Muchos proyectos enfrentan el problema de las pruebas escamosas, y este tema se ha planteado más de una vez en Habré. Las pruebas que no han decidido su condición constantemente requieren no solo tiempo de máquina, sino también el tiempo de los desarrolladores y probadores. Y si en una empresa comercial puede asignar un determinado recurso para resolver este problema y nombrar personas responsables, entonces en la comunidad de código abierto no es tan simple. Especialmente cuando se trata de grandes proyectos, por ejemplo, como Apache Ignite, donde hay casi 60 mil pruebas diferentes.

En esta publicación, de hecho, le diremos cómo resolver este problema en Apache Ignite. Somos Dmitry Pavlov, ingeniero de software líder / gerente comunitario en GridGain, y Nikolai Kulagin, ingeniero de TI en Sberbank Technologies.
Todo lo escrito a continuación no representa la posición de ninguna compañía, incluido Sberbank. Esta historia es exclusivamente de miembros de la comunidad Apache Ignite.Apache Ignite y pruebas
La historia de Apache Ignite comienza en 2014, cuando GridGain donó la primera versión del producto interno a Apache Software Foundation. Han pasado más de 4 años desde entonces, y durante este tiempo el número de pruebas se acercó a la marca de 60 mil.
Utilizamos JetBrains TeamCity como el servidor de integración continua, gracias a los muchachos de JetBrains por apoyar el movimiento de código abierto. Todas nuestras pruebas se distribuyen entre las suites, cuyo número para la rama maestra es cercano a 140. En las suites, las pruebas se agrupan según algún criterio. Esto puede probar solo la funcionalidad de Machine Learning [RunMl], solo el caché [RunCache] o el [RunAll] completo. En el futuro, la ejecución de las pruebas significará exactamente [RunAll]: una verificación completa. Lleva aproximadamente 55 horas de tiempo de máquina.
Junit se usa como la biblioteca principal, pero hay pocas pruebas unitarias. En su mayor parte, todas nuestras pruebas son pruebas de integración, ya que contienen el lanzamiento de uno o más nodos (y esto lleva varios segundos). Por supuesto, las pruebas de integración son convenientes porque una de esas pruebas cubre muchos aspectos e interacciones, lo cual es bastante difícil de lograr con una sola prueba unitaria. Pero también hay desventajas: en nuestro caso, este es un tiempo de entrega bastante largo, así como la dificultad de encontrar un problema.
Problemas con escamas
Parte de estas pruebas es escamosa. Ahora, según la clasificación de TeamCity, aproximadamente 1,700 pruebas están marcadas como escamosas, es decir, con un cambio de estado sin cambiar el código o la configuración. Estas pruebas no se pueden ignorar, ya que existe el riesgo de que se produzca un error en la producción. Por lo tanto, tienen que ser revisados y reiniciados, a veces varias veces, para analizar los resultados de las caídas, y esto requiere un tiempo y esfuerzo valiosos. Y si los miembros existentes de la comunidad hacen frente a esta tarea, para los nuevos contribuyentes esto puede convertirse en una barrera real. Debe admitir que cuando realiza cambios en el Java Doc, no espera encontrar un bloqueo, pero no uno, sino varias docenas.

¿Quién tiene la culpa?
La mitad de los problemas con las pruebas escamosas surgen debido a la configuración del equipo, debido al tamaño de la instalación. Y la segunda mitad está directamente relacionada con las personas que fallaron y no repararon su error.
Convencionalmente, todos los miembros de la comunidad se pueden dividir en dos grupos:
- Entusiastas que ingresan a la comunidad por su propia voluntad y contribuyen a su tiempo libre.
- Colaboradores a tiempo completo que trabajan para empresas que de alguna manera usan o están asociadas con este producto de código abierto.
Un contribuyente del primer grupo bien puede hacer una única edición y abandonar la comunidad. Y alcanzarlo en caso de detección de un error es casi imposible. Es más fácil interactuar con personas del segundo grupo, es más probable que respondan a una prueba que rompen. Pero sucede que una empresa que anteriormente estaba interesada en un producto ha dejado de necesitarlo. Ella está dejando la comunidad, y sus empleados contribuyentes están con ella. O es posible que el contribuyente abandone la empresa y, con ella, la comunidad. Por supuesto, después de tales cambios, algunos aún continúan participando en la comunidad. Pero no todos.
