
El tema del artículo tiene un enfoque bastante limitado, pero puede ser útil para aquellos que están desarrollando sus propios almacenes de datos y pensando en la integración con Spring Framework.
Antecedentes
A los desarrolladores generalmente no les gusta cambiar sus hábitos (a menudo, los marcos también se incluyen en la lista de hábitos). Cuando comencé a trabajar con CUBA , no tuve que aprender muchas cosas nuevas, era posible participar activamente en el trabajo del proyecto casi de inmediato. Pero había una cosa en la que tenía que quedarme más tiempo: trabajar con datos.
Spring tiene varias bibliotecas que se pueden usar para trabajar con la base de datos, una de las más populares es spring-data-jpa , que en la mayoría de los casos le permite no escribir SQL o JPQL. Solo necesita crear una interfaz especial con métodos que se nombren de una manera especial y Spring generará y hará el resto del trabajo por usted para obtener datos de la base de datos y crear instancias de objetos de entidad.
A continuación se muestra la interfaz, con un método para contar clientes con un apellido dado.
interface CustomerRepository extends CrudRepository<Customer, Long> { long countByLastName(String lastName); }
Esta interfaz se puede usar directamente en los servicios de Spring sin crear ninguna implementación, lo que acelera enormemente el trabajo.
CUBA tiene una API para trabajar con datos, que incluye varias funciones como entidades parcialmente cargadas o un sistema de seguridad complicado con control de acceso a atributos de entidad y filas en tablas de bases de datos. Pero esta API es ligeramente diferente de lo que los desarrolladores están acostumbrados en Spring Data o JPA / Hibernate.
¿Por qué no hay repositorios JPA en CUBA y puedo agregarlos?
Trabajando con datos en CUBA
En CUBA, hay tres clases principales responsables de trabajar con datos: DataStore, EntityManager y DataManager.
DataStore es una abstracción de alto nivel para cualquier almacenamiento de datos: base de datos, sistema de archivos o almacenamiento en la nube. Esta API le permite realizar operaciones básicas en datos. En la mayoría de los casos, los desarrolladores no necesitan trabajar con el DataStore directamente, excepto cuando desarrollan su propio repositorio, o si se requiere un acceso muy especial a los datos en el repositorio.
EntityManager es una copia del conocido JPA EntityManager. A diferencia de la implementación estándar, tiene métodos especiales para trabajar con representaciones de CUBA , para la eliminación "suave" (lógica) de datos y también para trabajar con consultas en CUBA . Como en el caso del DataStore, en el 90% de los proyectos, un desarrollador ordinario no tendrá que tratar con EntityManager, excepto cuando sea necesario cumplir algunas solicitudes sin pasar por el sistema de restricción de acceso a datos.
DataManager es la clase principal para trabajar con datos en CUBA. Proporciona una API para la manipulación de datos y admite el control de acceso a datos, incluido el acceso a atributos y restricciones a nivel de fila. El DataManager modifica implícitamente todas las consultas que se ejecutan en CUBA. Por ejemplo, puede excluir los campos de la tabla a los que el usuario actual no tiene acceso desde la instrucción select y agregar las condiciones para excluir las filas de la tabla de la selección. Y esto facilita la vida de los desarrolladores, ya que no tiene que pensar en cómo escribir consultas correctamente teniendo en cuenta los derechos de acceso, CUBA lo hace automáticamente en función de los datos de las tablas de servicio de la base de datos.
A continuación se muestra un diagrama de la interacción de los componentes de CUBA que participan en la obtención de datos a través del DataManager.
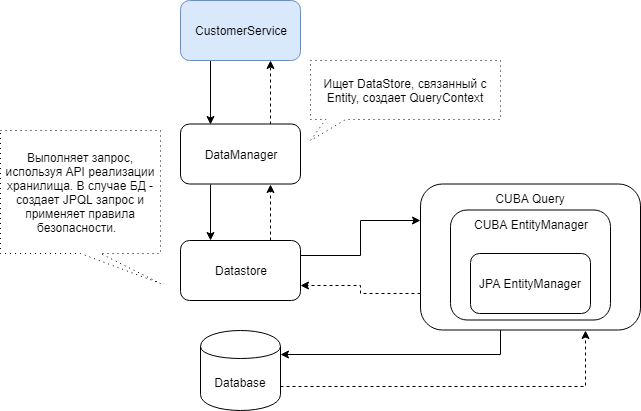
Usando el DataManager, puede cargar con relativa facilidad entidades y jerarquías enteras de entidades usando vistas CUBA. En su forma más simple, la consulta se ve así:
dataManager.load(Customer.class).list();
Como ya se mencionó, DataManager filtrará los registros "eliminados lógicamente", eliminará los atributos prohibidos de la solicitud y también abrirá y cerrará la transacción automáticamente.
Pero, cuando se trata de consultas más complicadas, debe escribir JPQL en CUBA.
Por ejemplo, si necesita contar a los clientes con un apellido dado, como en el ejemplo de la sección anterior, debe escribir algo como este código:
public Long countByLastName(String lastName) { return dataManager .loadValue("select count(c) from sample$Customer c where c.lastName = :lastName", Long.class) .parameter("lastName", lastName) .one(); }
o tal:
public Long countByLastName(String lastName) { LoadContext<Customer> loadContext = LoadContext.create(Customer.class); loadContext .setQueryString("select c from sample$Customer c where c.lastName = :lastName") .setParameter("lastName", lastName); return dataManager.getCount(loadContext); }
En la API CUBA, debe pasar una expresión JPQL como una cadena (la API Criteria aún no es compatible), esta es una forma legible y comprensible de crear consultas, pero la depuración de esas consultas puede traer muchos minutos divertidos. Además, las cadenas JPQL no son verificadas por el compilador ni por Spring Framework durante la inicialización del contenedor, lo que conduce a errores solo en Runtime.
