 Publicado por Denis Tsyplakov , arquitecto de soluciones, DataArt
Publicado por Denis Tsyplakov , arquitecto de soluciones, DataArtEn DataArt, trabajo de dos maneras. En el primero, ayudo a las personas a reparar sistemas que están rotos de una forma u otra y por una variedad de razones. En el segundo, ayudo a diseñar nuevos sistemas para que no se rompan en el futuro o, para ser más realistas, romperlos fue más difícil.
Si no está haciendo algo fundamentalmente nuevo, por ejemplo, el primer motor de búsqueda en Internet del mundo o inteligencia artificial para controlar el lanzamiento de misiles nucleares, crear un buen diseño del sistema es bastante simple. Es suficiente tener en cuenta todos los requisitos, observar el diseño de sistemas similares y hacer lo mismo, sin cometer errores graves. Parece una simplificación excesiva del problema, pero recordemos que en el patio está el año 2019, y hay "recetas estándar" para el diseño del sistema para casi todo. Una empresa puede abordar tareas técnicas complejas, por ejemplo, procesar un millón de archivos PDF heterogéneos y extraer tablas de gastos, pero la arquitectura del sistema rara vez es muy original. Lo principal aquí es no cometer un error al determinar qué sistema estamos construyendo, y no perder la elección de las tecnologías.
Los errores típicos ocurren regularmente en el último párrafo, algunos de los cuales discutiré en un artículo.
¿Cuál es la dificultad de elegir una pila técnica? Agregar cualquier tecnología al proyecto lo hace más difícil y trae algún tipo de limitaciones. En consecuencia, agregar una nueva herramienta (marco, biblioteca) solo debe hacerse cuando esta herramienta es más útil que perjudicial. En las conversaciones con los miembros del equipo sobre la adición de bibliotecas y marcos, a menudo uso en broma el siguiente truco: “Si quieres agregar una nueva dependencia al proyecto, pones una caja de cerveza para el equipo. Si crees que esta dependencia de una caja de cerveza no vale la pena, no la agregues ”.
Supongamos que creamos una determinada aplicación, por ejemplo, en Java y agregamos la biblioteca TimeMagus al proyecto para manipular fechas (un ejemplo es ficticio). La biblioteca es excelente, nos proporciona muchas características que no están disponibles en la biblioteca de clases estándar. ¿Cómo puede ser dañina tal decisión? Veamos los posibles escenarios:
- No todos los desarrolladores conocen una biblioteca no estándar, el umbral de entrada para los nuevos desarrolladores será mayor. Aumenta la posibilidad de que un nuevo desarrollador cometa un error al manipular una fecha usando una biblioteca desconocida.
- El tamaño de la distribución está aumentando. Cuando el tamaño de la aplicación promedio en Spring Boot puede crecer fácilmente a 100 MB, esto no es en absoluto un poco. Vi casos en los que, por el bien de un método, una biblioteca de 30 MB se introdujo en el kit de distribución. Lo justificaron de esta manera: "Utilicé esta biblioteca en un proyecto anterior y hay un método conveniente allí".
- Dependiendo de la biblioteca, el tiempo de inicio puede aumentar significativamente.
- El desarrollador de la biblioteca puede abandonar su creación, luego la biblioteca comenzará a entrar en conflicto con la nueva versión de Java, o se detectará un error en ella (causado, por ejemplo, por el cambio de zonas horarias), y no se lanzará ningún parche.
- La licencia de la biblioteca en algún momento entrará en conflicto con la licencia de su producto (¿verifica las licencias de todos los productos que utiliza?).
- Jar hell: la biblioteca TimeMagus necesita la última versión de la biblioteca SuperCollections, luego de unos meses necesita conectar la biblioteca para la integración con una API de terceros, que no funciona con la última versión de SuperCollections, y solo funciona con la versión 2.x. No puede conectar una API. No hay otra biblioteca para trabajar con esta API.