¿Quién lo arreglará?
Si estamos hablando de personas que abandonaron la comunidad, entonces sus errores, por supuesto, van a los contribuyentes actuales. Vale la pena señalar que para la revisión que condujo al error, el revisor también es responsable, pero también puede ser un entusiasta, es decir, no siempre estará disponible.
Sucede que resulta llegar a una persona, decirle: este es el problema. Pero él dice: no, esta no es mi solución introdujo un error. Dado que una ejecución completa de la rama maestra se realiza automáticamente con una cola relativamente libre, esto ocurre con mayor frecuencia por la noche. Antes de esto, se pueden verter varios commits en la rama durante todo el día.
En TeamCity, cualquier modificación del código se considera como un registro de cambios. Si después de tres cambiadores tenemos una nueva caída, entonces tres personas dirán que esto no se debe a su compromiso. Si hay cinco cambiadores, lo escucharemos de cinco personas.
Otro problema: informar al contribuyente que las pruebas deben ejecutarse antes de cada revisión. Algunos no saben dónde, qué y cómo correr. O las pruebas se ejecutaron, pero el contribuyente no escribió sobre eso en el ticket. También hay problemas en esta etapa.
Adelante Suponga que las pruebas se ejecutan y que en el ticket hay un enlace a los resultados. Pero, como resultó, esto no ofrece ninguna garantía de análisis de las pruebas de ejecución. El contribuyente puede mirar su carrera, ver algunas gotas allí, pero escribir "TeamCity se ve bien". El revisor, especialmente si está familiarizado con el contribuyente o lo ha revisado con éxito antes, puede que realmente no vea el resultado. Y obtenemos este "TeamCity se ve bien":
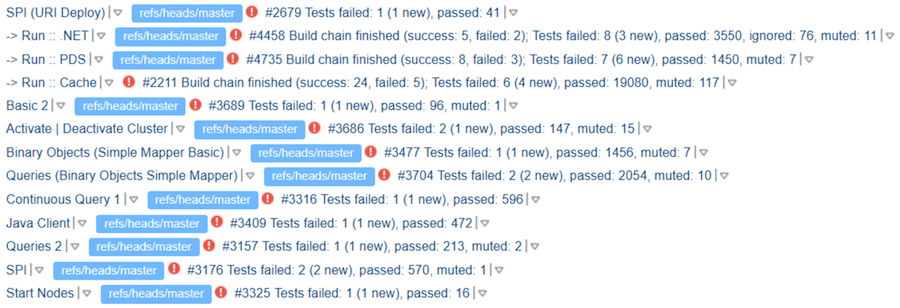
Donde "Bueno" está aquí no está claro. Pero aparentemente, los autores al menos saben que las pruebas deben ejecutarse.
Cómo luchamos contra esto
Método 1. Pruebas separadas
Dividimos las pruebas en dos grupos. En el primero, "limpio" - pruebas estables. En el segundo - inestable. El enfoque es bastante obvio, pero no funcionó incluso con dos intentos. Por qué Porque una suite con pruebas inestables se convierte en un gueto donde algo comienza a expirar necesariamente, se bloquea, etc. Como resultado, todos comienzan a ignorar estas pruebas siempre problemáticas. En general, no tiene sentido dividir las pruebas por grado.
Método 2. Separación y notificación.
La segunda opción es similar a la primera: asignar pruebas más estables y ejecutar las pruebas de PR restantes por la noche. Si algo se rompe en un grupo estable, se envía un mensaje al contribuyente con las herramientas estándar de TeamCity que dice que algo debe repararse.
... 0 personas reaccionaron a estos mensajes. Todos los ignoraron.
Método 3. Monitoreo diario
Dividimos las suites en varios "observadores", los miembros más responsables de la comunidad, y los firmamos para recibir alertas sobre caídas. Como resultado, se confirmó en la práctica que el entusiasmo tiende a terminar. Los contribuyentes abandonan esta empresa y dejan de verificar regularmente. Luego lo extrañé, miré allí, y otra vez algo se arrastró hacia el maestro.
