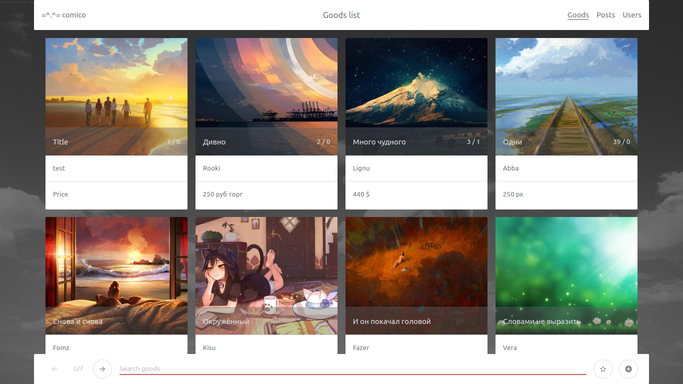
Hola a todos, quiero compartir el resultado de mis pensamientos sobre lo que puede ser una aplicación web moderna. Como ejemplo, considere diseñar un tablero de anuncios para cómics. En cierto sentido, el producto en cuestión está diseñado para una audiencia de geeks y simpatizantes, lo que le permite mostrar libertad en la interfaz. En el componente técnico, por el contrario, es necesaria la atención al detalle.
En verdad, no entiendo nada en los cómics, pero me encantan los mercados de pulgas, especialmente en el formato de foro, que eran populares en cero. Por lo tanto, la suposición (posiblemente falsa), de la que surgen las siguientes conclusiones, es solo una: el tipo principal de interacción con la aplicación es ver, la secundaria: publicar anuncios y discusiones.
Nuestro objetivo será crear una aplicación simple, sin conocimientos técnicos silbidos adicionales, sin embargo, consistentes con las realidades modernas. Los principales requisitos que me gustaría lograr son:
Lado del servidor:
a) Realiza las funciones de almacenar, validar y enviar datos de usuario al cliente
b) Las operaciones anteriores consumen una cantidad aceptable de recursos (tiempo, incluido)
c) La aplicación y los datos están protegidos de los vectores de ataque populares.
d) Tiene una API simple para clientes de terceros e interacción entre servidores
e) Multiplataforma, despliegue simple
Lado del cliente:
a) Proporciona la funcionalidad necesaria para crear y consumir contenido.
b) La interfaz es conveniente para el uso regular, la ruta mínima a cualquier acción, la cantidad máxima de datos por pantalla
c) Fuera de comunicación con el servidor, todas las funciones disponibles en esta situación están disponibles
d) La interfaz muestra la versión actual del estado y el contenido, sin reiniciar ni esperar
d) Reiniciar la aplicación no afecta su estado
f) Si es posible, reutilice los elementos DOM y el código JS
g) No utilizaremos bibliotecas y marcos de terceros en tiempo de ejecución
h) El diseño es semántico para accesibilidad, analizadores, etc.
i) Se puede acceder a la navegación del contenido principal utilizando la URL y el teclado
En mi opinión, los requisitos lógicos y la mayoría de las aplicaciones modernas cumplen en cierta medida estas condiciones. Veamos qué pasa con nosotros (enlace a la fuente y la demostración al final de la publicación).
Advertencias:- Quiero pedir disculpas a los autores desconocidos de las imágenes utilizadas en la demostración sin permisos, así como a Gösse G., Prozorovskaya B. D. y la editorial "Library of Florence Pavlenkov" por utilizar extractos de la obra "Siddhartha".
- El autor no es un programador real, no recomiendo usar el código o las técnicas utilizadas en este proyecto si no sabe lo que está haciendo.
- Pido disculpas por el estilo del código; podría haber sido escrito de manera más legible y obvia, pero esto no es divertido. Un proyecto para el alma y para un amigo, tal como dicen.
- También me disculpo por la tasa de alfabetización, especialmente en el texto en inglés. Años hablan de May Hart.
- El rendimiento del prototipo presentado se probó en [cromo 70; linux x86_64; 1366x768], estaré extremadamente agradecido con los usuarios de otras plataformas y dispositivos por los mensajes de error.
- Este es un prototipo y un tema de discusión propuesto: enfoques y principios, pido que todas las críticas a la implementación y el lado estético estén acompañadas de argumentos.
