
Érase una vez, cuando el cielo era azul, la hierba era más verde y los dinosaurios deambulaban por la Tierra ... No, olvídate de los dinosaurios. Bueno, en general, una vez surgió la idea de distraerme de la programación web estándar y hacer algo más loco. Podría, por supuesto, ser cualquier cosa, pero la elección recayó en escribir su propio intérprete. ¿Qué puedo decir?
Nunca escriba sus propios lenguajes de programación . Pero obtuve algo de experiencia de todo esto, así que decidí compartirlo. Comencemos con la base misma: el lexer.
Prólogo
Antes de comenzar a comprender qué tipo de animal es "lexer", vale la pena averiguar de qué están hechos los YaP.
En el mundo moderno, cada compilador / intérprete / transpilador / algo similar (digamos simplemente "compilador" adicional, sin distinción entre tipos) se divide en dos partes. En la terminología de los tíos inteligentes, tales piezas se denominan "frontend" y "backend". No, esto no es en absoluto lo que, cuando trabajamos con la web, lo que solíamos llamar y el frente no está escrito en JS con HTML. Aunque ... está bien.
La tarea de la primera interfaz es tomar el
texto y convertirlo en un
AST (árbol de sintaxis abstracta), verificando la sintaxis (y a veces la semántica) en el camino. La tarea del segundo backend es hacer que todo funcione. Si el código se ensambla dentro del intérprete, el AST crea un conjunto de instrucciones para el procesador virtual (máquina virtual), si el compilador, entonces el conjunto de instrucciones para el procesador real. En la vida, todo es bastante más complicado y puede que no se implemente de esa manera. Por ejemplo, en el caso del compilador GCC, todo está mezclado, pero Clang ya es más canónico, LLVM es un representante típico del "backend" para compiladores.
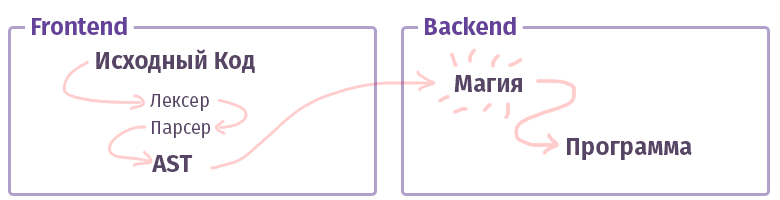
Ahora conozcamos una pieza llamada frontend.
Análisis léxico
La tarea del lexer y la etapa del análisis léxico es obtener muchas, muchas letras en la entrada y agruparlas en algunas categorías: "tokens". Por lo tanto, el análisis léxico también se llama "tokenización". Esta es la primera etapa del procesamiento de texto que produce cada compilador existente.
Algo como esto:
$tokens = ['class', '\w+', '}', '{']; var_dump(lex('class Example {}', $tokens));
Por cierto, aquí ya hemos escrito un montón de herramientas para hacer la vida más fácil. Las mismas funciones
preg que solíamos usar para analizar el texto son bastante
capaces de esta tarea. Sin embargo, existen herramientas más convenientes para este asunto:
- Phlexy , escrita por Nikita Popov.
- Hoa es un kit de herramientas que consta de Lexer + Parser + Grammar.
- Port Yacc , escrito por Anthony Ferrara, que también es un conjunto de herramientas completo, y en el que está escrito el conocido analizador Popov PHP , aplicable en herramientas que utilizan análisis de código.
- Railt Lexer mi implementación para PHP 7.1+
- Parle es una extensión para PHP que permite un conjunto limitado de expresiones PCRE (sin anticipación y otras construcciones de sintaxis).
- Y finalmente, la función php estándar token_get_all , que está destinada directamente para el análisis léxico de PHP.
Bueno, está claro que hay muchos artilugios que pueden dividir el texto por tokens, tal vez incluso olvidé algo, como el
Doctrine lexer. Pero que sigue?
Tipos de Lexers
Y como siempre, no todo es tan simple como parecía. Hay al menos dos categorías diferentes de lexers. Existe la opción habitual, bastante trivial, a la que deslizas las reglas, y ya divide todo en tokens. La configuración de los mismos no es muy diferente del ejemplo que he mostrado anteriormente. Sin embargo, hay otra opción llamada
multiestado . Tales lexers son un poco más difíciles de entender, por lo tanto, quiero hablar un poco más sobre ellos.
La tarea de un lexer multiestado es mostrar varios tokens dependiendo del estado anterior. Bueno, por ejemplo, en PHP, tales estados de "transición" se forman usando las etiquetas <? Php +?>, Líneas internas, comentarios y construcciones
HEREDOC /
NOWDOC .
