
 Anton Chaynikov, desarrollador de Data Science, Redmadrobot
Anton Chaynikov, desarrollador de Data Science, Redmadrobot
Hola Habr! Hoy hablaré sobre las dificultades en el camino al chatbot, lo que facilita el trabajo de los operadores de chat de la compañía de seguros. Más precisamente, cómo enseñamos al bot a distinguir las solicitudes entre sí mediante el aprendizaje automático. Con qué modelos se experimentaron y cuáles obtuvieron los resultados. ¿Cómo cuatro enfoques para limpiar y enriquecer datos de calidad decente y cinco intentos de limpiar datos de calidad "indecente"?
Desafío
El chat de la compañía de seguros recibe más de 100500 llamadas de clientes por día. La mayoría de las preguntas son simples y repetitivas, pero los operadores no son más fáciles y los clientes aún tienen que esperar de cinco a diez minutos. ¿Cómo mejorar la calidad del servicio y optimizar los costos de mano de obra para que los operadores tengan menos rutina y los usuarios tengan sensaciones más agradables al resolver rápidamente sus problemas?
Y haremos un chatbot. Permítale leer mensajes de usuario, dar instrucciones para casos simples y hacer preguntas estándar para casos complejos para obtener la información que el operador necesita. Un operador en vivo tiene un árbol de guiones: un guión (o diagrama de flujo) que dice qué preguntas pueden hacer los usuarios y cómo responderlas. Tomaríamos este esquema y lo pondríamos en un chatbot, pero es una mala suerte: el chatbot no entiende humanamente y no sabe cómo relacionar la pregunta del usuario con la rama del script.
Entonces, le enseñaremos con la ayuda del buen aprendizaje automático. Pero no puede simplemente tomar un dato generado por los usuarios y enseñarle un modelo de calidad decente. Para hacer esto, debe experimentar con la arquitectura del modelo, los datos, para limpiarlos y, a veces, volver a recopilarlos.
Cómo enseñar a un bot:
- Considere las opciones del modelo: cómo se combinan el tamaño del conjunto de datos, los detalles de la vectorización de los textos, la reducción de la dimensión, el clasificador y la precisión final.
- Limpiemos los datos decentes: encontraremos clases que se pueden tirar de forma segura; descubriremos por qué los últimos seis meses de marcado son mejores que los tres anteriores; determinar dónde se encuentra el modelo y dónde está el marcado; Descubra cómo los errores tipográficos pueden ser útiles.
- Limpiaremos los datos "indecentes": descubriremos cuándo la agrupación es útil e inútil, a medida que los usuarios y operadores hablan cuando es hora de dejar de sufrir e ir a recoger el marcado.
Textura
Teníamos dos clientes, compañías de seguros con chats en línea, y proyectos de capacitación de chatbot (no los llamaremos, esto no es importante), con una calidad de datos muy diferente. Bueno, si la mitad de los problemas del segundo proyecto pudieran resolverse mediante manipulaciones del primero. Los detalles están abajo.
Desde un punto de vista técnico, nuestra tarea es clasificar textos. Esto se realiza en dos etapas: primero, los textos se vectorizan (usando tf-idf, doc2vec, etc.), luego el modelo de clasificación se entrena en los vectores (y clases) obtenidos: bosque aleatorio, SVM, red neuronal, etc. Y así sucesivamente.
De dónde provienen los datos:
- Historial de chat de carga SQL. Campos de carga relevantes: texto del mensaje; autor (cliente u operador); agrupar mensajes en diálogos; marca de tiempo categoría de contacto con el cliente (preguntas sobre seguro obligatorio de responsabilidad civil, seguro de casco, seguro médico voluntario; preguntas sobre el sitio; preguntas sobre programas de lealtad; preguntas sobre cambios en las condiciones del seguro, etc.).
- Un árbol de scripts, o secuencias de preguntas y respuestas de operadores a clientes con diferentes solicitudes.
