A velocidades de más de mil millones de cuadros por segundo, este es posiblemente el grupo de consolas de 8 bits más rápido del mundo.
 Tetris distribuido (1989)
Tetris distribuido (1989)¿Cómo construir una computadora así?
La receta
Tome un puñado de silicio, aplique entrenamiento de refuerzo, experimente con supercomputadoras, una pasión por la arquitectura de computadoras, agregue sudor y lágrimas, agite 1000 horas hasta que hierva, y listo.
¿Por qué alguien necesitaría una computadora así?
En resumen: avanzar hacia la mejora de la inteligencia artificial.
 Una de las 48 placas de computadoras neuronales de IBM utilizadas para experimentos
Una de las 48 placas de computadoras neuronales de IBM utilizadas para experimentosY aquí hay una versión más detallada.
2016 año. El aprendizaje profundo es omnipresente. El reconocimiento de imágenes se puede considerar una tarea resuelta gracias a las redes neuronales convolucionales, y mis intereses de investigación buscan redes neuronales con memoria y aprendizaje reforzado.
Específicamente, en el trabajo de autoría de Google Deepmind se demostró que es posible alcanzar el nivel de una persona o incluso superarlo en varios juegos para la Atari 2600 (consola de juegos doméstica, lanzada en 1977), utilizando un algoritmo de aprendizaje simple compatible con Deep Q-Neural Network. Y todo esto sucede simplemente al ver el juego. Me llamó la atención.
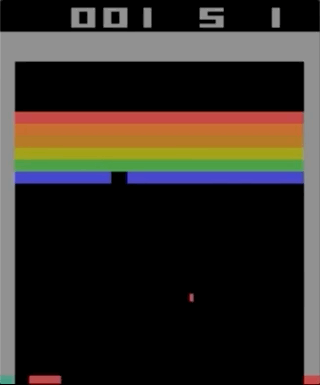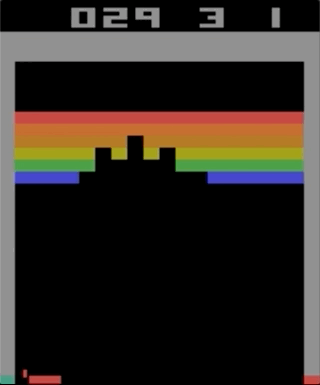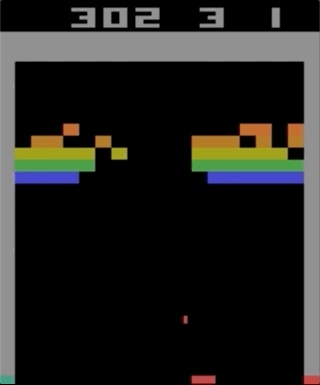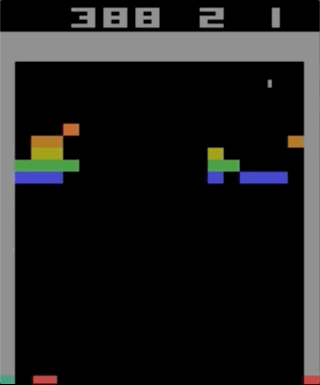 Uno de los juegos con el Atari 2600, Breakout. La máquina fue entrenada usando un algoritmo de aprendizaje de refuerzo simple. Después de millones de iteraciones, la computadora comenzó a jugar mejor que los humanos.
Uno de los juegos con el Atari 2600, Breakout. La máquina fue entrenada usando un algoritmo de aprendizaje de refuerzo simple. Después de millones de iteraciones, la computadora comenzó a jugar mejor que los humanos.Comencé a experimentar con los juegos de Atari 2600. Breakout, aunque impresionante, no se puede llamar complicado. La dificultad puede determinarse por el grado de dificultad de acuerdo con sus acciones (joystick) y sus resultados (puntos). El problema aparece cuando el efecto necesita esperar mucho tiempo.
 Ilustración de un problema usando juegos más complejos como ejemplo. Izquierda - Breakout (ATARI 2600) [el autor se equivocó, este es un juego de Pong / aprox. trans.] con una respuesta muy rápida y retroalimentación rápida. Derecha: Mario Land (Nintendo Game Boy) no proporciona información instantánea sobre los efectos de la acción; pueden aparecer largos períodos de observaciones irrelevantes entre dos eventos importantes.
