortSteps() { // , // // , DMA !!! // , !!! StepperController_X_SingleVibrator_WritePeriod (6); // // — CY_SET_REG16(StepperController_X_Datapath_1_D0_PTR, 4); CY_SET_REG16(StepperController_X_Datapath_1_D1_PTR, 2); // . // static const uint16 steps[] = { 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001, 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001 }; // DMA , uint8 channel = DMA_X_DmaInitialize (sizeof(steps[0]),1,HI16(steps),HI16(StepperController_X_Datapath_1_F1_PTR)); CyDmaChRoundRobin (channel,true); // , uint8 td = CyDmaTdAllocate(); // . , . CyDmaTdSetConfiguration(td, sizeof(steps), CY_DMA_DISABLE_TD, TD_INC_SRC_ADR | TD_AUTO_EXEC_NEXT); // CyDmaTdSetAddress(td, LO16((uint32)steps), LO16((uint32)StepperController_X_Datapath_1_F1_PTR)); // CyDmaChSetInitialTd(channel, td); // CyDmaChEnable(channel, 1); }
Ahora considere sus partes importantes.
Si la longitud de la parte positiva del pulso es igual a 92 ciclos de reloj, entonces el osciloscopio no podrá discernir si hay una inserción de ciclo único en la parte negativa o no. La escala no será la misma. Es necesario hacer que la parte positiva sea lo más corta posible para que el pulso total sea comparable en escala con el latido insertado. Por lo tanto, cambio a la fuerza el período del contador que establece la duración de la parte positiva del pulso:
// , // // , DMA !!! // , !!! StepperController_X_SingleVibrator_WritePeriod (6);
¿Pero por qué seis medidas enteras? ¿Por qué no tres? ¿Por qué no dos? ¿Por qué, después de todo, no uno? Esta es una historia triste. Si el pulso positivo es más corto que 6 ciclos, entonces el sistema no funciona. La depuración prolongada en un osciloscopio con la salida de líneas de prueba al exterior mostró que DMA no es algo rápido. Si la máquina está funcionando por menos de una cierta duración, para el momento en que
abandona el estado de
Retardo , FIFO casi siempre está vacío. ¡Es posible que aún no se haya colocado una sola palabra de datos nueva! Y solo cuando la parte positiva del pulso tiene una duración de 6 ciclos, se garantiza que FIFO tendrá tiempo para cargar ...
Digresión de latencia
Otra idea de solución que se encuentra en mi cabeza es la aceleración de hardware de ciertas funciones del núcleo de nuestro RTOS MAX. Pero, por desgracia, todas mis mejores ideas están rotas sobre esas mismas latencias.
Hubo un caso, estudié el desarrollo de aplicaciones Bare Metal para Cyclone V SoC. Pero resultó que trabajar con registros FPGA únicos (cuando se les escribe alternativamente y luego se les lee) reduce la operación central cientos (!!!) veces. Escuchaste bien. Está en cientos. Además, todo esto está mal documentado, pero al principio lo percibí internamente y luego, a partir de fragmentos de la documentación, probé que las latencias eran culpables al pasar solicitudes a través de un montón de puentes. Si necesita expulsar una gran matriz, también habrá latencia, pero en términos de una palabra bombeada, no será significativa. Cuando las solicitudes son únicas (y la aceleración de hardware del núcleo del sistema operativo solo las implica), la desaceleración se produce exactamente cientos de veces. Será mucho más rápido hacer todo de una manera puramente de software, cuando el programa trabaje con la memoria principal a través de la caché a una velocidad frenética.
En PSoC, también tenía ciertos planes. En apariencia, puedes buscar maravillosamente datos en una matriz usando DMA y UDB. ¡Qué hay realmente allí! ¡Debido a la estructura del descriptor DMA, estos controladores podrían realizar una búsqueda completamente de hardware en las listas vinculadas! Pero después de recibir el enchufe descrito anteriormente, me di cuenta de que también está asociado con la latencia. Aquí, esta latencia se describe maravillosamente en la documentación. Tanto en la familia TRM como en un documento separado
AN84810 - Temas de PSoC 3 y PSoC 5LP Advanced DMA . Allí la sección 3.2 está dedicada a esto. Entonces se cancela la próxima aceleración de hardware. Una pena Pero, como dijo Semyon Semyonovich Gorbunkov: "Vamos a buscar".
Experimentos continuos de software
A continuación, configuro los parámetros del algoritmo de Bresenham:
// // — CY_SET_REG16(StepperController_X_Datapath_1_D0_PTR, 4); CY_SET_REG16(StepperController_X_Datapath_1_D1_PTR, 2);
Bueno, luego viene el código regular que transfiere una serie de palabras a través de DMA a FIFO1 de la unidad de control del motor X.