Sin validación, por supuesto, en ninguna parte. Todos los modelos fueron entrenados en el 70% de los datos y evaluados de acuerdo con los resultados en el 30% restante.
Métricas de calidad para los modelos que utilizamos:
- En entrenamiento: logloss, para diferenciabilidad;
- Al escribir informes: precisión de clasificación en una muestra de prueba, por simplicidad y claridad (incluso para el cliente);
- Al elegir la dirección para futuras acciones: la intuición de un científico de datos que mira fijamente los resultados.
Experimentos modelo
Es raro cuando la tarea deja en claro de inmediato qué modelo dará los mejores resultados. Entonces aquí: sin experimentación, en ninguna parte.
Intentaremos las opciones de vectorización:
- tf-idf en palabras simples;
- tf-idf en triples de caracteres (en adelante: 3 gramos);
- tf-idf en 2, 3, 4, 5 gramos por separado;
- tf-idf en 2-, 3-, 4-, 5 gramos tomados juntos;
- Todo lo anterior + reducción de palabras en el texto fuente a una forma de diccionario;
- Todo lo anterior + disminución de dimensión por el método SVD truncado;
- Con el número de mediciones: 10, 30, 100, 300;
- doc2vec, entrenado en el cuerpo de textos de la tarea.
Las opciones de clasificación en este contexto parecen bastante pobres: SVM, XGBoost, LSTM, bosques aleatorios, bahías ingenuas, bosque aleatorio sobre las predicciones SVM y XGB.
Y aunque verificamos la reproducibilidad de los resultados en tres conjuntos de datos ensamblados independientemente y sus fragmentos, solo podemos garantizar la amplia aplicabilidad.
Los resultados de los experimentos:
- En la cadena "clasificación-dimensión de preprocesamiento-vectorización-reducción", el efecto de la elección en cada paso es casi independiente de los otros pasos. Lo cual es muy conveniente, no puede pasar por una docena de opciones con cada nueva idea y usar la opción más conocida en cada paso.
- tf-idf en palabras pierde 3 gramos (precisión 0,72 frente a 0,78). 2-, 4-, 5 gramos pierden a 3 gramos (0.75–0.76 vs 0.78). Los {2; 5} gramos en conjunto superan bastante los 3 gramos. Dado el fuerte aumento en la memoria requerida, decidimos descuidar el entrenamiento con una ganancia de 0.4% de precisión.
- En comparación con tf-idf de todas las variedades, doc2vec era inútil (precisión 0.4 y menos). Valdría la pena tratar de entrenarlo no en el cuerpo de la tarea (~ 250,000 textos), sino en uno mucho más grande (2.5–25 millones de textos), pero hasta ahora, por desgracia, sus manos no han llegado.
- SVD truncado no ayudó. La precisión aumenta monotónicamente al aumentar la medición, logrando sin problemas la precisión sin TSVD.
- Entre los clasificadores, XGBoost gana por un margen notable (+ 5–10%). Los competidores más cercanos son SVM y bosques aleatorios. Naive Bayes no es un competidor incluso para bosques aleatorios.
- El éxito de LSTM depende en gran medida del tamaño del conjunto de datos: en una muestra de 100,000 objetos, puede competir con XGB. En una muestra de 6000 - en el rezago junto con Bayes.
- Un bosque aleatorio en la parte superior de SVM y XGB siempre está de acuerdo con XGB o se confunde más. Esto es muy triste, esperamos que SVM encuentre en los datos al menos algunos patrones que no están disponibles para XGB, pero lamentablemente.
- XGBoost es complicado con la estabilidad. Por ejemplo, su actualización de la versión 0.72 a 0.80 redujo inexplicablemente la precisión de los modelos entrenados en un 5–10%. Y una cosa más: XGBoost admite el cambio de los parámetros de entrenamiento durante el entrenamiento y la compatibilidad con la API estándar de scikit-learn, pero estrictamente por separado. No pueden hacer las dos cosas juntas. Tuve que arreglarlo.
