En OpenAI descubrimos que la escala de ruido de gradiente, un método estadístico simple, predice la paralelización del aprendizaje de una red neutral en una amplia gama de tareas. Dado que el gradiente generalmente se vuelve más ruidoso para tareas más complejas, un aumento en el tamaño de los paquetes disponibles para el procesamiento simultáneo resultará útil en el futuro y eliminará una de las limitaciones potenciales de los sistemas de IA. En el caso general, estos resultados muestran que el entrenamiento de redes neuronales no debe considerarse como un arte misterioso, y que se le puede dar precisión y sistematizar.
En los últimos años, los investigadores de IA han tenido un éxito creciente en acelerar el aprendizaje de redes neuronales al paralelizar datos, dividiendo grandes paquetes de datos en múltiples computadoras. Los investigadores han utilizado con éxito decenas de miles de unidades para la
clasificación de imágenes y el
modelado del lenguaje , e incluso para millones
de agentes de aprendizaje de refuerzo que jugaron Dota 2. Tales paquetes grandes pueden aumentar la cantidad de potencia informática que está efectivamente involucrada en la enseñanza de un modelo, y son uno de las fuerzas que impulsan el
crecimiento en el entrenamiento de IA. Sin embargo, con los paquetes de datos que son demasiado grandes, hay una disminución rápida en los retornos algorítmicos, y no está claro por qué estas restricciones resultan ser más grandes para algunas tareas y más pequeñas para otras.
 La escala de ruido de gradiente, promediada sobre los enfoques de entrenamiento, representa la mayoría (r 2 = 80%) de las variaciones de tamaño del paquete de datos críticos para varios problemas, que difieren en seis órdenes de magnitud. Los tamaños de los paquetes se miden en el número de imágenes, fichas (para modelos de lenguaje) u observaciones (para juegos).
La escala de ruido de gradiente, promediada sobre los enfoques de entrenamiento, representa la mayoría (r 2 = 80%) de las variaciones de tamaño del paquete de datos críticos para varios problemas, que difieren en seis órdenes de magnitud. Los tamaños de los paquetes se miden en el número de imágenes, fichas (para modelos de lenguaje) u observaciones (para juegos).Descubrimos que al medir la escala de ruido de gradiente, estadísticas simples que determinan numéricamente la relación señal / ruido en los gradientes de la red, podemos predecir aproximadamente el tamaño máximo del paquete. Heurísticamente, la escala de ruido mide la variación de datos desde el punto de vista del modelo (en una etapa particular de entrenamiento). Cuando la escala de ruido es pequeña, el aprendizaje paralelo en una gran cantidad de datos se vuelve redundante rápidamente, y cuando es grande, podemos aprender mucho en grandes conjuntos de datos.
Las estadísticas de este tipo se usan ampliamente para
determinar el tamaño de la muestra , y se
sugirió su uso en
el aprendizaje profundo , pero no se usó sistemáticamente para el entrenamiento moderno de las redes neuronales. Hemos confirmado esta predicción para una amplia gama de tareas de aprendizaje automático descritas en el gráfico anterior, incluido el reconocimiento de patrones, el modelado de idiomas, los juegos de Atari y Dota. En particular, capacitamos redes neuronales diseñadas para resolver cada uno de estos problemas en paquetes de datos de varios tamaños (ajustando por separado la velocidad de aprendizaje para cada uno de ellos), y comparamos la aceleración de aprendizaje con la predicha por la escala de ruido. Dado que los paquetes de datos grandes a menudo requieren un ajuste cuidadoso y costoso o un horario especial de velocidad de aprendizaje para que el entrenamiento sea efectivo, conociendo el límite superior de antemano, puede obtener una ventaja significativa al entrenar nuevos modelos.
Encontramos útil visualizar los resultados de estos experimentos como un compromiso entre el tiempo de entrenamiento real y la cantidad total de cómputo requerida para el entrenamiento (proporcional a su costo en dinero). En paquetes de datos muy pequeños, duplicar el tamaño del paquete permite que la capacitación se lleve a cabo el doble de rápido sin el uso de potencia informática adicional (ejecutamos el doble de hilos individuales que funcionan el doble de rápido). En maquetas de datos muy grandes, la paralelización no acelera el aprendizaje. La curva en el centro se dobla y la escala de gradiente de ruido predice dónde se produce exactamente el doblez.
