El primer comentario sobre el notable artículo
Visión subjetiva de un lenguaje de programación ideal resultó ser una referencia al
lenguaje de programación Zig . Naturalmente, se volvió interesante qué tipo de lenguaje es el que dice ser un nicho de C ++, D y Rust. Miré, el lenguaje parecía bonito y algo interesante. Buena sintaxis tipo si, enfoque original para el manejo de errores, corutinas incorporadas. Este artículo es una breve descripción de la
documentación oficial entremezclada con sus propios pensamientos e impresiones de ejemplos de código en ejecución.
Empezando
Instalar el compilador es bastante simple, para Windows, simplemente descomprima el paquete de distribución en alguna carpeta. Creamos el archivo de texto hello.zig en la misma carpeta, insertamos el código de la documentación allí y lo guardamos. El montaje se realiza mediante el comando
zig build-exe hello.zig
después de lo cual hello.exe aparece en el mismo directorio.
Además del ensamblaje, el modo de prueba de la unidad está disponible, para esto, los bloques de prueba se usan en el código, y el ensamblaje y el lanzamiento de las pruebas se llevan a cabo mediante el comando
zig test hello.zig
Primeras rarezas
El compilador no admite saltos de línea de Windows (\ r \ n). Por supuesto, el hecho de que los saltos de línea en cada sistema (Win, Nix, Mac) sean algunos de los suyos es lo salvaje y una reliquia del pasado. Pero no hay nada que hacer, así que solo seleccione, por ejemplo, en Notepad ++ el formato que desea para el compilador.
La segunda rareza que encontré por accidente: ¡las pestañas no son compatibles con el código! Solo espacios. Pero sucede :)
Sin embargo, esto está escrito honestamente en la documentación: la verdad ya está al final.
Comentarios
Otra rareza es que Zig no admite comentarios de varias líneas. Recuerdo que todo se hizo correctamente en el antiguo turbo pascal: se admitieron comentarios anidados de varias líneas. Aparentemente, desde entonces, ningún desarrollador de idiomas ha dominado algo tan simple :)
Pero hay comentarios documentales. Comience con ///. Debe estar en ciertos lugares, delante de los objetos correspondientes (variables, funciones, clases ...). Si están en otro lugar, un error de compilación. No esta mal.
Declaración variable
Hecho en el estilo de moda ahora (e ideológicamente correcto), cuando la palabra clave (const o var) se escribe primero, luego el nombre, luego opcionalmente el tipo y luego el valor inicial. Es decir La inferencia automática de tipos está disponible. Las variables deben inicializarse: si no especifica un valor inicial, habrá un error de compilación. Sin embargo, se proporciona un valor indefinido especial, que puede usarse explícitamente para especificar variables no inicializadas.
var i:i32 = undefined;
Salida de la consola
Para los experimentos, necesitamos salida a la consola; en todos los ejemplos, este es el método utilizado. En el campo de los complementos
const warn = std.debug.warn;
y el código está escrito así:
warn("{}\n{}\n", false, "hi");
El compilador tiene algunos errores, que informa honestamente cuando intenta generar un número entero o un número de coma flotante de esta manera:
error: error del compilador: los literales enteros y flotantes en la función var args deben ser convertidos. github.com/ziglang/zig/issues/557
Tipos de datos
Tipos primitivos
Los nombres de los tipos aparentemente se toman de Rust (i8, u8, ... i128, u128), también hay tipos especiales para compatibilidad binaria C, 4 tipos de tipos de punto flotante (f16, f32, f64, f128). Hay un tipo bool. Hay un tipo de vacío de longitud cero y un retorno especial, que discutiremos más adelante.
También puede construir tipos enteros de cualquier longitud en bits del 1 al 65535. El nombre del tipo comienza con la letra i o u, y luego se escribe la longitud en bits.
// ! var j:i65535 = 0x0123456789ABCDEF0123456789ABCDEF0123456789ABCDEF0123456789ABCDEF;
Sin embargo, no pude obtener este valor en la consola: se produjo un error en el LLVM durante el proceso de compilación.
En general, esta es una solución interesante, aunque ambigua (en mi humilde opinión: admitir literales numéricos exactamente largos en el nivel del compilador es correcto, pero nombrar los tipos de esta manera no es muy bueno, es mejor hacerlo honestamente a través de un tipo de plantilla). ¿Y por qué es el límite 65535? ¿Las bibliotecas como GMP no parecen imponer tales restricciones?
