El primer servicio en Nomad I se lanzó en septiembre de 2016. En este momento lo uso como programador y apoyo como administrador de dos clusters Nomad: un "hogar" para mis proyectos personales (6 máquinas micro-virtuales en Hetzner Cloud y ArubaCloud en 5 centros de datos diferentes en Europa) y el segundo en funcionamiento (alrededor de 40 servidores privados virtuales y físicos en dos centros de datos).
En el pasado, se ha acumulado bastante experiencia con el entorno de Nomad, en el artículo describiré los problemas encontrados por Nomad y cómo lidiar con ellos.

Yamal Nomad realiza la instancia de entrega continua de su software © National Geographic Russia
1. El número de nodos de servidor por centro de datos
Solución: un nodo de servidor es suficiente para un centro de datos.
La documentación no indica explícitamente cuántos nodos de servidor se requieren en un centro de datos. Solo se indica que se necesitan 3-5 nodos por región, lo cual es lógico para el consenso del protocolo de balsa.
Al principio, planeé 2-3 nodos de servidor en cada centro de datos para proporcionar redundancia.
Al usarlo resultó:
- Esto simplemente no es necesario, ya que en el caso de una falla del nodo en el centro de datos, el papel del nodo del servidor para los agentes en este centro de datos será desempeñado por otros nodos del servidor en la región.
- Resulta aún peor si el problema 8 no se resuelve. Cuando el asistente es reelegido, pueden producirse incoherencias y Nomad reiniciará parte de los servicios.
2. Recursos del servidor para el nodo del servidor
Solución: una pequeña máquina virtual es suficiente para el nodo del servidor. En el mismo servidor, está permitido ejecutar otros servicios que no requieren muchos recursos.
El consumo de memoria del demonio Nomad depende del número de tareas en ejecución. Consumo de CPU: basado en la cantidad de tareas y la cantidad de servidores / agentes en la región (no lineal).
En nuestro caso: para 300 tareas en ejecución, el consumo de memoria es de aproximadamente 500 MB para el nodo maestro actual.
En un clúster de trabajo, una máquina virtual para un nodo de servidor: 4 CPU, 6 GB de RAM.
Lanzado adicionalmente: Consul, Etcd, Vault.
3. Consenso sobre la falta de centros de datos.
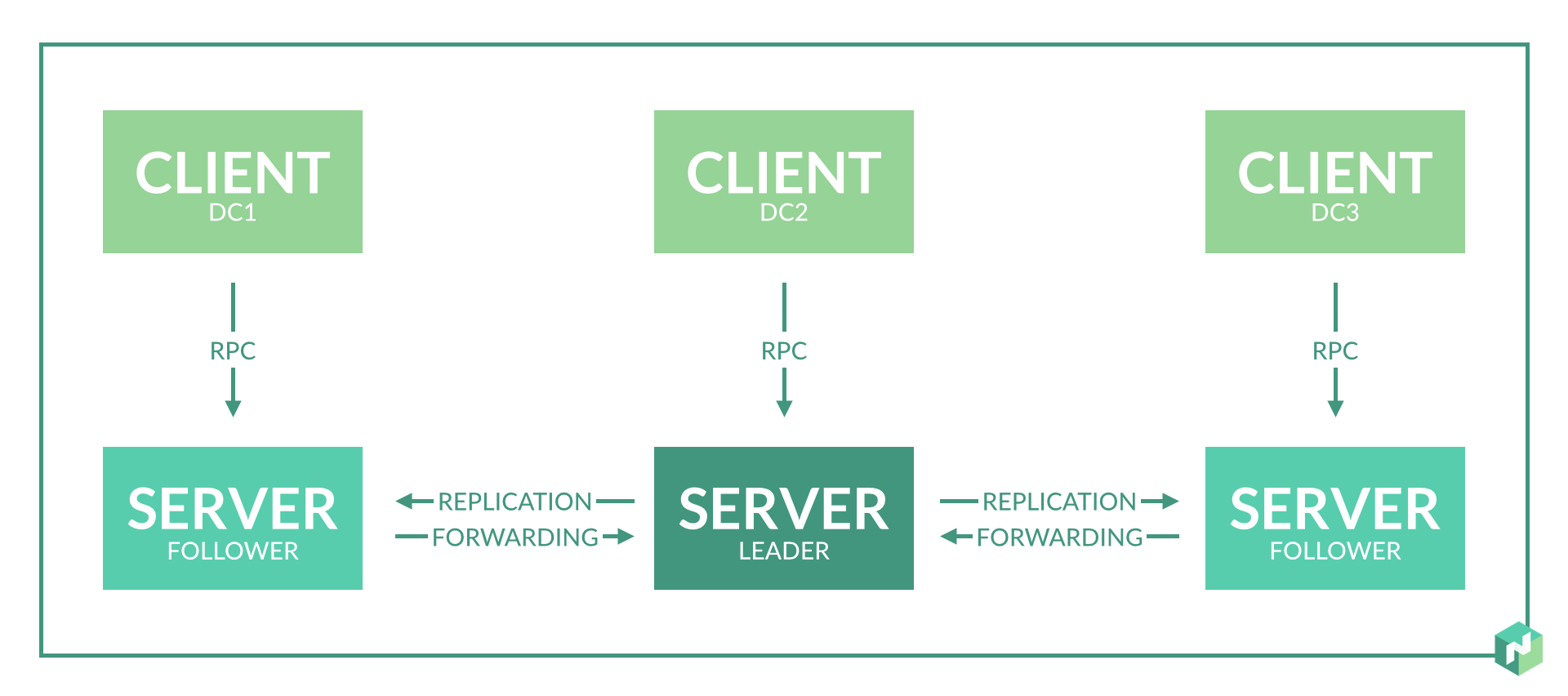
Solución: creamos tres centros de datos virtuales y tres nodos de servidor para dos centros de datos físicos.
