Muchos sospechan de la posibilidad de bifurcar y escribir algo por su cuenta. A menudo el precio es demasiado alto. Es especialmente extraño escuchar acerca de sus propios JDK, que supuestamente se encuentran en todas las empresas bastante grandes. ¿Qué demonios están furiosos con la grasa? Este artículo será una historia detallada sobre la compañía, que todo esto trae beneficios comerciales reales y que hizo un trabajo terrible, porque ellos:
- Desarrolló una máquina Java virtual multiinquilino;
- Se les ocurrió un mecanismo para la operación de objetos que no llevan sobrecarga a la recolección de basura;
- Hicieron algo como la contraparte ReadyNow de Azul Zing;
- Bañaron sus propias corutinas con rendimientos y continuaciones (e incluso están listas para compartir su experiencia con Loom, sobre la que escribí en otoño );
- Se atornillaron a todos estos milagros su propio subsistema de diagnóstico.
Como siempre, el video, el descifrado de texto completo y las diapositivas lo esperan debajo del corte. ¡Bienvenido al infierno de una de las áreas más difíciles de adaptación de proyectos de código abierto!

Doctor, ¿de dónde sacas esas fotos? O'Reilly Covers Corner: el fondo de KDPV es proporcionado por Joshua Newton y representa la Danza Sagrada Sangyang Jaran en Ubud, Indonesia. Este es un espectáculo clásico balinés compuesto de danza de fuego y trance. Un hombre con tacones desnudos se mueve alrededor de una hoguera, criado en cáscaras de coco, empujando cosas con los pies y bailando en estado de trance bajo la influencia de un espíritu de caballo. Ilustración perfecta para tu propio JDK, ¿verdad?
Diapositivas y una descripción del informe (no las necesita, este habratopike tiene todo lo que necesita).
Hola, mi nombre es Sanhong Lee, trabajo en Alibaba y me gustaría hablar sobre los cambios que hicimos en OpenJDK para las necesidades de nuestro negocio. La publicación consta de tres partes. En el primero hablaré sobre cómo se usa Java en Alibaba. La segunda parte, en mi opinión, es la más importante: en ella discutiremos cómo configuramos OpenJDK para las necesidades de nuestro negocio. La tercera parte tratará sobre las herramientas que creamos para el diagnóstico.
Pero antes de pasar a la primera parte, me gustaría contarles brevemente sobre nuestra empresa.
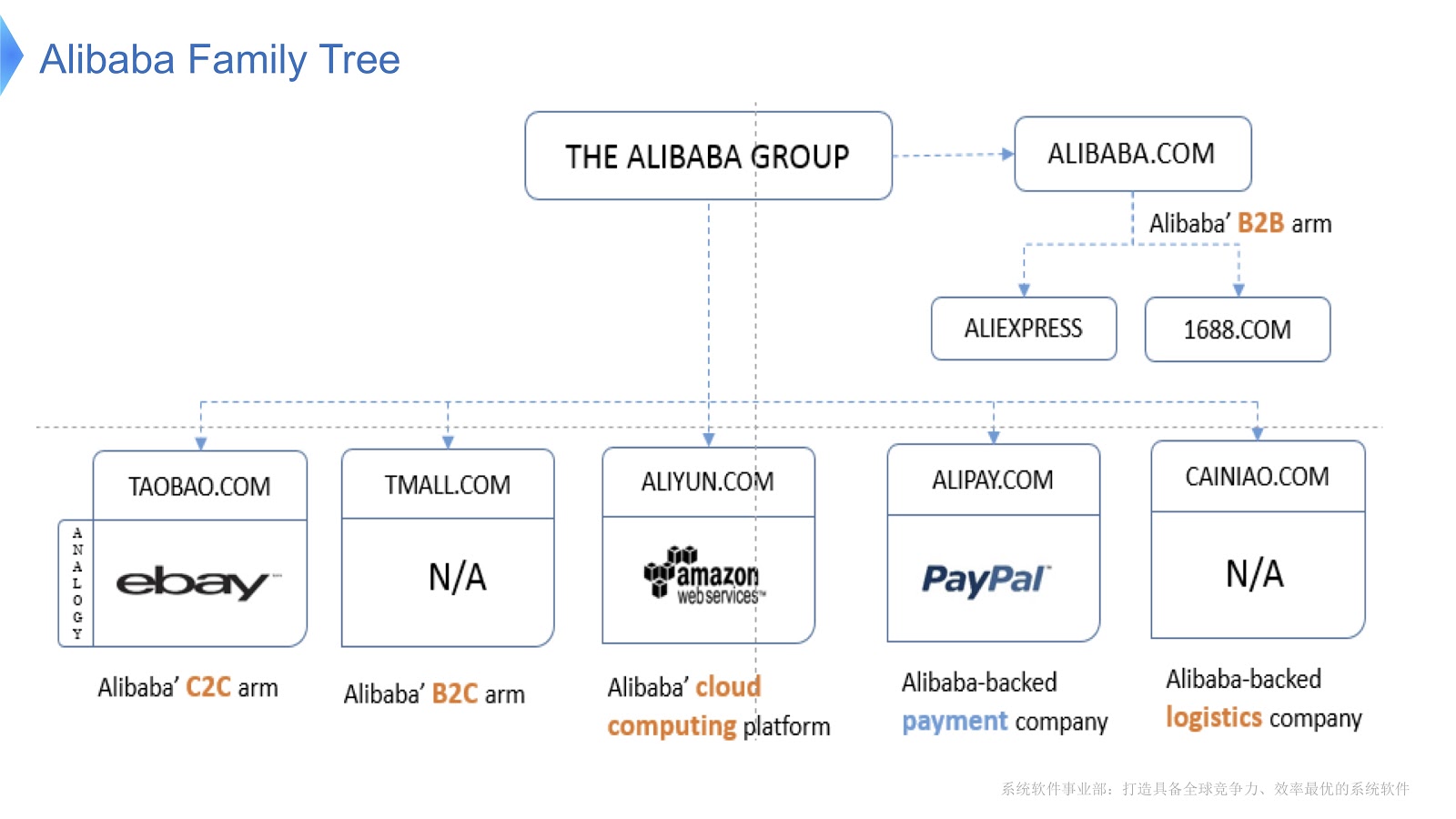
El diagrama muestra la estructura interna de Alibaba. Se compone de varias empresas cuya especialización principal es la organización del mercado electrónico y la provisión de plataformas financieras y logísticas. Creo que la mayoría de la gente en Rusia está familiarizada con AliExpress. Alibaba tiene un equipo dedicado de programadores que desarrollan y dan soporte a toda la pila distribuida, brindando servicio a clientes de Aliexpress en todo el mundo.
Para tener una idea de la escala del trabajo de Alibaba, veamos qué sucede en China el Día de los Solteros . Se celebra todos los años el 11 de noviembre, y en este día la gente compra especialmente muchos productos a través de Alibaba. Por lo que sé, de las vacaciones en todo el mundo, esta es la mayor cantidad de compras.
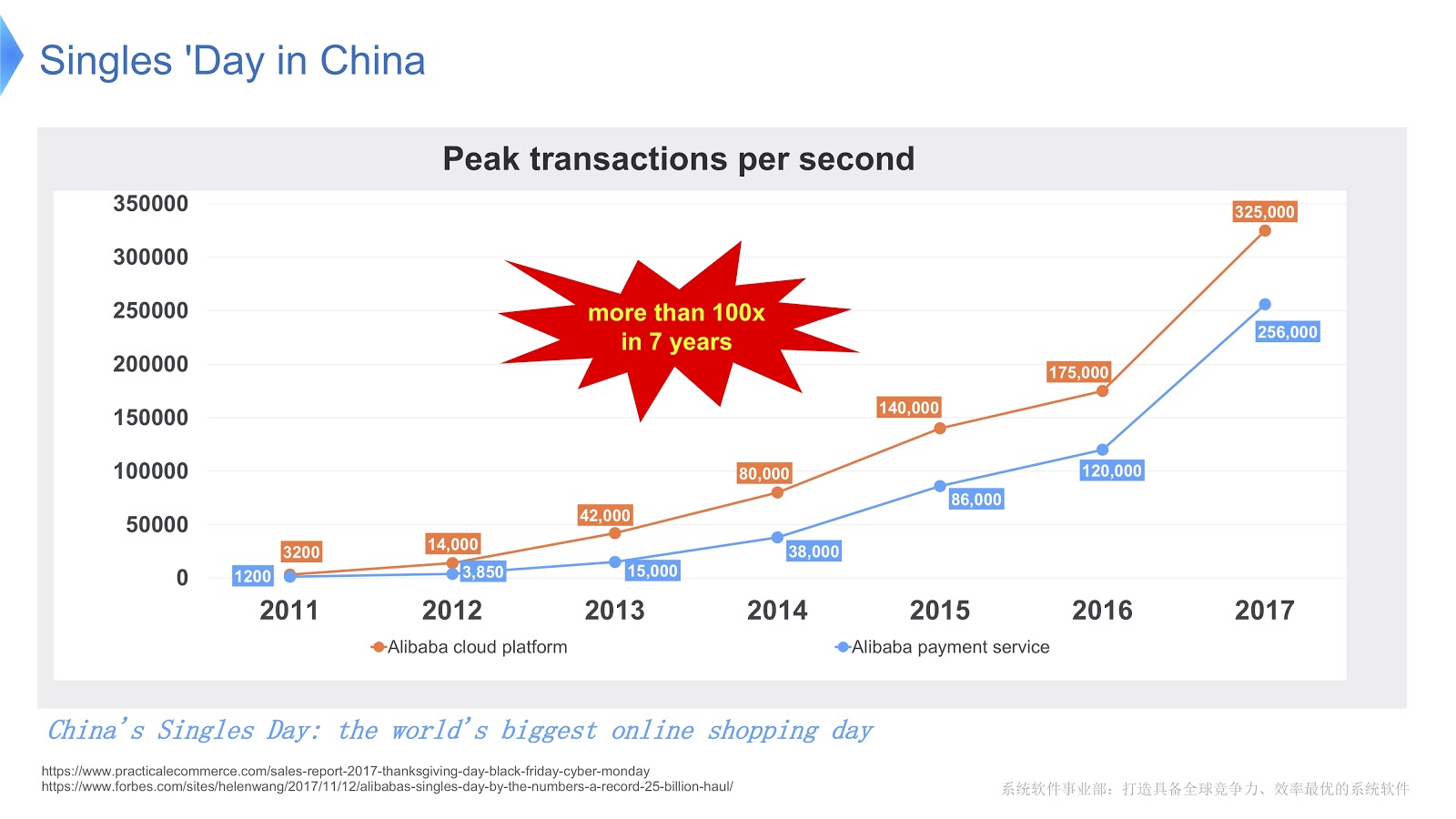
En la imagen de arriba, ve un diagrama que muestra la carga en nuestro sistema de soporte. La línea roja muestra el trabajo de nuestro servicio de pedidos y muestra el número máximo de transacciones por segundo, el año pasado ascendió a 325 mil. La línea azul se refiere al servicio de pago, y ella tiene esta cifra de 256 mil. Me gustaría hablar sobre cómo optimizar la pila que sirve tantas transacciones.
