La mayoría de los sistemas de almacenamiento disponibles en el mercado no son muy diferentes entre sí, ya que muchos proveedores solicitan equipos de casi los mismos fabricantes de ODM. Tenemos casi todo lo nuestro, desde el chasis hasta los controladores, tecnologías como RAID 2.0+ y software.

Debajo del corte, hay algunos detalles sobre lo que podría ser tan inusual en cada uno de los nodos del sistema de almacenamiento de datos.
¿Qué es interesante a nivel de módulo?
Estructuralmente, todos los sistemas de almacenamiento modernos de cualquier fabricante tienen el mismo aspecto: los controladores se instalan en la parte frontal del chasis de la caja de acero y los módulos de interfaz en la parte posterior. También hay fuentes de alimentación y ventilación. Parece que todo es familiar y estándar. Pero, de hecho, hemos introducido muchas cosas interesantes en este paradigma.
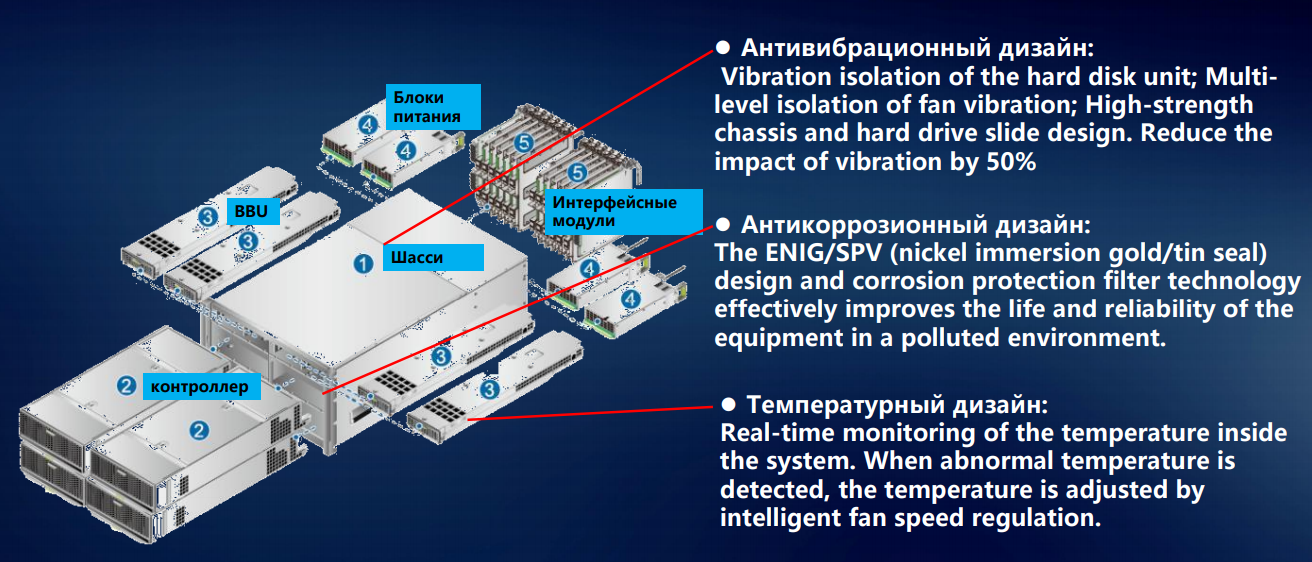
Comencemos por montar los elementos del sistema de almacenamiento en el chasis. Hay menos unidades magnéticas de 3,5 pulgadas en el sistema de almacenamiento; los sistemas híbridos y todo flash están comenzando a dominar. Pero incluso varias unidades de disco con una velocidad de huso de hasta 15 mil revoluciones por minuto crean una vibración que no se puede ignorar. Hemos desarrollado un conjunto completo de recomendaciones para este caso: cómo distribuir unidades magnéticas con varios parámetros entre los estantes de discos.
Incluso a una fracción de un porcentaje, pero afecta la fiabilidad. Y a la escala de un gran centro de datos, los porcentajes por unidad se convierten en indicadores tangibles de fallas y mal funcionamiento. Para garantizar que la vibración de los discos individuales se transmita menos a través de la estructura rígida del chasis, equipamos los discos debajo de los discos con amortiguadores de goma o metal. Para neutralizar otra fuente de vibración en el sistema de almacenamiento, los módulos de ventilación, colocamos ventiladores bidireccionales y aislamos todos los elementos giratorios del chasis.
Para las unidades de husillo, la sacudida mínima ya es un problema: los cabezales comienzan a extraviarse, el rendimiento disminuye significativamente. Los SSD son otro asunto; no tienen miedo a las vibraciones. Pero la fijación segura de los componentes sigue siendo importante. Tome el proceso de entrega: la caja se puede soltar o arrojar casualmente, poner de lado o boca abajo. Por lo tanto, tenemos todos los componentes del sistema de almacenamiento que se fijan estrictamente en tres dimensiones. Esto elimina la posibilidad de su desplazamiento durante el transporte, protege los conectores para que no se salgan de los enchufes en caso de impacto accidental.