El trabajo de Nomad dentro de la región se basa en el protocolo de la balsa. Para un funcionamiento correcto, necesita al menos 3 nodos de servidor ubicados en diferentes centros de datos. Esto permitirá un funcionamiento correcto con una pérdida completa de conectividad de red con uno de los centros de datos.
Pero solo tenemos dos centros de datos. Nos comprometemos: seleccionamos un centro de datos, en el que confiamos más, y hacemos un nodo de servidor adicional en él. Hacemos esto mediante la introducción de un centro de datos virtual adicional, que se ubicará físicamente en el mismo centro de datos (consulte el subpárrafo 2 del problema 1).
Solución alternativa: separamos los centros de datos en regiones separadas.
Como resultado, los centros de datos funcionan de manera independiente y solo se necesita consenso dentro de un centro de datos. Dentro de un centro de datos, en este caso es mejor hacer 3 nodos de servidor implementando tres centros de datos virtuales en uno físico.
Esta opción es menos conveniente para la distribución de tareas, pero ofrece una garantía del 100% de la independencia de los servicios en caso de problemas de red entre centros de datos.
4. "Servidor" y "agente" en el mismo servidor
Solución: válida si tiene un número limitado de servidores.
La documentación nómada dice que hacer esto no es deseable. Pero si no tiene la oportunidad de asignar máquinas virtuales separadas para los nodos del servidor, puede colocar el servidor y los nodos de agente en el mismo servidor.
Ejecutar simultáneamente significa iniciar el daemon Nomad tanto en modo cliente como en modo servidor.
¿Qué amenaza esto? Con una gran carga en la CPU de este servidor, el nodo del servidor Nomad funcionará de manera inestable, se puede perder el consenso y el latido, y los servicios se recargarán.
Para evitar esto, aumentamos los límites de la descripción del problema No. 8.
5. Implementación de espacios de nombres
Solución: quizás a través de la organización de un centro de datos virtual.
A veces necesita ejecutar parte de los servicios en servidores separados.
La solución es la primera, simple, pero más exigente en recursos. Dividimos todos los servicios en grupos de acuerdo con su propósito: frontend, back-end, ... Agrega meta atributos a los servidores, prescribe los atributos para ejecutar para todos los servicios.
La segunda solución es simple. Agregamos nuevos servidores, prescribimos meta atributos para ellos, prescribimos estos atributos de lanzamiento a los servicios necesarios, y todos los demás servicios prescriben la prohibición de iniciar servidores con este atributo.