Ilustración de un problema usando juegos más complejos como ejemplo. Izquierda - Breakout (ATARI 2600) [el autor se equivocó, este es un juego de Pong / aprox. trans.] con una respuesta muy rápida y retroalimentación rápida. Derecha: Mario Land (Nintendo Game Boy) no proporciona información instantánea sobre los efectos de la acción; pueden aparecer largos períodos de observaciones irrelevantes entre dos eventos importantes.Para que el aprendizaje sea más efectivo, uno puede imaginar intentos de transferir parte del conocimiento de juegos más simples. Esta tarea ahora permanece sin resolver y es un tema activo para la investigación. Una
tarea recientemente publicada de OpenAI está tratando de medir precisamente eso.
La capacidad de transferir conocimiento no solo aceleraría la capacitación, creo que algunos problemas de aprendizaje no pueden resolverse en absoluto en ausencia de conocimiento básico. Necesitamos eficiencia de datos. Toma el juego Prince of Persia:

No hay puntos obvios en ello.
Tarda 60 minutos en completar el juego.

¿Es posible aplicar el mismo enfoque que se usó al escribir el trabajo en el Atari 2600? ¿Qué tan probable es que puedas llegar al final presionando teclas aleatorias?
Esta pregunta me llevó a contribuir a la comunidad, que consiste en tratar de resolver este problema. De hecho, tenemos la tarea de la gallina y los huevos: necesitamos un mejor algoritmo que nos permita transmitir un mensaje, sin embargo, esto requiere investigación, y los experimentos llevan mucho tiempo, ya que no tenemos un algoritmo más eficiente.
 Un ejemplo de transferencia de conocimiento: imagine que primero aprendimos a jugar un juego simple, como el de la izquierda. Luego guardamos conceptos como "carrera", "auto", "pista", "ganar" y aprender colores o modelos tridimensionales. Argumentamos que los conceptos comunes pueden ser "transferidos" entre juegos. La similitud de los juegos puede determinarse por el número de conocimientos transferidos entre ellos. Por ejemplo, los juegos Tetris y F1 no serán similares.
Un ejemplo de transferencia de conocimiento: imagine que primero aprendimos a jugar un juego simple, como el de la izquierda. Luego guardamos conceptos como "carrera", "auto", "pista", "ganar" y aprender colores o modelos tridimensionales. Argumentamos que los conceptos comunes pueden ser "transferidos" entre juegos. La similitud de los juegos puede determinarse por el número de conocimientos transferidos entre ellos. Por ejemplo, los juegos Tetris y F1 no serán similares.Por lo tanto, decidí usar el segundo enfoque ideal, evitando la desaceleración inicial, acelerando drásticamente el sistema. Mis metas fueron:
- entorno acelerado (imagina que Prince of Persia se puede completar 100 veces más rápido) y el lanzamiento simultáneo de 100,000 juegos.
- un entorno más adecuado para la investigación (nos concentramos en tareas, pero no en cálculos preliminares, tenemos acceso a varios juegos).
Inicialmente, pensé que el cuello de botella de rendimiento podría depender de alguna manera de la complejidad del código del emulador (por ejemplo, la base del código de Stella es grande y se basa en abstracciones de C ++, no es la mejor opción para los emuladores).
Consolas

En total, trabajé en varias plataformas, comenzando con uno de los primeros juegos creados (junto con el juego Pong): Arcade Space Invaders, Atari 2600, NES y Game Boy. Y todo esto fue escrito en C.
Logré alcanzar una velocidad de fotogramas máxima de 2000-3000 por segundo. Para comenzar a obtener los resultados de los experimentos, necesitamos millones o miles de millones de marcos, por lo que la brecha era enorme.
 Space Invaders trabajando en FPGA - modo de depuración a baja velocidad. El contador FPGA muestra el número de ciclos de reloj que han pasado.
Space Invaders trabajando en FPGA - modo de depuración a baja velocidad. El contador FPGA muestra el número de ciclos de reloj que han pasado.Y luego pensé: ¿qué pasaría si pudiéramos acelerar el entorno adecuado con hierro? Por ejemplo, los Space Invaders originales fueron a la CPU 8080 con una frecuencia de 1 MHz. Logré emular una CPU 8080 de 40 MHz en un procesador Xeon de 3 GHz. No está mal, pero después de poner todo esto dentro del FPGA, la frecuencia subió a 400 MHz. Eso significó 24,000 FPS de una transmisión, ¡el equivalente a un Xeon de 30 GHz! ¿Mencioné que puedes meter 100 procesadores 8080 en un FPGA promedio? Esto ya produce 2.4 millones de FPS.