Método 4. Automatización
Después de otro método fallido, los chicos de GridGain recordaron una utilidad previamente desarrollada que agregó la funcionalidad que faltaba en ese momento en TeamCity. A saber, la capacidad de ver estadísticas generales sobre el número de caídas: cuánto y qué cayó, deterioró o mejoró el resultado al día siguiente. Esta utilidad se desarrolló gradualmente, se agregaron informes y se les cambió el nombre. Luego agregaron notificaciones, renombradas nuevamente. Entonces resultó TeamCity Bot. Ahora tiene casi 500 confirmaciones y 7 contribuyentes y está en el repositorio complementario de Apache.
¿Qué hace el bot? Sus capacidades se pueden combinar en dos grupos:
- Monitoreo de proyectos: monitoreo visual al ver los resultados de las ejecuciones, así como la notificación automática en mensajería instantánea (por ejemplo, holgura)
- Verificación de sucursal: análisis de pruebas de relaciones públicas, así como la emisión de una visa en un boleto.
Flujo de trabajo de TeamCity Bot
Antes de Apache Ignite Teamcity Bot, el proceso de "contribución" a la comunidad era el siguiente:
- En JIRA, uno de los tickets está seleccionado y arreglado;
- Se crea una solicitud de extracción;
- Ejecuta pruebas que pueden verse afectadas por los cambios realizados;
- Si se aprueban las pruebas, el confirmador puede previsualizar y moderar la solicitud de extracción.
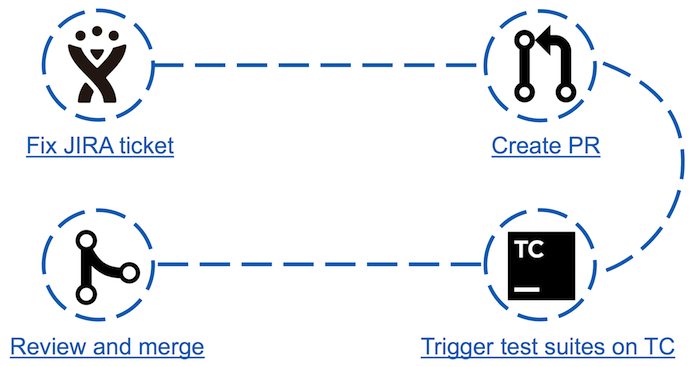
Parece simple, pero de hecho el tercer punto puede ser una barrera para algunos contribuyentes. Por ejemplo: un recién llegado a la comunidad decide hacer su primera contribución eligiendo el boleto más simple. Esto podría estar editando un Java Doc o actualizando versiones de dependencia de Maven. Analizando los resultados de la carrera en su pequeño arreglo, de repente descubre que han caído unas 30 pruebas. De dónde viene el número de pruebas fallidas y cómo analizarlas, él no lo sabe. Es de esperar que el contribuyente nunca vuelva aquí nuevamente.
Los miembros más experimentados de la comunidad también sufren de escamas: pasan tiempo analizando pruebas que se cayeron por casualidad y, por lo tanto, obstaculizan el desarrollo de productos.
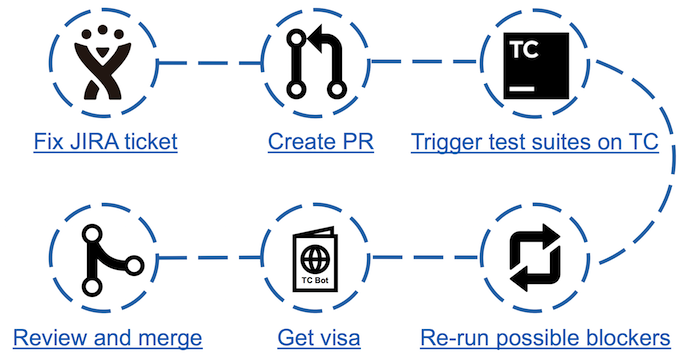 Esquema de contribución con TeamCity Bot
Esquema de contribución con TeamCity BotCon la llegada del bot, los pasos en el contrajuego aumentaron, pero el tiempo dedicado a analizar las pruebas caídas disminuyó significativamente. Ahora es suficiente para ejecutar la prueba y después de pasarla, mira la página del bot correspondiente. Si hay posibles bloqueadores (pruebas descartadas que no se consideran escamosas), es suficiente realizar una doble verificación, después de lo cual puede obtener una visa en forma de un comentario en JIRA con los resultados de la prueba.