El resultado requiere alguna explicación. Aquí esta:

El valor del contador A0 se muestra en rojo cuando la máquina está en el estado
Uno . El asterisco verde muestra los casos en que se inserta el retraso debido a que la máquina está en estado
ExtraTick . También hay barras donde el retraso se debe a estar en el estado
ClearA0 , están marcadas con una cuadrícula azul.
Como puede ver, cuando ingresa por primera vez se pierde el primer retraso. Esto se debe al hecho de que A0 se restablece cuando está en
inactivo , pero aumenta cuando ingresa
LoadData . Por lo tanto, hasta el punto de análisis (salida del estado de
Uno ), ya es igual a la unidad. La cuenta comienza con ella. Pero en general, esto no afectará la frecuencia media. Solo hay que tenerlo en cuenta. Como debe tenerse en cuenta que al restablecer A0, el reloj también se insertará. Debe tenerse en cuenta al calcular la frecuencia promedio.
Pero en general, el número de pulsos es correcto. Su duración también es creíble.
Intentemos programar una cadena de descriptores más real,
consistente en una fase de aceleración, movimiento lineal y frenado. void TestWithPacking(int countOnLinearStage) { // , // . // , DMA !!! // , !!! StepperController_X_SingleVibrator_WritePeriod (6); // // — CY_SET_REG16(StepperController_X_Datapath_1_D0_PTR, 4); CY_SET_REG16(StepperController_X_Datapath_1_D1_PTR, 2); // static const uint16 accelerate[] = {0x0010,0x0008,0x0004}; // static const uint16 deccelerate[] = {0x004,0x0008,0x0010}; // . . static const uint16 steps[] = {0x0001}; // DMA , uint8 channel = DMA_X_DmaInitialize (sizeof(steps[0]),1,HI16(steps),HI16(StepperController_X_Datapath_1_F1_PTR)); CyDmaChRoundRobin (channel,true); // uint8 tdDeccelerate = CyDmaTdAllocate(); CyDmaTdSetConfiguration(tdDeccelerate, sizeof(deccelerate), CY_DMA_DISABLE_TD, TD_INC_SRC_ADR | TD_AUTO_EXEC_NEXT); CyDmaTdSetAddress(tdDeccelerate, LO16((uint32)deccelerate), LO16((uint32)StepperController_X_Datapath_1_F1_PTR)); // uint8 tdSteps = CyDmaTdAllocate(); // !!! // !!! CyDmaTdSetConfiguration(tdSteps, countOnLinearStage, tdDeccelerate, /*TD_INC_SRC_ADR |*/ TD_AUTO_EXEC_NEXT); CyDmaTdSetAddress(tdSteps, LO16((uint32)steps), LO16((uint32)StepperController_X_Datapath_1_F1_PTR)); // // !!! uint8 tdAccelerate = CyDmaTdAllocate(); CyDmaTdSetConfiguration(tdAccelerate, sizeof(accelerate), tdSteps, TD_INC_SRC_ADR | TD_AUTO_EXEC_NEXT); CyDmaTdSetAddress(tdAccelerate, LO16((uint32)accelerate), LO16((uint32)StepperController_X_Datapath_1_F1_PTR)); // CyDmaChSetInitialTd(channel, tdAccelerate); // CyDmaChEnable(channel, 1); }
Primero, llame para los mismos diez pasos (en DMA, 20 bytes realmente van):
TestWithPacking (20);
El resultado es el esperado. Al principio, la aceleración es visible. Y la salida a
IDLE (rayo azul) ocurre con un gran retraso desde el último pulso, fue entonces cuando el último paso se completó por completo, su valor es aproximadamente igual al valor del primero.
