Hola Habr! Después de haber descansado lo suficiente después de largas vacaciones, estamos nuevamente listos para hacerle el bien en todas las formas disponibles. Los colegas del departamento de TI siempre tienen algo que contar, y hoy compartimos con ustedes un informe de Alexander Prizov, administrador del sistema Yandex.Money, de la reunión de JavaJam.
Cómo creamos un flujo de retroalimentación para detectar versiones de problemas usando Graphite y Moira. Le diremos cómo recopilar y analizar métricas sobre la cantidad de errores en la aplicación.
- Hola a todos, mi nombre es Alexander Prizov, trabajo en el departamento de automatización de operaciones en Yandex.Money, y hoy les contaré cómo recopilamos, procesamos y analizamos información sobre nuestro sistema.
Probablemente se haya preguntado por qué el informe se llama The Second Way (se edita el nombre del informe de la reunión). Todo es bastante simple. En el corazón de DevOps hay una serie de principios que se dividen condicionalmente en tres grupos.
La primera es el principio del flujo. La segunda forma implica el principio de retroalimentación. La tercera forma es el aprendizaje continuo y la experimentación.
Como regla general, en términos del desarrollo y operación de productos de software, la retroalimentación significa telemetría, que recopilamos sobre nuestro sistema, y el caso más común es la recopilación y el procesamiento de métricas.
¿Por qué necesitamos estas métricas? Con la ayuda de las métricas, obtenemos comentarios del sistema y podemos saber en qué estado se encuentra nuestro sistema, si todo va bien, cómo nuestros cambios han afectado su funcionamiento y si es necesaria alguna intervención para resolver ciertos problemas.
¿Qué métricas recopilamos?
Recopilamos métricas de tres niveles.
El nivel comercial incluye indicadores que son interesantes desde el punto de vista de cualquier tarea comercial. Por ejemplo, podemos obtener respuestas a preguntas como cuántos usuarios hemos registrado, con qué frecuencia los usuarios inician sesión en nuestro sistema, cuántos usuarios activos tiene nuestra aplicación móvil.
El siguiente nivel es el nivel de aplicación . Los desarrolladores suelen ver las métricas de este nivel, ya que estos indicadores dan una respuesta a la pregunta de qué tan bien funciona nuestra aplicación, qué tan rápido procesa las solicitudes, ¿hay algún inconveniente en el rendimiento? Esto incluye el tiempo de respuesta, el número de solicitudes, la longitud de la cola y mucho más.
Y finalmente, el nivel de infraestructura . Todo está muy claro aquí. Usando estas métricas, podemos estimar la cantidad de recursos consumidos, cómo predecirlos e identificar problemas relacionados con la infraestructura.
Ahora, en pocas palabras, describiré cómo enviamos, procesamos y dónde almacenamos estas métricas. Junto a la aplicación, tenemos un recopilador de métricas. En nuestro caso, este es el servicio Heka, que escucha el puerto UDP y espera que se ingresen las métricas en el formato StatsD.
El formato de StatsD es el siguiente:

Es decir, determinamos el nombre de la métrica, indicamos el valor de esta métrica, es 1, 26, etc., e indicamos su tipo. En total, StatsD tiene alrededor de cuatro o cinco tipos. Si de repente le interesa, puede ver en detalle la descripción de estos tipos .
