
The Guardian es uno de los periódicos británicos más grandes, fue fundado en 1821. Durante casi 200 años de existencia, el archivo ha acumulado una cantidad justa. Afortunadamente, no todo está almacenado en el sitio, solo en las últimas décadas. La base de datos, que los propios británicos llamaron la "fuente de la verdad" para todo el contenido en línea, contiene alrededor de 2,3 millones de elementos. Y en un momento, se dieron cuenta de la necesidad de migrar de Mongo a Postgres SQL: después de un caluroso día de julio de 2015, los procedimientos de conmutación por error se probaron severamente. ¡La migración tomó casi 3 años! ..
Hemos traducido
un artículo que describe cómo fue el proceso de migración y qué dificultades enfrentaron los administradores. El proceso es largo, pero el resumen es simple: llegar a la gran tarea, conciliar que los errores serán necesarios. Pero al final, 3 años después, los colegas británicos lograron celebrar el final de la migración. Y dormir
Primera parte: el comienzo
En Guardian, la mayor parte del contenido, incluidos artículos, blogs, galerías de fotos y videos, se produce dentro de nuestro propio CMS, Composer. Hasta hace poco, Composer trabajaba con Mongo DB basado en AWS. Esta base de datos era esencialmente una "fuente de verdad" para todo el contenido en línea de Guardian: alrededor de 2,3 millones de elementos. Y acabamos de completar la migración de Mongo a Postgres SQL.
Composer y sus bases de datos se alojaron originalmente en Guardian Cloud, un centro de datos en el sótano de nuestra oficina cerca de Kings Cross, con conmutación por error en otros lugares de Londres. Un
caluroso día de julio de 2015, nuestros procedimientos de conmutación por error fueron sometidos a una prueba bastante severa.
 Calor: bueno para bailar en la fuente, desastroso para el centro de datos. Foto: Sarah Lee / Guardian
Calor: bueno para bailar en la fuente, desastroso para el centro de datos. Foto: Sarah Lee / GuardianDesde entonces, la migración de Guardian a AWS se ha convertido en una cuestión de vida o muerte. Para migrar a la nube, decidimos comprar
OpsManager , el software de administración Mongo DB, y firmamos un contrato de soporte técnico de Mongo. Utilizamos OpsManager para administrar copias de seguridad, orquestar y monitorear nuestro grupo de bases de datos.
Debido a los requisitos editoriales, necesitábamos iniciar el clúster de base de datos y OpsManager en nuestra propia infraestructura en AWS, y no usar la solución administrada de Mongo. Tuvimos que sudar, ya que Mongo no proporcionó ninguna herramienta para una configuración fácil en AWS: diseñamos manualmente toda la infraestructura y escribimos
cientos de scripts Ruby para instalar agentes de monitoreo / automatización y orquestar nuevas instancias de bases de datos. Como resultado, tuvimos que organizar un equipo de programas educativos sobre gestión de bases de datos en el equipo, lo que esperábamos que asumiera OpsManager.
Desde la transición a AWS, hemos tenido dos fallas significativas debido a problemas en la base de datos, cada uno de los cuales no permitió la publicación en theguardian.com durante al menos una hora. En ambos casos, ni el personal de soporte técnico de OpsManager ni Mongo pudieron brindarnos asistencia suficiente, y nosotros mismos resolvimos el problema, en un caso, gracias a un
miembro de nuestro equipo que logró abordar la situación por teléfono desde el desierto en las afueras de Abu Dhabi.
Cada uno de los problemas problemáticos merece una publicación separada, pero aquí están los puntos generales:
- Preste mucha atención al tiempo: no bloquee el acceso a su VPC hasta el punto de que NTP deje de funcionar.
- Crear automáticamente índices de bases de datos al inicio de la aplicación es una mala idea.
- La administración de la base de datos es extremadamente importante y difícil, y no quisiéramos hacerlo nosotros mismos.
