Esta es la segunda parte de mi serie de
publicaciones Kubernetes in the Enterprise . Como mencioné en mi última publicación, es muy importante al pasar a las
"Guías de diseño e implementación" que todos estén en el mismo nivel de comprensión de Kubernetes (K8).
No quiero usar el enfoque tradicional aquí para explicar la arquitectura y las tecnologías de Kubernetes, pero explicaré todo a través de una comparación con la plataforma vSphere, con la que ustedes, como usuarios de VMware, están familiarizados. Esto le permitirá superar la aparente confusión y la gravedad de la comprensión de Kubernetes. Utilicé este enfoque dentro de VMware para presentar Kubernetes a diferentes audiencias, y demostró que funciona muy bien y ayuda a las personas a acostumbrarse a los conceptos clave más rápido.
Nota importante antes de comenzar. No uso esta comparación para probar similitudes o diferencias entre vSphere y Kubernetes. Tanto eso como otro, en esencia, son sistemas distribuidos y, por lo tanto, deben tener similitudes con cualquier otro sistema similar. Por lo tanto, al final, trato de presentar una tecnología tan maravillosa como Kubernetes a una amplia comunidad de usuarios.

Un poco de historia
Leer esta publicación implica conocer los contenedores. No describiré los conceptos básicos de los contenedores, ya que hay muchos recursos que hablan de esto. Al hablar con los clientes muy a menudo, veo que no pueden entender por qué los contenedores se apoderaron de nuestra industria y se hicieron muy populares en un tiempo récord. Para responder a esta pregunta, hablaré sobre mi experiencia práctica en la comprensión de los cambios que están teniendo lugar en nuestra industria.
Antes de explorar el mundo de las telecomunicaciones, fui desarrollador web (2003).
Este fue mi segundo trabajo remunerado después de trabajar como ingeniero / administrador de redes (sé que era un experto en todos los oficios). Desarrollé en PHP. Desarrollé todo tipo de aplicaciones, comenzando con las pequeñas que usaba mi empleador, terminando con una aplicación de votación profesional para programas de televisión, e incluso aplicaciones de telecomunicaciones que interactúan con los concentradores VSAT y los sistemas satelitales. La vida fue genial, con la excepción de un obstáculo importante que todo desarrollador conoce: las adicciones.
Al principio desarrollé la aplicación en mi computadora portátil, usando algo como la pila LAMP, cuando funcionó bien en mi computadora portátil, descargué el código fuente a los servidores host (¿todos recuerdan RackShack?) O a los servidores privados del cliente. Puedes imaginar que tan pronto como hice esto, la aplicación se bloqueó y no funcionó en estos servidores. La razón de esto es la adicción. Los servidores tenían otras versiones del software (Apache, PHP, MySQL, etc.) que las que yo usaba en la computadora portátil. Así que necesitaba encontrar una manera de actualizar las versiones de software en los servidores remotos (mala idea) o reescribir el código en mi computadora portátil para que coincida con las versiones en los servidores remotos (peor idea). Fue una pesadilla, a veces me odiaba y me preguntaba por qué me gano la vida.
Han pasado 10 años, apareció la compañía Docker. Como consultor de VMware en Professional Services (2013), escuché acerca de Docker y me dejó decir que no podía entender esta tecnología en esos días. Continué diciendo algo como: ¿por qué usar contenedores si hay máquinas virtuales? ¿Por qué renunciar a tecnologías importantes como vSphere HA, DRS o vMotion debido a ventajas tan extrañas como el lanzamiento instantáneo de contenedores o la eliminación de la sobrecarga del hipervisor? Después de todo, todos trabajan con máquinas virtuales y funcionan perfectamente. En resumen, lo miré en términos de infraestructura.
Pero luego comencé a mirar de cerca y me di cuenta. Todo lo relacionado con Docker está relacionado con los desarrolladores. Recién comenzando a pensar como desarrollador, inmediatamente me di cuenta de que si tuviera esta tecnología en 2003, podría empaquetar todas mis dependencias. Mis aplicaciones web podrían funcionar independientemente del servidor utilizado. Además, no sería necesario descargar el código fuente o configurar algo. Simplemente puede "empaquetar" mi aplicación en una imagen y pedir a los clientes que descarguen y ejecuten esta imagen. ¡Este es el sueño de cualquier desarrollador web!