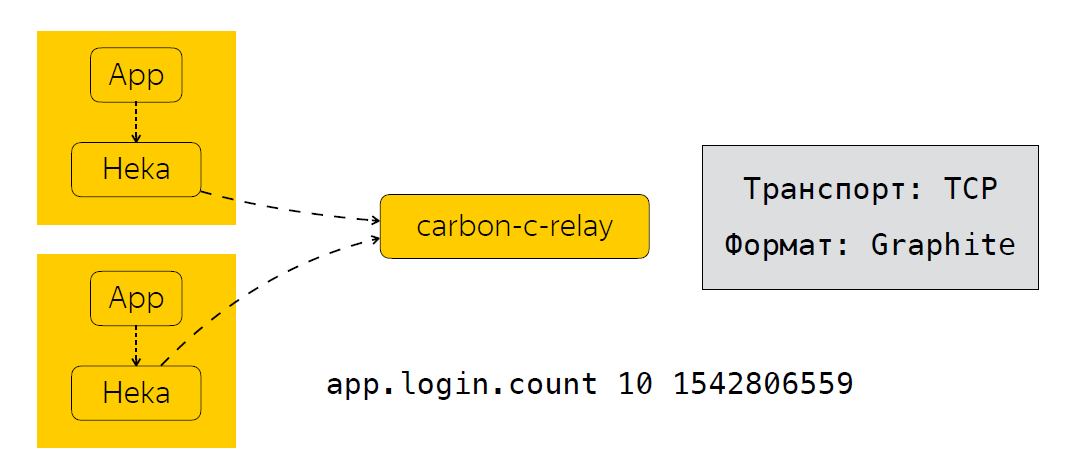
Una vez que la aplicación ha enviado los datos de Heka, las métricas se agregan durante un tiempo determinado. En nuestro caso, esto es 30 segundos, después de lo cual Heka envía datos a carbon-c-relay, que lleva a cabo la función de filtrado, enrutamiento, actualización de métricas, que, a su vez, envía métricas a nuestro almacenamiento, usamos clickhouse (sí, no se ralentiza ), así como en Moira. Si alguien no lo sabe, este es un servicio que le permite configurar ciertos desencadenantes para las métricas. Hablaré de Moira un poco más tarde. Entonces, analizamos qué métricas recopilamos, cómo las enviamos y procesamos. Y el siguiente paso lógico es el análisis de estas métricas.
¿Cómo analizamos las métricas?
Daré una situación real donde el análisis de las métricas nos dio resultados tangibles. Tome el proceso de lanzamiento como un ejemplo. En términos generales, incluye los siguientes pasos.
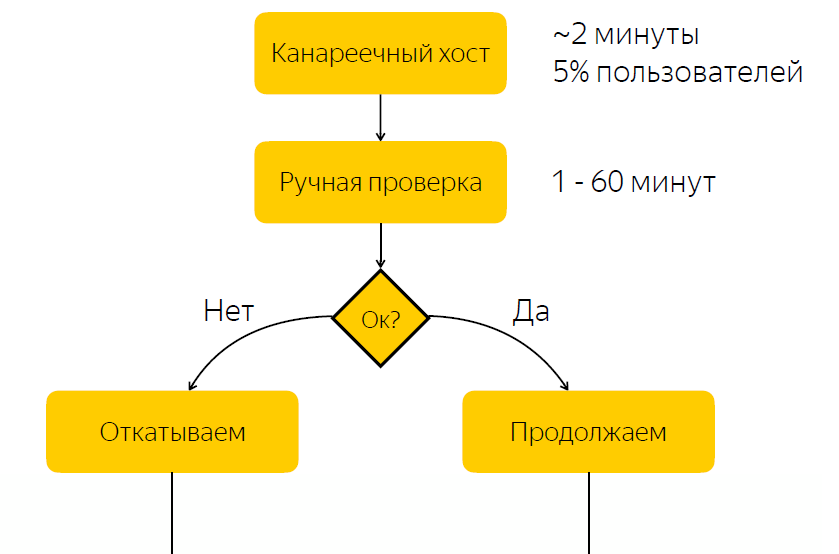
El lanzamiento se implementa en el host canario. Representa aproximadamente el cinco por ciento del tráfico de usuarios. Una vez completada la liberación al host canario, notificamos a la persona responsable de la liberación que debe verificar si todo está bien con la liberación. Y él debe reaccionar, reaccionar a este lanzamiento y hacer clic en el botón con la decisión de si este lanzamiento se debe implementar o no.