 Space Invaders con aceleración de hardware de 100 MHz, un cuarto de la velocidad máxima
Space Invaders con aceleración de hardware de 100 MHz, un cuarto de la velocidad máxima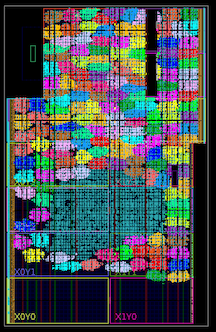 Más de cien núcleos dentro del Xilinx Kintex 7045 FPGA (indicado por colores brillantes; el punto azul en el medio es la lógica general para la demostración).
Más de cien núcleos dentro del Xilinx Kintex 7045 FPGA (indicado por colores brillantes; el punto azul en el medio es la lógica general para la demostración). Ruta de ejecución desigual
Ruta de ejecución desigualUsted puede preguntar, ¿qué pasa con la GPU? En resumen, necesitamos concurrencia como
MIMD , no
SIMD . Como estudiante, trabajé durante algún tiempo en la
implementación de una búsqueda de árbol de Monte Carlo en una GPU (dicha búsqueda se utilizó en AlphaGo).
En ese momento, pasé innumerables horas tratando de hacer que la GPU y otras piezas de hardware funcionaran según el principio de SIMD (IBM Cell, Xeon Phi, AVX CPU) para ejecutar dicho código, y no surgió nada. Hace unos años, comencé a pensar que sería bueno poder desarrollar de forma independiente hardware específicamente diseñado para resolver problemas relacionados con el entrenamiento de refuerzo.
 Concurrencia MIMD
Concurrencia MIMD¿ATARI 2600, NES o Game Boy?
En 8080, implementé Space Invaders, NES, 2600 y Game Boy. Y aquí hay algunos datos sobre ellos y los beneficios de cada uno de ellos.
 NES Pacman
NES PacmanLos Space Invaders fueron solo un calentamiento. Logramos que funcionen, pero fue solo un juego, por lo que el resultado no fue muy útil.
El Atari 2600 es en realidad el estándar en la investigación de aprendizaje por refuerzo. El procesador MOS 6507 es una versión simplificada del famoso 6502, su diseño es más elegante y más eficiente que el del 8080. Elegí 2600 no solo por ciertas restricciones relacionadas con los juegos y sus gráficos.
También implementé NES (Nintendo Entertainment System), comparte la CPU con 2600. Hay juegos que son mucho mejores que 2600. Pero ambas consolas tienen una canalización de procesamiento de gráficos demasiado compleja y varios formatos de cartuchos que deben ser compatibles.
Mientras tanto, redescubrí el Nintendo Game Boy. Y eso era lo que estaba buscando.
¿Por qué es Game Boy tan genial?
 1049 juegos clásicos y 576 juegos para Game Boy Color
1049 juegos clásicos y 576 juegos para Game Boy ColorEn total, más de 1000 juegos, una variedad muy amplia, de alta calidad, algunos de ellos son bastante complejos (Prince), los juegos se pueden agrupar y asignar complejidad para la investigación sobre la transferencia de conocimiento y entrenamiento (por ejemplo, hay opciones para Tetris, juegos de carreras, Mario). Para resolver el juego Prince of Persia, es posible que necesites transferir el conocimiento de otro juego similar en el que los puntos están claramente indicados (en Prince esto no es así).
