Hace poco más de un año con mi participación, tuvo lugar el siguiente "diálogo":
Aplicación .Net : Hola Entity Framework, ¡por favor, dame muchos datos!
Entity Framework : lo siento, no te entendí. A que te refieres
Aplicación .Net : Sí, acabo de recibir una colección de 100k transacciones. Y ahora necesitamos verificar rápidamente la exactitud de los precios de los valores que se indican allí.
Entity Framework : Ahh, bueno, intentemos ...
Aplicación .Net : Aquí está el código:
var query = from p in context.Prices join t in transactions on new { p.Ticker, p.TradedOn, p.PriceSourceId } equals new { t.Ticker, t.TradedOn, t.PriceSourceId } select p; query.ToList();
Marco de la entidad :

Clásico Creo que muchas personas están familiarizadas con esta situación: cuando realmente quiero "maravillosamente" y hacer una búsqueda rápida en la base de datos utilizando JOIN de la colección local y DbSet . Por lo general, esta experiencia es decepcionante.
En este artículo (que es una traducción gratuita de mi otro artículo ) llevaré a cabo una serie de experimentos e intentaré diferentes formas de sortear esta limitación. Habrá un código (sin complicaciones), pensamientos y algo así como un final feliz.
Introduccion
Todos conocen el Entity Framework , muchos lo usan todos los días, y hay muchos buenos artículos sobre cómo cocinarlo correctamente (use consultas más simples, use los parámetros en Omitir y Tomar, use VIEW, solicite solo los campos necesarios, monitoree el almacenamiento en caché de consultas y otros), sin embargo, el tema JOIN de la colección local y DbSet sigue siendo un punto débil.
Desafío
Suponga que hay una base de datos con precios y hay una colección de transacciones para las cuales necesita verificar la exactitud de los precios. Y supongamos que tenemos el siguiente código.
var localData = GetDataFromApiOrUser(); var query = from p in context.Prices join s in context.Securities on p.SecurityId equals s.SecurityId join t in localData on new { s.Ticker, p.TradedOn, p.PriceSourceId } equals new { t.Ticker, t.TradedOn, t.PriceSourceId } select p; var result = query.ToList();
Este código no funciona en Entity Framework 6 en absoluto. En Entity Framework Core , funciona, pero todo se hará en el lado del cliente y en el caso de que haya millones de registros en la base de datos, esta no es una opción.
Como dije, intentaré diferentes formas de evitar esto. De simple a complejo. Para mis experimentos, uso el código del siguiente repositorio . El código se escribe usando: C # , .Net Core , EF Core y PostgreSQL .
