En un artículo anterior del St. Petersburg HSE, mostramos cómo el aprendizaje automático puede buscar errores en el código del programa. En esta publicación, hablaremos sobre cómo nosotros, junto con JetBrains Research, estamos tratando de usar una de las secciones más interesantes, modernas y de rápido crecimiento del aprendizaje automático, el aprendizaje por refuerzo, tanto en problemas prácticos reales como en ejemplos de modelos.

Sobre mi
Me llamo Nikita Sazanovich. Hasta junio de 2018, estudié en SPbAU durante tres años y luego, junto con mis otros compañeros de clase, me transfirieron a HSE St. Petersburg, donde ahora estoy terminando mis estudios de pregrado. Recientemente, también trabajo como investigador en JetBrains Research. Antes de ingresar a la universidad, me gustaba la programación deportiva y jugué para el equipo nacional de Bielorrusia.
Entrenamiento de refuerzo
El aprendizaje por refuerzo es una rama del aprendizaje automático en el que el agente, al interactuar con el entorno, recibe refuerzo (de ahí el nombre) en forma de recompensa positiva o negativa. Dependiendo de estas indicaciones, el agente cambia su comportamiento. El objetivo final de este proceso es recibir la mayor recompensa posible o, de otra manera, lograr las acciones que el agente ha establecido.
Los agentes operan en condiciones y acciones selectas. Por ejemplo, en el problema de salir del laberinto, nuestros estados serán las coordenadas xey, y las acciones serán arriba / abajo / izquierda / derecha. El esquema general se ve así:
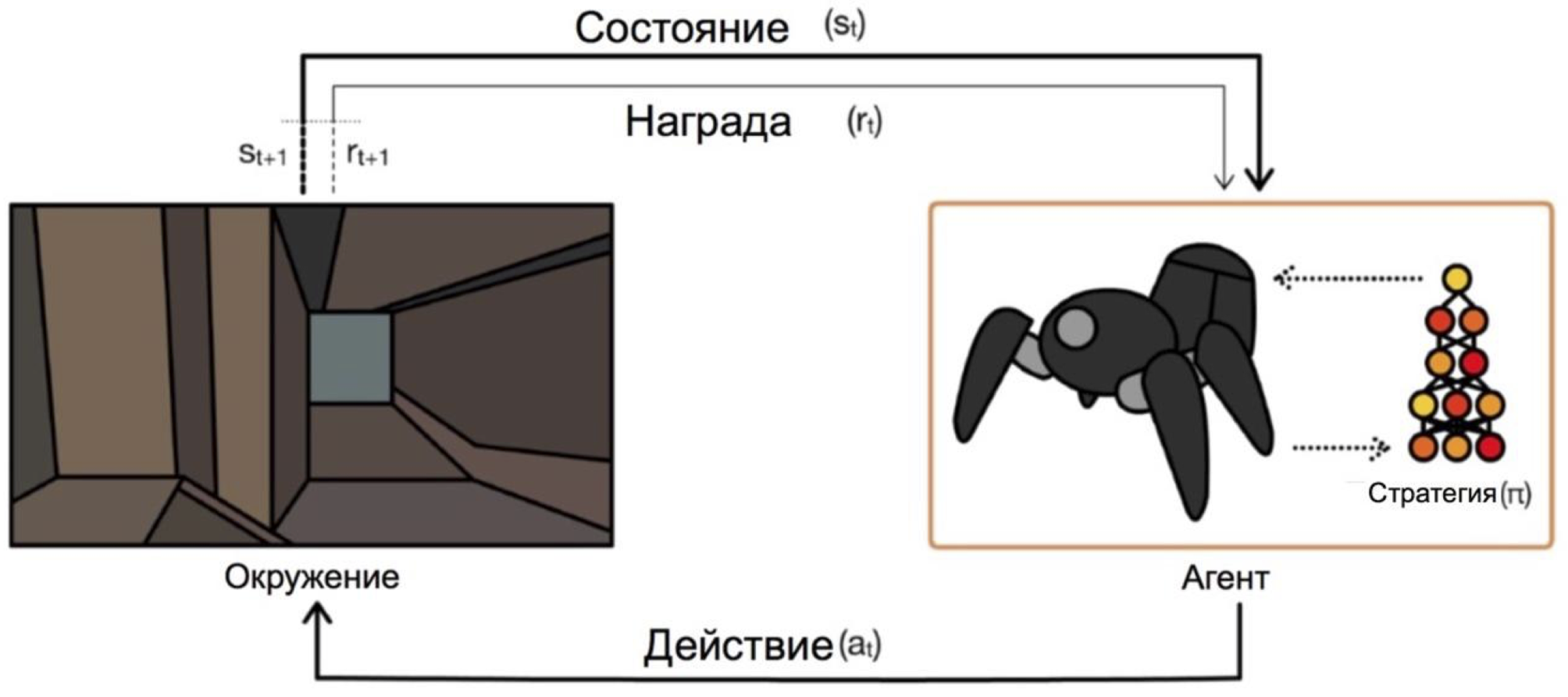
El principal problema en la transición de tareas ficticias / simples (como el mismo laberinto) a tareas reales / prácticas es la siguiente: las recompensas en tales problemas suelen ser muy raras. Si queremos que un agente, por ejemplo, entregue pizza en un mapa de la ciudad, entonces comprenderá que hizo algo bien, solo entregando el pedido a la puerta, y esto sucederá solo si sigue una secuencia de acciones larga y correcta.
