Abril 2018. Tenía 14 años. Mis amigos y yo jugamos en el muy popular cuestionario en línea "Clover" de VKontakte. Uno de nosotros (generalmente yo) siempre estaba detrás de una computadora portátil para tratar de buscar rápidamente en Google preguntas y buscar en los resultados de búsqueda la respuesta correcta. Pero de repente me di cuenta de que estaba haciendo lo mismo cada vez, y decidí intentar escribirlo en Python 3, parcialmente conocido por mí entonces.
Paso 0. ¿Qué está pasando aquí?
Para empezar, actualizaré en tu memoria la mecánica de "Clover".
El juego para todos comienza al mismo tiempo, a las 13:00 y a las 20:00 hora de Moscú. Para jugar, debe ingresar a la aplicación en este momento y conectarse a la transmisión en vivo. El juego dura 15 minutos, durante los cuales se envían preguntas a los participantes por teléfono
al mismo tiempo . La respuesta es de
10 segundos. Entonces se anuncia la respuesta correcta. Todos los que adivinaron van más allá. Hay 12 preguntas en total, y si responde a todas, recibirá un premio en efectivo.
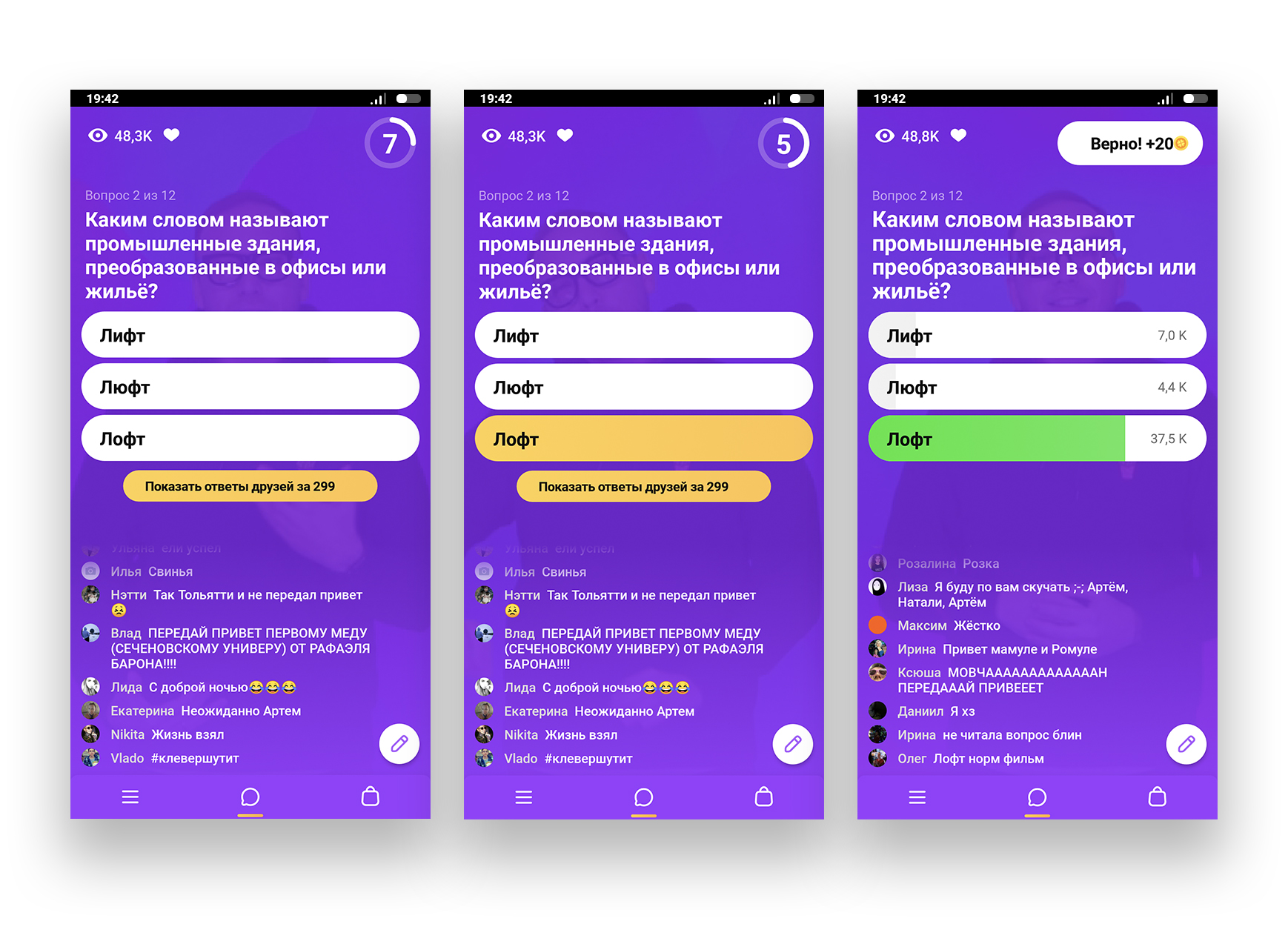
Resulta que nuestra tarea es capturar instantáneamente nuevas preguntas del servidor Clover, procesarlas a través de un motor de búsqueda y determinar la respuesta correcta en función de los resultados de la búsqueda. Se decidió enviar la respuesta en un bot de telegramas para que las notificaciones aparecieran en el teléfono durante el juego. Y todo esto es deseable en un par de segundos, porque el tiempo de respuesta es muy limitado. Si quieres ver cómo un código bastante simple, pero funcional (y mirar este será útil para los principiantes) nos ayudó a vencer a Clover, bienvenido al corte.