También tomé algunas métricas: tiempo dedicado y consumo de memoria. Descargo de responsabilidad: si la prueba se realizó durante más de 10 minutos, la interrumpí (la restricción es de arriba). Máquina de prueba Intel Core i5, 8 GB de RAM, SSD.
Esquema de base de datos
Solo 3 tablas: precios , valores y fuentes de precios . Precios : contiene 10 millones de entradas.
Método 1. Ingenuo
Comencemos de manera simple y usemos el siguiente código:
Código para el método 1 var result = new List<Price>(); using (var context = CreateContext()) { foreach (var testElement in TestData) { result.AddRange(context.Prices.Where( x => x.Security.Ticker == testElement.Ticker && x.TradedOn == testElement.TradedOn && x.PriceSourceId == testElement.PriceSourceId)); } }
La idea es simple: en un bucle leemos los registros de la base de datos de uno en uno y los agregamos a la colección resultante. Este código solo tiene una ventaja: la simplicidad. Y un inconveniente es la baja velocidad: incluso si hay un índice en la base de datos, la mayoría de las veces tomará comunicación con el servidor de la base de datos. Las métricas son las siguientes:
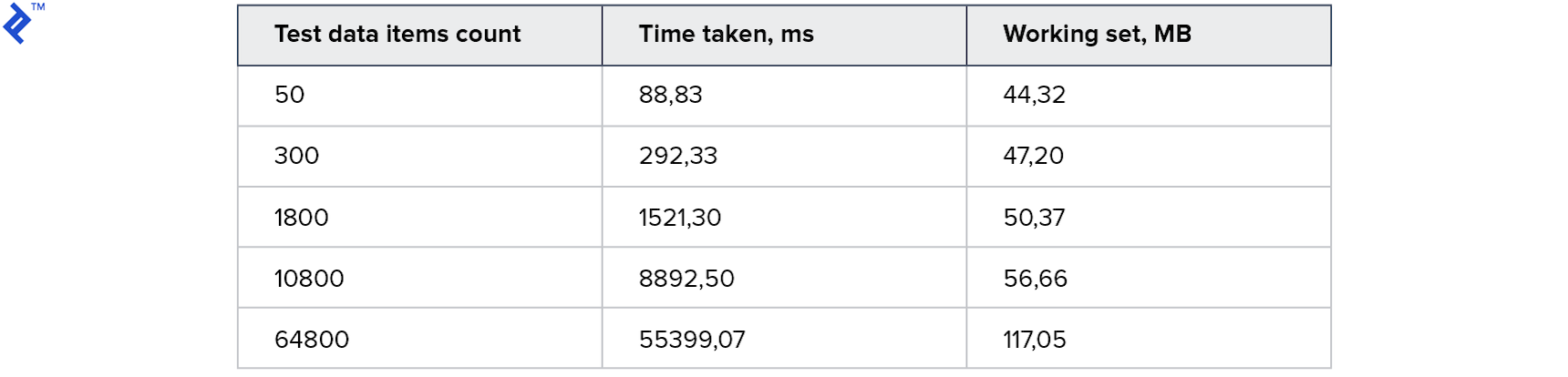
El consumo de memoria es pequeño. Una gran colección lleva 1 minuto. Para empezar, no está mal, pero lo quiero más rápido.
Método 2: paralelo ingenuo
Intentemos agregar paralelismo. La idea es acceder a la base de datos desde múltiples hilos.
Código para el método 2 var result = new ConcurrentBag<Price>(); var partitioner = Partitioner.Create(0, TestData.Count); Parallel.ForEach(partitioner, range => { var subList = TestData.Skip(range.Item1) .Take(range.Item2 - range.Item1) .ToList(); using (var context = CreateContext()) { foreach (var testElement in subList) { var query = context.Prices.Where( x => x.Security.Ticker == testElement.Ticker && x.TradedOn == testElement.TradedOn && x.PriceSourceId == testElement.PriceSourceId); foreach (var el in query) { result.Add(el); } } } });
Resultado:
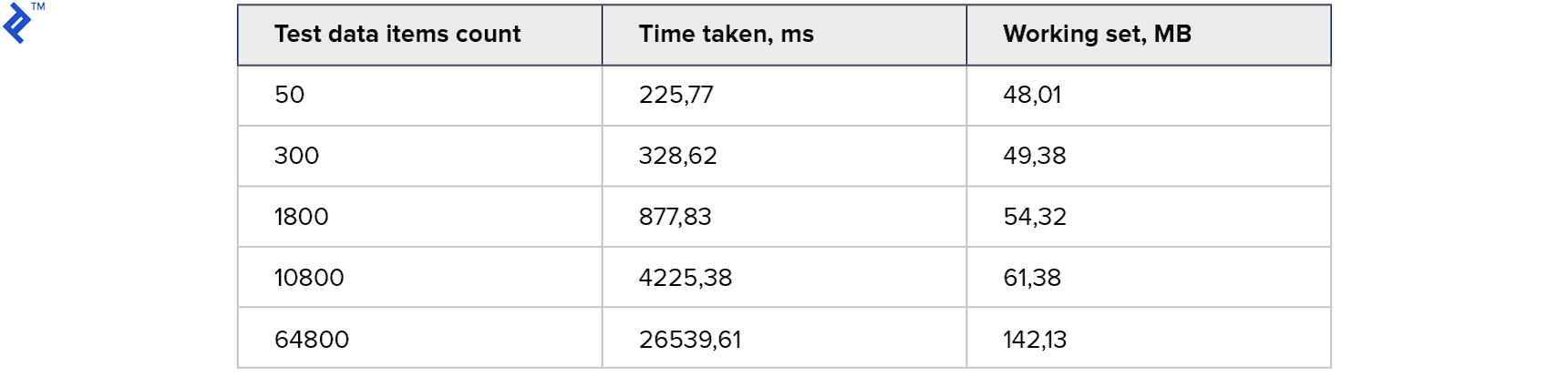
Para colecciones pequeñas, este enfoque es aún más lento que el primer método. Y para los más grandes: 2 veces más rápido. Curiosamente, se generaron 4 hilos en mi máquina, pero esto no condujo a una aceleración 4x. Esto sugiere que la sobrecarga en este método es significativa: tanto en el lado del cliente como en el lado del servidor. El consumo de memoria ha aumentado, pero no significativamente.