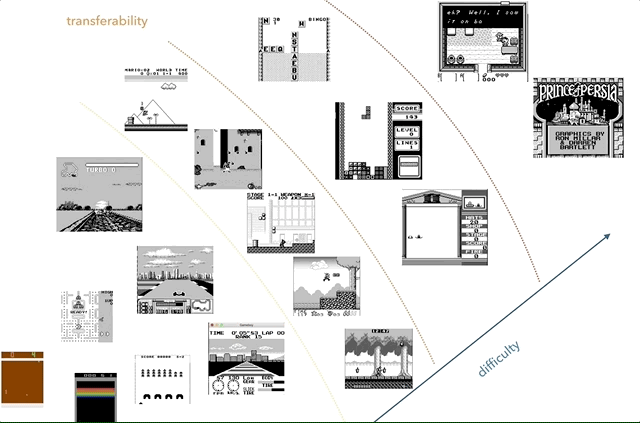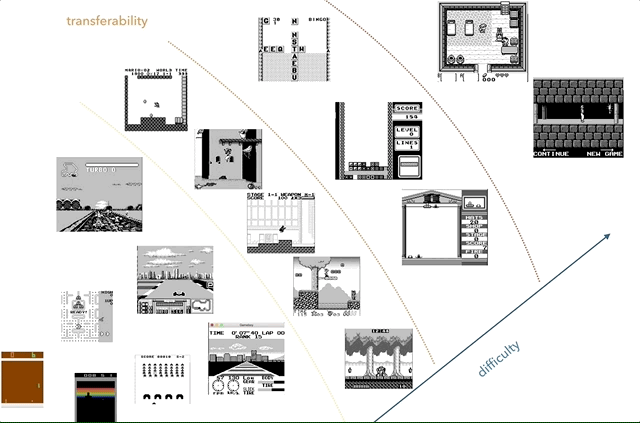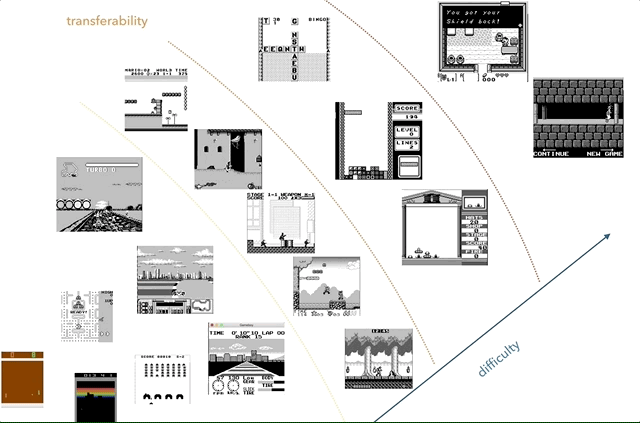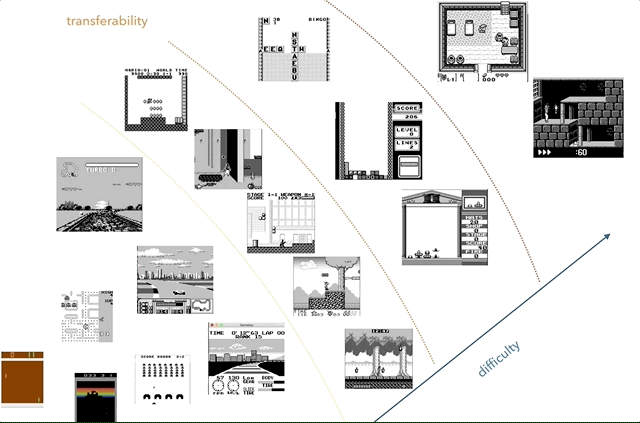 Nintendo Game Boy es mi plataforma de investigación de transferencia de conocimiento favorita. En el gráfico, intenté agrupar los juegos según la complejidad (subjetiva) y la similitud (conceptos como carreras, saltos, disparos, varios juegos como Tetris; ¿alguien jugó HATRIS?).
Nintendo Game Boy es mi plataforma de investigación de transferencia de conocimiento favorita. En el gráfico, intenté agrupar los juegos según la complejidad (subjetiva) y la similitud (conceptos como carreras, saltos, disparos, varios juegos como Tetris; ¿alguien jugó HATRIS?).El Game Boy clásico tiene una pantalla muy simple (160x144, color de 2 bits), por lo que el preprocesamiento se vuelve simple y puedes concentrarte en cosas importantes. A 2600, incluso los juegos simples tienen muchos colores. Además, en Game Boy los objetos se demuestran mucho mejor, sin parpadear y sin la necesidad de tomar un máximo de dos cuadros consecutivos.

Sin diseño de memoria loco, como el NES o 2600. La mayoría de los juegos pueden funcionar con 2-3 mapeadores.