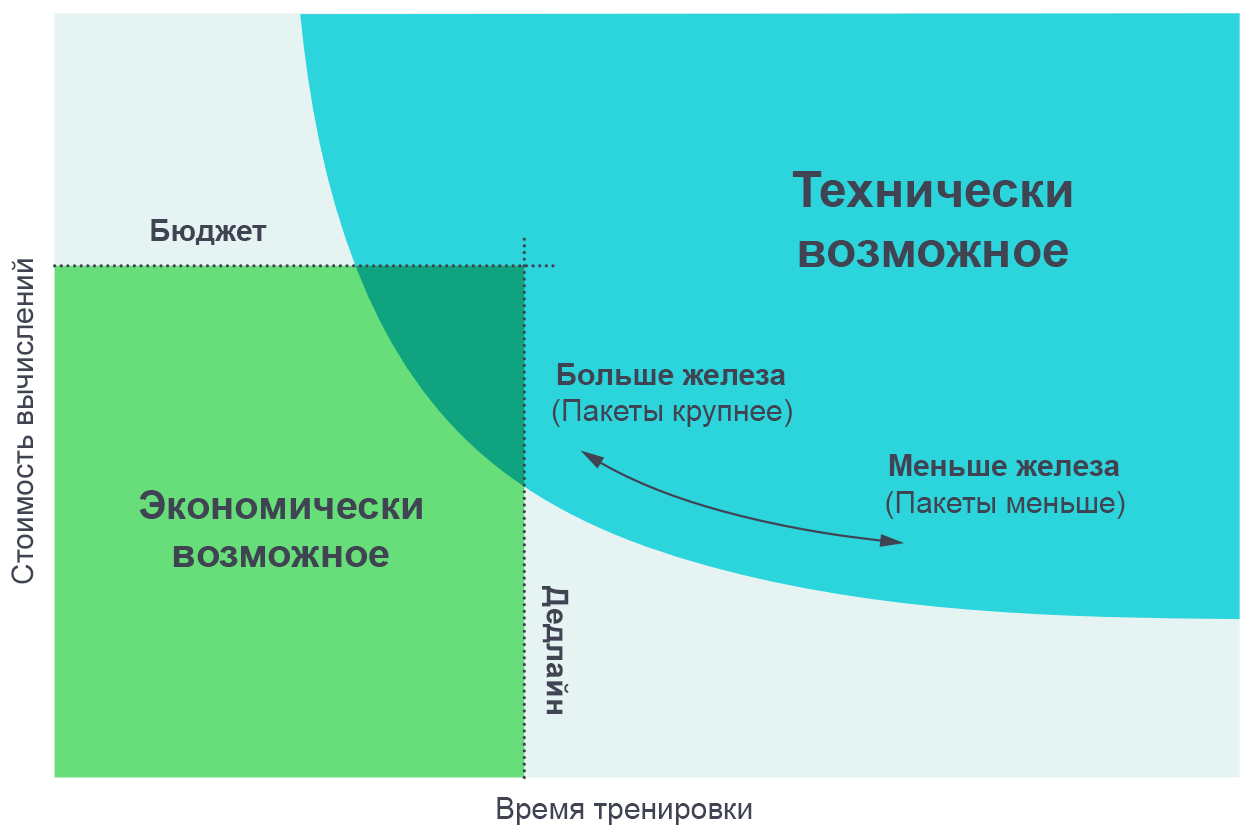 Aumentar el número de procesos paralelos le permite entrenar modelos más complejos en un tiempo razonable. El diagrama de borde de Pareto es la forma más intuitiva de visualizar comparaciones de algoritmos y escalas.
Aumentar el número de procesos paralelos le permite entrenar modelos más complejos en un tiempo razonable. El diagrama de borde de Pareto es la forma más intuitiva de visualizar comparaciones de algoritmos y escalas.Obtenemos estas curvas asignando un objetivo a una tarea (por ejemplo, 1000 puntos en el juego Beam Rider de Atari) y observando cuánto tiempo lleva entrenar una red neuronal para lograr este objetivo en diferentes tamaños de paquetes. Los resultados coinciden con bastante precisión con las predicciones de nuestro modelo, teniendo en cuenta los diversos valores de los objetivos que establecemos.