Este problema se puede resolver dando al agente al principio ejemplos de cómo "jugar", las llamadas demostraciones de expertos.
Tarea para aprender
El problema modelo que se discutirá en el artículo es Dota 2.
Dota 2 es un popular juego MOBA en el que un equipo de cinco héroes debe derrotar a un equipo contrario destruyendo su "fortaleza". Dota 2 se considera un juego bastante complicado, tiene deportes electrónicos con premios en el torneo principal a $ 25000000 .
Se podía escuchar sobre los recientes éxitos de OpenAI en Dota 2. Primero crearon un bot uno a uno y derrotaron a jugadores profesionales , luego cambiaron a un juego de 5x5 y mostraron resultados impresionantes este verano, aunque perdieron ante equipos profesionales.

El único problema es que entrenaron al agente para un juego uno a uno, según ellos , en 60,000 CPU y 256 GPU K80 en la nube de Azure. Ellos, por supuesto, tienen la oportunidad de ordenar tanto poder. Pero si tienes menos poder, entonces tienes que usar trucos. Uno de esos trucos es el uso de juegos ya jugados por personas.
Demos en el juego
En la mayoría de los casos, las demostraciones se graban artificialmente: simplemente completa una tarea / juega un juego y de alguna manera recopila las acciones que ha realizado. Por lo tanto, recopila algunos datos que pueden integrarse en la capacitación de varias maneras. Hasta ahora lo he hecho, pero cómo exactamente: después de la parte quedará claro el esquema de interacción con el cliente del juego.
Un objetivo más grande y aventurero es obtener más datos del acceso abierto. Una de las razones al elegir Dota 2 para acelerar el aprendizaje fue un recurso como dotabuff . Se recopilan diferentes estadísticas sobre el juego, pero lo que es más importante, hay repeticiones completas de los juegos. Y se pueden ordenar por calificación.
Hasta ahora no he probado cómo los gigabytes de tales datos serán de gran ayuda en comparación con varios episodios. Darse cuenta de que la recopilación de datos fue bastante simple: obtienes enlaces a juegos de dotabuff, descargas juegos y usas el analizador de juegos Dota 2 .