OpsManager no cumplió su promesa de una gestión simple de la base de datos. Por ejemplo, la administración real de OpsManager en sí, en particular, la actualización de OpsManager versión 1 a la versión 2, requirió mucho tiempo y conocimiento especial sobre nuestra configuración de OpsManager. Tampoco cumplió su promesa de "actualizaciones de un clic" debido a cambios en el esquema de autenticación entre diferentes versiones de Mongo DB. Perdimos al menos dos meses de ingenieros por año administrando la base de datos.
Todos estos problemas, combinados con la importante tarifa anual que pagamos por el contrato de soporte y OpsManager, nos obligaron a buscar una opción de base de datos alternativa con las siguientes características:
- Esfuerzo mínimo para administrar la base de datos.
- Cifrado en reposo.
- Una ruta de migración aceptable con Mongo.
Dado que todos nuestros otros servicios ejecutan AWS, la opción obvia es Dynamo, la base de datos NoSQL de Amazon. Desafortunadamente, en ese momento, Dynamo no admitía el cifrado en reposo. Después de esperar unos nueve meses para que se agregue esta característica, terminamos abandonando esta idea al decidir usar Postgres en AWS RDS.
"¡Pero Postgres no es un repositorio de documentos!" - estás indignado ... Bueno, sí, este no es un repositorio de base, pero tiene tablas similares a las columnas JSONB, con soporte para índices en los campos de la herramienta JSON Blob. Esperábamos que con JSONB pudiéramos migrar de Mongo a Postgres con cambios mínimos en nuestro modelo de datos. Además, si quisiéramos pasar a un modelo más relacional en el futuro, tendríamos esa oportunidad. Otra gran cosa sobre Postgres es lo bien que funcionó: para cada pregunta que teníamos, en la mayoría de los casos, la respuesta ya estaba dada en Stack Overflow.
En términos de rendimiento, estábamos seguros de que Postgres podría hacerlo: Composer es una herramienta exclusiva para grabar contenido (escribe en la base de datos cada vez que un periodista deja de imprimir), y generalmente el número de usuarios simultáneos no excede varios cientos, lo que no requiere el sistema super alta potencia!
Segunda parte: la migración de contenido de dos décadas pasó sin tiempo de inactividad
PlanLa mayoría de las migraciones de bases de datos implican las mismas acciones, y la nuestra no fue la excepción. Esto es lo que hicimos:
- Creó una nueva base de datos.
- Crearon una forma de escribir en una nueva base de datos (nueva API).
- Creamos un servidor proxy que envía tráfico tanto a la base de datos antigua como a la nueva, utilizando la antigua como la principal.
- Se movieron los registros de la base de datos anterior a la nueva.
- Hicieron de la nueva base de datos la principal.
- Se eliminó la base de datos anterior.
Dado que la base de datos a la que migramos proporcionó el funcionamiento de nuestro CMS, fue crítico que la migración causara la menor cantidad de problemas posible para nuestros periodistas. Al final, la noticia nunca termina.
Nueva APIEl trabajo en la nueva API basada en Postgres comenzó a fines de julio de 2017. Este fue el comienzo de nuestro viaje. Pero para entender cómo fue, primero debemos aclarar dónde comenzamos.
Nuestra arquitectura CMS simplificada era algo así: una base de datos, una API y varias aplicaciones relacionadas (como una interfaz de usuario). La pila fue construida y durante 4 años ahora opera sobre la base de
Scala ,
Scalatra Framework y
Angular.js .
Después de un análisis, llegamos a la conclusión de que antes de que podamos migrar el contenido existente, necesitamos una forma de contactar la nueva base de datos PostgreSQL, manteniendo operativa la antigua API. Después de todo, Mongo DB es nuestra "fuente de verdad". Ella nos sirvió como un salvavidas mientras experimentamos con la nueva API.
