Hola Habr!
En este artículo, queremos compartir nuestra experiencia en la optimización del rendimiento y la exploración de las características de AspNetCore.Mvc.

Antecedentes
Hace varios años, en uno de nuestros servicios cargados, notamos un consumo significativo de recursos de CPU. Parecía extraño, ya que la tarea del servicio era tomar el mensaje y ponerlo en la cola, habiendo realizado previamente algunas operaciones en él, como validación, adición de datos, etc.
Como resultado de la creación de perfiles, descubrimos que la deserialización "consume" la mayor parte del tiempo del procesador. Descartamos el serializador estándar y escribimos el nuestro en Jil, como resultado de lo cual el consumo de recursos disminuyó varias veces. Todo funcionó como debería y logramos olvidarlo.
El problema
Estamos mejorando constantemente nuestro servicio en todas las áreas, incluidas la seguridad, el rendimiento y la tolerancia a fallas, por lo que el "equipo de seguridad" realiza varias pruebas de nuestros servicios. Y hace algún tiempo, una alerta sobre un error en el registro nos "vuela", de alguna manera hemos perdido un mensaje inválido.
Con un análisis detallado, todo parecía bastante extraño. Hay un modelo de solicitud (aquí daré un ejemplo de código simplificado):
public class RequestModel { public string Key { get; set; } FromBody] Required] public PostRequestModelBody Body { get; set; } } public class PostRequestModelBody { [Required] [MinLength(1)] public IEnumerable<long> ItemIds { get; set; } }
Hay un controlador con acción Publicar, por ejemplo:
[Route("api/[controller]")] public class HomeController : Controller { [HttpPost] public async Task<ActionResult> Post(RequestModel request) { if (this.ModelState.IsValid) { return this.Ok(); } return this.BadRequest(); } }
Todo parece lógico. Si una solicitud proviene de la vista Cuerpo
{"itemIds":["","","" … ] }
La API devolverá BadRequest, y hay pruebas para esto.
Sin embargo, en el registro vemos lo contrario. Tomamos el mensaje de los registros, lo enviamos a la API y obtuvimos el estado OK ... y ... un nuevo error en el registro. Sin creer lo que veíamos, cometimos un error y nos aseguramos de que sí, de hecho ModelState.IsValid == true. Al mismo tiempo, notaron un tiempo de ejecución de consultas inusualmente largo de aproximadamente 500 ms, mientras que el tiempo de respuesta habitual rara vez supera los 50 ms y esto está en producción, ¡que atiende miles de solicitudes por segundo!
La diferencia entre esta solicitud y nuestras pruebas fue solo que la solicitud contenía más de 600 líneas vacías ...
Lo siguiente será un montón de código bukaf.
Razón
Comenzaron a entender lo que estaba mal. Para eliminar el error, escribieron una aplicación limpia (de la cual di un ejemplo), con la cual reproducimos la situación descrita. En total, pasamos un par de días-hombre en investigación, pruebas, depuración mental del código AspNetCore.Mvc y resultó que el problema estaba en
JsonInputFormatter .
JsonInputFormatter usa un JsonSerializer que, al obtener una secuencia para la deserialización y el tipo, intenta serializar cada propiedad, si es una matriz, cada elemento de esta matriz. Al mismo tiempo, si se produce un error durante la serialización, JsonInputFormatter guarda cada error y su ruta, lo marca como procesado, para que pueda continuar el intento de deserializar aún más.
