
Cualquier proyecto cliente-servidor implica una separación clara de la base del código en 2 partes (a veces más): cliente y servidor. A menudo, cada parte de este tipo se ejecuta en forma de un proyecto independiente por separado, respaldado por su propio equipo de desarrolladores.
En este artículo, propongo una mirada crítica a la división estándar de código en un backend y un frontend. Y considere una alternativa donde el código no tiene una línea clara entre el cliente y el servidor.
Contras del enfoque estándar
La principal desventaja de la separación estándar del proyecto en 2 partes es la erosión de la lógica empresarial entre el cliente y el servidor. Editamos los datos en el formulario en el navegador, los verificamos en el código del cliente y los enviamos a la aldea del abuelo (al servidor). El servidor ya es otro proyecto. Allí, también debe verificar la exactitud de los datos recibidos (es decir, duplicar la funcionalidad del cliente), hacer algunas manipulaciones adicionales (guardar en la base de datos, enviar correos electrónicos, etc.).
Por lo tanto, para rastrear toda la ruta de información desde el formulario en el navegador hasta la base de datos en el servidor, tendremos que profundizar en dos sistemas diversos. Si los roles se dividen en un equipo y diferentes especialistas son responsables del backend y la interfaz, surgen problemas organizativos adicionales relacionados con su sincronización.
Soñemos
Supongamos que podemos describir la ruta de datos completa desde el formulario en el cliente hasta la base de datos en el servidor en un modelo. En el código, puede verse más o menos así (el código no funciona):
class MyDataModel {
Por lo tanto, toda la lógica de negocios del modelo está ante nuestros ojos. Mantener dicho código es más fácil. Estas son las ventajas que puede aportar la combinación de métodos cliente-servidor en un modelo:
- La lógica de negocios se concentra en un solo lugar, no es necesario compartirla entre el cliente y el servidor.
- Puede transferir fácilmente la funcionalidad de servidor a cliente o de cliente a servidor durante el desarrollo del proyecto.
- No es necesario duplicar los mismos métodos para el backend y el frontend.
- Un conjunto único de pruebas para toda la lógica de negocios del proyecto.
- Sustitución de líneas horizontales de delimitación de responsabilidad en el proyecto por verticales.
Revelaré el último punto con más detalle. Imagine una aplicación cliente-servidor normal en forma de dicho esquema:
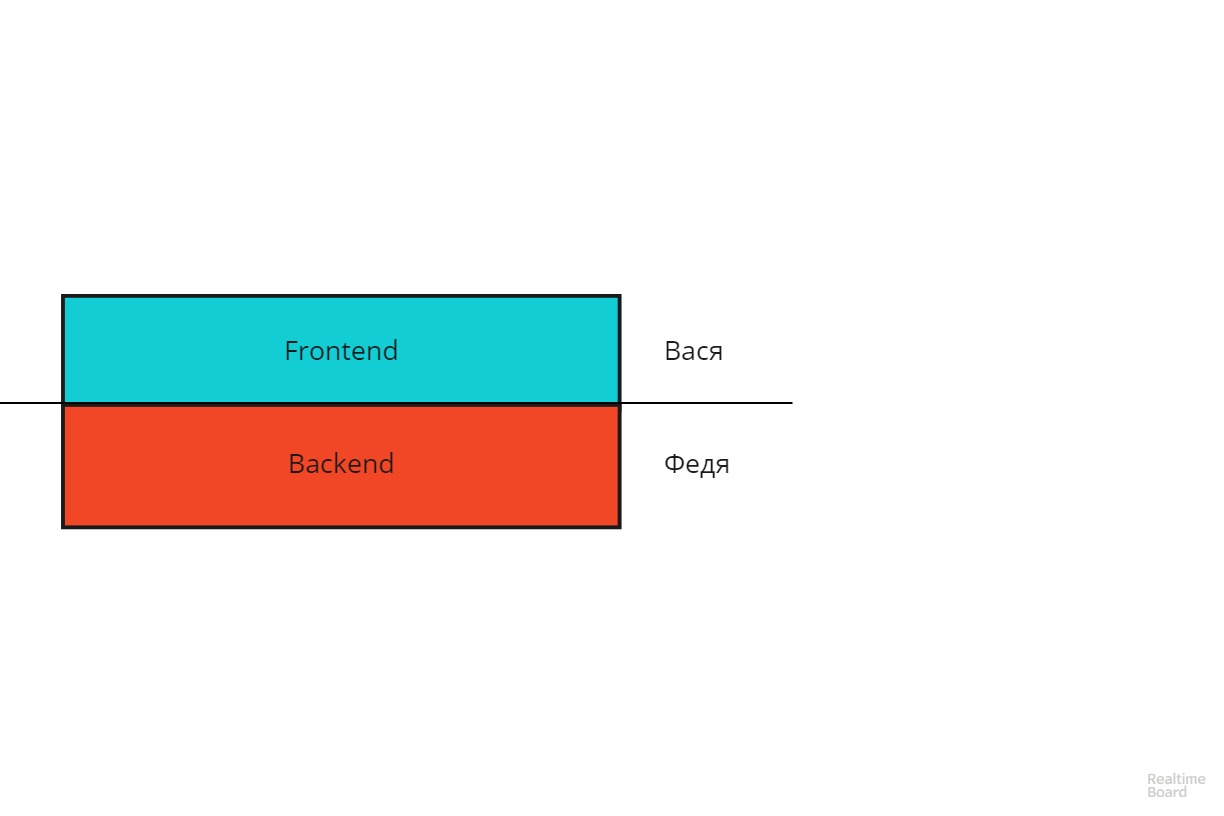
Vasya es responsable del frontend, Fedya, del backend. La línea de delimitación de responsabilidad corre horizontalmente. Este esquema tiene las desventajas de cualquier estructura vertical: es difícil de escalar y tiene baja tolerancia a fallas. Si el proyecto se está expandiendo, tendrá que tomar una decisión bastante difícil: ¿a quién fortalecer Vasya o Fedya? O si Fedya se enfermó o renunció, Vasya no podrá reemplazarlo.
