Soy ingeniero jefe de DevOps en Miro (ex-RealtimeBoard). Compartiré cómo nuestro equipo de DevOps resolvió el problema de las versiones diarias del servidor de una aplicación con estado monolítico y las hizo automáticas, invisibles para los usuarios y convenientes para sus propios desarrolladores.
Nuestra infraestructura
Nuestro equipo de desarrollo está compuesto por 60 personas que se dividen en equipos Scrum, entre los cuales también está el equipo DevOps. La mayoría de los comandos Scrum admiten la funcionalidad actual del producto y presentan nuevas características. La tarea de DevOps es crear y mantener una infraestructura que ayude a la aplicación a trabajar de manera rápida y confiable y permita a los equipos ofrecer rápidamente nuevas funcionalidades a los usuarios.

Nuestra aplicación es un tablero en línea sin fin. Consta de tres capas: un sitio, un cliente y un servidor en Java, que es una aplicación monolítica con estado. La aplicación mantiene una conexión de socket web constante con los clientes, y cada servidor mantiene en memoria un caché de placas abiertas.
Toda la infraestructura, más de 70 servidores, se encuentra en Amazon: más de 30 servidores con nuestra aplicación Java, servidores web, servidores de bases de datos, corredores y mucho más. Con el crecimiento de la funcionalidad, todo esto debe actualizarse regularmente, sin interrumpir el trabajo de los usuarios.
Actualizar el sitio y el cliente es simple: reemplazamos la versión anterior por una nueva, y la próxima vez que el usuario acceda a un nuevo sitio y a un nuevo cliente. Pero si hacemos esto cuando se lanza el servidor, tenemos tiempo de inactividad. Para nosotros, esto es inaceptable, porque el valor principal de nuestro producto es el trabajo conjunto de los usuarios en tiempo real.
Cómo se ve nuestro proceso de CI / CD
El proceso de CI / CD con nosotros es git commit, git push, luego ensamblaje automático, pruebas automáticas, implementación, lanzamiento y monitoreo.
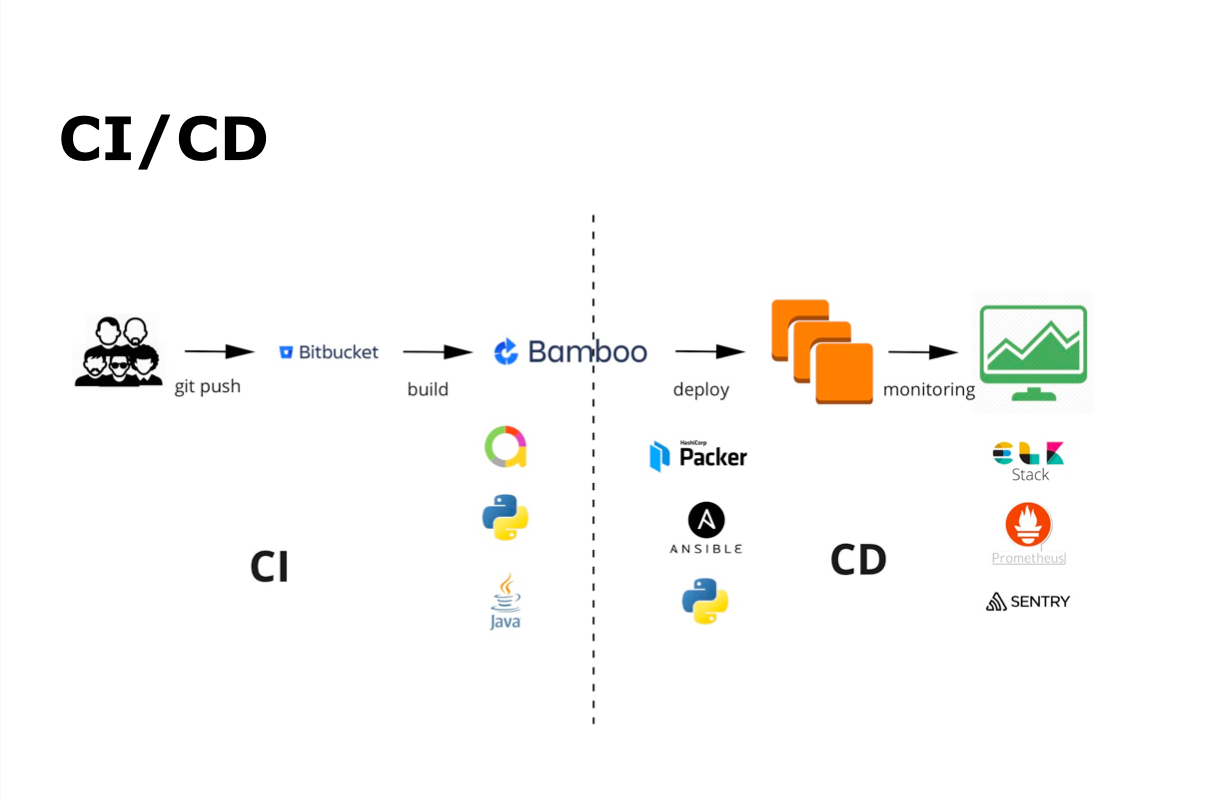
Para una integración continua, utilizamos Bamboo y Bitbucket. Para pruebas automáticas (Java y Python y Allure) para mostrar los resultados de las pruebas automáticas. Para entrega continua: Packer, Ansible y Python. Todo el monitoreo se realiza utilizando ELK Stack, Prometheus y Sentry.