Paquete con el cliente del juego para entrenar
Tenemos un juego Dota 2 cuyo cliente existe bajo las plataformas Windows, Linux y macOS. Pero aún así, generalmente el entrenamiento se lleva a cabo en algún tipo de script de Python, y en él se crea un entorno, ya sea un laberinto, una máquina que sube una colina o algo así. Pero no hay entorno para Dota 2. Por lo tanto, yo mismo tuve que crear este contenedor, que era bastante interesante técnicamente. Resultó hacerlo así:
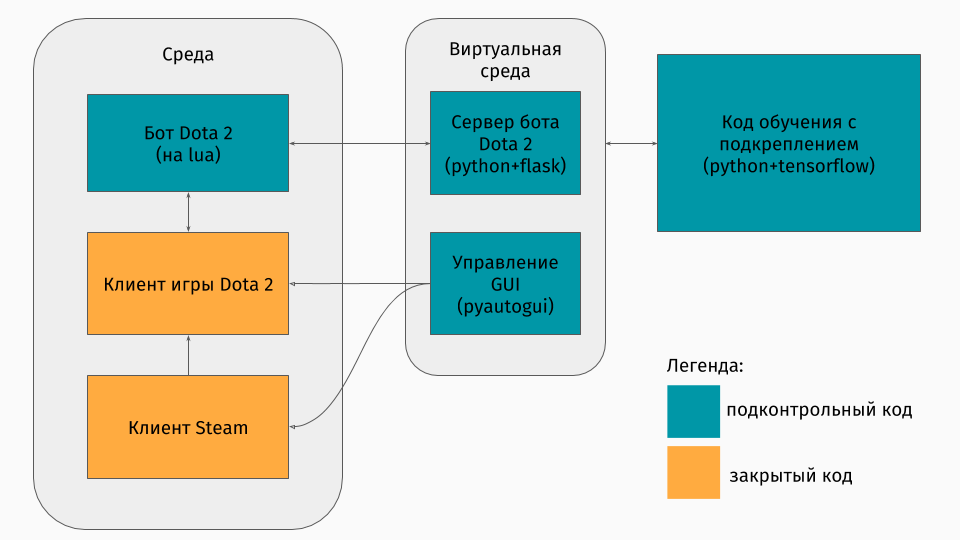
La primera parte es un script para comunicarse con el cliente del juego. Afortunadamente, para Dota 2 hay una API oficial para crear bots: Dota Bot Scripting . Se implementa como inserciones en el lenguaje Lua, que resultó ser popular en el desarrollo de juegos. El script de bot, que interactúa con el cliente del juego, extrae en el momento adecuado la información que nos interesa (por ejemplo, coordenadas en el mapa, posiciones de los oponentes) y envía json al servidor.
La segunda parte es el envoltorio en sí. Está diseñado como un servidor que procesa toda la lógica de iniciar Steam, Dota y recibir json de un script dentro del juego. La gestión del lanzamiento de juegos y clientes se organiza a través de pyautogui , y la comunicación con el lua-insert en el juego es a través del servidor Flask.
La tercera parte consiste en el algoritmo de aprendizaje en sí. Este algoritmo selecciona acciones, recibe los siguientes estados y recompensas del servidor, detrás de los cuales se oculta toda comunicación con el juego, y mejora su comportamiento.
Aprendiendo de expertos
El algoritmo en sí no es particularmente importante en este artículo, porque estas técnicas se pueden usar con cualquier algoritmo. Utilizamos DQN (sobre el que puede leer en el hub ). En esencia, esta es una red neuronal profunda + algoritmo de Q-learning . Sí, este es exactamente el DQN que DeepMind creó para jugar juegos de Atari.
También es más interesante hablar sobre cómo usar juegos anteriores. Intenté dos enfoques: la conformación de recompensas basada en el potencial y consejos de acción.
La idea general de los enfoques es que el agente recibirá una recompensa no solo por los objetivos de la tarea (por ejemplo, al final del laberinto o por escalar la montaña), sino también durante el entrenamiento en cada paso. Esta recompensa adicional mostrará qué tan bien trabaja el agente para lograr el objetivo final. Por supuesto, me gustaría preguntarle automáticamente, y no seleccionar las reglas / condiciones. Los siguientes enfoques ayudan a lograr esto.
La esencia del modelado de recompensas basado en el potencial es que algunos estados nos parecen inicialmente más prometedores que otros, y en base a esto modificamos las recompensas reales que recibe el algoritmo. Lo hacemos así: donde - premio modificado, - la recompensa es real, - factor de descuento del algoritmo de aprendizaje (no muy importante para nosotros), pero y existe nuestro potencial para la condición que visitamos durante . Un ejemplo simple es superar un laberinto.
