
La tarea principal de los servicios comerciales (y también no comerciales) es estar siempre disponibles para el usuario. Aunque todos fallan, la pregunta es qué hace el equipo de TI para minimizarlos. Tradujimos un artículo de Ben Treynor, Mike Dahlin, Vivek Rau y Betsy Beyer "Cálculo de la confiabilidad del servicio", que dice, incluyendo, usando el ejemplo de Google, por qué el 100% es un punto de referencia incorrecto para el indicador de confiabilidad, cuál es la "regla de los cuatro nueves" y cómo, en la práctica, predecir matemáticamente la viabilidad de interrupciones grandes y pequeñas del servicio y / o sus componentes críticos: la cantidad esperada de tiempo de inactividad, el tiempo que lleva detectar una falla y el tiempo para restaurar el servicio.
Cálculo de la fiabilidad del servicio.
Su sistema es tan confiable como sus componentes.
Ben Trainor, Mike Dalin, Vivec Rau, Betsy Beyer
Como se describe en el libro " Ingeniería de confiabilidad del sitio: confiabilidad y confiabilidad como en Google " (en adelante, el libro SRE), el desarrollo de los productos y servicios de Google puede lograr una alta velocidad de lanzamiento de nuevas funciones, mientras se mantiene un SLO agresivo (objetivos de nivel de servicio, metas de nivel de servicio) ) para garantizar una alta fiabilidad y una respuesta rápida. Los SLO requieren que el servicio esté casi siempre en buenas condiciones y casi siempre rápido. Además, los SLO también indican los valores exactos de este "casi siempre" para un servicio en particular. Los SLO se basan en las siguientes observaciones:
En el caso general, para cualquier servicio o sistema de software, 100% es el punto de referencia incorrecto para el indicador de confiabilidad, ya que ningún usuario puede notar la diferencia entre 100% y 99,999% de disponibilidad. Entre el usuario y el servicio hay muchos otros sistemas (su computadora portátil, Wi-Fi doméstico, proveedor, fuente de alimentación ...), y todos estos sistemas en conjunto están disponibles no en el 99.999% de los casos, pero con mucha menos frecuencia. Por lo tanto, la diferencia entre 99.999% y 100% se pierde debido a factores aleatorios causados por la inaccesibilidad de otros sistemas, y el usuario no obtiene ningún beneficio por el hecho de que dedicamos mucho esfuerzo para lograr esta última fracción de un porcentaje de disponibilidad del sistema. ¡Serias excepciones a esta regla son los sistemas de control de frenos antibloqueo y los marcapasos!
Para una discusión detallada de cómo los SLO se relacionan con los SLI (indicadores de nivel de servicio) y los SLA (acuerdos de nivel de servicio), consulte el capítulo Nivel de servicio objetivo de SRE. Este capítulo también describe en detalle cómo seleccionar métricas que sean relevantes para un servicio o sistema en particular, lo que a su vez determina la elección del SLO apropiado para ese servicio o sistema.
Este artículo amplía el tema de SLO para centrarse en los componentes del servicio. En particular, examinaremos cómo la confiabilidad de los componentes críticos afecta la confiabilidad de un servicio, así como también cómo diseñar sistemas para mitigar el impacto o reducir la cantidad de componentes críticos.
La mayoría de los servicios ofrecidos por Google están destinados a proporcionar el 99,99 por ciento (a veces llamado "cuatro nueves") accesibilidad para los usuarios. Para algunos servicios, se indica un número menor en el acuerdo del usuario, sin embargo, el objetivo 99.99% se almacena dentro de la empresa. Esta barra más alta ofrece una ventaja en situaciones en las que los usuarios se quejan del desempeño del servicio mucho antes de la violación de los términos del acuerdo, ya que el objetivo número 1 del equipo de SRE es hacer que los usuarios estén contentos con los servicios. Para muchos servicios, un objetivo interno del 99,99% representa el término medio, que equilibra el costo, la complejidad y la confiabilidad. Para algunos otros, en particular los servicios globales en la nube, el objetivo interno es 99.999%.
