OSGI no es difícil
Me he encontrado muchas veces que OSGI es difícil. Y además, él mismo tuvo una vez esa opinión. Año en 2009, para ser exactos. En ese momento, recopilamos proyectos utilizando Maven Tycho y los implementamos en Equinox. Y realmente fue más difícil que desarrollar y ensamblar proyectos para JavaEE (en ese momento apareció la versión de EJB 3, a la que cambiamos). Equinox era mucho menos conveniente que Weblogic, por ejemplo, y los beneficios de OSGI no eran obvios para mí en ese momento.
Pero luego, después de muchos años, tuve que comenzar un proyecto en un nuevo trabajo, que fue concebido sobre la base de Apache Camel y Apache Karaf. Esta no fue mi idea, conocía a Camel por mucho tiempo y decidí leer sobre Karaf, incluso sin una oferta. Lo leí una noche y me di cuenta: aquí está, simple y listo, casi la misma solución para algunos problemas de un JavaEE típico, similar al que hice una vez sobre mis rodillas usando Weblogic WLST, Jython y Maven Aether.
Entonces, digamos que decides probar OSGI en la plataforma Karaf. Por donde empezamos
Si quieres una comprensión más profunda
Por supuesto, puede comenzar leyendo la documentación. Y es posible con Habré: hubo muy buenos artículos aquí, digamos
hace mucho tiempo. Pero en general, karaf recibió hasta ahora poca atención inmerecida. Hubo un par de críticas más sobre
esto o
esto . Es mejor omitir
esta mención de karaf. Como dicen, no lean los periódicos soviéticos por la noche ... porque allí les dirán que karaf es un marco OSGI, por lo que no lo creen. Los marcos OSGI son Apache Felix o Eclipse Equinox, sobre la base de los cuales karaf simplemente funciona. Puedes elegir cualquiera de ellos.
Cabe señalar que cuando se menciona Jboss Fuse o Apache ServiceMix, debe leerse como "Karaf, con componentes preinstalados", es decir de hecho, lo mismo, solo recolectado por el vendedor. No recomendaría comenzar con esto en la práctica, pero es bastante posible leer artículos de revisión sobre ServiceMix, por ejemplo.
Para comenzar, intentaré determinar aquí muy brevemente qué es OSGI y para qué se puede utilizar.
En general, OSGI es una herramienta para crear aplicaciones Java a partir de módulos. Se puede considerar un análogo cercano, por ejemplo, JavaEE, y hasta cierto punto los contenedores OSGI pueden ejecutar módulos JavaEE (por ejemplo, aplicaciones web en forma de guerra), y por otro lado, muchos contenedores JavaEE contienen OSGI en su interior como un medio para implementar modularidad "por sí mismos ". Es decir, JavaEE y OSGI son cosas similares a la compatibilidad, y exitosamente complementarias.
Una parte importante de cualquier sistema modular es la definición del módulo en sí. En el caso de OSGI, el módulo se llama paquete y es un archivo jar conocido por todos los desarrolladores con algunas adiciones (es decir, aquí es muy similar, por ejemplo, a war u ear). Por analogía con JavaEE, los paquetes pueden exportar e importar servicios, que son esencialmente métodos de clase (es decir, un servicio es una interfaz o todos los métodos públicos de una clase).
Los metadatos del paquete son familiares para todos los META-INF / MANIFEST.MF. Los encabezados del manifiesto OSGI no se cruzan con los encabezados para el JRE, respectivamente, fuera del paquete contenedor OSGI hay un contenedor normal. Es significativo que entre los metadatos siempre haya:
Bundle-SymbolicName: com.example.myosgi Bundle-Version: 1.0.0
Estas son las "coordenadas" del paquete y es importante el hecho de que podamos tener dos o más versiones instaladas simultáneamente y funcionando del mismo paquete en un contenedor.