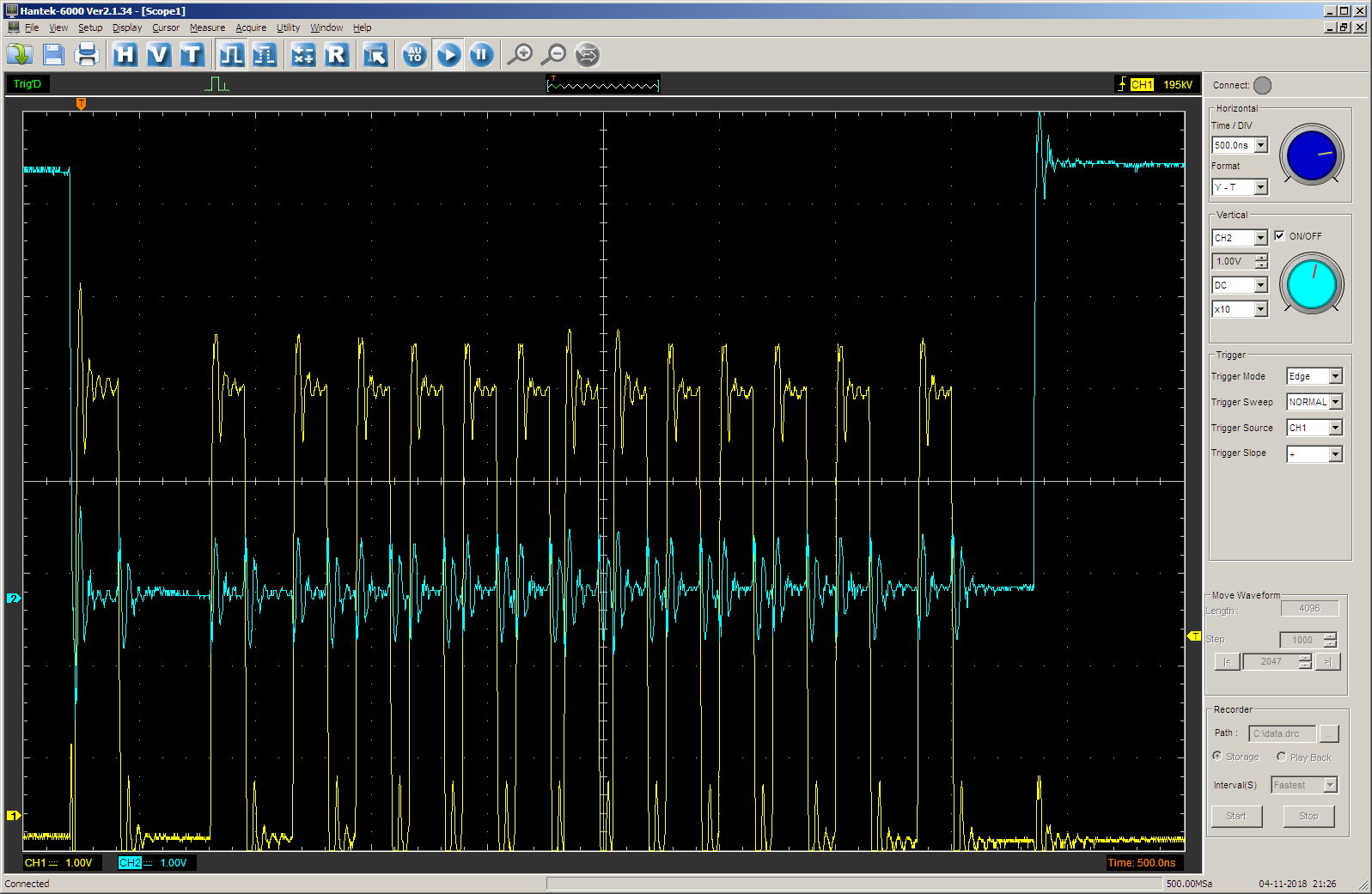
Caballo real en condiciones normales
Al remodelar el equipo, de alguna manera salte de un ancho de pulso de 24 bits a un trabajo de 16 bits. Pero descubrimos que esto no se puede hacer: la frecuencia de pulso mínima será demasiado alta. Lo hice intencionalmente. El hecho es que la técnica para expandir la capacidad de bits de un contador de 16 bits resultó ser tan complicada que si hubiera comenzado a describirla junto con la máquina principal, habría desviado toda la atención. Por lo tanto, lo consideramos por separado.
Tenemos una batería de 16 bits. Decidí agregar la entidad estándar de contador de siete bits a los bits altos. ¿Qué es este contador de siete bits? Este es el diseño que está disponible en cada bloque UDB (el bloque UDB base tiene un ancho de bits de todos los registros de 8 bits, el aumento en la profundidad de bits está determinado por la combinación de bloques en grupos). De los mismos recursos, se pueden implementar registros de
Control / Estado . Ahora tenemos un contador y no un solo par
Control / Estado para 16 bits de datos. Entonces, al agregar otro contador al sistema, no demoraremos los recursos adicionales. Solo tomamos lo que ya nos ha sido asignado. Eso es lindo! Realizamos el byte alto del contador de ancho de pulso a través de este mecanismo y obtenemos el ancho total del contador de ancho de pulso igual a 23 bits.
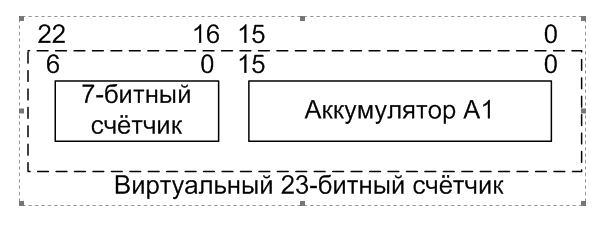
Primero diré lo que estaba pensando. Pensé que después de salir del estado de
Retraso , comprobaría la finalización del recuento de este contador adicional. Si no ha terminado de contar, reduciré su valor y volveré al estado de
Retraso . Si contó, la lógica seguirá siendo la misma, sin agregar ciclos adicionales.