No es difícil adivinar que hay un inconveniente significativo en este esquema, a saber, que esperamos una reacción responsable. Si la persona responsable en este momento por alguna razón no puede responder rápidamente, entonces si tenemos una liberación con errores, entonces, por algún tiempo, el cinco por ciento del tráfico llega al nodo problemático. Si todo está en orden con el lanzamiento, simplemente pasamos tiempo esperando y, por lo tanto, ralentizamos el proceso de lanzamiento.
Sin errores: ralentizamos el proceso de lanzamiento
Con errores - afecto del usuario
Entendiendo este problema, decidimos averiguar si es posible automatizar el proceso de toma de decisiones sobre si un lanzamiento es problemático o no.
Por supuesto, recurrimos a nuestros desarrolladores para comprender cómo se realiza la verificación de la versión. Resultó, y parece bastante lógico, que el indicador principal de que la versión es problemática es el aumento en el número de errores en los registros de esta aplicación.
¿Qué hicieron los desarrolladores? Abrieron Kibana, hicieron una selección de acuerdo con el nivel de ERROR del bloque de la aplicación y, si vieron las listas, pensaron que algo iba mal con la aplicación. Vale la pena mencionar que los registros de nuestra aplicación se almacenan en Elastic, y parece que todo parece bastante simple. Tenemos los registros en Elastic, solo tenemos que crear una solicitud en Elastic, hacer una selección y comprender en función de estos datos si el lanzamiento es problemático o no. Pero esta decisión nos pareció no muy buena.
¿Por qué no elástico?
En primer lugar, nos preocupaba que no pudiéramos recibir rápidamente datos de Elastic. Existen tales casos, por ejemplo, durante las pruebas de estrés, cuando tenemos un gran flujo de datos y el clúster puede no hacer frente, y, en última instancia, hay un retraso en el envío de registros durante aproximadamente 10-15 minutos.
También hubo razones secundarias, por ejemplo, la falta de un nombre uniforme para los índices. Esto tuvo que ser tenido en cuenta en la herramienta de automatización. Y también las aplicaciones en diferentes plataformas podrían tener diferentes formatos de registro.
Pensamos, ¿por qué no tratar de hacer algún tipo de métrica sobre la base de la cual podamos decidir si el lanzamiento es problemático o no? Al mismo tiempo, no queríamos cargar a nuestros desarrolladores para que hicieran cambios en la base del código. Y, como nos parece, encontramos una solución bastante elegante al agregar un apéndice adicional a log4j.
Como se ve
<?xml version="1.0" encoding="UTF-8" ?> <Configuration status="warn" name="${sys:application.name}" > <Properties> <Property name="logsCountStatsDFormat">app_name.logs.%level:1|c</Property> </Properties> ... <Appenders> <Socket name="STATSD" host="127.0.0.1" port="8125" protocol="UDP"> <PatternLayout pattern="${logsCountStatsDFormat}"/> </Socket> </Appenders> <Loggers> <Root level="INFO"> <AppenderRef ref="STATSD"/> </Root> </Loggers> </Configuration>
Primero, determinamos el formato de la métrica que estamos enviando. A continuación se describe un apéndice adicional, que envía entradas en el formato que hemos especificado anteriormente al puerto 8125 a través de UDP, es decir, a Heka. ¿Qué nos da esto? Log4j para cada entrada en el registro envía una métrica de tipo Counter, con un nivel de registro dado ERROR, INFO, WARN, etc.
Sin embargo, nos dimos cuenta rápidamente de que enviar una métrica a cada entrada de registro puede crear una carga bastante significativa, y escribimos una biblioteca que agrega las métricas durante un cierto tiempo y envía la métrica ya agregada al servicio Heka. En realidad, estamos agregando este complemento a los registradores, y con este enfoque ahora sabemos cuánto escribe nuestra aplicación los registros para la nivelación, tenemos un nombre unificado para las métricas, independientemente de la plataforma que se utilice. Podemos entender fácilmente cuántos errores hay en el registro de la aplicación. Y finalmente, pudimos automatizar el proceso de toma de decisiones para un lanzamiento problemático.