Esta es una de las razones por las cuales construir sobre la antigua API no era parte de nuestros planes. La separación de funciones en la API original fue mínima, y los métodos específicos necesarios para trabajar específicamente con Mongo DB se pueden encontrar incluso a nivel de controlador. Como resultado, la tarea de agregar otro tipo de base de datos a una API existente era demasiado arriesgada.
Fuimos al otro lado y duplicamos la antigua API. Así nació APIV2. Era una copia más o menos exacta de la antigua API relacionada con Mongo, e incluía los mismos puntos finales y funcionalidades. Utilizamos
doobie , la capa de características JDBC pura para Scala, agregamos
Docker para ejecutar y probar localmente, y mejoramos el registro de operaciones y el intercambio de responsabilidades. Se suponía que APIV2 era una versión rápida y moderna de la API.
A fines de agosto de 2017, implementamos una nueva API que utilizaba PostgreSQL como su base de datos. Pero eso fue solo el comienzo. Hay artículos en Mongo DB que se crearon por primera vez hace más de dos décadas, y todos tuvieron que migrar a la base de datos de Postgres.
La migracionDeberíamos poder editar cualquier artículo en el sitio, independientemente de cuándo se publicó, por lo tanto, todos los artículos existen en nuestra base de datos como una única "fuente de verdad".
Aunque todos los artículos viven en la
API de contenido de Guardian (CAPI) , que sirve a las aplicaciones y al sitio, fue extremadamente importante para nosotros migrar sin ningún problema técnico, ya que nuestra base de datos es nuestra "fuente de verdad". Si algo le sucediera al clúster Elasticsearch CAPI, lo volveríamos a indexar desde la base de datos de Composer.
Por lo tanto, antes de deshabilitar Mongo, tuvimos que asegurarnos de que la misma solicitud para la API que se ejecuta en Postgres y la API que se ejecuta en Mongo devolvería respuestas idénticas.
Para hacer esto, necesitábamos copiar todo el contenido en la nueva base de datos de Postgres. Esto se hizo usando un script que interactuaba directamente con las API antiguas y nuevas. La ventaja de este método fue que ambas API ya proporcionaban una interfaz bien probada para leer y escribir artículos dentro y fuera de las bases de datos, en lugar de escribir algo que accediera directamente a las bases de datos respectivas.
El orden básico de migración fue el siguiente:
- Obtén contenido de Mongo.
- Publica contenido en Postgres.
- Obtén contenido de Postgres.
- Asegúrese de que las respuestas de ellos sean idénticas.
La migración de la base de datos puede considerarse exitosa solo si los usuarios finales no se han dado cuenta de que esto ha sucedido, y un buen script de migración siempre será la clave de dicho éxito. Necesitábamos un script que pudiera:
- Ejecuta solicitudes HTTP.
- Asegúrese de que después de migrar parte del contenido, la respuesta de ambas API sea la misma.
- Deténgase cuando ocurra un error.
- Cree un registro detallado de operaciones para diagnosticar problemas.
- Reinicie después de un error desde el punto correcto.
Comenzamos usando
amonita . Le permite escribir scripts en el lenguaje Scala, que es el núcleo de nuestro equipo. Fue una buena oportunidad para experimentar con algo que no habíamos usado antes para ver si nos sería útil. Aunque Ammonite nos permitió usar un lenguaje familiar, encontramos varias deficiencias al trabajar en él. Intellij actualmente
admite Ammonite, pero no lo hizo durante nuestra migración, y perdimos la finalización automática y la importación automática. Además, durante un largo período de tiempo, el script Ammonite no se pudo ejecutar.
Finalmente, Ammonite no era la herramienta adecuada para este trabajo, y en su lugar utilizamos el proyecto sbt para hacer la migración. Esto nos permitió trabajar en un idioma en el que confiamos, así como realizar varias 'migraciones de prueba' antes de lanzarnos en el entorno de trabajo principal.
