
Entonces, es hora de hablar sobre la próxima generación de procesadores multicelulares: MultiClet S1. Si es la primera vez que escuchas sobre ellos, asegúrate de revisar la historia y la ideología de la arquitectura en estos artículos:
Por el momento, el nuevo procesador está en desarrollo, pero los primeros resultados ya han aparecido y puede evaluar de lo que será capaz.
Comencemos con los cambios más importantes: características básicas.
Caracteristicas
Está previsto alcanzar los siguientes indicadores:
- Número de celdas: 64
- Proceso técnico: 28 nm.
- Frecuencia de reloj: 1.6 GHz
- El tamaño de la memoria en el chip: 8 MB
- Área de cristal: 40 mm 2
- Consumo de energía: 6 W
Los números reales se anunciarán en función de los resultados de las pruebas de muestras fabricadas en 2019. Además de las características del chip en sí, el procesador admitirá hasta 16 GB de RAM estándar DDR4 3200MHz, bus PCI Express y PLL.
Cabe señalar que el proceso de fabricación de 28 nm es el rango doméstico más bajo que no requiere permisos especiales para su uso, por lo que fue él quien fue elegido. Según el número de celdas, se consideraron diferentes opciones: 128 y 256, pero con un aumento en el área del cristal, aumenta el porcentaje de rechazos. Nos instalamos en 64 células y, en consecuencia, en un área relativamente pequeña, que dará un mayor rendimiento de cristales adecuados en la placa. Es posible un mayor desarrollo en el marco del
ICS (sistema en el caso) , donde será posible combinar varios cristales de 64 células en un caso.
Hay que decir que el propósito y el uso del procesador están cambiando radicalmente. S1 no será un microprocesador diseñado para incrustar, como lo fueron P1 y R1, sino un acelerador de cálculos. Al igual que GPGPU, se puede insertar una placa basada en S1 en la placa base PCI Express de una PC normal y usarla para el procesamiento de datos.
Arquitectura
En S1, el "multicelda" es ahora la unidad computacional mínima: un conjunto de 4 celdas que ejecuta una cierta secuencia de comandos. Al principio, se planeó combinar multiceldas en grupos llamados clúster para la ejecución conjunta de comandos: un clúster tenía que contener 4 multiceldas, en total había 4 clústeres separados en el cristal. Sin embargo, cada célula tiene una conexión completa con todas las otras células en el grupo, y con un aumento en el grupo de enlaces se vuelve demasiado, lo que complica enormemente el diseño topológico del microcircuito y reduce sus características. Por lo tanto, decidieron abandonar la división de conglomerados, ya que la complicación no justifica los resultados. Además, para obtener el máximo rendimiento, es más beneficioso ejecutar código en paralelo en cada multicelda. Total, ahora el procesador contiene 16 multiceldas separadas.
Un multicelda, aunque consta de 4 celdas, difiere de un R1 de 4 celdas, en el que cada celda tiene su propia memoria, su propio bloque de comandos de muestra, su propia ALU. S1 está organizado de manera un poco diferente. ALU tiene 2 partes: un bloque aritmético de coma flotante y un bloque aritmético de enteros. Cada celda tiene un bloque de enteros separado, pero solo hay dos bloques con un punto flotante en una celda múltiple y, por lo tanto, dos pares de celdas los dividen entre sí. Esto se hizo principalmente para reducir el área del cristal: la aritmética de coma flotante de 64 bits, en contraste con la aritmética de enteros, ocupa mucho espacio. Tener dicha ALU en cada celda resultó ser redundante: los comandos de recuperación no proporcionan carga de ALU y están inactivos. Mientras se reduce la cantidad de bloques de ALU y se mantiene el ritmo de recuperación de comandos y datos, como lo ha demostrado la práctica, el tiempo total para resolver problemas prácticamente no cambia o cambia ligeramente, y los bloques de ALU se cargan completamente. Además, la aritmética de coma flotante no se usa con tanta frecuencia como con un entero.
