Hola Soy Dima, y he estado sentada en Python desde hace bastante tiempo. Hoy quiero mostrarles las diferencias entre dos marcos asincrónicos: Tornado y Aiohttp. Contaré la historia de la elección entre los marcos en nuestro proyecto, cómo difieren las corutinas en Tornado y AsyncIO, mostraré puntos de referencia y daré algunos consejos útiles sobre cómo entrar en la naturaleza de los marcos y salir con éxito de allí.

Como saben, Avito es un servicio de publicidad bastante grande. Tenemos muchos datos y cargas, 35 millones de usuarios cada mes y 45 millones de anuncios activos diariamente. Trabajo como asesor técnico de un grupo de desarrollo de recomendaciones. Mi equipo escribe microservicios, ahora tenemos unos veinte. Se está acumulando una carga en todo esto, como 5k RPS.
Elegir un marco asincrónico
Primero te diré cómo terminamos donde estamos ahora. En 2015, necesitábamos elegir un marco asincrónico, porque sabíamos:
- que tiene que hacer muchas solicitudes a otros microservicios: http, json, rpc;
- que necesitará recopilar datos de diferentes fuentes todo el tiempo: Redis, Postgres, MongoDB.
Por lo tanto, tenemos muchas tareas de red, y la aplicación está ocupada principalmente con entrada / salida. La versión actual de python en ese momento era 3.4, asíncrono y en espera aún no aparecía. Aiohttp también fue - en la versión 0.x. El Tornado Asíncrono de Facebook apareció en 2010. Muchos de los controladores de bases de datos están escritos para él que necesitamos. Tornado mostró resultados estables en los puntos de referencia. Luego detuvimos nuestra elección en este marco.
Tres años después, entendimos mucho.
Primero, Python 3.5 salió con mecánica asíncrona / espera. Descubrimos cuál es la diferencia entre el rendimiento y el rendimiento y cómo Tornado es consistente con esperar (spoiler: no muy bueno).
En segundo lugar, nos encontramos con extraños problemas de rendimiento con una gran cantidad de rutina en el programador, incluso cuando la CPU no está completamente ocupada.
En tercer lugar, descubrimos que al realizar una gran cantidad de solicitudes http a otros servicios de Tornado, debe ser especialmente amigable con la resolución asíncrona de DNS, no respeta los tiempos de espera para establecer una conexión y enviar la solicitud que especificamos. Y, en general, el mejor método para realizar solicitudes http en Tornado es curl, lo cual es bastante extraño en sí mismo.
En su
charla en PyCon Rusia 2018, Andrei Svetlov dijo: “Si quieres escribir algún tipo de aplicación web asíncrona, solo escribe asíncrono, espera. Event loop, probablemente, no lo necesitará en absoluto pronto. No entre en la naturaleza de los marcos para no confundirse. No uses primitivas de bajo nivel, y todo estará bien contigo ... ". En los últimos tres años, lamentablemente, hemos tenido que subir al interior del Tornado con bastante frecuencia, aprender muchas cosas interesantes desde allí y ver trazas gigantes para 30-40 llamadas.
Rendimiento vs rendimiento de
Uno de los mayores problemas para entender en Python asíncrono es la diferencia entre rendimiento y rendimiento.
Guido Van Rossum escribió más sobre esto. Adjunto la traducción con ligeras abreviaturas.
Me han preguntado varias veces por qué PEP 3156 insiste en usar el rendimiento desde en lugar del rendimiento, lo que elimina la posibilidad de hacer backport en Python 3.2 o incluso 2.7.
(...)
cada vez que quieres un resultado futuro, usas rendimiento.
Esto se implementa de la siguiente manera. La función que contiene el rendimiento es (obviamente) un generador, por lo que debe haber algún tipo de código iterativo. Vamos a llamarlo un planificador. De hecho, el planificador no "itera" en el sentido clásico (con for-loop); en su lugar, admite dos colecciones futuras.