Servidor
El idioma para el servidor es golang. Un lenguaje simple y rápido con una excelente biblioteca y documentación estándar ... un poco molesto. La elección inicial recayó en elixir / erlang, pero como ya sabía ir (relativamente), se decidió no complicarlo (y los paquetes necesarios eran solo para ir).
No se recomienda el uso de marcos web en la comunidad go (justificadamente, vale la pena admitirlo), elegimos un compromiso y utilizamos el microframework labstack / echo , lo que reduce la cantidad de rutina y, según me parece, no pierde mucho rendimiento.
Usamos tidwall / buntdb como la base de datos. En primer lugar, la solución integrada es más conveniente y reduce los costos generales, y en segundo lugar, en memoria + clave / valor: de moda, con estilo Rápido y no se necesita caché. Almacenamos y damos datos en JSON, validando solo cuando se cambia.
En el i3 de segunda generación, el registrador incorporado muestra el tiempo de ejecución para diferentes solicitudes de 0,5 a 10 ms. Ejecutar wrk en la misma máquina también muestra resultados suficientes para nuestros propósitos:
➜ comico git:(master) wrk -t2 -c500 -d60s http://localhost:9001/pub/mtimes Running 1m test @ http://localhost:9001/pub/mtimes 2 threads and 500 connections Thread Stats Avg Stdev Max +/- Stdev Latency 20.74ms 16.68ms 236.16ms 72.69% Req/Sec 13.19k 627.43 15.62k 73.58% 1575522 requests in 1.00m, 449.26MB read Requests/sec: 26231.85 Transfer/sec: 7.48MB
➜ comico git:(master) wrk -t2 -c500 -d60s http://localhost:9001/pub/goods Running 1m test @ http://localhost:9001/pub/goods 2 threads and 500 connections Thread Stats Avg Stdev Max +/- Stdev Latency 61.79ms 65.96ms 643.73ms 86.48% Req/Sec 5.26k 705.24 7.88k 70.31% 628215 requests in 1.00m, 8.44GB read Requests/sec: 10454.44 Transfer/sec: 143.89MB
Estructura del proyecto
El paquete comico / model se divide en tres archivos:
model.go: contiene una descripción de los tipos de datos y funciones generales: creación / actualización (buntdb no distingue entre estas operaciones y verificamos la presencia de un registro manualmente), validación, eliminación, obtención de un registro y obtención de una lista;
rules.go: contiene reglas de validación para un tipo específico y una función de registro;
files.go: trabaja con imágenes.
El tipo Mtimes almacena datos sobre el último cambio de los tipos restantes en la base de datos, informando así al cliente qué datos han cambiado.
El paquete comico / bd contiene funciones generalizadas para interactuar con la base de datos: creación, eliminación, selección, etc. Buntdb guarda todos los cambios en un archivo (en nuestro caso, una vez por segundo), en formato de texto, lo cual es conveniente en algunas situaciones. El archivo de la base de datos no se edita, los cambios en caso de éxito de la transacción se agregan al final. Todos mis intentos de violar la integridad de los datos no tuvieron éxito, en el peor de los casos, los cambios en el último segundo se pierden.
En nuestra implementación, cada tipo corresponde a una base de datos separada en un archivo separado (excepto los registros que se almacenan exclusivamente en la memoria y se restablecen a cero al reiniciar). Esto se debe en gran parte a la conveniencia de la copia de seguridad y la administración, una pequeña ventaja: una transacción abierta para editar bloquea el acceso a un solo tipo de datos.
Este paquete se puede reemplazar fácilmente por uno similar utilizando otra base de datos, SQL, por ejemplo. Para hacer esto, es suficiente implementar las siguientes funciones:
func Delete(db byte, key string) error func Exist(db byte, key string) bool func Insert(db byte, key, val string) error func ReadAll(db byte, pattern string) (str string, err error) func ReadOne(db byte, key string) (str string, err error) func Renew(db byte, key string) (err error, newId string)
El paquete comico / cnst contiene algunas constantes necesarias en todos los paquetes (tipos de datos, tipos de acción, tipos de usuario). Además, este paquete contiene todos los mensajes legibles por humanos con los que nuestro servidor responderá al mundo exterior.