Método 3: contiene múltiples
Es hora de intentar otra cosa e intentar reducir la tarea a una sola consulta. Se puede hacer de la siguiente manera:
- Prepare 3 colecciones únicas de Ticker , PriceSourceId y Date
- Ejecute la solicitud y use 3 Contiene
- Vuelva a verificar los resultados localmente
Código para el método 3 var result = new List<Price>(); using (var context = CreateContext()) {
El problema aquí es que el tiempo de ejecución y la cantidad de datos devueltos dependen en gran medida de los datos en sí (tanto en la consulta como en la base de datos). Es decir, solo puede devolver un conjunto de datos necesarios, y pueden devolverse registros adicionales (incluso 100 veces más).
Esto puede explicarse utilizando el siguiente ejemplo. Supongamos que hay la siguiente tabla con datos:

Supongamos también que necesito precios para Ticker1 con TradedOn = 2018-01-01 y para Ticker2 con TradedOn = 2018-01-02 .
Entonces valores únicos para Ticker = ( Ticker1 , Ticker2 )
Y valores únicos para TradedOn = ( 2018-01-01 , 2018-01-02 )
Sin embargo, se devolverán 4 registros como resultado, porque realmente corresponden a estas combinaciones. Lo malo es que cuantos más campos se usen, mayores serán las posibilidades de obtener registros adicionales como resultado.
Por esta razón, los datos obtenidos por este método deben filtrarse adicionalmente en el lado del cliente. Y este es el mayor inconveniente.
Las métricas son las siguientes:
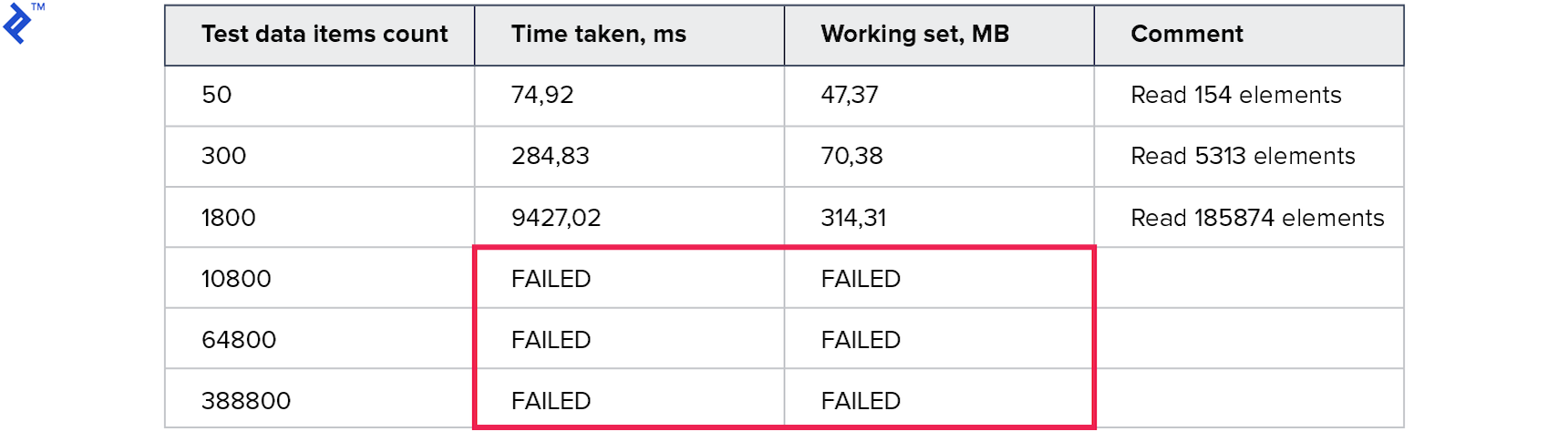
El consumo de memoria es peor que todos los métodos anteriores. El número de líneas leídas es muchas veces mayor que el número solicitado. Las pruebas para colecciones grandes se interrumpieron porque se ejecutaron durante más de 10 minutos. Este método no es bueno.