Érase una vez, comenzamos con el desarrollo de tecnología informática para la industria de las telecomunicaciones, donde los estándares de operatividad en temperatura y humedad son tradicionalmente altos. Y los trasladamos a otras direcciones: las partes metálicas de los sistemas de almacenamiento no se oxidan incluso con alta humedad, debido al uso de niquelado y galvanizado.
El diseño térmico de nuestros sistemas de almacenamiento se desarrolló con énfasis en la distribución uniforme de la temperatura a través del chasis, para evitar el sobrecalentamiento o el enfriamiento excesivo de cualquier esquina del estante del disco. De lo contrario, no se puede evitar la deformación física, incluso si es insignificante, pero aún así viola la geometría y es capaz de acortar la vida útil del equipo. Por lo tanto, se ganan algunas fracciones de porcentaje, pero esto aún afecta la confiabilidad general del sistema.
Sutilezas de semiconductores
Duplicamos componentes importantes de los sistemas de almacenamiento: si algo falla, siempre hay una red de seguridad. Por ejemplo, los módulos de potencia para modelos más jóvenes funcionan de acuerdo con el esquema 1 + 1, para los más sólidos: 2 + 1 e incluso 3 + 1.

Los controladores, de los cuales hay al menos dos en el sistema de almacenamiento (no suministramos sistemas de controlador único) también están reservados. En el sistema de almacenamiento de la serie 6800 y anteriores, la redundancia se realiza de acuerdo con el esquema 3 + 1, en los modelos más jóvenes: 1 + 1.
Incluso una placa de administración está reservada, lo que no afecta directamente el funcionamiento del sistema, pero solo es necesario para cambios de configuración y monitoreo. Además, cualquier tarjeta de expansión de interfaz para sistemas de almacenamiento se vende solo en pares, para que el cliente tenga una reserva.
Todos los componentes: PSU, ventiladores, controladores, módulos de gestión, etc. - Equipado con microcontroladores capaces de responder a ciertas situaciones. Por ejemplo, si el ventilador comienza a disminuir la velocidad por sí mismo, se envía una alarma al módulo de control. Como resultado, el cliente tiene una imagen completa del estado del sistema de almacenamiento y, si es necesario, puede reemplazar algunos componentes por su cuenta, sin esperar la llegada de nuestro ingeniero de servicio. Y si la política de seguridad del cliente lo permite, configuramos los controladores para que transmitan información sobre el estado de la plancha a nuestro soporte técnico.
Sus chips son mejores y más comprensibles.
Somos la única compañía que desarrolla sus propios procesadores, chips y controladores de unidades de estado sólido para sus sistemas de almacenamiento.

Entonces, en algunos modelos, como el procesador principal del sistema de almacenamiento (Storage Controller Chip), no utilizamos el clásico Intel x86, sino el procesador ARM HiSilicon, nuestra subsidiaria. El hecho es que la arquitectura ARM en el almacenamiento, para calcular el mismo RAID y deduplicación, se muestra mejor que el estándar x86.
Nuestro orgullo especial son los chips para controladores SSD. Y si nuestros servidores pueden estar equipados con unidades de semiconductores de terceros (Intel, Samsung, Toshiba, etc.), en los sistemas de almacenamiento de datos instalamos solo SSD de nuestro propio diseño.