Paso 1. Obtenga preguntas del servidor
Al principio parecía la etapa más difícil. Ya respiré hondo y estaba listo para subir a la naturaleza como la visión por computadora, interceptar el tráfico o descompilar la aplicación ... Cuando de repente me esperaba una sorpresa: ¡Clover tiene una API abierta! No está documentado en ninguna parte, pero si durante el juego, tan pronto como se hizo una pregunta a todos los jugadores, haga una solicitud en api.vk.com, a cambio recibiremos la pregunta y las opciones de respuesta en JSON:
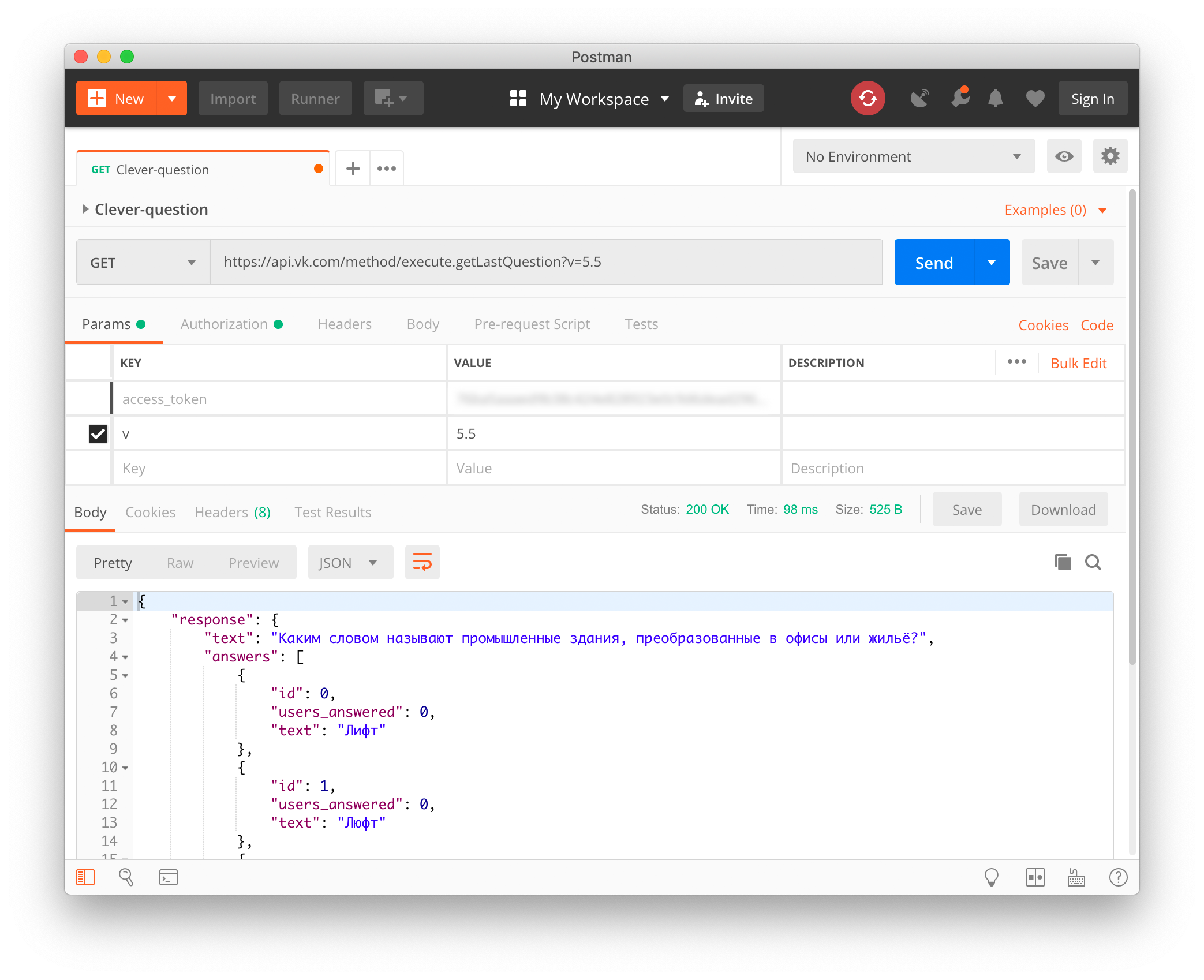
https://api.vk.com/method/execute.getLastQuestion?v=5.5&access_token=VK_USER_TOKEN
Como access_token, es necesario transferir el token API de cualquier usuario de VKontakte, pero es importante que se haya emitido originalmente específicamente para Clover. Su app_id es 6334949.
