
Probablemente, no hay tantos usuarios en Habr que nunca hayan escuchado sobre el
"Archivo de Internet" , un servicio que busca y almacena los datos digitales que son importantes para toda la humanidad, ya sean páginas de Internet, libros, videos u otro tipo. de información.
¿Quién administra el archivo de Internet, cuándo apareció y cuál es su misión? Lea sobre esto en la "Consulta" de hoy.
¿Por qué necesitamos incluso un "Archivo"?
Esto está lejos de ser solo entretenimiento. La misión de la organización es proporcionar el acceso universal a toda la información. El "archivo de Internet" busca combatir el monopolio de la provisión de información por parte de las compañías de telecomunicaciones (Google, Facebook, etc.) y los gobiernos.
Al mismo tiempo, el "Archivo" es una organización respetuosa de la ley. Si según la ley de los EE. UU. Es necesario eliminar alguna información, la organización lo hace.
El "archivo de Internet" también sirve como una herramienta para científicos, agencias de seguridad, historiadores (por ejemplo, arqueólogos) y representantes de muchos otros campos, sin mencionar a los usuarios individuales.
¿Cuándo apareció el "archivo de Internet"?
El creador del "Archivo" es Brewster Cale de los Estados Unidos, quien creó la compañía Alexa Internet. Sus dos servicios se han vuelto extremadamente populares, ambos siguen siendo prósperos.
El "archivo de Internet" comenzó a archivar la información de los sitios web y a guardar las copias de las páginas web en 1996. La sede de esta organización sin fines de lucro se encuentra en San Francisco, EE. UU.
Sin embargo, durante cinco años los datos no estuvieron disponibles para el acceso público: los datos se almacenaron en los servidores del "Archivo", y eso es todo, solo la administración del servicio podía ver las copias antiguas de los sitios. Desde 2001, la administración del servicio ha decidido proporcionar acceso a los datos almacenados a todos.
Al principio, el "archivo de Internet" era solo un archivo web, pero luego la organización comenzó a guardar libros, archivos de audio, imágenes en movimiento y software. Ahora el "archivo de Internet" actúa como un depósito de fotos y otras imágenes de la NASA, textos abiertos de la Biblioteca, etc.
¿Cómo existe la organización?
El "Archivo" existe en donaciones voluntarias, tanto de las organizaciones como de los individuos. Puede proporcionar soporte en bitcoins, el número de billetera es 1Archive1n2C579dMsAu3iC6tWzuQJz8dN. Esta billetera, por cierto, ha recibido 357.47245492 BTC durante su existencia, que es de aproximadamente $ 2.25 millones al tipo actual.
¿Cómo funciona el "Archivo"?
La mayoría del personal está empleado en los centros de escaneo de libros, realizando tareas rutinarias pero que requieren mucho tiempo. La organización tiene tres centros de datos ubicados en California, EE. UU. Uno en San Francisco, uno en la ciudad de Redwood, uno en Richmond. Para evitar el riesgo de pérdida de datos en caso de un desastre natural u otras catástrofes, el "Archivo" tiene capacidad disponible en Egipto y Amsterdam.
“Millones de personas han dedicado mucho tiempo y esfuerzo a compartir con otros lo que sabemos en forma de Internet. Queremos crear una biblioteca para esta nueva plataforma de publicación ", dijo Brewster Kahle, fundador de Internet Archive)
¿Qué tan grande es el "Archivo" ahora?
El "archivo de Internet" tiene varias divisiones, y la que recopila información de los sitios tiene su propio nombre: Wayback Machine. Al momento de escribir la "Consulta", el archivo contenía 339 mil millones de páginas web guardadas. En 2017, el "Archivo"
almacenó 30 petabytes de información, que son alrededor de 300 mil millones de páginas web, 12 millones de libros, 4 millones de grabaciones de audio, 3.3 millones de videos, 1.5 millones de fotos y 170 mil distribuciones de software diferentes. En solo un año, el servicio significativamente "agregó peso". Ahora el "Archivo" almacena 339 mil millones de páginas web, 19 millones de libros, 4.5 millones de archivos de video, 4.7 millones de archivos de audio, 3.2 millones de imágenes de varios tipos, 381 mil distribuciones de software.
¿Cómo se organiza el almacenamiento de datos?