Por otro lado, la biblioteca estándar nos proporciona herramientas convenientes para manipular fechas, y si no necesita mantener, por ejemplo, un calendario exótico o calcular el número de días desde hoy hasta "el segundo día de la tercera luna nueva en el año anterior del águila altísima", puede valer la pena abstenerse de usar una biblioteca de terceros. Incluso si es completamente maravilloso y en una escala de proyecto, le ahorrará hasta 50 líneas de código.
El ejemplo considerado es bastante simple, y creo que es fácil tomar una decisión. Pero hay una serie de tecnologías que están muy extendidas, para los oídos de todos, y su uso es obvio, lo que hace que la elección sea más difícil: realmente brindan serias ventajas para el desarrollador. Pero esto no siempre tiene que ser una ocasión para arrastrarlos a su proyecto. Veamos algunos de ellos.
Docker
Antes de la aparición de esta tecnología realmente genial, al implementar sistemas, había muchos problemas desagradables y complejos relacionados con el conflicto de versiones y las dependencias oscuras. Docker le permite empaquetar una instantánea del estado del sistema, pasarlo a producción y ejecutarlo allí. Esto permite evitar los conflictos mencionados, lo que, por supuesto, es genial.
Anteriormente, esto se hacía de una manera monstruosa, y algunas tareas no se resolvieron en absoluto. Por ejemplo, tiene una aplicación PHP que usa la biblioteca ImageMagick para trabajar con imágenes, su aplicación también necesita configuraciones específicas de php.ini y la aplicación en sí misma está alojada usando Apache httpd. Pero hay un problema: algunas rutinas regulares se implementan al ejecutar scripts Python desde cron, y la biblioteca utilizada por estos scripts entra en conflicto con las versiones de las bibliotecas utilizadas en su aplicación. Docker le permite empaquetar toda su aplicación, junto con la configuración, las bibliotecas y un servidor HTTP, en un contenedor que atiende solicitudes en el puerto 80, y las rutinas en otro contenedor. Todos juntos funcionarán perfectamente, y puedes olvidarte del conflicto de las bibliotecas.
¿Debo usar Docker para empacar cada aplicación? Mi opinión: no, no vale la pena. La imagen muestra una composición típica de una aplicación dockerizada implementada en AWS. Los rectángulos aquí indican las capas de aislamiento que tenemos.
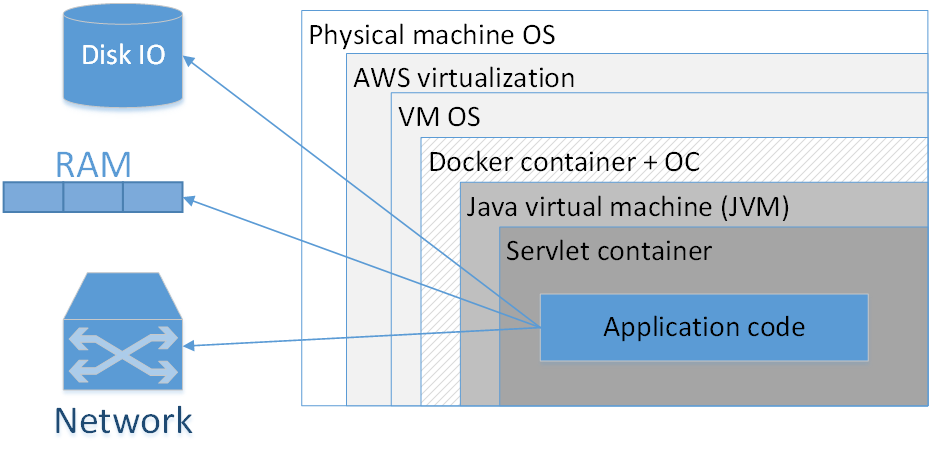
El rectángulo más grande es la máquina física. El siguiente es el sistema operativo de la máquina física. Luego, el virtualizador amazónico, luego el sistema operativo de la máquina virtual, luego el contenedor docker, seguido por el sistema operativo contenedor, JVM, luego el contenedor Servlet (si es una aplicación web), y el código de su aplicación ya está dentro de él. Es decir, ya vemos bastantes capas de aislamiento.