El microcontrolador del módulo de entrada-salida (chip de E / S inteligente) en los sistemas de almacenamiento también es un desarrollo de HiSilicon, así como el chip de gestión inteligente para la gestión de almacenamiento remoto. El uso de nuestros propios microchips nos ayuda a comprender mejor lo que sucede en cada momento en el tiempo con cada celda de memoria. Esto es lo que nos permitió minimizar los retrasos al acceder a los datos en los mismos sistemas de almacenamiento de Dorado.

Para los discos magnéticos, el monitoreo continuo es extremadamente importante en términos de confiabilidad. Nuestros sistemas de almacenamiento admiten DHA (Disk Health Analyzer): el disco en sí registra continuamente lo que le está sucediendo, lo bien que se siente. Gracias a la acumulación de estadísticas y la construcción de modelos predictivos inteligentes, es posible predecir la transición de la unidad a un estado crítico en 2-3 meses, y no en 5-10 días. El disco todavía está "vivo", los datos en él están completamente seguros, pero el cliente está listo para reemplazarlo a la primera señal de una posible falla.
RAID 2.0+
Diseño a prueba de fallas en sistemas de almacenamiento que hemos pensado a nivel de sistema. Nuestra tecnología Smart Matrix es un complemento sobre PCIe: este bus, en base al cual se implementan las conexiones entre controladores, es especialmente adecuado para SSD.
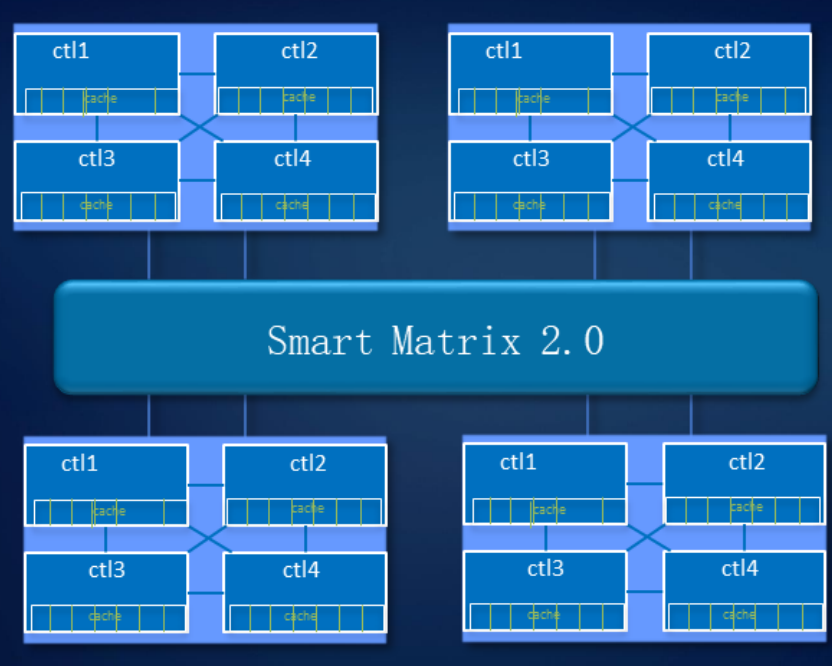
Smart Matrix proporciona, en particular, la malla completa de 4 controladores en nuestro almacenamiento Ocean Store 6800 v5. Para que cada controlador tenga acceso a todos los discos del sistema, desarrollamos un servidor SAS especial. El caché, por supuesto, se refleja entre todos los controladores actualmente activos.

Cuando el controlador falla, los servicios de él cambian rápidamente al controlador espejo, y los controladores restantes restauran la relación para reflejarse entre sí. Al mismo tiempo, los datos registrados en la memoria caché tienen una reserva espejo para garantizar la confiabilidad del sistema.

El sistema soporta la falla de tres controladores. Como se muestra en la figura, si el control A falla, los datos del caché del controlador B seleccionarán el controlador C o D para reflejar el caché. Cuando el controlador D falla, los controladores B y C reflejan el caché.