- Si lleva palabras a una forma de diccionario, esto mejora un poco la calidad, en combinación con tf-idf en palabras, pero es inútil en todos los demás casos. Al final, lo apagamos para ahorrar tiempo.
Experiencia 1. Limpieza de datos, o qué hacer con el marcado
Los operadores de chat son solo personas. Al definir las categorías de consultas de los usuarios, a menudo se equivocan y tienen diferentes interpretaciones de los límites entre las categorías. Por lo tanto, los datos de origen deben limpiarse de manera despiadada e intensiva.
Nuestros datos sobre la capacitación modelo en el primer proyecto:
- Una historia de mensajes de chat en línea durante varios años. Esto es 250,000 publicaciones en 60,000 conversaciones. Al final del diálogo, el operador seleccionó la categoría a la que pertenece la llamada del usuario. Hay alrededor de 50 categorías en este conjunto de datos.
- Árbol de guiones En nuestro caso, los operadores no tenían scripts de trabajo.
Lo que los datos son exactamente malos, los formulamos como hipótesis, luego los verificamos y, cuando es posible, los corregimos. Esto es lo que sucedió:
El primer acercamiento. De toda la enorme lista de clases, puede dejar de forma segura 5-10.
Descartamos clases pequeñas (<1% de la muestra): pocos datos + pequeño impacto. Unimos clases difíciles de distinguir, a las cuales los operadores aún reaccionan de la misma manera. Por ejemplo:
'dms' + 'cómo hacer una cita con un médico' + 'pregunta sobre cómo completar el programa'
'cancelación' + 'estado de cancelación' + 'cancelación de la política pagada'
'pregunta de renovación' + '¿cómo renovar la política?'
Luego, descartamos clases como "otro", "otro" y similares: para un chatbot, son inútiles (de todos modos, redirigiendo a un operador), y al mismo tiempo dañan mucho la precisión, ya que el 20% de las solicitudes (30, 50, 90) están clasificadas inapropiadamente por los operadores. y aqui Ahora descartamos la clase con la que el chatbot no puede trabajar (todavía).
Resultado: en un caso, crecimiento de una precisión de 0.40 a 0.69, en otro, de 0.66 a 0.77.
El segundo enfoque. Al comienzo del chat, los propios operadores no comprenden cómo elegir una clase para que el usuario se ponga en contacto, por lo que hay mucho "ruido" y errores en los datos.
Experimento: solo tomamos los últimos dos (tres, seis, ...) meses de diálogos y capacitamos al modelo en
ellos.
Resultado: en un caso notable, la precisión aumentó de 0,40 a 0,60, en otro, de 0,69 a 0,78.
El tercer enfoque. A veces, una precisión de 0,70 no significa "el modelo está equivocado en el 30% de los casos", sino "en el 30% de los casos el marcado es falso y el modelo lo corrige de manera muy razonable".
Por métricas como precisión o logloss, esta hipótesis no puede ser verificada. Para los fines del experimento, nos limitamos a la mirada de un científico de datos, pero en el caso ideal, debe reorganizar cualitativamente el conjunto de datos, sin olvidar la validación cruzada.
Para trabajar con tales muestras, se nos ocurrió el proceso de "enriquecimiento iterativo":
- Divide el conjunto de datos en 3-4 fragmentos.
- Entrena al modelo en el primer fragmento.
- Predecir las clases de la segunda por el modelo entrenado.
- Observe de cerca las clases predichas y el grado de confianza del modelo, elija el valor límite de confianza.
- Elimine los textos (objetos) predichos con confianza debajo del límite del segundo fragmento, entrene al modelo en esto.
- Repita hasta que los fragmentos se cansen o se agoten.
Por un lado, los resultados son excelentes: el primer modelo de iteración tiene una precisión del 70%, el segundo - 95%, el tercero - 99 +%. Una mirada cercana a los resultados de las predicciones confirma completamente esta precisión.