A continuación se muestra el código para el controlador de errores JsonInputFormatter (está disponible en Github en el enlace de arriba):
void ErrorHandler(object sender, Newtonsoft.Json.Serialization.ErrorEventArgs eventArgs) { successful = false; // When ErrorContext.Path does not include ErrorContext.Member, add Member to form full path. var path = eventArgs.ErrorContext.Path; var member = eventArgs.ErrorContext.Member?.ToString(); var addMember = !string.IsNullOrEmpty(member); if (addMember) { // Path.Member case (path.Length < member.Length) needs no further checks. if (path.Length == member.Length) { // Add Member in Path.Memb case but not for Path.Path. addMember = !string.Equals(path, member, StringComparison.Ordinal); } else if (path.Length > member.Length) { // Finally, check whether Path already ends with Member. if (member[0] == '[') { addMember = !path.EndsWith(member, StringComparison.Ordinal); } else { addMember = !path.EndsWith("." + member, StringComparison.Ordinal); } } } if (addMember) { path = ModelNames.CreatePropertyModelName(path, member); } // Handle path combinations such as ""+"Property", "Parent"+"Property", or "Parent"+"[12]". var key = ModelNames.CreatePropertyModelName(context.ModelName, path); exception = eventArgs.ErrorContext.Error; var metadata = GetPathMetadata(context.Metadata, path); var modelStateException = WrapExceptionForModelState(exception); context.ModelState.TryAddModelError(key, modelStateException, metadata); _logger.JsonInputException(exception); // Error must always be marked as handled // Failure to do so can cause the exception to be rethrown at every recursive level and // overflow the stack for x64 CLR processes eventArgs.ErrorContext.Handled = true; }
Los errores de marcado como procesados se realizan al final del procesador
eventArgs.ErrorContext.Handled = true;
Por lo tanto, se implementa una función para generar todos los errores de deserialización y rutas a ellos, en qué campos / elementos eran, bueno ... casi todos ...
El hecho es que JsonSerializer tiene un límite de 200 errores, después de lo cual se bloquea, mientras que todo el código se bloquea y ModelState se vuelve ... ¡válido! ... los errores también se pierden.
Solución
Sin dudarlo, implementamos nuestro formateador Json para Asp.Net Core usando el Deserializador Jil. Dado que el número de errores en el cuerpo no es absolutamente importante para nosotros, solo el hecho de su presencia es importante (y generalmente es difícil imaginar una situación en la que sería realmente útil), el código del serializador resultó ser bastante simple.
Daré el código principal de JilJsonInputFormatter personalizado:
using (var reader = context.ReaderFactory(request.Body, encoding)) { try { var result = JSON.Deserialize( reader: reader, type: context.ModelType, options: this.jilOptions); if (result == null && !context.TreatEmptyInputAsDefaultValue) { return await InputFormatterResult.NoValueAsync(); } else { return await InputFormatterResult.SuccessAsync(result); } } catch { // - } return await InputFormatterResult.FailureAsync(); }
Atencion Jil distingue entre mayúsculas y minúsculas, es decir, el contenido del cuerpo
{"ItemIds":["","","" … ] }
y
{"itemIds":["","","" … ] }
No es lo mismo. En el primer caso, si se usa camelCase, la propiedad ItemIds será nula después de la deserialización.
Pero como esta es nuestra API, la usamos y controlamos, para nosotros no es crítica. El problema puede surgir si es una API pública y alguien ya la llama, pasando el nombre del parámetro no en camelCase.
Resultado
El resultado incluso excedió nuestras expectativas, la API comenzó a devolver BadRequest a la solicitud solicitada y lo hizo muy rápidamente. A continuación se muestran capturas de pantalla de algunos de nuestros gráficos, que muestran claramente los cambios en el tiempo de respuesta y la CPU, antes y después de la implementación.
Solicitar plazo de entrega:

Alrededor de las 16:00 hubo un despliegue. Antes del despliegue, el tiempo de ejecución de p99 era de 30-57 ms, después del despliegue se convirtió en 9-15 ms. (No puede prestar atención a los picos repetidos de las 18:00; esta fue otra implementación)
Así es como ha cambiado el gráfico de la CPU:
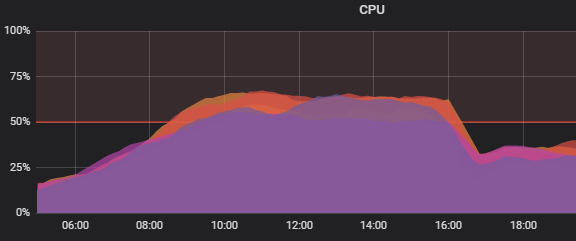
Por esta razón, trajimos un
problema a Github, al momento de escribir, se marcó como un error con el hito 3.0.0-preview3.
En conclusión
Hasta que se resuelva el problema, creemos que es mejor abandonar el uso de la deserialización estándar, especialmente si tiene una API pública. Conociendo este problema, un atacante puede poner fácilmente su servicio lanzando un montón de solicitudes inválidas similares, porque cuanto más grande es la matriz errónea, más cuerpo, más tiempo tiene lugar el procesamiento en JsonInputFormatter.
Artyom Astashkin, líder del equipo de desarrollo