En este artículo, presentamos
páginas , un esquema de administración de memoria muy común que también aplicamos en nuestro sistema operativo. El artículo explica por qué se necesita el aislamiento de la memoria, cómo funciona la
segmentación , qué
es la memoria virtual y cómo las páginas resuelven el problema de fragmentación. También exploramos el esquema de tablas de páginas multinivel en la arquitectura x86_64.
Este blog está publicado en
GitHub . Si tiene alguna pregunta o problema, abra la solicitud correspondiente allí.
Protección de la memoria
Una de las tareas principales del sistema operativo es aislar los programas entre sí. Por ejemplo, un navegador no debe interferir con un editor de texto. Existen varios enfoques según el hardware y la implementación del sistema operativo.
Por ejemplo, algunos procesadores ARM Cortex-M (en sistemas integrados) tienen
una unidad de protección de memoria (MPU) que define un pequeño número (por ejemplo, 8) de áreas de memoria con diferentes permisos de acceso (por ejemplo, sin acceso, solo lectura, lectura y registros). Cada vez que se accede a la memoria, la MPU se asegura de que la dirección esté en el área con los permisos correctos, de lo contrario arroja una excepción. Al cambiar el alcance y los permisos de acceso, el sistema operativo garantiza que cada proceso tenga acceso solo a su memoria para aislar los procesos entre sí.
En x86, se admiten dos enfoques diferentes para proteger la memoria:
segmentación y
paginación .
Segmentación
La segmentación se implementó en 1978, inicialmente para aumentar la cantidad de memoria direccionable. En ese momento, la CPU solo admitía direcciones de 16 bits, lo que limitaba la cantidad de memoria direccionable a 64 KB. Para aumentar este volumen, se introdujeron registros de segmento adicionales, cada uno de los cuales contiene una dirección de desplazamiento. La CPU agrega automáticamente este desplazamiento en cada acceso a la memoria, dirigiendo así hasta 1 MB de memoria.
La CPU selecciona automáticamente un registro de segmento según el tipo de acceso a la memoria: el registro de segmento de código
CS se usa para recibir instrucciones, y el registro de segmento de pila
SS se usa para operaciones de pila (push / pop). Otras instrucciones utilizan el registro de segmento de datos
DS o el registro de segmento
ES opcional. Más tarde, se agregaron dos registros de segmento adicionales
FS y
GS para uso gratuito.
En la primera versión de la segmentación, los registros contenían directamente el desplazamiento y no se realizó el control de acceso. Con la llegada del
modo protegido, el mecanismo ha cambiado. Cuando la CPU funciona en este modo, los descriptores de segmento almacenan el índice en una tabla de descriptores locales o globales, que además de la dirección de desplazamiento contiene el tamaño del segmento y los permisos de acceso. Al cargar tablas de descriptores globales / locales separadas para cada proceso, el sistema operativo puede aislar los procesos entre sí.
Al cambiar las direcciones de memoria antes del acceso real, la segmentación implementó un método que ahora se usa en casi todas partes: es
la memoria virtual .
Memoria virtual
La idea de la memoria virtual es abstraer las direcciones de memoria de un dispositivo físico. En lugar de acceder directamente al dispositivo de almacenamiento, primero se realiza un paso de conversión. En el caso de la segmentación, la dirección de desplazamiento del segmento activo se agrega en la etapa de traducción. Imagine un programa que accede a la dirección de memoria
0x1234000 en un segmento con un desplazamiento de
0x1111000 : en realidad, la dirección va a
0x2345000 .
Para distinguir entre dos tipos de direcciones, las direcciones antes de la conversión se llaman
virtuales y las direcciones después de la conversión se llaman
físicas . Hay una diferencia importante entre ellos: las direcciones físicas son únicas y siempre se refieren a la misma ubicación única en la memoria. Las direcciones virtuales, por otro lado, dependen de la función de traducción. Dos direcciones virtuales diferentes pueden referirse a la misma dirección física. Además, las direcciones virtuales idénticas pueden referirse a diferentes direcciones físicas después de la conversión.
Un ejemplo del uso útil de esta propiedad es el lanzamiento paralelo del mismo programa dos veces:
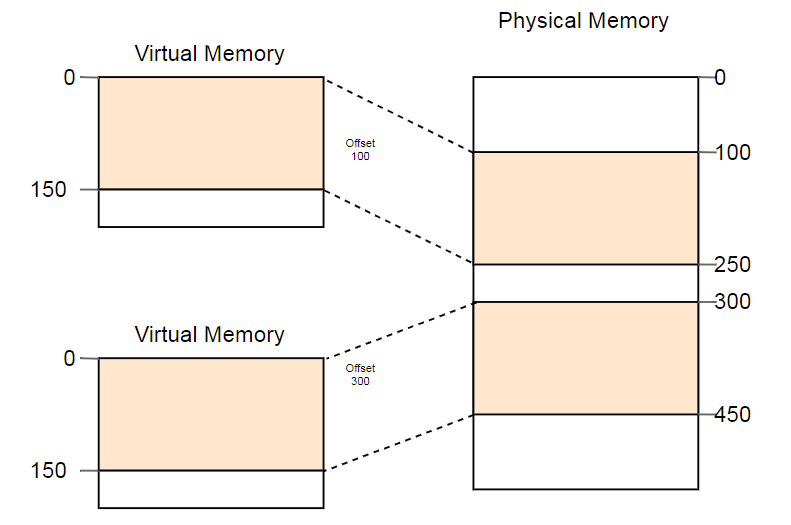
Aquí, el mismo programa se ejecuta dos veces, pero con diferentes funciones de conversión. La primera instancia tiene un desplazamiento de segmento de 100, por lo que sus direcciones virtuales 0-150 se convierten en direcciones físicas 100-250. La segunda instancia tiene un desplazamiento de 300, que traduce las direcciones virtuales 0-150 en direcciones físicas 300-450. Esto permite que ambos programas ejecuten el mismo código y usen las mismas direcciones virtuales sin interferir entre sí.