Código compacto: logré ajustar todo el emulador en C en no más de 700 líneas de código, y mi implementación de Verilog cabe en 500 líneas.
Existe la misma versión simple de Space Invaders que en el arcade.
Y aquí está, mi Game Boy de matriz de puntos de 1989 y la versión FPGA que funciona a través de HDMI en una pantalla 4K.

Y esto es lo que mi viejo Game Boy no puede:
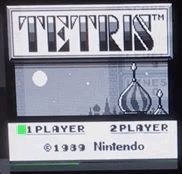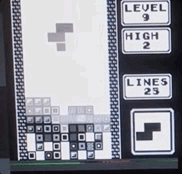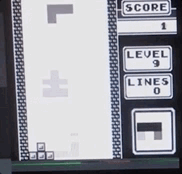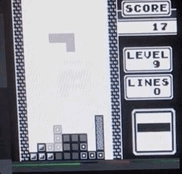 Tetris acelerado con hierro: grabando desde la pantalla en tiempo real, la velocidad es 1/4 del máximo.
Tetris acelerado con hierro: grabando desde la pantalla en tiempo real, la velocidad es 1/4 del máximo.¿Hay algún beneficio real para esto?
Si lo hay Hasta ahora, he probado el sistema en condiciones simples, con una red externa de reglas que interactúa con Game Boys individuales. Más específicamente, utilicé el algoritmo A3C (Advantage Actor Critic), y planeo describirlo en una publicación separada. Mi colega lo conectó a la red convolucional en FPGA, y funciona.
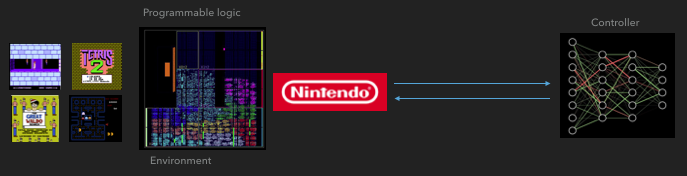 Cómo se comunica FGPA con una red neuronal
Cómo se comunica FGPA con una red neuronal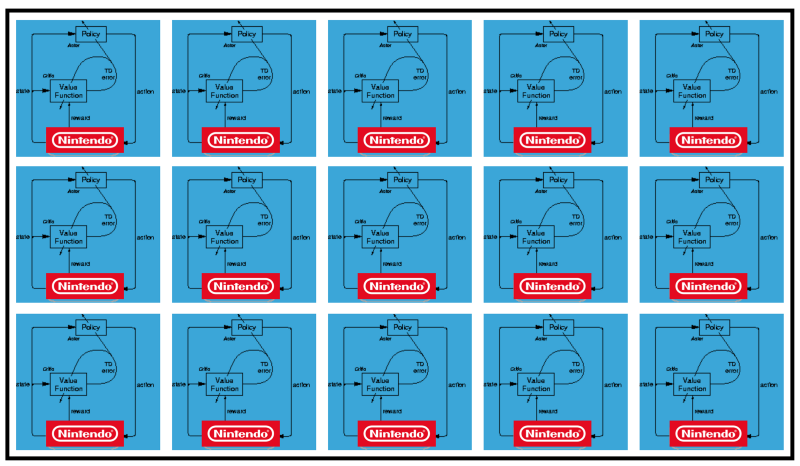 A3C distribuido
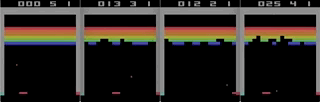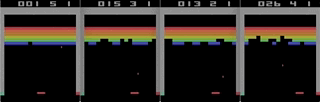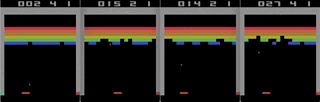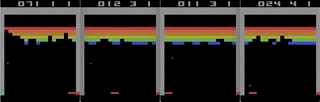
A3C distribuido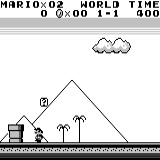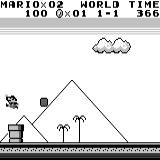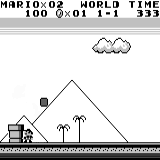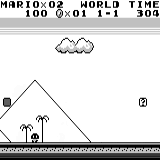 Mario land: condición inicial. Una pulsación aleatoria no nos llevará lejos. La esquina superior derecha muestra el tiempo restante. Si tenemos suerte, terminaremos rápidamente el juego después de tocar la gumba. Si no, tomará 400 segundos "perder".