Método 4. Constructor de predicados
Probémoslo del otro lado: la vieja y buena expresión . Utilizándolos, puede crear 1 consulta grande en el siguiente formulario:
… (.. AND .. AND ..) OR (.. AND .. AND ..) OR (.. AND .. AND ..) …
Esto da la esperanza de que será posible construir 1 solicitud y obtener solo los datos necesarios para 1 llamada. Código:
Código para el método 4 var result = new List<Price>(); using (var context = CreateContext()) { var baseQuery = from p in context.Prices join s in context.Securities on p.SecurityId equals s.SecurityId select new TestData() { Ticker = s.Ticker, TradedOn = p.TradedOn, PriceSourceId = p.PriceSourceId, PriceObject = p }; var tradedOnProperty = typeof(TestData).GetProperty("TradedOn"); var priceSourceIdProperty = typeof(TestData).GetProperty("PriceSourceId"); var tickerProperty = typeof(TestData).GetProperty("Ticker"); var paramExpression = Expression.Parameter(typeof(TestData)); Expression wholeClause = null; foreach (var td in TestData) { var elementClause = Expression.AndAlso( Expression.Equal( Expression.MakeMemberAccess( paramExpression, tradedOnProperty), Expression.Constant(td.TradedOn) ), Expression.AndAlso( Expression.Equal( Expression.MakeMemberAccess( paramExpression, priceSourceIdProperty), Expression.Constant(td.PriceSourceId) ), Expression.Equal( Expression.MakeMemberAccess( paramExpression, tickerProperty), Expression.Constant(td.Ticker)) )); if (wholeClause == null) wholeClause = elementClause; else wholeClause = Expression.OrElse(wholeClause, elementClause); } var query = baseQuery.Where( (Expression<Func<TestData, bool>>)Expression.Lambda( wholeClause, paramExpression)).Select(x => x.PriceObject); result.AddRange(query); }
El código resultó ser más complicado que en los métodos anteriores. La creación manual de Expression no es la operación más fácil y rápida.
Métricas:
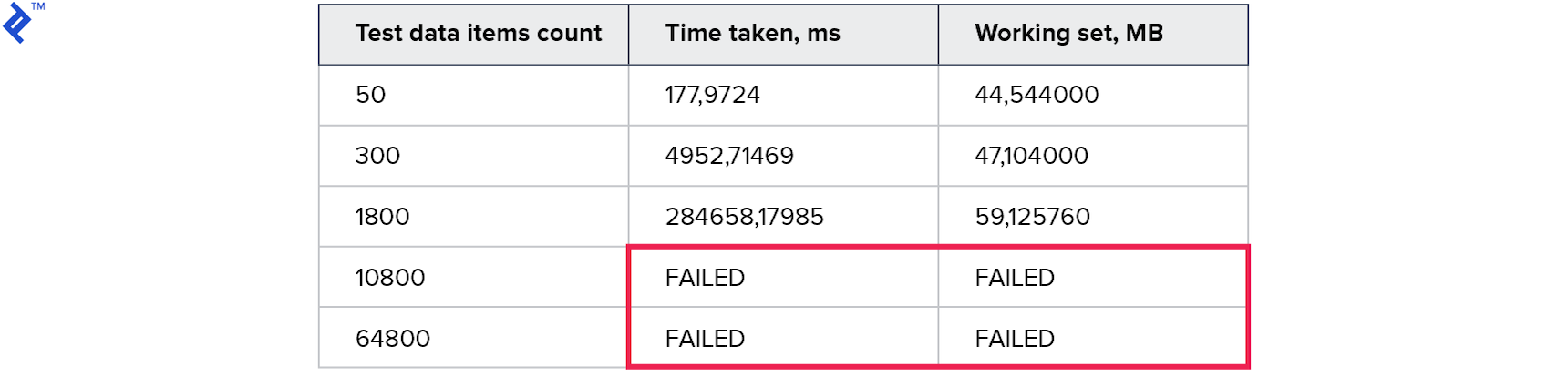
Los resultados temporales fueron incluso peores que en el método anterior. Parece que la sobrecarga durante la construcción y al caminar a través del árbol resultó ser mucho más que la ganancia de usar una solicitud.