La situación se verá aún peor si miramos el acrónimo JVM. JVM es, curiosamente, la máquina virtual Java, es decir, siempre tenemos al menos una máquina virtual en Java. Agregar aquí un contenedor Docker adicional, en primer lugar, a menudo no brinda una ventaja tan notable, porque la JVM en sí misma ya nos aísla bastante bien del entorno externo y, en segundo lugar, no está exento de costos.
Tomé cifras de un estudio de IBM, si no se equivocó, hace dos años. Brevemente, si estamos hablando de operaciones de disco, uso de procesador o acceso a memoria, Docker casi no agrega una sobrecarga (literalmente una fracción de porcentaje), pero si estamos hablando de latencia de red, los retrasos son bastante notables. No son gigantes, pero dependiendo de la aplicación que tenga, pueden sorprenderle desagradablemente.
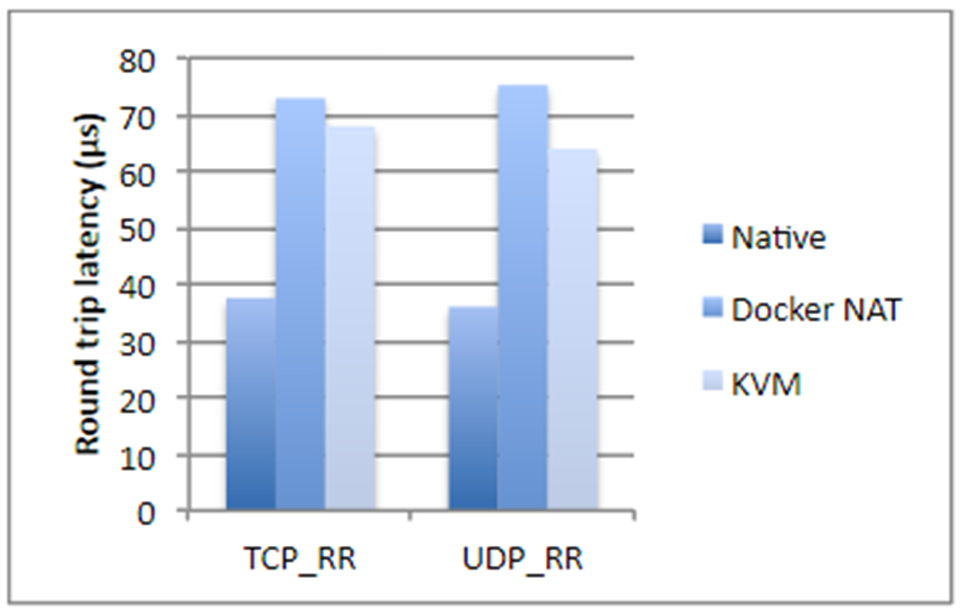
Además, Docker consume espacio de disco adicional, ocupa parte de la memoria y agrega tiempo de inicio. Los tres puntos no son críticos para la mayoría de los sistemas, generalmente hay mucho espacio en disco y memoria. El tiempo de lanzamiento, por regla general, tampoco es un problema crítico, lo principal es que se inicia la aplicación. Pero todavía hay situaciones en las que la memoria puede agotarse, y el tiempo de inicio total del sistema, que consta de veinte servicios dependientes, ya es bastante grande. Además, esto afecta el costo del alojamiento. Y si está involucrado en cualquier operación de alta frecuencia, Docker categóricamente no le conviene. En el caso general, es mejor no acoplar ninguna aplicación que sea sensible a los retrasos de la red de hasta 250–500 ms.
Además, con el acoplador, el análisis de problemas en los protocolos de red es notablemente complicado, no solo aumentan los retrasos, sino que todos los tiempos se vuelven diferentes.
¿Cuándo se necesita realmente Docker?
Cuando tenemos diferentes versiones del JRE, y sería bueno arrastrar el JRE. Hay momentos en los que necesita ejecutar una determinada versión de Java (no "el último Java 8", sino algo más específico). En este caso, es bueno empacar el JRE con la aplicación y ejecutarlo como un contenedor. En principio, está claro que se pueden colocar diferentes versiones de Java en el sistema de destino debido a JAVA_HOME, etc. Pero Docker en este sentido es mucho más conveniente, porque conoce la versión exacta del JRE, todo está empaquetado y con otro JRE la aplicación ni siquiera comenzará por accidente .