El enfoque propuesto aquí le permite expandir la línea de división de responsabilidad en 90 grados y convertir la arquitectura vertical en horizontal.
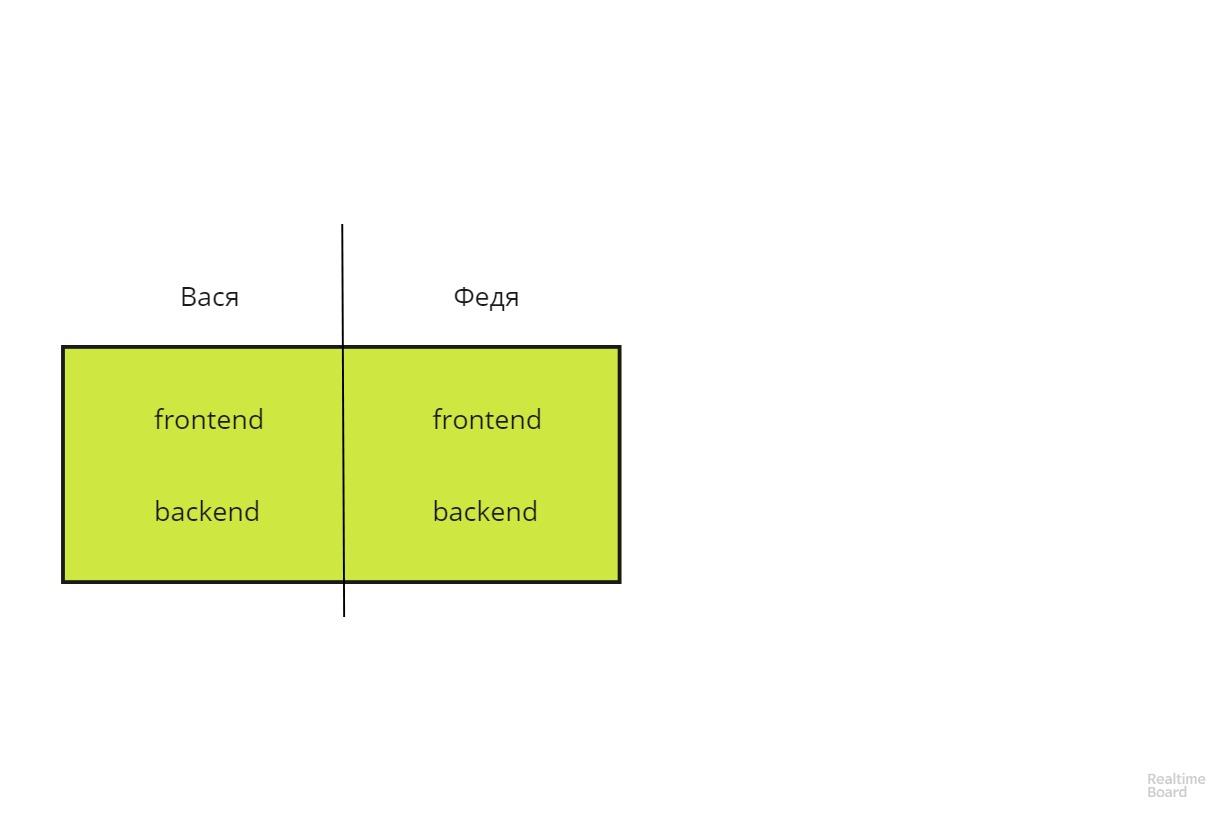
Tal arquitectura es mucho más fácil de escalar y más tolerante a fallas. Vasya y Fedya se vuelven intercambiables.