Otra ventaja es que ahora los programas se pueden colocar en lugares arbitrarios en la memoria física. Por lo tanto, el sistema operativo utiliza la cantidad total de memoria disponible sin la necesidad de volver a compilar programas.
Fragmentación
La diferencia entre las direcciones virtuales y físicas es un logro real de la segmentación. Pero hay un problema. Imagine que queremos ejecutar la tercera copia del programa que vimos arriba:
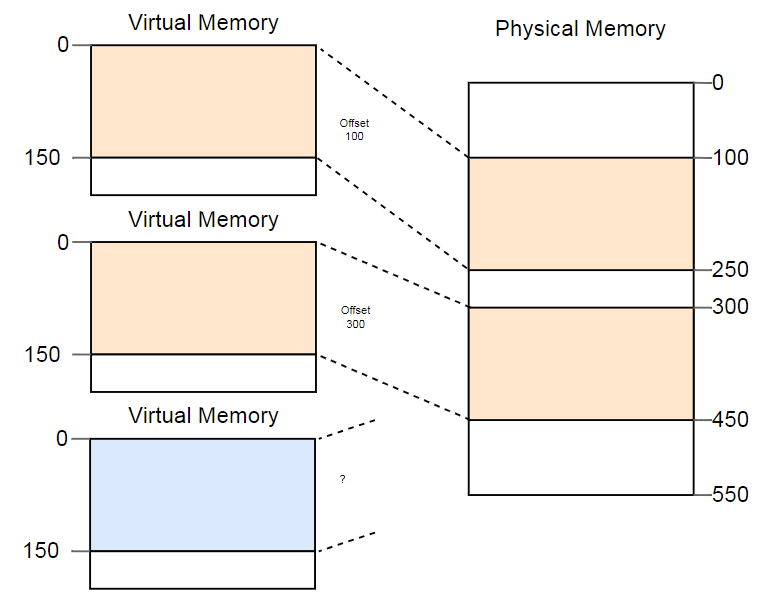
Aunque hay más que suficiente espacio en la memoria física, la tercera copia no cabe en ningún lado. El problema es que necesita un fragmento
continuo de memoria y no podemos usar secciones libres separadas.
Una forma de combatir la fragmentación es pausar la ejecución del programa, acercar las partes usadas de la memoria, actualizar la conversión y luego reanudar la ejecución:
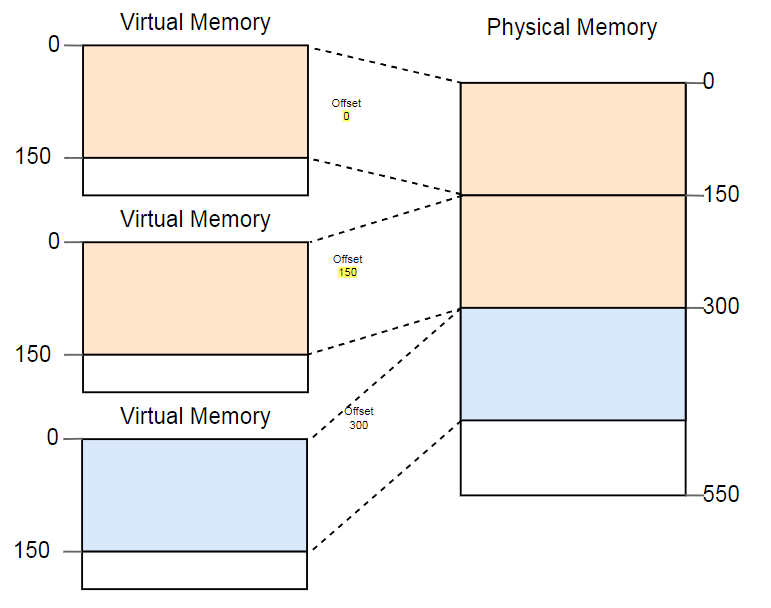
Ahora hay suficiente espacio para lanzar la tercera instancia.
La desventaja de esta desfragmentación es la necesidad de copiar grandes cantidades de memoria, lo que reduce el rendimiento. Este procedimiento debe realizarse regularmente hasta que la memoria se haya fragmentado demasiado. El rendimiento se vuelve impredecible, los programas se detienen en cualquier momento y pueden dejar de responder.
La fragmentación es una de las razones por las cuales la segmentación no se usa en la mayoría de los sistemas. De hecho, ya no es compatible incluso en modo de 64 bits en x86. En lugar de segmentación, se utilizan páginas que eliminan completamente el problema de la fragmentación.
Organización de la página de memoria
La idea es dividir el espacio de la memoria virtual y física en pequeños bloques de un tamaño fijo. Los bloques de memoria virtual se denominan páginas, y los bloques de espacio de direcciones físicas se denominan cuadros. Cada página se asigna individualmente a un marco, lo que le permite dividir grandes áreas de memoria entre marcos físicos no adyacentes.