Analicemos las principales tecnologías que funcionan en Alibaba con Java. En primer lugar, debo decir que tenemos una serie de aplicaciones de código abierto como base. Para el procesamiento de big data utilizamos HBase Hadoop. Como contenedor utilizamos Tomcat y OSGi. Java se utiliza en una escala colosal: millones de instancias de JVM se implementan en nuestro centro de datos. También debo decir que nuestra arquitectura está orientada a servicios, es decir, creamos muchos servicios que se comunican entre sí mediante llamadas RPC. Finalmente, nuestra arquitectura es heterogénea. Para mejorar el rendimiento, muchos algoritmos se escriben utilizando bibliotecas C y C ++, por lo que se comunican con Java mediante llamadas JNI.

La historia de nuestro trabajo con OpenJDK comenzó en 2011, durante OpenJDK 6. Hay tres razones importantes por las que elegimos OpenJDK. Primero, podemos cambiar directamente su código de acuerdo con las necesidades del negocio. En segundo lugar, cuando surgen problemas urgentes, podemos resolverlos por nuestra cuenta más rápido que esperar el lanzamiento oficial. Esto es vital para nuestro negocio. En tercer lugar, nuestros desarrolladores de Java utilizan nuestras propias herramientas para la depuración y el diagnóstico rápidos y de alta calidad.
Antes de pasar a cuestiones técnicas, quiero enumerar las principales dificultades que tenemos que superar. En primer lugar, hemos lanzado una gran cantidad de instancias de JVM; en esta situación, la cuestión de reducir los costos de hardware es un problema grave. En segundo lugar, ya he dicho que atendemos una gran cantidad de transacciones. Gracias al recolector de basura, Java nos promete "memoria infinita". Además, gana en rendimiento a bajo nivel gracias al compilador JIT. Pero esto también tiene un lado negativo: un tiempo más largo para detener el mundo para la recolección de basura. Además, Java necesita ciclos de CPU adicionales para compilar métodos Java. Esto significa que los compiladores compiten por los ciclos de CPU. Ambos problemas empeoran a medida que la aplicación se vuelve más compleja.
La tercera dificultad es que tenemos muchas aplicaciones en ejecución. Creo que todos aquí están familiarizados con las herramientas que vienen con OpenJDK, como JConsole o VisualVM. El problema es que no nos dan la información exacta que necesitamos para configurar. Además, cuando usamos estas herramientas (por ejemplo, JConsole o VisualVM) en producción, una baja sobrecarga no es solo un deseo, sino un requisito necesario. Tuve que escribir mis propias herramientas de diagnóstico.

La imagen describe los cambios que realizamos en OpenJDK. Echemos un vistazo a cómo superamos las dificultades de las que hablé anteriormente.
JVM multiempresa
Una solución que llamamos JVM multiinquilino. Le permite ejecutar de forma segura múltiples aplicaciones web en un contenedor. Otra solución se llama GCIH (GC Invisible Heap). Este es un mecanismo que le proporciona objetos Java completos que no requieren el costo de la recolección de basura. Además, para reducir los costos de los contextos de subprocesos, implementamos corutinas en nuestra plataforma Java. Además, escribimos un mecanismo llamado JWarmup: su función es muy similar a ReadyNow. Douglas Hawkins parece haberlo mencionado en su informe . Finalmente, desarrollamos nuestra propia herramienta de creación de perfiles, ZProfiler.
Echemos un vistazo más de cerca a cómo implementamos la tenencia múltiple basada en OpenJDK.
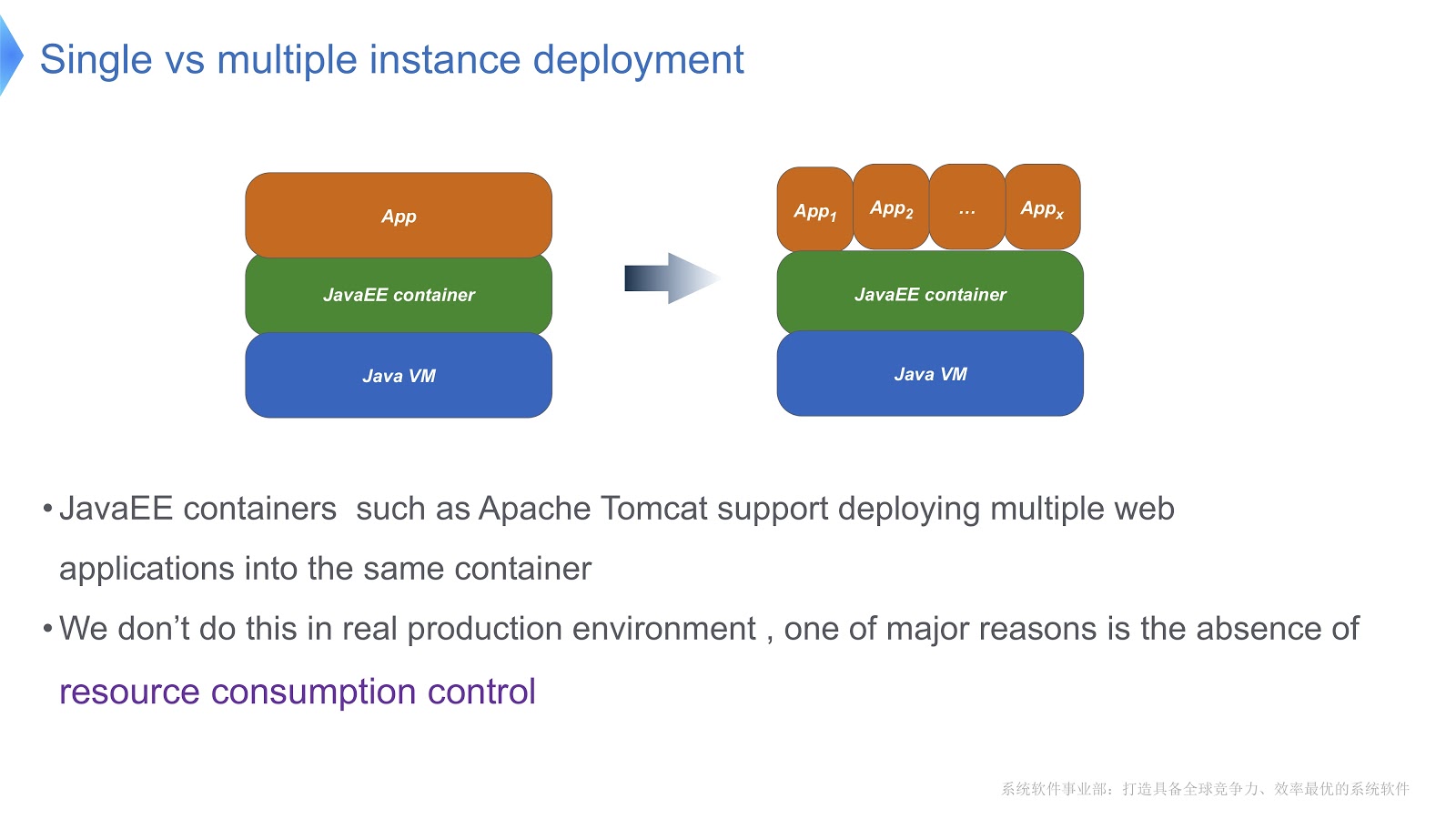
Eche un vistazo a la imagen de arriba: creo que la mayoría de ustedes está familiarizada con este patrón. Compare el enfoque tradicional con el multiinquilino. Si su aplicación se ejecuta con Apache Tomcat, también puede ejecutar varias instancias en el mismo contenedor. Pero Tomcat no proporciona un consumo estable de recursos para cada uno de ellos. Digamos, si una de las aplicaciones en ejecución necesita más tiempo de CPU que la otra, ¿cómo va a controlar la asignación de tiempo de CPU? ¿Cómo asegurar que esta aplicación no afecte el trabajo de otros? Fue principalmente esta pregunta la que nos hizo recurrir a la tecnología multiempresa.
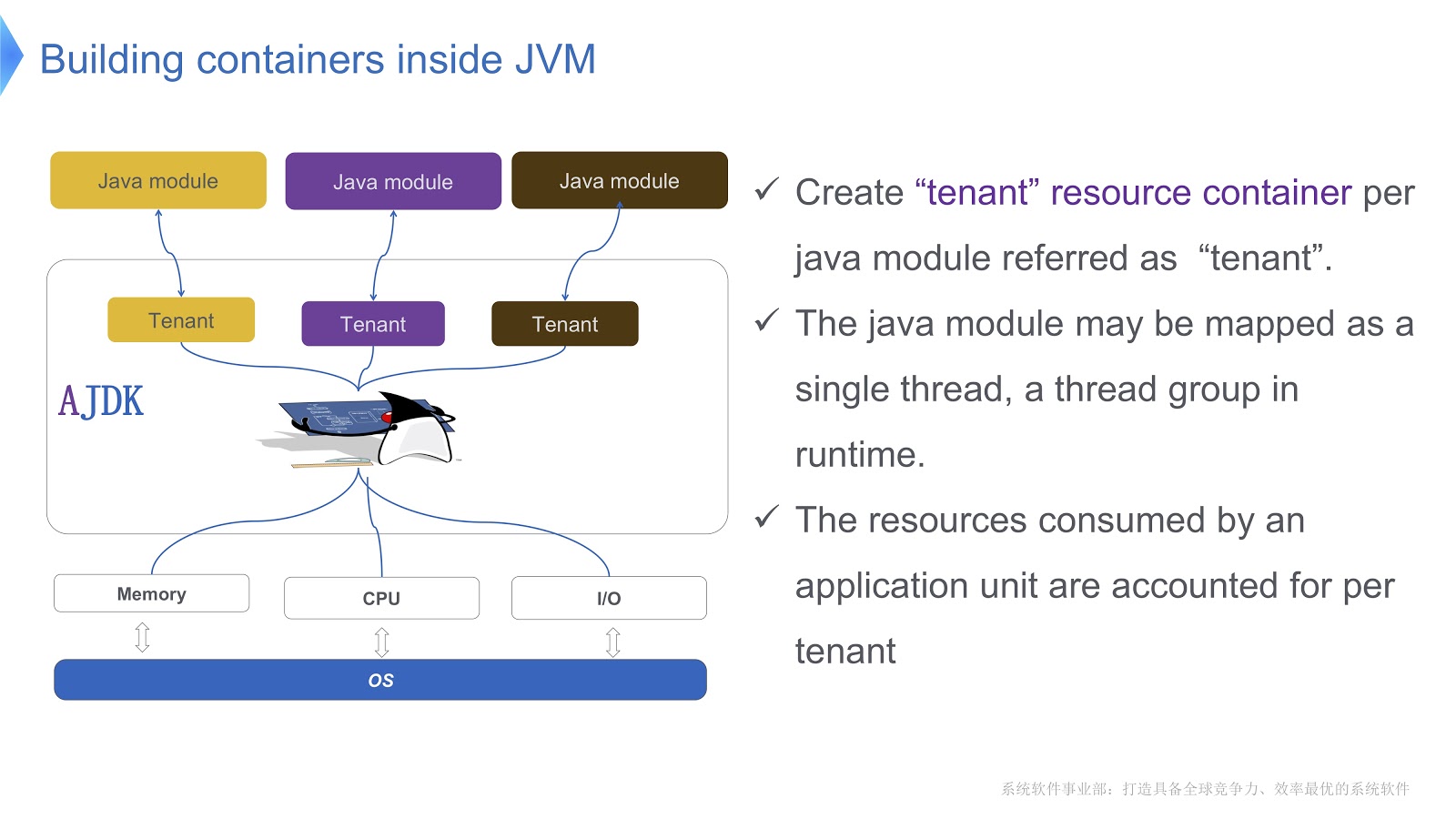
La imagen muestra esquemáticamente cómo lo implementamos. Creamos varios contenedores para inquilinos dentro de la JVM. Cada uno de estos contenedores proporciona un control confiable del consumo de recursos para cada módulo Java. Se pueden implementar múltiples módulos en un contenedor. Cada módulo se puede asociar con un hilo o un grupo de hilos en tiempo de ejecución.