Por otro lado, ¿cómo se puede verificar sistemáticamente en este proceso que los modelos posteriores no aprenden los errores de los anteriores? Existe la idea de probar el proceso en un conjunto de datos manualmente "ruidoso" con marcado inicial de alta calidad, como MNIST. Pero, por desgracia, no hubo tiempo suficiente para esto. Y sin verificación, no nos atrevimos a lanzar el enriquecimiento iterativo y los modelos resultantes en producción.
El cuarto enfoque. El conjunto de datos se puede ampliar y, por lo tanto, aumentar la precisión y reducir el reciclaje, agregando muchos errores tipográficos a los textos existentes.
Los errores tipográficos son errores tipográficos: duplicar una letra, omitir una letra, reorganizar las letras vecinas en algunos lugares, reemplazar una letra con una letra adyacente en el teclado.
Experimento: la proporción de letras p en las que se producirá un error tipográfico: 2%, 4%, 6%, 8%, 10%, 12%. Aumento del conjunto de datos: generalmente hasta 60,000 réplicas. Dependiendo del tamaño inicial (después de los filtros), esto significó un aumento de 3 a 30 veces.
Resultado: depende del conjunto de datos. En un conjunto de datos pequeño (~ 300 réplicas), 4–6% de los errores tipográficos dan un aumento estable y significativo en la precisión (0,40 → 0,60). En grandes conjuntos de datos, todo es peor. Con una proporción de errores tipográficos de 8% o más, los textos se vuelven sin sentido y la precisión disminuye. Con una tasa de error del 2 al 8%, la precisión fluctúa en el rango de un pequeño porcentaje, muy rara vez excede la precisión sin errores tipográficos y, según las sensaciones, no hay necesidad de aumentar el tiempo de entrenamiento varias veces.
Como resultado, obtenemos un modelo que distingue 5 clases de llamadas con una precisión de 0,86. Coordinamos con el cliente los textos de preguntas y respuestas para cada uno de los cinco tenedores, sujetamos los textos al chatbot y los enviamos a QA.
Experiencia 2. Hasta la rodilla en los datos, o qué hacer sin marcado
Habiendo obtenido buenos resultados en el primer proyecto, nos acercamos al segundo con toda confianza. Pero, afortunadamente, no olvidamos cómo sorprendernos.
Lo que nos encontramos con:
- Un árbol de script de cinco ramas acordado con el cliente hace aproximadamente un año.
- Una muestra etiquetada de 500 mensajes y 11 clases de origen desconocido.
- Etiquetado por operadores de chat de 220,000 mensajes, 21,000 conversaciones y otras 50 clases.
- El modelo SVM, entrenado en la primera muestra, con una precisión de 0,69, que fue heredado del equipo anterior de científicos de datos. Por qué SVM, la historia es silenciosa.
En primer lugar, observamos las clases: en el árbol de scripts, en la muestra del modelo SVM, en la muestra principal. Y aquí está lo que vemos:
- Las clases del modelo SVM corresponden aproximadamente a las ramas de los scripts, pero de ninguna manera corresponden a las clases de una muestra grande.
- El árbol de secuencias de comandos se escribió en los procesos comerciales hace un año y está desactualizado, casi inútil. El modelo SVM está en desuso con él.
- Las dos clases más grandes en la muestra grande son Ventas (50%) y Otros (45%).
- De las cinco siguientes clases más grandes, tres son tan generales como Ventas.
- Las 45 clases restantes contienen menos de 30 cuadros de diálogo cada una. Es decir no tenemos un árbol de scripts, no hay una lista de clases ni marcas.
¿Qué hacer en tales casos? Nos arremangamos y fuimos por nuestra cuenta para obtener clases y marcas de los datos.
El primer intento. Intentemos agrupar las preguntas de los usuarios, es decir Los primeros mensajes en el diálogo, excepto los saludos.