Inesperado fue lo útil que fue para verificar la versión de la API que se ejecuta en Postgres. Encontramos varios errores difíciles de encontrar y casos limitantes que no encontramos antes.
Avancemos rápidamente hasta enero de 2018, cuando es el momento de probar la migración completa en nuestro entorno de CODIGO previo.
Como la mayoría de nuestros sistemas, la única similitud entre CODE y PROD es la versión de la aplicación que se está lanzando. La infraestructura de AWS compatible con CODE fue mucho menos potente que PROD, simplemente porque obtiene mucha menos carga de trabajo.
Esperamos que la migración de prueba en el entorno CODE nos ayude a:
- Calcule cuánto tiempo llevará la migración en el entorno PROD.
- Evaluar cómo (si es que la migración) afecta la productividad.
Para obtener mediciones precisas de estos indicadores, tuvimos que poner los dos entornos en completa correspondencia mutua. Esto incluyó restaurar una copia de seguridad de Mongo DB de PROD a CODE y actualizar la infraestructura compatible con AWS.
La migración de poco más de 2 millones de elementos de datos debería haber llevado mucho más tiempo de lo que permitiría una jornada laboral estándar. Por lo tanto, ejecutamos el script en la
pantalla durante la noche.
Para medir el progreso de la migración, enviamos consultas estructuradas (usando tokens) a nuestra pila ELK (Elasticsearch, Logstash y Kibana). A partir de ahí, podríamos crear paneles detallados mediante el seguimiento de la cantidad de artículos transferidos con éxito, la cantidad de bloqueos y el progreso general. Además, todos los indicadores se mostraban en la pantalla grande para que todo el equipo pudiera ver los detalles.