Echemos un vistazo a cómo se ve la API del contenedor de inquilinos. Tenemos una clase de configuración de inquilinos que almacena información sobre el consumo de recursos. A continuación, hay una clase del contenedor en sí.
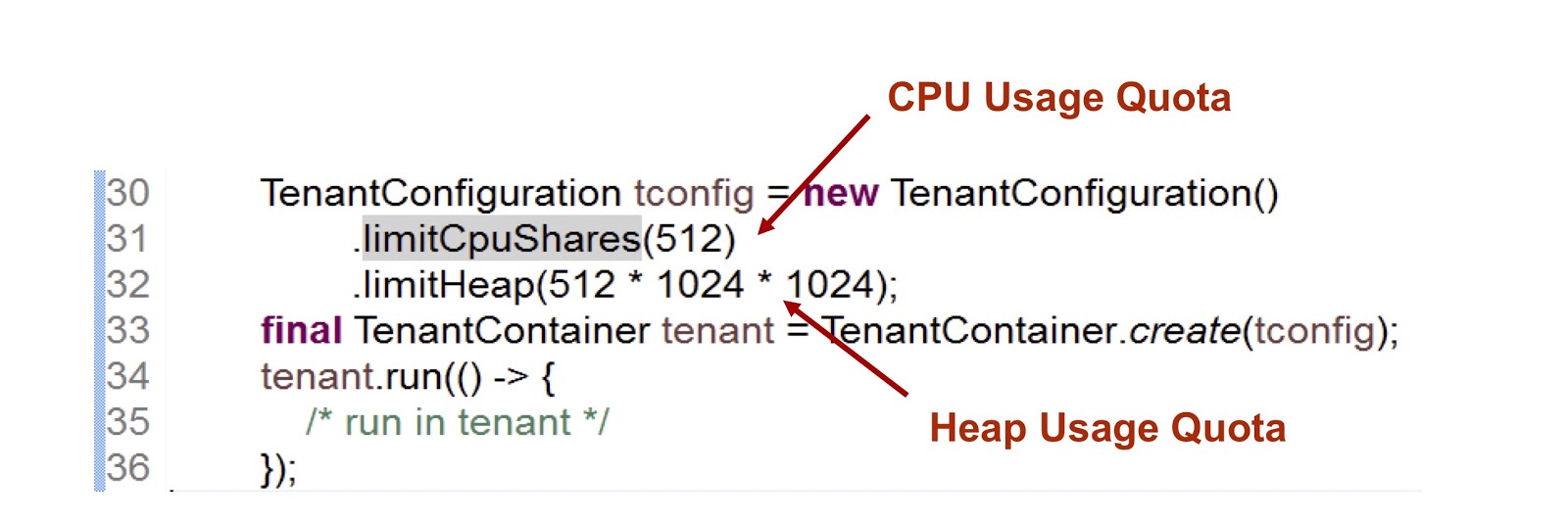
En el fragmento de código presentado, creamos un inquilino y luego indicamos cuánto tiempo se le proporciona la CPU y la memoria. El primer indicador es un número entero, lo que significa la parte del tiempo de CPU disponible para el inquilino, en este caso indicamos 512. Utilizamos un enfoque muy similar en el caso de cgroups, me detendré en esto con más detalle. La segunda métrica es el tamaño de almacenamiento dinámico máximo que pueden usar los inquilinos.
Considere cómo un inquilino interactúa con un hilo. La clase TenantContainer proporciona el método .run() , y cuando un hilo lo ingresa, se une automáticamente al inquilino, y cuando lo abandona, se produce el procedimiento inverso. Entonces todo el código se ejecuta dentro del método .run() . Además, cualquier subproceso creado dentro del método .run() se adjunta al inquilino del subproceso principal.
Llegamos a una pregunta muy importante: ¿cómo se gestiona la CPU en una JVM multiinquilino? Nuestra solución acaba de implementarse en la plataforma Linux x64. Existe un mecanismo de grupo de control, cgroups. Le permite seleccionar un proceso en un grupo separado y luego indicar su modo de consumo de recursos para cada grupo. Intentemos transferir este enfoque al contexto de la JVM Hotspot. En Hotstpot, los hilos de Java se organizan como hilos nativos.

Esto se muestra en el diagrama anterior: cada hilo de Java está en una correspondencia uno a uno con el hilo nativo. En nuestro ejemplo, tenemos un contenedor TenantA , en el que hay dos hilos nativos. Para poder controlar la distribución del tiempo de CPU, colocamos ambos hilos nativos en un grupo de control. Debido a esto, podemos regular el consumo de recursos, confiando únicamente en la funcionalidad de [grupos de control] ( https://en.wikipedia.org/wiki/Cgroups ).
Echemos un vistazo a un ejemplo más detallado.
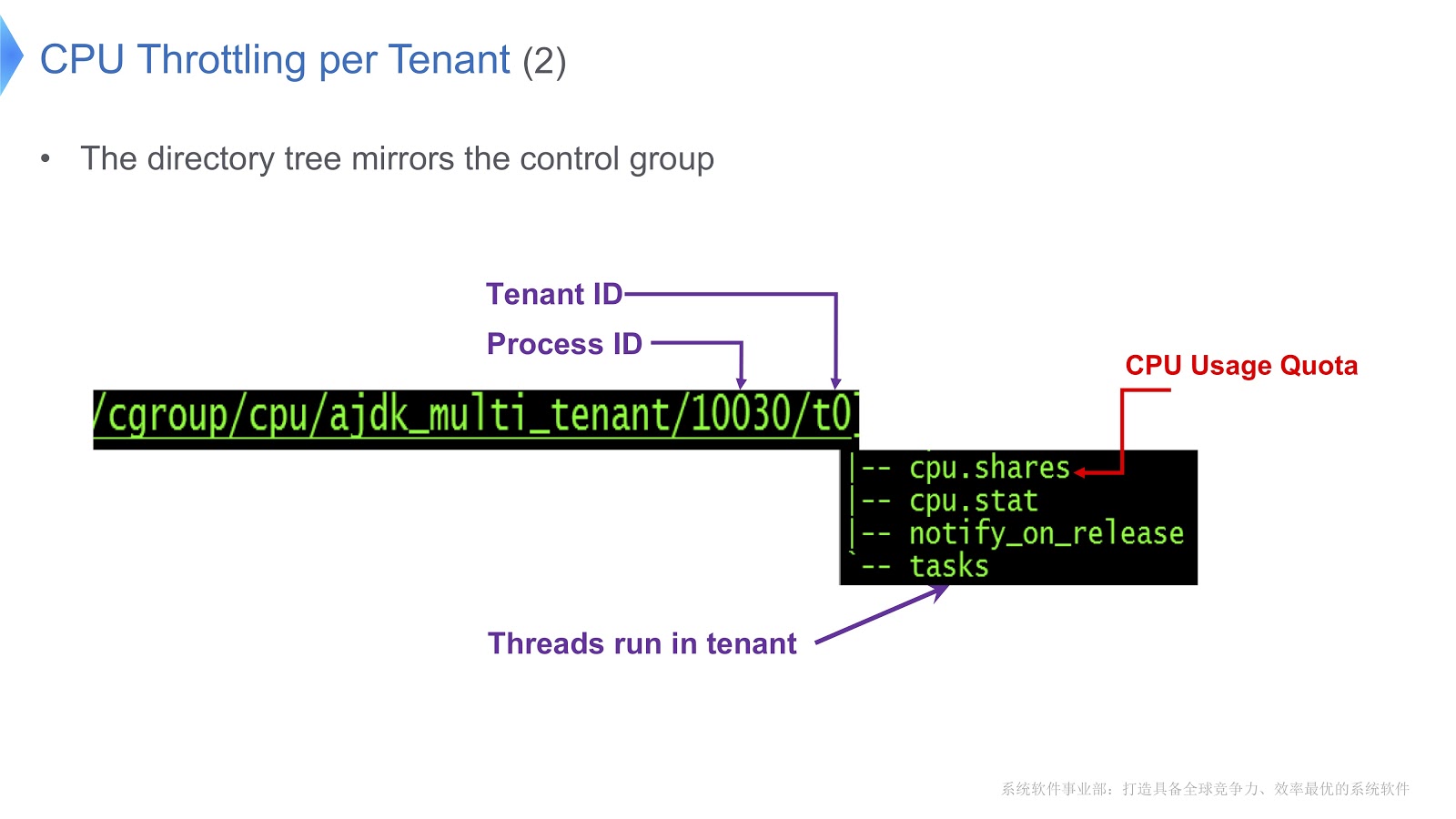
Los grupos de control en Linux se asignan a un directorio. En nuestro ejemplo, creamos el directorio /t0 para el inquilino 0. Este directorio contiene el directorio /t0/tasks , todos los hilos para t0 se t0 aquí. Otro archivo importante es /t0/cpu.shares . Indica cuánto tiempo se le dará la CPU a este inquilino. Toda esta estructura se hereda de los grupos de control: simplemente garantizamos una correspondencia directa entre el hilo de Java, el hilo nativo y el grupo de control.