En el siguiente diagrama se muestra una vista esquemática de los bloques de procesadores R1 y S1. Aquí:
- CU (Unidad de control) - unidad de búsqueda de instrucciones
- ALU FX - unidad lógica aritmética de aritmética de enteros
- ALU FP - Unidad lógica aritmética de aritmética de coma flotante
- DMS (Data Memory Scheduler) - unidad de control de memoria de datos
- DM - memoria de datos
- PMS (Program Memory Scheduler) - unidad de control de memoria de programa
- PM - memoria de programa
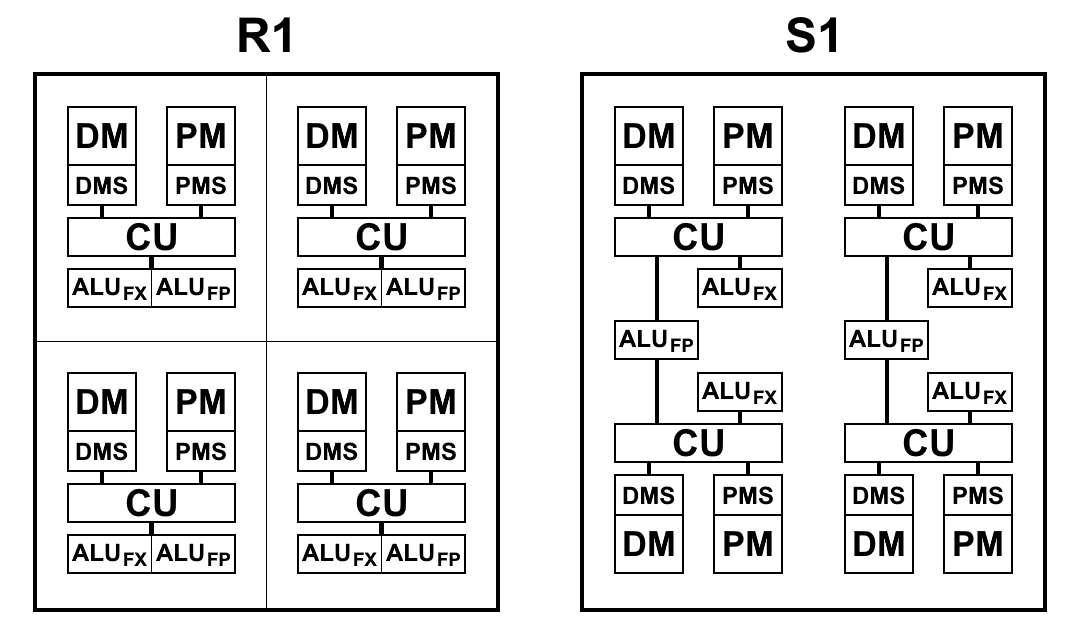
Diferencias arquitectónicas S1:
- Los equipos ahora pueden acceder a los resultados del equipo de los párrafos anteriores. Este es un cambio muy importante que le permite acelerar significativamente las transiciones al bifurcar el código. Los procesadores P1 y R1 no tuvieron más remedio que escribir los resultados deseados en la memoria e inmediatamente volver a leerlos con los primeros comandos en el nuevo párrafo. Incluso cuando se usa la memoria en un chip, las operaciones de escritura y lectura toman de 2 a 5 ciclos cada una, lo que se puede guardar simplemente refiriéndose al resultado del comando del párrafo anterior
- La escritura en la memoria y los registros ahora ocurre inmediatamente, y no al final de un párrafo, lo que le permite comenzar a escribir comandos antes del final del párrafo. Como resultado, se reduce el tiempo de inactividad potencial entre párrafos.
- El sistema de comando ha sido optimizado, a saber:
- Se agregó aritmética de enteros de 64 bits: suma, resta, multiplicación de números de 32 bits, que devuelve un resultado de 64 bits.
- El método de lectura desde la memoria ha cambiado: ahora para cualquier comando, simplemente puede especificar la dirección desde la que desea leer los datos como argumento, mientras se conserva el orden de ejecución de los comandos de lectura y escritura.
También hizo obsoleto un comando de lectura de memoria separado. En cambio, el comando de valor de carga se usa en el interruptor de carga (anteriormente, get ), especificando la dirección en la memoria como argumento:
.data foo: .long 0x1234 .text habr: load_l foo ; foo load_l [foo] ; 0x1234 add_l [foo], 0xABCD ; ; complete
- Se ha agregado un formato de comando que permite usar 2 argumentos constantes.
Anteriormente, podía especificar una constante solo como un segundo argumento, el primer argumento siempre debe ser un enlace al resultado en el cambio. El cambio se aplica a todos los equipos de dos argumentos. El campo constante siempre es de 32 bits, por lo que este formato permite, por ejemplo, generar constantes de 64 bits con un comando.
Fue:
load_l 0x12345678 patch_q @1, 0xDEADBEEF
Se convirtió en:
patch_q 0x12345678, 0xDEADBEEF
- Tipos de datos vectoriales modificados y complementados.
Lo que solía llamarse tipos de datos "empaquetados" ahora se puede llamar con seguridad vectorial. En P1 y R1, las operaciones en números empaquetados solo tomaron una constante como el segundo argumento, es decir, al sumar, cada elemento del vector se agregó con el mismo número, y esto no se pudo aplicar de manera inteligente. Ahora, se pueden aplicar operaciones similares a dos vectores completos. Además, esta forma de trabajar con vectores es totalmente coherente con el mecanismo de vectores en LLVM, que ahora permite al compilador generar código utilizando tipos de vectores.
patch_q 0x00010002, 0x00030004 patch_q 0x00020003, 0x00040005 mul_ps @1, @2 ; - 00020006000C0014
- Banderas del procesador eliminadas.