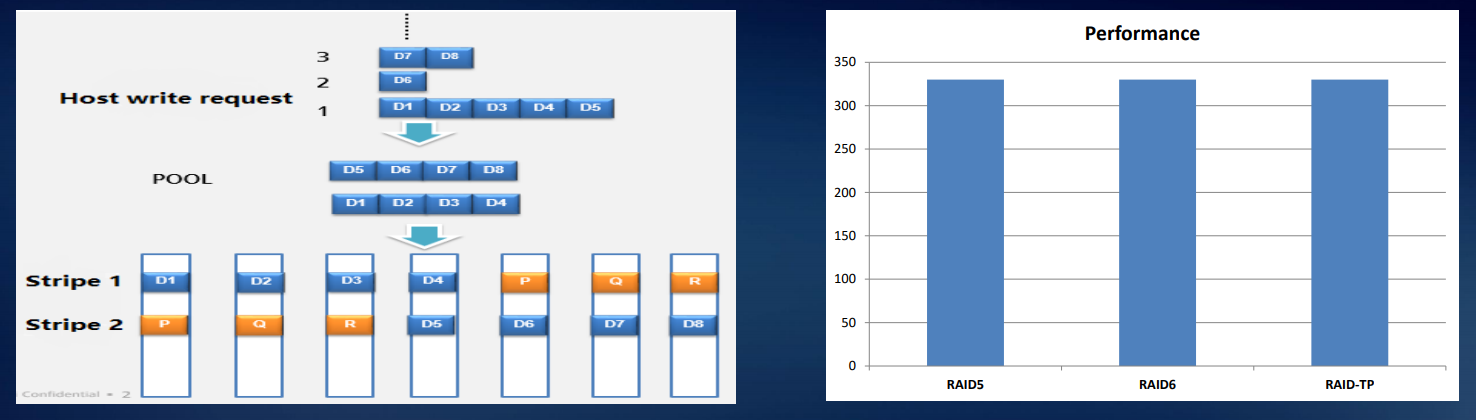
El sistema de distribución de datos RAID 2.0 es el estándar para nuestros sistemas de almacenamiento: la virtualización a nivel de disco ha reemplazado durante mucho tiempo la copia ingeniosa bloque por bloque de contenido de un medio a otro. Todos los discos se agrupan en bloques, se combinan en conglomerados más grandes de una estructura de dos niveles, y ya en la parte superior de su nivel superior están los volúmenes lógicos que componen los conjuntos RAID.

La principal ventaja de este enfoque es el tiempo de reconstrucción reducido de la matriz. Además, en el caso de una falla del disco, la reconstrucción no se realiza en el disco de repuesto dinámico que ha estado en reposo todo este tiempo, sino en el espacio libre en todos los discos usados. La siguiente figura muestra nueve discos duros RAID5 como ejemplo. Cuando el disco duro 1 falla, los datos CKG0 y CKG1 están dañados. El sistema selecciona CK para la reconstrucción al azar.

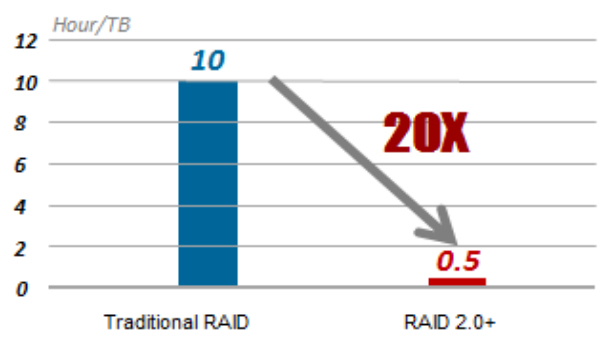
La velocidad normal de recuperación de RAID es de 30 MB / s, por lo que lleva 10 horas recuperar 1 TB de datos. RAID 2.0+ reduce este tiempo a 30 minutos.
Nuestros desarrolladores lograron lograr una distribución de carga uniforme entre todas las unidades de husillo y SSD en el sistema. Esto le permite desbloquear el potencial de los sistemas de almacenamiento híbrido mucho mejor que el uso habitual de unidades de estado sólido como caché.

En sistemas de la clase Dorado, implementamos el llamado RAID-TP, una matriz con triple paridad. Dicho sistema continuará funcionando mientras fallan las tres unidades. Esto aumenta la confiabilidad en comparación con RAID 6 en dos órdenes decimales, con RAID 5 en tres.
Recomendamos RAID-TP para datos especialmente críticos, más aún debido a RAID 2.0 y unidades flash de alta velocidad, esto no tiene un impacto significativo en el rendimiento. Solo necesita más espacio libre para reservar.