Supongamos que hay un laberinto en el que queremos pasar de la celda (0,0) a la celda (5,5). Entonces, nuestro potencial para el estado (x, y) puede ser menos la distancia euclidiana de (x, y) a nuestro objetivo (5.5): . Es decir, cuanto más nos acercamos a la línea de meta, mayor es el potencial del estado (por ejemplo, , , ) Entonces motivamos al agente por cualquier medio para que se acerque a la meta.
Para Dota 2, la idea es la misma, pero los potenciales se establecen un poco más complicados:

Imagine que solo queremos pasar por los mismos estados que el demostrador. Entonces, cuantos más estados pasemos, mayor será el potencial. Ponemos el potencial del estado por el porcentaje de finalización de la repetición, si hay una condición cercana a la nuestra. Esto tiene diferentes significados en diversas tareas. Pero es en Dota 2 que esto significa que al principio queremos que el bot llegue al centro (después de todo, al comienzo de las demostraciones solo hay pasos hacia el centro), y luego se mantiene el estado del jugador humano (gran salud, distancia segura a los oponentes, etc. )
El segundo método, el consejo de acción, fue tomado de este artículo . Su esencia es que ahora le aconsejamos al agente no la utilidad de los estados, sino la utilidad de las acciones. Por ejemplo, en nuestro juego Dota 2 puede haber tales consejos: si hay un secuaz enemigo cerca de ti, entonces ataca; si no has llegado al centro, ve en su dirección; si pierdes salud, entonces retírate a tu torre. Y este artículo describe un método para especificar dichos consejos sin que el programador lo piense, automáticamente.
Los potenciales se generan de acuerdo con este principio: potencial de acción capaz de
aumenta en presencia de condiciones relacionadas con el mismo
acción en las manifestaciones Recompensa adicional por la acción en el diagrama de arriba
varía según .
Vale la pena señalar aquí que ya establecemos potenciales para acciones en los estados.
Resultados
Para empezar, noto que el objetivo del juego se simplificó ligeramente, porque lo enseñé todo en mi computadora portátil. El objetivo del agente era infligir tantos ataques como fuera posible, lo que parece un objetivo real en alguna aproximación. Para hacer esto, primero debes llegar al centro del mapa y luego atacar a los oponentes, tratando de no morir. Para acelerar el aprendizaje, solo grabé algunas (1 a 3) demostraciones de dos minutos.
Entrenar a un agente usando cualquiera de los enfoques lleva solo 20 horas en una computadora personal (la mayoría de las veces se necesita para representar un juego de Dota 2), y a juzgar por los gráficos de OpenAI, el entrenamiento en sus servidores lleva varias semanas.
Breve exposición del juego cuando se utiliza el enfoque de modelado de recompensas basado en el potencial:
Y para el enfoque de consejos de acción:
Estas notas fueron hechas a una velocidad de entrenamiento de x10. Las imprecisiones en el comportamiento del agente cuando se muda al centro aún son visibles, pero la lucha en el centro muestra las maniobras aprendidas. Por ejemplo, retirarse con poca salud.
También puede ver las diferencias en los enfoques: con la formación de recompensas basada en el potencial, el agente se mueve sin problemas, porque "Pasa por potencial"; Con consejos de acción, el bot juega de forma más agresiva en el centro, ya que recibe pistas sobre el ataque.
Resumen
Noto de inmediato que algunos puntos se omitieron intencionalmente: qué algoritmo era exactamente, cómo se representaba el estado y si es posible entrenar a un agente para jugar con jugadores reales, etc.
En primer lugar, en este artículo quería mostrar que en el caso del entrenamiento reforzado, no siempre es necesario elegir entre un entorno muy simple (escapar del laberinto) o un costo de entrenamiento muy alto (según mis cálculos superficiales, OpenAI le cuesta a esos servidores el entrenamiento en Azure $ 4715 por hora). Existen técnicas que pueden acelerar el aprendizaje, y solo hablé de una de ellas: el uso de demostraciones. Es importante tener en cuenta que de esta manera no solo repite el demostrador, sino que solo se "empuja". Es importante que con más capacitación el agente tenga la oportunidad de superar a los expertos.
Si está interesado en los detalles, puede encontrar el código del proceso de capacitación en GitHub .