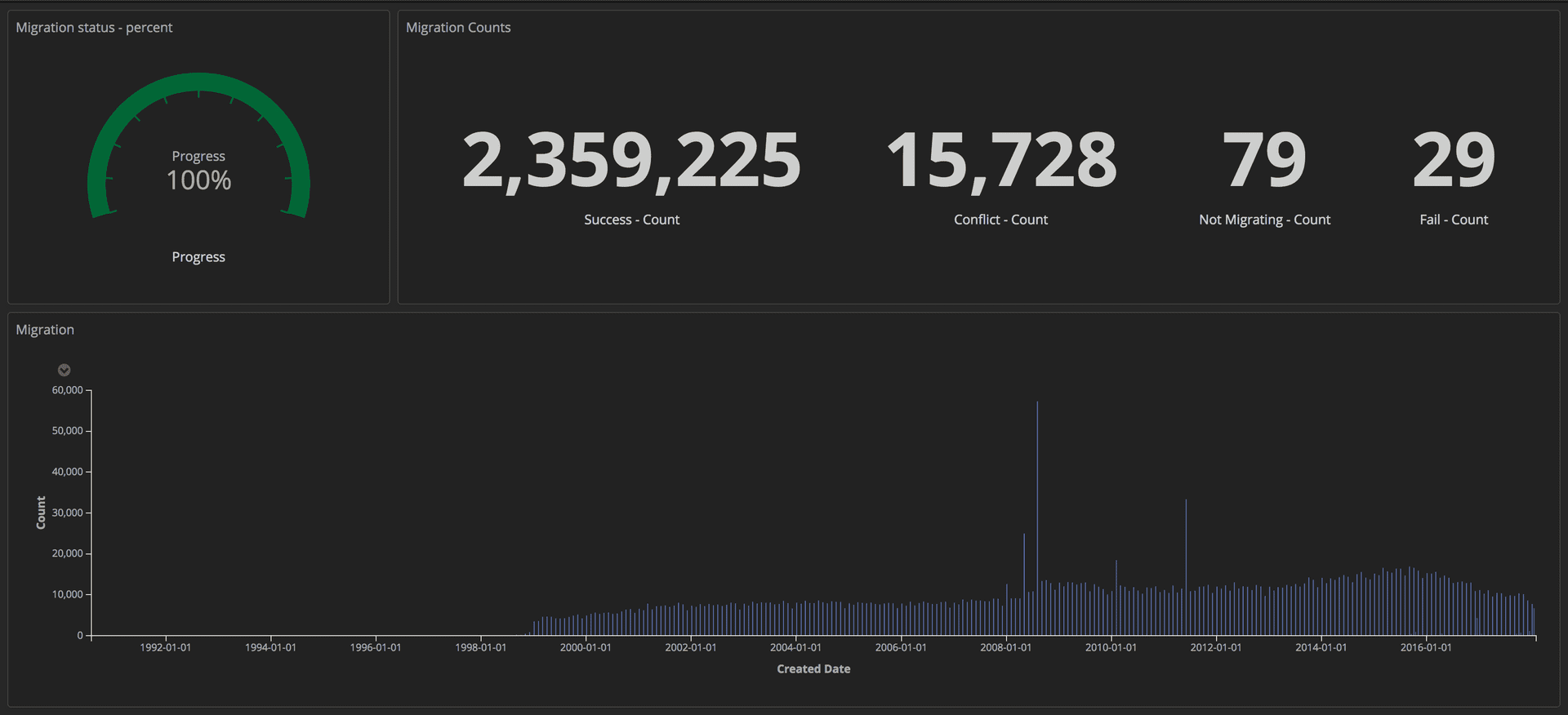 Panel de control que muestra el progreso de la migración: Herramientas editoriales / Guardian
Panel de control que muestra el progreso de la migración: Herramientas editoriales / GuardianUna vez que se completó la migración, verificamos una coincidencia para cada documento en Postgres y en Mongo.
Tercera parte: Proxies y lanzamiento en Prod
ProxiesAhora que se lanzó la nueva API que se ejecuta en Postgres, necesitábamos probarla con patrones reales de tráfico y acceso a datos para asegurarnos de su confiabilidad y estabilidad. Había dos formas posibles de hacer esto: actualizar cada cliente que accede a la API de Mongo para que acceda a ambas API; o ejecute un proxy que lo haga por nosotros. Escribimos proxies en Scala usando
Akka Streams .
El proxy era bastante simple:
- Reciba el tráfico del equilibrador de carga.
- Redirigir el tráfico a la API principal y viceversa.
- Reenvíe el mismo tráfico de forma asíncrona a una API adicional.
- Calcule las discrepancias entre las dos respuestas y regístrelas en un registro.
Inicialmente, el proxy registró muchas discrepancias, incluidas algunas diferencias de comportamiento difíciles de encontrar pero importantes en las dos API que debían corregirse.
Registro estructuradoEn Guardian, iniciamos sesión con la pila
ELK (Elasticsearch, Logstash y Kibana). Usar Kibana nos dio la oportunidad de visualizar la revista de la manera más conveniente para nosotros. Kibana usa
la sintaxis de consulta de Lucene , que es bastante fácil de aprender. Pero pronto nos dimos cuenta de que era imposible filtrar o agrupar las entradas de diario en la configuración actual. Por ejemplo, no pudimos filtrar los que se enviaron como resultado de solicitudes GET.