Similar a JavaEE, los paquetes tienen un ciclo de vida similar al siguiente:
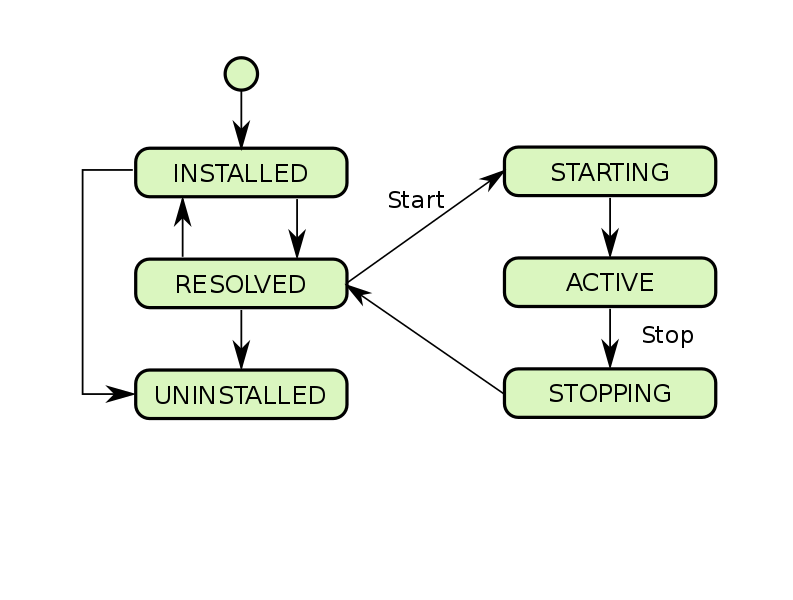
Además de los servicios, los paquetes también pueden importar y exportar paquetes (paquetes, en el sentido habitual del término para java). Los paquetes exportados se definen dentro del paquete y están disponibles para otros componentes cuando el paquete se instala en el sistema. Los importados se definen en algún lugar desde afuera, deben ser exportados por alguien y el contenedor los debe proporcionar al paquete antes de que pueda comenzar a funcionar.
Las importaciones de paquetes pueden declararse opcionales, así como las importaciones de servicios. Y es bastante significativo que la importación y exportación contenga una indicación de la versión (o rango de versiones).
Diferencias de JavaEE
Bueno, es bueno que sean iguales, lo entendimos. ¿Y en qué se diferencian?
En mi opinión, la principal diferencia es que OSGI nos da mucha más flexibilidad. Una vez que el paquete está en estado INICIADO, las posibilidades están limitadas solo por su imaginación. Supongamos que puede crear fácilmente subprocesos (sí, sí, sé sobre ManagedExecutorService), grupos de conexión a bases de datos, etc. Un contenedor no toma el control de todos los recursos en la misma medida que JavaEE.
Puede exportar nuevos servicios en el proceso. ¿Intenta decir en JavaEE crear dinámicamente un nuevo servlet? Y aquí es bastante posible, además, el servlet contenedor creado por el embarcadero karaf será detectado inmediatamente por su servlet creado y estará disponible para los clientes en una URL específica.
Aunque esto es una ligera simplificación, pero si la aplicación JavaEE en su forma clásica consta principalmente de componentes:
- pasivo, esperando una llamada del cliente
- definido estáticamente, es decir, en el momento del despliegue de la aplicación.
Por otro lado, una aplicación basada en OSGI puede contener:
- componentes programados activos y pasivos, realizar encuestas, bueno, escuchar un socket, etc.
- los servicios se pueden definir y publicar dinámicamente
- Puede suscribirse a eventos marco, por ejemplo, escuchar el registro de servicios, paquetes, etc., recibir enlaces a otros paquetes y servicios, y hacer mucho más.
Sí, en JavaEE, gran parte de esto también es parcialmente posible (por ejemplo, a través de JNDI), pero en el caso de OSGI, en la práctica se hace más fácil. Aunque probablemente haya algunos riesgos más aquí.
Diferencias entre karaf y OSGI puro
Además del marco karaf, hay muchas cosas útiles. En esencia, karaf es una herramienta para administrar convenientemente el marco OSGI: instalar paquetes (incluidos grupos) allí, configurarlos, monitorear, describir el modelo a seguir y garantizar la seguridad, y similares.
¿Y practiquemos ya?
Bueno, entonces, comencemos de inmediato con la instalación. No hay mucho que escribir aquí: vaya a karaf.apache.org, descargue el paquete de distribución, descomprímalo. Las versiones de karaf difieren en el soporte de diferentes especificaciones OSGI (4, 5 o 6) y versiones de Java. No recomiendo la familia 2.x, pero aquí hay 3 (si tiene Java 8, como la mía), y se puede usar 4, aunque hoy solo se está desarrollando la familia 4.x (versión actual 4.2.2, es compatible con OSGI 6 y Java hasta 10).