Docker también es necesario si tiene dependencias en algunas bibliotecas binarias, por ejemplo, para el procesamiento de imágenes. En este caso, podría ser una buena idea empacar todas las bibliotecas necesarias con la aplicación Java en sí.
El siguiente caso se refiere a un sistema que es un compuesto complejo de varios servicios escritos en varios idiomas. Tiene una pieza en Node.js, una parte en Java, una biblioteca en Go y, además, algún tipo de Machine Learning en Python. Todo este zoológico debe ser cuidadoso y cuidadosamente ajustado para enseñar a sus elementos a verse. Dependencias, rutas, direcciones IP: todo esto debe pintarse y plantearse cuidadosamente en producción. Por supuesto, en este caso, Docker te ayudará mucho. Además, hacerlo sin su ayuda es simplemente doloroso.
Docker puede proporcionar cierta conveniencia cuando necesita especificar muchos parámetros diferentes en la línea de comando para iniciar la aplicación. Por otro lado, los scripts de bash lo hacen muy bien, a menudo desde una sola línea. Decide cuál usar mejor.
Lo último que viene a la mente de inmediato es la situación en la que utiliza, por ejemplo, Kubernetes, y necesita realizar la orquestación del sistema, es decir, generar una cierta cantidad de microservicios diferentes que se escalan automáticamente de acuerdo con ciertas reglas.
En todos los demás casos, Spring Boot es suficiente para empaquetar todo en un solo archivo jar. Y, en principio, el tarro springboot es una buena metáfora para el contenedor Docker. Esto, por supuesto, no es lo mismo, pero en términos de facilidad de implementación, son realmente similares.
Kubernetes
¿Qué pasa si usamos Kubernetes? Para empezar, esta tecnología le permite implementar una gran cantidad de microservicios en diferentes máquinas, administrarlos, realizar escalas automáticas, etc. Sin embargo, hay muchas aplicaciones que le permiten controlar la orquestación, por ejemplo, Puppet, motor CF, SaltStack y otras. Kubernetes en sí mismo es ciertamente bueno, pero puede agregar una sobrecarga significativa, que no todos los proyectos están listos para vivir.
Mi herramienta favorita es Ansible, combinada con Terraform donde la necesitas. Ansible es una herramienta liviana declarativa bastante simple. No requiere la instalación de agentes especiales y tiene la sintaxis comprensible de los archivos de configuración. Si está familiarizado con Docker compose, verá inmediatamente secciones superpuestas. Y si usa Ansible, no hay necesidad de pre-rezerez: puede implementar sistemas utilizando medios más clásicos.
Está claro que de todos modos, estas son tecnologías diferentes, pero hay un conjunto de tareas en las que son intercambiables. Y un enfoque concienzudo del diseño requiere un análisis de qué tecnología es más adecuada para el sistema que se está desarrollando. Y cómo será mejor igualarlo en unos años.
Si la cantidad de servicios diferentes en su sistema es pequeña y su configuración es relativamente simple, por ejemplo, solo tiene un archivo jar, y no ve un crecimiento repentino y explosivo en la complejidad, es posible que necesite sobrevivir con los mecanismos de implementación clásicos.
Esto plantea la pregunta, "espera, ¿cómo es un archivo jar?". ¡El sistema debe constar de tantos microservicios atómicos como sea posible! Veamos quién y qué debería hacer el sistema con microservicios.