Resumen de características
 Inspeccionar contribución: una lista de todos los RP no cerrados con un resumen de cada información: la fecha de la última actualización, el número de RP, el nombre, el autor y el boleto en JIRA
Inspeccionar contribución: una lista de todos los RP no cerrados con un resumen de cada información: la fecha de la última actualización, el número de RP, el nombre, el autor y el boleto en JIRA .
 Para cada solicitud de extracción, hay disponible una pestaña con información más detallada: el nombre de RP correcto, sin el cual el bot no podrá encontrar el ticket deseado en JIRA; si se realizaron pruebas; si el resultado de la prueba está listo; dejó un comentario en JIRA.
Para cada solicitud de extracción, hay disponible una pestaña con información más detallada: el nombre de RP correcto, sin el cual el bot no podrá encontrar el ticket deseado en JIRA; si se realizaron pruebas; si el resultado de la prueba está listo; dejó un comentario en JIRA.Análisis de resultados de la prueba:


Aquí hay dos informes sobre cómo probar el mismo PR. El primero es del bot. El segundo es un informe estándar sobre Teamcity. La diferencia en la cantidad de información es obvia, y esto no tiene en cuenta el hecho de que para ver el historial de las pruebas TC, también será necesario realizar varias transiciones a páginas adyacentes.
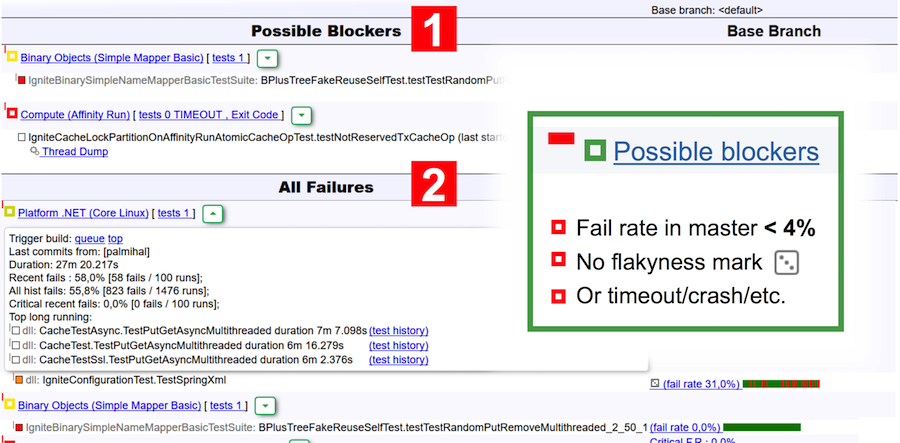
Volvamos al informe del bot. Este informe se divide visualmente en dos tablas: posibles bloqueadores y todos los bloqueos. Los bloqueadores incluyen pruebas que:
- tener una tasa de falla en el maestro de menos del 4% (menos de 4 inicios de cada 100 no tuvieron éxito);
- no son escamosas en la clasificación de TeamCity;
- cayó debido a un tiempo de espera, falta de memoria, código de salida, falla de JVM.
Por ejemplo, en la captura de pantalla anterior, dos suites se indican como posibles bloqueadores: en la primera, la prueba cayó, y en la segunda, se produjo un tiempo de espera.
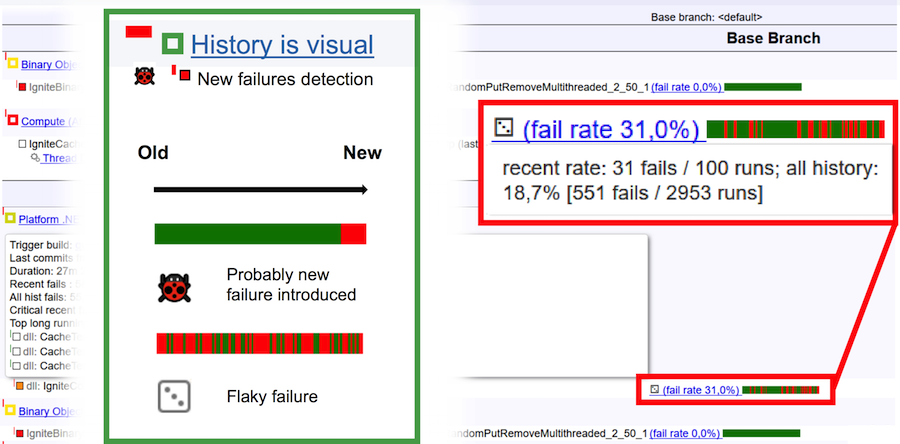
Para finalmente entender qué es una prueba escamosa y qué es un error, considere la imagen de arriba. La barra horizontal es de 100 carreras. Barra verde vertical: éxito al pasar la prueba, rojo: caída. En el caso de un error, el historial de ejecución se ve natural: una barra verde al final cambia de color a rojo. Esto significa que fue en este lugar donde apareció un error y la prueba comenzó a caer constantemente. Si tenemos ante nosotros una prueba escamosa, entonces su historial de carreras es una alternancia continua de colores verde y rojo.