El paquete comico / server contiene información de enrutamiento. Además, solo un par de líneas (gracias a los desarrolladores de Echo), se configura la autorización mediante JWT, CORS, encabezados CSP, registrador, distribución estática, gzip, certificado automático ACME, etc.
Puntos de entrada de API
| URL | Datos | Descripción |
|---|
| get / pub / (bienes | publicaciones | usuarios | cmnts | archivos) | - | Obtener una variedad de anuncios relevantes, publicaciones, usuarios, comentarios, archivos |
| obtener / pub / mtimes | - | Obtener el último tiempo de cambio para cada tipo de datos |
| post / pub / login | {id *: inicio de sesión, pase *: contraseña} | Devuelve el token JWT y su duración. |
| publicación / pub / pase | {id *, pass *} | Crea un nuevo usuario si los datos son correctos |
| poner / api / pasar | {id *, pass *} | Actualización de contraseña |
| publicar | poner / api / bienes | {id *, auth *, title *, type *, price *, text *, images: [], Table: {key: value}} | Crear / actualizar anuncio |
| post | put / api / posts | {id *, auth *, title *, type *, text *} | Crear / actualizar publicación en el foro |
| post | put / api / usuarios | {id *, título, tipo, estado, escribanos: [], ignora: [], Tabla: {clave: valor}} | Crear / Actualizar usuario |
| post / api / cmnts | {id *, auth *, owner *, type *, to, text *} | Creación de comentarios |
| eliminar / api / (bienes | publicaciones | usuarios | cmnts) / [id] | - | Elimina una entrada con id |
| obtener / api / actividad | - | Actualiza el último tiempo de lectura de los comentarios entrantes para el usuario actual |
| get / api / (suscribirse | ignorar) / [etiqueta] | - | Agrega o elimina (si corresponde) una etiqueta al usuario en la lista de suscripciones / ignorar |
| post / api / upload / (bienes | usuarios) | multiparte (nombre, archivo) | Sube anuncios fotográficos / avatar de usuario |
* - campos obligatorios
api - requiere autorización, pub - no
Con una solicitud de obtención que no coincide con lo anterior, el servidor busca un archivo en el directorio para la estática (por ejemplo, / img / * - images, /index.html - el cliente).
Cualquier punto API devolverá un código de respuesta 200 si tiene éxito, 400 o 404 por un error, y un mensaje corto si es necesario.
Los derechos de acceso son simples: la creación de una entrada está disponible para un usuario autorizado, la edición para el autor y moderador, el administrador puede editar y nombrar moderadores.
La API está equipada con el antivandálico más simple: las acciones se registran junto con la identificación de usuario y la IP, y, en el caso de acceso frecuente, se devuelve un error pidiéndole que espere un poco (útil contra la suposición de contraseña).
Cliente
Me gusta el concepto de web'a reactiva, creo que la mayoría de los sitios / aplicaciones modernos deberían hacerse dentro de este concepto o completamente estáticos. Por otro lado, un sitio simple con megabytes de código JS no puede sino deprimirse. En mi opinión, este (y no solo) problema puede ser resuelto por Svelte. Este marco (o más bien el lenguaje para construir interfaces reactivas) no es inferior a Vue en la funcionalidad necesaria, pero tiene una ventaja innegable: los componentes se compilan en vanilla JS, lo que reduce tanto el tamaño del paquete como la carga en la máquina virtual (bundle.min.js.gz nuestro mercado de pulgas es modesto, según los estándares actuales, 24 KB). Los detalles se pueden encontrar en la documentación oficial.
Elegimos el mercado de pulgas SvelteJS para el lado del cliente del mercado de pulgas, ¡le deseamos todo lo mejor a Rich Harris y el desarrollo del proyecto!
PD: no quiero ofender a nadie. Estoy seguro de que cada especialista y cada proyecto tienen sus propias herramientas.
Cliente / Datos
URL
Usamos para la navegación. No simularemos un documento de varias páginas; en su lugar, usamos páginas hash con parámetros de consulta. Para las transiciones, puede usar el <a> habitual sin js.
Las secciones corresponden a los tipos de datos: / # bienes , / # publicaciones , / # usuarios .
Parámetros :? Id = record_id,? Página = page_number,? Search = search_query .