Como resultado, se eliminaron unos 40 equipos basados únicamente en los valores de las banderas. Esto ha reducido significativamente el número de equipos y, en consecuencia, el área del cristal. Y toda la información necesaria ahora se almacena directamente en la celda del interruptor.
- Al comparar con cero, en lugar de la bandera de cero, ahora solo se usa el valor en el interruptor
- En lugar de la bandera de signo, ahora se usa un bit correspondiente al tipo de comando: séptimo para byte, 15 para corto, 31 para largo, 63 para quad. Debido al hecho de que el personaje se multiplica hasta el bit 63, independientemente del tipo, puede comparar números de diferentes tipos:
.data long: .long -0x1000 byte: .byte -0x10 .text habr: a := load_b [byte] ; 0xFFFFFFFFFFFFFFF0, ; byte 7 63. b := loadu_b [byte] ; 0x00000000000000F0, ; .. loadu_b c := load_l [long] ; 0xFFFFFFFFFFFFF000. ge_l @a, @c ; " " 1: ; 31 , . lt_s @a, @b ; 1, .. b complete
- La bandera de transporte ya no es necesaria, ya que hay aritmética de 64 bits.
- El tiempo de transición de un párrafo a otro se redujo a 1 medida (en lugar de 2-3 en R1)
Compilador basado en LLVM
El compilador de lenguaje C para S1 es similar a R1, y dado que la arquitectura no ha cambiado fundamentalmente, los problemas descritos en el artículo anterior, desafortunadamente, no han desaparecido.
Sin embargo, en el proceso de implementación del nuevo sistema de comando, la cantidad de código de salida disminuyó por sí solo, simplemente debido a la actualización del sistema de comando. Además, hay muchas más optimizaciones menores que reducirán la cantidad de instrucciones en el código, algunas de las cuales ya se han realizado (por ejemplo, generar constantes de 64 bits con una sola instrucción). Pero hay optimizaciones aún más serias que deben hacerse, y se pueden construir en orden ascendente de eficiencia y complejidad de implementación:
- La capacidad de generar todos los comandos de dos argumentos con dos constantes.
Generar una constante de 64 bits a través de patch_q es solo un caso especial, pero necesitamos uno general. De hecho, el objetivo de esta optimización es permitir que los equipos sustituyan solo el primer argumento como una constante, ya que el segundo argumento siempre podría ser una constante, y esto se ha implementado durante mucho tiempo. Este no es un caso muy frecuente, pero, por ejemplo, cuando necesita llamar a una función y escribir la dirección de retorno desde la parte superior de la pila, puede
load_l func wr_l @1, #SP
optimizar a
wr_l func, #SP
- La capacidad de sustituir el acceso a la memoria a través de un argumento en cualquier comando.
Por ejemplo, si necesita agregar dos números de la memoria, puede
load_l [foo] load_l [bar] add_l @1, @2
optimizar a
add_l [foo], [bar]
Esta optimización es una extensión de la anterior, sin embargo, el análisis ya es necesario aquí: tal reemplazo solo puede llevarse a cabo si los valores cargados se usan solo una vez en este comando de adición y en ningún otro lugar. Si el resultado de la lectura se usa incluso en solo dos comandos, es más rentable leer de la memoria una vez como un comando separado, y en los otros dos referirse a él a través del interruptor.
- Optimización de la transferencia de registros virtuales entre unidades base.
Para R1, la transferencia de todos los registros virtuales se realizó a través de la memoria, lo que da lugar a una gran cantidad de lecturas y escrituras en la memoria, pero simplemente no había otra forma de transferir datos entre párrafos. S1 le permite acceder a los resultados de los comandos de los párrafos anteriores, por lo tanto, en teoría, se pueden eliminar muchas operaciones de memoria, lo que daría el mayor efecto entre todas las optimizaciones. Sin embargo, este enfoque todavía está limitado por el cambio: no más de 63 resultados anteriores, lejos de cada transferencia del registro virtual se puede implementar de esta manera. Cómo hacer esto no es una tarea trivial, y aún no se ha realizado un análisis de las posibilidades para resolverlo. Las fuentes del compilador pueden aparecer en el dominio público, por lo que si alguien tiene ideas y desea unirse al desarrollo, puede hacerlo.
Puntos de referencia
Dado que el procesador aún no se ha lanzado en el chip, es difícil evaluar su rendimiento real. Sin embargo, el código del núcleo RTL ya está listo, lo que significa que puede realizar una evaluación mediante simulación o FPGA. Para ejecutar los siguientes puntos de referencia, utilizamos una simulación usando el programa ModelSim para calcular el tiempo de ejecución exacto (en medidas). Dado que es difícil simular todo el cristal y lleva mucho tiempo, por lo tanto, se simuló una multicelda y el resultado se multiplicó por 16 (si la tarea está diseñada para subprocesamiento múltiple), ya que cada multicelda puede funcionar de manera completamente independiente de las demás.