Microservicios
En primer lugar, los microservicios permiten lograr una mayor flexibilidad y escalabilidad, y permiten versiones flexibles de partes individuales del sistema. Supongamos que tenemos algún tipo de aplicación que ha estado en producción durante muchos años. La funcionalidad está creciendo, pero no podemos desarrollarla sin cesar de manera extensa. Por ejemplo
Tenemos una aplicación en Spring Boot 1 y Java 8. Una combinación maravillosa y estable. Pero el año es 2019, y nos guste o no, debemos avanzar hacia Spring Boot 2 y Java 12. Incluso la transición relativamente simple de un sistema grande a la nueva versión de Spring Boot puede ser muy laboriosa, pero se trata de saltar sobre el abismo de Java 8 a Java 12 No quiero hablar. Es decir, en teoría todo es simple: migramos, corregimos los problemas que han surgido, probamos todo y lo ejecutamos en producción. En la práctica, esto puede significar varios meses de trabajo que no aportan nuevas funcionalidades al negocio. Un pequeño paso a Java 12, como saben, tampoco funciona. Aquí la arquitectura de microservicios nos puede ayudar.
Podemos asignar un grupo compacto de funciones de nuestra aplicación a un servicio separado, migrar este grupo de funciones a una nueva pila técnica y ponerlo en producción en un tiempo relativamente corto. Repita el proceso pieza por pieza hasta que las viejas tecnologías se agoten por completo.
Además, los microservicios pueden proporcionar aislamiento de fallas, cuando un componente caído no arruina todo el sistema.
Los microservicios nos permiten tener una pila técnica flexible, es decir, no escribir todo monolíticamente en un idioma y una versión, y si es necesario, usar una pila técnica diferente para componentes individuales. Por supuesto, es mejor cuando usa una pila técnica uniforme, pero esto no siempre es posible y, en este caso, los microservicios pueden ayudar.
Los microservicios también permiten una forma técnica de resolver una serie de problemas de gestión. Por ejemplo, cuando su equipo grande consiste en grupos separados que trabajan en diferentes compañías (sentados en diferentes zonas horarias y hablando diferentes idiomas). Los microservicios ayudan a aislar esta diversidad organizacional mediante componentes que se desarrollarán por separado. Los problemas de una parte del equipo permanecerán dentro de un servicio y no se extenderán por toda la aplicación.
Pero los microservicios no son la única forma de resolver estos problemas. Por extraño que parezca, hace algunas décadas, para la mitad de ellos, a la gente se le ocurrieron clases y, un poco más tarde, componentes y el patrón de Inversión de Control.
Si observamos Spring, vemos que, de hecho, es una arquitectura de microservicios dentro de un proceso Java. Podemos declarar un componente que, en esencia, es un servicio. Tenemos la capacidad de realizar una búsqueda a través de @Autowired, hay herramientas para administrar el ciclo de vida de los componentes y la capacidad de configurar los componentes por separado de una docena de fuentes diferentes. En principio, obtenemos casi todo lo que tenemos con microservicios, solo dentro de un proceso, lo que reduce significativamente los costos. Una clase Java normal es el mismo contrato de API que también le permite aislar los detalles de implementación.
Estrictamente hablando, en el mundo de Java, los microservicios son más similares a OSGi: allí tenemos una copia casi exacta de todo lo que está en microservicios, excepto, además de la posibilidad de usar diferentes lenguajes de programación y ejecución de código en diferentes servidores. Pero incluso estando dentro de las capacidades de las clases Java, tenemos una herramienta bastante poderosa para resolver una gran cantidad de problemas de aislamiento.
Incluso en un escenario "gerencial" con aislamiento de equipo, podemos crear un repositorio separado que contenga un módulo Java separado con un contrato externo claro y un conjunto de pruebas. Esto reducirá significativamente la capacidad de un equipo para complicar inadvertidamente la vida de otro equipo.