Otra cuestión importante se relaciona con la gestión de un grupo de cada inquilino.
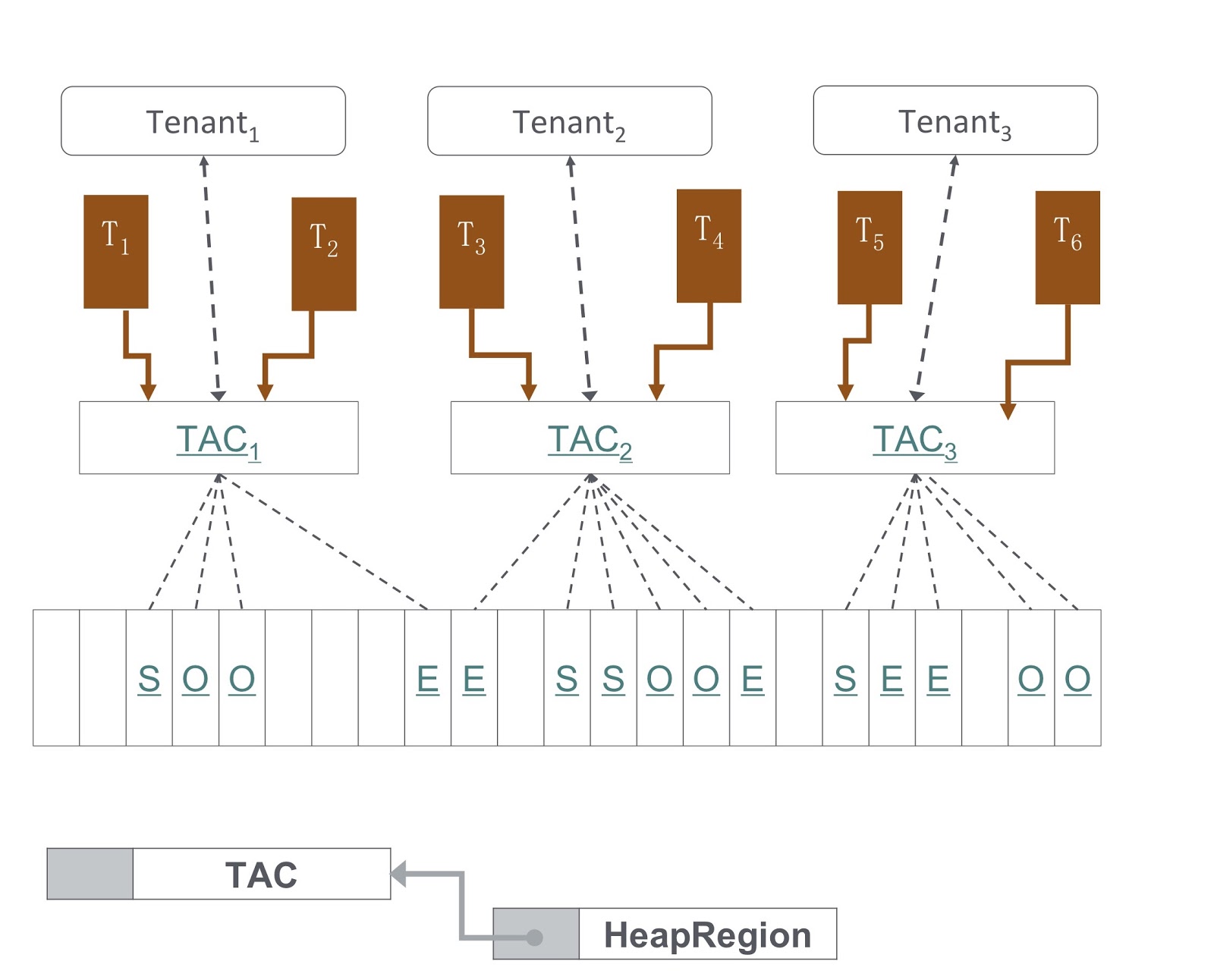
En la imagen puede ver un diagrama de cómo se implementa. Nuestro enfoque se basa en el G1GC. En la parte inferior de la imagen, G1GC divide el montón en secciones del mismo tamaño. En base a ellos, creamos Contextos de asignación de inquilinos, TAC, con los cuales el inquilino administra su sección de montón. A través de TAC, limitamos el tamaño de la porción del montón disponible para el inquilino. Aquí, se aplica el principio, según el cual cada sección del montón contiene objetos de un solo inquilino. Para implementarlo, necesitábamos hacer cambios en el proceso de copiar un objeto durante la recolección de basura: era necesario asegurarse de que el objeto se copiara en la sección correcta del montón.
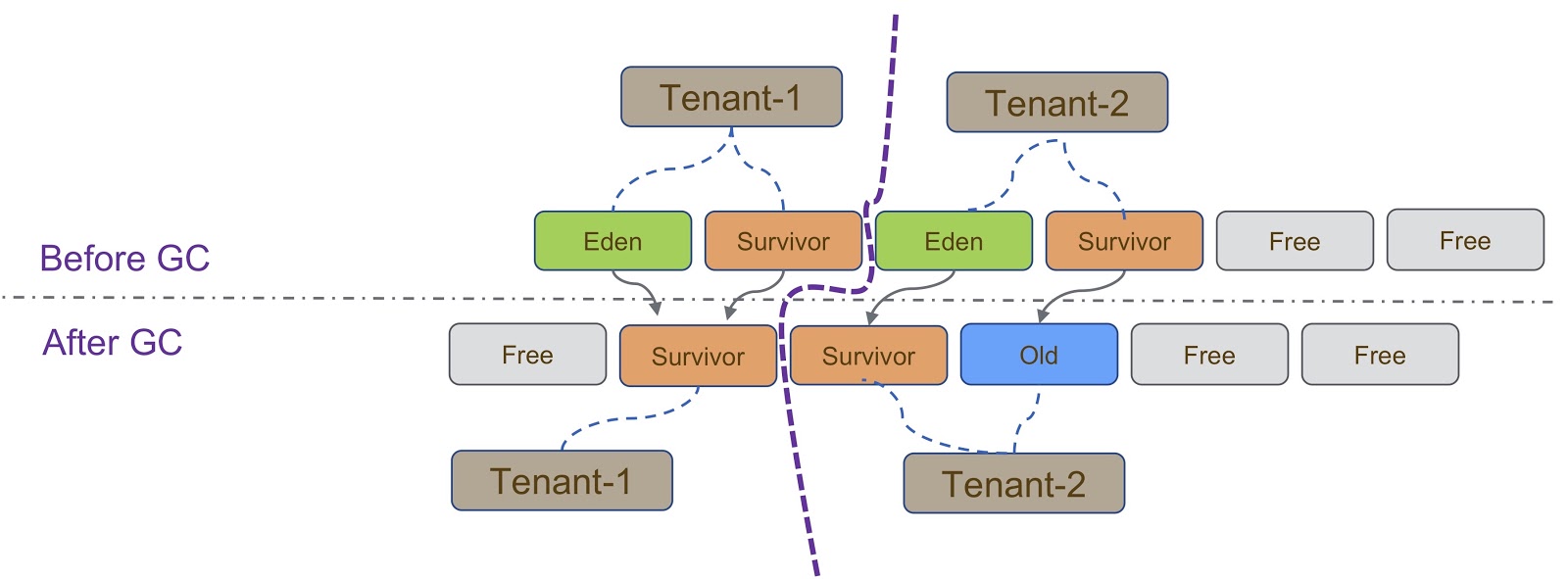
Esquemáticamente, este proceso se representa en el diagrama anterior. Como dije, nuestra implementación se basa en G1GC. G1GC es un recolector de basura de copia, por lo que durante la recolección de basura debemos asegurarnos de que el objeto se copie en la sección correcta del montón. En la diapositiva, todos los objetos creados por Tenant-1 deben copiarse en su parte del montón, de forma similar a Tenant-2 .
Hay otras consideraciones que surgen cuando los inquilinos están aislados unos de otros. Aquí debo decir sobre TLAB (Thread Local Allocation Buffer), un mecanismo para la asignación rápida de memoria. El espacio TLAB depende de la sección del montón. Como dije, diferentes inquilinos tienen diferentes grupos de secciones de montón.

Los detalles de trabajar con TLAB se muestran en la diapositiva: cuando el subproceso cambia de Tenant 1 a Tenant 2 , debemos asegurarnos de que se use la sección de montón correcta para el espacio TLAB. Esto se puede lograr de dos maneras. La primera forma es cuando el Thread A cambia del Tenant 1 al Tenant 2 , simplemente nos deshacemos del anterior y creamos uno nuevo en el Tenant 2 . Este método es relativamente fácil de implementar, pero desperdicia espacio en TLAB, lo que no es deseable. La segunda forma es más complicada: hacer que TLAB conozca a los inquilinos. Esto significa que tendremos varios búferes TLAB para un hilo. Cuando el Thread A cambia del Tenant 1 al Tenant 2 , debemos cambiar el búfer y usar el que se creó en el Tenant 2 .
Otro mecanismo que debe decirse en relación con la delimitación de los inquilinos es IHOP (Porcentaje de ocupación de subprocesos iniciadores). Inicialmente, IHOP se calculó sobre la base de todo el montón, pero en el caso de un mecanismo de múltiples inquilinos, se debe calcular sobre la base de solo una sección del montón.
Echemos un vistazo más de cerca a lo que es GCIH (GC Invisible Heap). Este mecanismo crea una sección en el montón, oculta al recolector de basura y, en consecuencia, no se ve afectada por la recolección de basura. Este sitio es administrado por el inquilino de GCIH.

Es importante decir aquí que proporcionamos una API pública a nuestros desarrolladores de Java. Un ejemplo de trabajar con él se puede ver en la pantalla. Permite usar el método moveIn() para mover objetos de un montón regular a una parte del montón GCIH. Su ventaja es que aún puede interactuar con estos objetos como con los objetos normales de Java, son muy similares en estructura. Pero al mismo tiempo no requieren el costo de la recolección de basura. La conclusión, en mi opinión, es que si desea acelerar la recolección de basura, debe personalizar el comportamiento del recolector de basura de acuerdo con las necesidades de su aplicación.