Como regla general, los sistemas all-flash se usan para DBMS con bloques de datos pequeños y IOPS altos. Esto último no es muy bueno para los SSD: las celdas de memoria NAND se agotan rápidamente. En nuestra implementación, el sistema primero recopila un bloque de datos relativamente grande en la memoria caché de la unidad y luego lo escribe por completo en las celdas. Esto le permite reducir la carga en los discos, así como en un modo más moderado, "recolección de basura" y liberar espacio en el SSD.
Seis nueves
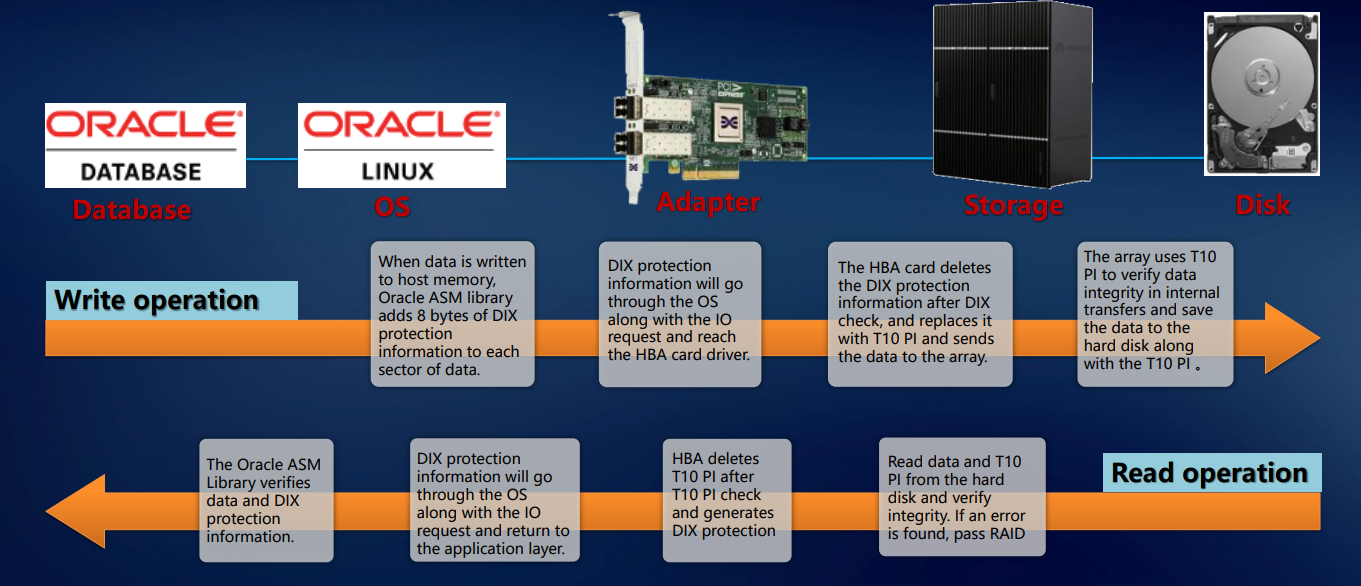
Lo anterior nos permite hablar sobre la tolerancia a fallas de nuestros sistemas a nivel de toda la solución. La validación se implementa a nivel de aplicación (por ejemplo, Oracle DBMS), sistema operativo, adaptador, almacenamiento, etc., hasta el disco. Este enfoque garantiza que exactamente el bloque de datos que llegó a los puertos externos se escribirá en los discos internos del sistema sin ningún daño o pérdida. Esto implica un nivel empresarial.
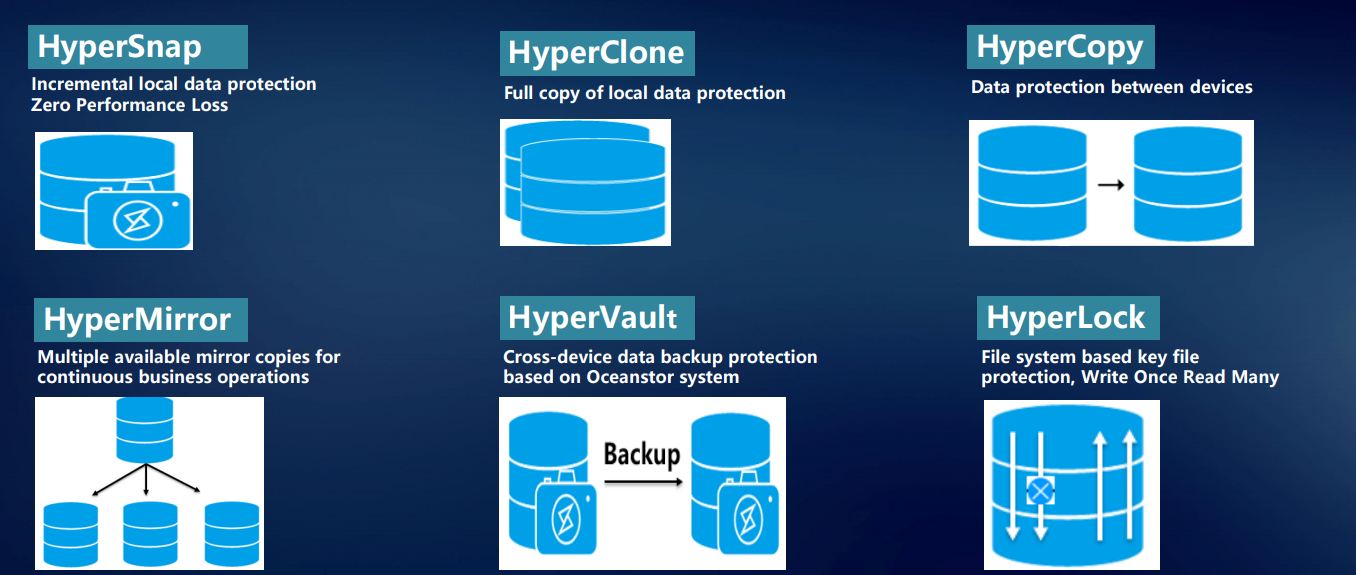
Para el almacenamiento, la protección y la recuperación de datos confiables, así como el acceso rápido a ellos, hemos desarrollado una serie de tecnologías patentadas.