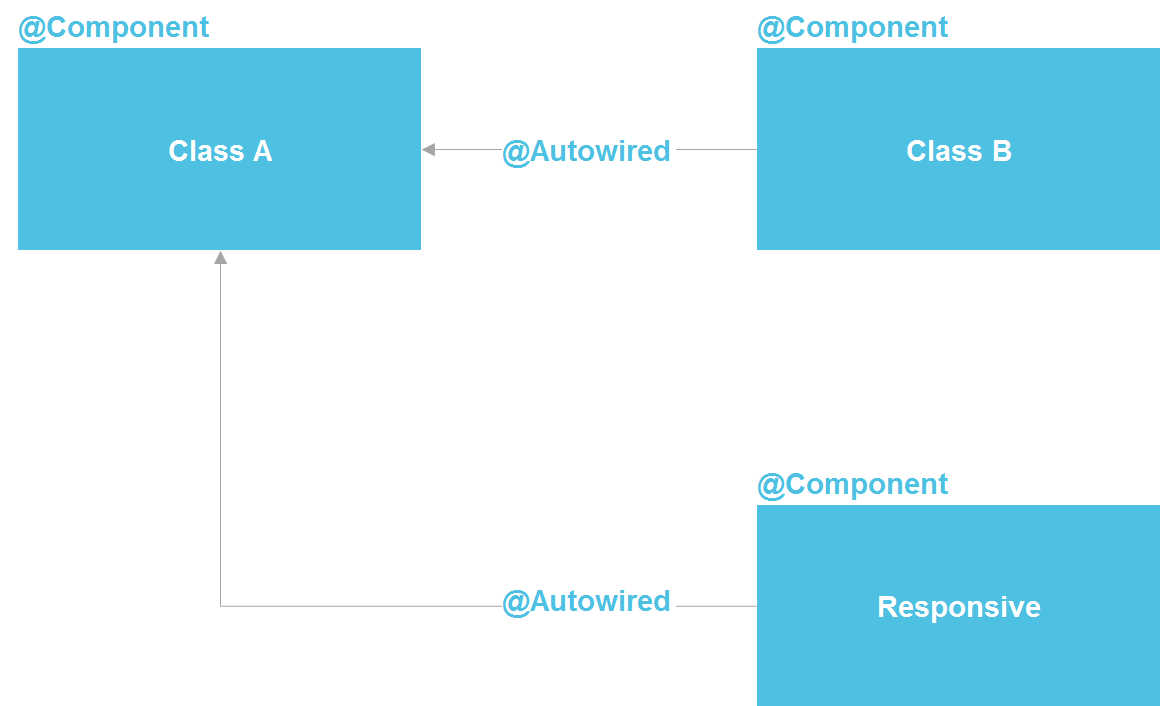
Repetidamente he escuchado que es imposible aislar los detalles de implementación sin microservicios. Pero puedo responder que toda la industria del software se trata solo de aislar la implementación. Para esto, la subrutina se inventó por primera vez (en los años 50 del siglo pasado), luego las funciones, los procedimientos, las clases y los microservicios posteriores. Pero el hecho de que los microservicios en esta serie aparecieron por última vez no los convierte en el punto más alto de desarrollo y no nos obliga a recurrir siempre a su ayuda.
Cuando se usan microservicios, también se debe tener en cuenta que las llamadas entre ellos toman algún tiempo. Esto a menudo no es importante, pero he visto un caso en el que el cliente necesitaba ajustar el tiempo de respuesta del sistema de 3 segundos. Era una obligación contractual conectarse a un sistema de terceros. La cadena de llamadas pasó a través de varias docenas de microservicios atómicos, y la sobrecarga de hacer llamadas HTTP no hizo posible que se redujera en 3 segundos. En general, debe comprender que cualquier división del código monolítico en una serie de servicios afecta inevitablemente el rendimiento general del sistema. Solo porque los datos no se pueden teletransportar entre procesos y servidores "de forma gratuita".
¿Cuándo se necesitan microservicios?
¿En qué casos una aplicación monolítica realmente necesita dividirse en varios microservicios? Primero, cuando hay un uso desequilibrado de recursos en áreas funcionales.