Llamaré a la primera colección una secuencia "ejecutable". Este es el futuro, cuyos resultados están disponibles. Si bien esta lista no está vacía, el planificador selecciona un elemento y realiza un paso de iteración. Este paso llama al método generador .send () con el resultado del futuro (que pueden ser datos que se acaban de leer desde el socket); en el generador, este resultado aparece como el valor de retorno de la expresión de rendimiento. Cuando send () devuelve un resultado o se completa, el planificador analiza el resultado (que puede ser StopIteration, otra excepción o algún tipo de objeto).
(Si está confundido, probablemente debería leer sobre cómo funcionan los generadores, en particular, el método .send (). Quizás PEP 342 es un buen punto de partida).
(...)
La segunda colección futura que admite el planificador consiste en el futuro, que todavía está esperando E / S. De alguna manera se pasan a select / poll / shell, etc. que devuelve la llamada cuando el descriptor de archivo está listo para E / S. La devolución de llamada realmente realiza la operación de E / S solicitada por futuro, establece el valor futuro resultante al resultado de la operación de E / S y mueve el futuro a la cola de ejecución.
(...)
Ahora hemos llegado a lo más interesante. Supongamos que está escribiendo un protocolo complejo. Dentro de su protocolo, lee bytes de un socket utilizando el método recv (). Estos bytes llegan al búfer. El método recv () está envuelto en un shell asíncrono, que establece la E / S y devuelve el futuro, que se ejecuta cuando se completa la E / S, como expliqué anteriormente. Ahora suponga que alguna otra parte de su código desea leer datos del búfer una línea a la vez. Suponga que usó el método readline (). Si el tamaño del búfer es mayor que la longitud de línea promedio, su método readline () simplemente puede obtener la siguiente línea del búfer sin bloquear; pero a veces el búfer no contiene una línea completa, y readline () a su vez llama a recv () en el zócalo.
Pregunta: ¿debería readline () regresar futuro o no? No sería muy bueno si a veces devolviera una cadena de bytes y, a veces, en el futuro, obligando a la persona que llama a realizar una verificación de tipo y rendimiento condicional. Entonces la respuesta es que readline () siempre debe regresar en el futuro. Cuando se llama a readline (), comprueba el búfer y, si encuentra al menos una línea completa allí, crea un futuro, establece el resultado futuro de una línea tomada del búfer y devuelve el futuro. Si el búfer no tiene una línea completa, inicia E / S y lo espera, y cuando se completa la E / S, comienza de nuevo.
(...)
Pero ahora estamos creando muchos futuros que no requieren el bloqueo de E / S, pero que aún fuerzan una llamada al planificador, porque readline () devuelve el futuro, se requiere rendimiento de la persona que llama, y eso significa una llamada al planificador.
El planificador puede transferir el control directamente a la rutina si ve que se muestra el futuro, que ya se ha completado, o puede devolver el futuro a la cola de ejecución. Este último ralentizará en gran medida el trabajo (siempre que haya más de una rutina ejecutable), ya que no solo se requiere esperar al final de la cola, sino que también se pierde la localidad de la memoria (si es que existe).
(...)
El efecto neto de todo esto es que los autores de rutina necesitan saber sobre el rendimiento futuro y, por lo tanto, existe una mayor barrera psicológica para reorganizar el código complejo en corutinas más legibles, mucho más fuerte que la resistencia existente, porque las llamadas a funciones en Python son bastante lentas. Y recuerdo de una conversación con Glyph que la velocidad es importante en una estructura de E / S asíncrona típica.
Ahora comparemos esto con el rendimiento de.
(...)
Es posible que haya escuchado que "rendimiento de S" es más o menos equivalente a "para i en S: rendimiento i". En el caso más simple, esto es cierto, pero esto no es suficiente para entender la rutina. Considere lo siguiente (no piense en E / S asíncrona todavía):
def driver(g): print(next(g)) g.send(42) def gen1(): val = yield 'okay' print(val) driver(gen1())
Este código imprime dos líneas que contienen "okay" y "42" (y luego produce una StopIteration no controlada, que puede suprimir agregando rendimiento al final de gen1). Puede ver este código en acción en pythontutor.com en el enlace .