Mario land: condición inicial. Una pulsación aleatoria no nos llevará lejos. La esquina superior derecha muestra el tiempo restante. Si tenemos suerte, terminaremos rápidamente el juego después de tocar la gumba. Si no, tomará 400 segundos "perder".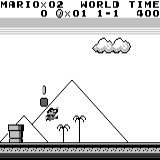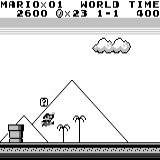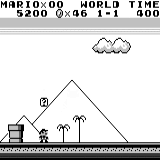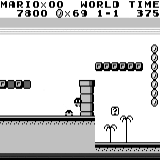 Mario land: después de una hora de juego, Mario aprendió a correr, saltar e incluso abrió una habitación secreta, metiéndose en una tubería.
Mario land: después de una hora de juego, Mario aprendió a correr, saltar e incluso abrió una habitación secreta, metiéndose en una tubería. Pac Man: después de aproximadamente una hora de entrenamiento, la red neuronal incluso pudo terminar todo el juego una vez (después de haber comido todos los puntos).
Pac Man: después de aproximadamente una hora de entrenamiento, la red neuronal incluso pudo terminar todo el juego una vez (después de haber comido todos los puntos).Conclusión
Me gustaría pensar que la próxima década será el período en que la supercomputación y la IA se encuentren. Me gustaría tener un hardware que me permita configurarme a un cierto nivel para adaptarme al algoritmo de IA deseado.
 La próxima décadaCódigo para Game Boy en C.
La próxima décadaCódigo para Game Boy en C.Depuración
La gente a menudo me pregunta: ¿qué fue lo más difícil? Eso es todo, todo el proyecto fue bastante doloroso. Para empezar, no hay una especificación para un Game Boy. Todo lo que aprendimos lo obtuvimos gracias a la ingeniería inversa, es decir, lanzamos una tarea intermedia, como un juego, y vimos cómo se lleva a cabo. Esto es muy diferente de la depuración de software estándar, porque aquí depuramos el hardware que ejecuta los programas. Tuve que encontrar diferentes formas de lograr esto. ¿Y hablé de lo difícil que es monitorear un proceso cuando se ejecuta a una frecuencia de 100 MHz? Ah, y no hay impresión allí.
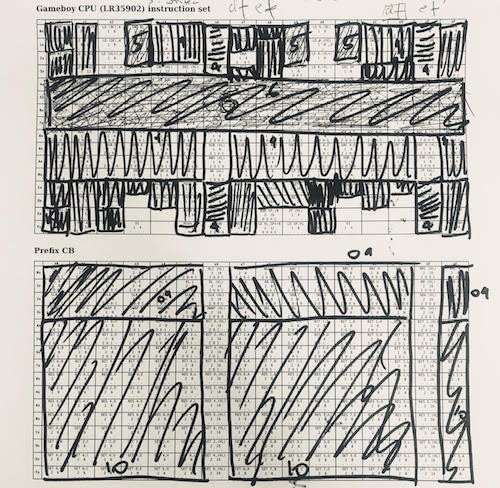 Un enfoque para implementar una CPU es agrupar instrucciones sobre sus funciones. Con 6502 es mucho más fácil. LR35092 abarrotó muchas tonterías "aleatorias" y hay muchas excepciones. Usé esta tabla cuando trabajaba con la CPU Game Boy. Utilicé una estrategia codiciosa: tomé la mayor parte de las instrucciones, las implementé y las eliminé, luego las repetí. 1/4 de las instrucciones es ALU, 1/4 es la carga de registros, que se puede implementar con bastante rapidez. En el otro lado del espectro hay todo tipo de cosas separadas, como "cargar de HL a SP con un signo", que tuvieron que procesarse por separado.