Además, la documentación para este contador dice que tengo razón. Literalmente dice:
Periodo
Define el valor de registro del período inicial. Para un período de N relojes, el valor del período debe establecerse en el valor de N-1. El contador contará desde N-1 hasta 0, lo que resulta en un período de ciclo de reloj N. Un valor de registro de período de 0 no es compatible y dará como resultado que la salida de recuento de terminales se mantenga en un estado alto constante.
La vida ha demostrado que todo es diferente. Deducí el estado de la línea de
conteo de terminales en el osciloscopio y observé su valor en un cero precargado en
Periodo y durante la carga del programa. Ay y ah. ¡No hubo
un estado alto constante !
Por prueba y error, logré que el sistema funcionara correctamente, pero para que esto suceda, ¡debe suceder al menos una resta del contador! El nuevo estado de
"resta" no
está del lado. Tenía que ser encajado en el camino requerido. Se encuentra frente al estado de
retraso y se llama
Next65536 .
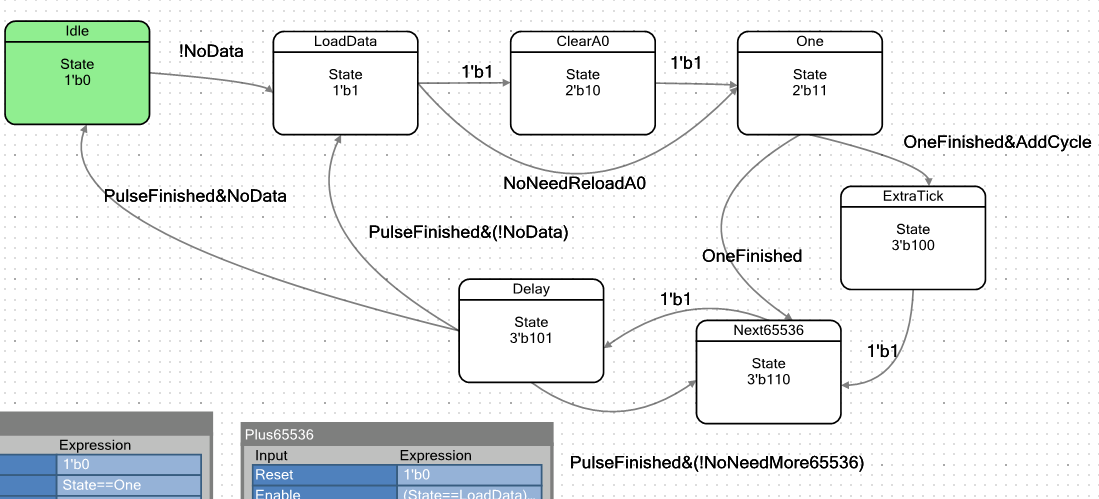
ALU en este estado no realiza ninguna acción útil. En realidad, solo un nuevo contador reacciona al hecho de estar en este estado. Aquí está en el diagrama:

Aquí están sus propiedades con más detalle:
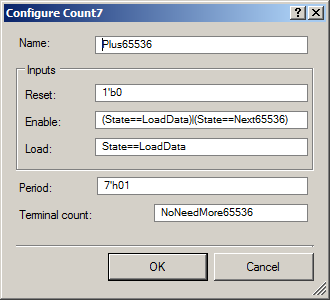
En general, teniendo en cuenta los artículos anteriores, la esencia de este contador es clara. Solo la línea
Enable está sufriendo. Nuevamente, no entiendo completamente por qué debería estar encendido cuando la máquina está en el estado
LoadData (luego el contador vuelve a cargar el valor del período). Tomé prestado este truco de las propiedades del contador que controla los LED, tomado del autor inglés de la unidad de control para esos LED. Sin él, el valor cero del período no funciona. Ella trabaja con ella
En el código API, agregamos la inicialización de un nuevo contador. Ahora la función de inicio se ve así:
void `$INSTANCE_NAME`_Start() { `$INSTANCE_NAME`_SingleVibrator_Start(); //"One" Generator start `$INSTANCE_NAME`_Plus65536_Start(); }
Veamos el nuevo sistema. Aquí está el código de función para probar
(solo la primera línea difiere de la ya conocida): void JustTest(int extra65536s) { // 65536 StepperController_X_Plus65536_WritePeriod((uint8) extra65536s); // // — CY_SET_REG16(StepperController_X_Datapath_1_D0_PTR, 4); CY_SET_REG16(StepperController_X_Datapath_1_D1_PTR, 2); // . // static const uint16 steps[] = { 0x1000,0x1000,0x1000,0x1000 }; // DMA , uint8 channel = DMA_X_DmaInitialize (sizeof(steps[0]),1,HI16(steps),HI16(StepperController_X_Datapath_1_F1_PTR)); CyDmaChRoundRobin (channel,true); // , uint8 td = CyDmaTdAllocate(); // . , . CyDmaTdSetConfiguration(td, sizeof(steps), CY_DMA_DISABLE_TD, TD_INC_SRC_ADR | TD_AUTO_EXEC_NEXT); // CyDmaTdSetAddress(td, LO16((uint32)steps), LO16((uint32)StepperController_X_Datapath_1_F1_PTR)); // CyDmaChSetInitialTd(channel, td); // CyDmaChEnable(channel, 1); }
Lo llamamos así:
JustTest(0);
En el osciloscopio vemos lo siguiente (haz amarillo - salida STEP, azul - valor de la salida TC del contador para el control del proceso). La duración del pulso se establece mediante la matriz de
pasos . En cada paso, la duración es de 0x1000 medidas.