¿Recuerdas el ejemplo anterior con 4 tokens anteriores? Modifíquelo un poco para comprender cuáles son estos estados:
class Example {
En este caso, si tenemos el lexer más simple sin las amplias capacidades de PCRE, obtenemos el siguiente conjunto de tokens:
var_dump(lex(...));
Como puede ver, obtuvimos una jamba completamente banal en los elementos 3-5: el comentario se recibió de manera inesperada y se dividió en tokens, aunque debería haberse considerado como una pieza completa.
Por supuesto, con el PCRE funcional, tal token podría ser arrancado con la ayuda de una simple regularidad "
// [^ \ n] * \ n ", pero si no es así? ¿O queremos cortarlo con nuestras manos? En resumen, en el caso de un lexer multiestado, podemos decir que todos los tokens deberían estar en el grupo
No1 , tan pronto como se encuentre el token "
// ", entonces debería ocurrir una transición al grupo
No2 . Y dentro del segundo grupo, la transición inversa, si se encuentra el token "
\ n ", la transición de regreso al primer grupo.
Algo como esto:
$tokens = [ 'group-1' => [ 'class', '\w+', '{', '}', '//' => 'group-2'
Creo que ahora se está volviendo más claro cómo se analiza un poco de HEREDOC, porque incluso con todo el poder de PCRE, escribir un periódico para este caso es extremadamente problemático, dado que esta sintaxis de HEREDOC admite interpolación variable. Solo intenta analizar algo como esto con la función incorporada
token_get_all (nota> token 12):
<?php $example = 42; $a = <<<EOL Your answer is $example !!! EOL; var_dump(token_get_all(file_get_contents(__FILE__)));
Bueno, parece que estamos listos para comenzar a practicar.
Practica
¿Recordemos lo que tenemos en PHP para tales cosas? Bueno, por supuesto, preg_match! De acuerdo, baja. El algoritmo basado en preg_match se implementa en
Hoa y
en esta implementación de Phelxy . Su tarea es bastante simple:
- Tenemos a mano el texto fuente y una serie de clientes habituales.
- Emparejamos hasta que se encuentre algo adecuado.
- Tan pronto como encuentre una pieza, córtela del texto y combine más.
En forma de código, se verá más o menos así:
Hoja de código <?php class SimpleLexer { private $tokens = []; public function __construct(array $tokens) { foreach ($tokens as $name => $definition) { $this->tokens[$name] = \sprintf('/\G%s/isSum', $definition); } } public function lex(string $sources): iterable { [$offset, $length] = [0, \strlen($sources)]; while ($offset < $length) { [$name, $token] = $this->next($sources, $offset); yield $name => $token; $offset += \strlen($token); } } private function next(string $sources, int $offset): array { foreach ($this->tokens as $name => $pcre) { \preg_match($pcre, $sources, $matches, 0, $offset); $token = \reset($matches); if (\count($matches) && \strpos($sources, $token, $offset) === $offset) { return [$name, $token]; } } throw new \RuntimeException('Unrecognized token at offset ' . $offset); } }
Usando una hoja de código $lexer = new SimpleLexer([ 'T_CLASS' => 'class', 'T_CONST' => '\w+', 'T_BRACE_OPEN' => '{', 'T_BRACE_CLOSE' => '}', 'T_WHITESPACE' => '\s+', ]); echo \sprintf('| %-10s | %-20s |', 'VALUE', 'NAME') . "\n"; foreach ($lexer->lex('class Example {}') as $name => $token) { echo \sprintf('| %-10s | %-20s |', '"' . \trim($token, "\n") . '"', $name) . "\n"; }
Este enfoque es bastante trivial y permite que un par de pulsaciones del teclado modifiquen el lexer en la región del método next (), agregando una transición entre estados y convirtiendo esta división de la masturbación en un lexer multiestado primitivo. En el área
$ this-> tokens, simplemente agregue algo como
$ this-> tokens [$ this-> state] .
Sin embargo, además del primitivismo en sí, hay otro inconveniente, no fatal como podría resultar, pero aún así ... Tal implementación es increíblemente lenta. En el i7 7600k, cuyo propietario era por casualidad, un algoritmo similar procesa alrededor de 400 tokens por segundo y con un aumento en sus variaciones (es decir, las definiciones que pasamos al constructor), puede disminuir la velocidad de los presidentes cambiantes en Rusia ... ejem lo siento Quería decir, por supuesto, que funcionará
muy lentamente .