Fiabilidad 99.99%: observaciones y conclusiones
Veamos algunas observaciones y conclusiones clave sobre el diseño y la operación del servicio con una confiabilidad del 99.99%, y luego pasemos a la práctica.
Observación # 1: Causas de fallas
Las fallas ocurren por dos razones principales: problemas con el servicio en sí y problemas con los componentes críticos del servicio. Un componente crítico es un componente que, en caso de falla, causa una falla correspondiente en la operación de todo el servicio.
Observación No. 2: Matemáticas de confiabilidad
La confiabilidad depende de la frecuencia y duración del tiempo de inactividad. Se mide a través de:
- Frecuencia inactiva, o inversa de la misma: MTTF (tiempo medio de falla).
- Tiempo de inactividad, MTTR (tiempo medio de reparación). El tiempo de inactividad está determinado por el tiempo del usuario: desde el comienzo del mal funcionamiento hasta la reanudación del funcionamiento normal del servicio.
Por lo tanto, la fiabilidad se define matemáticamente como MTTF / (MTTF + MTTR) utilizando las unidades apropiadas.
Conclusión # 1: Regla de nueves extra
Un servicio no puede ser más confiable que todos sus componentes críticos combinados. Si su servicio busca garantizar la disponibilidad a un nivel de 99.99%, entonces todos los componentes críticos deberían estar disponibles significativamente más del 99.99% del tiempo.
Dentro de Google, utilizamos la siguiente regla general: los componentes críticos deben proporcionar nueves adicionales en comparación con la confiabilidad reclamada de su servicio, en el ejemplo anterior, disponibilidad del 99.999 por ciento, porque cualquier servicio tendrá varios componentes críticos, así como sus propios problemas específicos. Esto se llama la "regla de nueves extra".
Si tiene un componente crítico que no proporciona suficientes nueves (¡un problema relativamente común!), Debe minimizar las consecuencias negativas.
Conclusión No. 2: Matemáticas de frecuencia, tiempo de detección y tiempo de recuperación.
Un servicio no puede ser más confiable que el producto de la frecuencia de incidentes y el tiempo de detección y recuperación. Por ejemplo, tres paradas totales por año de 20 minutos cada una conducen a un total de 60 minutos de tiempo de inactividad. Incluso si el servicio funcionara perfectamente el resto del año, la confiabilidad del 99.99 por ciento (no más de 53 minutos de tiempo de inactividad por año) sería imposible.
Esta es una observación matemática simple, pero a menudo se pasa por alto.
Conclusión de las conclusiones No. 1 y No. 2
Si no se puede lograr el nivel de confiabilidad en el que se basa su servicio, se deben hacer esfuerzos para rectificar la situación, ya sea aumentando la disponibilidad del servicio o minimizando las consecuencias negativas, como se describió anteriormente. Reducir las expectativas (es decir, la confiabilidad declarada) también es una opción, y a menudo la más verdadera: deje en claro al servicio que depende de usted que debe reconstruir su sistema para compensar el error en la confiabilidad de su servicio o reducir sus propios objetivos de nivel de servicio . Si usted mismo no elimina la discrepancia, una falla lo suficientemente larga del sistema inevitablemente requerirá ajustes.
Aplicación práctica
Veamos un ejemplo de un servicio con una confiabilidad objetivo del 99.99% y resolvamos los requisitos tanto para sus componentes como para sus fallas.
Figuras
Suponga que su servicio del 99.99 por ciento está disponible con las siguientes características:
- Un corte mayor y tres cortes menores por año. Suena aterrador, pero tenga en cuenta que un nivel de confianza del 99.99% implica un tiempo de inactividad a gran escala de 20-30 minutos y algunas paradas breves por año. (Las matemáticas indican que: a) la falla de un segmento no se considera una falla de todo el sistema desde el punto de vista de SLO, yb) la confiabilidad total se calcula por la suma de la confiabilidad de los segmentos).