Método 5: tabla de datos de consulta compartida
Probemos con otra opción:
Creé una nueva tabla en la base de datos en la que escribiré los datos necesarios para completar la solicitud (implícitamente, necesito un nuevo DbSet en el contexto).
Ahora, para obtener el resultado que necesita:
- Iniciar transacción
- Subir datos de consulta a una nueva tabla
- Ejecute la consulta en sí (usando la nueva tabla)
- Revertir una transacción (para borrar la tabla de datos para consultas)
El código se ve así:
Código para el método 5 var result = new List<Price>(); using (var context = CreateContext()) { context.Database.BeginTransaction(); var reducedData = TestData.Select(x => new SharedQueryModel() { PriceSourceId = x.PriceSourceId, Ticker = x.Ticker, TradedOn = x.TradedOn }).ToList();
Primeras métricas:
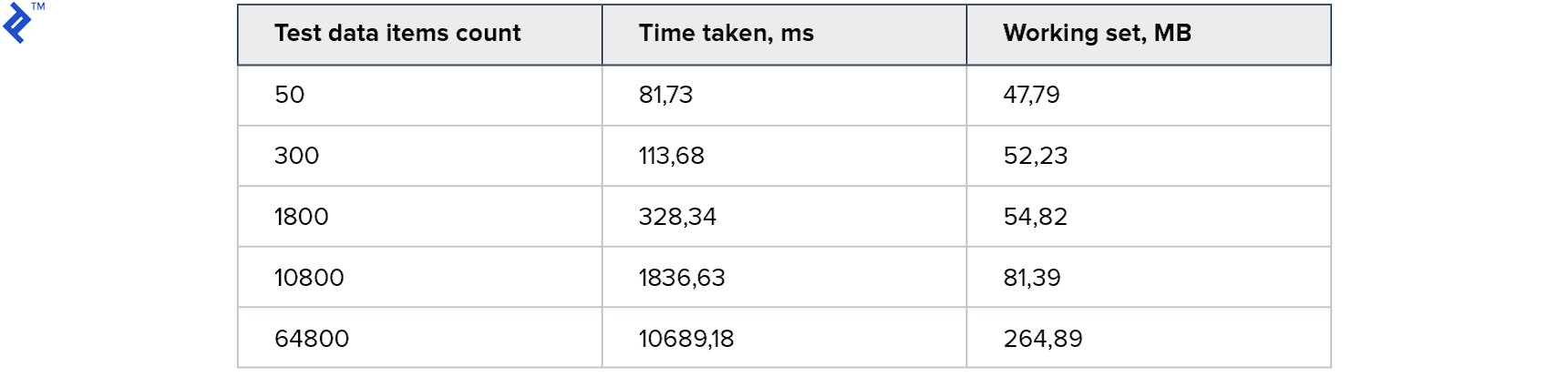
¡Todas las pruebas funcionaron y funcionaron rápidamente! El consumo de memoria también es aceptable.
Por lo tanto, mediante el uso de una transacción, esta tabla puede ser utilizada simultáneamente por varios procesos. Y dado que esta es una tabla real existente, todas las características de Entity Framework están disponibles para nosotros: solo necesita cargar los datos en la tabla, crear una consulta usando JOIN y ejecutarla. A primera vista, esto es lo que necesita, pero hay desventajas significativas:
- Debe crear una tabla para un tipo específico de consulta.
- Es necesario usar transacciones (y desperdiciar recursos DBMS en ellas)
- Y la idea de que necesitas ESCRIBIR algo, cuando necesitas LEER, parece extraña. Y en Read Replica, simplemente no funcionará.
Y el resto es una solución más o menos funcional que ya se puede utilizar.
Método 6. Extensión MemoryJoin
Ahora puede intentar mejorar el enfoque anterior. Los pensamientos son:
- En lugar de usar una tabla que sea específica para un tipo de consulta, puede usar alguna opción generalizada. A saber, cree una tabla con un nombre como shared_query_data , y agregue varios campos Guid , varios Long , varios String , etc. Se pueden tomar nombres simples: Guid1 , Guid2 , String1 , Long1 , Date2 , etc. Entonces esta tabla se puede usar para el 95% de los tipos de consulta. Los nombres de propiedades se pueden "ajustar" más tarde utilizando la perspectiva Seleccionar .
- A continuación, debe agregar un DbSet para shared_query_data .