Ok, que podemos hacer? Para empezar, puedes entender lo que va mal. El hecho es que cada vez que llamamos
preg_match dentro de la naturaleza del lenguaje, surge un compilador con su JIT llamado PCRE (y con PHP 7.3, PCRE2 ya lo es). Cada vez que analiza los clientes habituales y recopila un analizador para ellos, con el que analizamos el texto para crear tokens. Suena un poco extraño y tautológico. Pero en resumen, cada token requiere compilación de 1 a N regulares, donde N es el número de definiciones de estos tokens. Al mismo tiempo, vale la pena señalar que incluso la bandera "
S " aplicada y la optimización usando "
\ G " en el constructor, donde se generan expresiones regulares para tokens, no ayudan.
Solo hay una forma de salir de esta situación: debe analizar todo este texto de una sola vez, es decir. ejecutando solo una función
preg_match . Queda por resolver dos problemas:
- ¿Cómo indicar que el resultado de la expresión regular N1 corresponde al token N2? Es decir cómo indicar que " \ w + ", por ejemplo, es T_CONST .
- Cómo determinar la secuencia de tokens como resultado. Como sabes, el resultado de preg_match o preg_match_all contendrá todo mezclado. E incluso con la ayuda de banderas aprobadas como el cuarto argumento, la situación no cambiará.
Aquí puedes hacer una pausa y pensar un poco. Bien o no.
La solución al primer problema se
denomina grupos PCRE , que también se denominan "submáscaras". Usando las reglas: "
(? <T_WHITESPACE> \ s + | <T_WORD> \ w + | ...) " puede obtener todos los tokens en una pasada comparándolos con sus nombres. Como resultado de la coincidencia, se formará una matriz asociativa, que consta de los pares "
[TOKEN_NAME => TOKEN_VALUE] ".
El segundo es un poco más complicado. Pero aquí puede aplicar un truco táctico y usar la función
preg_replace_callback . Su peculiaridad es que el anónimo pasado como el segundo argumento se llamará estrictamente secuencialmente para cada token, desde el primero hasta el último.
Para no languidecer, la implementación es la siguiente:
Otra solapa de código class PregReplaceLexer { private $tokens = []; public function __construct(array $tokens) { foreach ($tokens as $name => $definition) { $this->tokens[] = \sprintf('(?<%s>%s)', $name, $definition); } } public function lex(string $sources): iterable { $result = []; \preg_replace_callback($this->compilePcre(), function (array $matches) use (&$result) { foreach (\array_reverse($matches) as $name => $value) { if (\is_string($name) && $value !== '') { $result[] = [$name, $value]; break; } } }, $sources); foreach ($result as [$name, $value]) { yield $name => $value; } } private function compilePcre(): string { return \sprintf('/\G(?:%s)/isSum', \implode('|', $this->tokens)); } }