Un enfoque para implementar una CPU es agrupar instrucciones sobre sus funciones. Con 6502 es mucho más fácil. LR35092 abarrotó muchas tonterías "aleatorias" y hay muchas excepciones. Usé esta tabla cuando trabajaba con la CPU Game Boy. Utilicé una estrategia codiciosa: tomé la mayor parte de las instrucciones, las implementé y las eliminé, luego las repetí. 1/4 de las instrucciones es ALU, 1/4 es la carga de registros, que se puede implementar con bastante rapidez. En el otro lado del espectro hay todo tipo de cosas separadas, como "cargar de HL a SP con un signo", que tuvieron que procesarse por separado. Depuración: ejecute el código en el hardware que está depurando, escriba el registro de su implementación e información adicional (esto muestra una comparación del código Verilog a la izquierda con mi C-emulador a la derecha). Luego ejecute diff para los registros para encontrar inconsistencias (azul). Una de las razones para usar la automatización es que en muchos casos encontré problemas después de millones de ciclos de ejecución cuando un solo indicador de CPU causó un efecto de bola de nieve. Intenté varios enfoques, y este resultó ser el más efectivo.
Depuración: ejecute el código en el hardware que está depurando, escriba el registro de su implementación e información adicional (esto muestra una comparación del código Verilog a la izquierda con mi C-emulador a la derecha). Luego ejecute diff para los registros para encontrar inconsistencias (azul). Una de las razones para usar la automatización es que en muchos casos encontré problemas después de millones de ciclos de ejecución cuando un solo indicador de CPU causó un efecto de bola de nieve. Intenté varios enfoques, y este resultó ser el más efectivo. ¡Necesitarás mucho café!
¡Necesitarás mucho café! Estos libros tienen 40 años. Fue increíble hurgar en ellos y mirar el mundo de las computadoras a través de los ojos de esos usuarios en ese momento: me sentí como un invitado del futuro.
Estos libros tienen 40 años. Fue increíble hurgar en ellos y mirar el mundo de las computadoras a través de los ojos de esos usuarios en ese momento: me sentí como un invitado del futuro.Solicitud de investigación de OpenAI
Al principio quería trabajar con juegos en términos de memoria, como se describe en una
publicación de OpenAI.
Sorprendentemente, hacer que Q-learning funcione bien en entradas que representan estados de memoria fue inesperadamente difícil.
Este proyecto puede no tener una solución. Sería inesperado descubrir que Q-learning nunca tendrá éxito trabajando con memoria en Atari, pero hay posibilidades de que esta tarea sea bastante difícil.
Teniendo en cuenta que los juegos en Atari usaban solo 128 b de memoria, parecía muy atractivo procesar estos 128 b en lugar de cuadros de pantalla completa. Obtuve resultados mixtos, así que comencé a resolverlo.
Y aunque no puedo demostrar que es imposible aprender de la memoria, puedo demostrar que la suposición de que la memoria refleja el estado completo del juego es incorrecta. La CPU Atari 2600 (6507) usa 128 b de memoria, pero aún tiene acceso a registros adicionales que viven en un circuito separado (TIA, adaptador para un televisor, algo así como una GPU). Estos registros se utilizan para almacenar y procesar información sobre objetos (raqueta, cohete, pelota, colisión). En otras palabras, serán inaccesibles si consideramos solo la memoria. NES y Game Boy también tienen registros adicionales que se utilizan para controlar la pantalla y desplazarse. Solo una memoria no refleja el estado completo del juego.
Solo el 8080 almacena directamente datos en la memoria de video, lo que le permite extraer el estado completo del juego. En otros casos, los registros de "GPU" están conectados entre la CPU y el búfer de pantalla, mientras están fuera de la RAM.
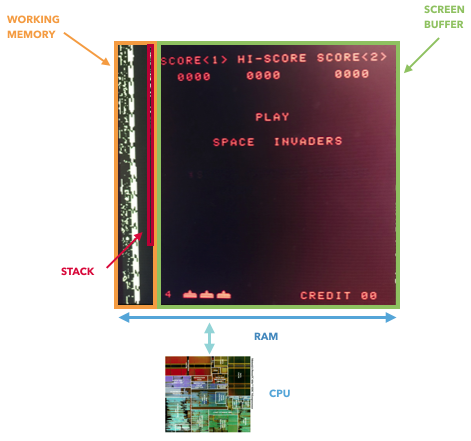
Un hecho interesante: si realiza una investigación sobre la historia de la GPU, entonces el 8080 puede ser el primer "acelerador de gráficos": tiene un registro de desplazamiento externo que le permite mover invasores del espacio con un solo comando, que descarga la CPU.

Eof