Algunos ejemplos
- / # posts? id = 1542309643 & page = 999 & search = {auth: anon} - sección de publicaciones , id de publicación - 1542309643 , página de comentarios - 999 , consulta de búsqueda - {auth: anon}
- / # goods? page = 2 & search = siddhartha - sección bienes , sección página - 2 , consulta de búsqueda - siddhartha
- / # goods? search = wer {key: value} t - bienes de sección, consulta de búsqueda - consiste en buscar la subcadena wert en el encabezado o texto del anuncio y el valor de la subcadena en la propiedad clave de la parte tabular del anuncio
- / # goods? search = {model: 100, display: 256} - Creo que todo está claro aquí por analogía
Las funciones de análisis y generación de URL en nuestra implementación se ven así:
window.addEventListener('hashchange', function() { const hash = location.hash.slice(1).split('?'), result = {} if (!!hash[1]) hash[1].split('&').forEach(str => { str = str.split('=') if (!!str[0] && !!str[1]) result[decodeURI(str[0]).toLowerCase()] = decodeURI(str[1]).toLowerCase() }) result.type = hash[0] || 'goods' store.set({ hash: result }) }) function goto({ type, id, page, search }) { const { hash } = store.get(), args = arguments[0], query = [] new Array('id', 'page', 'search').forEach(key => { const value = args[key] !== undefined ? args[key] : hash[key] || null if (value !== null) query.push(key + '=' + value) }) location.hash = (type || hash.type || 'goods') + (!!query.length ? '?' + query.join('&') : '') }
API
Para intercambiar datos con el servidor, usaremos la API de búsqueda. Para descargar registros actualizados a intervalos cortos, solicitamos a / pub / mtimes , si la hora del último cambio para cualquier tipo difiere de la local, cargamos una lista de este tipo. Sí, fue posible implementar la notificación de actualizaciones a través de SSE o WebSockets y la carga incremental, pero en este caso podemos prescindir de ella. ¿Qué obtuvimos?
async function GET(type) { const response = await fetch(location.origin + '/pub/' + type) .catch(() => ({ ok: false })) if (type === 'mtimes') store.set({ online: response.ok }) return response.ok ? await response.json() : [] } async function checkUpdate(type, mtimes, updates = {}) { const local = store.get()._mtimes, net = mtimes || await GET('mtimes') if (!net[type] || local[type] === net[type]) return const value = updates['_' + type] = await GET(type) local[type] = net[type]; updates._mtimes = local if (!!value && !!value.sort) store.set(updates) } async function checkUpdates() { setTimeout(() => checkUpdates(), 30000) const mtimes = await store.GET('mtimes') new Array('users', 'goods', 'posts', 'cmnts', 'files') .forEach(type => checkUpdate(type, mtimes)) }
Para el filtrado y la paginación, utilizamos las propiedades calculadas de Svelte, basadas en datos de navegación. La dirección de los valores calculados es: elementos (matrices de registros provenientes del servidor) => ignoredItems (registros filtrados basados en la lista de ignorados del usuario actual) => scriptionsItems (filtra los registros de acuerdo con la lista de suscripciones, si este modo está activado) => curItem y curItems (calcula los registros actuales dependiendo de la sección) => filterItems (filtra los registros dependiendo de la consulta de búsqueda, si solo hay un registro - filtra los comentarios) => maxPage (calcula el número de páginas en función de 12 registros / comentarios por página) => pagedItem (devuelve la matriz final con publicaciones / comentarios basados en el número de página actual).
Los comentarios e imágenes ( comentarios e imágenes) se calculan por separado, agrupados por tipo y registro de propietario.
Los cálculos se realizan automáticamente y solo cuando los datos asociados cambian, los datos intermedios están constantemente en la memoria. En este sentido, llegamos a una conclusión desagradable: para una gran cantidad de información y / o su actualización frecuente, se puede gastar una gran cantidad de recursos.