HyperMetro es probablemente el desarrollo más interesante del último año y medio. Se está implementando una solución llave en mano basada en nuestros sistemas de almacenamiento para construir un clúster metropolitano a prueba de fallas a nivel del controlador; no requiere puertas de enlace o servidores adicionales, excepto el árbitro. Se implementa simplemente por una licencia: dos sistemas de almacenamiento de Huawei más una licencia, y funciona.

La tecnología HyperSnap proporciona protección continua de datos sin pérdida de rendimiento. El sistema es compatible con RoW. Para evitar la pérdida de datos en el almacenamiento en cualquier momento, se utilizan muchas tecnologías: varias instantáneas, clones, copias.
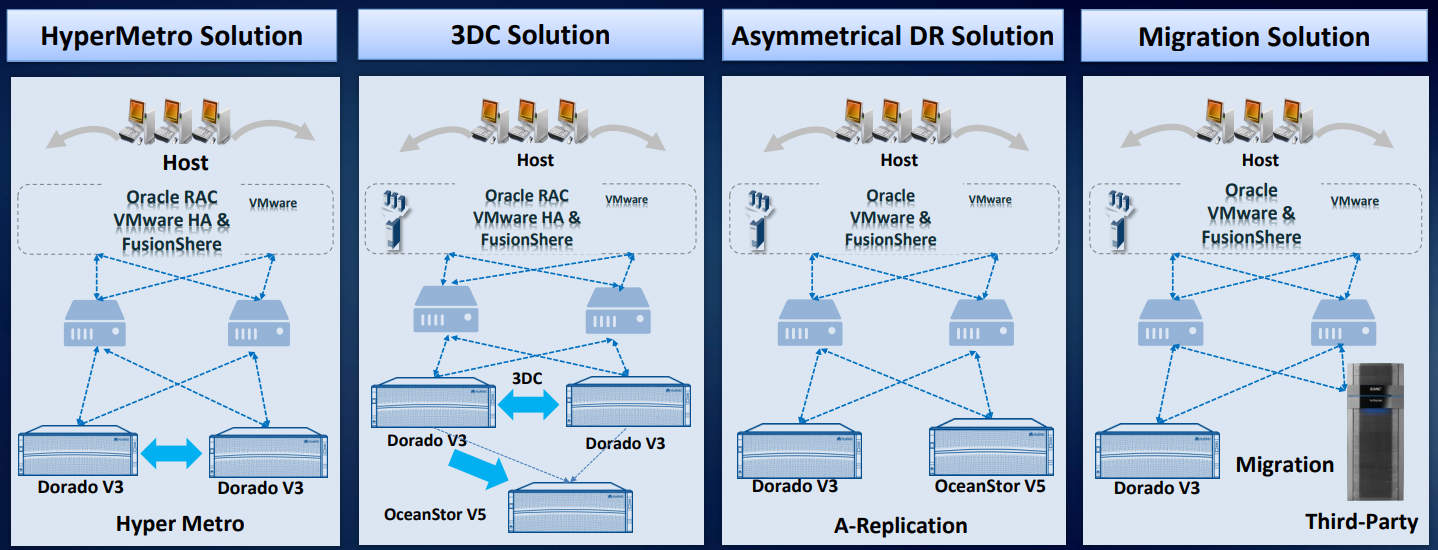
En base a nuestros sistemas de almacenamiento, en la práctica se han desarrollado y probado al menos cuatro soluciones de recuperación ante desastres.