Decidimos enviar datos más estructurados a Kibana, no solo mensajes. Una entrada de registro contiene varios campos, por ejemplo, la marca de tiempo y el nombre de la pila o aplicación que envió la solicitud. Agregar nuevos campos es muy fácil. Estos campos estructurados se denominan marcadores y pueden implementarse utilizando la
biblioteca logstash-logback-encoder . Para cada solicitud, extrajimos información útil (por ejemplo, ruta, método, código de estado) y creamos un mapa con información adicional necesaria para el registro. Aquí hay un ejemplo:
import akka.http.scaladsl.model.HttpRequest import ch.qos.logback.classic.{Logger => LogbackLogger} import net.logstash.logback.marker.Markers import org.slf4j.{LoggerFactory, Logger => SLFLogger} import scala.collection.JavaConverters._ object Logging { val rootLogger: LogbackLogger = LoggerFactory.getLogger(SLFLogger.ROOT_LOGGER_NAME).asInstanceOf[LogbackLogger] private def setMarkers(request: HttpRequest) = { val markers = Map( "path" -> request.uri.path.toString(), "method" -> request.method.value ) Markers.appendEntries(markers.asJava) } def infoWithMarkers(message: String, akkaRequest: HttpRequest) = rootLogger.info(setMarkers(akkaRequest), message) }
Los campos adicionales en nuestros registros nos permitieron crear paneles informativos y agregar más contexto a las discrepancias, lo que nos ayudó a identificar algunas inconsistencias menores entre las dos API.
Replicación de tráfico y refactorización de proxyDespués de transferir el contenido a la base de datos CODE, obtuvimos una copia casi exacta de la base de datos PROD. La principal diferencia era que CODE no tenía tráfico. Para replicar el tráfico real al entorno CODE, utilizamos la herramienta de código abierto
GoReplay (en lo sucesivo, gor). Es muy fácil de instalar y flexible para personalizar según sus requisitos.
Dado que todo el tráfico que llegaba a nuestras API fue primero a servidores proxy, tenía sentido instalar gor en contenedores proxy. Vea a continuación cómo cargar gor en su contenedor y cómo comenzar a monitorear el tráfico en el puerto 80 y enviarlo a otro servidor.
wget https://github.com/buger/goreplay/releases/download/v0.16.0.2/gor_0.16.0_x64.tar.gz tar -xzf gor_0.16.0_x64.tar.gz gor sudo gor --input-raw :80 --output-http http://apiv2.code.co.uk
Durante un tiempo, todo funcionó bien, pero muy pronto hubo un mal funcionamiento cuando el proxy no estuvo disponible durante varios minutos. En el análisis, encontramos que los tres contenedores proxy se colgaban periódicamente al mismo tiempo. Al principio pensamos que el proxy estaba fallando porque gor estaba usando demasiados recursos. Tras un análisis más detallado de la consola de AWS, encontramos que los contenedores proxy se colgaban regularmente, pero no al mismo tiempo.
Antes de profundizar más en el problema, tratamos de encontrar una manera de ejecutar gor, pero esta vez sin carga adicional en el proxy. La solución vino de nuestra pila secundaria para Composer. Esta pila se usa solo en caso de emergencia, y nuestra
herramienta de monitoreo de trabajo la prueba constantemente. Esta vez, la reproducción del tráfico de esta pila a CODE a doble velocidad funcionó sin ningún problema.
Nuevos hallazgos han planteado muchas preguntas. El proxy se creó como una herramienta temporal, por lo que es posible que no se haya diseñado con tanto cuidado como otras aplicaciones. Además, fue construido usando
Akka Http , con el que ninguno de nuestro equipo estaba familiarizado. El código estaba desordenado y lleno de soluciones rápidas. Decidimos comenzar muchas refactorizaciones para mejorar la legibilidad. Esta vez utilizamos generadores for en lugar de la creciente lógica anidada que usamos antes. Y agregó aún más marcadores de registro.
Esperábamos poder evitar que los contenedores proxy se congelen si entramos en detalles de lo que estaba sucediendo dentro del sistema y simplificamos la lógica de su funcionamiento. Pero eso no funcionó. Después de dos semanas de intentar hacer que el proxy sea más confiable, nos sentimos atrapados. Era necesario tomar una decisión. Decidimos arriesgarnos y dejar el proxy tal como está, ya que es mejor dedicar tiempo a la migración en sí misma que tratar de arreglar un software que será innecesario en un mes. Pagamos esta solución con dos fallas más, casi dos minutos cada una, pero tenía que hacerse.