- Pero, ¿qué sucede si, en lugar de escribir datos en la base de datos, pasar valores utilizando la construcción VALUES ? Es decir, es necesario que en la consulta SQL final, en lugar de acceder a shared_query_data, haya una apelación a VALUES . Como hacerlo
- En Entity Framework Core, solo usando FromSql .
- En Entity Framework 6, debe usar DbInterception , es decir, cambiar el SQL generado agregando la construcción VALUES justo antes de la ejecución. Esto dará como resultado una limitación: en una sola solicitud, no más de una construcción VALUES . ¡Pero funcionará!
- Como no vamos a escribir en la base de datos, obtenemos la tabla shared_query_data creada en el primer paso, ¿no es necesaria? Respuesta: sí, no es necesario, pero DbSet todavía es necesario, ya que Entity Framework debe conocer el esquema de datos para generar consultas. Resulta que necesitamos un DbSet para algún modelo generalizado que no existe en la base de datos y se usa solo para inspirar el Entity Framework, que sabe lo que está haciendo.
Convertir IEnumerable a IQueryable Ejemplo- La entrada recibió una colección de objetos del siguiente tipo:
class SomeQueryData { public string Ticker {get; set;} public DateTimeTradedOn {get; set;} public int PriceSourceId {get; set;} }
- Tenemos a nuestra disposición DbSet con los campos String1 , String2 , Date1 , Long1 , etc.
- Deje que Ticker se almacene en String1 , TradedOn en Date1 y PriceSourceId en Long1 ( int mapps en long , para no hacer que los campos para int y long se separen)
- Entonces FromSql + VALUES será así:
var query = context.QuerySharedData.FromSql( "SELECT * FROM ( VALUES (1, 'Ticker1', @date1, @id1), (2, 'Ticker2', @date2, @id2) ) AS __gen_query_data__ (id, string1, date1, long1)")
- Ahora puede hacer una proyección y devolver un IQueryable conveniente usando el mismo tipo que estaba en la entrada:
return query.Select(x => new SomeQueryData() { Ticker = x.String1, TradedOn = x.Date1, PriceSourceId = (int)x.Long1 });
Logré implementar este enfoque e incluso diseñarlo como un paquete NuGet EntityFrameworkCore.MemoryJoin (el código también está disponible). A pesar de que el nombre contiene la palabra Core , Entity Framework 6 también es compatible. Lo llamé MemoryJoin , pero de hecho envía datos locales al DBMS en la construcción VALUES y todo el trabajo se realiza en él.
El código es el siguiente:
Código para el método 6 var result = new List<Price>(); using (var context = CreateContext()) {
Métricas:
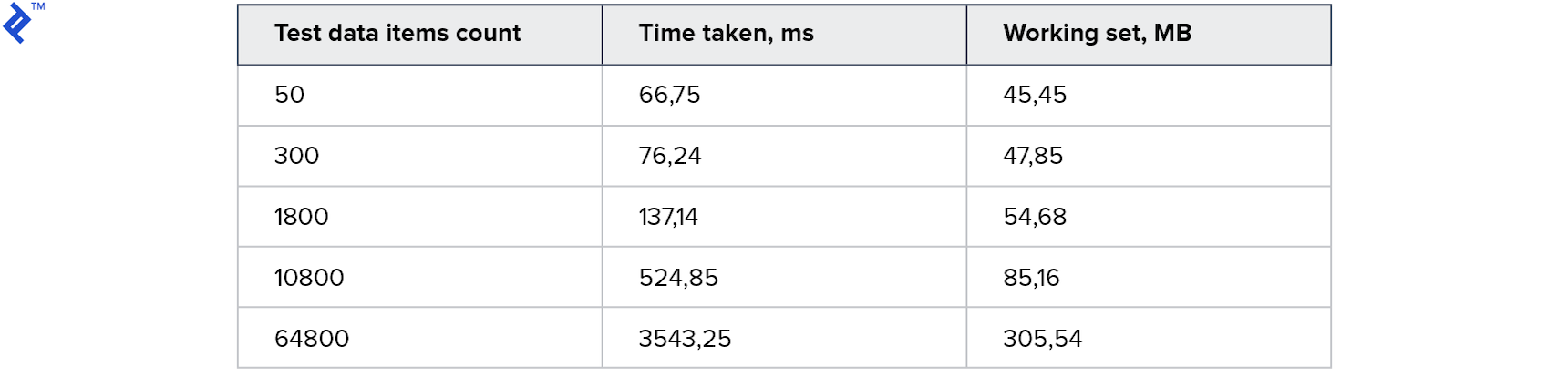
Este es el mejor resultado que he probado. El código era muy simple y directo, y al mismo tiempo funcionaba para Read Replica.