En teoría, se ve bien, intentemos implementar todo esto en la práctica, sin perder todo lo que nos da la existencia separada del cliente y el servidor en el camino.
Declaración del problema.
No es necesario que tengamos un servidor cliente integrado en el producto. Por el contrario, tal decisión sería extremadamente perjudicial desde todos los puntos de vista. La tarea es que en el proceso de desarrollo tendríamos una única base de código para los modelos de datos para el backend y la interfaz, pero la salida sería un cliente y servidor independientes. En este caso, obtendremos todas las ventajas del enfoque estándar y obtendremos los servicios enumerados anteriormente para el desarrollo y el soporte del proyecto.
Solución
He estado experimentando con la integración de cliente y servidor en un archivo durante bastante tiempo. Hasta hace poco, el principal problema era que en JS estándar, la conexión de módulos de terceros en el cliente y el servidor era demasiado diferente: requiere (...) en node.js, toda la magia de AJAX en el cliente. Todo ha cambiado con la llegada de los módulos ES. En los navegadores modernos, "importar" ha sido compatible durante mucho tiempo. Node.js está ligeramente retrasado en este aspecto y los módulos ES solo son compatibles con el indicador "--experimental-modules" habilitado. Se espera que en el futuro previsible, los módulos funcionen de forma inmediata en node.js. Además, es poco probable que algo cambie mucho, porque En los navegadores, esta funcionalidad ha estado funcionando por defecto durante mucho tiempo. Creo que ahora puede usar módulos ES no solo en el cliente sino también en el lado del servidor (si tiene contraargumentos sobre este tema, escriba los comentarios).
El esquema de solución se ve así:

El proyecto contiene tres catálogos principales:
protegido - backend;
público - frontend;
shared - modelos compartidos cliente-servidor.
Un proceso de observación independiente monitorea los archivos en el directorio compartido y, con cualquier cambio, crea versiones del archivo modificado por separado para el cliente y por separado para el servidor (en los directorios protegidos / compartidos y públicos / compartidos).
Implementación
Considere el ejemplo de un simple mensajero en tiempo real. Necesitaremos una nueva versión de node.js (tengo la versión 11.0.0) y Redis (instalarlos no está cubierto aquí).
Clonar un ejemplo:
git clone https://github.com/Kolbaskin/both-example cd ./both-example npm i
Instale y ejecute el proceso de observador (observador en el diagrama):
npm i both-js -g both ./index.mjs
Si todo está en orden, el observador iniciará el servidor web y comenzará a monitorear los cambios en los archivos en los directorios compartidos y protegidos. Cuando se realizan cambios en compartido, se crean las versiones correspondientes de los modelos de datos para el cliente y para el servidor. Tras los cambios a protegido, el observador reiniciará automáticamente el servidor web.
Puede ver el rendimiento del mensajero en el navegador haciendo clic en el enlace
http://localhost:3000/index.html?token=123&user=Vasya(el token y el usuario son arbitrarios). Para emular múltiples usuarios, abra la misma página en otro navegador especificando diferentes tokens y usuarios.
Ahora un pequeño código.
Servidor web
protegido / server.mjs
import express from 'express'; import bodyParser from 'body-parser';
Este es un servidor express regular, no hay nada interesante aquí. La extensión mjs es necesaria para los módulos ES en node.js. Por coherencia, utilizaremos esta extensión para el cliente.
Cliente
public / index.html
<!DOCTYPE html> <html lang="en"> <head> ... <script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script> <script src="/main.mjs" type="module"></script> </head> <body> ... <ul id="users"> <li v-for="user in users"> {{ user.name }} ({{user.id}}) </li> </ul> <div id="messages"> <div> <input type="text" v-model="msg" /> <button v-on:click="sendMessage()"></button> </div> <ul> <li v-for="message in messages">[{{ message.date }}] <strong>{{ message.text }}</strong></li> </ul> </div> </body> </html>
Por ejemplo, uso Vue en el cliente, pero esto no cambia la esencia. En lugar de Vue, puede haber cualquier cosa en la que pueda separar el modelo de datos en una clase separada (knockout, angular).
public / main.mjs
main.mjs es un script que asocia modelos de datos con vistas correspondientes. Para simplificar el código, las representaciones de muestra para la lista de usuarios activos y feeds de mensajes se integran directamente en index.html
Modelo de datos
shared / messages / model / dataModel.mjs
Estos diversos métodos implementan toda la funcionalidad de enviar y recibir mensajes en tiempo real. Las directivas! #Client y! #Server le indican al proceso del observador qué método para qué parte (cliente o servidor) está destinado. Si no existen estas directivas antes de definir un método, dicho método está disponible tanto en el cliente como en el servidor. Las barras inclinadas de comentarios antes de la directiva son opcionales y existen solo para evitar que el IDE estándar insista en errores de sintaxis.