La tercera solución es complicada. Creamos un centro de datos virtual: inicie Consul para un nuevo centro de datos, inicie el nodo del servidor Nomad para este centro de datos, sin olvidar el número de nodos del servidor para esta región. Ahora puede ejecutar servicios individuales en este centro de datos virtual dedicado.
6. Integración con Vault
Solución: Evite las dependencias circulares de Nomad <-> Vault.
La Bóveda lanzada no debería tener ninguna dependencia de Nomad. La dirección de la Bóveda registrada en Nomad preferiblemente debe apuntar directamente a la Bóveda, sin capas de equilibradores (pero válidos). La reserva de bóveda en este caso se puede hacer a través de DNS - Consul DNS o externa.
Si los datos de Vault se escriben en los archivos de configuración de Nomad, Nomad intenta acceder a Vault al inicio. Si el acceso no es exitoso, Nomad se niega a comenzar.
Cometí un error con una dependencia cíclica hace mucho tiempo, esto una vez destruyó brevemente casi por completo el grupo Nomad. Vault se lanzó correctamente, independientemente de Nomad, pero Nomad miró la dirección de Vault a través de los equilibradores que se ejecutaban en Nomad. La reconfiguración y el reinicio de los nodos del servidor Nomad provocaron un reinicio de los servicios del equilibrador, lo que provocó un error al iniciar los nodos del servidor.
7. Lanzamiento de importantes servicios estatales.
Solución: válida, pero yo no.
¿Es posible ejecutar PostgreSQL, ClickHouse, Redis Cluster, RabbitMQ, MongoDB a través de Nomad?
Imagine que tiene un conjunto de servicios importantes, cuyo trabajo está vinculado a la mayoría de los otros servicios. Por ejemplo, una base de datos en PostgreSQL / ClickHouse. O almacenamiento general a corto plazo en Redis Cluster / MongoDB. O un bus de datos en Redis Cluster / RabbitMQ.
Todos estos servicios de alguna forma implementan un esquema tolerante a fallas: Stolon / Patroni para PostgreSQL, su propia implementación de balsa en Redis Cluster, su propia implementación de clúster en RabbitMQ, MongoDB, ClickHouse.
Sí, todos estos servicios se pueden iniciar a través de Nomad con referencia a servidores específicos, pero ¿por qué?
Además: facilidad de lanzamiento, un formato de script único, como otros servicios. No hay que preocuparse por los guiones ansibles / cualquier otra cosa.
Menos es un punto adicional de falla, que no ofrece ninguna ventaja. Personalmente, eliminé por completo el clúster Nomad dos veces por varias razones: una vez "en casa", una vez trabajando. Esto fue en las primeras etapas de la presentación de Nomad y debido a la negligencia.
Además, Nomad comienza a comportarse mal y reinicia los servicios debido al problema número 8. Pero incluso si ese problema se resuelve, el peligro permanece.
8. La estabilización del trabajo y el servicio se reinicia en una red inestable.
Solución: use las opciones de ajuste de latidos.
De forma predeterminada, Nomad está configurado para que cualquier problema de red a corto plazo o carga de CPU provoque la pérdida de consenso y la reelección del asistente o marque el nodo del agente como inaccesible. Y esto lleva a reinicios espontáneos de servicios y su transferencia a otros nodos.
Estadísticas del clúster "hogar" antes de solucionar el problema: la vida útil máxima del contenedor antes de reiniciar es de aproximadamente 10 días. Aquí, todavía tiene la carga de ejecutar el agente y el servidor en el mismo servidor y colocarlo en 5 centros de datos diferentes en Europa, lo que implica una gran carga en la CPU y una red menos estable.
Estadísticas del clúster de trabajo antes de solucionar el problema: la vida útil máxima del contenedor antes de reiniciar es más de 2 meses. Aquí todo es relativamente bueno debido a los servidores separados para los nodos del servidor Nomad y la excelente red entre los centros de datos.
Valores por defecto
heartbeat_grace = "10s" min_heartbeat_ttl = "10s" max_heartbeats_per_second = 50.0
A juzgar por el código: en esta configuración, los latidos se hacen cada 10 segundos. Con la pérdida de dos latidos, comienza la reelección del maestro o la transferencia de servicios desde el nodo del agente. Configuraciones controvertidas, en mi opinión. Los editamos dependiendo de la aplicación.
