TL; DR: GitHub: // PastorGL / AQLSelectEx .
Una vez, no en la temporada de frío, sino ya en la temporada de invierno, y específicamente hace un par de meses, para un proyecto en el que estaba trabajando (algo geoespacial basado en Big Data), necesitaba un almacenamiento rápido NoSQL / Key-Value.
Masticamos terabytes de códigos fuente con la ayuda de Apache Spark, pero el resultado final de los cálculos, colapsado en una cantidad ridícula (solo millones de registros), debe almacenarse en algún lugar. Y es muy deseable almacenarlo de tal manera que pueda encontrarse rápidamente y enviarse utilizando metadatos asociados con cada línea del resultado (esto es un dígito) (pero hay bastantes).
Los formatos de la pila Khadupov en este sentido son de poca utilidad, y las bases de datos relacionales en millones de registros se ralentizan, y el conjunto de metadatos no está tan fijo como para encajar bien en el esquema rígido de un RDBMS regular - PostgreSQL en nuestro caso. No, normalmente admite JSON, pero aún tiene problemas con los índices en millones de registros. Los índices se hinchan, se hace necesario dividir la tabla, y tal molestia con la administración comienza que nafig-nafig.
Históricamente, MongoDB se usó como NoSQL en el proyecto, pero con el tiempo, la monga se muestra cada vez peor (especialmente en términos de estabilidad), por lo que se retiró gradualmente. Una búsqueda rápida de una alternativa más moderna, más rápida, con menos errores y, en general, mejor condujo a Aerospike . Muchos tipos cabezudos lo tienen a favor, y decidí comprobarlo.
Las pruebas mostraron que, de hecho, los datos se almacenan en la historia directamente desde el trabajo de Spark con un silbato, y la búsqueda en muchos millones de registros es mucho más rápida que en el mong. Y ella come menos memoria. Pero resultó uno "pero". La API del cliente de Aero Solder es puramente funcional y no declarativa.
Para grabar en la historia, esto no es importante, porque de todos modos, todos los tipos de campos de cada registro resultante deben determinarse localmente en el trabajo mismo, y el contexto no se pierde. El estilo funcional está en su lugar aquí, especialmente porque escribir un código de una manera diferente no funcionará. Pero en el bozal web, que debería cargar el resultado al mundo exterior, y es una aplicación web de primavera ordinaria, sería mucho más lógico formar un SQL SELECT estándar a partir de un formulario de usuario, en el que estaría lleno de AND y OR, es decir, predicados , - en la cláusula WHERE.
Explicaré la diferencia con un ejemplo tan sintético:
SELECT foo, bar, baz, qux, quux FROM namespace.set WITH (baz!='a') WHERE (foo>2 AND (bar<=3 OR foo>5) AND quux LIKE '%force%') OR NOT (qux WITHIN CAST('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}' AS GEOJSON)
- es legible y relativamente claro qué registros deseaba recibir el cliente. Si lanza una solicitud de este tipo directamente en el registro tal como está, puede extraerla más tarde para depurarla manualmente. Lo cual es muy conveniente al analizar todo tipo de situaciones extrañas.
Ahora veamos la llamada a la API de predicados en un estilo funcional:
Statement reference = new Statement(); reference.setSetName("set"); reference.setNamespace("namespace"); reference.setBinNames("foo", "bar", "baz", "qux", "quux"); reference.setFillter(Filter.stringNotEqual("baz", "a")); reference.setPredExp(
Aquí está el muro de código, e incluso en notación polaca inversa . No, entiendo que la máquina de pila es simple y conveniente para la implementación desde el punto de vista del programador del motor en sí, pero para descifrar y escribir predicados en RPN desde la aplicación del cliente ... Personalmente no quiero pensar en el proveedor, quiero que yo sea un consumidor de esta API Fue conveniente. Y los predicados incluso con una extensión de cliente de proveedor (conceptualmente similar a la API de Criterios de Persistencia de Java) son inconvenientes para escribir. Y todavía no hay SELECT legible en el registro de consultas.
En general, SQL se inventó para escribir consultas basadas en criterios en un lenguaje de pájaro, casi natural. Entonces, uno se pregunta, ¿qué demonios?
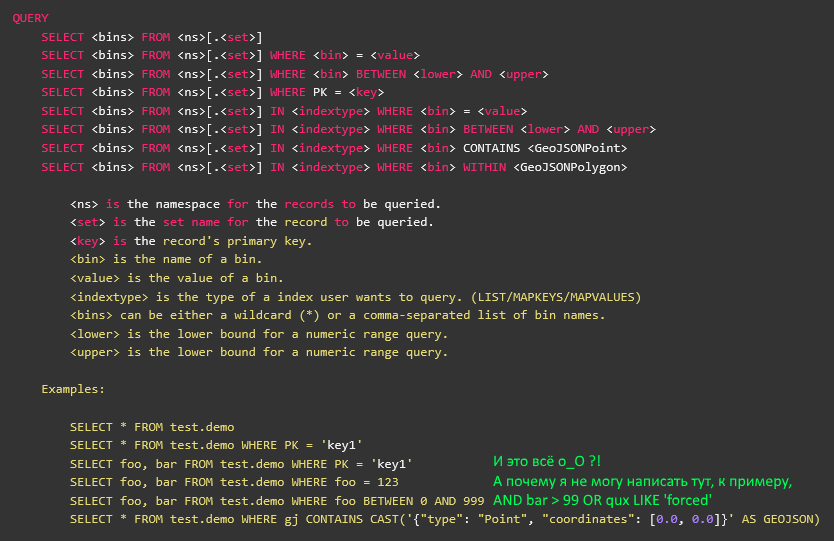
Espera, algo no está bien ... En el KDPV, ¿hay una captura de pantalla de la documentación oficial del aerosol, en la que SELECT se describe completamente?