Avancemos rápidamente hasta marzo de 2018, cuando ya completamos la migración a CODE sin sacrificar el rendimiento de la API o la experiencia del cliente en CMS. Ahora podríamos comenzar a pensar en descartar proxies de CODE.
El primer paso fue cambiar las prioridades de la API para que el proxy interactuara primero con Postgres. Como dijimos anteriormente, esto se decidió por un cambio en la configuración. Sin embargo, hubo una dificultad.
Composer envía mensajes a la secuencia de Kinesis después de actualizar el documento. Solo se necesita una API para enviar mensajes para evitar la duplicación. Para esto, las API tienen un indicador en la configuración: verdadero para la API admitida por Mongo y falso para los Postgres admitidos. Simplemente cambiar el proxy para interactuar con Postgres primero no fue suficiente, ya que el mensaje no se enviaría a la transmisión de Kinesis hasta que la solicitud llegara a Mongo. Ha pasado demasiado tiempo
Para resolver este problema, creamos puntos finales HTTP para cambiar instantáneamente la configuración de todas las instancias del equilibrador de carga sobre la marcha. Esto nos permitió conectar la API principal muy rápidamente sin la necesidad de editar el archivo de configuración y volver a implementar. Además, esto puede automatizarse, lo que reduce la interacción humana y la probabilidad de errores.
Ahora todas las solicitudes se enviaron primero a Postgres, y API2 interactuó con Kinesis. Los reemplazos podrían hacerse permanentes con cambios de configuración y redistribución.
El siguiente paso fue eliminar completamente el proxy y obligar a los clientes a acceder exclusivamente a la API de Postgres. Como tenemos muchos clientes, no fue posible actualizar cada uno de ellos individualmente. Por lo tanto, elevamos esta tarea al nivel de DNS. Es decir, creamos un CNAME en DNS que primero apuntaba al proxy ELB y cambiaría para apuntar a la API ELB. Esto permitió realizar un solo cambio en lugar de actualizar cada cliente API individual.