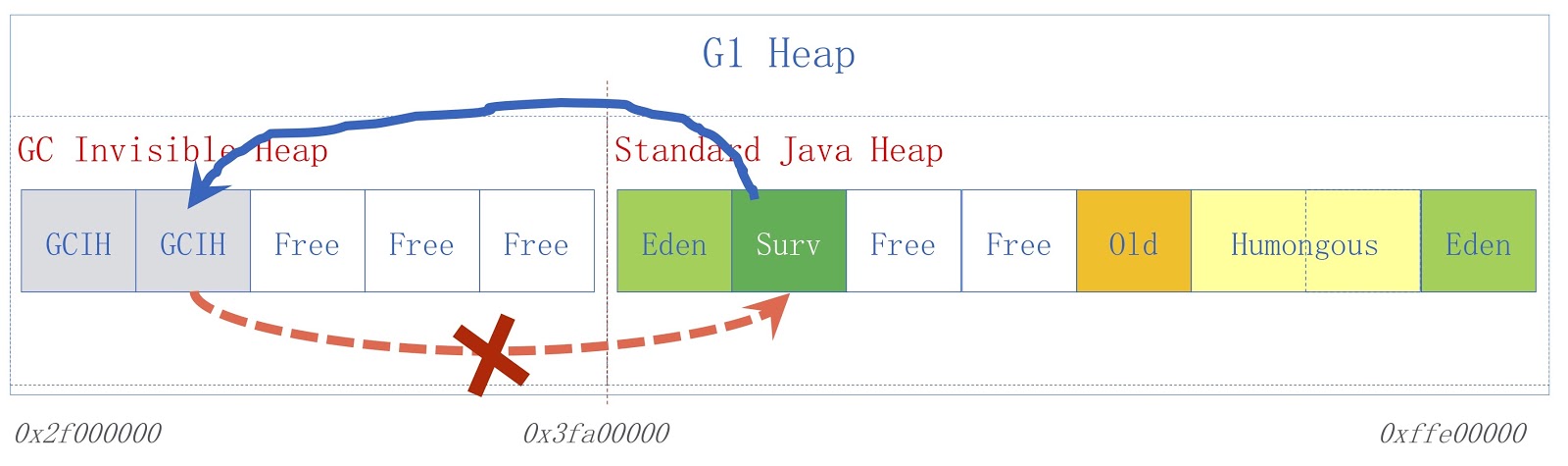
La imagen muestra un esquema GCIH de alto nivel. A la derecha hay un montón de Java normal, a la izquierda está el espacio asignado para GCIH. Los enlaces de un montón regular a objetos en GCIH son válidos, pero los enlaces de GCIH a un montón regular no lo son. Para entender por qué es así, considere un ejemplo. Tenemos el objeto "A" en GCIH, que contiene una referencia al objeto "B" en un montón normal. El problema es que el objeto B puede ser movido por el recolector de basura. Como ya dije, no hacemos actualizaciones en GCIH, por lo que después de que el recolector de basura funciona, el objeto "A" puede contener una referencia no válida al objeto "B". Este problema se puede resolver utilizando la barrera previa a la escritura; se discutieron en un informe anterior. Como ejemplo, supongamos que alguien necesita guardar un enlace de un montón de Java normal a GCIH antes de que el guardado que asumimos resultaría en una excepción de predicción con un indicador de que se violó la regla.
Para una aplicación específica, se utiliza una JVM multiinquilino en nuestra Plataforma de personalización de Taobao, abreviado TPP. Este es un sistema de recomendación para nuestra aplicación de compras electrónicas. TPP puede implementar varios microservicios en un contenedor, y con la ayuda de la JVM multiinquilino controlamos la memoria y el tiempo de CPU proporcionado a cada microservicio.
En cuanto a GCIH, se usa en nuestro otro sistema, la Plataforma UM. Esta es una aplicación de descuento en línea. El propietario de esta aplicación utiliza GCIH para almacenar en caché previamente los datos de GCIH en la máquina local, para no acceder a los objetos en el servidor de caché remoto o la base de datos remota. Como resultado, facilitamos la carga en la red y realizamos menos serialización y deserialización.
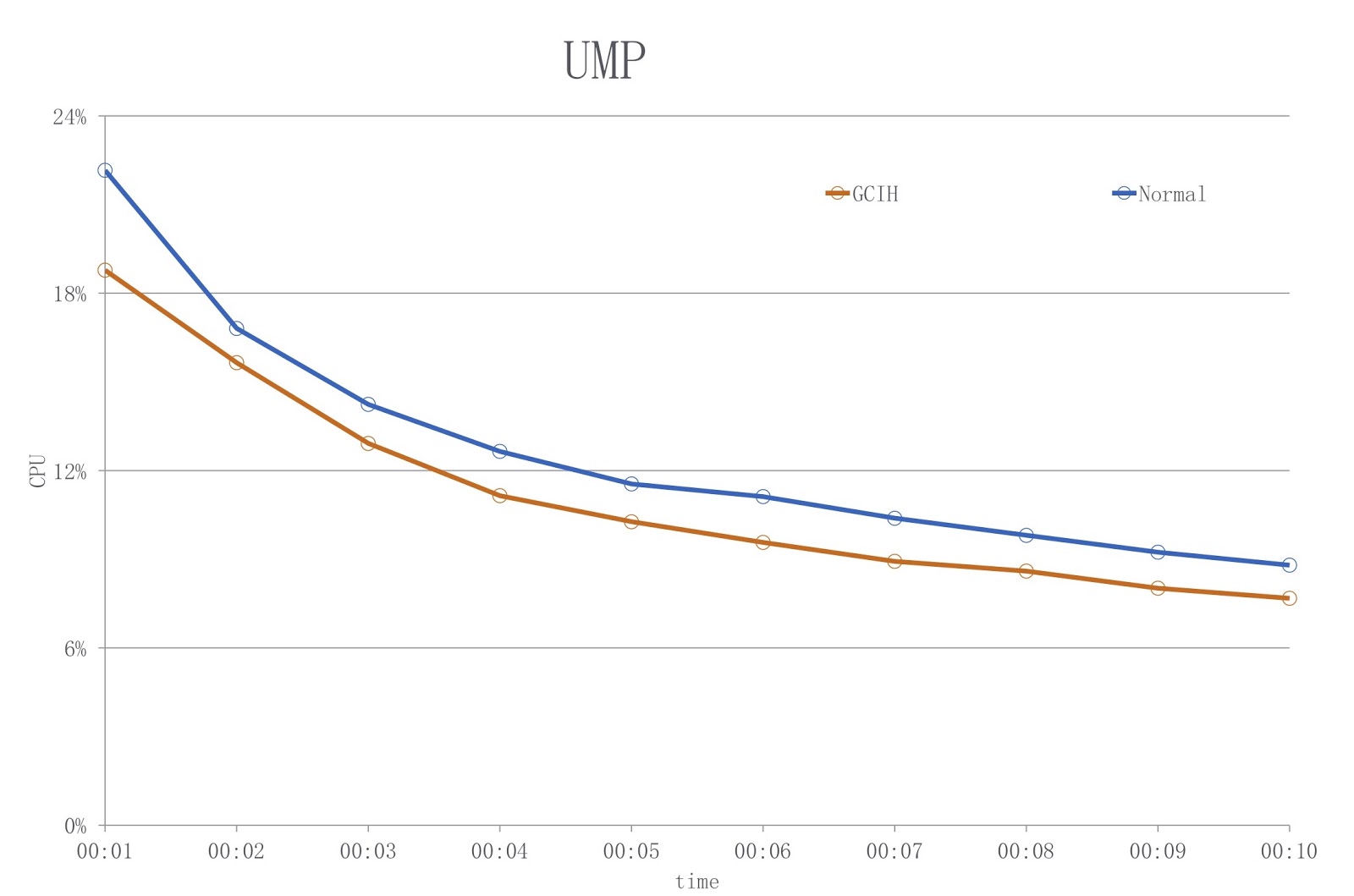
La imagen muestra un diagrama en el que el color azul muestra la carga cuando se usa un JDK convencional y el rojo - GCIH. Como puede ver, estamos reduciendo la utilización de la CPU en más del 18%.
Hasta donde yo sé, BellSoft resolvió un problema similar, y su solución fue similar a GCIH, pero utilizaron un enfoque diferente para reducir los costos de serialización y deserialización.
Corutinas en Java
Volvamos a Alibaba y veamos cómo se pueden implementar las rutinas en Java. Pero primero, hablemos sobre los orígenes, sobre por qué necesitamos hacer esto. En Java, siempre fue muy fácil escribir aplicaciones de subprocesos múltiples. Pero el problema con la creación de tales aplicaciones es que, como dije, en Hotspot los hilos de Java ya están implementados como hilos nativos. Por lo tanto, cuando hay muchos hilos en su aplicación, los costos de cambiar el contexto del hilo se vuelven muy altos.

Considere un ejemplo en el que tendremos 4 hilos de E / S y 200 hilos con la lógica de su aplicación. La tabla en la pantalla muestra los resultados de iniciar esta demostración simple: puede ver cuánto tiempo tarda la CPU en cambiar los contextos. La solución a este problema puede ser la implementación de corutina en Java.
Para proporcionarlo, necesitábamos dos cosas. Primero, Alibaba JDK necesitaba agregar soporte de continuación. Este trabajo se basó en el parche JKU, nos detendremos en él con más detalle. En segundo lugar, agregamos un programador de modo de usuario que será responsable de la continuación del hilo. En tercer lugar, hay muchas aplicaciones en Alibaba. Por lo tanto, nuestra solución es muy importante para nuestros desarrolladores de Java, y fue necesario que sea absolutamente transparente para ellos. Y esto significa que en nuestra aplicación comercial no debería haber prácticamente cambios en el código. Llamamos a nuestra solución Wisp. Nuestra implementación de corutinas en Java se usa ampliamente en Alibaba, por lo que puede considerarse comprobado que funciona en Java. Llegar a conocerlo con más detalle.

Comencemos con el ejemplo, cuyo código se presenta anteriormente: esta es una aplicación Java completamente normal. Primero, se crea un grupo de subprocesos. Luego se crea otra tarea Runnable que acepta el socket. Después de eso, se realiza la lectura de la secuencia. A continuación, creamos otra tarea Runnable, con la que nos conectamos al servidor y, finalmente, escribimos datos en la transmisión. Como puede ver, todo parece bastante estándar. Si ejecuta el código en un JDK normal, cada una de estas tareas Ejecutables se ejecutará en un hilo separado. Pero en nuestra decisión, la mecánica será completamente diferente.