- Cinco componentes críticos en forma de otros servicios independientes con 99.999% de confiabilidad.
- Cinco segmentos independientes que no pueden fallar uno tras otro.
- Todos los cambios se llevan a cabo gradualmente, un segmento a la vez.
El cálculo matemático de la confiabilidad será el siguiente:
Requerimientos de componentes
- El límite de error total para el año es 0.01 por ciento de 525,600 minutos por año, o 53 minutos (basado en el año de 365 días, en el peor de los casos).
- El límite asignado para el apagado de componentes críticos es cinco componentes críticos independientes con un límite de 0.001% cada uno = 0.005%; 0.005% de 525,600 minutos por año, o 26 minutos.
- El límite de error restante de su servicio es 53-26 = 27 minutos.
Requisitos de respuesta de apagado
- Tiempo de inactividad esperado: 4 (1 apagado completo y 3 paradas que afectan solo a un segmento)
- El efecto acumulativo de los cortes esperados: (1 × 100%) + (3 × 20%) = 1.6
- Detección de fallas y recuperación después de esto: 27 / 1.6 = 17 minutos
- Tiempo asignado a la supervisión para detectar una falla y notificar al respecto: 2 minutos
- Tiempo otorgado al especialista de turno para comenzar a analizar la alerta: 5 minutos. (El sistema de monitoreo debe rastrear las infracciones de SLO y enviar una señal al localizador de turno cada vez que se produce un bloqueo del sistema. Muchos servicios de Google son respaldados por ingenieros de turno de turno de turno SR que responden preguntas urgentes)
- Tiempo restante para minimizar efectivamente los efectos adversos: 10 minutos
Conclusión: apalancamiento para aumentar la confiabilidad del servicio
Vale la pena mirar cuidadosamente las cifras presentadas, porque enfatizan el punto fundamental: hay tres palancas principales para aumentar la confiabilidad del servicio.
- Reduzca la frecuencia de las interrupciones: a través de políticas de lanzamiento, pruebas, evaluaciones periódicas de la estructura del proyecto, etc.
- Reduzca su tiempo de inactividad promedio con segmentación, aislamiento geográfico, degradación gradual o aislamiento del cliente.
- Reduzca el tiempo de recuperación: con monitoreo, operaciones de rescate con un botón (por ejemplo, retroceder a un estado anterior o agregar energía de reserva), prácticas de preparación operativa, etc.
Puede equilibrar estos tres métodos para simplificar la implementación de la tolerancia a fallas. Por ejemplo, si es difícil lograr un MTTR de 17 minutos, concéntrese en reducir el tiempo de inactividad promedio. Las estrategias para minimizar los efectos adversos y mitigar los efectos de los componentes críticos se analizan con más detalle más adelante en este artículo.
Aclaración "Reglas para nueves adicionales" para componentes anidados
Un lector aleatorio puede concluir que cada enlace adicional en la cadena de dependencias requiere nueve adicionales, por lo que se requieren dos nueve adicionales para las dependencias de segundo orden, se necesitan tres nueve adicionales para las dependencias de tercer orden, etc.
Esta es la conclusión incorrecta. Se basa en un modelo ingenuo de una jerarquía de componentes en forma de árbol con una ramificación constante en cada nivel. En dicho modelo, como se muestra en la Fig. 1, hay 10 componentes únicos de primer orden, 100 componentes únicos de segundo orden, 1,000 componentes únicos de tercer orden, etc., lo que resulta en un total de 1,111 servicios únicos, incluso si la arquitectura está limitada a cuatro capas. Un ecosistema de servicios altamente confiables con tantos componentes críticos independientes es claramente poco realista.