Lo comprobamos Vectorizamos réplicas contando 3 gramos. Bajamos la dimensión a las primeras diez mediciones de TSVD. Agrupamos por agrupamiento aglomerativo con la distancia euclidiana y la función Ward objetivo. Baje la dimensión nuevamente usando t-SNE (hasta dos mediciones para que pueda ver los resultados con los ojos). Dibujamos puntos de réplica en el plano, pintando con los colores de los grupos.
Resultado: miedo y horror. Clusters sanos, podemos suponer que no hay:
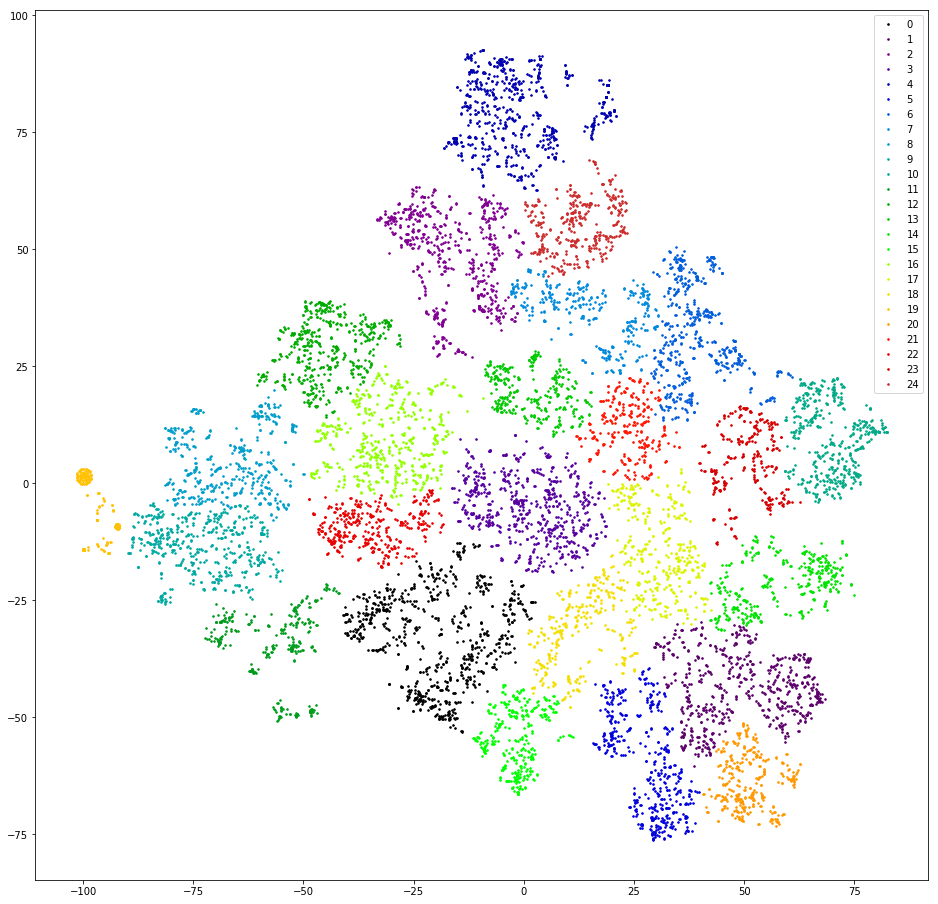
Casi no, hay uno, naranja a la izquierda, esto se debe a que todos los mensajes contienen el "@" de 3 gramos. Este 3 gramos es un artefacto de preprocesamiento. En algún lugar del proceso de filtrado de signos de puntuación, "@" no solo no se filtró, sino que también se cubrió de espacios. Pero el artefacto es útil. Este clúster incluye usuarios que primero escriben su correo electrónico. Desafortunadamente, solo por la disponibilidad de correo no está completamente claro cuál es la solicitud del usuario. Seguimos adelante.
El segundo intento. ¿Qué sucede si los operadores a menudo responden con enlaces más o menos estándar?