Ahora considere lo siguiente:
def gen2(): yield from gen1() driver(gen2())
Funciona exactamente de la misma manera . Ahora piensa. Como funciona Aquí no se puede usar la extensión de rendimiento simple en el ciclo for, ya que en este caso el código devolvería None. (Pruébalo) Yield-from actúa como un "canal transparente" entre driver y gen1. Es decir, cuando gen1 da el valor "está bien", sale de gen2, a través del rendimiento desde, al controlador, y cuando el controlador envía 42 de vuelta a gen2, este valor se devuelve a través del rendimiento desde a gen1 nuevamente (donde se convierte en el resultado del rendimiento )
Lo mismo sucedería si el conductor arrojara un error en el generador: el error pasa por el rendimiento desde el generador interno que lo procesa. Por ejemplo:
def throwing_driver(g): print(next(g)) g.throw(RuntimeError('booh')) def gen1(): try: val = yield 'okay' except RuntimeError as exc: print(exc) else: print(val) yield throwing_driver(gen1())
El código dará "okay" y "bah", así como el siguiente código:
def gen2(): yield from gen1()
(Ver aquí: goo.gl/8tnjk )
Ahora me gustaría presentar gráficos simples (ASCII) para poder hablar sobre este tipo de código. Utilizo [f1 -> f2 -> ... -> fN) para representar la pila con f1 en la parte inferior (marco de llamada más antiguo) y fN en la parte superior (marco de llamada más reciente), donde cada elemento de la lista es un generador, y -> son rendimientos de . El primer ejemplo, driver (gen1 ()) no tiene rendimiento de, pero tiene un generador gen1, por lo que se ve así:
[ gen1 )
En el segundo ejemplo, gen2 llama a gen1 usando el rendimiento desde, por lo que se ve así:
[ gen2 -> gen1 )
Utilizo la notación matemática para el intervalo medio abierto [...) para mostrar que se puede agregar otro cuadro a la derecha cuando el generador más a la derecha usa el rendimiento desde para llamar a otro generador, mientras que el extremo izquierdo está más o menos fijo. El final izquierdo es lo que ve el controlador (es decir, el planificador).
Ahora estoy listo para volver al ejemplo de readline (). Podemos reescribir readline () como un generador que llama a read (), otro generador que usa yield-from; este último, a su vez, llama a recv (), que realiza la entrada / salida real desde el socket. A nuestra izquierda está la aplicación, que también consideramos como un generador que llama a readline (), nuevamente usando el rendimiento desde. El esquema es el siguiente:
[ app -> readline -> read -> recv )
Ahora el generador recv () establece E / S, lo une al futuro y lo pasa al planificador usando * yield * (¡no rendimiento-desde!). El futuro va a la izquierda a lo largo de ambas flechas de rendimiento en el programador (ubicado a la izquierda de "["). Tenga en cuenta que el planificador no sabe que contiene una pila de generadores; todo lo que sabe es que contiene el generador más a la izquierda y que acaba de emitir un futuro. Cuando se completa la E / S, el planificador establece el resultado futuro y lo envía de vuelta al generador; el resultado se mueve hacia la derecha en ambas flechas desde el generador de recepción, que recibe los bytes que quería leer desde el socket como resultado del rendimiento.
En otras palabras, el planificador de marco de rendimiento desde maneja las operaciones de E / S al igual que el planificador de marco basado en rendimiento que describí anteriormente. * Pero: * no necesita preocuparse por la optimización cuando el futuro ya está ejecutado, ya que el programador no participa en la transferencia de control entre readline () y read () o entre read () y recv (), y viceversa. Por lo tanto, el planificador no participa en absoluto cuando app () llama a readline (), y readline () puede satisfacer la solicitud del búfer (sin llamar a read ()) - la interacción entre app () y readline () en este caso es procesada completamente por el intérprete de bytecode Pitón El programador puede ser más simple, y el número de futuros creados y administrados por el programador es menor, porque no hay futuros que se creen y destruyan con cada llamada de rutina. El único futuro que aún se necesita son aquellos que representan la E / S real, por ejemplo, creada por recv ().
Si has leído hasta este punto, mereces una recompensa. Omití muchos detalles de implementación, pero la ilustración anterior refleja esencialmente la imagen correctamente.