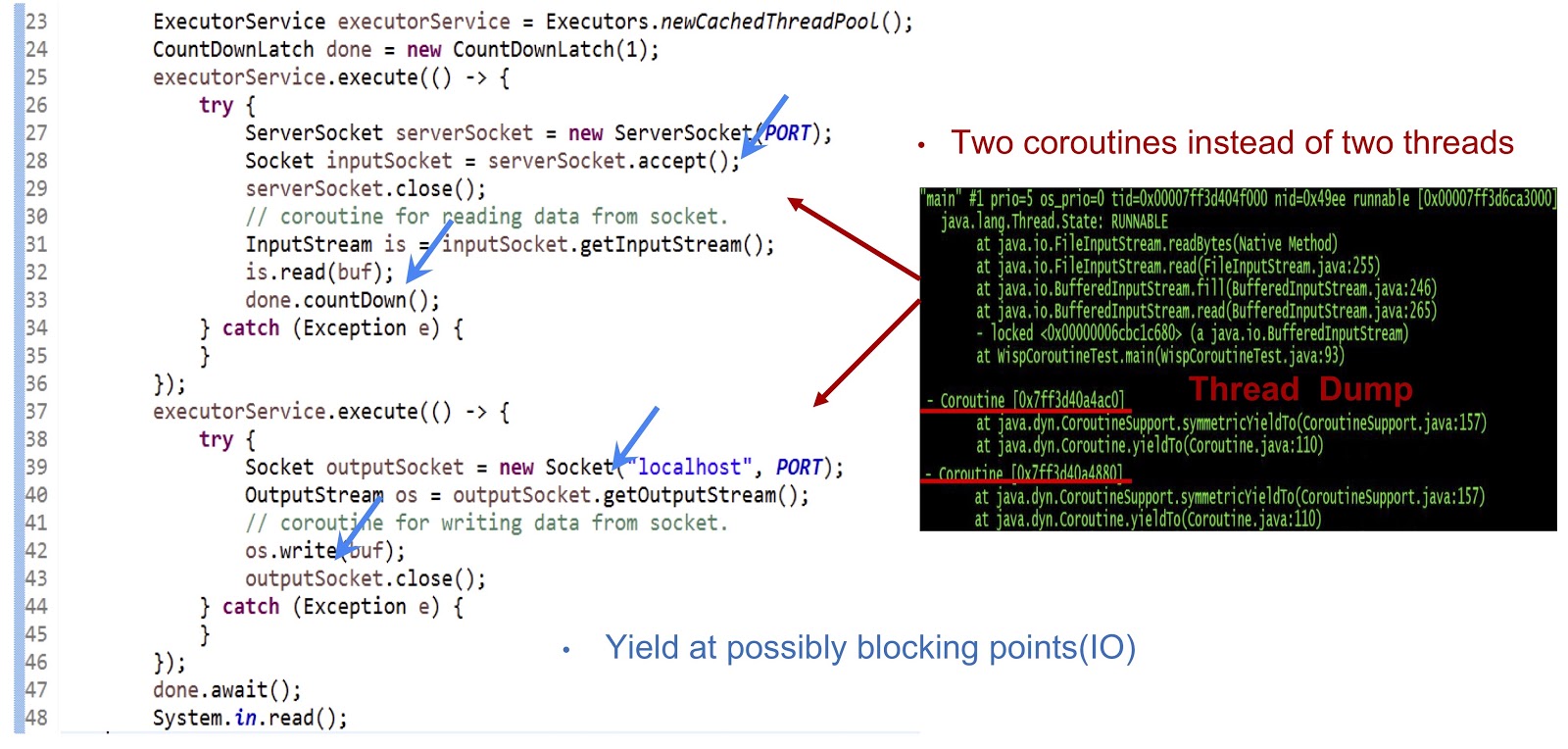
Como puede ver en el volcado del hilo que se muestra en la diapositiva, creamos dos corutinas en un hilo, y no dos hilos. Ahora necesita hacer que esta solución funcione. Lo principal aquí es hacer que la generación de eventos fondee en todos los puntos de bloqueo posibles. En nuestro ejemplo, estos puntos serán serverSocket.accept() , is.read(buf) , una conexión de socket y os.write(buf) . Gracias a los eventos de rendimiento en estos puntos, podremos transferir el control de una corutina a otra dentro del mismo hilo. En resumen, nuestro enfoque es que logramos un rendimiento asincrónico usando la rutina, pero nuestros programadores pueden escribir código en un estilo sincrónico, ya que dicho código es mucho más simple y fácil de mantener y depurar.
Veamos exactamente cómo proporcionamos soporte de continuación en Alibaba JDK. Como dije, este trabajo se basa en un proyecto de máquina virtual multilingüe creado por la comunidad, es de dominio público. Utilizamos este parche en Alibaba JDK y solucionamos algunos errores que ocurrían en nuestro entorno de producción.
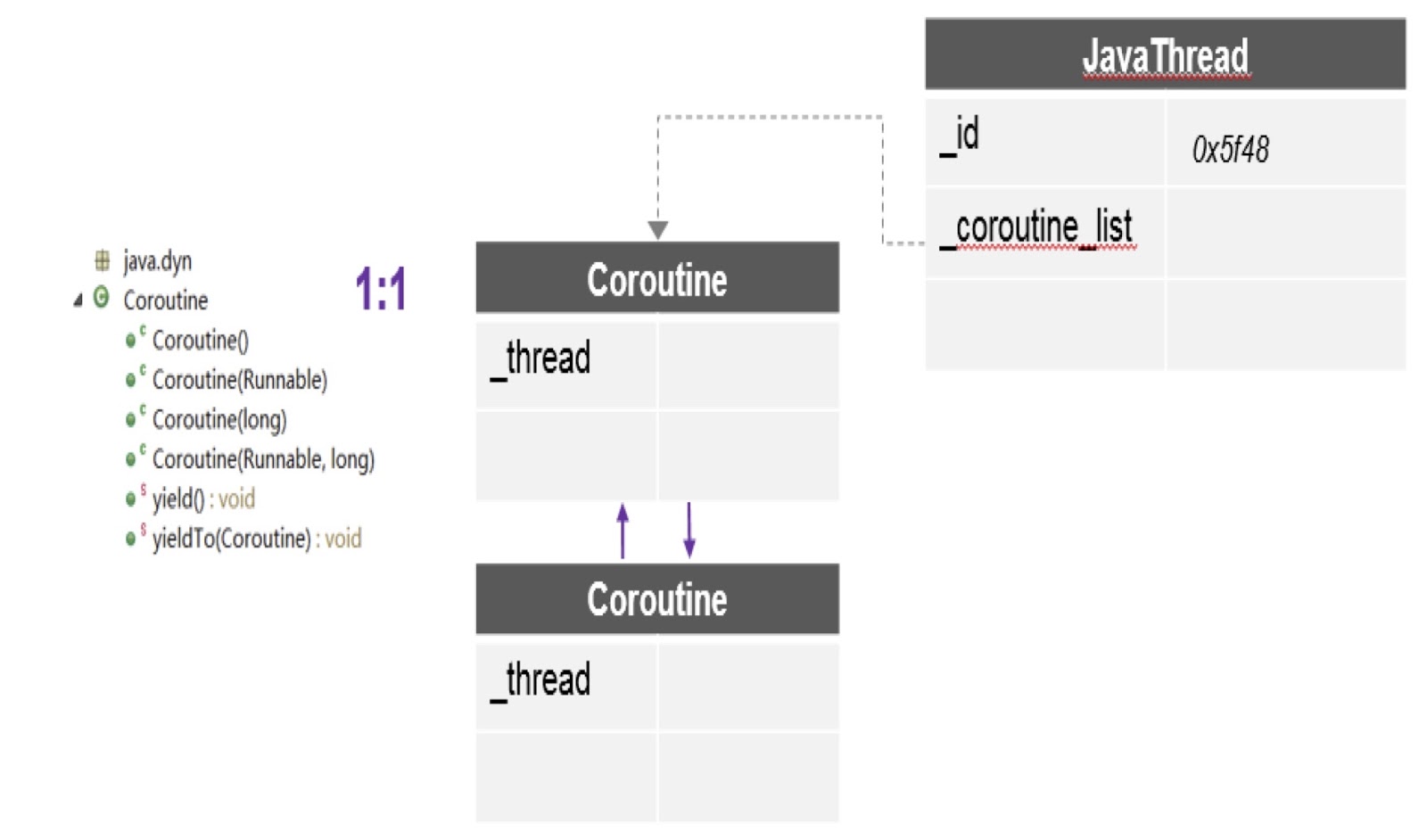
Como puede ver en el diagrama, aquí en un hilo puede haber varias corutinas, y para cada una se crea una pila separada. Además, el parche del que hablé nos proporciona la API más importante aquí: yieldTo, con la ayuda de la cual el control se transfiere de una rutina a otra.
Pasemos a cómo implementamos el programador de modo de usuario para la rutina. Usamos un selector, y con él registramos varios canales. Cuando ocurre cualquier evento de E / S (lectura de socket, escritura de socket, conexión de socket o aceptación de socket), se escribe como una clave para el selector. Por lo tanto, al final de este evento, recibimos una alerta del selector. Por lo tanto, usamos un selector para planificar corutinas en caso de un bloqueo de E / S. Considere un ejemplo de cómo funcionará esto.