Caché
De acuerdo con la decisión de crear una aplicación fuera de línea, implementamos el almacenamiento de registros y algunos aspectos del estado en localStorage, archivos de imagen en CacheStorage. Trabajar con localStorage es extremadamente simple, acordamos que las propiedades con el prefijo "_" se guardan y restauran automáticamente al reiniciar cuando se cambian. Entonces nuestra solución puede verse así:
store.on('state', ({ changed, current }) => { Object.keys(changed).forEach(prop => { if (!prop.indexOf('_')) localStorage.setItem(prop, JSON.stringify(current[prop])) }) }) function loadState(state = {}) { for (let i = 0; i < localStorage.length; i++) { const prop = localStorage.key(i) const value = JSON.parse(localStorage.getItem(prop) || 'null') if (!!value && !prop.indexOf('_')) state[prop] = value } store.set(state) }
Los archivos son un poco más complicados. En primer lugar, utilizaremos la lista de todos los archivos relevantes (con el tiempo de creación) procedentes del servidor. Al actualizar esta lista, la comparamos con los valores anteriores, colocamos los archivos nuevos en CacheStorage y eliminamos los obsoletos de allí:
async function cacheImages(newFiles) { const oldFiles = JSON.parse(localStorage.getItem('_files') || '[]') const cache = await caches.open('comico') oldFiles.forEach(file => { if (!~newFiles.indexOf(file)) { const [ id, type ] = file.split(':') cache.delete(`/img/${type}_${id}_sm.jpg`) }}) newFiles.forEach(file => { if (!~oldFiles.indexOf(file)) { const [ id, type ] = file.split(':'), src = `/img/${type}_${id}_sm.jpg` cache.add(new Request(src, { cache: 'no-cache' })) }}) }
Luego, debe redefinir el comportamiento de recuperación para que el archivo se tome de CacheStorage sin conectarse al servidor. Para hacer esto, debe usar ServiceWorker. Al mismo tiempo, configuraremos otros archivos para que se almacenen en caché para que funcionen fuera de la comunicación con el servidor:
const CACHE = 'comico', FILES = [ '/', '/bundle.css', '/bundle.js' ] self.addEventListener('install', (e) => { e.waitUntil(caches.open(CACHE).then(cache => cache.addAll(FILES)) .then(() => self.skipWaiting())) }) self.addEventListener('fetch', (e) => { const r = e.request if (r.method !== 'GET' || !!~r.url.indexOf('/pub/') || !!~r.url.indexOf('/api/')) return if (!!~r.url.lastIndexOf('_sm.jpg') && e.request.cache !== 'no-cache') return e.respondWith(fromCache(r)) e.respondWith(toCache(r)) }) async function fromCache(request) { return await (await caches.open(CACHE)).match(request) || new Response(null, { status: 404 }) } async function toCache(request) { const response = await fetch(request).catch(() => fromCache(request)) if (!!response && response.ok) (await caches.open(CACHE)).put(request, response.clone()) return response }
Parece un poco torpe, pero realiza sus funciones.
Cliente / interfaz
Estructura componente
index.html | main.js
== header.html : contiene un logotipo, barra de estado, menú principal, menú de navegación inferior, formulario de envío de comentarios
== aside.html - es un contenedor para todos los componentes modales
==== goodForm.html - formulario para agregar y editar un anuncio
==== userForm.html - edita el formulario del usuario actual
====== tableForm.html : un fragmento del formulario para ingresar datos tabulares
==== postForm.html - formulario para publicación en el foro
==== login.html - formulario de inicio de sesión / registro
==== activity.html : muestra los comentarios dirigidos al usuario actual
==== goodImage.html : vea los anuncios fotográficos principales y adicionales
== main.html - contenedor para el contenido principal
==== mercancías.html - lista o tarjetas de anuncio individuales
==== users.html : lo mismo para los usuarios
==== posts.html - Creo que está claro
==== cmnts.html - lista de comentarios en la publicación actual
====== cmntsPager.html - paginación para comentarios
- En cada componente, tratamos de minimizar la cantidad de etiquetas html.
- Usamos clases solo como un indicador de estado.
- Tomamos funciones similares a la tienda (las propiedades y métodos de la tienda esbelta se pueden usar directamente desde los componentes agregando el prefijo '$').
- La mayoría de las funciones esperan un evento de usuario o un cambio de ciertas propiedades, manipulan los datos del estado, guardan el resultado de su trabajo en el estado y finalizan. Por lo tanto, se logra una pequeña coherencia y extensibilidad del código.