Todo esto es genial. Docker resolvió el gran problema de interacción y empaque, pero ¿qué sigue? ¿Puedo, como cliente corporativo, administrar estas aplicaciones mientras escalo? Todavía quiero usar HA, DRS, vMotion y DR. Docker resolvió los problemas de mis desarrolladores y creó un montón de problemas para mis administradores (equipo de DevOps). Necesitan una plataforma para lanzar contenedores, la misma que para lanzar máquinas virtuales. Y volvimos nuevamente al principio.
Pero luego apareció Google, diciéndole al mundo sobre el uso de contenedores durante muchos años (de hecho, los contenedores fueron inventados por Google: cgroups) y el método correcto de usarlos, a través de una plataforma que llamaron Kubernetes. Luego abrieron el código fuente de Kubernetes. Presentado a la comunidad de Kubernetes. Y eso cambió todo de nuevo.
Comprensión de Kubernetes versus vSphere
Entonces, ¿qué es Kubernetes? En pocas palabras, Kubernetes para contenedores es lo mismo que vSphere para máquinas virtuales en un centro de datos moderno. Si utilizó VMware Workstation a principios de la década de 2000, sabrá que esta solución se consideró seriamente como una solución para centros de datos. Cuando apareció VI / vSphere con vCenter y hosts ESXi, el mundo de las máquinas virtuales cambió drásticamente. Kubernetes está haciendo lo mismo hoy con el mundo de los contenedores, brindando la capacidad de lanzar y administrar contenedores en producción. Y es por eso que comenzaremos a comparar vSphere lado a lado con Kubernetes para explicar los detalles de este sistema distribuido para comprender sus funciones y tecnologías.

Resumen del sistema
Como en vSphere hay hosts vCenter y ESXi en el concepto de Kubernetes, hay Master y Node's. En este contexto, Master en K8s es el equivalente de vCenter, en el sentido de que es el plano de gestión de un sistema distribuido. También es el punto de entrada para la API con la que interactúa al administrar su carga de trabajo. Del mismo modo, los nodos K8 funcionan como recursos informáticos, de forma similar a los hosts ESXi. Es en ellos que ejecutan cargas de trabajo (en el caso de los K8, los llamamos Pods). Los nodos pueden ser máquinas virtuales o servidores físicos. Por supuesto, con vSphere ESXi, los hosts siempre deben ser físicos.

Puede ver que K8 tiene un almacén de valores clave llamado "etcd". Este almacenamiento es similar a la base de datos de vCenter, donde guarda la configuración de clúster deseada a la que desea adherirse.
En cuanto a las diferencias: en Master K8s también puede ejecutar cargas de trabajo, pero en vCenter no puede. vCenter es un dispositivo virtual dedicado únicamente a la administración. En el caso de los K8, Master se considera un recurso informático, pero ejecutar aplicaciones empresariales en él no es una buena idea.
Entonces, ¿cómo se verá en la realidad? Utilizará principalmente la CLI para interactuar con Kubernetes (pero la GUI sigue siendo una opción muy viable). La captura de pantalla siguiente muestra que estoy usando una máquina Windows para conectarme a mi clúster de Kubernetes a través de la línea de comandos (uso cmder si está interesado) En la captura de pantalla tengo un nodo maestro y 4 nodos. Funcionan bajo el control de K8s v1.6.5, y el sistema operativo (SO) Ubuntu 16.04 está instalado en los nodos. Al momento de escribir esta publicación, vivimos principalmente en el mundo de Linux, donde Master y Node siempre ejecutan una distribución de Linux.