Literales de cadena
Estas son matrices de caracteres (sin cero al final). Para literales con un cero final, se usa el prefijo 'c'.
const normal_bytes = "hello"; const null_terminated_bytes = c"hello";
Como la mayoría de los idiomas, Zig admite secuencias de escape estándar e inserta caracteres Unicode a través de sus códigos (\ uNNNN, \ UNNNNNN donde N es un dígito hexadecimal).
Los literales de varias líneas se forman utilizando dos barras invertidas al comienzo de cada línea. No se requieren comillas. Es decir, algunos intentos de hacer cadenas sin formato, pero en mi humilde opinión no tiene éxito, la ventaja de las cadenas sin formato es que puede insertar cualquier parte del texto desde cualquier parte del código, e idealmente no cambie nada, pero aquí debe agregar \\ al comienzo de cada línea.
const multiline = \\#include <stdio.h> \\ \\int main(int argc, char **argv) { \\ printf("hello world\n"); \\ return 0; \\} ;
Literales enteros
Todo está en lenguajes tipo si. Estaba muy contento de que para los literales octales, se usa el prefijo 0o, y no solo cero, como en C. Los literales binarios con el prefijo 0b también son compatibles. Los literales de coma flotante pueden ser hexadecimales (como se hace en
la extensión GCC ).
Operaciones
Por supuesto, hay operaciones C aritméticas, lógicas y bit a bit estándar. Se admiten operaciones abreviadas (+ = etc.). En lugar de && y || Las palabras clave y y o se utilizan. Un punto interesante es que las operaciones con semántica envolvente garantizada también son compatibles. Se ven así:
a +% b a +%= b
En este caso, las operaciones aritméticas ordinarias no garantizan el desbordamiento y sus resultados durante el desbordamiento se consideran indefinidos (y se generan errores de compilación para las constantes). En mi humilde opinión esto es un poco extraño, pero aparentemente está hecho de algunas consideraciones profundas de compatibilidad con la semántica del lenguaje C.
Matrices
Los literales de matriz se ven así:
const msg = []u8{ 'h', 'e', 'l', 'l', 'o' }; const arr = []i32{ 1, 2, 3, 4 };
Las cadenas son matrices de caracteres, como en C. Indización clásica con corchetes. Se proporcionan las operaciones de adición (concatenación) y multiplicación de matrices. Es algo muy interesante, y si todo está claro con la concatenación, luego la multiplicación: seguí esperando hasta que alguien implementara esto, y ahora espero :) En Assembler (!) Existe una operación duplicada que le permite generar datos duplicados. Ahora en Zig:
const one = []i32{ 1, 2, 3, 4 }; const two = []i32{ 5, 6, 7, 8 }; const c = one ++ two; // { 1,2,3,4,5,6,7,8 } const pattern = "ab" ** 3; // "ababab"
Punteros
La sintaxis es similar a C.
var x: i32 = 1234; // const x_ptr = &x; //
Para desreferenciar (tomar valores por puntero), se utiliza una operación inusual de postfix:
x_ptr.* == 5678; x_ptr.* += 1;
El tipo de puntero se establece explícitamente estableciendo un asterisco delante del nombre del tipo
const x_ptr : *i32 = &x;
Rodajas (rodajas)
Una estructura de datos integrada en el lenguaje que le permite hacer referencia a una matriz o parte de ella. Contiene un puntero al primer elemento y el número de elementos. Se ve así:
var array = []i32{ 1, 2, 3, 4 }; const slice = array[0..array.len];
Parece haber sido tomado de Go, no estoy seguro. Y tampoco estoy seguro de si valía la pena incrustarlo en un lenguaje, mientras que la implementación en cualquier lenguaje OOP de tal cosa es muy elemental.
Estructuras
Una forma interesante de declarar una estructura: se declara una constante, cuyo tipo se muestra automáticamente como "tipo" (tipo), y es el que se usa como nombre de la estructura. Y la estructura misma (struct) es "sin nombre".
const Point = struct { x: f32, y: f32, };
Es imposible especificar un nombre de la manera habitual en lenguajes tipo C, sin embargo, el compilador muestra el nombre del tipo de acuerdo con ciertas reglas, en particular, en el caso considerado anteriormente, coincidirá con el nombre de la constante "tipo".
En general, el lenguaje no garantiza el orden de los campos y su alineación en la memoria. Si se necesitan garantías, entonces se deben usar estructuras "empaquetadas".
const Point2 = packed struct { x: f32, y: f32, };
Inicialización: al estilo de los designadores de Sishny:
const p = Point { .x = 0.12, .y = 0.34, };
Las estructuras pueden tener métodos. Sin embargo, colocar un método en una estructura es simplemente usar la estructura como un espacio de nombres; a diferencia de C ++, no se pasan implícitamente estos parámetros.