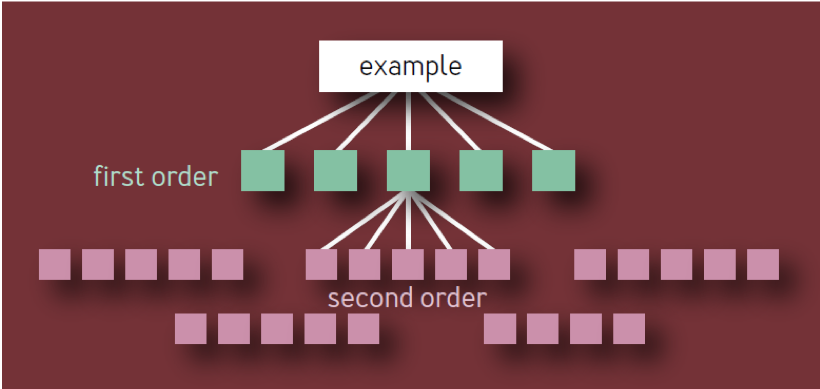
Fig. 1 - Jerarquía de componentes: modelo no válido
Un componente crítico en sí mismo puede causar la falla de todo el servicio (o segmento de servicio), independientemente de dónde se encuentre en el árbol de dependencias. Por lo tanto, si un componente dado de X se muestra como una dependencia de varios componentes de primer orden, X debe contarse solo una vez, ya que su falla finalmente conducirá a una falla del servicio, independientemente de cuántos servicios intermedios también se vean afectados.
Una lectura correcta de la regla es la siguiente:
- Si un servicio tiene N componentes críticos únicos, cada uno de ellos contribuye con 1 / N a la falta de fiabilidad de todo el servicio causado por este componente, sin importar cuán bajo sea en la jerarquía de componentes.
- Cada componente debe contarse solo una vez, incluso si aparece varias veces en la jerarquía de componentes (en otras palabras, solo se cuentan los componentes únicos). Por ejemplo, al calcular los componentes del Servicio A en la Fig. 2, el Servicio B debe considerarse solo una vez.
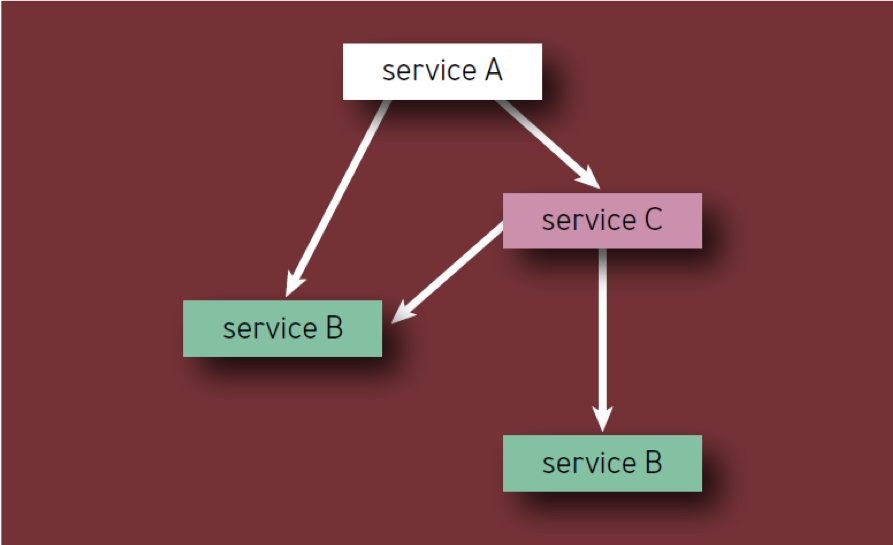
Fig. 2 - Componentes en la jerarquía
Por ejemplo, considere un servicio hipotético A con un límite de error de 0.01 por ciento. Los propietarios de servicios están listos para gastar la mitad de este límite en sus propios errores y pérdidas, y la mitad en componentes críticos. Si el servicio tiene N de dichos componentes, cada uno de ellos recibe 1 / N del límite de error restante. Los servicios típicos a menudo tienen de 5 a 10 componentes críticos y, por lo tanto, cada uno de ellos puede rechazar solo una décima o una vigésima parte del límite de error del Servicio A. Por lo tanto, como regla, las partes críticas del servicio deben tener una confiabilidad adicional de nueve.