Si tiene todos los servicios ejecutándose en varias instancias y son distribuidos por centros de datos, lo más probable es que no le importe un largo período para determinar la inaccesibilidad del servidor (aproximadamente 5 minutos, en el ejemplo a continuación): hacemos menos frecuente el intervalo de latidos y un período más largo para determinar la inaccesibilidad. Este es un ejemplo de cómo configurar mi clúster de inicio:
heartbeat_grace = "300s" min_heartbeat_ttl = "30s" max_heartbeats_per_second = 10.0
Si tiene una buena conectividad de red, servidores separados para los nodos del servidor, y el período para determinar la inaccesibilidad del servidor es importante (hay algún servicio ejecutándose en una instancia y es importante transferirlo rápidamente), luego aumente el período para determinar la inaccesibilidad (heartbeat_grace). Opcionalmente, puede hacer más latidos (disminuyendo min_heartbeat_ttl); esto aumentará ligeramente la carga en la CPU. Ejemplo de configuración de clúster de trabajo:
heartbeat_grace = "60s" min_heartbeat_ttl = "10s" max_heartbeats_per_second = 50.0
Esta configuración soluciona completamente el problema.
9. Inicio de tareas periódicas.
Solución: Se pueden utilizar los servicios periódicos nómadas, pero cron es más conveniente para el soporte.
Nomad tiene la capacidad de lanzar periódicamente el servicio.
La única ventaja es la simplicidad de esta configuración.
El primer inconveniente es que si el servicio se inicia con frecuencia, ensuciará la lista de tareas. Por ejemplo, al inicio cada 5 minutos, se agregarán 12 tareas adicionales a la lista cada hora, hasta que se active el GC Nomad, lo que eliminará las tareas anteriores.
El segundo inconveniente: no está claro cómo configurar adecuadamente la supervisión de dicho servicio. ¿Cómo entender que un servicio comienza, cumple y hace su trabajo hasta el final?
Como resultado, para mí, llegué a la implementación "cron" de tareas periódicas:
- Puede ser un cron regular en un contenedor que se ejecuta constantemente. Cron ejecuta periódicamente un cierto script. Se agrega fácilmente una comprobación de estado del script a dicho contenedor, que verifica cualquier indicador que cree un script en ejecución.
- Puede ser un contenedor en ejecución constante, con un servicio en ejecución constante. Ya se ha implementado un lanzamiento periódico dentro del servicio. Se puede agregar fácilmente un script-healthcheck similar o http-healthcheck a dicho servicio, que verifica el estado inmediatamente por su "interior".
En el momento en que escribo la mayor parte del tiempo en Go, respectivamente, prefiero la segunda opción con http healthcheck: on Go y el lanzamiento periódico, y http healthcheck'i se agregan con algunas líneas de código.
10. Prestación de servicios redundantes.
Solución: no existe una solución simple. Hay dos opciones más difíciles.
El esquema de aprovisionamiento proporcionado por los desarrolladores de Nomad es para admitir la cantidad de servicios en ejecución. Dices que el nómada "lanzame 5 instancias del servicio" y él las inicia en algún lugar allí. No hay control sobre la distribución. Las instancias pueden ejecutarse en el mismo servidor.
Si el servidor falla, las instancias se transfieren a otros servidores. Mientras se transfieren las instancias, el servicio no funciona. Esta es una opción de provisión de reserva incorrecta.
Lo hacemos bien:
- Distribuimos instancias en servidores a través de distinct_hosts .
- Distribuimos instancias en centros de datos. Desafortunadamente, solo al crear una copia del script del formulario service1, service2 con los mismos contenidos, diferentes nombres y una indicación del lanzamiento en diferentes centros de datos.
En Nomad 0.9, aparecerá una funcionalidad que solucionará este problema: será posible distribuir servicios en una proporción porcentual entre servidores y centros de datos.
11. Web UI Nomad
Solución: la interfaz de usuario integrada es terrible, el hashi-ui es hermoso.