Los desarrolladores escriben código, lo agregan al repositorio, después de lo cual se inician el ensamblaje automático y las pruebas automáticas. Al mismo tiempo, dentro del equipo reúne a otros desarrolladores y lleva a cabo la Revisión del Código. Cuando todos los procesos requeridos, incluidas las pruebas automáticas, se completan, el equipo mantiene la compilación en la rama principal, y la construcción de la rama principal comienza y se envía para pruebas automáticas. Todo el proceso es depurado y realizado por el equipo por sí solo.
Imagen AMI
En paralelo con la compilación de compilación y las pruebas, se inicia la compilación de la imagen AMI para Amazon. Para hacer esto, utilizamos Packer de HashiCorp, una gran herramienta de código abierto que le permite crear una imagen de una máquina virtual. Todos los parámetros se pasan a JSON con un conjunto de claves de configuración. El parámetro principal es constructores, que indica para qué proveedor estamos creando la imagen (en nuestro caso, para Amazon).
"builders": [{ "type": "amazon-ebs", "access_key": "{{user `aws_access_key`}}", "secret_key": "{{user `aws_secret_key`}}", "region": "{{user `aws_region`}}", "vpc_id": "{{user `aws_vpc`}}", "subnet_id": "{{user `aws_subnet`}}", "tags": { "releaseVersion": "{{user `release_version`}}" }, "instance_type": "t2.micro", "ssh_username": "ubuntu", "ami_name": "packer-board-ami_{{isotime \"2006-01-02_15-04\"}}" }],
Es importante que no solo creemos una imagen de una máquina virtual, sino que la configuremos de antemano usando Ansible: instale los paquetes necesarios y realice los ajustes de configuración para iniciar una aplicación Java.
"provisioners": [{ "type": "ansible", "playbook_file": "./playbook.yml", "user": "ubuntu", "host_alias": "default", "extra_arguments": ["--extra_vars=vars"], "ansible_env_vars": ["ANSIBLE_HOST_KEY_CHECKING=False", "ANSIBLE_NOCOLOR=True"] }]
Ansible-roles
Solíamos usar el libro de jugadas Ansible habitual, pero esto condujo a una gran cantidad de código repetitivo, que se hizo difícil de mantener actualizado. Cambiamos algo en un libro de jugadas, olvidamos hacerlo en otro y, como resultado, tuvimos problemas. Entonces empezamos a usar Ansible-roles. Los hicimos lo más versátiles posible para poder reutilizarlos en diferentes partes del proyecto y no sobrecargar el código en grandes piezas repetidas. Por ejemplo, utilizamos la función de supervisión para todos los tipos de servidores.
- name: Install all board dependencies hosts: all user: ubuntu become: yes roles: - java - nginx - board-application - ssl-certificates - monitoring
Desde el lado de los equipos Scrum, este proceso parece lo más simple posible: el equipo recibe notificaciones en Slack de que la construcción y la imagen AMI están ensambladas.
Pre-lanzamientos
Introdujimos versiones preliminares para entregar cambios de productos a los usuarios lo más rápido posible. De hecho, se trata de versiones canarias que le permiten probar de forma segura nuevas funciones en un pequeño porcentaje de usuarios.
¿Por qué los lanzamientos se llaman canarios? Anteriormente, los mineros, cuando descendían a la mina, se llevaban un canario con ellos. Si había gas en la mina, el canario murió y los mineros salieron rápidamente a la superficie. Así sucede con nosotros: si algo sale mal con el servidor, entonces el lanzamiento no está listo y podemos retroceder rápidamente y la mayoría de los usuarios no notarán nada.
Cómo comienza la liberación canaria:- El equipo de desarrollo de Bamboo hace clic en un botón -> se llama una aplicación Python que inicia el prelanzamiento.
- Crea una nueva instancia en Amazon a partir de una imagen AMI preparada con una nueva versión de la aplicación.
- La instancia se agrega a los grupos objetivo y equilibradores de carga necesarios.
- Con Ansible, se configura una configuración individual para cada instancia.
- Los usuarios están trabajando con la nueva versión de la aplicación Java.
En el lado de los comandos de Scrum, el proceso de lanzamiento previo al lanzamiento nuevamente parece lo más simple posible: el equipo recibe notificaciones en Slack de que el proceso ha comenzado, y después de 7 minutos el nuevo servidor ya está en funcionamiento. Además, la aplicación envía a Slack todo el registro de cambios de la versión.
Para que esta barrera de verificación de protección y confiabilidad funcione, los equipos de Scrum monitorean nuevos errores en Sentry. Esta es una aplicación de seguimiento de errores de código abierto en tiempo real. Sentry se integra a la perfección con Java y tiene conectores con logback y log2j. Cuando se inicia la aplicación, transferimos a Sentry la versión en la que se está ejecutando, y cuando se produce un error, vemos en qué versión de la aplicación se produjo. Esto ayuda a los equipos de Scrum a responder rápidamente a los errores y corregirlos rápidamente.