Al mismo tiempo, se realizó el modelado multicelda en Xilinx Virtex-6 para probar el rendimiento del código del procesador en hardware real.
Coremark
CoreMark: un conjunto de pruebas para una evaluación integral del rendimiento de los microcontroladores y procesadores centrales, así como de sus compiladores C. Como puede ver, el procesador S1 no es ni uno ni el otro. Sin embargo, está destinado a ejecutar código de arbitraje absoluto, es decir, cualquiera que pueda estar ejecutándose en el procesador central. Por lo tanto, CoreMark es adecuado para evaluar el rendimiento de S1 no peor.
CoreMark contiene trabajo con listas vinculadas, matrices, una máquina de estado y cálculo de suma
CRC . En general, la mayor parte del código resulta ser estrictamente secuencial (lo que prueba la resistencia del
paralelismo de hardware multicelular) y con muchas ramas, por lo que las capacidades del compilador juegan un papel importante en el rendimiento final. El código compilado contiene bastantes párrafos cortos y, a pesar del hecho de que la velocidad de transición entre ellos ha aumentado, la ramificación incluye trabajar con memoria, lo que nos gustaría evitar al máximo.
Tarjeta de puntuación de CoreMark:
| Multiclet R1 (compilador llvm) | Multiclet S1 (compilador llvm) | Elbrus-4C (R500 / E) | Texas Inst. BRAZO AM5728 Cortex-A15 | Baikal-t1 | Intel Core i7 7700K |
|---|
| Año de fabricación | 2015 | 2019 | 2014 | 2018 | 2016 | 2017 |
| Frecuencia de reloj, MHz | 100 | 1600 | 700 | 1500 | 1200 | 4500 |
| Puntuación general de CoreMark | 59 | 18356 | 1214 | 15789 | 13142 | 182128 |
| Coremark / MHz | 0,59 | 11,47 | 5.05 | 10,53 | 10.95 | 40,47 |
El resultado de una multicelda es 1147, o 0.72 / MHz, que es más alto que el de R1. Esto habla de las ventajas de desarrollar arquitectura multicelular en el nuevo procesador.
Wheatstone
Piedra de afilar: un conjunto de pruebas para medir el rendimiento del procesador cuando se trabaja con números de coma flotante. Aquí la situación es mucho mejor: el código también es secuencial, pero sin una gran cantidad de ramas y con buena concurrencia interna.
Whetstone consta de muchos módulos, lo que le permite medir no solo el resultado general, sino también el rendimiento de cada módulo específico:
- Elementos de la matriz
- Matriz como parámetro
- Saltos condicionales
- Aritmética de enteros
- Funciones trigonométricas (tan, sin, cos)
- Llamadas de procedimiento
- Referencias de matriz
- Funciones estándar (sqrt, exp, log)
Se dividen en categorías: los módulos 1, 2 y 6 miden el rendimiento de las operaciones de coma flotante (líneas MFLOPS1-3); módulos 5 y 8 - funciones matemáticas (COS MOPS, EXP MOPS); módulos 4 y 7 - aritmética de enteros (FIXPT MOPS, EQUAL MOPS); módulo 3 - saltos condicionales (IF MOPS). En la tabla a continuación, la segunda fila de MWIPS es un indicador general.
A diferencia de CoreMark, Whetstone se comparará en un núcleo o, como en nuestro caso, en un multicelda. Dado que el número de núcleos es muy diferente en diferentes procesadores, entonces, para la pureza del experimento, consideramos los indicadores por megahercio.
Tarjeta de puntuación de piedra de afilar:
| CPU | MultiClet R1 | MultiClet S1 | Core i7 4820K | BRAZO v8-A53 |
|---|
| Frecuencia, MHz | 100 | 1600 | 3900 | 1300 |
| MWIPS / MHz | 0,311 | 0,343 | 0,887 | 0,642 |
| MFLOPS1 / MHz | 0,157 | 0,156 | 0,341 | 0,268 |
| MFLOPS2 / MHz | 0,153 | 0.111 | 0,308 | 0.241 |
| MFLOPS3 / MHz | 0,029 | 0,124 | 0,167 | 0,239 |
| COS MOPS / MHz | 0,018 | 0.008 | 0,023 | 0,028 |
| EXP MOPS / MHz | 0.008 | 0.005 | 0,014 | 0.004 |
| FIXPT MOPS / MHz | 0,714 | 0.116 | 0,998 | 1.197 |
| SI MOPS / MHz | 0,081 | 0,196 | 1.504 | 1.436 |
| MOPS IGUALES / MHz | 0.143 | 0,149 | 0.251 | 0.439 |
Whetstone contiene operaciones computacionales mucho más directas que CoreMark (que es muy notable cuando se mira el código a continuación), por lo que es importante recordar aquí: la cantidad de ALU de punto flotante se reduce a la mitad. Sin embargo, la velocidad de cálculo casi no se vio afectada, en comparación con R1.