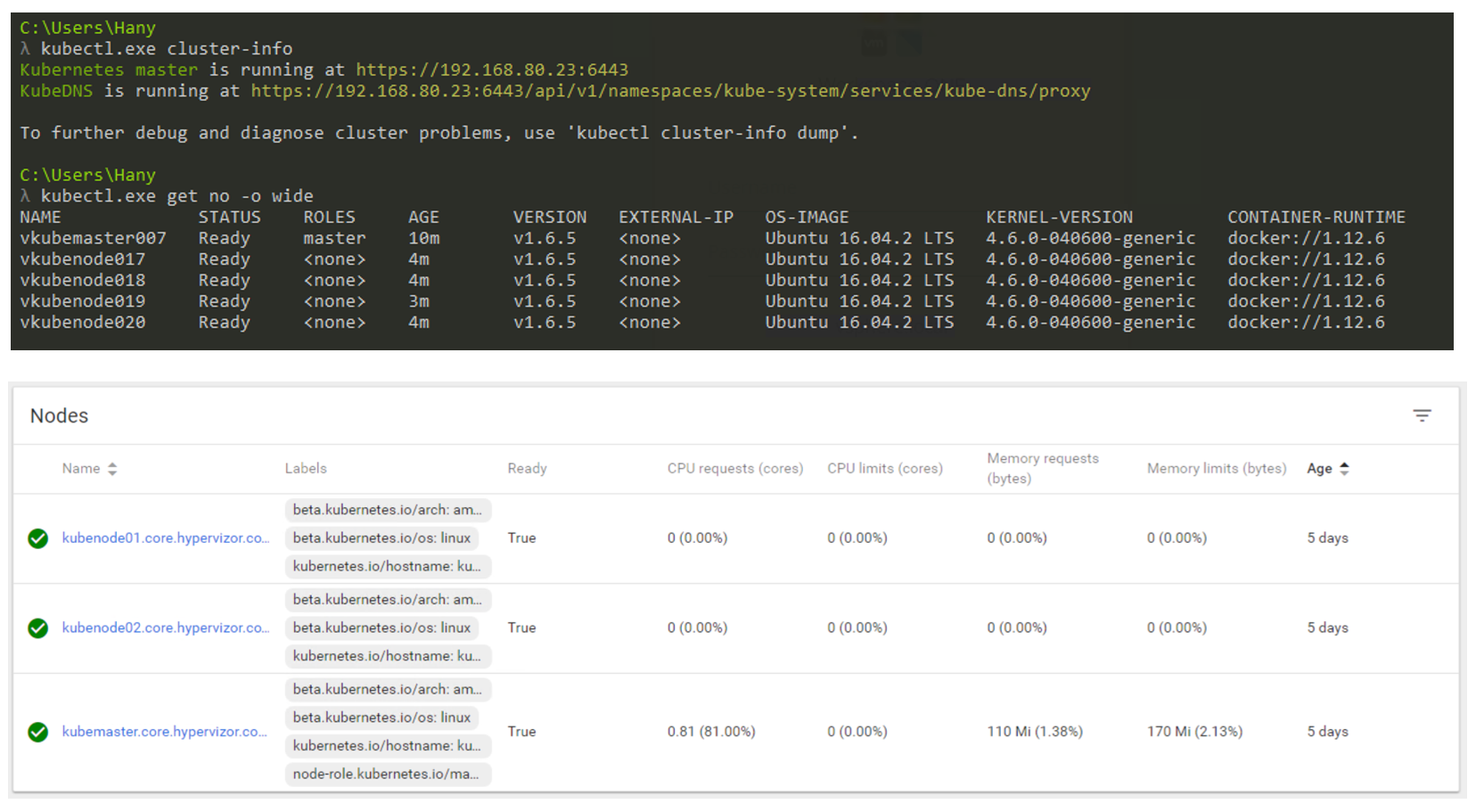 Gestión de clústeres de K8 a través de CLI y GUI.
Gestión de clústeres de K8 a través de CLI y GUI.Factor de forma de carga de trabajo
En vSphere, la máquina virtual es el límite lógico del sistema operativo. En Kubernetes, los Pods son límites de contenedores, al igual que el host ESXi, que puede ejecutar varias máquinas virtuales simultáneamente. Cada nodo puede ejecutar varios pods. Cada Pod recibe una dirección IP enrutable, como máquinas virtuales, para que los Pods se comuniquen entre sí.
En vSphere, las aplicaciones se ejecutan dentro del sistema operativo y en Kubernetes, las aplicaciones se ejecutan dentro de contenedores. Una máquina virtual solo puede funcionar con un sistema operativo a la vez, y un Pod puede ejecutar múltiples contenedores.