Por ejemplo, tenemos un grupo de llamadas API que realizan cálculos que requieren mucho tiempo de procesador. Y hay un grupo de llamadas API que se ejecutan muy rápidamente, pero que requieren una estructura de datos engorrosa de 64 GB para almacenarse en la memoria. Para el primer grupo, necesitamos un grupo de máquinas con un total de 32 procesadores, para la segunda máquina es suficiente (OK, que haya dos máquinas para tolerancia a fallas) con 64 GB de memoria. Si tenemos una aplicación monolítica, necesitaremos 64 GB de memoria en cada máquina, lo que aumenta el costo de cada máquina. Si estas funciones se dividen en dos servicios separados, podemos ahorrar recursos optimizando el servidor para una función específica. La configuración del servidor puede verse así:

Se necesitan microservicios y si necesitamos escalar seriamente alguna área funcional estrecha. Por ejemplo, cien métodos API se llaman 10 veces por segundo y, por ejemplo, cuatro métodos API se llaman 10 mil veces por segundo. A menudo no es necesario escalar todo el sistema, es decir, nosotros, por supuesto, podemos multiplicar los 100 métodos en muchos servidores, pero esto, por regla general, es notablemente más costoso y más complicado que escalar un grupo reducido de métodos. Podemos separar estas cuatro llamadas en un servicio separado y escalarlo solo a una gran cantidad de servidores.
También está claro que es posible que necesitemos un microservicio si hemos escrito un área funcional separada, por ejemplo, en Python. Debido a que alguna biblioteca (por ejemplo, para Machine Learning) resultó estar disponible solo en Python, y queremos separarla en un servicio separado. También tiene sentido hacer un microservicio si alguna parte del sistema es propensa a fallas. Es bueno, por supuesto, escribir código para que no haya fallas en principio, pero las razones pueden ser externas. Y nadie está a salvo de sus propios errores. En este caso, el error puede aislarse dentro de un proceso separado.
Si su aplicación no tiene nada de lo anterior y no se espera en el futuro previsible, lo más probable es que una aplicación monolítica se adapte mejor a usted. Lo único: recomiendo escribirlo para que las áreas funcionales que no estén relacionadas entre sí no dependan entre sí en el código. De modo que, si es necesario, las áreas funcionales que no están interconectadas se pueden separar entre sí. Sin embargo, esta es siempre una buena recomendación, ya que aumenta la consistencia interna y le enseña a formular cuidadosamente los contratos del módulo.
Arquitectura reactiva y programación reactiva.
Un enfoque reactivo es algo relativamente nuevo. El momento de su aparición puede considerarse el año 2014, cuando se publicó
The Reactive Manifesto . Dos años después de la publicación del manifiesto, era conocido por todos. Este es un enfoque verdaderamente revolucionario para el diseño de sistemas. , , , , .
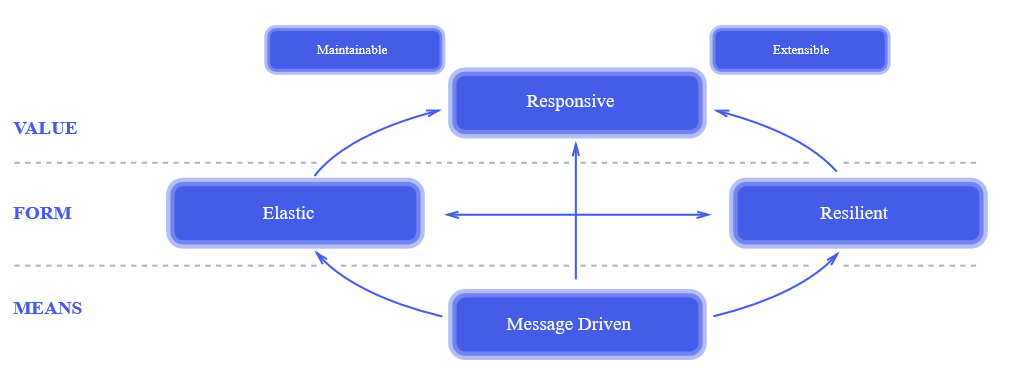
, . , , : « , !?» , , , , «». , 100% , , .
— , — . .
? , .
- , - . - -, , HTTP-. , . , . , , , .
? , HTTP- , ( callback) ( ) . , - ( , HTTP-) .
— . . . . 3 Ghz , , . . . , Java-, HTTP- — 5-10%. , , , , 100 50 $/ — $500 . , , .
, ? .
, . , , , , , , . , , . .
- . , JDBC ( . ADA, R2DBC, ). 90 % , . — HTTP- , . , .