Algunos módulos encajan muy bien en una arquitectura multicelular. Por ejemplo, el módulo 2 cuenta muchos valores en un ciclo, y gracias al soporte total de números de punto flotante de doble precisión por parte del procesador y el compilador, después de la compilación, obtenemos párrafos grandes y hermosos que realmente revelan las capacidades computacionales de una arquitectura multicelular:
Párrafo grande y hermoso para 120 equipos. pa: SR4 := loadu_q [#SP + 16] SR5 := loadu_q [#SP + 8] SR6 := loadu_l [#SP + 4] SR7 := loadu_l [#SP] setjf_l @0, @SR7 SR8 := add_l @SR6, 0x8 SR9 := add_l @SR6, 0x10 SR10 := add_l @SR6, 0x18 SR11 := loadu_q [@SR6] SR12 := loadu_q [@SR8] SR13 := loadu_q [@SR9] SR14 := loadu_q [@SR10] SR15 := add_d @SR11, @SR12 SR11 := add_d @SR15, @SR13 SR15 := sub_d @SR11, @SR14 SR11 := mul_d @SR15, @SR5 SR15 := add_d @SR12, @SR11 SR12 := sub_d @SR15, @SR13 SR15 := add_d @SR14, @SR12 SR12 := mul_d @SR15, @SR5 SR15 := sub_d @SR11, @SR12 SR16 := sub_d @SR12, @SR11 SR17 := add_d @SR11, @SR12 SR11 := add_d @SR13, @SR15 SR13 := add_d @SR14, @SR11 SR11 := mul_d @SR13, @SR5 SR13 := add_d @SR16, @SR11 SR15 := add_d @SR17, @SR11 SR16 := add_d @SR14, @SR13 SR13 := div_d @SR16, @SR4 SR14 := sub_d @SR15, @SR13 SR15 := mul_d @SR14, @SR5 SR14 := add_d @SR12, @SR15 SR12 := sub_d @SR14, @SR11 SR14 := add_d @SR13, @SR12 SR12 := mul_d @SR14, @SR5 SR14 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR15, @SR12 SR15 := add_d @SR11, @SR14 SR11 := add_d @SR13, @SR15 SR14 := mul_d @SR11, @SR5 SR11 := add_d @SR16, @SR14 SR15 := add_d @SR17, @SR14 SR16 := add_d @SR13, @SR11 SR11 := div_d @SR16, @SR4 SR13 := sub_d @SR15, @SR11 SR15 := mul_d @SR13, @SR5 SR13 := add_d @SR12, @SR15 SR12 := sub_d @SR13, @SR14 SR13 := add_d @SR11, @SR12 SR12 := mul_d @SR13, @SR5 SR13 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR15, @SR12 SR15 := add_d @SR14, @SR13 SR13 := add_d @SR11, @SR15 SR14 := mul_d @SR13, @SR5 SR13 := add_d @SR16, @SR14 SR15 := add_d @SR17, @SR14 SR16 := add_d @SR11, @SR13 SR11 := div_d @SR16, @SR4 SR13 := sub_d @SR15, @SR11 SR4 := loadu_q @SR4 SR5 := loadu_q @SR5 SR6 := loadu_q @SR6 SR7 := loadu_q @SR7 SR15 := mul_d @SR13, @SR5 SR8 := loadu_q @SR8 SR9 := loadu_q @SR9 SR10 := loadu_q @SR10 SR13 := add_d @SR12, @SR15 SR12 := sub_d @SR13, @SR14 SR13 := add_d @SR11, @SR12 SR12 := mul_d @SR13, @SR5 SR13 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR15, @SR12 SR15 := add_d @SR14, @SR13 SR13 := add_d @SR11, @SR15 SR14 := mul_d @SR13, @SR5 SR13 := add_d @SR16, @SR14 SR15 := add_d @SR17, @SR14 SR16 := add_d @SR11, @SR13 SR11 := div_d @SR16, @SR4 SR13 := sub_d @SR15, @SR11 SR15 := mul_d @SR13, @SR5 SR13 := add_d @SR12, @SR15 SR12 := sub_d @SR13, @SR14 SR13 := add_d @SR11, @SR12 SR12 := mul_d @SR13, @SR5 SR13 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR15, @SR12 SR15 := add_d @SR14, @SR13 SR13 := add_d @SR11, @SR15 SR14 := mul_d @SR13, @SR5 SR13 := add_d @SR16, @SR14 SR15 := add_d @SR17, @SR14 SR16 := add_d @SR11, @SR13 SR11 := div_d @SR16, @SR4 SR13 := sub_d @SR15, @SR11 SR15 := mul_d @SR13, @SR5 SR13 := add_d @SR12, @SR15 SR12 := sub_d @SR13, @SR14 SR13 := add_d @SR11, @SR12 SR12 := mul_d @SR13, @SR5 SR13 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR14, @SR13 SR13 := add_d @SR11, @SR17 SR14 := mul_d @SR13, @SR5 SR5 := add_d @SR16, @SR14 SR13 := add_d @SR11, @SR5 SR5 := div_d @SR13, @SR4 wr_q @SR15, @SR6 wr_q @SR12, @SR8 wr_q @SR14, @SR9 wr_q @SR5, @SR10 complete
popcnt
Para reflejar las características de la arquitectura en sí (independientemente del compilador), mediremos algo escrito en ensamblador teniendo en cuenta todas las características de la arquitectura. Por ejemplo, contar bits de unidad en un número de 512 bits (popcnt). Para mayor claridad, tomaremos los resultados de una multicelda, para que puedan compararse con R1.