Traslados
En general, lo mismo que en C / C ++. Existen algunos medios integrados convenientes para acceder a la metainformación, por ejemplo, el número de campos y sus nombres, implementados por macros de sintaxis incorporados en el lenguaje (que se denominan funciones integradas en la documentación).
Para "compatibilidad binaria con C" se proporcionan algunas enumeraciones externas.
Para indicar el tipo que debería ser la base de la enumeración, una construcción del formulario
packed enum(u8)
donde u8 es el tipo base.
Las enumeraciones pueden tener métodos similares a las estructuras (es decir, usar un nombre de enumeración como espacio de nombres).
Sindicatos
Según tengo entendido, la unión en Zig es una suma de tipo algebraica, es decir contiene un campo de etiqueta oculto que determina cuál de los campos de unión está "activo". La "activación" de otro campo se realiza mediante una reasignación completa de toda la asociación. Ejemplo de documentación
const assert = @import("std").debug.assert; const mem = @import("std").mem; const Payload = union { Int: i64, Float: f64, Bool: bool, }; test "simple union" { var payload = Payload {.Int = 1234}; // payload.Float = 12.34; // ! assert(payload.Int == 1234); // payload = Payload {.Float = 12.34}; assert(payload.Float == 12.34); }
Los sindicatos también pueden usar explícitamente enumeraciones para la etiqueta.
// Unions can be given an enum tag type: const ComplexTypeTag = enum { Ok, NotOk }; const ComplexType = union(ComplexTypeTag) { Ok: u8, NotOk: void, };
Los sindicatos, como las enumeraciones y las estructuras, también pueden proporcionar su propio espacio de nombres para los métodos.
Tipos opcionales
Zig tiene soporte opcional incorporado. Se agrega un signo de interrogación antes del nombre del tipo:
const normal_int: i32 = 1234; // normal integer const optional_int: ?i32 = 5678; // optional integer
Curiosamente, Zig implementa una cosa sobre la posibilidad que sospechaba, pero no estaba seguro de si era correcta o no. Los punteros se hacen compatibles con las opciones sin agregar un campo oculto adicional ("etiqueta"), que almacena un signo de la validez del valor; y nulo se usa como un valor no válido. Por lo tanto, los tipos de referencia representados en Zig por punteros ni siquiera requieren memoria adicional para "opcionalidad". Al mismo tiempo, está prohibido asignar valores nulos a punteros regulares.
Tipos de error
Son similares a los tipos opcionales, pero en lugar de la etiqueta booleana ("realmente inválida"), se utiliza un elemento de enumeración correspondiente al código de error. La sintaxis es similar a las opciones, se agrega un signo de exclamación en lugar de un signo de interrogación. Por lo tanto, estos tipos se pueden usar, por ejemplo, para regresar de las funciones: se devuelve el resultado del objeto de la operación exitosa de la función o se devuelve un error con el código correspondiente. Los tipos de error son una parte importante del sistema de manejo de errores del lenguaje Zig; para más detalles, consulte la sección Manejo de errores.
Tipo vacío
Variables como anulación y operaciones con ellas son posibles en Zig
var x: void = {}; var y: void = {}; x = y;
no se genera código para tales operaciones; Este tipo es principalmente útil para la metaprogramación.
También hay un tipo c_void para compatibilidad con C.
Operadores de control y funciones
Estos incluyen: bloques, cambiar, mientras, para, si, si no, romper, continuar. Para agrupar el código, se utilizan llaves estándar. Solo los bloques, como en C / C ++, se utilizan para limitar el alcance de las variables. Los bloques pueden considerarse como expresiones. No hay goto en el lenguaje, pero hay etiquetas que se pueden usar con las declaraciones break y continue. Por defecto, estos operadores trabajan con bucles; sin embargo, si un bloque tiene una etiqueta, puede usarlo.
var y: i32 = 123; const x = blk: { y += 1; break :blk y; // blk y };
La declaración de cambio difiere del operador en que no tiene "caída", es decir solo se ejecuta una condición (caso) y se cierra el conmutador. La sintaxis es más compacta: en lugar de mayúsculas, se usa la flecha "=>". Switch también se puede considerar una expresión.