Análisis de resultados de prueba
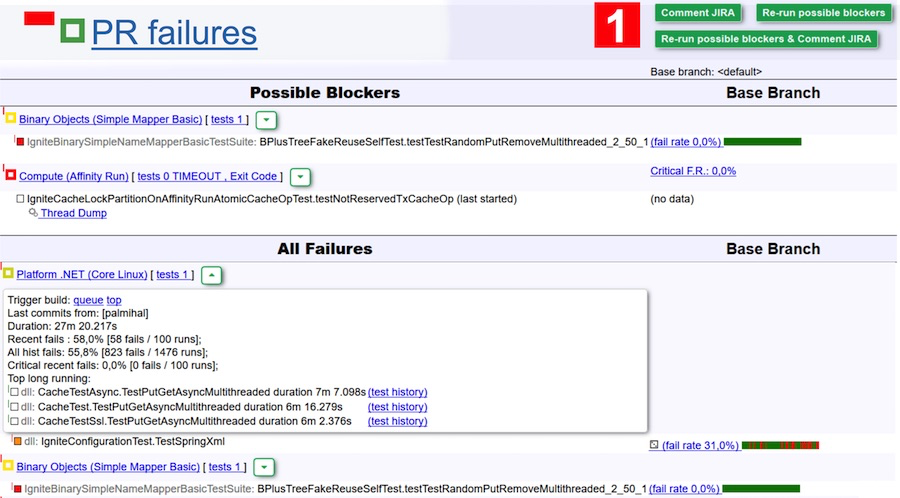
Por ejemplo, analizamos los resultados de pasar las pruebas en la captura de pantalla anterior. Según la versión del bot, puede haber dos bloqueos debido a un error: se enumeran en la tabla de posibles bloqueadores. Pero bien pueden ser pruebas escamosas con una baja tasa de fracaso. Para excluir esta opción, simplemente haga clic en el botón Volver a ejecutar posibles bloqueadores, y estas dos suites pasarán a una doble verificación. Para facilitar aún más la tarea, puede hacer clic en Volver a ejecutar posibles bloqueadores y comentar JIRA, y obtener un comentario (y con él una notificación por correo electrónico) del bot después de que se complete la verificación. Luego entre y vea si hay un problema o no.
Para los revisores, esto es muy bueno. Puede olvidarse de las ediciones que no pasaron ninguna verificación, pero simplemente haga clic en varias ediciones, haga clic en el botón verde grande Volver a ejecutar y espere la carta.
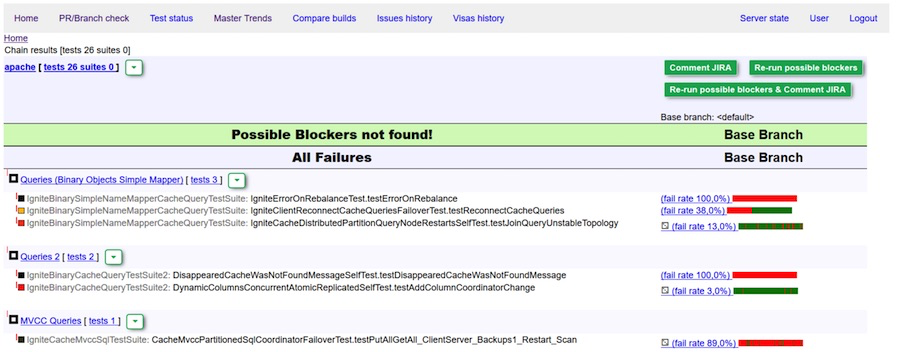 Informe perfecto: no se detectaron bloqueadores
Informe perfecto: no se detectaron bloqueadores

Visa verde (comentario) del bot. No se encontraron bloqueadores.
