Uno de los pinceles elimina / agrega árboles, el otro - de personas, etc.Las redes de contención generativa (GAN) crean imágenes increíblemente realistas, a menudo indistinguibles de las reales. Desde la invención de tales redes en 2014, se han realizado muchas investigaciones en esta área y se han creado una serie de aplicaciones, incluso para la
manipulación de imágenes y
la predicción de videos . Se han desarrollado varias variantes de GAN y se están realizando experimentos.
A pesar de este tremendo éxito, quedan muchas preguntas. No está claro cuáles son exactamente las razones de los artefactos terriblemente poco realistas, qué conocimiento mínimo se necesita para generar objetos específicos, ¿por qué una variante GAN funciona mejor que otra, qué diferencias fundamentales están codificadas en sus escalas? Para comprender mejor el funcionamiento interno de GAN, los investigadores del Instituto de Tecnología de Massachusetts, MIT-IBM Watson AI e IBM Research han desarrollado el marco GANDissection y el programa
GANpaint , un editor gráfico en una red de confrontación generativa.
El trabajo va acompañado de un
artículo científico que explica en detalle la funcionalidad del marco y discute las preguntas a las que los investigadores están tratando de encontrar respuestas. En particular, están tratando de estudiar las
representaciones internas de las redes generativas-competitivas. La "estructura analítica para visualizar y comprender la GAN a nivel de unidades, objetos y escenas", es decir, el marco de GANDissection, debería ayudar.
Mediante el método de dividir una imagen en partes (disección de red basada en segmentación), el sistema determina grupos de "unidades interpretadas" que están estrechamente relacionadas con los conceptos de objetos. Luego se realiza una evaluación cuantitativa de las causas que causan cambios en las unidades interpretadas. Esto se hace "midiendo la capacidad de las intervenciones para controlar objetos en la salida". En pocas palabras, los investigadores estudian la relación contextual entre objetos específicos y su entorno mediante la introducción de objetos detectados en nuevas imágenes.
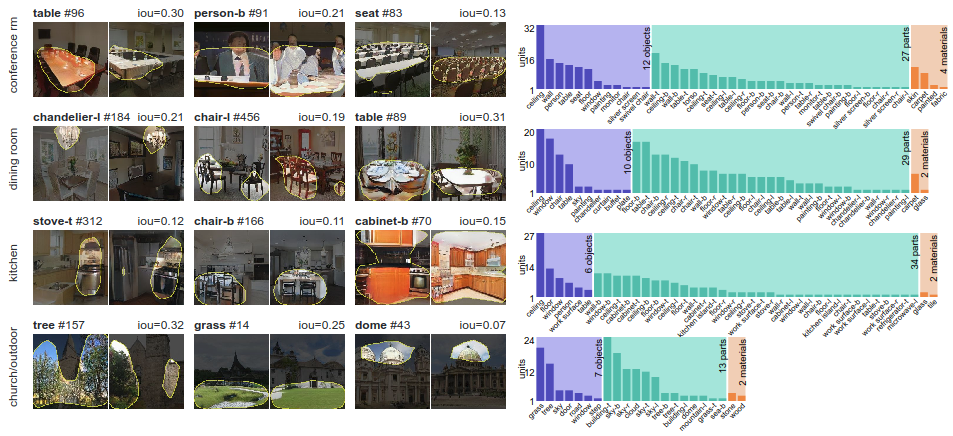 El marco de disección de GAN demuestra que las neuronas específicas en la GAN se entrenan según el tipo de escena que está aprendiendo a dibujar: por ejemplo, aparece una neurona chaqueta cuando se estudian salas de conferencias y una neurona de placa cuando se dibujan cocinas
El marco de disección de GAN demuestra que las neuronas específicas en la GAN se entrenan según el tipo de escena que está aprendiendo a dibujar: por ejemplo, aparece una neurona chaqueta cuando se estudian salas de conferencias y una neurona de placa cuando se dibujan cocinasPara asegurarse de que los conjuntos de neuronas controlen el dibujo de objetos, y no solo se correlacionen, el marco interviene en la red y activa y desactiva las neuronas directamente. Así es como funciona el editor gráfico GANpaint: esta es una demostración visual del marco analítico.
GANpaint activa y desactiva neuronas en una red entrenada para crear imágenes. Cada botón en el panel izquierdo corresponde a un conjunto de 20 neuronas. Solo siete botones:
- un arbol
- hierba
- la puerta
- el cielo
- una nube
- ladrillo
- la cúpula
GANpaint puede agregar o eliminar tales objetos.
Al cambiar las neuronas directamente, puede observar la estructura del mundo visual que la red neuronal ha aprendido a modelar.
Al estudiar los resultados del trabajo de otras redes generativas competitivas, un extraño puede hacer una pregunta: ¿la GAN realmente crea una nueva imagen o simplemente inventa una escena a partir de objetos que encontró durante el entrenamiento? ¿Quizás la red solo recuerda las imágenes y luego las reproduce de la misma manera? Este trabajo de investigación y el editor de GANpaint muestran que las redes realmente han aprendido algunos aspectos de la composición, dicen los autores.
Un descubrimiento interesante es que las mismas neuronas controlan una cierta clase de objetos en diferentes contextos, incluso si la apariencia final del objeto varía mucho. Las mismas neuronas pueden cambiar al concepto de "puerta" independientemente de si necesita agregar una puerta pesada en un muro de piedra grande o una puerta pequeña en una cabaña pequeña. La GAN también comprende cuándo y cuándo no se pueden crear objetos. Por ejemplo, cuando se activan las neuronas de la puerta, la puerta realmente aparece en el lugar correcto del edificio. Pero si haces lo mismo en el cielo o en un árbol, generalmente ese intento no tiene ningún efecto.
El artículo científico
"Disección de GAN: visualización y comprensión de redes adversas generativas" se publicó el 26 de noviembre de 2018 en el sitio de preimpresión arXiv.org (arXiv: 1811.10597v2).
Demos interactivos, videos, códigos y datos se publican
en Github y en
el sitio web del MIT .