La información se almacena en discos duros en los llamados "nodos de datos". Estos son los servidores. Cada uno de ellos contiene 36 discos duros (más dos unidades del sistema operativo). Los nodos de datos se agrupan en matrices de 10 máquinas y representan un almacenamiento en clúster. En 2016, el "Archivo" utilizaba un disco duro de 8 terabytes, ahora la situación es casi la misma. Resulta que un nodo almacena aproximadamente 288 terabytes de datos. En general, también se utilizan los discos duros de otros tamaños: 2.3 y 4 TB.
En 2016, había alrededor de 20,000 discos duros. Los centros de datos del "Archivo" están equipados con unidades de aire acondicionado para el control del clima con características constantes. Un almacenamiento agrupado de 10 nodos consume aproximadamente 5 kilovatios de energía.
La estructura de Internet Archive es una "biblioteca" virtual, que se divide en secciones como libros, películas, música, etc. Para cada elemento hay una descripción en el catálogo, generalmente el nombre, el nombre del autor e información adicional. Desde un punto de vista técnico, los elementos están estructurados y ubicados en directorios de Linux.
La cantidad total de datos almacenados por el "Archivo" es de 22 PB, y ahora hay espacio para otros 22 PB. "Porque somos paranoicos", declaran los representantes del servicio.

Mire la captura de pantalla del contenido del directorio: hay un archivo con el nombre que termina con "_files.xml". Este es un directorio con información sobre todos los archivos en el directorio.
¿Qué pasará con los datos si uno o más servidores fallan?
Nada malo: los datos están duplicados. Tan pronto como aparece un nuevo elemento en la biblioteca "Archivo", se
replica inmediatamente y se coloca en diferentes discos duros en diferentes servidores. El proceso de "duplicación" de contenido ayuda a hacer frente a problemas como cortes de energía y fallas del sistema de archivos.