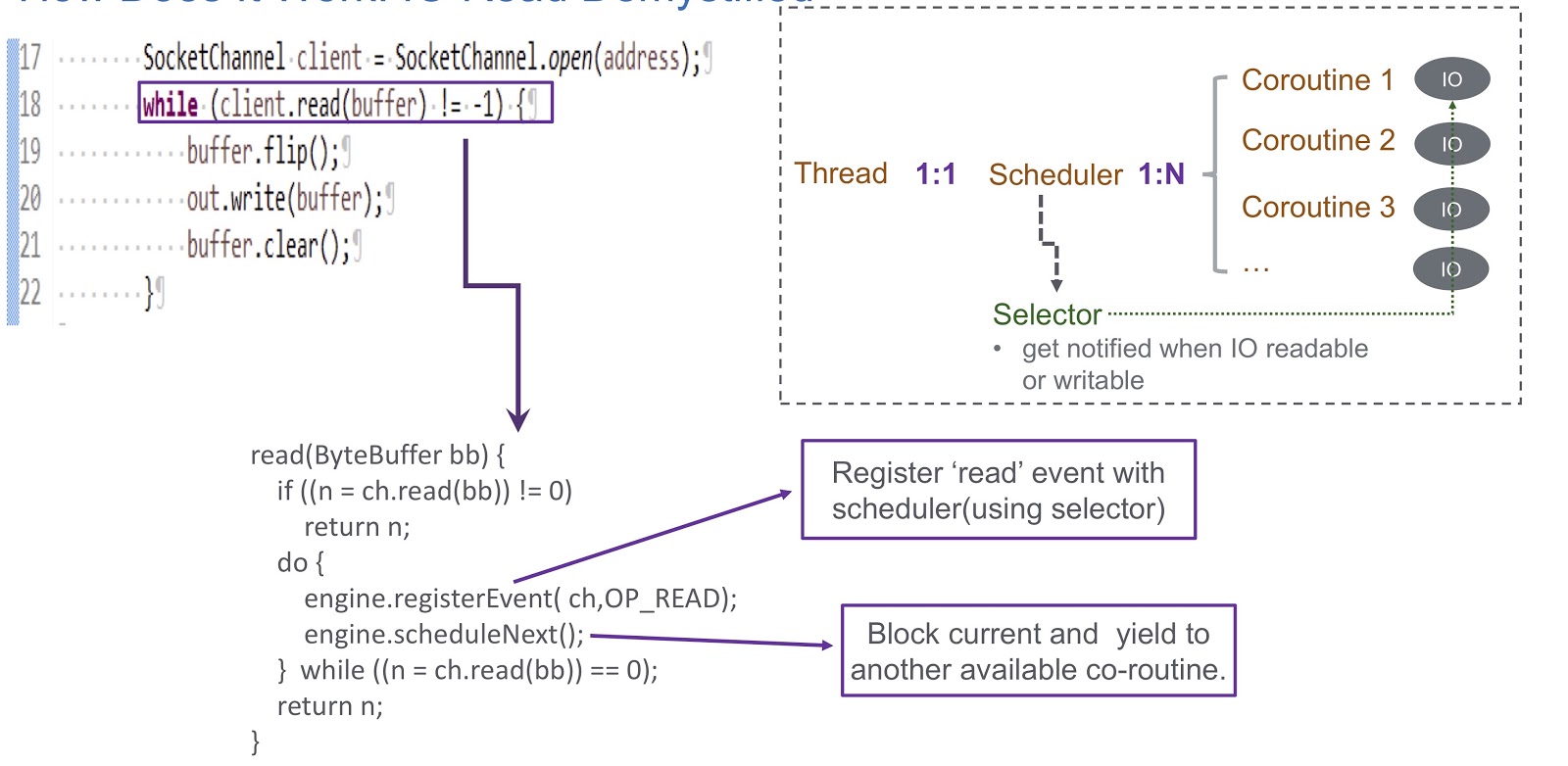
En la imagen vemos el socket y la llamada síncrona client.read(buffer) . En la parte inferior de la diapositiva, se escribe un código que se ejecutará dentro de esta llamada. Primero, verifica si es posible leer desde el canal o no. Si es así, entonces devolvemos el resultado. Lo más interesante sucede si no se puede leer. Luego registramos el evento de lectura en nuestro planificador con selector. Esto hace posible planificar la ejecución de cualquier otra rutina. Echa un vistazo a cómo sucede esto. Tenemos un hilo en el que se crea un planificador. El hilo y nuestra rutina están en correspondencia uno a uno entre sí. Sheduler nos permite gestionar las rutinas de este hilo. ¿Qué sucede si se bloquea la E / S? Cuando ocurren eventos de E / S, el programador recibe una alerta y, en esta situación, depende completamente del selector. Después de tal evento, el planificador tiene la oportunidad de planificar la próxima rutina disponible.
Resumamos la descripción general de nuestro programador, al que llamamos WispEngine. Para cada uno de nuestros hilos, asignamos un WispEngine separado. Cuando ocurre un bloqueo de rutina, registramos ciertos eventos (lectura / escritura de socket, etc.) usando WispEngine. Algunos eventos están relacionados con el estacionamiento de subprocesos, por ejemplo, si llama a thread.sleep() con un retraso de 100 milisegundos. En este caso, se generará un evento de estacionamiento de subprocesos para usted, que luego se registrará en el selector. Otra cuestión importante es cuando el programador designa la siguiente rutina disponible. Hay dos condiciones principales. La primera es cuando se generan ciertos eventos, como eventos de E / S o eventos de tiempo de espera. Aquí todo es bastante simple: suponga que realiza una llamada a thread.sleep() con un retraso de 200 milisegundos. Cuando caducan, el planificador tiene la oportunidad de ejecutar la siguiente rutina disponible. O aquí podemos hablar sobre algunos eventos de desempaque que se generan, por ejemplo, llamando a object.notify() u object.notifyAll() La segunda condición es cuando el usuario envía nuevas solicitudes, y creamos una rutina para atender estas solicitudes, y luego el programador asigna su implementación
Aquí también debe decir sobre el servicio que creamos, WispThreadExecutor.

En la pantalla se presenta un código de ejemplo, y vemos que se trata de un ExecutorService normal, creado de la misma manera. Los .execute() y submit() están disponibles para las tareas Runnable, pero el problema es que todas las tareas Runnable que pasan por el método submit() se ejecutarán en corutin, y no en el hilo. Esta solución es completamente transparente para aquellos que implementarán nuestra aplicación, podrán usar nuestra API para las rutinas.

Llegué a la última parte difícil de la publicación: cómo resolver el problema de la sincronización en las rutinas. Esta es una pregunta compleja, así que veámosla con un ejemplo simplificado. Aquí tenemos la corutina A ( test::foo ) y la corutina test::bar ). Primero, asignamos la ejecución de test:foo a la corutina wait() . Si no se hace nada, la llamada a wait() bloqueará el hilo actual. Como se puede ver en este volcado del subproceso, se producirá un punto muerto y no podremos programar la ejecución de la siguiente corutina.
¿Cómo resolver este problema? Hotspot proporciona tres tipos de cerraduras. El primero es el bloqueo rápido. Aquí, el propietario del bloqueo está determinado por la dirección en la pila. Como dije, cada una de nuestras corutinas tiene una pila separada. Por lo tanto, en el caso de bloqueo rápido, no necesitamos hacer ningún trabajo adicional. No hay soporte similar para el bloqueo sesgado en nuestro sistema. Lo probamos en nuestra producción y resultó que, en ausencia de un bloqueo sesgado, el rendimiento no disminuye. Para nosotros es bastante adecuado.
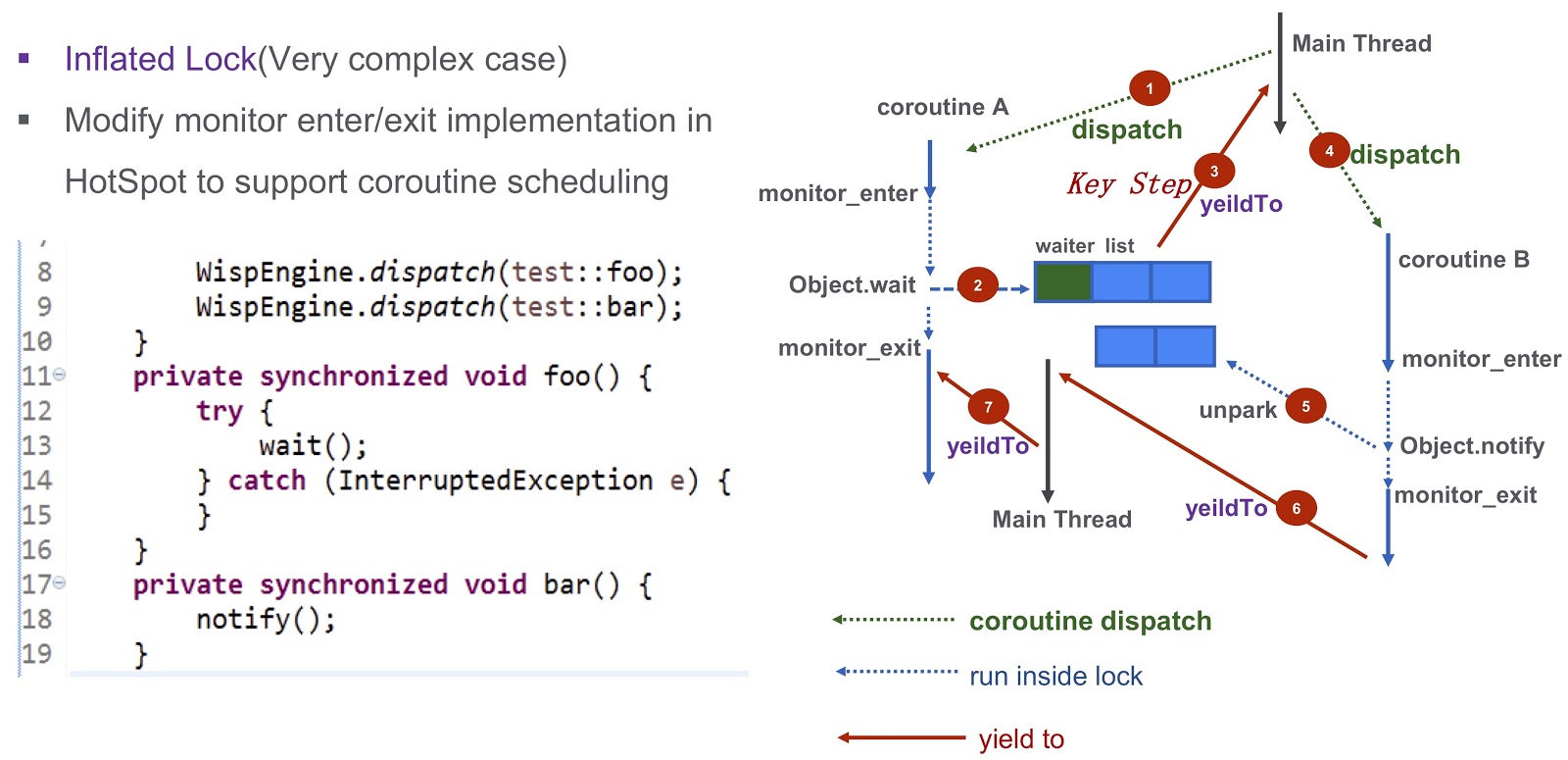
Hablemos de un caso más complicado: bloqueo inflado. Veamos nuevamente el ejemplo que cité anteriormente. Tenemos Corutin .foo() ) y Corutin B ( .bar() ). Primero, asignamos la ejecución de la rutina Object.wait , después de lo cual Object.wait en la lista de espera. Después de eso, damos un paso muy importante: generamos el evento yieldTo , que transfiere el control al hilo principal. A continuación, comenzamos Corutin B Llama a Object.notify y se unpark eventos de no unpark correspondientes. Eventualmente despertarán la corutina bar() , será posible transferir el control a la rutina
Discutamos el rendimiento ahora. Usamos corutinas en una de nuestras aplicaciones en línea de Carros. Sobre esta base, podemos comparar el trabajo de la corutina con el trabajo de un JDK normal.
Como puede ver, nos permiten reducir el consumo de tiempo del procesador en casi un 10%. Entiendo que la mayoría de ustedes probablemente no tengan la capacidad de realizar directamente cambios tan complejos en el código JDK. Pero la conclusión principal aquí, en mi opinión, es que si las pérdidas de rendimiento cuestan dinero y la cantidad resultante es lo suficientemente grande, puede intentar mejorar el rendimiento utilizando la biblioteca de rutina.