La ventaja se vuelve obvia si repite el ejemplo con un espacio de memoria fragmentado, pero esta vez usando páginas en lugar de segmentación:
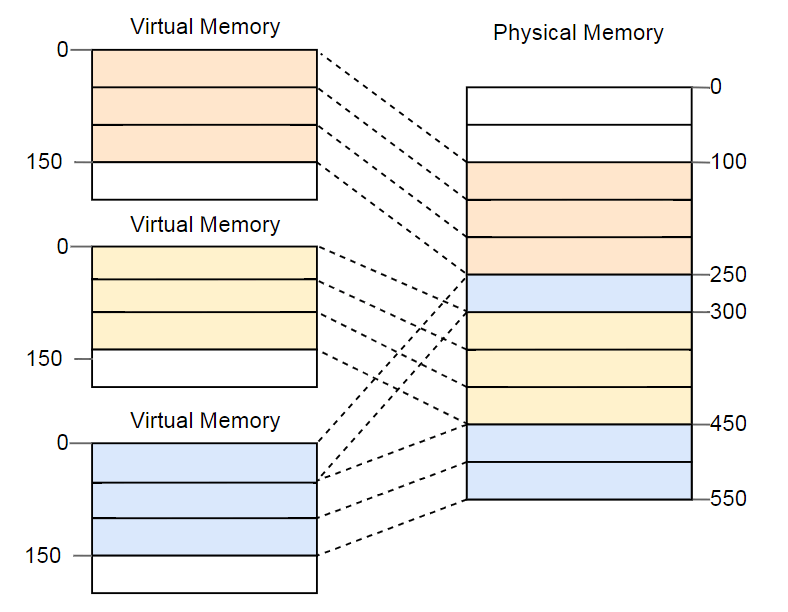
En este ejemplo, el tamaño de la página es de 50 bytes, es decir, cada una de las áreas de memoria se divide en tres páginas. Cada página se asigna a un marco separado, por lo que una región contigua de memoria virtual se puede asignar a marcos físicos aislados. Esto le permite ejecutar la tercera instancia del programa sin desfragmentación.
Fragmentación oculta
En comparación con la segmentación, una organización de paginación utiliza muchas áreas pequeñas de memoria de tamaño fijo en lugar de varias áreas grandes de tamaño variable. Cada cuadro tiene el mismo tamaño, por lo que no es posible la fragmentación debido a cuadros demasiado pequeños.
Pero esto es solo una
apariencia . De hecho, existe una forma oculta de fragmentación, la llamada
fragmentación interna debido al hecho de que no todas las áreas de memoria son exactamente un múltiplo del tamaño de la página. Imagine en el ejemplo anterior, un programa de tamaño 101: aún necesitará tres páginas de tamaño 50, por lo que tomará 49 bytes más de lo que necesita. Para mayor claridad, la fragmentación debida a la segmentación se denomina
fragmentación externa .
No hay nada bueno en la fragmentación interna, pero a menudo es un mal menor que la fragmentación externa. Todavía se consume memoria adicional, pero ahora no es necesario desfragmentarla, y el volumen de fragmentación es predecible (en promedio, media página por área de memoria).
Tablas de página
Vimos que cada uno de los millones de páginas posibles se asigna individualmente a un marco. Esta información de traducción de direcciones debe almacenarse en algún lugar. Al segmentar, se utilizan registros de segmento separados para cada área de memoria activa, lo cual es imposible en el caso de las páginas, porque hay muchos más que registros. En cambio, utiliza una estructura llamada
tabla de páginas .
Para el ejemplo anterior, las tablas se verán así:
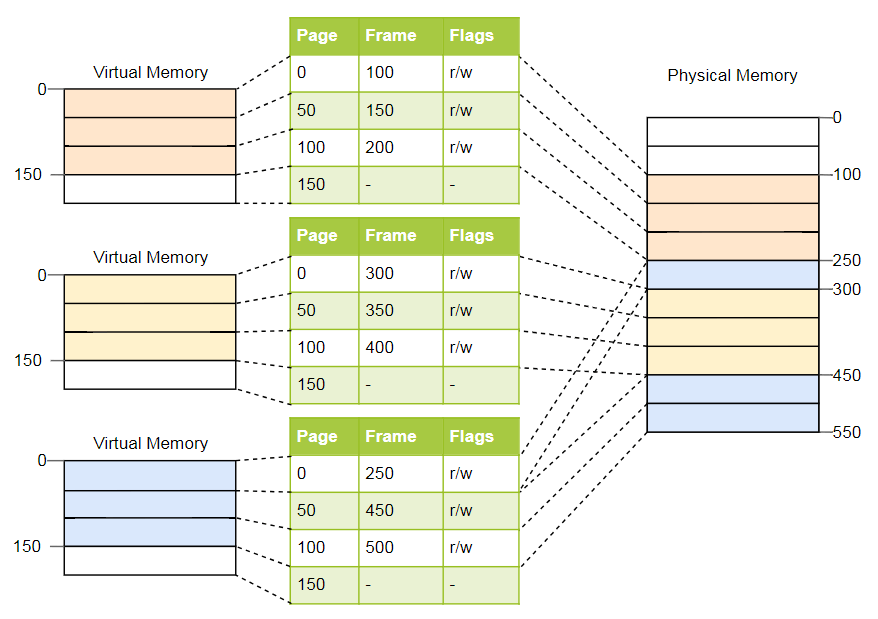
Como puede ver, cada instancia del programa tiene su propia tabla de páginas. Un puntero a la tabla activa actual se almacena en un registro especial de la CPU. En
x86 se llama
CR3 . Antes de comenzar cada instancia del programa, el sistema operativo debe cargar un puntero a la tabla de páginas correcta allí.
Cada vez que se accede a la memoria, la CPU lee el puntero de la tabla del registro y busca el marco correspondiente en la tabla. Esta es una función totalmente de hardware que se ejecuta de forma completamente transparente para un programa en ejecución. Para acelerar el proceso, muchas arquitecturas de procesador tienen un caché especial que recuerda los resultados de las últimas conversiones.
Según la arquitectura, los atributos como los permisos también se pueden almacenar en el campo de marca de la tabla de páginas. En el ejemplo anterior, el indicador
r/w hace que la página sea legible y escribible.