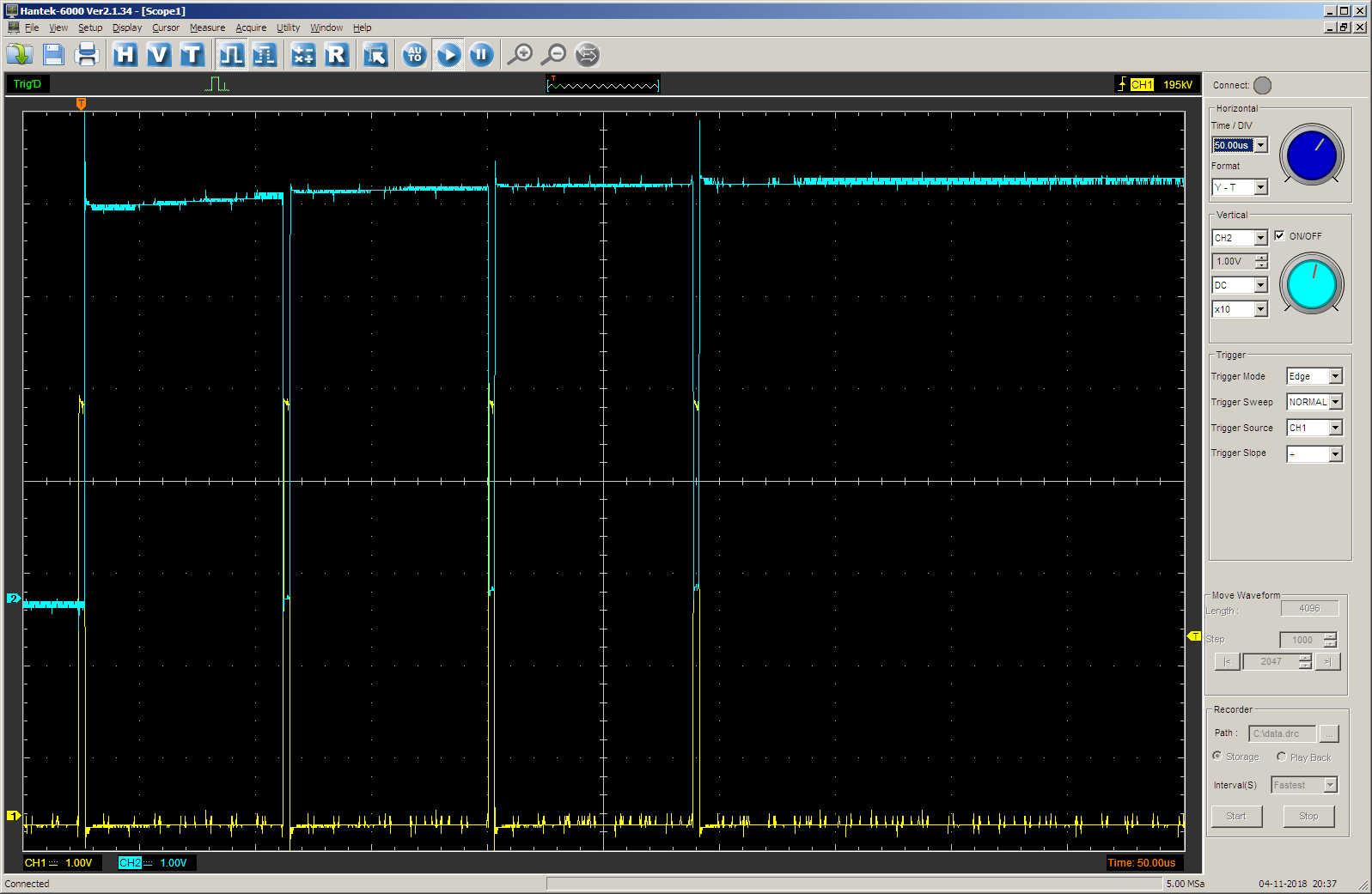
Cambie a otro escaneo para que haya compatibilidad entre diferentes resultados:
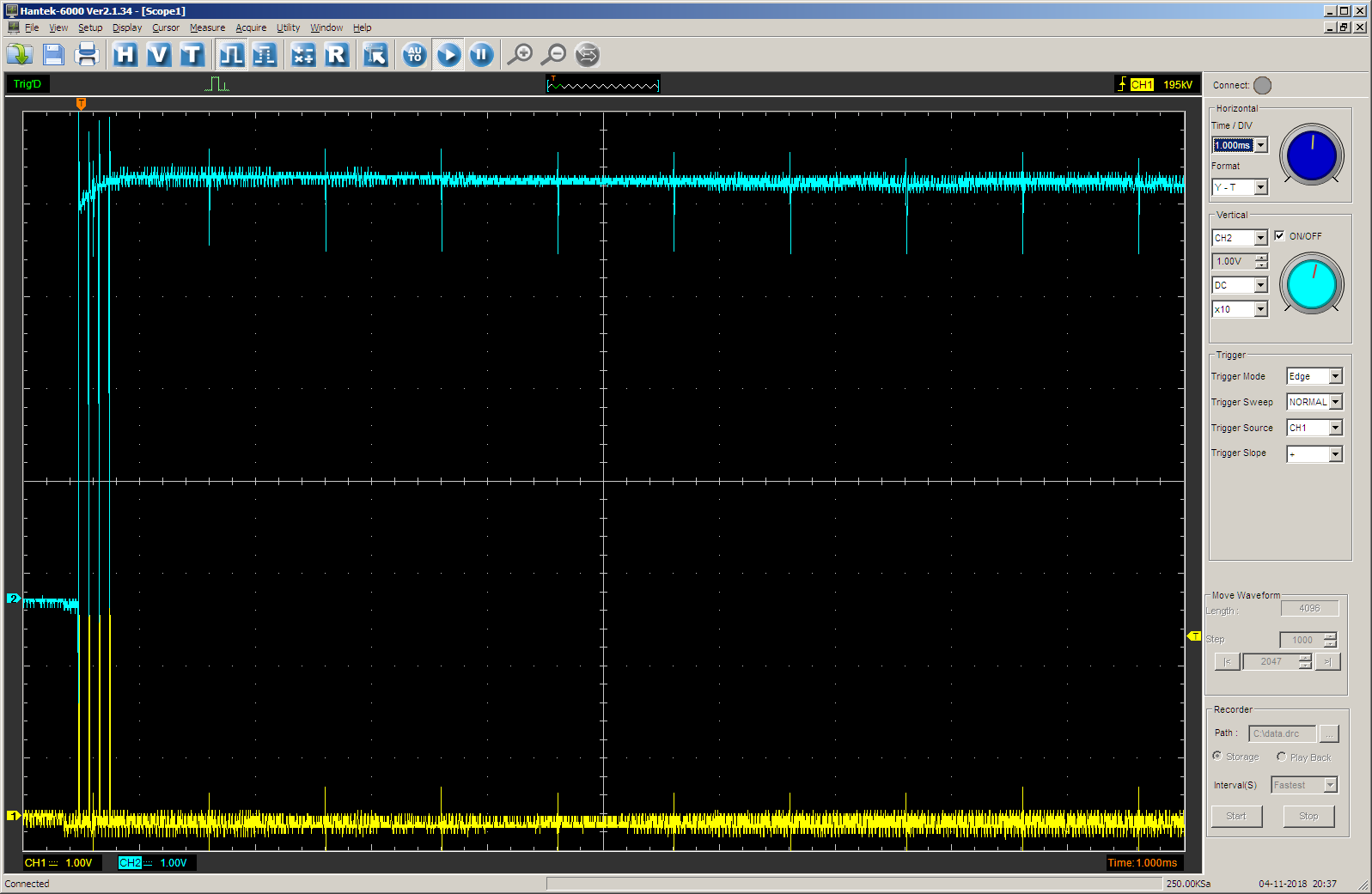
Cambie la llamada de función a esto:
JustTest(1);
El resultado es el esperado. Primero, la salida TC es cero para 0x1000 ciclos, luego, una unidad para 0x10000 (65536d) ciclos. La frecuencia es aproximadamente igual a 700 hertz, descubrimos en la última parte del artículo, por lo que todo está bien.