El cliente de la consola realiza la mayor parte de la funcionalidad requerida, pero a veces desea ver los gráficos, presionar los botones ...
Nomad tiene una interfaz de usuario incorporada. No es muy conveniente (incluso peor que la consola).
La única alternativa que conozco es hashi-ui .
De hecho, ahora personalmente necesito el cliente de consola solo para "nomad run". E incluso esto planea transferir a CI.
12. Soporte para sobresuscripciones de memoria
Solución: no.
En la versión actual de Nomad, debe especificar un límite de memoria estricto para el servicio. Si se excede el límite, el servicio será asesinado por OOM Killer.
La suscripción excesiva es cuando los límites para un servicio se pueden especificar "desde y hacia". Algunos servicios requieren más memoria al inicio que durante el funcionamiento normal. Algunos servicios pueden consumir más memoria de lo habitual por un corto tiempo.
La elección de una restricción estricta o suave es un tema de discusión, pero, por ejemplo, Kubernetes permite al programador tomar una decisión. Desafortunadamente, en las versiones actuales de Nomad no existe tal posibilidad. Admito que aparecerá en futuras versiones.
13. Limpieza del servidor de los servicios Nomad
Solución:
sudo systemctl stop nomad mount | fgrep alloc | awk '{print $3}' | xargs -I QQ sudo umount QQ sudo rm -rf /var/lib/nomad sudo docker ps | grep -v '(-1|-2|...)' | fgrep -v IMAGE | awk '{print $1}' | xargs -I QQ sudo docker stop QQ sudo systemctl start nomad
A veces "algo sale mal". En el servidor, mata el nodo del agente y se niega a iniciarse. O el nodo del agente deja de responder. O el nodo del agente "pierde" los servicios en este servidor.
Esto a veces sucedió con versiones anteriores de Nomad, ahora esto no sucede, o muy raramente.
¿Qué es lo más fácil en este caso, dado que el servidor de drenaje no producirá el resultado deseado? Limpiamos el servidor manualmente:
- Detén al agente nómada.
- Desmonta en la montura que crea.
- Eliminar todos los datos del agente.
- Eliminamos todos los contenedores filtrando los contenedores de servicio (si los hay).
- Comenzamos el agente.
14. ¿Cuál es la mejor manera de desplegar Nomad?
Solución: por supuesto, a través del Cónsul.
El cónsul en este caso no es en absoluto una capa adicional, sino un servicio que se adapta orgánicamente a la infraestructura, lo que brinda más ventajas que desventajas: DNS, almacenamiento KV, búsqueda de servicios, monitoreo de la disponibilidad del servicio, la capacidad de intercambiar información de manera segura.
Además, se desarrolla tan fácilmente como el propio Nomad.
15. ¿Qué es mejor: nómada o kubernetes?
Solución: depende de ...
Anteriormente, a veces tenía la idea de comenzar una migración a Kubernetes; estaba tan molesto por el reinicio periódico y espontáneo de los servicios (vea el problema número 8). Pero después de una solución completa al problema, puedo decir: Nomad me conviene en este momento.
Por otro lado: Kubernetes también tiene una recarga de servicios semi-espontánea, cuando el planificador de Kubernetes redistribuye instancias dependiendo de la carga. Esto no es muy bueno, pero es muy probable que esté configurado.
Ventajas de Nomad: la infraestructura es muy fácil de implementar, scripts simples, buena documentación, soporte integrado para Consul / Vault, que a su vez brinda: una solución simple al problema del almacenamiento de contraseñas, DNS incorporado, helchecks fáciles de configurar.
Ventajas de Kubernetes: ahora es un "estándar de facto". Buena documentación, muchas soluciones listas para usar, con una buena descripción y estandarización del lanzamiento.
Desafortunadamente, no tengo la misma gran experiencia en Kubernetes para responder inequívocamente a la pregunta: qué usar para el nuevo clúster. Depende de las necesidades planificadas.
Si tiene planeados muchos espacios de nombres (problema número 5) o sus servicios específicos consumen mucha memoria al principio, luego libérelos (problema número 12), definitivamente Kubernetes, porque Estos dos problemas en Nomad no están completamente resueltos o son inconvenientes.