Tablas de página en capas
Las tablas de páginas simples tienen un problema con grandes espacios de direcciones: se desperdicia memoria. Por ejemplo, el programa usa cuatro páginas virtuales
0 ,
1_000_000 ,
1_000_050 y
1_000_100 (usamos
_ como separador de dígitos):
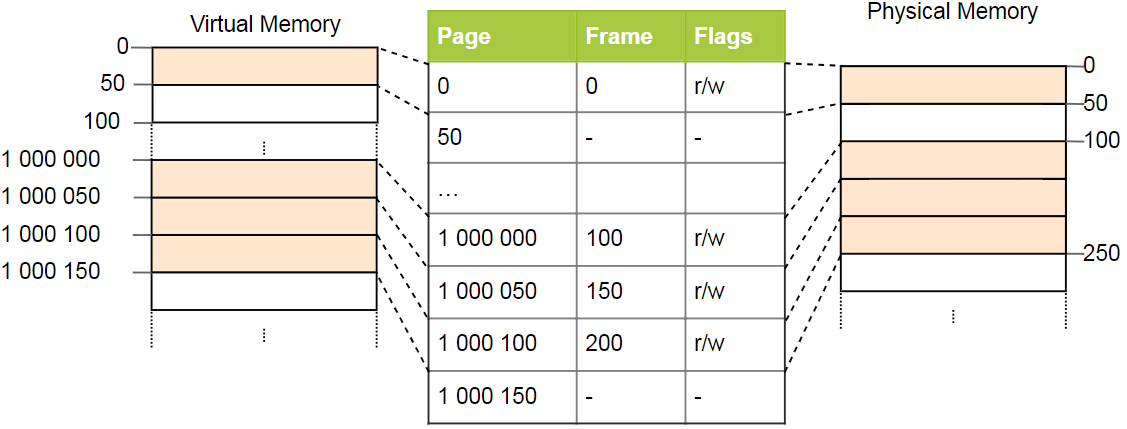
Solo se requieren cuatro marcos físicos, pero hay más de un millón de registros en la tabla de páginas. No podemos omitir entradas vacías, porque la CPU durante el proceso de conversión no podrá ir directamente a la entrada correcta (por ejemplo, ya no se garantiza que la cuarta página use la cuarta entrada).
Para reducir la pérdida de memoria, puede usar una
organización de dos niveles . La idea es que usemos diferentes tablas para diferentes áreas. Una tabla adicional, llamada tabla de páginas de
segundo nivel , convierte entre las áreas de direcciones y las tablas de páginas de primer nivel.
Esto se explica mejor con un ejemplo. Definimos que cada tabla de página de nivel 1 es responsable de un área de tamaño
10_000 . Luego, en el ejemplo anterior, existirán las siguientes tablas:
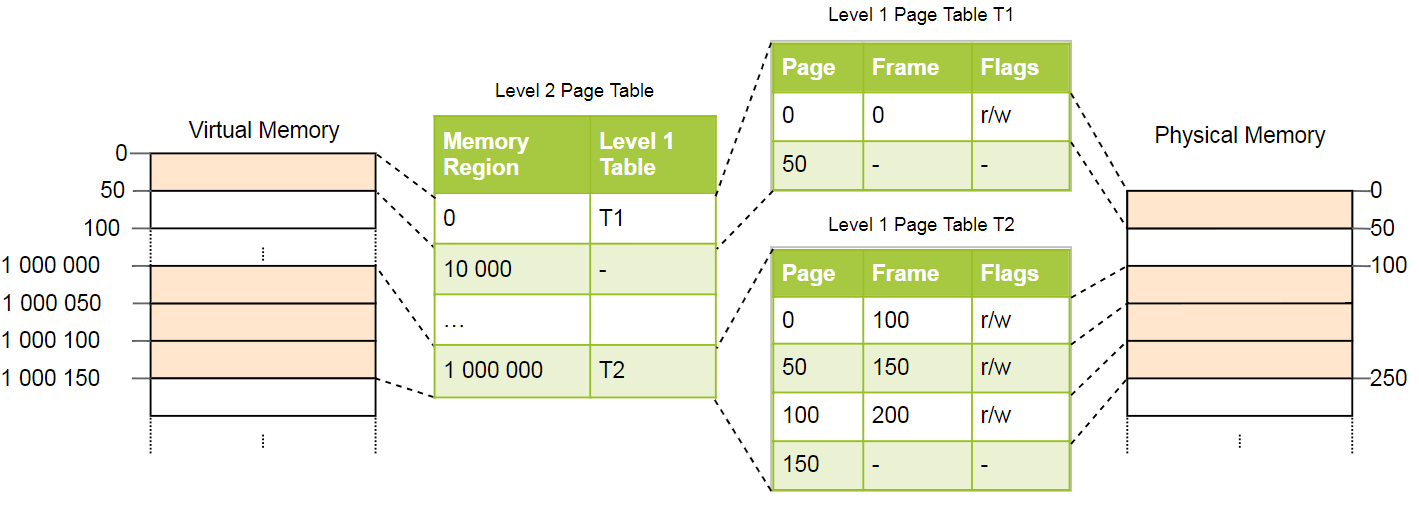
La página 0 se encuentra en la primera área de
10_000 bytes, por lo que utiliza el primer registro en la tabla de páginas del segundo nivel. Esta entrada apunta a la tabla de página T1 de primer nivel, que determina que la página 0 se refiere al cuadro 0.
Las páginas
1_000_000 ,
1_000_050 y
1_000_100 caen en la región de 100 bytes de
10_000 , por lo que utilizan el registro número 100 de la tabla de páginas de nivel 2. Este registro apunta a otra tabla de primer nivel T2, que traduce tres páginas en marcos 100, 150 y 200. Nota que la dirección de la página en las tablas del primer nivel no contiene un desplazamiento de región, por lo tanto, por ejemplo, el registro de la página
1_000_050 es solo
50 .
Todavía tenemos 100 entradas vacías en la tabla de segundo nivel, pero esto es mucho menos que el millón anterior. La razón de los ahorros es que no necesita crear tablas de páginas de primer nivel para áreas de memoria
10_000 entre
10_000 y
1_000_000 .
El principio de las tablas de dos niveles se puede extender a tres, cuatro o más niveles. En general, dicho sistema se denomina tabla de páginas
multinivel o
jerárquica .
