Recordatorio
Hola Habr! Les traigo a su atención otra traducción de mi nuevo artículo del
medio .
La última vez (
primer artículo ) (
Habr ), creamos un agente utilizando la tecnología Q-Learning, que realiza transacciones en series de tiempo de intercambio simuladas y reales e intentamos verificar si esta área de tareas es adecuada para el aprendizaje reforzado.
Esta vez agregaremos una capa LSTM para tener en cuenta las dependencias de tiempo dentro de la trayectoria y hacer una recompensa en función de las presentaciones.
Permítame recordarle que para verificar el concepto, utilizamos los siguientes datos sintéticos:
Datos sintéticos: seno con ruido blanco.
La función seno fue el primer punto de partida. Dos curvas simulan el precio de compra y venta de un activo, donde el diferencial es el costo mínimo de transacción.
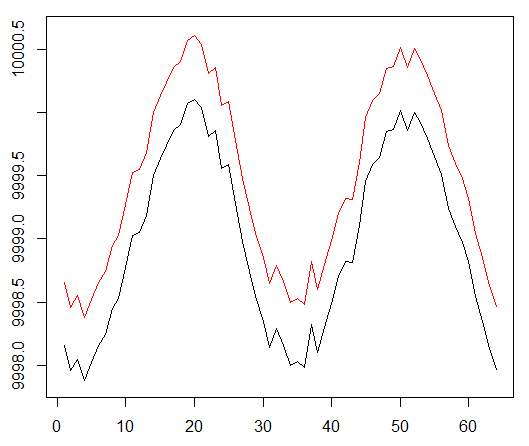
Sin embargo, esta vez queremos complicar esta tarea simple al extender la ruta de asignación de crédito:
Datos sintéticos: seno con ruido blanco.
La fase sinusal se duplicó.
Esto significa que las escasas recompensas que utilizamos deben extenderse en trayectorias más largas. Además, reducimos significativamente la probabilidad de recibir una recompensa positiva, ya que el agente tuvo que realizar una secuencia de acciones correctas 2 veces más para superar los costos de transacción. Ambos factores complican enormemente la tarea de RL incluso en condiciones tan simples como una onda sinusoidal.
Además, recordamos que utilizamos esta arquitectura de red neuronal:
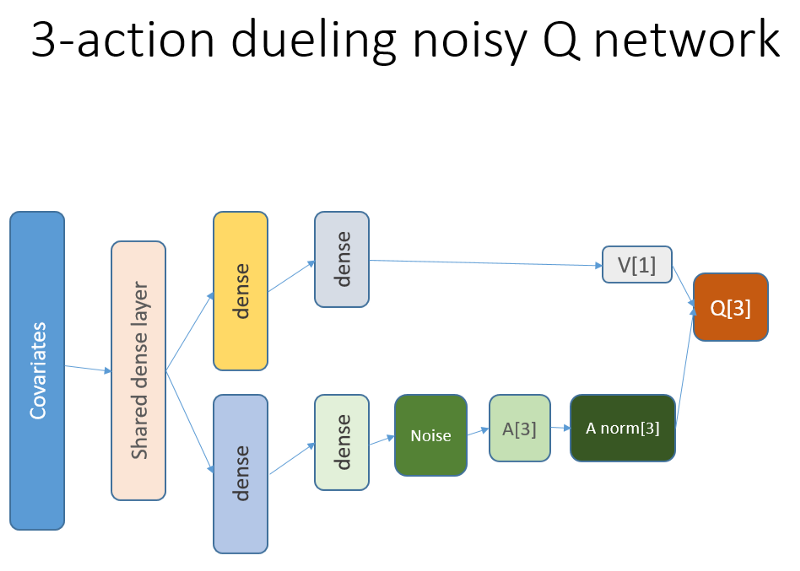
Qué se agregó y por qué
Lstm
En primer lugar, queríamos darle al agente una mayor comprensión de la dinámica de los cambios dentro de la trayectoria. En pocas palabras, el agente debe comprender mejor su propio comportamiento: lo que hizo en este momento y durante algún tiempo en el pasado, y cómo se desarrolló la distribución de las acciones estatales, así como las recompensas recibidas. El uso de una capa de recurrencia puede resolver exactamente este problema. Bienvenido a la nueva arquitectura utilizada para lanzar un nuevo conjunto de experimentos:

Tenga en cuenta que he mejorado ligeramente la descripción. La única diferencia con el antiguo NN es la primera capa LSTM oculta en lugar de una capa completamente unida.
Tenga en cuenta que con LSTM en el trabajo, debemos cambiar la selección de ejemplos de reproducción de la experiencia para el entrenamiento: ahora necesitamos secuencias de transición en lugar de ejemplos separados. Así es como funciona (este es uno de los algoritmos). Utilizamos puntos de muestreo antes:

El esquema ficticio del búfer de reproducción.
Utilizamos este esquema con LSTM:

Ahora se seleccionan las secuencias (cuya longitud especificamos empíricamente).
Como antes, y ahora la muestra está regulada por un algoritmo de prioridad basado en errores de aprendizaje temporal-temporal.
El nivel de recurrencia LSTM permite la difusión directa de información de series de tiempo para interceptar una señal adicional oculta en retrasos pasados. La serie temporal con nosotros es un tensor bidimensional con tamaño: la longitud de la secuencia en la representación de nuestra acción estatal.
Presentaciones
La ingeniería galardonada, Potential Based Reward Shaping (PBRS), basada en el potencial, es una herramienta poderosa que le permite aumentar la velocidad, la estabilidad y no violar la optimización del proceso de búsqueda de políticas para resolver nuestro entorno. Recomiendo leer al menos este documento original sobre el tema:
people.eecs.berkeley.edu/~russell/papers/ml99-shaping.psEl potencial determina qué tan bien nuestro estado actual es relativo al estado objetivo en el que queremos ingresar. Una vista esquemática de cómo funciona esto:

Hay opciones y dificultades que podría comprender después de la prueba y error, y omitimos estos detalles, dejándolo con su tarea.
Vale la pena mencionar una cosa más, que es que PBRS puede justificarse mediante presentaciones, que son una forma de conocimiento experto (o simulado) sobre el comportamiento
casi óptimo del agente en el medio ambiente. Hay una manera de encontrar tales presentaciones para nuestra tarea utilizando esquemas de optimización. Omitimos los detalles de la búsqueda.
La recompensa potencial toma la siguiente forma (ecuación 1):
r '= r + gamma * F (s') - F (s)
donde F es el potencial del estado y r es la recompensa inicial, gamma es el factor de descuento (0: 1).
Con estos pensamientos, pasamos a la codificación.Implementación en R
Aquí está el código de red neuronal basado en la API de Keras:
Depuración de su decisión sobre su conciencia ...
Resultados y comparación
Vamos a sumergirnos en los resultados finales.
Nota: todos los resultados son estimaciones puntuales y pueden diferir en múltiples ejecuciones con diferentes sid de semillas al azar.La comparación incluye:
- versión anterior sin LSTM y presentaciones
- LSTM simple de 2 elementos
- LSTM de 4 elementos
- LSTM de 4 celdas con recompensas PBRS generadas
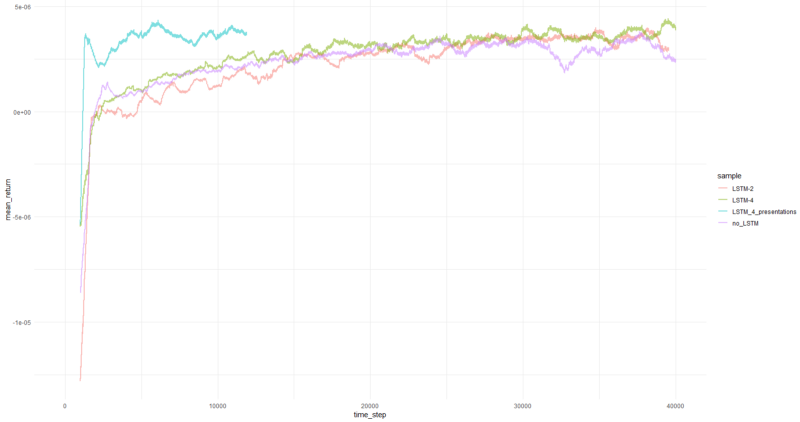
El rendimiento promedio por episodio promedió más de 1000 episodios.
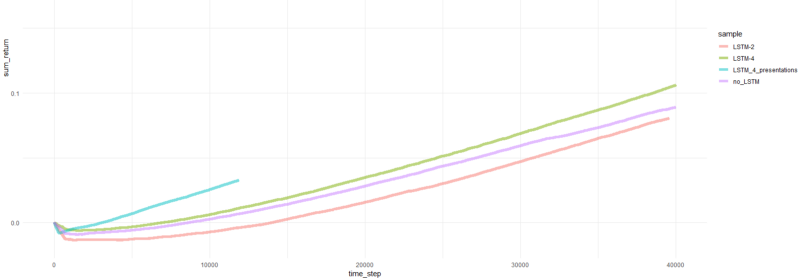
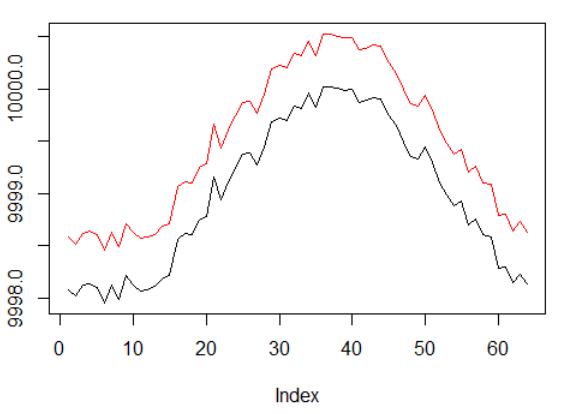
El episodio total vuelve.
Gráficos para el agente más exitoso:

Rendimiento del agente.
Bueno, es bastante obvio que el agente en forma de PBRS converge de manera tan rápida y estable en comparación con intentos anteriores que puede aceptarse como un resultado significativo. La velocidad es aproximadamente 4-5 veces mayor que sin presentaciones. La estabilidad es maravillosa.
Cuando se trata de usar LSTM, 4 células se desempeñaron mejor que 2 células. Un LSTM de 2 celdas funcionó mejor que una versión no LSTM (sin embargo, tal vez esto sea una ilusión de un solo experimento).
Palabras finales
Hemos visto que las recompensas de recurrencia y creación de capacidad ayudan. Me gustó especialmente cómo el PBRS se desempeñó tan bien.
No le crea a nadie que me haga decir que es fácil crear un agente de RL que converja bien, ya que eso es mentira. Cada nuevo componente agregado al sistema lo hace potencialmente menos estable y requiere mucha configuración y depuración.
Sin embargo, existe evidencia clara de que la solución al problema puede mejorarse simplemente mejorando los métodos utilizados (los datos permanecieron intactos). Es un hecho que para cualquier tarea un cierto rango de parámetros funciona mejor que otros. Con esto en mente, te embarcas en un camino de aprendizaje exitoso.
Gracias