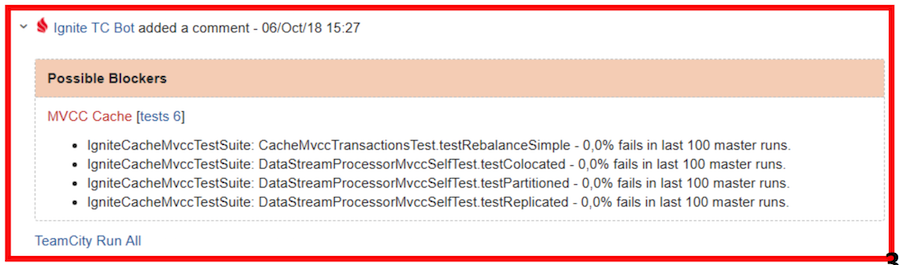
Visa roja: se requieren verificaciones y / o errores de ediciónSucede que algunos errores todavía se filtran en el "maestro". Como dijimos, antes de esto se luchaba a través de notificaciones personales. O alguna persona se aseguró de que nada cayera. Ahora estamos usando una solución más simple:

Cuando se detecta un nuevo error, se envía un mensaje a la lista de desarrolladores, que indica los contribuyentes y sus cambiadores, que pueden ser la causa del error. Entonces, toda la comunidad descubrirá quién hizo que todo sucediera.
Por lo tanto, pudimos aumentar el número de soluciones rápidas y reducir en gran medida el tiempo que lleva solucionar el problema.
Monitoreo del estado del asistente
Otra de las funciones del bot es monitorear el estado del asistente con las estadísticas de los últimos lanzamientos.

Domina las tendencias

La página de Tendencias maestras compara dos selecciones "maestras" para períodos de tiempo específicos. Para cada elemento de la tabla, se muestra el valor máximo, mínimo y la mediana.

Además de los resultados generales para toda la muestra, la tabla contiene gráficos para cada indicador con la visualización de los valores de cada compilación. Al hacer clic en un punto, puede ir a los resultados de la ejecución en TeamCity. Además, es posible eliminar el resultado de las estadísticas. Esto es útil cuando se producen valores anormales debido a fallas graves, que el contribuyente probablemente no tenga la culpa. Dichos resultados deben excluirse para que no se tengan en cuenta al calcular las mismas pruebas escamosas. Además, la construcción también se puede distinguir para rastrear los resultados de cada indicador.
Apache Ignite Teamcity Bot ahora tiene más de 65 miembros registrados. Durante todo el período de uso del bot, las visas recibieron más de 400 solicitudes de extracción, y en promedio se emiten cinco visas por día.
Estructura de TeamCity Bot
El bot está alojado en un servidor separado, va a ignite.apache.org para obtener datos, notifica públicamente a todos en la lista de desarrolladores, esta es nuestra plataforma principal para desarrolladores de Ignite, y escribe visas para tickets a través de la API JIRA.
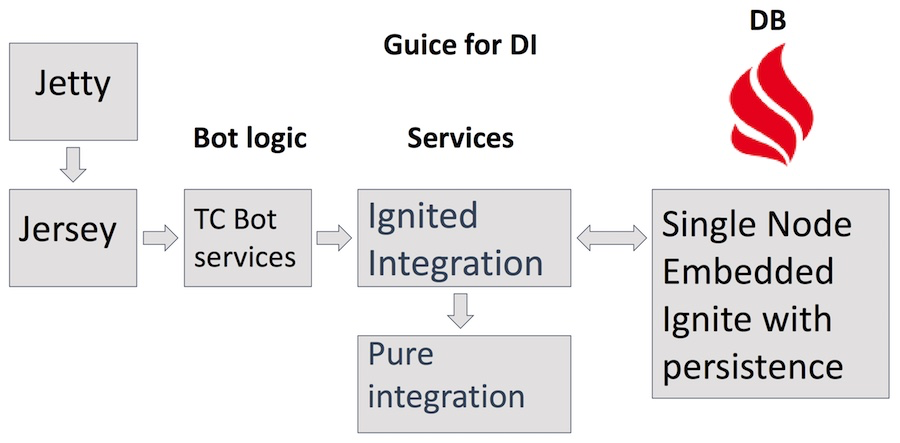
Utiliza el servidor Jetty, los servlets de Jersey, una serie de servicios con una lógica empresarial compleja del propio bot, incluidos los servicios Teamcity, JIRA y GitHub que acceden al servicio de integración encendida. Además de esta integración pura para solicitudes http. Como almacenamiento: el producto de Apache Ignite en el modo incrustado de configuración de nodo único con persistencia activa. Además de las ventajas obvias de usar Ignite como base de datos, también nos ayuda a encontrar varias áreas de aplicación de Ignite y comprender qué es conveniente y qué no.