Automatización
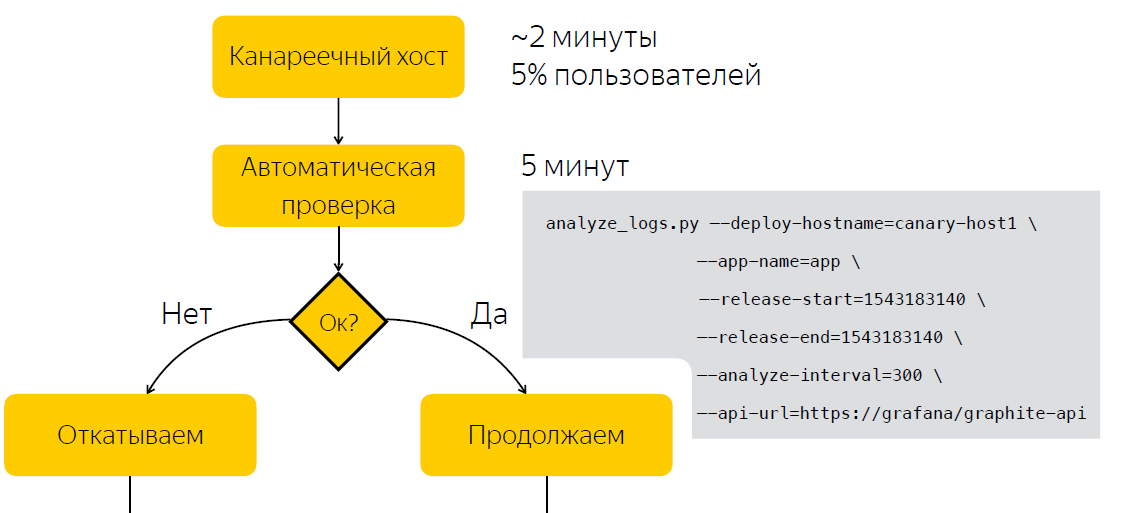
En lugar de verificar manualmente después del lanzamiento, esperamos cinco minutos, luego de lo cual recopilamos datos sobre la cantidad de entradas en los registros de la aplicación. Después de ejecutar el script, que, en base a dos ejemplos, antes del lanzamiento y después, toma una decisión si el lanzamiento es problemático. Por lo tanto, redujimos la cantidad de tiempo que dedicamos a tomar una decisión a cinco minutos.
Además del hecho de que la información sobre el número de errores en los registros es útil durante el lanzamiento, resultó ser una buena ventaja que también es útil durante la operación. Entonces, por ejemplo, podemos visualizar el número de errores en los registros en Grafana y registrar sobretensiones anómalas en los registros de la aplicación.
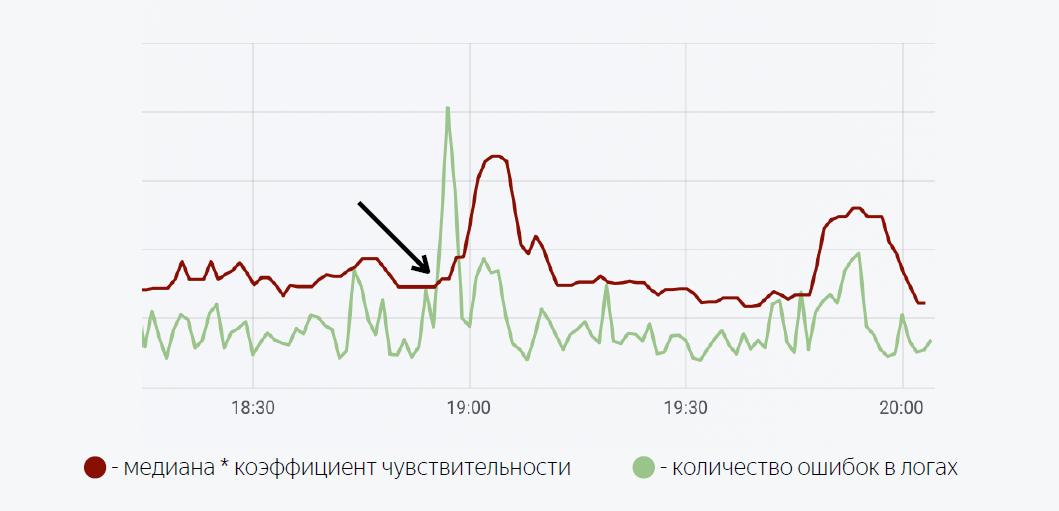
Aquí se usa un modelo matemático bastante simple. La línea verde es el número de errores en los registros de la aplicación. El rojo oscuro es la mediana del factor de sensibilidad. En el caso en que el número de errores en los registros cruza la mediana, se activa un activador, cuando activa una notificación a través de Moira.