Las declaraciones while y if son generalmente las mismas que en todos los lenguajes tipo C. La declaración for es más como foreach. Todos ellos pueden considerarse como expresiones. De las nuevas características, while y for, así como if, pueden tener un bloque else que se ejecuta si no hubo iteración de bucle.
Y aquí es el momento de hablar sobre una característica común para el cambio, mientras que, de alguna manera, está prestado del concepto de bucles foreach: variables de "captura". Se ve así:
while (eventuallyNullSequence()) |value| { sum1 += value; } if (opt_arg) |value| { assert(value == 0); } for (items[0..1]) |value| { sum += value; }
Aquí, el argumento while es una cierta "fuente" de datos, que puede ser opcional, por ejemplo, para una matriz o un segmento, y una variable ubicada entre dos líneas verticales contiene un valor "expandido", es decir, el elemento actual de la matriz o segmento (o un puntero a él), el valor interno del tipo opcional (o un puntero a él).
Diferir y errar declaraciones
La declaración de ejecución diferida prestada de Go. Funciona de la misma manera: el argumento de este operador se ejecuta al salir del ámbito en el que se utiliza el operador. Además, se proporciona el operador errdefer, que se activa si la función devuelve un tipo de error con un código de error activo. Esto es parte del sistema original de manejo de errores Zig.
Operador inalcanzable
El elemento de la programación del contrato. Una palabra clave especial, que se coloca donde la administración no debe venir bajo ninguna circunstancia. Si llega allí, entonces en los modos Debug y ReleaseSafe se genera un pánico, y en ReleaseFast el optimizador arroja estas ramas por completo.
noreturn
Técnicamente, es un tipo compatible en expresiones con cualquier otro tipo. Esto es posible debido a que un objeto de este tipo nunca volverá. Dado que los operadores son expresiones en Zig, se necesita un tipo especial para expresiones que nunca se evaluarán. Esto sucede cuando el lado derecho de la expresión transfiere irrevocablemente el control a un lugar externo. A tales declaraciones se rompen, continúan, regresan, inalcanzables, bucles infinitos y funciones que nunca devuelven el control. A modo de comparación, una llamada a una función regular (control de retorno) no es un operador de retorno, porque aunque el control se transfiere al exterior, tarde o temprano se devolverá al punto de llamada.
Por lo tanto, las siguientes expresiones se vuelven posibles:
fn foo(condition: bool, b: u32) void { const a = if (condition) b else return; @panic("do something with a"); }
La variable a obtiene el valor devuelto por la instrucción if / else. Para esto, las partes (tanto if como else) deben devolver una expresión del mismo tipo. La parte if devuelve bool, la parte else es del tipo noreturn, que es técnicamente compatible con cualquier tipo, como resultado, el código se compila sin errores.
Las funciones
La sintaxis es clásica para idiomas de este tipo:
fn add(a: i8, b: i8) i8 { return a + b; }
En general, las funciones se ven bastante estándar. Hasta ahora no he notado signos de funciones de primera clase, pero mi conocimiento del lenguaje es muy superficial, podría estar equivocado. Aunque quizás esto aún no se haya hecho.
Otra característica interesante es que en Zig, ignorar los valores devueltos solo se puede hacer explícitamente usando el guión bajo _
_ = foo();
Hay una reflexión que le permite obtener información variada sobre la función.
const assert = @import("std").debug.assert; test "fn reflection" { assert(@typeOf(assert).ReturnType == void); // assert(@typeOf(assert).is_var_args == false); // }
Ejecución de código en tiempo de compilación
Zig proporciona una característica poderosa: ejecutar código escrito en zig en tiempo de compilación. Para que el código se ejecute en tiempo de compilación, simplemente envuélvalo en un bloque con la palabra clave comptime. La misma función se puede llamar tanto en tiempo de compilación como en tiempo de ejecución, lo que le permite escribir código universal. Por supuesto, hay algunas limitaciones asociadas con diferentes contextos del código. Por ejemplo, en la documentación de muchos ejemplos, comptime se usa para verificar el tiempo de compilación:
// array literal const message = []u8{ 'h', 'e', 'l', 'l', 'o' }; // get the size of an array comptime { assert(message.len == 5); }
Pero, por supuesto, el poder de este operador está lejos de ser completamente revelado aquí. Entonces, en la descripción del lenguaje, se da un ejemplo clásico del uso efectivo de macros sintácticas: la implementación de una función similar a printf, pero analizando la cadena de formato y realizando todas las verificaciones de tipo necesarias de los argumentos en la etapa de compilación.