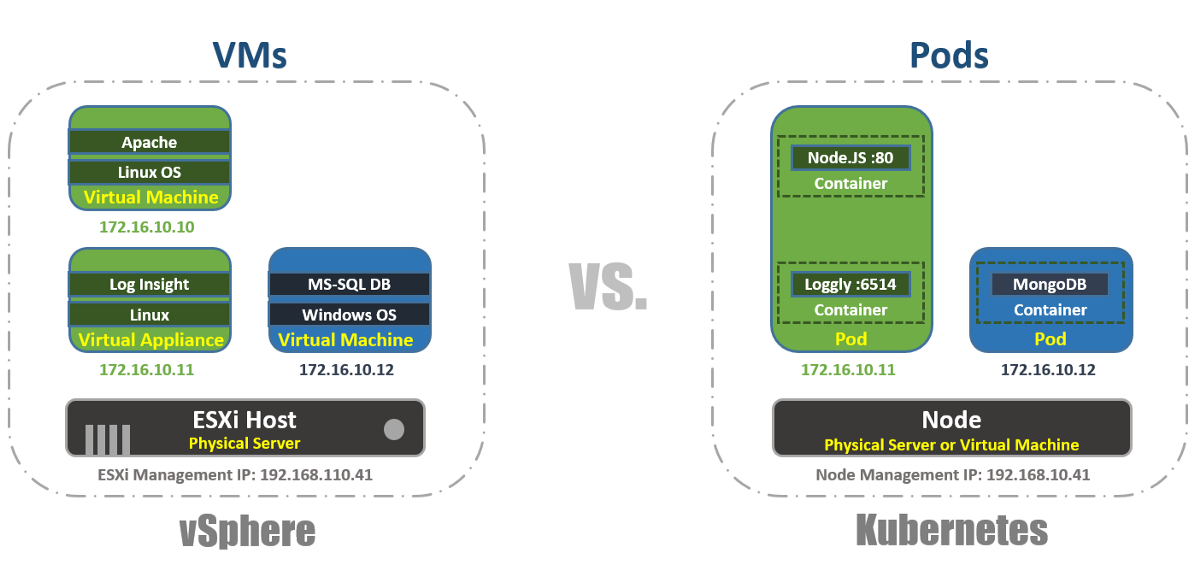
Así es como puede enumerar los Pods dentro del clúster K8s utilizando la herramienta kubectl a través de la CLI, verificar la capacidad de trabajo de los Pods, su edad, dirección IP y Nodos en los que están trabajando actualmente.

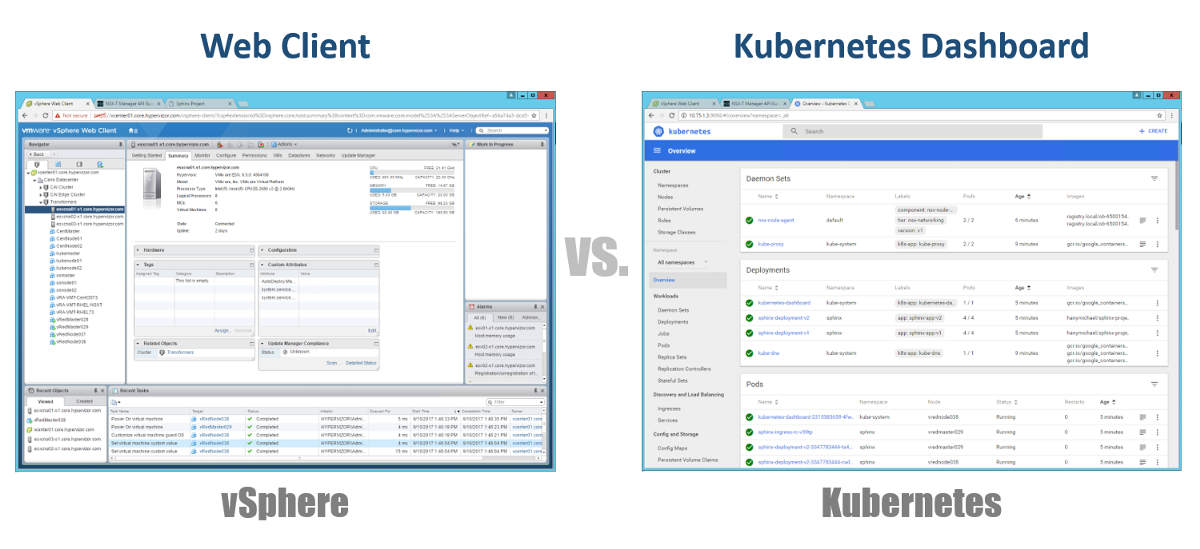
Gestión
Entonces, ¿cómo gestionamos nuestros Masters, Nodos y Pods? En vSphere, utilizamos el cliente web para administrar la mayoría de los componentes (si no todos) de nuestra infraestructura virtual. Para Kubernetes, de manera similar, usando Dashboard. Este es un buen portal web basado en GUI al que puede acceder a través de su navegador de la misma manera que con el cliente web vSphere. En las secciones anteriores, puede ver que puede administrar su clúster K8 utilizando el comando kubeclt de la CLI. Siempre es discutible dónde pasará la mayor parte de su tiempo en la CLI o en el Tablero gráfico. Dado que este último se está convirtiendo en una herramienta cada vez más poderosa todos los días (puede ver este video para estar seguro). Personalmente, creo que el Tablero es muy conveniente para monitorear rápidamente el estado o mostrar los detalles de varios componentes de K8, sin tener que ingresar comandos largos en la CLI. Encontrará un equilibrio entre ellos de forma natural.