Sí, descrito Eso es solo AQL: esta es una utilidad de terceros escrita por el pie izquierdo trasero en una noche oscura, y abandonada por el proveedor hace tres años durante la versión anterior del aerosol. No tiene nada que ver con la biblioteca del cliente, aunque está escrito en un sapo , incluido.
La versión de hace tres años no tenía una API de predicados y, por lo tanto, en AQL no hay soporte para predicados, y todo eso después de WHERE es realmente una llamada al índice (secundario o primario). Bueno, es decir, más cerca de la extensión SQL como USE o WITH. Es decir, no puede simplemente tomar fuentes AQL, desarmarlas en repuestos y usarlas en su aplicación para llamadas predicadas.
Además, como dije, fue escrito en la noche oscura con el pie izquierdo posterior, y es imposible mirar la gramática ANTLR4, que AQL analiza la consulta sin lágrimas. Bueno, para mi gusto. Por alguna razón, me encanta cuando la definición declarativa de la gramática no se mezcla con trozos de código de sapo, y allí se preparan fideos muy frescos.
Bueno, afortunadamente, también parece que sé hacer ANTLR. Es cierto que durante mucho tiempo no tomé un corrector, y la última vez que lo escribí en la tercera versión. Cuarto: es mucho mejor, porque quién quiere escribir un recorrido AST manual, si todo fue escrito antes que nosotros, y hay un visitante normal, así que comencemos.
Tomamos la sintaxis SQLite como base e intentamos descartar todo lo innecesario. Solo necesitamos SELECCIONAR, y nada más.
grammar SQLite; simple_select_stmt : ( K_WITH K_RECURSIVE? common_table_expression ( ',' common_table_expression )* )? select_core ( K_ORDER K_BY ordering_term ( ',' ordering_term )* )? ( K_LIMIT expr ( ( K_OFFSET | ',' ) expr )? )? ; select_core : K_SELECT ( K_DISTINCT | K_ALL )? result_column ( ',' result_column )* ( K_FROM ( table_or_subquery ( ',' table_or_subquery )* | join_clause ) )? ( K_WHERE expr )? ( K_GROUP K_BY expr ( ',' expr )* ( K_HAVING expr )? )? | K_VALUES '(' expr ( ',' expr )* ')' ( ',' '(' expr ( ',' expr )* ')' )* ; expr : literal_value | BIND_PARAMETER | ( ( database_name '.' )? table_name '.' )? column_name | unary_operator expr | expr '||' expr | expr ( '*' | '/' | '%' ) expr | expr ( '+' | '-' ) expr | expr ( '<<' | '>>' | '&' | '|' ) expr | expr ( '<' | '<=' | '>' | '>=' ) expr | expr ( '=' | '==' | '!=' | '<>' | K_IS | K_IS K_NOT | K_IN | K_LIKE | K_GLOB | K_MATCH | K_REGEXP ) expr | expr K_AND expr | expr K_OR expr | function_name '(' ( K_DISTINCT? expr ( ',' expr )* | '*' )? ')' | '(' expr ')' | K_CAST '(' expr K_AS type_name ')' | expr K_COLLATE collation_name | expr K_NOT? ( K_LIKE | K_GLOB | K_REGEXP | K_MATCH ) expr ( K_ESCAPE expr )? | expr ( K_ISNULL | K_NOTNULL | K_NOT K_NULL ) | expr K_IS K_NOT? expr | expr K_NOT? K_BETWEEN expr K_AND expr | expr K_NOT? K_IN ( '(' ( select_stmt | expr ( ',' expr )* )? ')' | ( database_name '.' )? table_name ) | ( ( K_NOT )? K_EXISTS )? '(' select_stmt ')' | K_CASE expr? ( K_WHEN expr K_THEN expr )+ ( K_ELSE expr )? K_END | raise_function ;
Hmm ... Demasiado para SELECCIONAR demasiado. Y si es bastante fácil deshacerse del exceso, entonces hay otra cosa mala con respecto a la estructura misma de la solución resultante.
El objetivo final es traducir a la API predicada con su RPN y máquina de pila implícita. Y aquí atomic expr no contribuye a tal transformación de ninguna manera, porque implica un análisis normal de izquierda a derecha. Sí, y recursivamente definido.