Paso 2. Procesamos el problema a través de un motor de búsqueda.
Había dos opciones: utilizar la API oficial del motor de búsqueda o agregar argumentos de búsqueda directamente a la barra de direcciones y analizar los resultados. Al principio probé el segundo, pero no solo capté captcha, sino que también perdí mucho tiempo, porque las páginas se cargaron en promedio en 2 segundos. Y les recuerdo que es aconsejable que nos encontremos estos dos segundos. Bueno, y lo principal: no obtuve textos grandes y estructurados de los motores de búsqueda sobre el tema necesario, ya que solo pequeñas piezas del material necesario, que se llaman
fragmentos, cuelgan en la página de búsqueda:

Entonces comencé a buscar una API. Google no encajaba: sus soluciones eran muy limitadas y devolvían muy pocos datos.
Yandex.XML resultó ser el más generoso: le permite enviar 10,000 solicitudes por día, no más de 5 por segundo, y devuelve datos muy rápidamente. La solicitud es opcionalmente el número de páginas (hasta 100) y el número de pasajes, valores especiales que se utilizan para formar fragmentos. Obtenemos los datos en XML. Sin embargo, estos son todos los mismos fragmentos.
Para que pueda familiarizarse y jugar con lo que Yandex devuelve, aquí hay un ejemplo de una respuesta a la pregunta "¿Cuál es el nombre del antagonista principal en la serie de videos" The Legend of Zelda? ":
Yandex. ConducirTuve suerte, y resultó que en pypi, ya existe un módulo separado
de búsqueda yandex para esto. Entonces, traté de obtener la pregunta del servidor, encontrarla en Yandex, hacer un gran texto con fragmentos y dividirlo en oraciones:
import requests as req import yandex_search import json apiurl = "https://api.vk.com/method/execute.getLastQuestion?access_token=VK_USER_TOKEN&v=5.5" clever_response = (json.loads(req.get(apiurl).content))["response"]
Paso 3. Buscando respuestas
Inicialmente, la tarea de reconocer con precisión la respuesta según los fragmentos me parecía poco realista (le recuerdo que al momento de escribir el código era un principiante absoluto). Por lo tanto, decidí simplificar primero la tarea que realizamos con una búsqueda manual.
¿Qué hicimos mis amigos y yo cuando dirigimos nuestra pregunta a un motor de búsqueda? Comenzaron a buscar rápidamente a través de los ojos las respuestas en los resultados. ¿Cuál es el problema con este enfoque? En
las letras múltiples, hay una gran cantidad de innecesarias, que no contienen información sobre respuestas, propuestas. Buscar con mis ojos a veces tomaba mucho tiempo. Por lo tanto, lo primero que decidí hacer fue seleccionar todas las oraciones con una mención de cualquiera de las respuestas y mostrarlas para buscar la respuesta en un texto muy pequeño que contenga con precisión la información que necesitamos.
hint = []
Parece que obtienes las ofertas correctas, las lees y respondes correctamente. ¿Pero qué pasa si no encontramos una sola oración? En este caso, decidí recortar las palabras para no perderlas si están en otro caso. Y también para capturar los que se forman a partir de la fuente. En resumen, acabo de recortar su final en dos caracteres:
if len(hint) == 0: def cut(string): if len(string) > 2: return string[0:-2] else: return string short_ans1, short_ans2, short_ans3 = cut(ans1), cut(ans2), cut(ans3) for pred in itemslist:
Pero incluso después de dicha red de seguridad, todavía hubo casos en que la pista permaneció vacía, simplemente porque los resultados no siempre tocaban las respuestas. Diga, a la pregunta
"¿Cuál de estos escritores tiene una historia, llamada así como la canción del grupo Bi 2?" No se puede encontrar una respuesta exacta. En este caso, recurrí al enfoque opuesto: pregunté sobre las respuestas y deduje la opción en función de la frecuencia con que se mencionan las palabras de la pregunta en los resultados.