Lo comprobamos Extraemos subcadenas similares a enlaces de los mensajes del operador, editamos ligeramente los enlaces, de diferente ortografía, pero con el mismo significado (http / https, / search? City =% city%), consideramos las frecuencias de los enlaces.
Resultado: poco prometedor. Primero, los operadores responden solo a una pequeña fracción de las solicitudes (<10%) con enlaces. En segundo lugar, incluso después de la limpieza manual y el filtrado de enlaces que ocurrieron una vez, hay más de treinta de ellos. En tercer lugar, en el comportamiento de los usuarios que finalizan el diálogo con un enlace, no existe una similitud particular.
El tercer intento. Busquemos las respuestas estándar de los operadores: ¿qué pasaría si fueran indicadores de cualquier clasificación de mensajes?
Lo comprobamos En cada diálogo tomamos la última réplica del operador (aparte de las despedidas: "Puedo ayudar a otra cosa", etc.) y consideramos la frecuencia de las réplicas únicas.
Resultado: prometedor, pero inconveniente. El 50% de las respuestas del operador son únicas, otro 10-20% se encuentra dos veces, el 30-40% restante está cubierto por un número relativamente pequeño de plantillas populares. Relativamente pequeño, alrededor de trescientos. Una mirada cercana a estas plantillas muestra que muchas de ellas son variantes de la misma respuesta en términos de significado: difieren en una letra, en una palabra, en un párrafo. Me gustaría agrupar estas respuestas que tienen un significado cercano.
El cuarto intento. Agrupación de las últimas réplicas de declaraciones. Estos se agrupan mucho mejor:
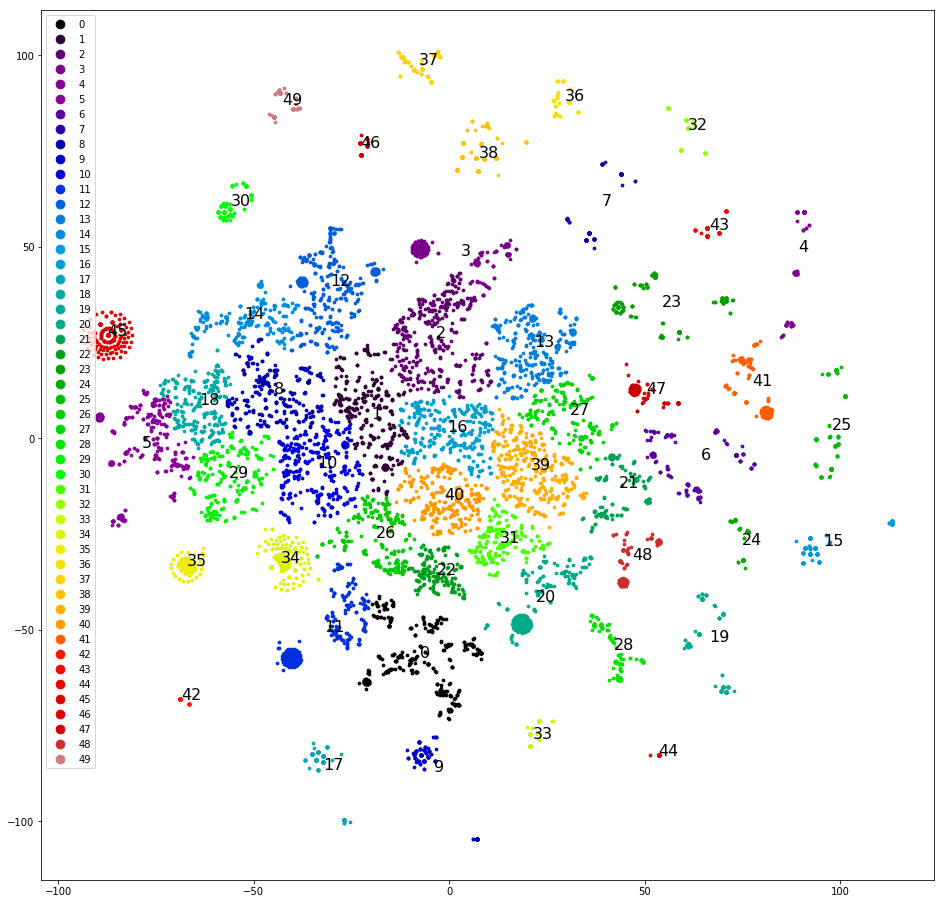
Ya puedes trabajar con esto.