Bueno, probemos un deuce:
JustTest(2);
Obtenemos:
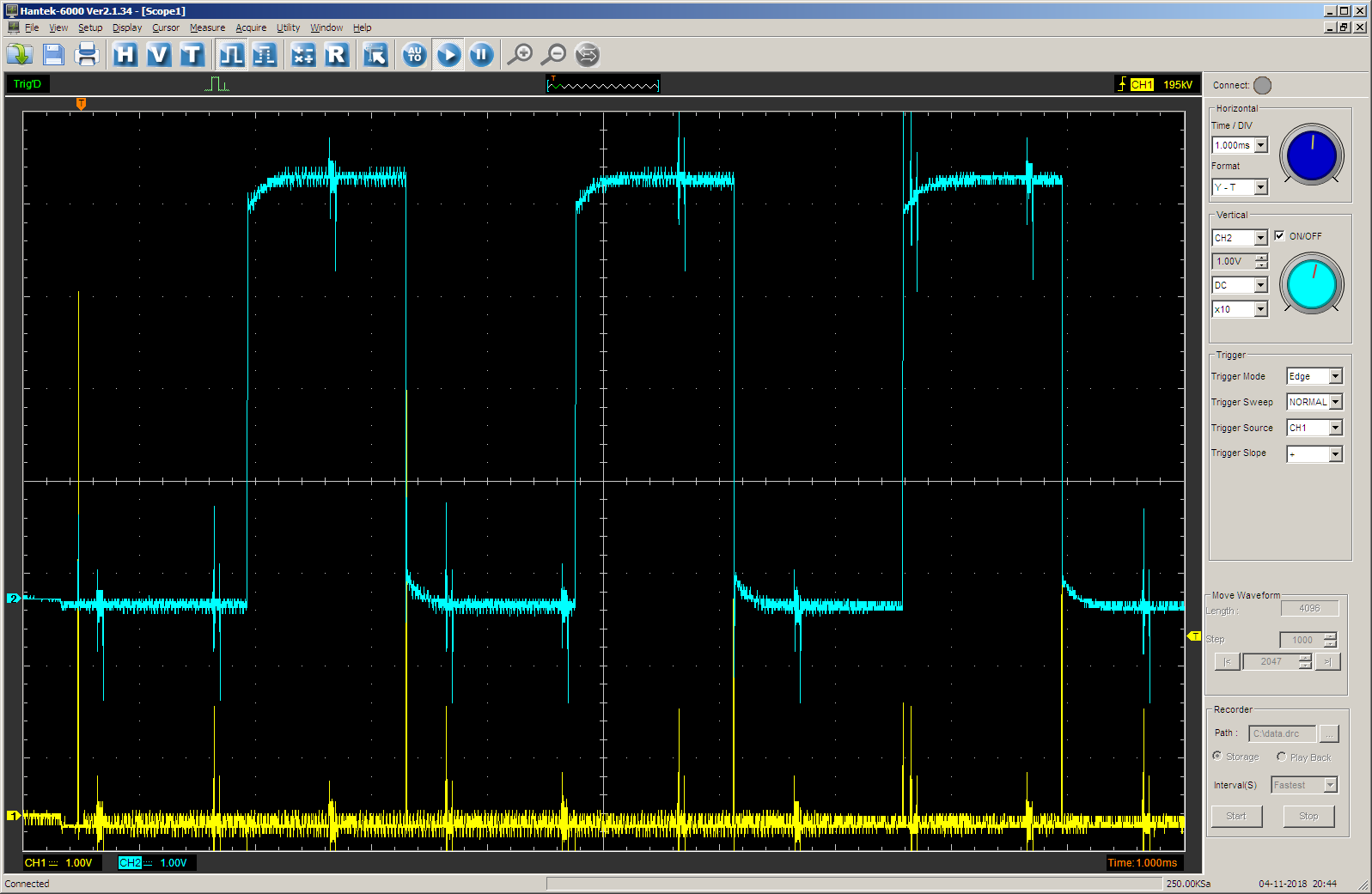
Eso es correcto La salida TC se invierte a uno en los últimos 65536 ciclos de reloj. Antes de eso, estaba en cero durante 0x1000 + 0x10000 ciclos.
Por supuesto, con este enfoque, todos los pulsos deben ir con el mismo valor del nuevo contador. Es imposible hacer un pulso con el byte más alto durante la aceleración, digamos 3, luego 1, luego 0. Pero, de hecho, a frecuencias tan bajas (menos de setecientos hertzios) las aceleraciones no tienen un significado físico, por lo tanto, este problema puede descuidarse. A esta frecuencia, puede trabajar con el motor linealmente.
Volar en la pomada
El documento TRM para la familia PSoC5LP dice:
Cada transacción puede ser de 1 a 64 KB
Pero en el ya mencionado AN84810 hay una frase así:
1. ¿Cómo puede almacenar más de 4095 bytes usando DMA?
El conteo máximo de transferencia de un TD está limitado a 4095 bytes. Si necesita transferir más de 4095 bytes usando un solo canal DMA, use múltiples TDs y encadénelos como se muestra en el Ejemplo 5.