Al conocer la organización de la página y las tablas de varios niveles, puede ver cómo se implementa la organización de la página en la arquitectura x86_64 (suponemos que el procesador se ejecuta en modo de 64 bits).
Organización de la página en x86_64
La arquitectura x86_64 utiliza una tabla de cuatro niveles con un tamaño de página de 4 KB. Independientemente del nivel, cada tabla de página tiene 512 elementos. Cada registro tiene un tamaño de 8 bytes, por lo que el tamaño de las tablas es de 512 × 8 bytes = 4 KB.

Como puede ver, cada índice de tabla contiene 9 bits, lo que tiene sentido, porque las tablas tienen 2 ^ 9 = 512 entradas. Los 12 bits inferiores son el desplazamiento de página de 4 kilobytes (2 ^ 12 bytes = 4 KB). Los bits 48 a 64 se descartan, por lo que x86_64 en realidad no es un sistema de 64 bits, sino que solo admite direcciones de 48 bits. Hay planes para expandir el tamaño de la dirección a 57 bits a través de una
tabla de páginas de 5 niveles , pero dicho procesador aún no se ha creado.
Aunque los bits 48 a 64 se descartan, no se pueden establecer en valores arbitrarios. Todos los bits en este rango deben ser copias del bit 47 para preservar direcciones únicas y permitir una expansión futura, por ejemplo, a una tabla de páginas de 5 niveles. Esto se llama extensión de signo, porque es muy similar a
una extensión de signo en código adicional . Si la dirección se expande incorrectamente, la CPU emite una excepción.
Ejemplo de conversión
Veamos un ejemplo de cómo funciona la traducción de direcciones:
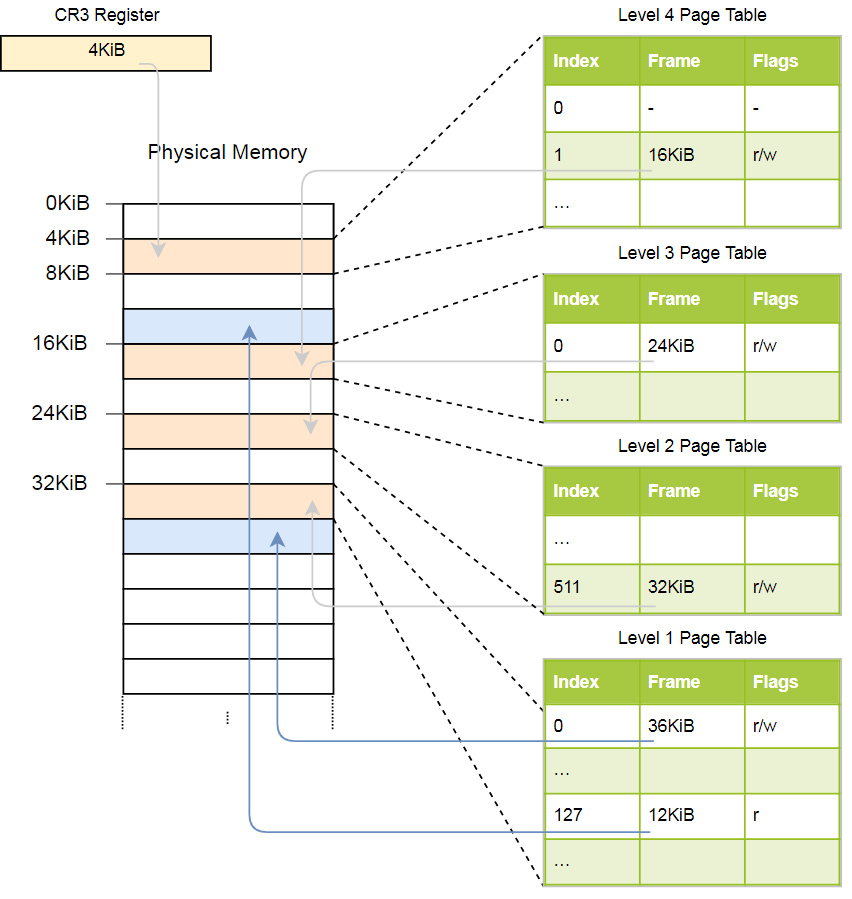
La dirección física de la tabla de página activa actual de las páginas de nivel 4, que es la tabla raíz de las páginas de página de este nivel, se almacena en el
CR3 . Cada entrada de la tabla de páginas señala el marco físico de la tabla de nivel siguiente. Una entrada de tabla de nivel 1 indica el marco visualizado. Tenga en cuenta que todas las direcciones en las tablas de página son físicas y no virtuales, porque de lo contrario la CPU necesitará convertir estas direcciones (lo que puede conducir a una recursión infinita).
La jerarquía anterior convierte dos páginas (en azul). A partir de los índices, podemos concluir que las direcciones virtuales de estas páginas son
0x803fe7f000 y
0x803FE00000 . Veamos qué sucede cuando un programa intenta leer la memoria en la dirección
0x803FE7F5CE . Primero, convierta la dirección a binario y determine los índices de la tabla de páginas y el desplazamiento de la dirección:

Con estos índices, ahora podemos pasar por la jerarquía de las tablas de páginas y encontrar el marco correspondiente:
- Lea la dirección de la tabla del cuarto nivel del
CR3 . - El índice del cuarto nivel es 1, por lo que miramos el registro con el índice 1 en esta tabla. Ella dice que una tabla de nivel 3 se almacena a 16 KB.
- Cargamos la tabla de tercer nivel desde esta dirección y miramos el registro con índice 0, que apunta a la tabla de segundo nivel con 24 KB.
- El índice del segundo nivel es 511, por lo que estamos buscando el último registro en esta página para encontrar la dirección de la tabla del primer nivel.
- De la entrada con el índice 127 en la tabla de primer nivel, finalmente descubrimos que la página corresponde a un marco de 12 KB o 0xc000 en formato hexadecimal.