Y su uso no es diferente de la versión anterior. Al mismo tiempo, la velocidad de trabajo aumenta de
400 a
57,000 fichas por segundo. Es este algoritmo el que apliqué
en mi implementación , retomando la reescritura del código fuente de Hoa. Por cierto, si usa Parle, puede exprimir hasta
600,000 tokens por segundo. Y la imagen general se ve más o menos así (con XDebug activado en PHP 7.1, por lo que los números son más bajos, pero la proporción puede representarse aproximadamente).
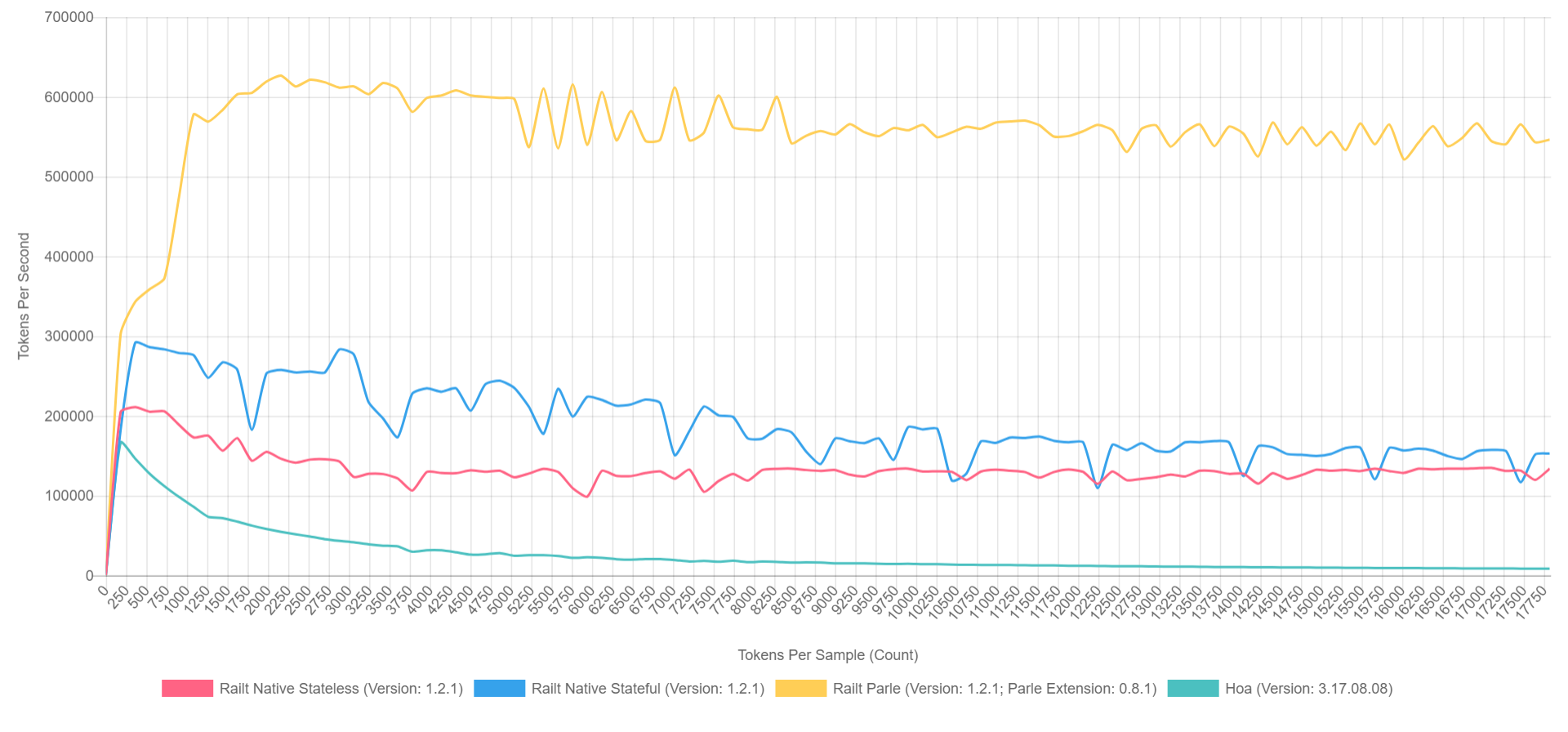
- El amarillo es la extensión nativa de Parle.
- Azul: implementación a través de preg_replace_callback con premontado regular.
- Rojo: de todos modos, pero con la regularidad generada durante la llamada a preg_replace_callback .
- Verde: implementación a través de preg_match .
Por qué
Bueno, todo esto, por supuesto, es maravilloso, pero los impacientes están ansiosos por hacer la pregunta: "¿Quién necesita esto?" En el mundo abstracto de PHP, donde domina el principio de "fig-fig-and-site-ready": tales bibliotecas no son necesarias, seremos honestos. Pero si hablamos del ecosistema como un todo, entonces podemos recordar las bibliotecas notorias como
Symfony / Yaml o
Doctrine . Las anotaciones en Symfony son el mismo sub-lenguaje dentro de PHP, que requieren un análisis léxico y sintáctico por separado. Además, hay incluso transpiladores CoffeeScript, Less y Scss / Sass poco menos conocidos escritos en PHP. Bueno, o
Yay y
preprocese basado en eso. Ni siquiera mencionaré herramientas de análisis de código como phpmd o phpcs. Y los generadores de documentación como phpDocumentnor o Sami son bastante triviales. Cada uno de estos proyectos, en un grado u otro, utiliza el análisis léxico en la primera etapa de análisis de texto / código.
Esta no es una lista completa de proyectos y quizás espero que mi historia lo ayude a descubrir algo nuevo y reponerlo.
Epílogo
Mirando hacia el futuro, si hay alguien interesado en el tema de analizadores y compiladores, entonces hay algunos informes interesantes sobre este tema, en particular de los chicos de JetBrains:
Aún así, por supuesto, la mayoría de las actuaciones de Andrei Breslav (
abreslav ), que se pueden encontrar en la inmensidad de YouTube, te aconsejo que mires.
Bueno, para los fanáticos de la ficción
existe un recurso que fue personalmente extremadamente útil para mí.
Post post scriptum. Si estás en algún lugar sellado en la inmensidad de esta epopeya, entonces puedes informar al autor de manera segura en cualquier forma conveniente para ti.
Como beneficio adicional, me gustaría dar
un ejemplo de un simple PHP lexer , parece que ahora no da tanto miedo, y ahora incluso está claro lo que hace, ¿verdad? Aunque a quien estoy engañando, los ojos sangran de los habituales. =)
Gracias