Un ejemplo de una solicitud generada para recibir 3 elementos. SELECT "p"."PriceId", "p"."ClosePrice", "p"."OpenPrice", "p"."PriceSourceId", "p"."SecurityId", "p"."TradedOn", "t"."Ticker", "t"."TradedOn", "t"."PriceSourceId" FROM "Price" AS "p" INNER JOIN "Security" AS "s" ON "p"."SecurityId" = "s"."SecurityId" INNER JOIN ( SELECT "x"."string1" AS "Ticker", "x"."date1" AS "TradedOn", CAST("x"."long1" AS int4) AS "PriceSourceId" FROM ( SELECT * FROM ( VALUES (1, @__gen_q_p0, @__gen_q_p1, @__gen_q_p2), (2, @__gen_q_p3, @__gen_q_p4, @__gen_q_p5), (3, @__gen_q_p6, @__gen_q_p7, @__gen_q_p8) ) AS __gen_query_data__ (id, string1, date1, long1) ) AS "x" ) AS "t" ON (("s"."Ticker" = "t"."Ticker") AND ("p"."PriceSourceId" = "t"."PriceSourceId")
Aquí también puede ver cómo el modelo generalizado (con los campos String1 , Date1 , Long1 ) que usa Select se convierte en el que se usa en el código (con los campos Ticker , TradedOn , PriceSourceId ).
Todo el trabajo se realiza en 1 consulta en el servidor SQL. Y este es un pequeño final feliz, del que hablé al principio. Sin embargo, el uso de este método requiere comprensión y los siguientes pasos:
- Necesita agregar un DbSet adicional a su contexto (aunque se puede omitir la tabla en sí)
- En el modelo generalizado, que se usa por defecto, se declaran 3 campos de tipo Guid , String , Double , Long , Date , etc. Eso debería ser suficiente para el 95% de los tipos de solicitud. Y si pasa una colección de objetos con 20 campos a FromLocalList , se lanzará una Excepción , que indica que el objeto es demasiado complejo. Esta es una restricción suave y se puede eludir: puede declarar su tipo y agregar al menos 100 campos allí. Sin embargo, más campos son más lentos para trabajar.
- Más detalles técnicos se describen en mi artículo .
Conclusión
En este artículo, presenté mis pensamientos sobre el tema de JOIN local collection y DbSet. Me pareció que mi desarrollo usando VALUES podría ser de interés para la comunidad. Al menos no conocí ese enfoque cuando resolví este problema yo mismo. Personalmente, este método me ayudó a superar una serie de problemas de rendimiento en mis proyectos actuales, tal vez también lo ayude.
Alguien dirá que el uso de MemoryJoin es demasiado "abstruso" y debe desarrollarse aún más, y hasta entonces no es necesario usarlo. Esta es exactamente la razón por la que tenía muchas dudas y durante casi un año no escribí este artículo. Estoy de acuerdo en que me gustaría que fuera más fácil (espero que algún día lo haga), pero también digo que la optimización nunca ha sido tarea de Juniors. La optimización siempre requiere una comprensión de cómo funciona la herramienta. Y si hay una oportunidad de obtener una aceleración de ~ 8 veces ( Naive Parallel vs MemoryJoin ), entonces dominaría 2 puntos y documentación.