Además, la palabra comptime se usa para indicar los parámetros de las funciones de tiempo de compilación, que es similar a las funciones de plantilla de C ++.
fn max(comptime T: type, a: T, b: T) T { return if (a > b) a else b; }
Manejo de errores
Zig inventó un sistema original de manejo de errores que no era como otros idiomas. Esto se puede llamar "excepciones explícitas" (en este lenguaje, la explicidad es generalmente uno de los modismos). También se parece a los códigos de retorno de Go, pero funciona de manera diferente.
El sistema de procesamiento de errores Zig se basa en enumeraciones especiales para implementar códigos de error personalizados (error) y se basa en sus "tipos de error" (suma de tipo algebraico, que combina el tipo de función devuelto y el código de error).
Las enumeraciones de error se declaran de la misma manera que las enumeraciones regulares:
const FileOpenError = error { AccessDenied, OutOfMemory, FileNotFound, }; const AllocationError = error { OutOfMemory, };
Sin embargo, todos los códigos de error reciben valores mayores que cero; Además, si declara un código con el mismo nombre en dos enumeraciones, recibirá el mismo valor. Sin embargo, las conversiones implícitas entre diferentes enumeraciones de errores están prohibidas.
La palabra clave anyerror significa una enumeración que incluye todos los códigos de error.
Al igual que los tipos opcionales, el lenguaje admite la generación de tipos de error utilizando una sintaxis especial. Type! U64 es una forma abreviada de anyerror! U64, que a su vez significa una unión (opción), que incluye el tipo u64 y type anyerror (según tengo entendido, el código 0 está reservado para indicar la ausencia de un error y la validez del campo de datos, el resto de los códigos son en realidad códigos de error).
La palabra clave catch le permite detectar el error y convertirlo en un valor predeterminado:
const number = parseU64(str, 10) catch 13;
Entonces, si ocurre un error en la función parseU64 que devuelve el tipo! U64, entonces catch lo "interceptará" y devolverá el valor predeterminado de 13.
La palabra clave try le permite "reenviar" el error al nivel superior (es decir, al nivel de la función de llamada). Ver código
fn doAThing(str: []u8) !void { const number = try parseU64(str, 10); // ... }
equivalente a esto:
fn doAThing(str: []u8) !void { const number = parseU64(str, 10) catch |err| return err; // ... }
Aquí sucede lo siguiente: se llama a parseU64, si se devuelve un error: se intercepta mediante la instrucción catch, en la que el código de error se extrae utilizando la sintaxis de "captura", colocada en la variable err, que se devuelve mediante! Void a la función de llamada.
El operador Errdefer descrito anteriormente también se refiere al manejo de errores. El código de argumento Errdefer se ejecuta solo si la función devuelve un error.
Algunas posibilidades más. Usando el || puedes combinar conjuntos de errores
const A = error{ NotDir, PathNotFound, }; const B = error{ OutOfMemory, PathNotFound, }; const C = A || B;
Zig también proporciona características como el seguimiento de errores. Esto es algo similar a un seguimiento de pila, pero contiene información detallada sobre qué error ocurrió y cómo se propagó a lo largo de la cadena de prueba desde el lugar de ocurrencia hasta la función principal del programa.