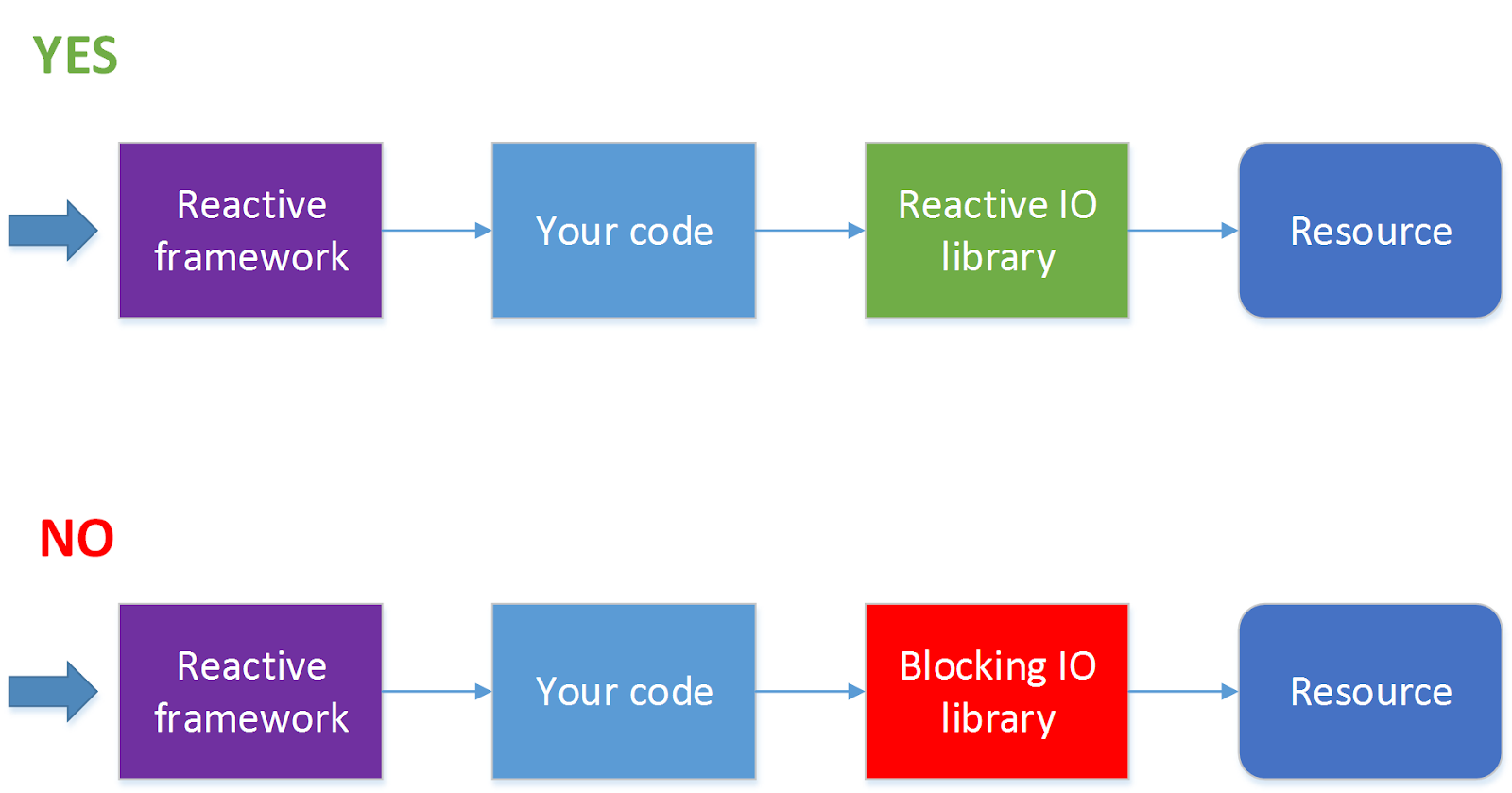
?
, , , ( ) . — - , . , , , HTTP.
, , , , , , .
. , « , » , , , . , , , 10 11 , , , .
Conclusión
, . , , , .