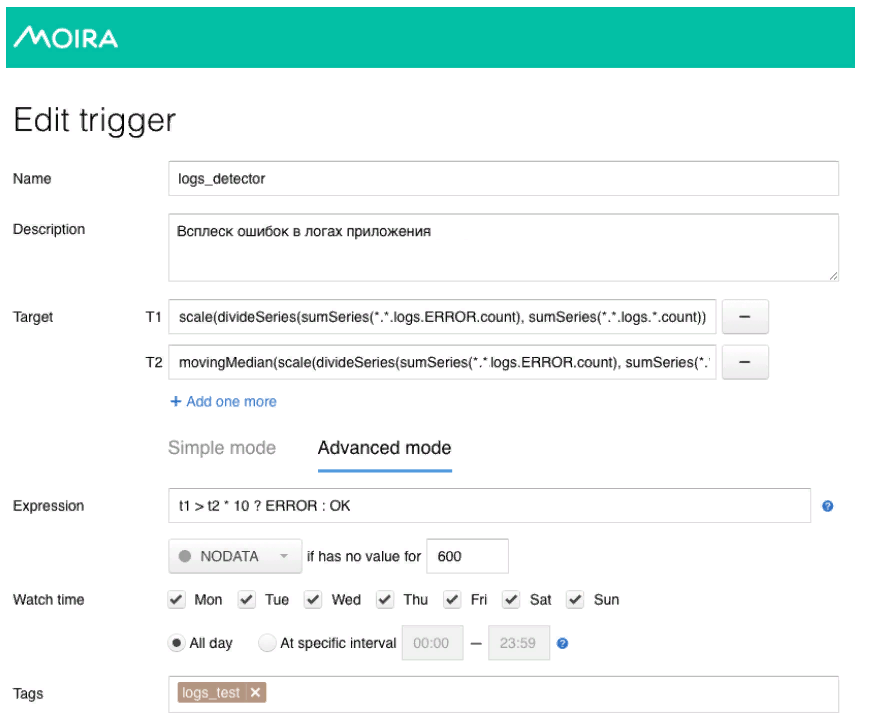
Como prometí, te contaré un poco sobre Moira, cómo funciona. Definimos las métricas objetivo que queremos observar. Este es el número de errores y la mediana móvil, así como las condiciones bajo las cuales funcionará este disparador, es decir, cuando el número de errores en los registros excede la mediana multiplicada por el coeficiente de sensibilidad. Cuando se activa el desencadenante, el desarrollador recibe una notificación de que se ha registrado un estallido anormal de errores en la aplicación, y se deben tomar algunas medidas.

¿Qué tenemos al final? Hemos desarrollado un mecanismo común para todas nuestras aplicaciones de back-end, que nos permite obtener información sobre el número de entradas en los registros de un nivel dado. Además, al utilizar métricas sobre el número de errores en los registros de la aplicación, pudimos automatizar el proceso de toma de decisiones sobre si el lanzamiento es problemático o no. También escribieron una biblioteca para log4j, que puede usar si desea probar el enfoque que describí. Enlace a la biblioteca a continuación.
Eso es probablemente todo para mí. Gracias
Enlaces utiles
Log4j-count-appender
Moira