- El paso final es agregar un desplazamiento a la dirección del marco para obtener la dirección física: 0xc000 + 0x5ce = 0xc5ce.
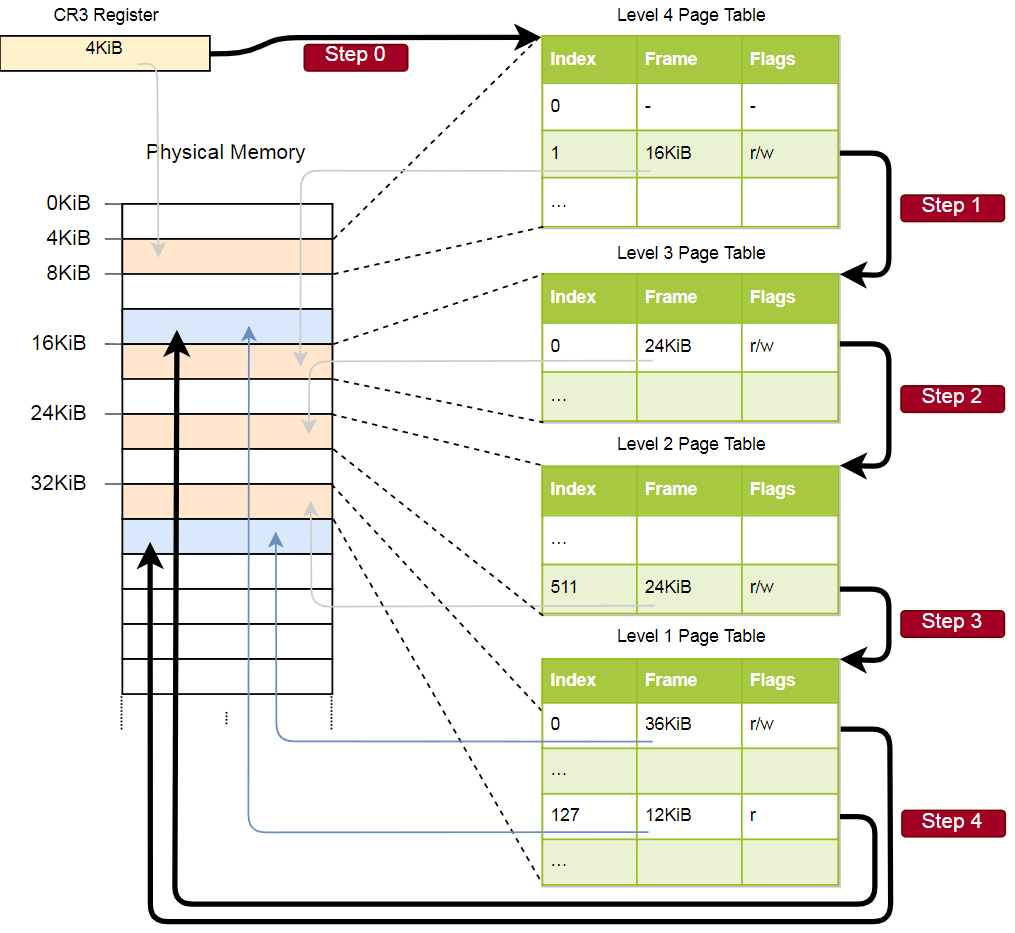
Para la página en la tabla del primer nivel, se especifica el indicador
r , es decir, solo se permite la lectura. Se lanzará una excepción a nivel de hardware si intentamos grabar allí. Los permisos de las tablas de nivel superior se extienden a los niveles inferiores, por lo que si establecemos el indicador de solo lectura en el tercer nivel, ni una sola página posterior del nivel inferior se podrá escribir, incluso si hay indicadores que permiten la escritura.
Aunque este ejemplo usa solo una instancia de cada tabla, generalmente en cada espacio de direcciones hay varias instancias de cada nivel. Máximo:
- una mesa del cuarto nivel,
- 512 tablas del tercer nivel (ya que hay 512 registros en la tabla del cuarto nivel),
- 512 * 512 tablas de segundo nivel (ya que cada una de las tablas de tercer nivel tiene 512 entradas), y
- 512 * 512 * 512 tablas del primer nivel (512 registros para cada tabla del segundo nivel).
Formato de tabla de página
En la arquitectura x86_64, las tablas de páginas son esencialmente matrices de 512 entradas. En sintaxis de Rust:
#[repr(align(4096))] pub struct PageTable { entries: [PageTableEntry; 512], }
Como se indica en el atributo
repr , las tablas deben estar alineadas en la página, es decir, en el borde de 4 KB. Este requisito asegura que la tabla siempre llene de manera óptima toda la página, haciendo que las entradas sean muy compactas.
El tamaño de cada registro es de 8 bytes (64 bits) y el siguiente formato:
| Bit (s) | Titulo | Valor |
|---|
| 0 0 | presente | página en memoria |
| 1 | grabable | registro permitido |
| 2 | accesible para el usuario | si el bit no está configurado, solo el núcleo tiene acceso a la página |
| 3 | escribir a través del almacenamiento en caché | escribir directamente en la memoria |
| 4 4 | deshabilitar caché | deshabilitar caché para esta página |
| 5 5 | accedido | La CPU establece este bit cuando la página está en uso. |
| 6 6 | sucio | La CPU establece este bit cuando escribe en la página |
| 7 7 | página enorme / nula | el bit cero en P1 y P4 crea páginas de 1 KB en P3, página de 2 MB en P2 |
| 8 | global | la página no se llena desde el caché al cambiar el espacio de direcciones (se debe establecer el bit PGE del registro CR4) |
| 9-11 | disponible | El sistema operativo puede usarlos libremente |
| 12-51 | dirección física | dirección física de 52 bits alineada con la página de la trama o la siguiente tabla de páginas |
| 52-62 | disponible | El sistema operativo puede usarlos libremente |
| 63 | no ejecutar | prohíbe la ejecución de código en esta página (el bit NXE debe establecerse en el registro EFER) |
Vemos que solo los bits 12-51 se utilizan para almacenar la dirección física de la trama, y el resto funciona como indicadores o puede ser utilizado libremente por el sistema operativo. Esto es posible porque siempre apuntamos a una dirección alineada con 4096 bytes, a una página alineada de tablas, o al comienzo del marco correspondiente. Esto significa que los bits 0-11 siempre son cero, por lo que no se pueden almacenar, simplemente se restablecen al nivel de hardware antes de usar la dirección. Lo mismo se aplica a los bits 52-63, ya que la arquitectura x86_64 solo admite direcciones físicas de 52 bits (y solo direcciones virtuales de 48 bits).