Configuraciones
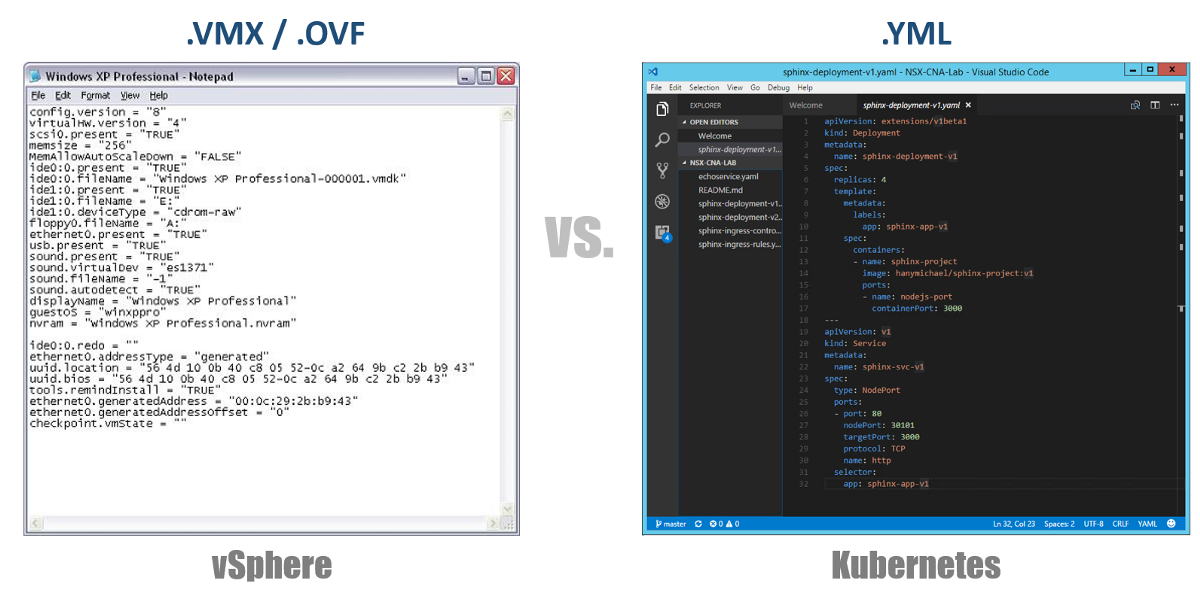
Uno de los conceptos muy importantes en Kubernetes es el estado deseado de las configuraciones. Usted declara que desea para casi cualquier componente de Kubernetes a través de un archivo YAML, y crea todo esto usando kubectl (o mediante un Tablero gráfico) como su estado deseado. De ahora en adelante, Kubernetes siempre se esforzará por mantener su entorno en un estado operativo determinado. Por ejemplo, si desea tener 4 réplicas de un Pod, los K8 continuarán monitoreando estos Pods, y si uno de ellos murió o el Nodo en el que funcionó tuvo problemas, K8 se recuperará automáticamente y creará automáticamente Pod en otro lado.