Otra cosa que me gustaría señalar. * Puede * hacer que parte del código use el rendimiento de, y la otra parte use el rendimiento. Pero el rendimiento requiere que cada eslabón de la cadena tenga un futuro, no solo una rutina. Dado que existen varias ventajas al usar el rendimiento desde, quiero que el usuario no tenga que recordar cuándo usar el rendimiento, y cuando el rendimiento desde, es más fácil usar siempre el rendimiento desde. Una solución simple incluso permite que recv () utilice el rendimiento desde para pasar E / S futuras al planificador: el método __iter__ es en realidad el generador que emite el futuro.
(...)
Y una cosa más. ¿Qué valor produce el rendimiento del rendimiento? Resulta que este es el valor de retorno del generador * externo *.
(...)
Por lo tanto, mientras las flechas unen los cuadros izquierdo y derecho al objetivo * que rinde *, también pasan los valores de retorno habituales de la manera habitual, un cuadro de pila a la vez. Las excepciones se mueven de la misma manera; por supuesto, en cada nivel, se requiere try / except para atraparlos.
Resulta que el rendimiento es más o menos lo mismo que esperar.
rendimiento de vs asíncrono
def coro () ^ y = rendimiento de a | async def async_coro (): y = espera un |
| 0 load_global | 0 load_global |
| 2 get_yield_from_iter | 2 get_awaitable |
| 4 load_const | 4 load_const |
| 6 rendimiento_de | 6 rendimiento_de |
| 8 store_fast | 8 store_fast |
| 10 load_const | 10 load_const
|
| 12 return_value | 12 return_value |
Las dos corutinas de las viejas y nuevas escuelas tienen solo una pequeña diferencia: obtener rendimiento de iter frente a esperar.
¿Por qué es todo esto? Tornado usa un rendimiento simple. Antes de la versión 5, conecta toda esta cadena de llamadas a través del rendimiento, que es poco compatible con el nuevo paradigma de rendimiento / espera fresco.
El punto de referencia asincrónico más simple
Es difícil encontrar un marco realmente bueno, eligiéndolo solo de acuerdo con pruebas sintéticas. En la vida real, muchas cosas pueden salir mal.
Tomé Aiohttp versión 3.4.4, Tornado 5.1.1, uvloop 0.11, tomé el procesador del servidor Intel Xeon, CPU E5 v4, 3.6 GHz, y con Python 3.6.5 comencé a verificar la competitividad de los servidores web.
El problema típico que resolvemos con la ayuda de microservicios, y que funciona en modo asíncrono, se ve así. Recibiremos solicitudes. Para cada uno de ellos haremos una solicitud a algún microservicio, obtendremos datos de allí, luego iremos a otros dos o tres microservicios, también de forma asíncrona, luego escribiremos los datos en algún lugar de la base de datos y devolveremos el resultado. Resulta muchos puntos donde esperaremos.
Llevamos a cabo una operación más simple. Encendemos el servidor, lo hacemos dormir 50 ms. Crea una rutina y complétala. No tendremos un RPS muy grande (puede que no sea un orden de magnitud similar a lo que se ve en los puntos de referencia completamente sintéticos) con un retraso aceptable debido al hecho de que mucha corutina girará simultáneamente en un servidor competitivo.
@tornado.gen.coroutine def old_school_work(): yield tornado.gen.sleep(SLEEP_TIME) async def work(): await tornado.gen.sleep(SLEEP_TIME)
Cargar: OBTENER solicitudes http. Duración - 300s, 1s - calentamiento, 5 repeticiones de la carga.
 Resultados en percentiles del tiempo de respuesta del servicio.
Resultados en percentiles del tiempo de respuesta del servicio.¿Qué son los percentiles?Tienes una gran cantidad de números. El percentil 95 X significa que el 95% de los valores en esta muestra son menores que X. Con una probabilidad del 5%, su número será mayor que X.
Vemos que Aiohttp hizo un buen trabajo a 1000 RPS en una prueba tan simple. Todo hasta ahora sin
uvloop .