Echemos un vistazo más de cerca a las banderas disponibles:
- La bandera
present distingue las páginas mostradas de las que no se muestran. Se puede usar para guardar temporalmente páginas en el disco cuando la memoria principal está llena. La próxima vez que se accede a la página, se produce una excepción especial PageFault, a la que el sistema operativo responde intercambiando la página desde el disco; el programa continúa funcionando. - Las
writable y no execute determinan si el contenido de la página es grabable o contiene instrucciones ejecutables, respectivamente. - El procesador establece automáticamente
dirty marcas dirty y a las que accessed cuando lee o escribe en la página. El sistema operativo puede usar esta información, por ejemplo, si intercambia páginas o cuando verifica si el contenido de la página ha cambiado desde la última extracción al disco. - Las
write through caching y disable cache permiten administrar el caché para cada página individualmente. - El indicador
user accessible hace que la página sea accesible para el código desde el espacio del usuario; de lo contrario, solo está disponible para el núcleo. Esta función se puede usar para acelerar las llamadas al sistema mientras se mantiene la asignación de direcciones para el núcleo mientras se ejecuta el programa de usuario. Sin embargo, la vulnerabilidad Spectre permite a los programas leer estas páginas desde el espacio del usuario. global , (. TLB ) (address space switch). user accessible .huge page , 2 3 . 512 : 2 = 512 × 4 , 1 = 512 × 2 . .
La arquitectura x86_64 define el formato de las tablas de página y sus registros , por lo que no tenemos que crear estas estructuras nosotros mismos.Memoria intermedia de traducción asociativa (TLB)
Debido a los cuatro niveles, cada traducción de dirección requiere cuatro accesos a la memoria. Por motivos de rendimiento, x86_64 almacena en caché las últimas traducciones en el denominado búfer de traducción asociativa (TLB). Esto le permite omitir la conversión si todavía está en la memoria caché.A diferencia de otros cachés de procesador, TLB no es completamente transparente, no actualiza ni elimina conversiones al cambiar el contenido de las tablas de páginas. Esto significa que el núcleo debe actualizar el TLB en sí mismo siempre que modifique la tabla de páginas. Para hacer esto, hay una instrucción especial de CPU llamada invlpg(invalidar página), que elimina la traducción de la página especificada del TLB, de modo que la próxima vez que se vuelva a cargar de la tabla de páginas. TLB se borra completamente mediante la recarga del registroCR3que imita un interruptor de espacio de direcciones. Ambas opciones están disponibles a través del módulo tlb en Rust.Es importante recordar limpiar el TLB después de cada cambio de tabla de páginas, de lo contrario, la CPU continuará utilizando la traducción anterior, lo que conducirá a errores impredecibles que son muy difíciles de depurar.Implementación
No mencionamos una cosa: nuestro núcleo ya es compatible con la organización de la página . El gestor de arranque del artículo "Minimal Kernel on Rust" ya ha establecido una jerarquía de cuatro niveles que asigna cada página de nuestro kernel a un marco físico, porque la organización de la página se requiere en modo de 64 bits en x86_64.Esto significa que en nuestro núcleo todas las direcciones de memoria son virtuales. El acceso al búfer VGA en la dirección 0xb8000funcionó solo porque el identificador del gestor de arranque tradujo esta página a la memoria, es decir, asignó la página virtual 0xb8000al marco físico 0xb8000.Gracias a la organización de la página, el núcleo ya es relativamente seguro: cada acceso más allá de la memoria permitida provoca un error de página y no permite escribir en la memoria física. El cargador incluso estableció los permisos de acceso correctos para cada página: solo las páginas con código serán ejecutables, y solo las páginas con datos están disponibles para escribirErrores de página (PageFault)
Intentemos llamar a PageFault accediendo a la memoria fuera del núcleo. Primero, cree un controlador de errores y regístrelo en nuestro IDT para ver una excepción específica en lugar de un doble error de tipo general:
Si la página falla, la CPU establece automáticamente el caso CR2. Contiene la dirección virtual de la página que causó la falla. Para leer y mostrar esta dirección, use la función Cr2::read. Por lo general, el tipo PageFaultErrorCodeproporciona más información sobre el tipo de acceso a la memoria que causó el error, pero se transmite un código de error no válido debido al error LLVM , por lo que ignoraremos esta información por ahora. La ejecución del programa no puede continuar hasta que resolvamos el error de la página, así que inserte al final hlt_loop.Ahora tenemos acceso a la memoria fuera del núcleo:
Después de comenzar, vemos que se llama al controlador de errores de página: el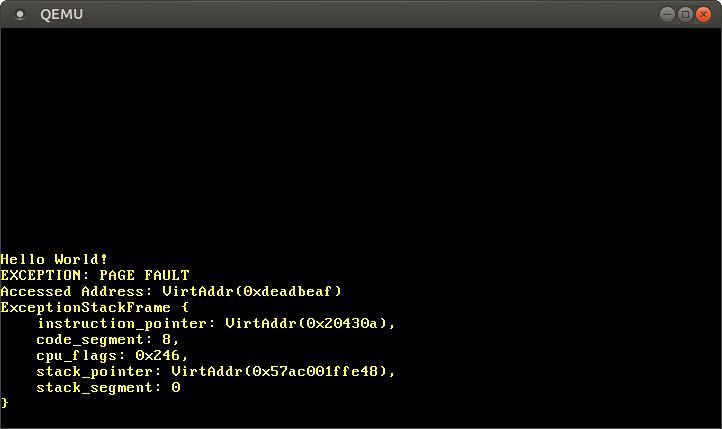 registro
registro CR2realmente contiene la dirección a la 0xdeadbeafque queríamos acceder.El puntero de instrucción actual es 0x20430a, por lo que sabemos que esta dirección apunta a una página de códigos. El cargador de solo lectura muestra las páginas de códigos, por lo que la lectura de esta dirección funciona y la escritura provocará un error. Intente cambiar el puntero 0xdeadbeafa 0x20430a:
Si comentamos la última línea, podemos asegurarnos de que la lectura funcione y que la escritura provoque un error de PageFault.Acceso a tablas de páginas.