Tabla de comparación, el número de ciclos de reloj por ciclo de cálculo de 32 bits:
| Algoritmo | Multiclet r1 | Multiclet S1 (una multicelda) |
|---|
| Bithacks | 5.0 | 2.625 |
Aquí se usaron nuevas instrucciones vectoriales actualizadas, lo que nos permitió reducir a la mitad el número de instrucciones en comparación con el mismo algoritmo implementado en el ensamblador R1. La velocidad del trabajo, respectivamente, aumentó en casi 2 veces.
popcnt bithacks: b0 := patch_q 0x1, 0x1 v0 := loadu_q [v] v1 := loadu_q [v+8] v2 := loadu_q [v+16] v3 := loadu_q [v+24] v4 := loadu_q [v+32] v5 := loadu_q [v+40] v6 := loadu_q [v+48] v7 := loadu_q [v+56] b1 := patch_q 0x55555555, 0x55555555 i00 := slr_pl @v0, @b0 i01 := slr_pl @v1, @b0 i02 := slr_pl @v2, @b0 i03 := slr_pl @v3, @b0 i04 := slr_pl @v4, @b0 i05 := slr_pl @v5, @b0 i06 := slr_pl @v6, @b0 i07 := slr_pl @v7, @b0 b2 := patch_q 0x33333333, 0x33333333 i10 := and_q @i00, @b1 i11 := and_q @i01, @b1 i12 := and_q @i02, @b1 i13 := and_q @i03, @b1 i14 := and_q @i04, @b1 i15 := and_q @i05, @b1 i16 := and_q @i06, @b1 i17 := and_q @i07, @b1 b3 := patch_q 0x2, 0x2 i20 := sub_pl @v0, @i10 i21 := sub_pl @v1, @i11 i22 := sub_pl @v2, @i12 i23 := sub_pl @v3, @i13 i24 := sub_pl @v4, @i14 i25 := sub_pl @v5, @i15 i26 := sub_pl @v6, @i16 i27 := sub_pl @v7, @i17 i30 := and_q @i20, @b2 i31 := and_q @i21, @b2 i32 := and_q @i22, @b2 i33 := and_q @i23, @b2 i34 := and_q @i24, @b2 i35 := and_q @i25, @b2 i36 := and_q @i26, @b2 i37 := and_q @i27, @b2 i40 := slr_pl @i20, @b3 i41 := slr_pl @i21, @b3 i42 := slr_pl @i22, @b3 i43 := slr_pl @i23, @b3 i44 := slr_pl @i24, @b3 i45 := slr_pl @i25, @b3 i46 := slr_pl @i26, @b3 i47 := slr_pl @i27, @b3 b4 := patch_q 0x4, 0x4 i50 := and_q @i40, @b2 i51 := and_q @i41, @b2 i52 := and_q @i42, @b2 i53 := and_q @i43, @b2 i54 := and_q @i44, @b2 i55 := and_q @i45, @b2 i56 := and_q @i46, @b2 i57 := and_q @i47, @b2 i60 := add_pl @i50, @i30 i61 := add_pl @i51, @i31 i62 := add_pl @i52, @i32 i63 := add_pl @i53, @i33 i64 := add_pl @i54, @i34 i65 := add_pl @i55, @i35 i66 := add_pl @i56, @i36 i67 := add_pl @i57, @i37 b5 := patch_q 0xf0f0f0f, 0xf0f0f0f i70 := slr_pl @i60, @b4 i71 := slr_pl @i61, @b4 i72 := slr_pl @i62, @b4 i73 := slr_pl @i63, @b4 i74 := slr_pl @i64, @b4 i75 := slr_pl @i65, @b4 i76 := slr_pl @i66, @b4 i77 := slr_pl @i67, @b4 b6 := patch_q 0x1010101, 0x1010101 i80 := add_pl @i70, @i60 i81 := add_pl @i71, @i61 i82 := add_pl @i72, @i62 i83 := add_pl @i73, @i63 i84 := add_pl @i74, @i64 i85 := add_pl @i75, @i65 i86 := add_pl @i76, @i66 i87 := add_pl @i77, @i67 b7 := patch_q 0x18, 0x18 i90 := and_q @i80, @b5 i91 := and_q @i81, @b5 i92 := and_q @i82, @b5 i93 := and_q @i83, @b5 i94 := and_q @i84, @b5 i95 := and_q @i85, @b5 i96 := and_q @i86, @b5 i97 := and_q @i87, @b5 iA0 := mul_pl @i90, @b6 iA1 := mul_pl @i91, @b6 iA2 := mul_pl @i92, @b6 iA3 := mul_pl @i93, @b6 iA4 := mul_pl @i94, @b6 iA5 := mul_pl @i95, @b6 iA6 := mul_pl @i96, @b6 iA7 := mul_pl @i97, @b6 iB0 := slr_pl @iA0, @b7 iB1 := slr_pl @iA1, @b7 iB2 := slr_pl @iA2, @b7 iB3 := slr_pl @iA3, @b7 iB4 := slr_pl @iA4, @b7 iB5 := slr_pl @iA5, @b7 iB6 := slr_pl @iA6, @b7 iB7 := slr_pl @iA7, @b7 wr_q @iB0, c wr_q @iB1, c+8 wr_q @iB2, c+16 wr_q @iB3, c+24 wr_q @iB4, c+32 wr_q @iB5, c+40 wr_q @iB6, c+48 wr_q @iB7, c+56 complete