Volviendo a nuestros archivos de configuración de YAML, puede considerarlos como un archivo .VMX para una máquina virtual o un descriptor .OVF para un dispositivo virtual que desea implementar en vSphere. Estos archivos definen la configuración de la carga de trabajo / componente que desea ejecutar. A diferencia de los archivos VMX / OVF, que son exclusivos de las máquinas virtuales / dispositivos virtuales, los archivos de configuración YAML se utilizan para definir cualquier componente K8, como ReplicaSets, Services, Deployments, etc. Considere esto en las siguientes secciones.
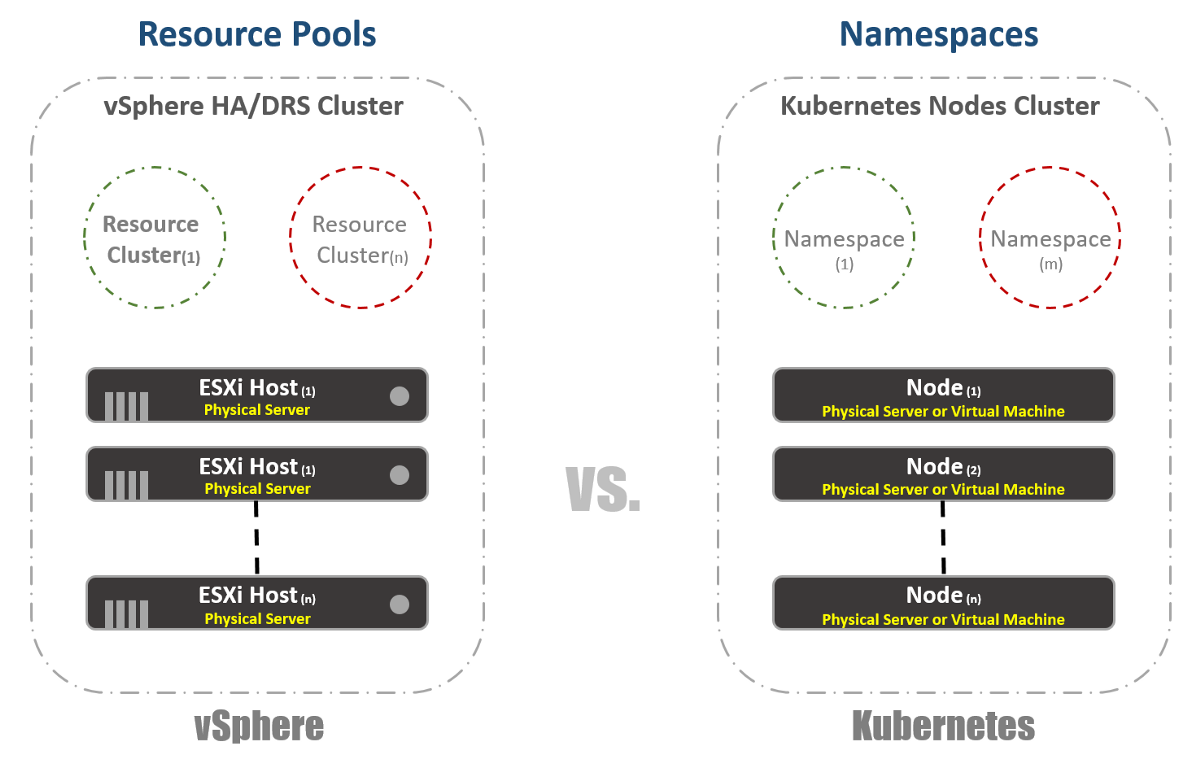
Clusters virtuales
En vSphere, tenemos hosts ESXi físicos que están agrupados lógicamente en clústeres. Estos grupos pueden dividirse en otros grupos virtuales llamados "Grupos de recursos". Estos "grupos" se utilizan principalmente para limitar los recursos. En Kubernetes, tenemos algo muy similar. Los llamamos "espacios de nombres", también se pueden utilizar para proporcionar límites de recursos, que se reflejarán en la siguiente sección. Sin embargo, la mayoría de las veces los "espacios de nombres" se utilizan como una herramienta de arrendamiento múltiple para aplicaciones (o usuarios, si utiliza clústeres K8 comunes). Esta es también una de las opciones con las que puede realizar la segmentación de la red con NSX-T. Considere esto en las siguientes publicaciones.