Ahora eche un vistazo a las tablas de páginas para el núcleo:
La función Cr3::readde x86_64devuelve del registro la CR3tabla activa actual de páginas del cuarto nivel. Vuelve una pareja PhysFramey Cr3Flags. Solo nos interesa lo primero.Después de comenzar, vemos este resultado: por loLevel 4 page table at: PhysAddr(0x1000)tanto, en la actualidad, la tabla activa de páginas del cuarto nivel se almacena en la memoria física en la dirección 0x1000indicada por el tipo PhysAddr. Ahora la pregunta es: ¿cómo acceder a esta tabla desde el núcleo?Con la organización de la página, el acceso directo a la memoria física no es posible; de lo contrario, los programas podrán eludir fácilmente la protección y obtener acceso a la memoria de otros programas. Por lo tanto, la única forma de obtener acceso es a través de alguna página virtual, que se traduce en un marco físico en0x1000. Este es un problema típico porque el núcleo debería acceder regularmente a las tablas de páginas, por ejemplo, al asignar una pila para un nuevo hilo.Las soluciones a este problema se describirán en detalle en el próximo artículo. Por ahora, digamos que el cargador utiliza un método llamado tablas de páginas recursivas . La última página del espacio de direcciones virtuales es 0xffff_ffff_ffff_f000, la usamos para leer algunas entradas en esta tabla:
Hemos reducido la dirección de la última página virtual a un puntero a u64. Como se indicó en la sección anterior, cada entrada de la tabla de páginas tiene un tamaño de 8 bytes (64 bits) y, por lo tanto, u64representa exactamente una entrada. Usando el bucle, formostramos los primeros 10 registros de la tabla. Dentro del bucle, usamos un bloque inseguro para leer directamente desde el puntero y offsetcalcular el puntero.Después de iniciar vemos los siguientes resultados: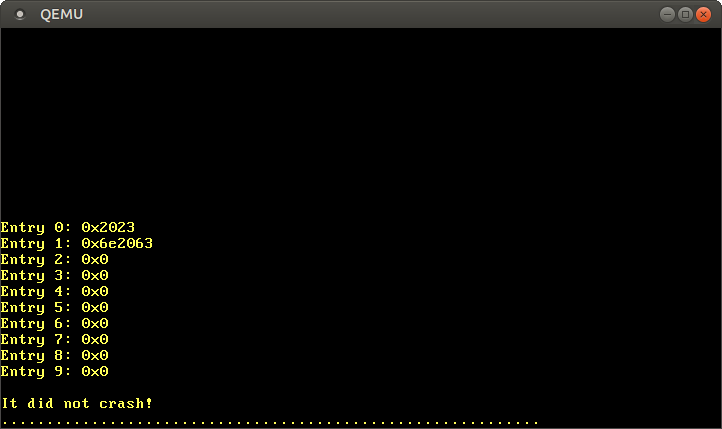 De acuerdo con el formato descrito anteriormente, el valor
De acuerdo con el formato descrito anteriormente, el valor 0x2023medio de grabación que tiene banderas 0 present, writable, accessedy la traducción en un marco 0x2000. El registro 1 se transmite en el marco 0x6e2000y tiene las mismas banderas, ademásdirty. Faltan las entradas 2–9, por lo que estos rangos de direcciones virtuales no se asignan a ninguna dirección física.En lugar de trabajar con punteros inseguros directamente, puede usar un tipo PageTablede x86_64:
0xffff_ffff_ffff_f000 , Rust. - , , .
&PageTable , ,
.
x86_64 , :

— 0 1 3. ,
0x2000 0x6e5000 , . .
Resumen
El artículo presenta dos métodos para proteger la memoria: segmentación y organización de la página. El primer método usa áreas de memoria de tamaño variable y sufre fragmentación externa, el segundo usa páginas de tamaño fijo y permite un control mucho más granular sobre los derechos de acceso.Una organización de páginas almacena información de traducción de páginas en tablas de uno o más niveles. La arquitectura x86_64 usa tablas de cuatro niveles con un tamaño de página de 4 KB. El equipo omite automáticamente las tablas de páginas y almacena en caché los resultados de conversión en el búfer de traducción asociativa (TLB). Al cambiar las tablas de páginas, debe forzarse a limpiar.Aprendimos que nuestro núcleo ya es compatible con la organización de la página, y que el acceso no autorizado a la memoria deja caer PageFault. Intentamos acceder a las tablas de página actualmente activas, pero logramos acceder solo a la tabla de cuarto nivel, ya que las direcciones de página almacenan direcciones físicas, y no podemos acceder a ellas directamente desde el núcleo.Que sigue
El siguiente artículo se basa en los fundamentos fundamentales que ahora hemos aprendido. Para acceder a las tablas de páginas desde el kernel, se utiliza una técnica avanzada llamada tablas de páginas recursivas para recorrer la jerarquía de tablas e implementar la traducción programática de direcciones. El artículo también explica cómo crear nuevas traducciones en tablas de páginas.