if len(hint) == 0: questionlist = question.split(" ") blacklist = ["", "", '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', ''] for w in questionlist: if w in blacklist: questionlist.remove(w) yandex_ans1 = yandexfind(ans1) yandex_ans2 = yandexfind(ans2) yandex_ans3 = yandexfind(ans3)
En este punto, el script ganó funcionalidad básica. Y ahora, solo una semana y media después del lanzamiento de Clover, estamos sentados y ya jugando con un "truco" hecho a sí mismo. ¡Deberías haber visto nuestras caras con un amigo la primera vez que
ganamos el juego leyendo sugerencias en la línea de comando como por arte de magia!
Paso 4. Mostrar respuestas claras
Pero pronto este formato está cansado. Primero, tenías que sentarte con una computadora portátil cada juego. En segundo lugar, mis amigos pidieron el script, y estoy cansado de explicar a todos cómo insertar su token VKontakte, cómo configurar Yandex.XML (está vinculado a IP, es decir, era necesario crear una cuenta para cada usuario del script) y cómo instalar Python en la computadora.
¡Sería mucho mejor si las respuestas aparecen en notificaciones automáticas en el teléfono durante el juego! ¡Solo miré la parte superior de la pantalla y respondí como está escrito en la notificación push! ¡Y puede organizar esto para todos si crea su canal de telegramas para el guión! Maravilloso!
Pero simplemente mostrar las mismas oraciones en telegramas no es una opción. Leerlos desde su teléfono es extremadamente inconveniente. Por lo tanto, tuve que aprender el guión yo mismo para comprender qué respuesta es correcta.
Importamos
telebot y cambiamos todas
las funciones
print () a
send_tg () y
notsure () , que usaremos en el último método, ya que falla un poco más a menudo que otros:
def send_tg(ans): bot.send_message("@autoclever", str(ans).capitalize()) print(str(ans)) return def notsure(ans): send_tg(ans.capitalize() + ". !") hint.append("WE TRIED!")
¡Y en ese momento, me di cuenta de que los fragmentos son mucho mejores que los textos largos! Debido a que el motor de búsqueda está tratando de
dar una respuesta a nuestra solicitud, y no solo para encontrar coincidencias en palabras. Y tiene éxito: los fragmentos a menudo contenían las respuestas correctas que las incorrectas, es decir, no había necesidad de analizar el texto. Y yo, de hecho, no sabía cómo.
Así que somos simples para contar la mención de palabras en los resultados:
anscounts = { ans1: 0, ans2: 0, ans3: 0 } for s in hint: for a in [ans1, ans2, ans3]: anscounts[a] += s.count(a) right = (max(anscounts, key=anscounts.get)) send_tg(right)
Lo que sucedió como resultado:

Más destino
Para ser justos, debo decir que no tuve éxito en la máquina de la muerte. En promedio, el bot respondió correctamente solo 9-10 de las 12 preguntas. Es comprensible, porque hubo personas difíciles que no sucumbieron al análisis de la búsqueda de Yandex. Yo y mis amigos nos cansamos de pasar constantemente por encima de un par de preguntas y esperar un juego exitoso, en el que el robot finalmente responderá todo correctamente. No ocurrió un milagro, ya no quería modificar el guión y, después de haber dejado de esperar una victoria fácil, abandonamos el juego.
Con el tiempo, mi idea comenzó a aparecer en la cabeza de otros jóvenes desarrolladores. Para la puesta de sol de 2018, había al menos 10 bots y sitios que mostraban sus conjeturas sobre problemas en Clover. La tarea no es tan difícil. Pero lo que es sorprendente, ninguno de ellos ha cruzado la barra de 9-10 preguntas por juego, y luego todos cayeron a 7-8, como mi bot. Aparentemente, los compiladores de las preguntas dejaron en claro cómo componer las preguntas para que el trabajo de los motores de búsqueda fuera irrelevante.
Desafortunadamente, el bot ya no se puede finalizar, porque el 31 de diciembre Clover pasó la última transmisión y no tenía ninguna pregunta. Sin embargo, fue una gran experiencia para un programador novato. Y seguramente habría un gran desafío para el avanzado: solo imagine el dúo word2vec y text2vec, solicitudes asincrónicas a Yandex, Google y Wikipedia al mismo tiempo, un clasificador avanzado de preguntas y un algoritmo para reformular la pregunta en caso de falla ... ¡Eh! Tal vez, por tales oportunidades, me encantó este juego más que por el juego en sí.