Ethereum
Los puntos de referencia son, por supuesto, buenos, pero tenemos una tarea específica: hacer un acelerador de cómputo, y sería bueno saber cómo maneja las tareas del mundo real. Las criptomonedas modernas son las más adecuadas para dicha verificación, porque los algoritmos de minería se ejecutan en muchos dispositivos diferentes y, por lo tanto, pueden servir como punto de referencia para la comparación. Comenzamos con Ethereum y el algoritmo Ethash, que se ejecuta directamente en el dispositivo de minería.
La elección de Ethereum se debió a las siguientes consideraciones. Como saben, los algoritmos como Bitcoin se implementan de manera muy eficiente mediante chips ASIC especializados, por lo que el uso de procesadores o tarjetas de video para extraer Bitcoin y sus clones se vuelve económicamente desventajoso debido al bajo rendimiento y al alto consumo de energía. La comunidad de mineros, en un intento de alejarse de esta situación, está desarrollando criptomonedas en otros principios algorítmicos, centrándose en el desarrollo de algoritmos que utilizan procesadores de uso general o tarjetas de video para la minería. Es probable que esta tendencia continúe en el futuro. Ethereum es la criptomoneda más famosa basada en este enfoque. La herramienta principal para extraer Ethereum son las tarjetas de video, que en términos de eficiencia (hashrate / TDP) están significativamente (varias veces) por delante de los procesadores de propósito general.
Ethash es un llamado algoritmo
vinculado a la memoria , es decir. su tiempo de cálculo está limitado principalmente por la cantidad y la velocidad de la memoria, y no por la velocidad de los cálculos en sí. Ahora para la minería Ethereum, las tarjetas de video son las más adecuadas, pero su capacidad para realizar simultáneamente muchas operaciones no ayuda mucho, y aún descansan en la velocidad de RAM, lo que se demuestra claramente en
este artículo . A partir de ahí, puede tomar una fotografía que ilustre el funcionamiento del algoritmo para explicar por qué sucede esto.
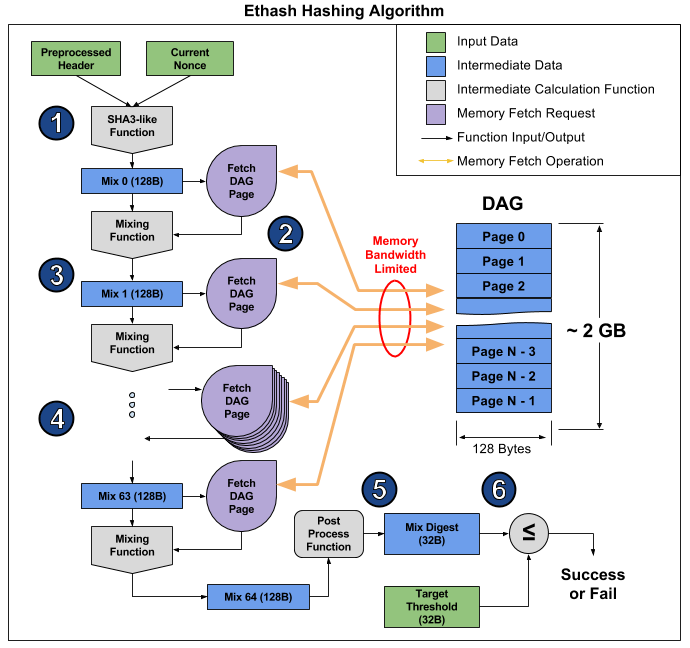
El artículo desglosa el algoritmo en 6 puntos, pero se pueden distinguir 3 etapas para obtener aún más evidencia:
- Inicio: SHA-3 (512) para calcular la mezcla 0 original de 128 bytes (punto 1)
- Nuevo cálculo de 64 veces de la matriz Mix al leer los siguientes 128 bytes y mezclarlos con los anteriores a través de la función de mezcla, para un total de 8 kilobytes (párrafos 2-4)
- Finalización y verificación del resultado.