Karaf funciona bien en Windows y Linux, todo lo que necesita para crear un servicio y ejecución automática está disponible. También se declara la compatibilidad con MacOS y muchos otros tipos de Unix.
Por lo general, puede iniciar karaf de inmediato si está en Internet. Si no es así, generalmente vale la pena arreglar el archivo de configuración, indicando dónde tiene repositorios maven. Por lo general, será un Nexus corporativo, o digamos Artifactory, a quien le guste qué. La configuración de karaf se encuentra en la carpeta etc. de la distribución. Los nombres de los archivos de configuración no son muy obvios, pero en este caso necesita el archivo org.ops4j.pax.url.mvn.cfg. El formato de este archivo es propiedades java.
Puede especificar el (los) repositorio (s) en el archivo de configuración en sí, enumerando la lista de URL en la configuración o simplemente mostrando dónde se encuentra su settings.xml. Allí, el karaf tomará la ubicación de su proxy, que generalmente es necesario saber en la intranet.
Kafar necesita varios puertos, estos son HTTP, HTTPS (si la web está configurada, por defecto no), SSH, RMI, JMX. Si están ocupados con usted o si desea ejecutar varias copias en el mismo host, también deberá cambiarlas. Hay aproximadamente cinco de estos puertos.
Puertos como jmx y rmi - aquí: org.apache.karaf.management.cfg, ssh - org.apache.karaf.shell.cfg, para cambiar los puertos http / https, deberá crear (probablemente no) el archivo etc / org.ops4j.pax.web.cfg, y escriba el valor org.osgi.service.http.port = port que necesita en él.
Entonces definitivamente puedes iniciarlo, y como regla, todo comenzará. Para uso industrial, obviamente, deberá realizar cambios en el archivo bin / setenv o bin / setenv.bat, por ejemplo, para asignar la cantidad de memoria requerida, pero primero, para ver, no es necesario.
Puede iniciar Karaf de inmediato con la consola, el comando karaf, o puede ejecutarlo en segundo plano con el comando de inicio del servidor y luego conectarse a él a través de SSH. Este es un SSH completamente estándar, con soporte para SCP y SFTP. Puede ejecutar comandos y copiar archivos de un lado a otro. Es posible conectarse con cualquier cliente, por ejemplo, mi herramienta favorita es Far NetBox. El inicio de sesión está disponible mediante inicio de sesión y contraseña, así como mediante claves. En menudillos jsch, con todo lo que implica.
Recomiendo tener una ventana de consola adicional de inmediato para ver los registros que se encuentran en data / log / karaf.log (y otros archivos generalmente están allí, aunque esto es personalizable). Los registros son útiles para usted, desde mensajes cortos en la consola, no todo está claro.
Aconsejaría instalar la web inmediatamente y la consola web hawtio. Estas dos cosas harán que sea mucho más fácil para usted navegar lo que está sucediendo en el contenedor y dirigir el proceso desde allí en gran medida (como beneficio adicional, obtendrá jolokia y la capacidad de monitorear a través de http). La instalación de hawtio se realiza mediante dos comandos desde la consola karaf (
como se describe aquí ), y lamentablemente, hoy la versión de karaf 3.x ya no es compatible (tendrá que buscar versiones anteriores de hawtio).
Fuera de la caja, https no será inmediato, para esto debe hacer algunos esfuerzos, como generar certificados, etc. La implementación se basa en el embarcadero, por lo que todos estos esfuerzos se realizan principalmente de la misma manera.
OK, comenzó, ¿qué sigue?

En realidad, ¿qué esperabas? Dije que será ssh. Tab funciona, si eso.
Es hora de instalar alguna aplicación. Una aplicación para OSGI es un paquete o consta de varios paquetes. Karaf puede implementar aplicaciones en varios formatos:
- Un paquete jar, con o sin un manifiesto OSGI
- xml que contiene Spring DM o Blueprint
- XML que contiene la denominada característica, que es una colección de paquetes, otras características y recursos (archivos de configuración)
- Archivo .kar que contiene varias características y un repositorio maven con dependencias
- Aplicaciones JavaEE (bajo algunas condiciones adicionales), por ejemplo .war
Hay varias formas de hacer esto:
- poner la aplicación en la carpeta de implementación
- instalar desde la consola con el comando de instalación
- instale la función con el comando de la función: instalar la consola
- kar: instalar
Bueno, en general, esto es bastante similar a lo que puede hacer un contenedor JavaEE típico, pero es algo más conveniente (yo diría que es mucho más conveniente).