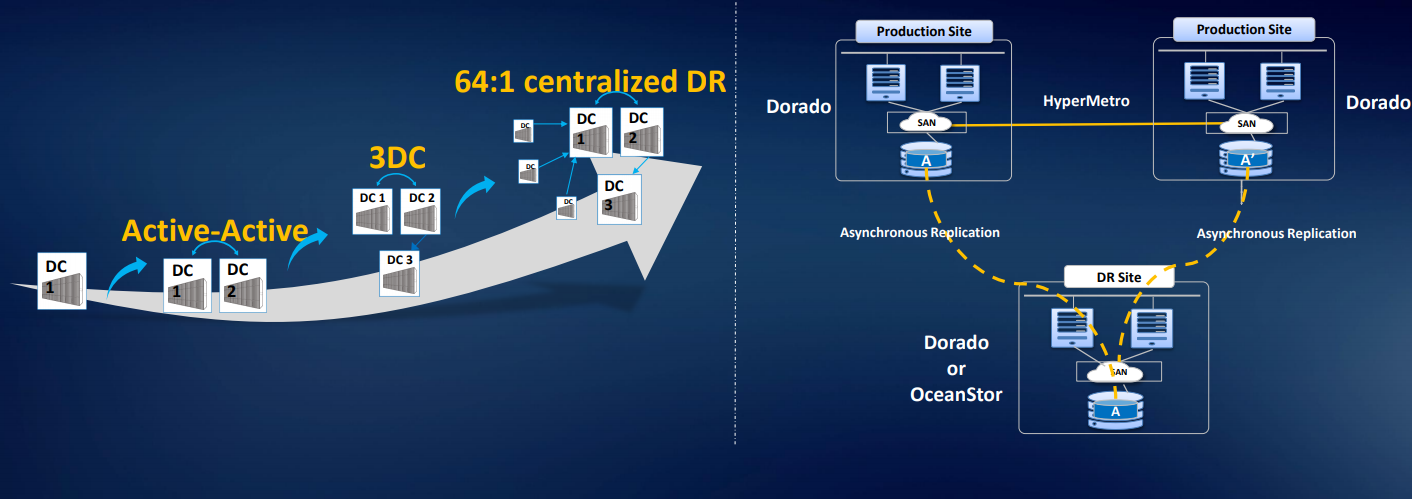
También tenemos una solución para tres centros de datos de 3DC Ring DR Solution: dos centros de datos en el clúster y el tercero se está replicando. Podemos organizar la replicación asíncrona o la migración desde matrices de terceros. Existe una licencia de virtualización inteligente, por lo que puede usar volúmenes de la mayoría de las matrices estándar con acceso FC: Hitachi, DELL EMC, HPE, etc. La solución está realmente resuelta, hay análogos en el mercado, pero cuestan más. Hay ejemplos de uso en Rusia.
Como resultado, a nivel de toda la solución, puede obtener la confiabilidad de seis nueves, y al nivel del almacenamiento local: cinco nueves. En general, lo intentamos.
Publicado por Vladimir Svinarenko, Gerente Senior de Soluciones de TI, Huawei Enterprise en Rusia