Límites de error
El concepto de límites de error se trata con cierto detalle en el libro SRE, pero aquí debe mencionarse. Los ingenieros de Google SR usan límites de error para equilibrar la confiabilidad y el ritmo de las actualizaciones. Este límite determina el nivel aceptable de falla para el servicio por un cierto período de tiempo (generalmente un mes). El límite de error es solo 1 menos el SLO del servicio, por lo que el servicio disponible del 99,99 por ciento mencionado anteriormente tiene un "límite" de 0,01% en la falta de fiabilidad. Hasta que el servicio haya agotado su límite de error dentro de un mes, el equipo de desarrollo es libre (dentro de lo razonable) para lanzar nuevas funciones, actualizaciones, etc.
Si el límite de error se agota, los cambios en el servicio se suspenden (con la excepción de arreglos de seguridad urgentes y cambios destinados a causar la violación en primer lugar) hasta que el servicio reponga la reserva en el límite de error o hasta que cambie el mes. Muchos servicios en Google utilizan un método de ventana deslizante para SLO para que el límite de error se restablezca gradualmente. Para servicios serios con un SLO de más del 99.99%, es aconsejable usar un reinicio cero trimestral en lugar de uno mensual, porque la cantidad de tiempo de inactividad permitido es pequeña.
Los límites de error eliminan la tensión entre los departamentos que de otro modo podrían surgir entre los ingenieros de SR y los desarrolladores de productos, proporcionándoles una herramienta común de evaluación de riesgos basada en datos para lanzar un producto. También les dan a los ingenieros de SR y a los equipos de desarrollo un objetivo común para desarrollar métodos y tecnologías que les permitan innovar más rápido y lanzar productos sin un "presupuesto abultado".
Reducción de componentes críticos y estrategias de mitigación
En este punto, en este artículo, hemos establecido lo que se puede llamar la "Regla de oro para la confiabilidad de los componentes" . Esto significa que la confiabilidad de cualquier componente crítico debe ser 10 veces mayor que el nivel objetivo de confiabilidad de todo el sistema para que su contribución a la falta de confiabilidad del sistema permanezca en el nivel de error. De ello se deduce que, en el caso ideal, la tarea es hacer que la mayor cantidad posible de componentes no sean críticos. Esto significa que los componentes pueden cumplir con un nivel más bajo de confiabilidad, brindando a los desarrolladores la oportunidad de innovar y asumir riesgos.
La estrategia más simple y obvia para reducir las dependencias críticas es eliminar puntos únicos de falla siempre que sea posible. Un sistema más grande debería poder funcionar de manera aceptable sin ningún componente dado que no sea una dependencia crítica o SPOF.
De hecho, lo más probable es que no pueda deshacerse de todas las dependencias críticas; pero puede seguir algunas pautas de diseño del sistema para optimizar la confiabilidad. Aunque esto no siempre es posible, es más fácil y más eficiente lograr una alta confiabilidad del sistema si establece la confiabilidad en las etapas de diseño y planificación, y no después de que el sistema funcione y afecte a los usuarios reales.
Evaluación de la estructura del proyecto.
Al planificar un nuevo sistema o servicio, o al rediseñar o mejorar un sistema o servicio existente, una revisión de la arquitectura o proyecto puede revelar una infraestructura común, así como dependencias internas y externas.