Tarro simple
La opción más fácil es instalar un jar regular. Si lo tiene en el repositorio maven, entonces el comando es suficiente para instalar:
install mvn:groupId/artifactId/version
Al mismo tiempo, Karaf se da cuenta de que tiene un frasco regular frente a él y lo procesa, creando un envoltorio de paquete sobre la marcha, el llamado wrapper, que genera un manifiesto predeterminado, con las importaciones y exportaciones de paquetes.
La sensación de instalar solo un jar generalmente no es mucha, ya que este paquete será pasivo: solo exporta clases que estarán disponibles para otros paquetes.
Este método se utiliza para instalar componentes como Apache Commons Lang, por ejemplo:
install mvn:org.apache.commons.lang3/commons-lang/3.8.1
Pero no funcionó :) Estas son las coordenadas correctas:
install mvn:org.apache.commons/commons-lang3/3.8.1
Veamos qué sucedió: list -u nos mostrará los paquetes y sus fuentes:
karaf@root()> list -u START LEVEL 100 , List Threshold: 50 ID | State | Lvl | Version | Name | Update location ------------------------------------------------------------------------------------------------- 87 | Installed | 80 | 3.8.1 | Apache Commons Lang | mvn:org.apache.commons/commons-lang3/3.8.1 88 | Installed | 80 | 3.6.0 | Apache Commons Lang | mvn:org.apache.commons/commons-lang3/3.6
Como puede ver, es bastante posible instalar dos versiones de un componente. Ubicación de actualización: aquí es donde obtuvimos el paquete y donde se puede actualizar si es necesario.
Contexto Jar y Spring
Si hay un contexto de primavera dentro de su frasco, las cosas se ponen más interesantes. Karaf Deployer busca automáticamente contextos xml en la carpeta META-INF / spring, y los crea si todos los paquetes externos necesarios para el paquete se han encontrado con éxito.
Por lo tanto, todos los servicios que estaban dentro de los contextos ya comenzarán. Si tenía Camel Spring allí, por ejemplo, las rutas Camel también comenzarán. Esto significa que decimos que un servicio REST, o un servicio que escucha en un puerto TCP, ya puede comenzar. Por supuesto, el lanzamiento de varios servicios de escucha en un puerto no funcionará de esa manera.
Just Spring contexto XML
Si tenía, por ejemplo, definiciones de JDBC DataSources dentro de Spring Context, puede instalarlas por separado en Karaf. Es decir tome un archivo xml que contenga solo un DataSource en forma de <bean>, o cualquier otro conjunto de componentes, puede colocarlo en la carpeta de implementación. El contexto se lanzará de la manera estándar. El único problema es que los DataSources creados de esta manera no serán visibles para otros paquetes. Deben exportarse a OSGI como servicios. Sobre esto, un poco más tarde.
Primavera dm
¿Cuál es la diferencia entre Spring DM (versión habilitada para OSGI) y el clásico Spring? Entonces, en el caso clásico, todos los beans en el contexto se crean en la etapa de inicialización del contexto. Los nuevos no pueden aparecer, los viejos no irán a ninguna parte. En el caso de OSGI, se pueden instalar nuevos paquetes y eliminar paquetes viejos. El entorno se está volviendo más dinámico, debe responder de alguna manera.
El método de respuesta se llama servicios. Un servicio suele ser una interfaz determinada, con sus propios métodos, que es publicada por algún paquete. Un servicio tiene metadatos que permiten buscarlo y distinguirlo de otro servicio que implementa una interfaz similar (obviamente, de otro DataSource). Los metadatos son un conjunto simple de propiedades clave-valor.
Dado que los servicios pueden aparecer y desaparecer, aquellos que los necesitan pueden suscribirse a los servicios al inicio o escuchar eventos para conocer su aparición o desaparición. En el nivel Spring DM, en XML, esto se implementa como dos elementos, servicio y referencia, cuyo propósito básico es bastante simple: publicar el bean existente desde el contexto como un servicio, y suscribirse a un servicio externo al publicarlo en el contexto actual de Spring.
En consecuencia, al inicializar dicho paquete, el contenedor encontrará los servicios externos que necesita y publicará los paquetes implementados dentro de él, haciéndolos accesibles desde el exterior. Un paquete comienza solo después de que se resuelven los enlaces de servicio.