[
La página con el artículo original presenta gráficos interactivos de un compromiso entre la experiencia y el tiempo de capacitación necesarios para lograr un objetivo determinado ]
Patrones de escala de ruido gradiente
Encontramos varios patrones en la escala de gradiente de ruido, sobre la base de los cuales podemos hacer suposiciones sobre el futuro del entrenamiento de IA.
Primero, en nuestros experimentos en el proceso de aprendizaje, la escala de ruido generalmente aumenta en un orden de magnitud o más. Aparentemente, esto significa que la red aprende características más "obvias" del problema al comienzo de la capacitación, y luego estudia los detalles más pequeños. Por ejemplo, en la tarea de clasificar imágenes, una red neuronal puede primero aprender a identificar características de pequeña escala, como los bordes o las texturas que se muestran en la mayoría de las imágenes, y solo más tarde comparar estas pequeñas cosas juntas, creando conceptos más generales, como gatos o perros. Para tener una idea de toda la variedad de caras y texturas, las redes neuronales necesitan ver una pequeña cantidad de imágenes, por lo que la escala de ruido es menor; Tan pronto como la red sepa más sobre los objetos más grandes, podrá procesar muchas más imágenes al mismo tiempo sin tener en cuenta los datos duplicados.
Vimos algunas
indicaciones preliminares de que un efecto similar también funciona en otros modelos que tratan con el mismo conjunto de datos: para modelos más potentes, la escala de ruido de gradiente es más alta, pero solo porque tienen menos pérdidas. Por lo tanto, existe cierta evidencia de que aumentar la escala de ruido durante el entrenamiento no es solo un artefacto de convergencia, sino que se debe a una mejora en el modelo. Si es así, entonces podemos esperar que los modelos futuros mejorados tengan una gran escala de ruido y se adapten mejor a la paralelización.
En segundo lugar, las tareas que son objetivamente más complejas son más susceptibles de paralelización. En el contexto de la enseñanza con un maestro, se observa un progreso obvio en la transición de MNIST a SVHN e ImageNet. En el contexto del entrenamiento de refuerzo, se observa un claro progreso en la transición de Atari Pong a
Dota 1v1 y
Dota 5v5 , y el tamaño del paquete de datos óptimo varía en 10,000 veces. Por lo tanto, a medida que la IA hace frente a tareas cada vez más complejas, se espera que los modelos hagan frente a conjuntos de datos cada vez más grandes.
Las consecuencias
El grado de paralelización de datos afecta seriamente la velocidad de desarrollo de las capacidades de IA. Acelerar el aprendizaje hace posible crear modelos más capaces y acelera la investigación, lo que le permite acortar el tiempo de cada iteración.
En un estudio anterior, "
IA y cálculos ", vimos que los cálculos para entrenar a los modelos más grandes se duplican cada 3.5 meses, y observamos que esta tendencia se basa en una combinación de economía (el deseo de gastar dinero en cálculos) y capacidades algorítmicas para paralelizar el aprendizaje. . El último factor (paralelización algorítmica) es más difícil de predecir, y sus limitaciones aún no se han estudiado por completo, pero nuestros resultados actuales representan un paso adelante en su sistematización y expresión numérica. En particular, tenemos evidencia de que las tareas más complejas, o los modelos más potentes destinados a una tarea conocida, permitirán un trabajo más paralelo con los datos. Este será un factor clave que respaldará el crecimiento exponencial de la informática relacionada con el aprendizaje. Y ni siquiera consideramos
los desarrollos recientes en el campo de los modelos paralelos, lo que nos puede permitir mejorar aún más la paralelización al agregarla al procesamiento de datos paralelos existente.
El crecimiento continuo del campo de la informática de entrenamiento y su base algorítmica predecible hablan de la posibilidad de un aumento explosivo en las capacidades de IA en los próximos años, y enfatizan la necesidad de un
estudio temprano
del uso seguro y
responsable de tales sistemas. La principal dificultad para crear una política de IA será decidir cómo se pueden usar tales medidas para predecir las características de los futuros sistemas de IA, y usar este conocimiento para crear reglas que permitan a la sociedad maximizar su utilidad y minimizar el daño de estas tecnologías.
OpenAI planea realizar un análisis riguroso para predecir el futuro de la IA y abordar de manera proactiva los desafíos planteados por este análisis.