Compare Tornado con las rutinas de las escuelas antiguas (rendimiento) y nuevas (asíncronas). Los autores recomiendan usar asíncrono. Podemos asegurarnos de que sean mucho más rápidos.
A las 1200 RPS, Tornado, incluso con las nuevas corutinas de la escuela, ya está comenzando a rendirse, y Tornado con las corutinas de la vieja escuela está completamente impresionado. Si dormimos durante 50 ms, y el microservicio es responsable de 80 ms, esto no entra en ninguna puerta.
La nueva escuela de Tornado a 1,500 RPS se ha rendido por completo, mientras que Aiohttp aún está lejos del límite de 3,000 RPS. Lo más interesante está por venir.
Pyflame, perfilando un microservicio en funcionamiento
Veamos qué está pasando en este momento con el procesador.

Cuando descubrimos cómo funcionan los microservicios asincrónicos de Python en la producción, tratamos de entender en qué se topaba todo. En la mayoría de los casos, el problema estaba en la CPU o en los descriptores. Hay una gran herramienta de creación de perfiles creada en Uber, el
generador de perfiles
Pyflame , que se basa en la llamada al sistema ptrace.
Comenzamos algún servicio en el contenedor y comenzamos a lanzar una carga de combate sobre él. A menudo, esta no es una tarea muy trivial: crear tal carga que está en batalla, porque a menudo sucede que ejecutas pruebas sintéticas en pruebas de carga, mira y todo funciona bien. Empujas la carga de combate sobre él, y aquí el microservicio comienza a disminuir.
Durante la operación, este generador de perfiles hace instantáneas de la pila de llamadas por nosotros. No puede cambiar el servicio en absoluto, solo ejecute pyflame cerca. Recopilará un rastro de la pila una vez en un cierto período de tiempo, y luego hará una visualización genial. Este generador de perfiles proporciona muy poca sobrecarga, especialmente cuando se compara con cProfile. Pyflame también admite programas multiproceso. Lanzamos esto directamente en el producto, y el rendimiento no se degradó mucho.
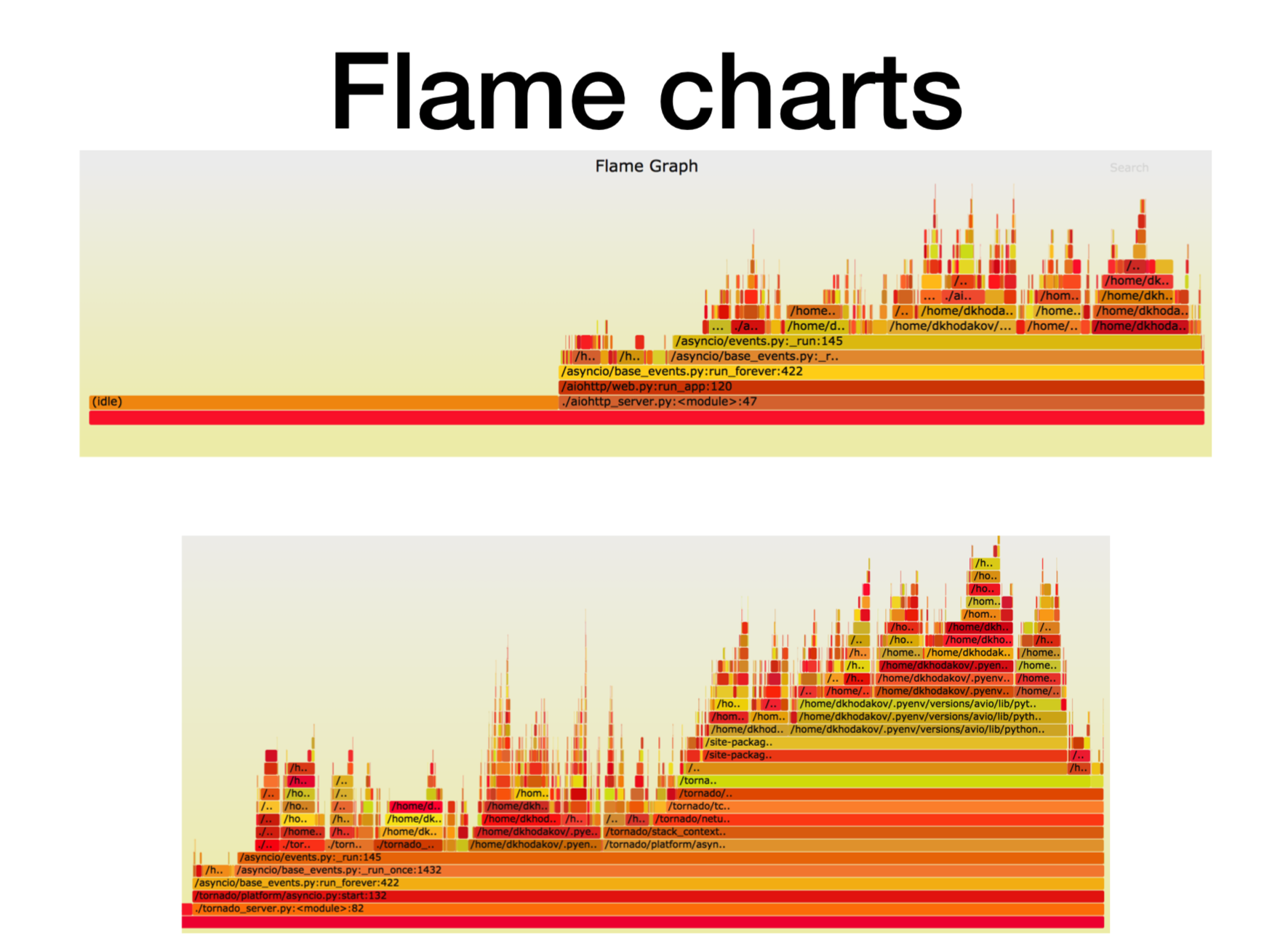