La primera versión de la implementación del bot se inspiró en un artículo sobre el almacenamiento en caché REST y fue un caché REST y servicios GitHub y Teamcity. Teamcity xml y json devueltos del servidor fueron analizados por Pure Java Objects, que luego se almacenaron en caché. Al principio funcionó, y bastante rápido. Pero con un aumento en la cantidad de datos, los resultados comenzaron a deteriorarse.
Vale la pena señalar que TeamCity elimina una historia anterior a ~ 2 semanas, pero el bot no. Finalmente, con este enfoque, aparecieron toneladas de datos que son muy difíciles de administrar.
TeamCity Bot Development
El nuevo enfoque implementa una opción compacta de almacenamiento de datos y opta por un pequeño número de particiones de caché. Una gran cantidad de particiones en un nodo afecta negativamente la velocidad de sincronización de datos al disco y aumenta el tiempo de inicio del clúster.
Todas las actualizaciones de datos principales se realizan de forma asincrónica, porque de lo contrario corremos el riesgo de tener una mala experiencia de usuario debido al lento retorno de los datos de TeamCity.
Para las cadenas que rara vez cambian sus valores (por ejemplo, los nombres de las pruebas), se realiza un mapeo simple en id, que es generado por Atomic Sequence. Aquí hay un ejemplo de tal entrada:

El nombre largo de la prueba corresponde al número int, que se almacena en todas las compilaciones. Esto ahorra una gran cantidad de recursos. Además de los métodos que devuelven esta línea está el interceptor de caché en memoria de Guava. Gracias a la anotación de caché, incluso en el montón no seleccionamos líneas al leerlas de Ignite por id. Y por id siempre obtenemos la misma línea, lo cual es bueno para el rendimiento.
Para las líneas "impredecibles", por ejemplo, los registros de seguimiento de pila, se utilizan varios tipos de compresión: compresión gzip, compresión rápida o sin comprimir, según cuál sea mejor. Todos estos métodos ayudan a ajustar los datos máximos en la memoria y dan rápidamente una respuesta al cliente.
Por qué TeamCity Bot es mejor
Esto no quiere decir que TeamCity no tenga las características enumeradas anteriormente. Lo están, pero dispersos en una pila de lugares diferentes. En el bot, todo se recopila en una página y puede comprender rápidamente cuál es el problema.
Una buena adición es la carta que el bot envía en la hoja de desarrollo cuando detecta un problema. Inmediatamente en la comunidad hay una ocasión para comenzar una discusión: "¿Quizás, ahora, vamos a revertir?". Esto agrega confianza a los revisores.
Con el bot, es mucho más fácil para los nuevos contribuyentes unirse al proceso de desarrollo. Al hacer su primera solución, no siempre sabe qué implican los cambios realizados. Y sumergiéndose de lleno en el análisis de los resultados de las pruebas en TeamCity, puede perder fácilmente su entusiasmo por un mayor desarrollo. Apache Ignite TeamCity Bot lo ayudará a comprender rápidamente si hay un problema y a mantener el entusiasmo.
Esperamos que el bot simplifique la vida de los contribuyentes actuales y atraiga a nuevas personas a la comunidad. Finalmente, aconsejamos, por supuesto, evitar la aparición de una gran cantidad de pruebas escamosas, porque es difícil lidiar con ellas. Y confíe en los robots: no tienen preferencias y no confían en la palabra de la gente.