La primera línea de la ruta utiliza la búsqueda & root. Al generar las versiones de cliente y servidor, & root se reemplazará con la ruta relativa a los directorios públicos y protegidos, respectivamente.
Otro punto importante: desde el método del cliente, puede llamar solo al método del servidor, cuyo nombre comienza con "$":
...
Esto se hace por razones de seguridad: desde el exterior solo puede recurrir a métodos especialmente diseñados para esto.
Veamos las versiones de los modelos de datos que el observador generó para el cliente y el servidor.
Cliente (public / shared / messages / model / dataModel.mjs)
import Base from '/lib/Base.mjs'; export default class dataModel extends Base { __getFilePath__() {return "messages/model/dataModel.mjs"}
En el lado del cliente, el modelo es un descendiente de la clase Vue (a través de Base.mjs). Por lo tanto, puede trabajar con él como con un modelo de datos Vue normal. El observador agregó el método __getFilePath__ a la versión del cliente del modelo, que devuelve la ruta al archivo de clase y reemplazó el código del método del servidor $ sendMessage con una construcción que, en esencia, llamará al método que necesitamos en el servidor a través del mecanismo rpc (__runSharedFunction se define en la clase principal).
Servidor (protegido / compartido / mensajes / modelo / dataModel.mjs)
import Base from '../../lib/Base.mjs'; export default class dataModel extends Base { __getFilePath__() {return "messages/model/dataModel.mjs"} ... ...
¡En la versión del servidor, también se agregó el método __getFilePath__ y se eliminaron los métodos del cliente marcados con la directiva!
En ambas versiones generadas del modelo, todas las filas eliminadas se reemplazan por vacías. Esto se hace para que el mensaje de error en el depurador pueda encontrar fácilmente la línea problemática en el código fuente del modelo.
Interacción cliente-servidor
Cuando necesitamos llamar a algún método de servidor en el cliente, simplemente lo hacemos.
Si la llamada está dentro del mismo modelo, entonces todo es simple:
... !#client async sendMessage(e) { await this.$sendMessage(this.msg); this.msg = ''; } !#server async $sendMessage(msg) {
Puede "tirar" de otro modelo:
import dataModel from "/shared/messages/model/dataModel.mjs"; var msg = new dataModel(); msg.$sendMessage('blah-blah-blah');
En la dirección opuesta, es decir Llamar a algún método de cliente en el servidor no funciona. Técnicamente, esto es factible, pero desde un punto de vista práctico no tiene sentido, porque el servidor es uno, pero hay muchos clientes. Si necesitamos iniciar algunas acciones en el servidor en el cliente, usamos el mecanismo de eventos:
El método fireEvent toma 3 parámetros: el nombre del evento, a quién se dirige y los datos. Puede configurar el destinatario de varias maneras: palabra clave "todos": el evento se enviará a todos los usuarios o en la matriz para enumerar los tokens de sesión de los clientes a los que se dirige el evento.
El evento no está vinculado a una instancia específica de la clase de modelo de datos y los controladores se activarán en todas las instancias de la clase en la que se llamó a fireEvent.
Escalado horizontal del backend
La monoliticidad de los modelos cliente-servidor en la implementación propuesta, a primera vista, debería imponer restricciones significativas sobre la posibilidad de escalado horizontal de la parte del servidor. Pero esto no es así: técnicamente, el servidor no depende del cliente. Puede copiar el directorio "público" en cualquier lugar y dar su contenido a través de cualquier otro servidor web (nginx, apache, etc.).
El lado del servidor se puede ampliar fácilmente mediante el lanzamiento de nuevas instancias de back-end. Redis y el sistema de colas Kue se utilizan para interactuar con instancias individuales.
API y diferentes clientes para un backend
En proyectos reales, diversos clientes de servidores pueden usar una API de servidor: sitios web, aplicaciones móviles, servicios de terceros. En la solución propuesta, todo esto está disponible sin ningún baile adicional. Bajo el capó de llamar a los métodos del servidor está el viejo y bueno rpc. El servidor web en sí es una aplicación express clásica. Es suficiente agregar un contenedor allí para las rutas con la llamada a los métodos necesarios de los mismos modelos de datos.
Post scriptum
El enfoque propuesto en el artículo no pretende cambios revolucionarios en las aplicaciones cliente-servidor. Solo agrega un poco de comodidad al proceso de desarrollo, lo que le permite centrarse en la lógica empresarial reunida en un solo lugar.
Este proyecto es experimental, escriba en los comentarios si, en su opinión, vale la pena continuar este experimento.