Aquí, el eje X es la cantidad de tiempo, el número de llamadas, cuando el marco de la pila estaba en la lista de todos los marcos de la pila Python. Esta es la cantidad aproximada de tiempo de procesador que pasamos en este marco particular de la pila.
Como puede ver, aquí la mayor parte del tiempo en aiohttp pasa a inactivo. Bien: esto es lo que queremos de un servicio asíncrono para que se ocupe de las llamadas de red la mayor parte del tiempo. La profundidad de la pila en este caso es de aproximadamente 15 cuadros.
En Tornado (segunda imagen) con la misma carga, se gasta mucho menos tiempo en inactivo y la profundidad de la pila en este caso es de aproximadamente 30 fotogramas.
Aquí hay un
enlace a svg , puede torcerse usted mismo.
Punto de referencia asincrónico más complejo
async def work():
Espere un tiempo de ejecución de 125 ms.

Tornado con uvloop aguanta mejor. Pero Aiohttp uvloop ayuda mucho más. Aiohttp comienza a comportarse mal en 2300-2400 RPS, y con uvloop expande significativamente el rango de carga. Una línea de importación, y ahora tiene un servicio mucho más productivo.
Resumen
Resumiré lo que quería transmitirles hoy.
- En primer lugar, lancé un determinado punto de referencia artificial, donde había una cantidad decente de larga rutina. En nuestra prueba, Aiohttp se desempeñó mejor 2.5 veces que Tornado.
- El segundo hecho. Uvloop muy bien ayuda a mejorar el rendimiento de Aiohttp (mejor que Tornado).
- Te conté sobre Pyflame, con el que a menudo perfilamos la aplicación directamente en producción.
- Y también hablamos sobre el rendimiento de (espera) versus rendimiento.
Como resultado de estos puntos de referencia, nuestro equipo de recomendaciones (y algunos otros) se trasladó casi por completo a Aiohttp con Tornado para microservicios en Python en producción.
- Para los servicios de combate, el consumo de CPU se redujo en más de 2 veces.
- Comenzamos a respetar los tiempos de espera para las solicitudes http.
- Los servicios de latencia cayeron de 2 a 5 veces.
Aquí hay un
enlace al punto de referencia . Si está interesado, puede repetirlo. Gracias a todos por su atención. Haga preguntas, trataré de responderlas.