Es decir, podemos obtener nuestro ejemplo sintético, pero se leerá exactamente como está escrito, de izquierda a derecha:
(foo>2 (bar<=3 foo>5) quux _ '%force%') (qux _('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}')
Hay paréntesis que determinan la prioridad del análisis (lo que significa que debe colgar de un lado a otro en la pila), y también algunos operadores se comportan como llamadas de función.
Y necesitamos esta secuencia:
foo 2 > bar 3 <= foo 5 > quux ".*force.*" _ qux "{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}" _
Brr, estaño, pobre cerebro para leer. Pero sin corchetes, no hay retrocesos y malentendidos con el orden de la llamada. ¿Y cómo traducimos uno a otro?
Y luego, en un cerebro pobre, ¡sucede un chocolate! - Hola, este es un clásico Shunting Yard de muchos. prof. Dijkstra! Por lo general, los chamanes okolobigdatovskih como yo no necesitan algoritmos, porque simplemente transferimos los prototipos ya escritos por los satanistas de datos de Python al sapo, y luego para un rendimiento largo y tedioso de la solución obtenida por métodos puramente de ingeniería (== chamanísticos), y no científicos .
Pero, de repente, se hizo necesario conocer el algoritmo. O al menos una idea de ello. Afortunadamente, no se ha olvidado todo el curso universitario en los últimos años, y desde que recuerdo las máquinas apiladas, también puedo descubrir algo más sobre los algoritmos asociados.
Esta bien En una gramática afilada por Shunting Yard, un SELECT en el nivel superior se vería así:
select_stmt : K_SELECT ( STAR | column_name ( COMMA column_name )* ) ( K_FROM from_set )? ( (K_USE | K_WITH) index_expr )? ( K_WHERE where_expr )? ; where_expr : ( atomic_expr | OPEN_PAR | CLOSE_PAR | logic_op )+ ; logic_op : K_NOT | K_AND | K_OR ; atomic_expr : column_name ( equality_op | regex_op ) STRING_LITERAL | ( column_name | meta_name ) ( equality_op | comparison_op ) NUMERIC_LITERAL | column_name map_op iter_expr | column_name list_op iter_expr | column_name geo_op cast_expr ;
Es decir, los tokens correspondientes a los corchetes son significativos, y no debería haber un expr recursivo. En cambio, habrá un montón de todos private_expr, y todos son finitos.
En el código del sapo, que implementa el visitante para este árbol, las cosas son un poco más adictivas, en estricta conformidad con el algoritmo, que en sí mismo procesa el logic_op colgante y equilibra los corchetes. No daré un extracto ( mire usted mismo el GC ), pero consideraré lo siguiente.
Queda claro por qué los autores del pico aéreo no se molestaron con el soporte de predicados en AQL y lo abandonaron hace tres años. Porque está estrictamente tipado, y el pico aerodinámico en sí se presenta como una historia sin esquema. Por lo tanto, es imposible tomar y destripar una consulta de SQL simple sin un esquema predeterminado. Ups
Pero nosotros, chicos, estamos quemados y, lo más importante, arrogantes. Necesitamos un esquema con tipos de campo, por lo que habrá un esquema con tipos de campo. Además, la biblioteca del cliente ya tiene todas las definiciones necesarias, solo necesitan ser recogidas. Aunque tuve que escribir mucho código para cada tipo (ver el mismo enlace, desde la línea 56).
Ahora inicializar ...
final HashMap FOO_BAR_BAZ = new HashMap() {{ put("namespace.set0", new HashMap() {{ put("foo", ParticleType.INTEGER); put("bar", ParticleType.DOUBLE); put("baz", ParticleType.STRING); put("qux", ParticleType.GEOJSON); put("quux", ParticleType.STRING); put("quuux", ParticleType.LIST); put("corge", ParticleType.MAP); put("corge.uier", ParticleType.INTEGER); }}); put("namespace.set1", new HashMap() {{ put("grault", ParticleType.INTEGER); put("garply", ParticleType.STRING); }}); }}; AQLSelectEx selectEx = AQLSelectEx.forSchema(FOO_BAR_BAZ);
... y listo, ahora nuestra consulta sintética se sacude simple y claramente del aerosolder:
Statement statement = selectEx.fromString("SELECT foo,bar,baz,qux,quux FROM namespace.set WITH (baz='a') WHERE (foo>2 AND (bar <=3 OR foo>5) AND quux LIKE '%force%') OR NOT (qux WITHIN CAST('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}' AS GEOJSON)");
Y para convertir el formulario del bozal web a la solicitud en sí, tomamos una tonelada de código escrito hace mucho tiempo en el bozal web ... cuando finalmente llega al proyecto, de lo contrario, el cliente lo ha puesto en el estante por ahora. Es una pena, maldita sea, pasé casi una semana de tiempo.
Espero haberlo gastado con beneficio, y la biblioteca AQLSelectEx será útil para alguien, y el enfoque en sí mismo será un tutorial un poco más realista que otros artículos del centro que trata sobre ANTLR.