Gestión de recursos
Como mencioné en la sección anterior, los espacios de nombres en Kubernetes se usan comúnmente como un medio de segmentación. Otro uso de los espacios de nombres es la asignación de recursos. Esta opción se llama "Cuotas de recursos". Como se deduce de las secciones anteriores, la definición de esto ocurre en los archivos de configuración YAML, en los que se declara el estado deseado. En vSphere, como se puede ver en la captura de pantalla a continuación, determinamos esto a partir de la configuración de los grupos de recursos.

Identificación de carga de trabajo
Esto es bastante simple y casi lo mismo para vSphere y Kubernetes. En el primer caso, usamos los conceptos de Etiquetas para definir (o agrupar) cargas de trabajo similares, y en el segundo usamos el término "Etiquetas". En el caso de Kubernetes, la identificación de la carga de trabajo es obligatoria.

Reserva
Ahora por verdadera diversión. Si fue o es un gran admirador de vSphere FT, como yo, le encantará esta característica en Kubernetes, a pesar de algunas diferencias en las dos tecnologías. En vSphere, es una máquina virtual con una instancia de sombra en ejecución que se ejecuta en un host diferente. Grabamos instrucciones en la máquina virtual principal y las reproducimos en la máquina virtual en la sombra. Si la máquina principal deja de funcionar, la máquina virtual oculta se enciende de inmediato. Luego, vSphere intenta encontrar otro host ESXi para crear una nueva instancia oculta de la máquina virtual para mantener la misma redundancia. En Kubernetes, tenemos algo muy similar. ReplicaSets es la cantidad que especifica para ejecutar varias instancias de Pods. Si un Pod falla, hay otras instancias disponibles para atender el tráfico. Al mismo tiempo, los K8 intentarán lanzar un nuevo Pod en cualquier Nodo disponible para mantener el estado de configuración deseado. La diferencia principal, como ya habrás notado, es que en el caso de los K8, los Pods siempre funcionan y sirven el tráfico. No son cargas de trabajo sombra.

Balanceo de carga
Aunque esta no sea una función integrada en vSphere, es muy, muy a menudo necesario ejecutar equilibradores de carga en la plataforma. En el mundo vSphere, existen equilibradores de carga físicos o virtuales para distribuir el tráfico de red entre múltiples máquinas virtuales. Puede haber muchos modos de configuración diferentes, pero supongamos que nos referimos a la configuración One-Armed. En este caso, equilibra la carga del tráfico Este-Oeste en sus máquinas virtuales.
Del mismo modo, Kubernetes tiene el concepto de "Servicios". El servicio en K8 también se puede utilizar en diferentes modos de configuración. Elija la configuración "ClusterIP" para compararla con el equilibrador de carga de un solo brazo. En este caso, el Servicio en K8 tendrá una dirección IP virtual (VIP), que siempre es estática y no cambia. Este VIP distribuirá el tráfico entre varios Pods. Esto es especialmente importante en el mundo de Kubernetes, donde por naturaleza los Pods son efímeros, se pierde la dirección IP del Pod en el momento en que muere o se elimina. Por lo tanto, siempre debe proporcionar un VIP estático.
Como ya mencioné, el Servicio tiene muchas otras configuraciones, por ejemplo, "NodePort", donde asigna un puerto en el nivel de Nodo y luego realiza la traducción de traducción de dirección de puerto para Pods. También hay un "LoadBalancer" donde ejecuta una instancia de Load Balancer desde un proveedor externo o en la nube.

Kuberentes tiene otro mecanismo de equilibrio de carga muy importante llamado "Controlador de entrada". Puede considerarlo un equilibrador de carga de aplicaciones en línea. La idea principal es que el Controlador de Ingreso (en forma de Pod) se iniciará con una dirección IP visible desde el exterior. Esta dirección IP puede tener algo así como registros DNS comodín. Cuando el tráfico llega al Controlador de Ingreso usando una dirección IP externa, verifica los encabezados y determina usando el conjunto de reglas que estableció previamente a qué Pod pertenece este nombre. Por ejemplo: sphinx-v1.esxcloud.net se dirigirá al Servicio sphinx-svc-1, y sphinx-v2.esxcloud.net se dirigirá al Servicio sphinx-svc2, etc.

Almacenamiento y red
El almacenamiento y las redes son temas muy, muy amplios cuando se trata de Kubernetes. Es casi imposible hablar brevemente sobre estos dos temas en una publicación introductoria, pero pronto hablaré en detalle sobre los diferentes conceptos y opciones para cada uno de estos temas. Mientras tanto, veamos rápidamente cómo funciona la pila de red en Kubernetes, ya que la necesitaremos en la siguiente sección.