Es hora de mover el PROD. Aunque daba un poco de miedo, bueno, porque este es el principal entorno de trabajo. El proceso fue relativamente simple, ya que todo se decidió cambiando la configuración. Además, a medida que se agregaba un marcador de etapa a los registros, era posible volver a perfilar tableros construidos previamente simplemente actualizando el filtro Kibana.
Desactivar proxies y Mongo DBDespués de 10 meses y 2.4 millones de artículos migrados, finalmente pudimos desactivar toda la infraestructura relacionada con Mongo. Pero primero, teníamos que hacer lo que todos estábamos esperando: matar el proxy.
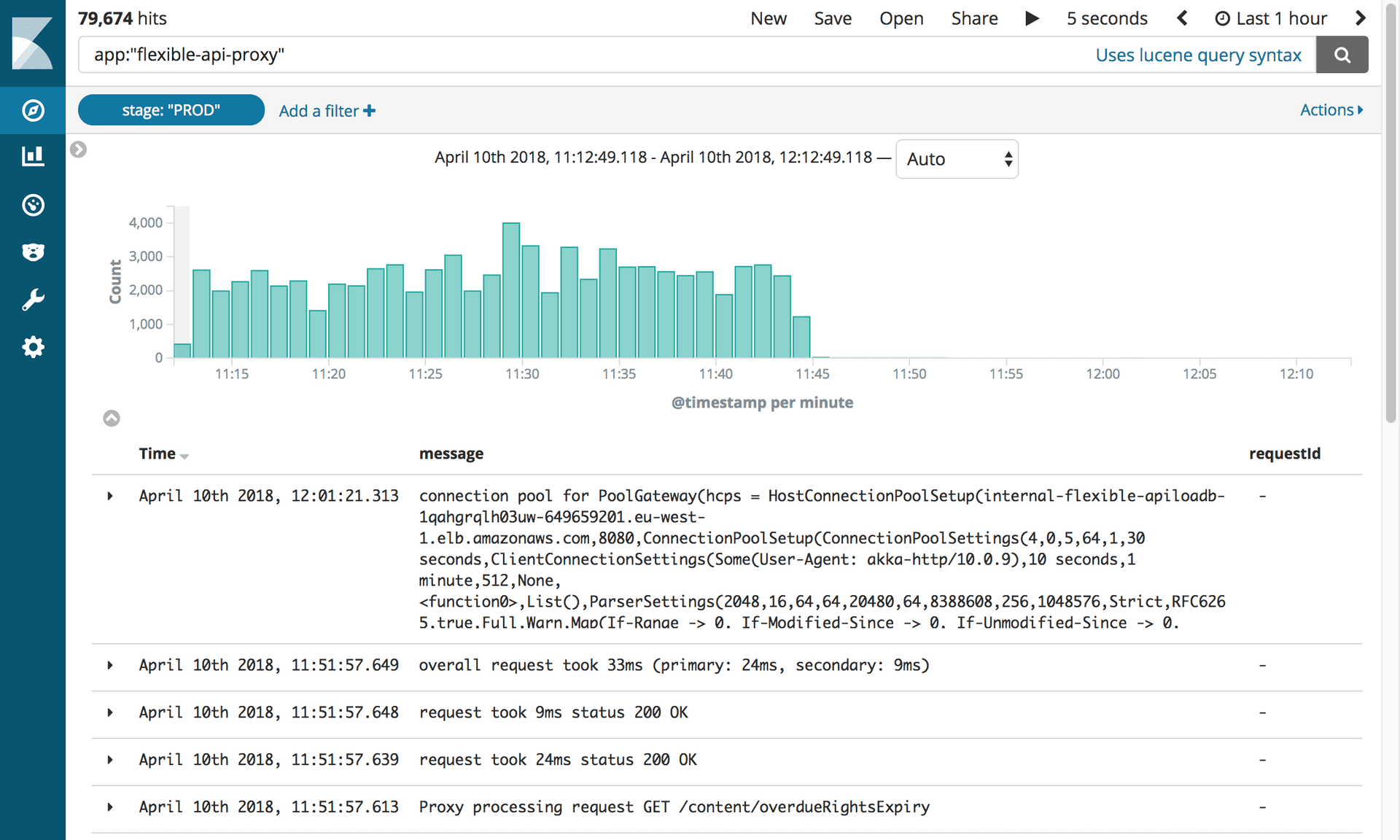 Registros que muestran la desactivación del Proxy API flexible. Fotografía: Editorial Tools / Guardian
Registros que muestran la desactivación del Proxy API flexible. Fotografía: Editorial Tools / Guardian¡Este pequeño software nos causó tantos problemas que anhelamos desconectarlo pronto! Todo lo que teníamos que hacer era actualizar el registro CNAME para apuntar directamente al equilibrador de carga APIV2.
Todo el equipo se reunió alrededor de una computadora. Era necesario hacer solo una pulsación de tecla. ¡Todos contuvieron el aliento! Silencio completo ... ¡Haz clic! El trabajo esta hecho. ¡Y nada voló! Todos exhalamos alegremente.
Sin embargo, eliminar la antigua API de Mongo DB estaba lleno de otra prueba. Desesperados por eliminar el código anterior, descubrimos que nuestras pruebas de integración nunca se ajustaron para usar la nueva API. Todo rápidamente se puso rojo. Afortunadamente, la mayoría de los problemas estaban relacionados con la configuración y los solucionamos fácilmente. Hubo varios problemas con las consultas PostgreSQL que fueron detectadas por las pruebas. Pensando en lo que podría hacerse para evitar este error, aprendimos una lección: al comenzar una gran tarea, reconcilie que habrá errores.
Después de eso, todo funcionó sin problemas. Desconectamos todas las instancias de Mongo de OpsManager y luego las desconectamos. Lo único que quedaba por hacer era celebrar. Y dormir