Si el disco duro falla, se reemplaza por uno nuevo. Gracias a la estructura de datos duplicada y reducida, se llena de inmediato con los datos que estaban en el disco duro anterior que fallaron.
El "Archivo" tiene un sistema especializado que monitorea el estado del HDD. Durante un día, debe reemplazar 6 a 7 de las unidades fallidas.
¿Qué es la máquina Wayback?
Este es solo uno de los servicios de "archivo de Internet" que se especializa en guardar páginas web. El servicio tiene su propia "araña", que examina regularmente todos los sitios disponibles en la red y los almacena en servidores especializados. Cuanto más popular es un sitio web, más a menudo el robot copia su contenido. Si el administrador de recursos no desea que el bot copie la información del sitio, es suficiente registrar una prohibición en el archivo robots.txt.
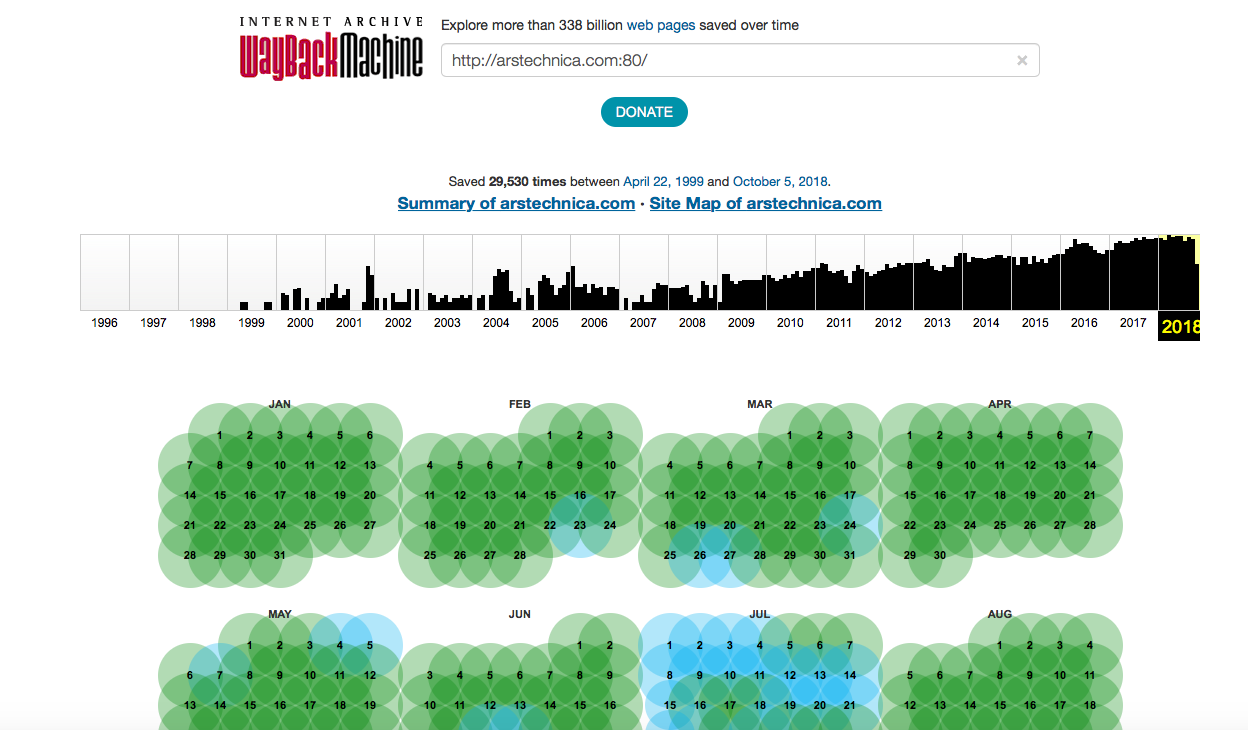 Los recursos populares se copian con frecuencia, casi a diario. Wayback Machine indexa incluso las redes sociales, como Twitter, Facebook
Los recursos populares se copian con frecuencia, casi a diario. Wayback Machine indexa incluso las redes sociales, como Twitter, Facebook
En 2017, el "Archivo" lanzó la máquina Wayback actualizada, prometiendo un acceso más conveniente a las páginas web guardadas. El servicio fue rediseñado en gran medida, si no está codificado desde cero. Ahora es compatible con varios formatos de archivo que anteriormente simplemente no se podían guardar. En el mismo 2017, la organización dijo que cada semana sus servidores ahorran alrededor de mil millones de páginas web.
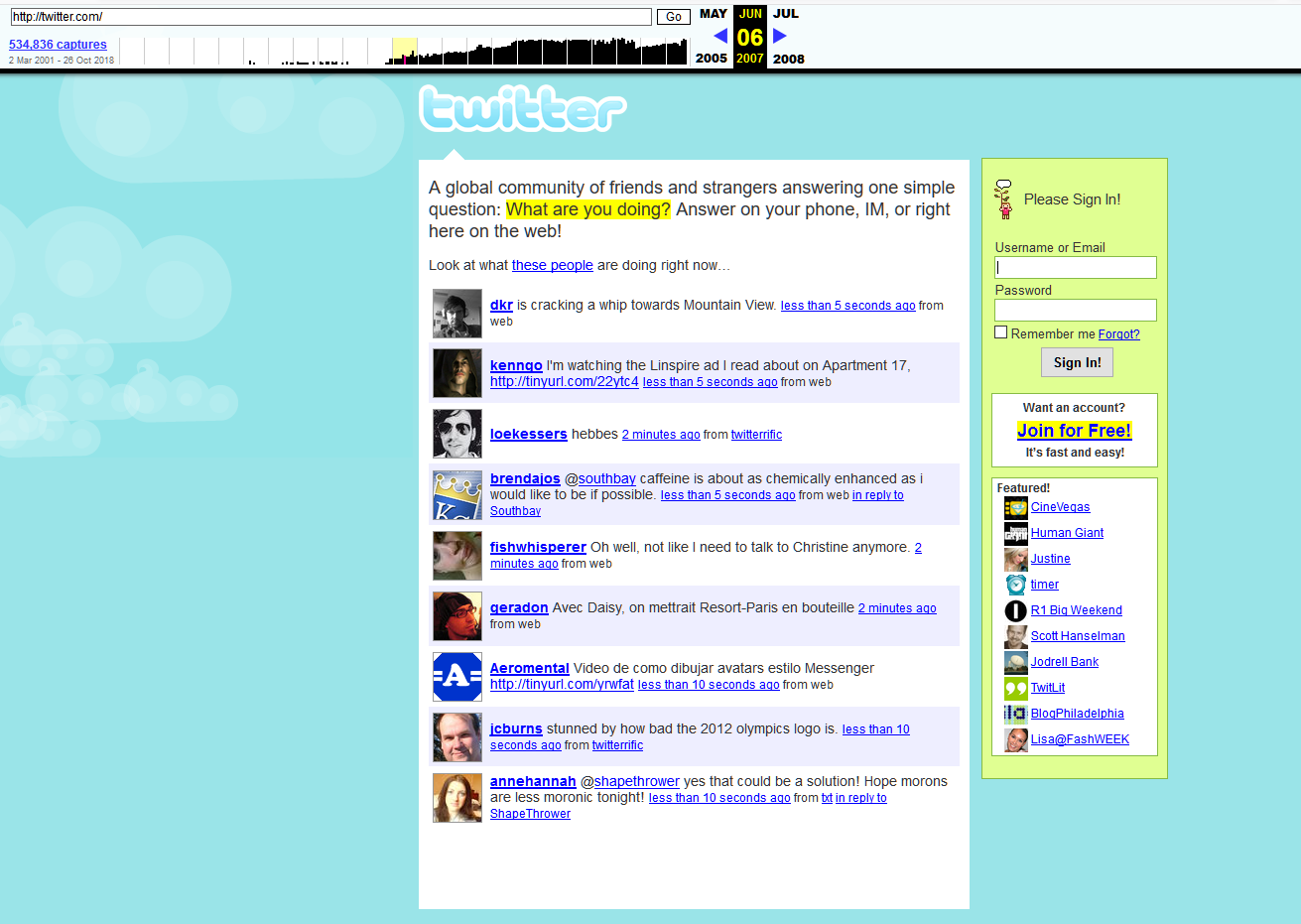 Así era Twitter en 2007
Así era Twitter en 2007¿Qué más se puede encontrar en la base de datos "archivo de Internet"?