Kubernetes tiene varios "complementos" de red que puede usar para configurar la red de sus nodos y pods. Un complemento común es "kubenet", que actualmente se usa en mega nubes como GCP y AWS. Aquí hablaré brevemente sobre la implementación de GCP y luego mostraré un ejemplo práctico de implementación en GKE.

A primera vista, esto puede parecer demasiado complicado, pero espero que puedan entender todo esto al final de esta publicación. En primer lugar, vemos que tenemos dos nodos de Kubernetes: Nodo 1 y Nodo (m). Cada nodo tiene una interfaz eth0, como cualquier máquina Linux. Esta interfaz tiene una dirección IP para el mundo exterior, en nuestro caso, en la subred 10.140.0.0/24. El dispositivo Upstream L3 actúa como la puerta de enlace predeterminada para enrutar nuestro tráfico. Puede ser un conmutador L3 en su centro de datos o un enrutador VPC en la nube, como GCP, como veremos más adelante. ¿Va todo bien?
Además, vemos que tenemos la interfaz Bridge cbr0 dentro del nodo. Esta interfaz es la puerta de enlace predeterminada para la subred IP 10.40.1.0/24 en el caso del nodo 1. Kubernetes asigna esta subred a cada nodo. Los nodos generalmente obtienen una subred / 24, pero puede cambiar esto usando NSX-T (lo cubriremos en las siguientes publicaciones). Por el momento, esta subred es la que emitiremos direcciones IP para Pods. De esta manera, cualquier Pod dentro del Nodo 1 obtendrá una dirección IP de esta subred. En nuestro caso, el Pod 1 tiene una dirección IP de 10.40.1.10. Sin embargo, observa que hay dos contenedores anidados en este Pod. Ya hemos dicho que dentro de un Pod se pueden lanzar uno o varios contenedores, que están estrechamente relacionados entre sí en términos de funcionalidad. Esto es lo que vemos en la figura. El contenedor 1 escucha en el puerto 80 y el contenedor 2 escucha en el puerto 90. Ambos contenedores tienen la misma dirección IP 10.40.1.10, pero no poseen el espacio de nombres de red. OK, entonces, ¿quién es el dueño de esta pila de red? En realidad, hay un contenedor especial llamado "Pause Container". El diagrama muestra que su dirección IP es la dirección IP de Pod para comunicarse con el mundo exterior. Por lo tanto, Pause Container posee esta pila de red, incluida la dirección IP 10.40.1.10, y, por supuesto, redirige el tráfico al contenedor 1 al puerto 80, y también redirige el tráfico al contenedor 2 al puerto 90.
¿Ahora tiene que preguntarse cómo se redirige el tráfico al mundo exterior? Tenemos el reenvío IP estándar de Linux habilitado para reenviar el tráfico de cbr0 a eth0. Esto es genial, pero ¿no está claro cómo el dispositivo L3 puede aprender cómo reenviar el tráfico a su destino? En este ejemplo específico, no tenemos enrutamiento dinámico para el anuncio de esta red. Por lo tanto, debemos tener algún tipo de rutas estáticas en el dispositivo L3. Para llegar a la subred 10.40.1.0/24, debe reenviar el tráfico a la dirección IP del nodo 1 (10.140.0.11) y llegar a la subred 10.40.2.0/24, la próxima esperanza es el nodo (m) con la dirección IP 10.140.0.12.
Todo esto es genial, pero es una forma poco práctica de administrar sus redes. Soportar todas estas rutas mientras escala su clúster será una pesadilla absoluta para los administradores de red. Es por eso que se necesitan algunas soluciones, como CNI (Container Network Interface) en Kuberentes, para administrar la conectividad de red. NSX-T es una de esas soluciones con una funcionalidad muy amplia tanto para la interacción de red como para la seguridad.
Recuerde que miramos el complemento kubenet, no CNI. El complemento de Kubenet es lo que utiliza Google Container Engine (GKE), y la forma en que lo hacen es bastante divertido porque está completamente definido por software y automatizado en su nube. , GCP. .
Que sigue
Kuberentes. ,
.
La segunda parte. .
.