 La clasificación de texto
La clasificación de texto es una de las tareas más comunes en
PNL y en la capacitación de maestros, cuando el conjunto de datos contiene documentos de texto y se usan etiquetas para entrenar al clasificador de texto.
Desde el punto de vista de la PNL, la tarea de clasificar el texto se lleva a cabo entrenando la representación a nivel de palabra usando la inserción de palabras y luego entrenando la representación a nivel de texto utilizada como una función para la clasificación.
El tipo de métodos basados en codificación ignora pequeños detalles y claves para la clasificación (ya que la representación general a nivel de texto se estudia comprimiendo las representaciones a nivel de palabra).
 Métodos basados en codificación para clasificar texto con coincidencia de nivel de texto
Métodos basados en codificación para clasificar texto con coincidencia de nivel de textoEXAMEN - Nuevo método de clasificación de texto
Investigadores de la Universidad de Shandong y la Universidad Nacional de Singapur han
propuesto un nuevo modelo de clasificación de texto que incluye señales de coincidencia de nivel de palabra en la tarea de clasificación de texto. Su método utiliza un mecanismo de interacción para introducir sugerencias detalladas a nivel de palabra en el proceso de clasificación.
Para resolver el problema de incluir señales de correspondencia de nivel de palabra más precisas, los investigadores propusieron
calcular explícitamente las estimaciones de correspondencia entre palabras y clases .
La idea principal es calcular la matriz de interacción a partir de una representación a nivel de palabra que llevará las claves correspondientes a nivel de palabra. Cada entrada en esta matriz es una evaluación de la correspondencia entre una palabra y una clase específica.
La estructura de clasificación de texto propuesta llamada EXAM - Modelo de interacción explícito (
GitHub ), contiene tres componentes principales:
- codificador de nivel de palabra,
- capa de interacción y
- capa de agregación.
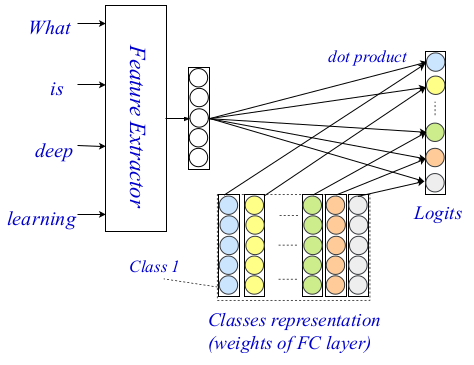
Esta arquitectura de tres niveles le permite codificar y clasificar texto utilizando señales y sugerencias pequeñas y generalizadas. Toda la arquitectura se muestra en la imagen a continuación.
 Arquitectura EXAM
Arquitectura EXAMEn el pasado, los codificadores de nivel de palabra se han investigado ampliamente en la comunidad de PNL, y han aparecido codificadores muy potentes. Los autores utilizan el método sovermenny como codificador de nivel de palabra, y en su trabajo describen en detalle otros dos componentes de su arquitectura: el nivel de interacción y agregación.
La capa de interacción, la contribución principal y la novedad en el método propuesto se basan en el conocido mecanismo de interacción. Los investigadores usan una
matriz de presentación capacitada para codificar cada una de las clases para que luego puedan calcular las estimaciones de interacción entre las clases. Los puntajes finales se fijan usando un producto puntual en función de la interacción entre la palabra objetivo y cada clase. No se consideraron funciones más complejas debido a la mayor complejidad de los cálculos.
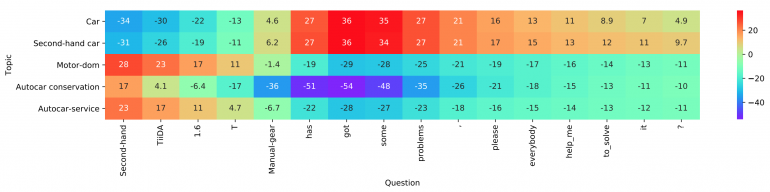 Visualización de la capa
Visualización de la capaFinalmente, usan un MLP de dos capas simple y completamente conectado como capa de agregación. También mencionan que aquí se puede usar un nivel de agregación más complejo, que incluye CNN o LSTM. MLP se utiliza para calcular los logits de clasificación final utilizando la matriz de interacción y las codificaciones de nivel de palabra. La entropía cruzada se utiliza en función de la pérdida para la optimización.
Grados
Para evaluar el marco propuesto para la clasificación de texto, los investigadores realizaron extensos experimentos en condiciones de múltiples clases y etiquetas múltiples. Muestran que su método es muy superior a los métodos modernos relevantes y modernos.
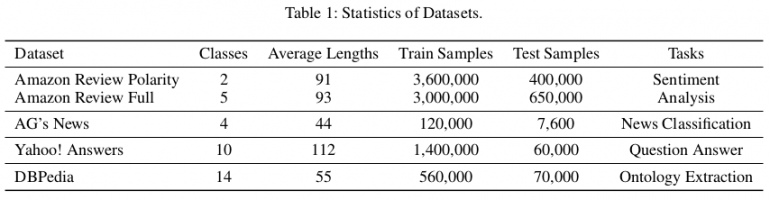 Estadísticas de conjuntos de datos usados para evaluación
Estadísticas de conjuntos de datos usados para evaluaciónPara la evaluación, establecen tres tipos básicos diferentes de modelos:
- Modelos basados en el desarrollo de atributos;
- Modelos profundos basados en personajes
- Profundos modelos basados en palabras.
Los autores utilizaron conjuntos de datos de referencia disponibles públicamente (Zhang, Zhao y LeCun 2015) para evaluar el método propuesto. En total, hay seis conjuntos de datos de texto de clasificación que corresponden a las tareas de análisis de estados de ánimo, clasificación de noticias, preguntas y respuestas, y extracción de ontologías, respectivamente. En el artículo, muestran que EXAM logra el mejor rendimiento entre tres conjuntos de datos: AG, Yah. A. y DBP. La evaluación y la comparación con otros métodos se pueden ver en las tablas a continuación.
![Test Set Accuracy [%] en tareas de clasificación de documentos de varias clases y comparación con otros métodos](https://habrastorage.org/getpro/habr/post_images/de7/8d8/b60/de78d8b6017c9624c347b0fb645ae0ae.png)

Conclusiones
Este trabajo es una contribución importante al campo del procesamiento del lenguaje natural (PNL). Este es el primer trabajo que introduce sugerencias de coincidencia de nivel de palabra más precisas en la clasificación de texto en modelos de redes neuronales profundas. El modelo propuesto proporciona indicadores de vanguardia para varios conjuntos de datos.
Traducción - Stanislav Litvinov