De hecho, todo es un poco más complicado, porque el paquete puede usar una lista de servicios similares y suscribirse de inmediato a la lista. Es decir un servicio, en general, tiene una propiedad como cardinalidad, que toma el valor 0..N. En este caso, la suscripción, donde se indica 0..1, describe un servicio opcional, y en este caso el paquete se inicia con éxito incluso si no hay tal servicio en el sistema (y en lugar de un enlace, obtendrá un código auxiliar).
Observo que un servicio es solo cualquier interfaz (o puede publicar solo clases), por lo que puede publicar java.util.Map con datos como servicio.
Entre otras cosas, el servicio le permite especificar metadatos, y la referencia le permite buscar un servicio por estos metadatos.
Anteproyecto
Blueprint es la nueva encarnación de Spring DM, que es un poco más simple. Es decir, si en Spring tiene elementos XML personalizados, entonces no están aquí, por innecesarios. A veces esto todavía causa inconvenientes, pero, francamente, con poca frecuencia. Si no está migrando un proyecto desde Spring, puede comenzar de inmediato con Blueprint.
La esencia aquí es la misma: es XML, que describe los componentes a partir de los cuales se ensambla el contexto del paquete. Para aquellos que conocen Spring, no hay nada desconocido en absoluto.
Aquí hay un ejemplo de cómo describir un DataSource y exportarlo como un servicio:
<?xml version="1.0" encoding="UTF-8"?> <blueprint xmlns="http://www.osgi.org/xmlns/blueprint/v1.0.0"> <bean id="dataSource" class="oracle.jdbc.pool.OracleDataSource"> <property name="URL" value="URL"/> <property name="user" value="USER"/> <property name="password" value="PASSWORD"/> </bean> <service interface="javax.sql.DataSource" ref="dataSource" id="ds"> <service-properties> <entry key="osgi.jndi.service.name" value="jdbc/ds"/> </service-properties> </service> </blueprint>
Bueno, implementamos este archivo en la carpeta de implementación y observamos los resultados del comando de lista. Vieron que el paquete no comenzó, en el estado Instalado. Intentamos iniciar y recibimos un mensaje de error.
Ahora en la lista de paquetes en el estado Error. Que pasa Obviamente, también necesita dependencias, en este caso, un Jar con clases JDBC de Oracle, o más precisamente, el paquete oracle.jdbc.pool.
Encontramos el jar necesario en el repositorio, o lo descargamos del sitio de Oracle, y lo instalamos, como se describió anteriormente. Nuestro DataSource ha comenzado.
¿Cómo usar todo esto? El enlace de servicio se llama en la referencia Blueprint (en algún lugar, en el contexto de otro paquete):
<reference id="dataSource" interface="javax.sql.DataSource"/>
Luego, este bean se convierte, como de costumbre, en una dependencia para otros beans (en el ejemplo camel-sql):
<bean id="sql" class="org.apache.camel.component.sql.SqlComponent"> <property name="dataSource" ref="dataSource"/> </bean>
Jarra y Activador
La forma canónica de inicializar paquetes es usar una clase que implemente la interfaz Activador. Esta es una interfaz típica de ciclo de vida que contiene métodos de inicio y detención que pasan el
contexto . Dentro de ellos, el paquete generalmente inicia sus hilos, si es necesario, comienza a escuchar puertos, se suscribe a servicios externos utilizando la API OSGI, y así sucesivamente. Esta es quizás la forma más compleja, más básica y más flexible. Durante tres años nunca lo he necesitado.
Configuraciones y configuración
Está claro que tal configuración de DataSource, como se muestra en el ejemplo, pocas personas necesitan. Inicio de sesión, contraseña y más, todo está codificado en XML. Es necesario eliminar estos parámetros.
<property name="url" value="${oracle.ds.url}"/> <property name="user" value="${oracle.ds.user}"/> <property name="password" value="${oracle.ds.password}"/>
La solución es bastante simple y similar a la utilizada en el clásico Spring: en cierto punto del ciclo de vida del contexto, los valores de propiedad se sustituyen de varias fuentes.
Con esto terminaremos la primera parte. Si hay interés en este tema, entonces continuará. Consideraremos cómo ensamblar aplicaciones a partir de paquetes, configurar, monitorear e implementar sistemas automáticamente en esta plataforma.