- Para la velocidad aparente de las transiciones y otros eventos de IU, separamos, en la medida de lo posible, las manipulaciones con datos que se producen en segundo plano y las acciones asociadas con la interfaz, que a su vez utiliza el resultado del cálculo actual, reconstruyendo si es necesario, el resto se realizará amablemente por el marco.
- Los datos del formulario a rellenar se almacenan en localStorage para cada entrada con el fin de evitar su pérdida.
- En todos los componentes, utilizamos el modo inmutable en el que el objeto de propiedad se considera cambiado solo cuando se recibe un nuevo enlace, independientemente del cambio en los campos, lo que acelera un poco nuestras aplicaciones, aunque debido a un pequeño aumento en la cantidad de código.
Cliente / Gerencia
Para controlar el uso del teclado, utilizamos las siguientes combinaciones:
Alt + s / Alt + a : cambia la página de registros hacia adelante / hacia atrás, ya que un registro cambia la página de comentarios.
Alt + w / Alt + q : se mueve al registro siguiente / anterior (si lo hay), funciona en modo de lista, registro único y vista de imagen
Alt + x / Alt + z : desplaza la página hacia abajo / arriba. En la vista de imagen, alterna las imágenes hacia adelante / atrás
Escape : cierra la ventana modal, si está abierta, vuelve a la lista, si hay una sola entrada abierta, cancela la consulta de búsqueda en modo de lista
Alt + c : se centra en el campo de búsqueda o comentario, según el modo actual
Alt + v : activar / desactivar el modo de visualización de fotos para un solo anuncio
Alt + r : abre / cierra la lista de comentarios entrantes para un usuario autorizado
Alt + t : alterna los temas claros / oscuros
Alt + g - Lista de anuncios
Alt + u - Usuarios
Alt + p - foro
Sé que en muchos navegadores estas combinaciones son utilizadas por el navegador en sí, pero para mi Chrome no podría encontrar algo más conveniente. Estaré encantado de sus sugerencias.
Además del teclado, por supuesto, puede usar la consola del navegador. Por ejemplo, store.goBack () , store.nextPage () , store.prevPage () , store.nextItem () , store.prevItem () , store.search (stringValue) , store.checkUpdate ('mercancías' || ' usuarios '||' publicaciones '||' archivos '||' cmnts ') - hagan lo que el nombre implica; store.get (). comments y store.get () ._ images : devuelve archivos agrupados y comentarios; store.get (). ignoredItems y store.get (). sitatedItems son listas de registros que ignora y rastrea. Una lista completa de todos los datos intermedios y calculados está disponible en store.get () . No creo que nadie pueda necesitar esto seriamente, pero, por ejemplo, filtrar registros por usuario y eliminarlos me pareció bastante conveniente desde la consola.
Conclusión
Aquí es donde puede finalizar su conocimiento del proyecto; puede encontrar más detalles en el código fuente. Como resultado, obtuvimos una aplicación bastante rápida y compacta, en la mayoría de los verificadores de validadores, seguridad, velocidad, disponibilidad, etc., muestra buenos resultados sin una optimización específica.
Me gustaría saber la opinión de la comunidad sobre cuán justificados están los enfoques para organizar las aplicaciones utilizadas en el prototipo, qué dificultades podrían ser, qué implementaría de una manera fundamentalmente diferente
Código fuente, instrucciones de instalación de muestra y demostración aquí (por favor destrozar probar en el marco del Código Penal).
Postdata Un poco mercantil en conclusión. Dime, con tal nivel, ¿es realmente posible comenzar a programar por dinero? Si no, qué buscar primero, si es así, dígame dónde están buscando trabajo interesante en una pila similar ahora. Gracias
Postdata Un poco más sobre dinero y trabajo. ¿Qué le parece esta idea? Suponga que una persona está lista para trabajar en un proyecto interesante para él por cualquier salario, sin embargo, los datos sobre las tareas y su pago estarán disponibles públicamente (la accesibilidad y un código para evaluar la calidad del desempeño son deseables), si el pago está significativamente por debajo del mercado, los competidores del empleador pueden ofrecer una gran cantidad de dinero para el desempeño de sus tareas, si son más altas; muchos artistas podrán ofrecer sus servicios a un precio más bajo. ¿Tal esquema en algunas situaciones equilibraría el mercado (TI) de manera más óptima y justa?