¿Quién tiene la razón? Si realiza experimentos, los resultados se inclinarán a favor de la peor de las declaraciones, pero el comportamiento será completamente incomprensible. Todo el error es esta verificación en la API:
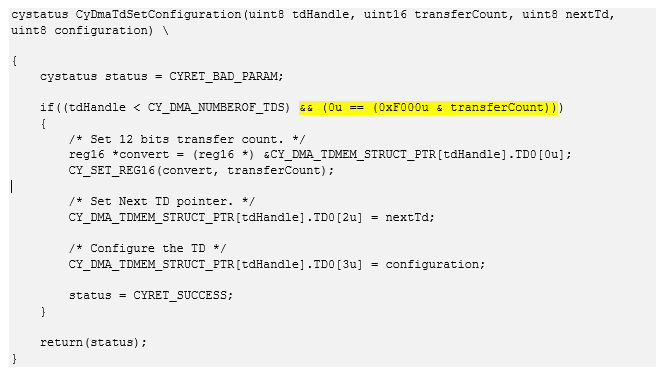
Mismo texto cystatus CyDmaTdSetConfiguration(uint8 tdHandle, uint16 transferCount, uint8 nextTd, uint8 configuration) \ { cystatus status = CYRET_BAD_PARAM; if((tdHandle < CY_DMA_NUMBEROF_TDS) && (0u == (0xF000u & transferCount))) { /* Set 12 bits transfer count. */ reg16 *convert = (reg16 *) &CY_DMA_TDMEM_STRUCT_PTR[tdHandle].TD0[0u]; CY_SET_REG16(convert, transferCount); /* Set Next TD pointer. */ CY_DMA_TDMEM_STRUCT_PTR[tdHandle].TD0[2u] = nextTd; /* Configure the TD */ CY_DMA_TDMEM_STRUCT_PTR[tdHandle].TD0[3u] = configuration; status = CYRET_SUCCESS; } return(status); }
Si se especifica una transacción de más de 4095 bytes, se usará la configuración anterior. Sí, no pensé en comprobar los códigos de error ...
Los experimentos mostraron que si elimina esta comprobación, la longitud real se cortará utilizando la máscara 0xfff (4096 = 0x1000). Ay y ah. Todas las esperanzas de un trabajo agradable se derrumbaron. Por supuesto, puede crear cadenas de descriptores relacionados en 4K. Pero, digamos, 64K son 16 cadenas. Tres motores activos (las extrusoras tendrán menos pasos): 48 cadenas. Exactamente tanto debe llenarse en el peor de los casos, antes de cada segmento. Quizás sea aceptable a tiempo. Como mínimo, hay 127 descriptores disponibles, por lo que definitivamente habrá suficiente memoria.
Puede enviar los datos faltantes según sea necesario. Se produjo una interrupción debido a que el canal DMA había completado el trabajo, estamos transfiriéndole otro segmento. En este caso, no se requieren cálculos, el segmento ya está formado, todo será rápido. Y no hay requisitos de rendimiento: cuando se emite una solicitud de interrupción, habrá 4 elementos más en FIFO que serán atendidos cada uno durante varios cientos o incluso miles de ciclos de reloj. Es decir, todo es real. Una estrategia específica será más fácil de elegir durante el trabajo real. Pero un error en la documentación (TRM) echó a perder todo el estado de ánimo. Si esto se supiera de antemano, tal vez no habría verificado la metodología.
Conclusión
En apariencia, la herramienta de firmware auxiliar desarrollada se volvió aceptable, por lo que, sobre la base, sería posible hacer una versión del "Firmware", por ejemplo, Marlin, que no está constantemente en el controlador de interrupciones para motores paso a paso. Hasta donde sé, esto es especialmente cierto para las impresoras Delta, donde la demanda de recursos informáticos es bastante alta. Quizás esto eliminará la afluencia que ocurre en mi Delta en lugares donde se detiene la cabeza. En el MZ3D en estos mismos lugares no se observa afluencia. Si es cierto o no, el tiempo lo dirá, y el informe sobre esto deberá publicarse en una rama completamente diferente.
Mientras tanto, hemos visto que en el bloque UDB, a pesar de su simplicidad, es bastante posible implementar un coprocesador que funcione en conjunto con el procesador principal y que permita que se descargue. Y cuando hay muchas de estas unidades, los coprocesadores pueden trabajar en paralelo.
Un error en la documentación del controlador DMA borró el resultado. No obstante, se requieren interrupciones, pero no con la misma frecuencia y con la criticidad en el tiempo que estaba en la versión original. Por lo tanto, el estado de ánimo se echa a perder, pero el uso de un "coprocesador" basado en UDB todavía ofrece una ganancia considerable en comparación con el trabajo puramente de software.
En el camino, se reveló que DMA funciona a una velocidad bastante baja. Como resultado de esto, se realizaron algunas mediciones tanto en el PSoC5LP como en el STM32. Los resultados sacan otro artículo. Quizás algún día lo haga si el tema resulta interesante.
Como resultado de los experimentos, se obtuvieron dos proyectos de prueba a la vez. El primero es más fácil de entender. Puedes llevarlo
aquí . El segundo se hereda del primero, pero se confunde al agregar un contador de siete bits y la lógica asociada. Puedes llevarlo
aquí . Por supuesto, estos ejemplos son solo de prueba. Todavía no hay tiempo libre para integrarse en el "firmware" real. Pero dentro del marco de estos artículos, es más importante practicar trabajar con UDB.