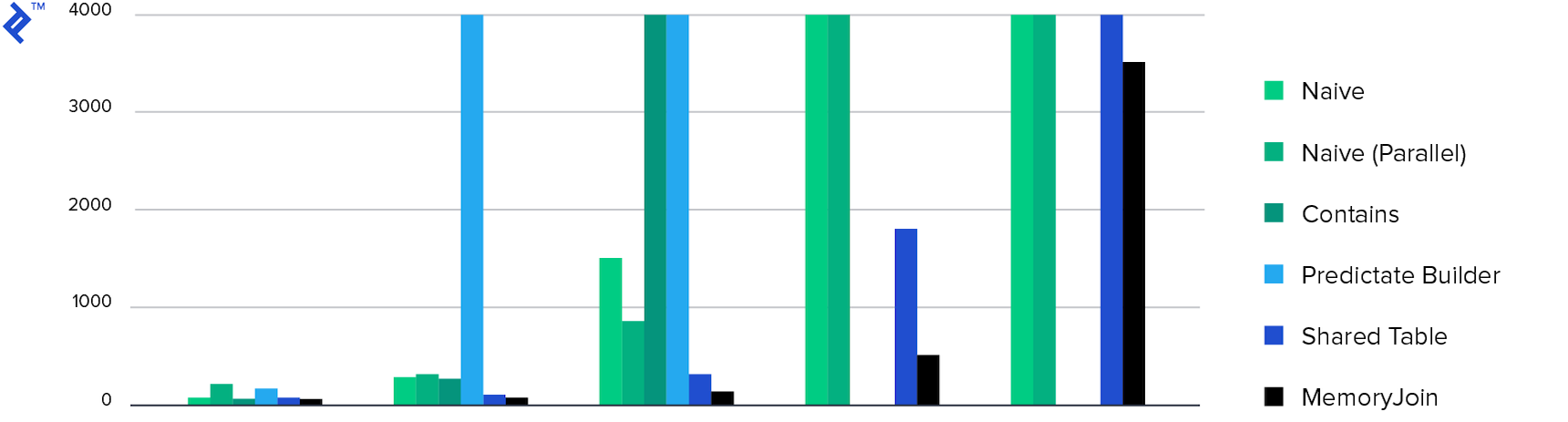
Y finalmente, los diagramas:
Tiempo gastado Solo 4 métodos completaron la tarea en menos de 10 minutos, y MemoryJoin es la única forma de completar la tarea en menos de 10 segundos.
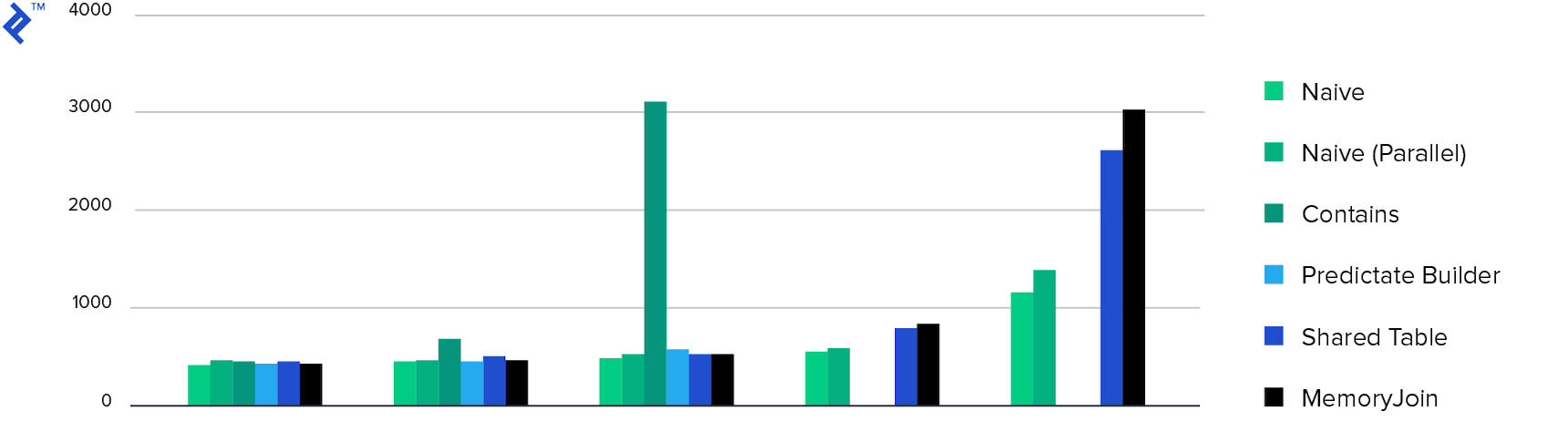
Consumo de memoria. Todos los métodos mostraron aproximadamente el mismo consumo de memoria, a excepción de los contenidos múltiples . Esto se debe a la cantidad de datos devueltos.
Gracias por leer!