Agrupamos y dibujamos réplicas en el plano, como en el primer intento, determinamos manualmente los grupos más claramente separados, los eliminamos del conjunto de datos y agrupamos nuevamente. Después de separar aproximadamente la mitad del conjunto de datos, los clústeres claros terminan y comenzamos a pensar qué clases asignarles. Dispersamos los grupos de acuerdo con las cinco clases originales: la muestra está "sesgada" y tres de las cinco clases originales no reciben un solo grupo. Que mal. Dispersamos los grupos en cinco clases, que designamos al azar, en: "llamar", "venir", "esperar un día para obtener una respuesta", "problemas con captcha", "otros". La inclinación es menor, pero la precisión es solo 0.4-0.5. Mal otra vez. Asigne a cada uno de los más de 30 grupos su propia clase. La muestra vuelve a estar sesgada y la precisión vuelve a ser 0,5, aunque alrededor de cinco clases seleccionadas tienen una precisión e integridad decentes (0,8 y superior). Pero el resultado aún no es impresionante.
El quinto intento. Necesitamos todos los entresijos de la agrupación. Recuperamos el dendrograma de agrupamiento completo en lugar de los treinta grupos principales. Lo guardamos en un formato accesible para los analistas de los clientes y les ayudamos a realizar el marcado: bosquejamos la lista de clases.
Para cada mensaje, calculamos una cadena de clústeres, que incluye cada mensaje, comenzando desde la raíz. Construimos una tabla con columnas: texto, id del primer grupo en la cadena, id del segundo grupo en la cadena, ..., id del grupo correspondiente al texto. Guardamos la tabla en csv / xls. Además, puede trabajar con herramientas de oficina.
Damos los datos y un boceto de la lista de clases para el marcado al cliente. Los analistas de clientes volvieron a marcar ~ 10,000 mensajes de primer usuario. Nosotros, ya enseñados por experiencia, pedimos marcar cada mensaje al menos dos veces. Y no en vano: 4.000 de estos 10.000 deben desecharse, porque los dos analistas marcaron de manera diferente. En los 6,000 restantes, repetimos rápidamente los éxitos del primer proyecto:
- Línea de base: sin filtrado en absoluto - precisión 0.66.
- Combine clases que sean iguales desde el punto de vista del operador. Obtenemos una precisión de 0,73.
- Eliminamos la clase "Otro": la precisión aumenta a 0,79.
El modelo está listo, ahora necesita dibujar un árbol de script. Por razones que no podemos explicar, no tuvimos acceso a los scripts para las respuestas del operador. No nos sorprendimos, fingimos ser usuarios y durante un par de horas en el campo recolectamos plantillas de respuestas y aclaramos las preguntas del operador para todas las ocasiones. Los decoraron en un árbol, los empacaron en un bot y fueron a probar. Cliente aprobado
Conclusiones, o lo que la experiencia ha demostrado:
- Puede experimentar con partes del modelo (preprocesamiento, vectorización, clasificación, etc.) individualmente.
- XGBoost todavía gobierna la pelota, aunque si necesita algo inusual, tiene problemas.
- El usuario es un dispositivo periférico para entrada caótica, por lo que debe limpiar los datos del usuario.
- El enriquecimiento iterativo es genial, aunque peligroso.
- A veces vale la pena devolver los datos al cliente para el marcado. Pero no olvide ayudarlo a obtener un resultado de calidad.
Para concluir