Jarmarm
Pasemos a nuestra otra herramienta: JWarmup. Es muy similar a otra herramienta, ReadyNow. Como sabemos, en Java hay un problema de calentamiento: el compilador en esta etapa requiere ciclos de CPU adicionales. Esto nos causó problemas, por ejemplo, se produjo un error TimeOut. Al escalar, estos problemas solo empeoran, y en nuestro caso estamos hablando de una aplicación muy compleja: más de 20 mil clases y más de 50 mil métodos.
Antes de comenzar a usar JWarmup, los propietarios de nuestra aplicación usaban datos simulados para calentar. En estos datos, el compilador JIT precompilado antes de recibir las solicitudes. Pero los datos simulados son diferentes de los reales; por lo tanto, no son representativos para el compilador. En algunos casos, se produjo una desoptimización inesperada, el rendimiento sufrió. La solución a este problema fue JWarmup. Tiene dos etapas principales de trabajo: grabación y compilación. Alibaba tiene dos tipos de entornos, beta y producción. Ambos reciben solicitudes reales de los usuarios, después de lo cual se implementa la misma versión de la aplicación en estos dos entornos. En el entorno beta, solo se recopilan datos de creación de perfiles, sobre la base de los cuales se realiza una compilación preliminar en la producción.

Veamos con más detalle qué tipo de información recopilamos. Necesitamos escribir exactamente qué clases se inicializan, qué métodos se compilan, luego estos datos se envían al registro en el disco duro, que es accesible para el compilador. El momento más difícil es la inicialización de las clases. . — Bar Foo.test() , foo.count . , .
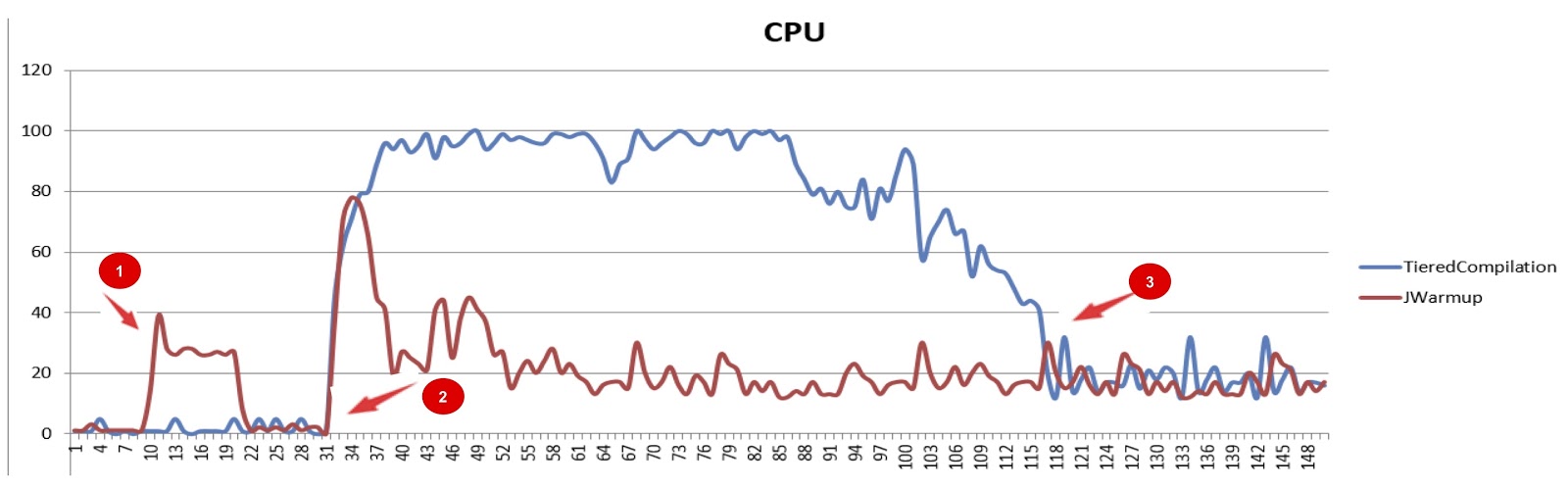
JWarmup (tiered compilation), . , — CPU. JWarmup , CPU, JDK. , , JDK. , , .
JWarmup. , , , groovy-, Java-, . . , , «null check elimination». . , JWarmup , JWarmup, .
, Alibaba.
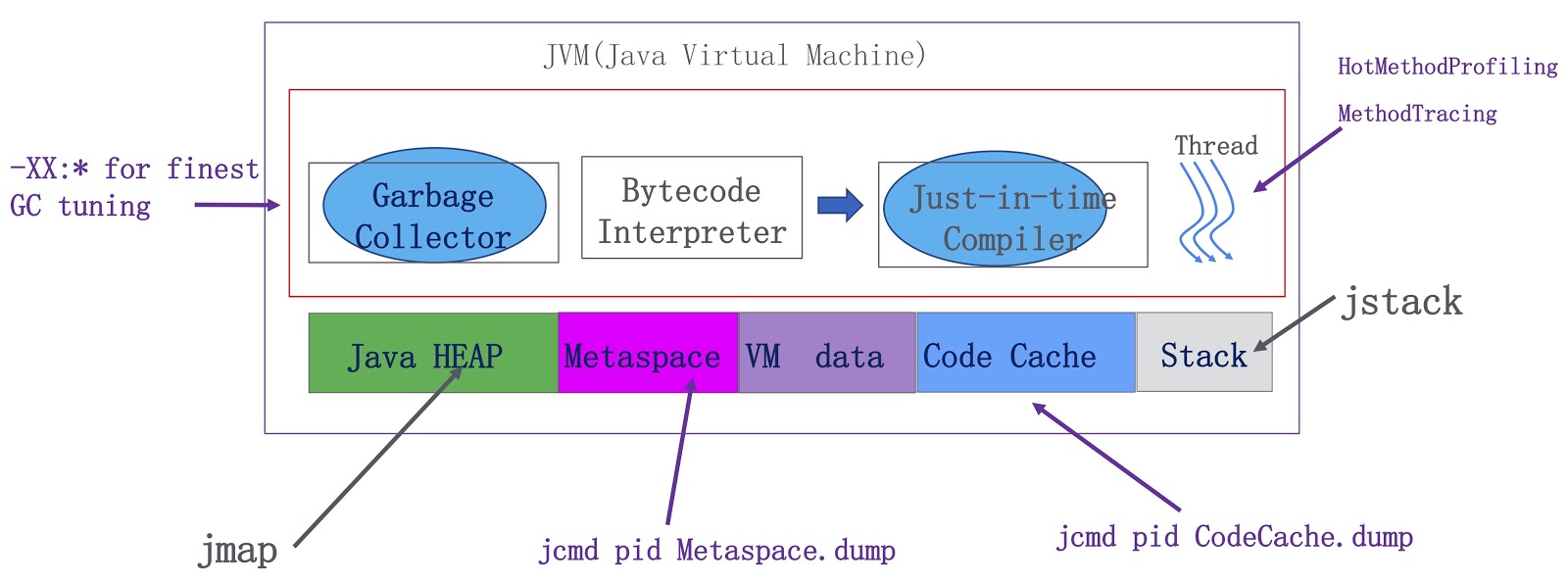
. JVM — , , . Java-, metaspace, VM ( VM) JIT-. OpenJDK. -, , . -, . HotMethodProfiling, , CPU. , , Honest Profiler , , , HotMethodProfiling. MethodTracing. , , . , metaspace . Java-, . metaspace , . Java.
, , ZProfiler.
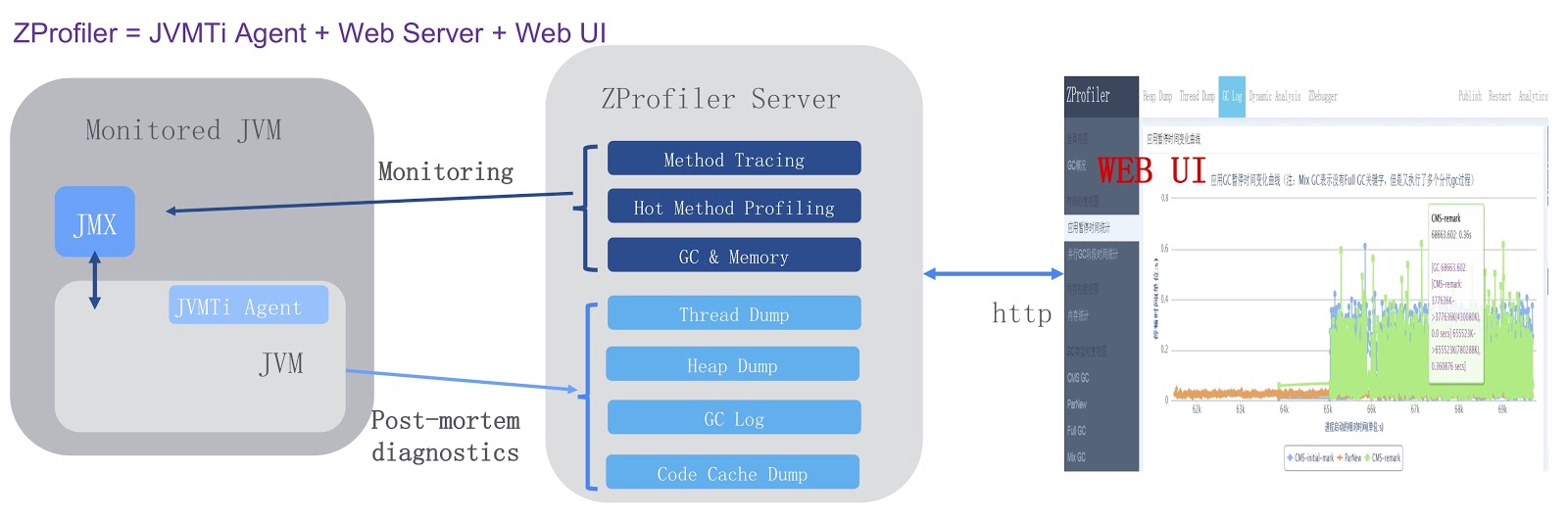
. JVMTi, JVM ( ). , ZProfiler Apache Tomcat. -. ZProfiler JVM. , ZProfiler -UI, . ZProfiler . -, UI JVM. -, ZProfiler post-mortem . , OutOfMemoryError, , JVM ZProfiler, . , , , Eclipse MAT.
. . JVM, GCIH, Alibaba JDK, JWarmup — , ReadyNow Zing JVM. , ZProfiler. , , OpenJDK. , , JWarmup OpenJDK. , OpenJDK Loom, Java. , .
. , , JPoint 2018 . 2019 , JPoint , 5-6 . , Rafael Winterhalter Sebastian Daschner. . , YouTube . JPoint!