Infraestructura compartida
Si su servicio usa una infraestructura compartida (por ejemplo, el servicio de base de datos principal utilizado por varios productos disponibles para los usuarios), considere si esta infraestructura se usa correctamente. Identifique claramente a los propietarios de la infraestructura compartida como participantes adicionales del proyecto. Además, tenga cuidado con las sobrecargas de componentes: para hacerlo, coordine cuidadosamente el proceso de inicio con los propietarios de estos componentes.
Dependencias internas y externas
A veces, un producto o servicio depende de factores fuera del control de su empresa, por ejemplo, de bibliotecas de software o servicios y datos de terceros. La identificación de estos factores minimizará las consecuencias impredecibles de su uso.
Planificar y diseñar sistemas cuidadosamente
Al diseñar su sistema, preste atención a los siguientes principios:
Redundancia y aislamiento.
Puede intentar reducir el impacto del componente crítico creando varias instancias independientes del mismo. Por ejemplo, si el almacenamiento de datos en una instancia garantiza el 99.9 por ciento de disponibilidad de estos datos, el almacenamiento de tres copias en tres copias ampliamente distribuidas proporcionará, en teoría, un nivel de disponibilidad de 1 a 0.013 o nueve nueves si la instancia falla independientemente con cero correlación.
En el mundo real, la correlación nunca es cero (considere las fallas de la red troncal que afectan a muchas celdas al mismo tiempo), por lo que la confiabilidad real nunca se acercará a nueve nueves, pero superará con creces las tres nueves.
Del mismo modo, enviar un RPC (llamada a procedimiento remoto) a un grupo de servidores en el mismo clúster puede proporcionar una disponibilidad del 99 por ciento de los resultados, mientras que enviar tres RPC simultáneos a tres grupos de servidores diferentes y aceptar la primera respuesta ayudará a alcanzar el nivel de disponibilidad más alto que tres nueves (ver arriba). Esta estrategia también puede acortar la cola del retraso del tiempo de respuesta si los grupos de servidores son equidistantes del remitente RPC. (Dado que el costo de enviar tres RPC al mismo tiempo es alto, Google a menudo asigna estratégicamente el tiempo para estas llamadas: la mayoría de nuestros sistemas esperan parte del tiempo asignado antes de enviar el segundo RPC y un poco más de tiempo antes de enviar el tercer RPC).
Reserva y su aplicación
Configure el inicio y la portabilidad del software para que los sistemas continúen funcionando cuando las partes individuales fallen (a prueba de fallas) y se aíslen cuando ocurran problemas. El principio básico aquí es que cuando conecte a la persona para activar la reserva, es probable que exceda su límite de error.
Asincronía
Para evitar que los componentes se vuelvan críticos, diséñelos de forma asíncrona siempre que sea posible. Si un servicio espera una respuesta RPC de una de sus partes no críticas, lo que muestra una fuerte desaceleración en el tiempo de respuesta, esta desaceleración empeorará innecesariamente el rendimiento del servicio principal. Al configurar el RPC para un componente no crítico en modo asíncrono, se liberará el tiempo de respuesta del servicio principal al rendimiento de este componente. Y aunque la asincronía puede complicar el código y la infraestructura del servicio, todavía vale la pena este compromiso.
Planificación de recursos
Asegúrese de que todos los componentes tengan todo lo que necesita. , — .
, \ .
, . . . , .
SLO. , , . , , , MTTR .
, . :
, , , . :
, : , , . — , . , , , .
, . , Google , 10 .
Conclusión
Si bien los lectores probablemente estén familiarizados con algunos o muchos de los conceptos descritos en este artículo, los ejemplos específicos de su uso los ayudarán a comprender mejor su esencia y transmitir este conocimiento a otros. Nuestras recomendaciones no son simples, pero no inalcanzables. Varios servicios de Google han demostrado repetidamente confiabilidad más allá de cuatro nueves, no debido a esfuerzos o inteligencia sobrehumanos, sino debido a la aplicación cuidadosa de principios y mejores prácticas desarrolladas durante muchos años (ver SRE, Apéndice B: Pautas prácticas para servicios en operaciones industriales).