El prelanzamiento debería funcionar durante al menos 4 horas. Durante este tiempo, el equipo monitorea su trabajo y decide si lanzará la versión a todos los usuarios.
Varios equipos pueden lanzar simultáneamente sus lanzamientos . Para hacer esto, acuerdan entre ellos qué entra en el prelanzamiento y quién es responsable del lanzamiento final. Después de eso, los equipos combinan todos los cambios en un prelanzamiento o lanzan varios lanzamientos previos al mismo tiempo. Si todas las versiones preliminares son correctas, se lanzarán como una versión al día siguiente.
Lanzamientos
Hacemos un lanzamiento diario:
- Introducimos nuevos servidores para trabajar.
- Monitoreamos la actividad del usuario en nuevos servidores usando Prometheus.
- Acceso cercano para nuevos usuarios a servidores antiguos.
- Transferimos usuarios de servidores antiguos a nuevos.
- Apaga el antiguo servidor.
Todo está construido con las aplicaciones Bamboo y Python. La aplicación verifica la cantidad de servidores en ejecución y se prepara para lanzar la misma cantidad de servidores nuevos. Si no hay suficientes servidores, se crean a partir de la imagen AMI. Se implementa una nueva versión en ellos, se inicia una aplicación Java y los servidores se ponen en funcionamiento.
Al monitorear, la aplicación Python que usa la API Prometheus verifica el número de placas abiertas en los nuevos servidores. Cuando comprende que todo funciona correctamente, cierra el acceso a los servidores antiguos y transfiere usuarios a los nuevos.
import requests PROMETHEUS_URL = 'https://prometheus' def get_spaces_count(): boards = {} try: params = { 'query': 'rtb_spaces_count{instance=~"board.*"}' } response = requests.get(PROMETHEUS_URL, params=params) for metric in response.json()['data']['result']: boards[metric['metric']['instance']] = metric['value'][1] except requests.exceptions.RequestException as e: print('requests.exceptions.RequestException: {}'.format(e)) finally: return boards
El proceso de transferencia de usuarios entre servidores se muestra en Grafana. En la mitad izquierda del gráfico, los servidores que se ejecutan en la versión anterior se muestran, a la derecha, en la nueva. La intersección de gráficos es el momento de la transferencia de usuarios.

El equipo supervisa el lanzamiento de Slack. Después del lanzamiento, todo el registro de cambios se publica en un canal separado en Slack, y en Jira todas las tareas asociadas con este lanzamiento se cierran automáticamente.
¿Qué es la migración de usuarios?
Almacenamos el estado de la pizarra en la que trabajan los usuarios, en la memoria de la aplicación y guardamos constantemente todos los cambios en la base de datos. Para transferir la placa en el nivel de interacción del clúster, la cargamos en la memoria del nuevo servidor y le enviamos al cliente un comando para que se vuelva a conectar. En este punto, el cliente se desconecta del servidor anterior y se conecta al nuevo. Después de un par de segundos, los usuarios ven la inscripción: se restableció la conexión. Sin embargo, continúan trabajando y no notan ningún inconveniente.
Lo que aprendimos al hacer invisible la implementación
¿A qué hemos llegado después de una docena de iteraciones?
- El equipo scrum verifica su código por sí mismo.
- El equipo de scrum decide cuándo lanzar el prelanzamiento y llevar algunos de los cambios a los nuevos usuarios.
- Scrum-team decide si su lanzamiento está listo para todos los usuarios.
- Los usuarios continúan trabajando y no notan nada.
Esto no fue posible de inmediato, pisamos el mismo rastrillo muchas veces y llenamos muchos conos. Quiero compartir las lecciones que hemos recibido.
Primero, el proceso manual, y solo luego su automatización. Los primeros pasos no necesitan profundizar en la automatización, porque puede automatizar lo que al final no es útil.
Ansible es bueno, pero los roles de Ansible son mejores. Hicimos que nuestras funciones fueran lo más universales posibles: nos deshicimos del código repetitivo, por lo que solo tienen la funcionalidad que deberían tener. Esto le permite ahorrar significativamente tiempo reutilizando roles, que ya tenemos más de 50.
Reutilice el código en Python y divídalo en bibliotecas y módulos separados. Esto lo ayuda a navegar proyectos complejos y sumergir rápidamente a nuevas personas en ellos.
Próximos pasos
El proceso de implementación invisible aún no ha terminado. Estos son algunos de los siguientes pasos:
- Permitir que los equipos completen no solo prelanzamientos, sino todos los lanzamientos.
- Hacer retrocesos automáticos en caso de errores. Por ejemplo, una versión preliminar debería revertirse automáticamente si se detectan errores críticos en Sentry.
- Automatice completamente el lanzamiento en ausencia de errores. Si no hubo errores en el prelanzamiento, significa que puede implementarse automáticamente.
- Agregue escaneo automático de código para detectar posibles errores de seguridad.