Compare esto con Spring JPA:
interface CustomerRepository extends CrudRepository<Customer, Long> { long countByLastName(String lastName); }
El código es tres veces más corto y no tiene líneas. Además, el nombre del método countByLastName verifica durante la inicialización del contenedor Spring. Si hay un error tipográfico y escribió countByLastNsme , la aplicación se bloqueará con un error durante la implementación:
Caused by: org.springframework.data.mapping.PropertyReferenceException: No property LastNsme found for type Customer!
CUBA se basa en Spring Framework, por lo que puede conectar la biblioteca spring-data-jpa en una aplicación escrita con CUBA, pero hay un pequeño problema: el control de acceso. La implementación de Spring CrudRepository utiliza su EntityManager. Por lo tanto, todas las consultas se realizarán sin pasar por el DataManager. Por lo tanto, para usar repositorios JPA en CUBA, debe reemplazar todas las llamadas de EntityManager con llamadas de DataManager y agregar soporte para las vistas de CUBA.
Alguien puede decir que spring-data-jpa es un cuadro negro tan incontrolado y siempre es preferible escribir JPQL puro o incluso SQL. Este es el problema eterno del equilibrio entre la conveniencia y el nivel de abstracción. Todos eligen el método que prefieren, pero tener una forma adicional de trabajar con datos en el arsenal nunca será perjudicial. Y para aquellos que necesitan más control, Spring tiene una manera de definir su propia solicitud de métodos de repositorio JPA.
Implementación
Los repositorios JPA se implementan como un módulo CUBA utilizando la biblioteca spring-data-commons . Abandonamos la idea de modificar spring-data-jpa, porque la cantidad de trabajo sería mucho más en comparación con escribir nuestro propio generador de consultas. Especialmente porque spring-data-commons hace la mayor parte del trabajo. Por ejemplo, el análisis de un nombre de método y la asociación de un nombre con clases y propiedades se realiza completamente en esta biblioteca. Spring-data-commons contiene todas las clases base necesarias para implementar sus propios repositorios y no requiere mucho esfuerzo implementar esto. Por ejemplo, esta biblioteca se usa en spring-data-mongodb .
Lo más difícil fue implementar con precisión la generación de JPQL basada en una jerarquía de objetos, el resultado de analizar el nombre del método. Pero, afortunadamente, ya se implementó una tarea similar en Apache Ignite, por lo que el código se tomó de allí y se adaptó un poco para generar JPQL en lugar de SQL y admitir el operador de delete .
Spring-data-commons utiliza el proxy para crear dinámicamente implementaciones de interfaz. Cuando se inicializa el contexto de la aplicación CUBA, todos los enlaces a las interfaces se reemplazan con enlaces a contenedores proxy publicados en el contexto. Cuando se llama al método de interfaz, es interceptado por el objeto proxy correspondiente. Luego, este objeto genera una consulta JPQL por el nombre del método, sustituye los parámetros y envía la consulta con parámetros al DataManager para su ejecución. El siguiente diagrama muestra un proceso simplificado de interacción entre los componentes clave del módulo.

Uso de repositorios en CUBA
Para usar repositorios en CUBA, solo necesita conectar el módulo en el archivo de compilación del proyecto:
appComponent("com.haulmont.addons.cuba.jpa.repositories:cuba-jpa-repositories-global:0.1-SNAPSHOT")
Puede usar la configuración XML para "habilitar" repositorios:
<?xml version="1.0" encoding="UTF-8"?> <beans:beans xmlns:beans="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:repositories="http://www.cuba-platform.org/schema/data/jpa" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.3.xsd http://www.cuba-platform.org/schema/data/jpa http://www.cuba-platform.org/schema/data/jpa/cuba-repositories.xsd"> <context:component-scan base-package="com.company.sample"/> <repositories:repositories base-package="com.company.sample.core.repositories"/> </beans:beans>
Y puedes usar las anotaciones:
@Configuration @EnableCubaRepositories public class AppConfig {
Después de activar el soporte de repositorios, puede crearlos en la forma habitual, por ejemplo:
public interface CustomerRepository extends CubaJpaRepository<Customer, UUID> { long countByLastName(String lastName); List<Customer> findByNameIsIn(List<String> names); @CubaView("_minimal") @JpqlQuery("select c from sample$Customer c where c.name like concat(:name, '%')") List<Customer> findByNameStartingWith(String name); }
Para cada método, puede usar anotaciones:
@CubaView : para configurar la vista CUBA que se utilizará en el DataManager@JpqlQuery : para especificar la consulta JPQL que se ejecutará, independientemente del nombre del método.
Este módulo se usa en el módulo global del marco CUBA, por lo tanto, los repositorios se pueden usar tanto en el módulo core como en la web . Lo único que debe recordar es activar los repositorios en los archivos de configuración de ambos módulos.
Un ejemplo de uso del repositorio en el servicio CUBA:
@Service(CustomerService.NAME) public class CustomerServiceBean implements PersonService { @Inject private CustomerRepository customerRepository; @Override public List<Date> getCustomersBirthDatesByLastName(String name) { return customerRepository.findByNameStartingWith(name) .stream().map(Customer::getBirthDate).collect(Collectors.toList()); } }
Conclusión
CUBA es un marco flexible. Si desea agregarle algo, entonces no hay necesidad de arreglar el núcleo usted mismo o esperar una nueva versión. Espero que este módulo haga que el desarrollo de CUBA sea más eficiente y rápido. La primera versión del módulo está disponible en GitHub , probado en CUBA versión 6.10