Por lo tanto, el sistema de manejo de errores en Zig es una solución muy original, que no parece excepciones en C ++ o códigos de retorno en Go. Podemos decir que dicha solución tiene un precio determinado: 4 bytes adicionales, que deben devolverse con cada valor devuelto; ventajas obvias son visibilidad y transparencia absolutas. A diferencia de C ++, aquí la función no puede lanzar una excepción desconocida desde algún lugar en la profundidad de la cadena de llamadas. Todo lo que devuelve la función: regresa explícitamente y solo explícitamente.Corutinas
Zig tiene corutinas incorporadas. Estas son funciones que se crean con la palabra clave asincrónica, con la ayuda de las cuales se transfieren las funciones del asignador y el asignador de negocios (según tengo entendido, para una pila adicional). test "create a coroutine and cancel it" { const p = try async<std.debug.global_allocator> simpleAsyncFn(); comptime assert(@typeOf(p) == promise->void); cancel p; assert(x == 2); } async<*std.mem.Allocator> fn simpleAsyncFn() void { x += 1; }
async devuelve un objeto especial de tipo promise-> T (donde T es el tipo de retorno de la función). Con este objeto, puede controlar la rutina.Los niveles más bajos incluyen las palabras clave suspender, reanudar y cancelar. Usando suspender, la ejecución de rutina se pausa y se pasa al programa de llamada. La sintaxis del bloque de suspensión es posible; todo lo que está dentro del bloque se ejecuta hasta que la rutina se suspende realmente.resume toma un argumento de tipo promise-> T y reanuda la ejecución de la rutina desde donde se suspendió.cancelar libera memoria de rutina.Esta imagen muestra la transferencia de control entre el programa principal (en forma de prueba) y la rutina. Todo es bastante simple: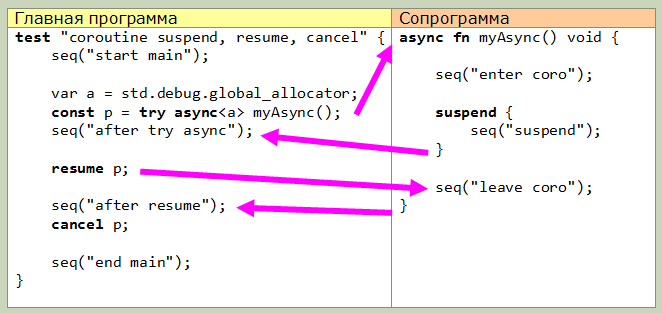 La segunda característica (nivel superior) es el uso de esperar. Esto es lo único que, francamente, no he descubierto (por desgracia, la documentación aún es muy escasa). Aquí está el diagrama de transferencia de control real de un ejemplo ligeramente modificado de la documentación, tal vez esto le explique algo:
La segunda característica (nivel superior) es el uso de esperar. Esto es lo único que, francamente, no he descubierto (por desgracia, la documentación aún es muy escasa). Aquí está el diagrama de transferencia de control real de un ejemplo ligeramente modificado de la documentación, tal vez esto le explique algo: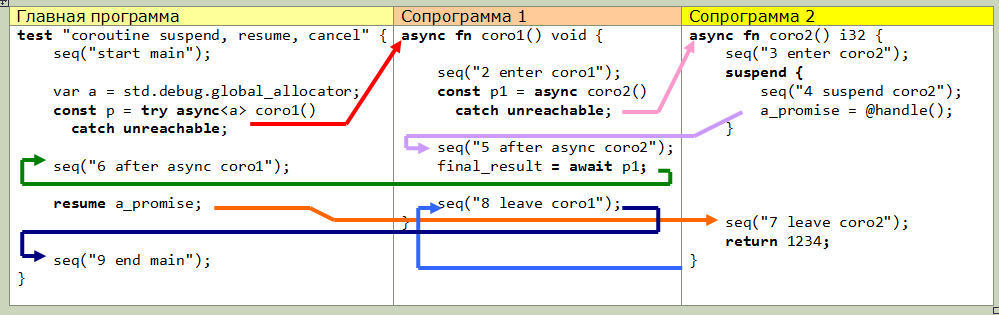
Funciones incorporadas
Funciones integradas: un conjunto bastante grande de funciones integradas en el lenguaje y que no requieren la conexión de ningún módulo. Quizás sea más correcto llamar a algunos de ellos "macros sintácticas incorporadas", porque las capacidades de muchos van mucho más allá de las funciones. los incorporados proporcionan acceso a herramientas de reflexión (sizeOf, tagName, TagType, typeInfo, typeName, typeOf), con sus módulos de ayuda (importación) conectados. Otros se parecen más al clásico C / C ++ incorporado: implementan conversiones de tipo de bajo nivel, diversas operaciones como sqrt, popCount, slhExact, etc. Es muy probable que la lista de funciones incorporadas cambie a medida que se desarrolle el lenguaje.En conclusión
Es muy agradable que tales proyectos aparezcan y se desarrollen. Aunque el lenguaje C es conveniente, conciso y familiar para muchos, todavía está desactualizado y por razones arquitectónicas no puede soportar muchos conceptos de programación modernos. C ++ se está desarrollando, pero rediseñado objetivamente, se está volviendo cada vez más difícil con cada nueva versión, y por las mismas razones arquitectónicas y debido a la necesidad de compatibilidad con versiones anteriores, no se puede hacer nada al respecto. El óxido es interesante, pero con un umbral de entrada muy alto, que no siempre está justificado. D es un buen intento, pero hay algunas fallas menores, parece que inicialmente el lenguaje se creó más probablemente bajo la influencia de Java, y las características posteriores se introdujeron de alguna manera, de alguna manera, no como deberían. Obviamente, Zig es otro de esos intentos. El lenguaje es interesante, y es interesante ver qué sale de él.