Libros La colección de la organización es enorme, incluye libros digitalizados, ediciones comunes y muy raras. Los libros se guardan no solo en inglés, sino también en muchos otros idiomas. El "Archivo" tiene centros especializados para escanear libros, 33 de dichos centros en total. Están ubicados en cinco países de todo el mundo.
El personal del centro escanea alrededor de 1,000 libros por día. La base de datos del servicio contiene millones de publicaciones. El trabajo en su digitalización es financiado por personas comunes y diversas organizaciones, incluidas bibliotecas y fundaciones.
Desde 2007, el "archivo de Internet" ha estado almacenando libros públicos de Google Book Search en su base de datos. Después del lanzamiento, la base de datos de libros ha crecido rápidamente: en 2013, se guardaron más de 900 mil libros del servicio de Google.
Uno de los servicios del "Archivo" también proporciona acceso a los libros que están completamente abiertos. Ya hay más de un millón de ellos. Este servicio se llama Open Library.
Video El servicio almacena 4,5 millones de videos. Se dividen en temas y tienen un enfoque muy diferente. Los servidores del "Archivo" almacenan películas, documentales, eventos deportivos, programas de televisión y muchos otros materiales.
En 2015, el "Archivo" dio lugar a un
proyecto a gran escala : la digitalización de los videocasetes. Al principio, se trataba de unos 40 mil casetes del archivo de Marion Stokes, una mujer que ha estado grabando las noticias en cinta durante décadas. Luego se agregaron otras cintas de video. Fueron enviados al "Archivo" por los fanáticos de la idea de digitalizar datos que son importantes para la humanidad.
Archivos de audio. De manera similar a los videos, el "Archivo" almacena archivos de audio, que también están divididos por temas. El año pasado, el "Archivo" comenzó a implementar su nuevo proyecto: la decodificación de registros de goma laca, el formato más antiguo de grabaciones de audio. El sonido se conservó en las placas de goma laca, una resina natural, que está aislada por los insectos escamas femeninas. En total, el archivo
Great 78 Project contiene
varios cientos de miles de registros .
Software Por supuesto, es simplemente imposible almacenar todo el software creado por la humanidad, incluso para el "Archivo". Los servidores almacenan vintage, por ejemplo, los programas para Macintosh, software para DOS y otro software. En 2016, los empleados de "Archivo" publicaron
más de 1500 programas para Windows 3.1. Puedes trabajar directamente en el navegador. En 2017, Internet Archive lanzó el
archivo de software para el primer Macintosh .
Juegos Sí, el "Archivo" proporciona acceso a una gran cantidad de juegos. Algunos de ellos se pueden jugar en el entorno del emulador del navegador. Se almacena una variedad de juegos, incluido el de las
consolas portátiles analógicas y digitales . Hay
juegos para MS-DOS y
juegos de consola
para Atari y ColecoVision .

Por primera vez, la organización
subió el archivo de juegos antiguos en 2013. Estamos hablando de los títulos de hace 30-40 años, que se podían jugar directamente en el navegador. Estos son los juegos para Atari 2600 (1977), Atari 7800 (1986), ColecoVision (1982), Philips Videopac G7000 (1978) y Astrocade (1983). Lo más interesante es que Internet Archive se ha asegurado de que puedas jugar de manera bastante legal. Ahora la colección tiene
más de 3400 juegos y sigue creciendo.