La lectura de 128 bytes aleatorios de RAM lleva mucho más tiempo del que parece. Si toma la tarjeta gráfica MSI RX 470, que tiene 2048 dispositivos informáticos y un ancho de banda de memoria máximo de 211.2 GB / s, para equipar cada dispositivo necesita 1 / (211.2 GB / (128 b * 2048)) = 1241 ns, o aproximadamente 1496 ciclos a una frecuencia dada. Dado el tamaño de la función de mezcla, podemos suponer que lleva más tiempo leer la memoria de una tarjeta de video que volver a calcular la información recibida. Como resultado, la etapa 2 del algoritmo lleva mucho tiempo, mucho más que las etapas 1 y 3, que finalmente tienen poco efecto en el rendimiento, a pesar de que contienen más cálculos (principalmente en SHA-3). Simplemente puede ver el hashrate de esta tarjeta de video: 26.375 megachashes / s teórico (limitado solo por el ancho de banda de la memoria) versus 24 megachehes / s real, es decir, las etapas 1 y 3 toman solo el 10% del tiempo.
En S1, los 16 multiceldas pueden funcionar en paralelo y en código diferente. Además, se instalará RAM de doble canal, a lo largo de un canal para 8 multiceldas. En la etapa 2 del algoritmo Ethash, nuestro plan es el siguiente: un multicelda lee 128 bytes de la memoria y comienza a contarlos, luego el siguiente lee la memoria y los relata, y así sucesivamente hasta el octavo, es decir. una multicelda, después de leer 128 bytes de memoria, tiene 7 * [tiempo de lectura de 128 bytes] para recalcular la matriz. Se supone que dicha lectura tomará 16 ciclos, es decir. Se dan 112 medidas para el recuento. Calcular la función de mezcla requiere aproximadamente el mismo ciclo de reloj, por lo que S1 está cerca de la relación ideal de ancho de banda de memoria con respecto al rendimiento del procesador. Como el tiempo no se desperdicia en la segunda etapa, las partes restantes del algoritmo deben optimizarse tanto como sea posible, porque realmente afectan el rendimiento.
Para evaluar la velocidad de cálculo SHA-3 (Keccak), se desarrolló y probó un programa en C, en función del cual se está creando actualmente su versión óptima en ensamblador. La programación de la evaluación muestra que un multicelda realiza el cálculo SHA-3 (Keccak) en 1550 ciclos de reloj. Por lo tanto, el tiempo total para calcular un hash por una multicelda será 1550 + 64 * (16 + 112) = 9742 ciclos. Con una frecuencia de 1.6 GHz y 16 multiceldas paralelas, la tasa de hash del procesador será de 2.6 MHash / s.| Acelerador | MultiClet S1 | NVIDIA GeForce GTX 980 Ti | Radeon RX 470 | Radeon RX Vega 64 | NVIDIA GeForce GTX 1060 | NVIDIA GeForce GTX 1080 Ti |
|---|
| Precio | | $ 650 | $ 180 | $ 500 | $ 300 | $ 700 |
| Tasa de hash | 2.6 MHash / s | 21.6 MHash / s | 25.8 MHash / s | 43.5 MHash / s | 25 MHash / s | 55 MHash / s |
| TDP | 6 W | 250 W | 120 W | 295 W | 120 W | 250 W |
| Hashrate / TDP | 0,43 | 0,09 | 0,22 | 0,15 | 0,22 | 0,21 |
| Tecnología de proceso | 28 nm | 28 nm | 14 nm | 14 nm | 16 nm | 16 nm |
Cuando se utiliza MultiClet S1 como herramienta de minería, se pueden instalar 20 o más procesadores en las placas. En este caso, el hashrate de dicha placa será igual o superior a los hashrates de las tarjetas de video existentes, mientras que el consumo de energía de una placa con S1 será la mitad, incluso que el de las tarjetas de video con estándares topográficos de 16 y 14 nm.En conclusión, debo decir que la tarea principal ahora es la fabricación de una placa multiprocesador para un minero de criptomonedas multicelular y un minero de supercomputación. Se planea lograr la competitividad debido al pequeño consumo de energía y la arquitectura, que es muy adecuada para la computación arbitraria.El procesador aún está en desarrollo, pero ya puede comenzar a programar en ensamblador, así como evaluar la versión actual del compilador. Ya existe un SDK mínimo que contiene ensamblador, enlazador, compilador y modelo funcional, en el que puede iniciar y probar sus programas.